Diagnostic d’un incident à l’aide de Metrics Advisor
Important
Depuis le 20 septembre 2023, vous ne pouvez plus créer de ressources Metrics Advisor. Le service Metrics Advisor sera mis hors service le 1er octobre 2026.
Qu’est-ce qu’un incident ?
Lorsqu’il existe des anomalies détectées sur plusieurs séries chronologiques au sein d’une seule métrique à un horodatage donné, Metrics Advisor regroupe automatiquement les anomalies qui partagent la même cause racine en un incident. Un incident indique généralement un vrai problème, Metrics Advisor effectue une analyse et fournit des insights d’analyse automatique de la cause racine.
Cela permet de supprimer de manière significative les efforts du client pour afficher chaque anomalie et de trouver rapidement le facteur contributif le plus important relatif à un problème.
Une alerte générée par Metrics Advisor peut contenir plusieurs incidents et chaque incident peut contenir plusieurs anomalies capturées sur différentes séries chronologiques pour un même horodatage.
Chemins pour diagnostiquer un incident
Diagnostiquer à partir d’une notification d’alerte
Si vous avez configuré un hook du type e-mail/Teams et appliqué au moins une configuration d’alerte, vous recevrez des notifications d’alerte continues remontant les incidents analysés par Metrics Advisor. Cette notification contient une liste d’incidents et une brève description. Pour chaque incident, un bouton « Diagnostiquer » vous dirigera vers la page de détails de l’incident pour consulter les insights de diagnostic.
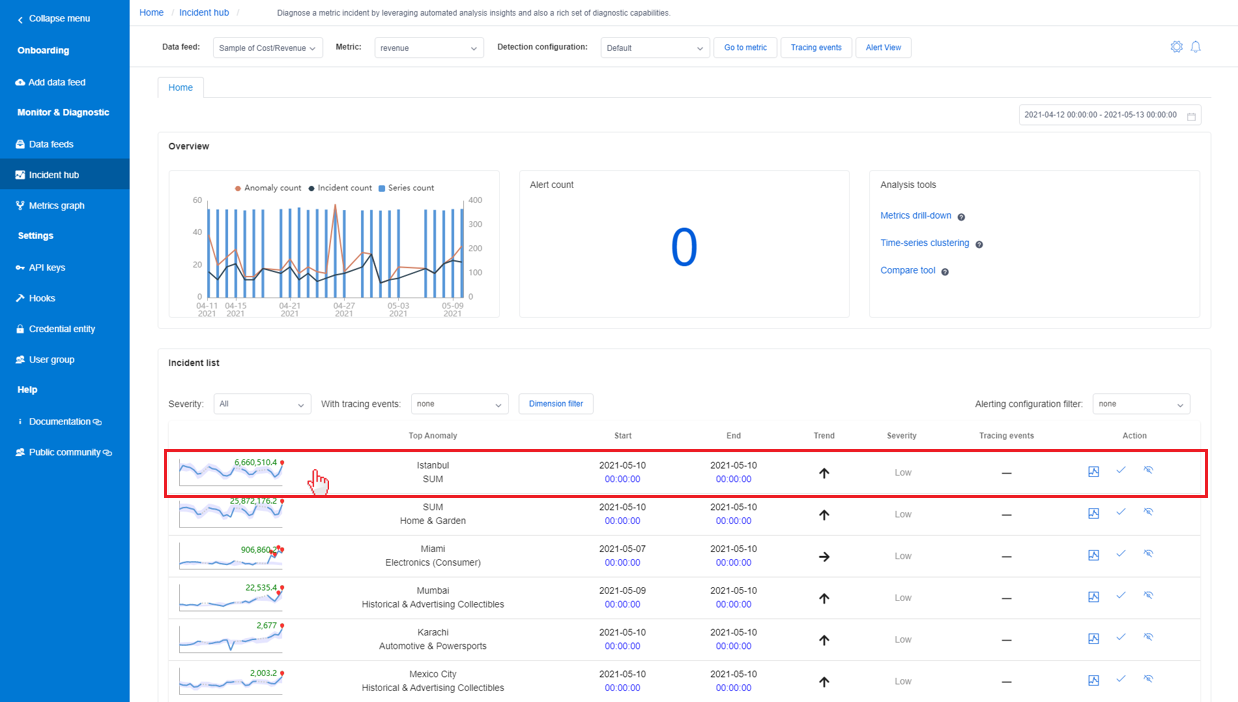
Diagnostiquer à partir d’un incident dans le « hub d’incidents »
Metrics Advisor offre un emplacement central qui rassemble tous les incidents qui ont été capturés et facilite le suivi des problèmes en cours. La sélection de l’onglet Hub d’incidents dans la barre de navigation de gauche répertorie tous les incidents au sein des métriques sélectionnées. Dans la liste des incidents, sélectionnez-en un pour voir des insights de diagnostic détaillés.
