Permettez à une application de gérer les défaillances temporaires quand elle tente de se connecter à un service ou à une ressource réseau en réessayant d’exécuter en toute transparence une opération qui a échoué. Cela peut améliorer la stabilité de l’application.
Contexte et problème
Une application qui communique avec des éléments en cours d’exécution dans le cloud doit être sensible aux défaillances temporaires qui peuvent se produire dans cet environnement. Les défaillances incluent la perte momentanée de la connectivité réseau aux composants et aux services, l’indisponibilité passagère d’un service ou les expirations de délai qui surviennent lorsqu’un service est occupé.