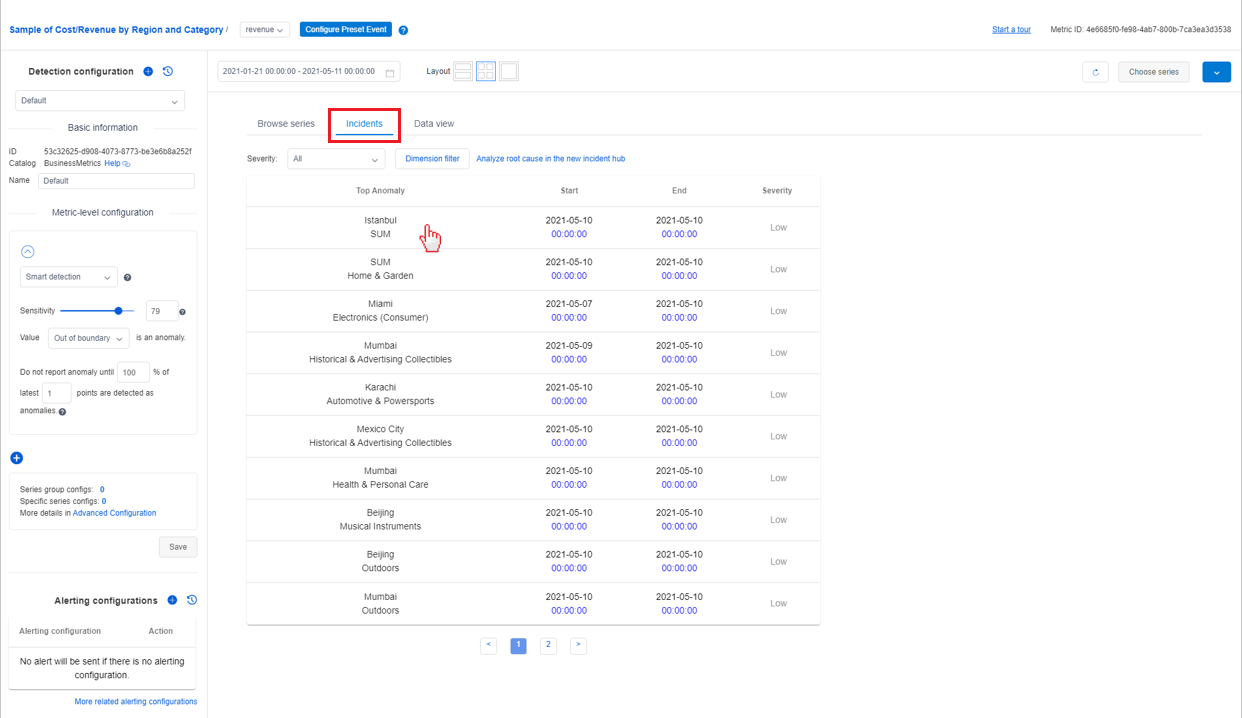
Diagnostiquer à partir d’un incident figurant dans la page des métriques
La page de détails des métriques contient un onglet nommé Incidents qui liste les incidents les plus récents capturés pour cette métrique. La liste peut être filtrée en fonction de la gravité des incidents ou de la valeur de dimension des métriques.
La sélection d’un incident dans la liste vous dirige vers la page de détails de l’incident où vous pouvez consulter les insights de diagnostic.
Flux de diagnostic standard
Une fois dirigé vers la page de détails d’un incident, vous pouvez tirer parti des insights qui sont automatiquement analysés par Metrics Advisor pour localiser rapidement la cause racine d’un problème ou utiliser l’outil d’analyse pour poursuivre l’évaluation de l’impact du problème. Les trois sections de la page Détails de l’incident correspondent aux trois étapes principales pour diagnostiquer un incident.
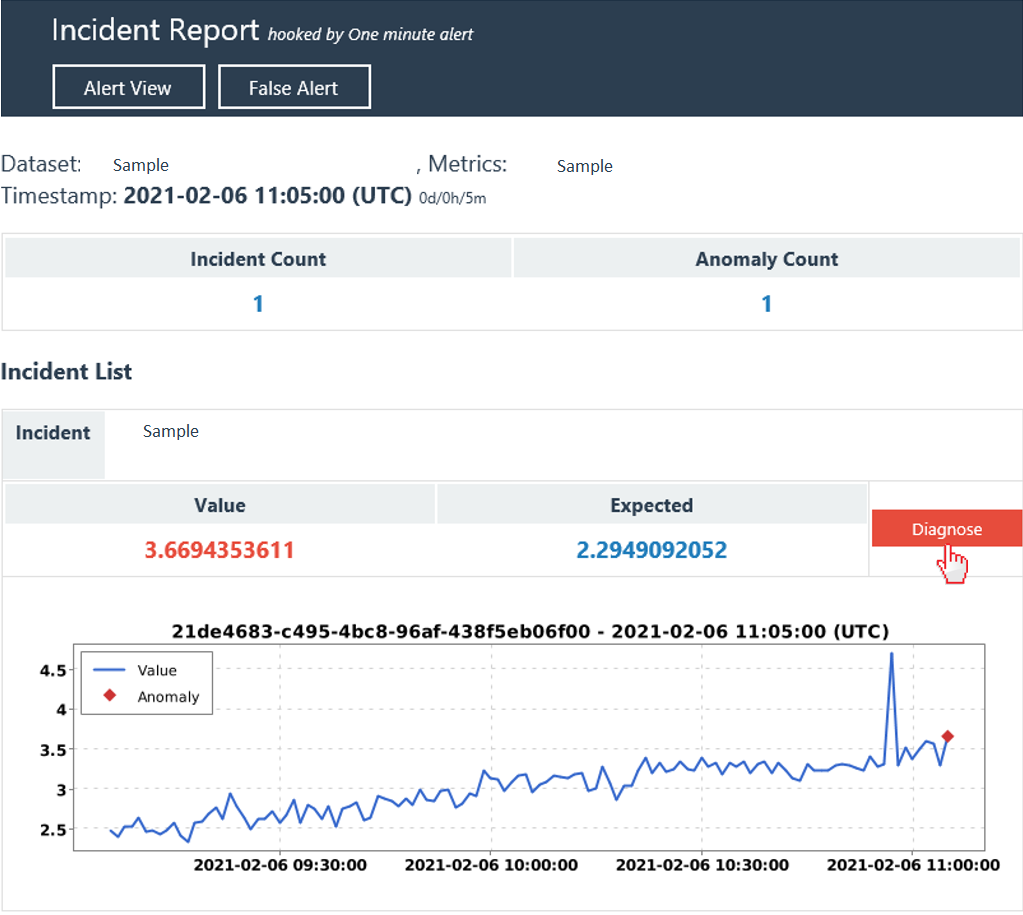
Étape 1 : Vérifier le résumé de l’incident actuel
La première section fournit un résumé de l’incident actuel, comprenant les informations de base, les actions et les suivis et une cause racine analysée.
Les informations de base incluent la « série Top impactée » avec un diagramme « impact Start & End Time », « gravité incident » et « nombre total d’anomalies incluses ». En lisant cela, vous pouvez obtenir une bonne compréhension de base d’un problème en cours et de son impact.
Actions et suivis : cette section est utilisée pour faciliter la collaboration d’équipe sur un incident en cours. Parfois, l’analyse et la résolution d’un incident peuvent nécessiter l’effort des membres de plusieurs équipes. Toute personne disposant de l’autorisation d’afficher l’incident peut ajouter une action ou un événement de suivi.
Par exemple, une fois l’incident diagnostiqué et la cause racine identifiée, un ingénieur peut ajouter un élément de suivi avec le type « personnalisé » et entrer la cause racine dans la section des commentaires. Laissez l’état « actif ». Ensuite, d’autres coéquipiers peuvent partager les mêmes informations et savoir qu’une personne travaille au correctif. Vous pouvez également ajouter un élément « Azure DevOps » pour suivre l’incident à l’aide d’une tâche ou d’un bogue spécifique.
La cause racine analysée est un résultat analysé automatiquement. Metrics Advisor analyse toutes les anomalies capturées sur les séries chronologiques au sein d’une métrique avec des valeurs de dimension différentes pour un même horodatage. Il effectue ensuite la corrélation, le clustering pour regrouper les anomalies associées et générer un avis de cause racine.
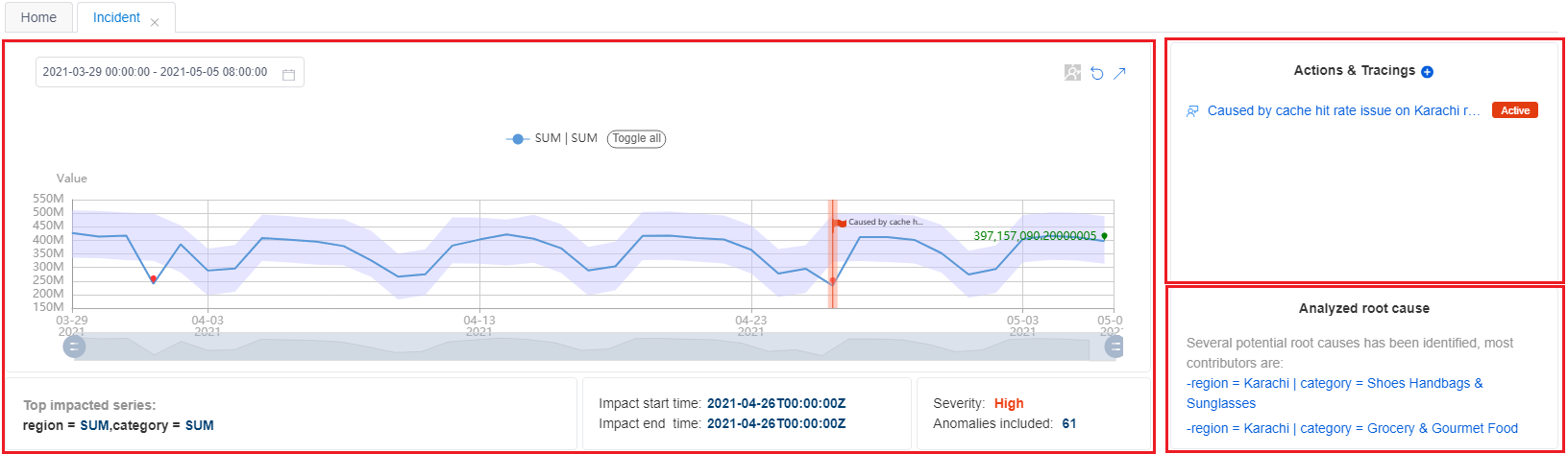
Pour les métriques à plusieurs dimensions, il est fréquent que plusieurs anomalies soient détectées en même temps. Toutefois, ces anomalies peuvent partager la même cause racine. Au lieu d’analyser toutes les anomalies une par une, tirer parti de la cause racine analysée doit être le moyen le plus efficace de diagnostiquer l’incident actuel.
Étape 2 : Visualiser les aperçus du diagnostic trans-dimensionnel
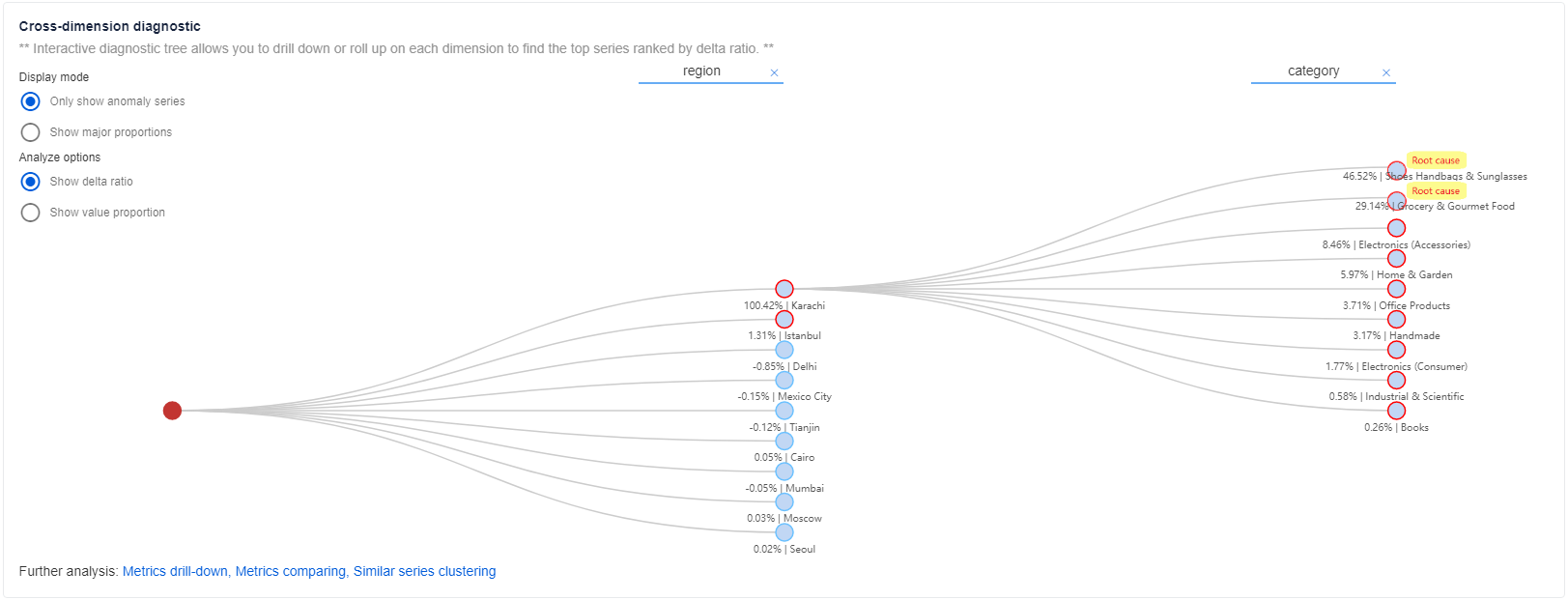
Après avoir obtenu des informations de base et une analyse automatique, vous pouvez obtenir des informations plus détaillées sur l’état anormal des autres dimensions dans la même métrique de façon holistique à l’aide de l’ « arborescence de diagnostic » .
Pour les métriques à plusieurs dimensions, Metrics Advisor classe les séries chronologiques dans une hiérarchie, nommée Arborescence de diagnostic. Par exemple, une mesure « chiffre d’affaires » est analysée par deux dimensions : « région » et « catégorie ». Malgré les valeurs de dimension concrètes, il doit y avoir une valeur de dimension agrégée, telle que « Somme » . Ensuite, les séries chronologiques « Région » = « Somme » et « Catégorie » = « Somme » sont classées comme nœud racine dans l’arborescence. Lorsqu’une anomalie est capturée à la dimension « Somme » , elle peut être extraite et analysée pour localiser la valeur de dimension spécifique qui a contribué le plus à l’anomalie du nœud parent. Sélectionnez chaque nœud à développer et consultez les informations détaillées.
Pour activer une valeur de dimension « agrégée » dans vos métriques
Metrics Advisor prend en charge l’exécution d’une fonction « Roll-up » (cumul) sur les dimensions pour calculer une valeur de dimension « agrégée ». L’arborescence de diagnostic prend en charge le diagnostic sur les agrégations « SUM », « AVG », « MAX », « MIN », « COUNT » . Pour activer une valeur de dimension « agrégée », vous pouvez activer la fonction « Roll-up » (cumul) au cours de l’intégration des données. Assurez-vous que vos métriques sont calculées mathématiquement et que la dimension agrégée a une valeur métier réelle.

S’il n’y a aucune valeur de dimension « agrégée » dans vos métriques
S’il n’y a aucune valeur de dimension « agrégée » dans vos métriques et que la fonction « Roll-up » (cumul) n’est pas activée au cours de l’intégration des données. Aucune valeur de métrique n’est calculée pour la dimension « agrégée », elle apparaît sous la forme d’un nœud gris dans l’arborescence et peut être développée pour afficher ses nœuds enfants.
Légende de l’arborescence de diagnostic
Il existe trois types de nœuds dans l’arborescence de diagnostic :
- Nœud bleu, qui correspond à une série chronologique avec une valeur métrique réelle.
- Nœud gris, qui correspond à une série chronologique virtuelle sans valeur métrique ; il s’agit d’un nœud logique.
- Nœud rouge, qui correspond à la série chronologique la plus affectée de l’incident actuel.
Pour chaque nœud, l’état anormal est décrit par la couleur de la bordure du nœud.
- Une bordure rouge signifie qu’une anomalie a été capturée sur la série chronologique correspondant à l’horodatage de l’incident.
- Une bordure autre que rouge signifie qu’aucune anomalie n’a été capturée sur la série chronologique correspondant à l’horodatage de l’incident.
Mode d’affichage
Il existe deux modes d’affichage pour une arborescence de diagnostic : afficher uniquement les séries avec anomalies ou afficher les proportions majeures.
- Le mode Afficher uniquement les séries avec anomalies permet au client de se concentrer sur les anomalies actuelles capturées sur différentes séries et de diagnostiquer la cause racine des principales séries affectées.
- Le mode Afficher les proportions majeures permet au client de vérifier l’état anormal des proportions majeures des principales séries impactées. Dans ce mode, l’arborescence affiche à la fois les séries avec une anomalie détectée et les séries sans anomalie, en mettant l’accent sur les séries importantes.
Options d’analyse
Show delta ratio (Afficher le taux de delta)
Le « taux de delta » est le pourcentage du delta du nœud actuel par rapport au delta du nœud parent. La formule est la suivante :
(valeur réelle du nœud actuel – valeur attendue du nœud actuel) / (valeur réelle du nœud parent – valeur attendue du nœud parent) * 100 %
Cette valeur est utilisée pour analyser la contribution majeure du delta du nœud parent.
Show value proportion (Afficher la proportion de valeur)
La « proportion de valeur » est le pourcentage de la valeur du nœud actuel par rapport à la valeur du nœud parent. La formule est la suivante :
(valeur réelle du nœud actuel / valeur réelle du nœud parent) * 100 %
Cette valeur est utilisée pour évaluer la proportion de nœud actuel dans l’ensemble.
En utilisant l’« arborescence de diagnostic », les clients peuvent localiser la cause racine de l’incident actuel dans une dimension spécifique. Cela supprime de manière significative les efforts du client pour afficher chaque anomalie ou parcourir différentes dimensions afin de trouver la contribution à l’anomalie principale.
Étape 3 : Afficher les informations de diagnostic des mesures croisées à l’aide du « graphique de métriques »
Parfois, il est difficile d’analyser un problème en vérifiant l’état anormal d’une métrique unique, et vous devez mettre en corrélation plusieurs métriques. Les clients sont en mesure de configurer un graphique de métriques qui indique la relation entre les métriques. Reportez-vous à Création d’un graphique de métriques pour commencer.
Vérifier l’état d’anomalie dans la dimension de cause racine dans le « graphique de métriques »
En utilisant le résultat de diagnostic inter-dimensions ci-dessus, la cause racine est limitée à une valeur de dimension spécifique. Utilisez ensuite le « graphique de métriques » et filtrez en fonction de la dimension de cause racine analysée pour vérifier l’état d’anomalie sur d’autres métriques.
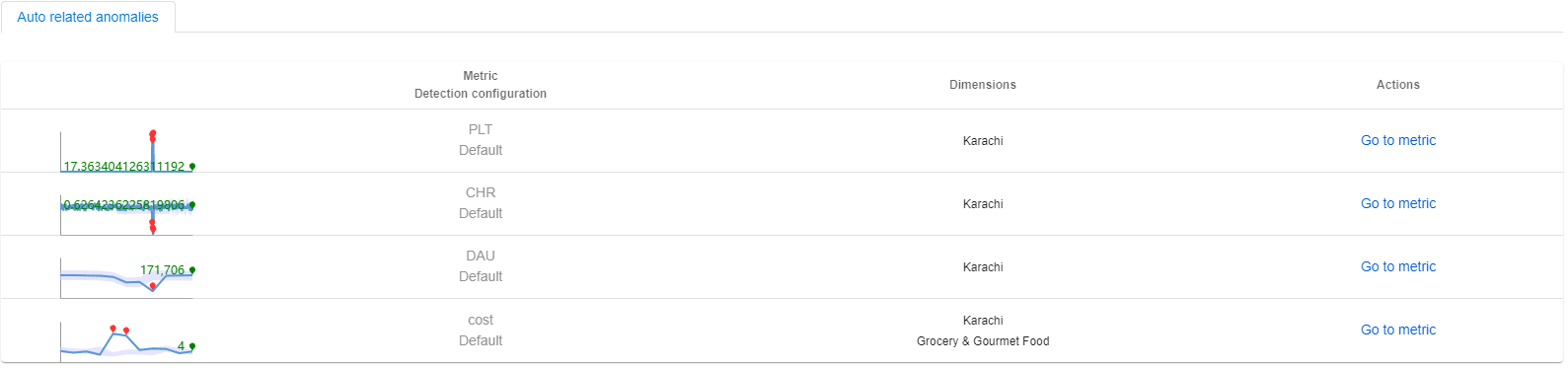
Par exemple, si un incident est capturé sur les métriques « revenus ». La série la plus affectée est dans la région globale avec « région » = « SUM ». En utilisant le diagnostic inter-dimensions, la cause racine a été localisée sur « région » = « Karachi ». Il existe un graphique de métriques préconfiguré, comprenant les métriques « revenu », « coût », « DAU », « PLT(temps de chargement de la page) » et « CHR(taux d’accès au cache) ».
Metrics Advisor filtre automatiquement le graphique de métriques en fonction de la dimension de la cause racine de « région » = « Karachi » et affiche l’état d’anomalie de chaque métrique. En analysant la relation entre les métriques et l’état d’anomalie, les clients peuvent obtenir davantage d’insights sur la cause racine finale.

Anomalies liées automatiquement
Si vous appliquez le filtre de dimension de cause racine au graphique des métriques, les anomalies sur chaque métrique à l’horodatage de l’incident actuel sont liées de manière automatique. Ces anomalies doivent être associées à la cause racine identifiée de l’incident actuel.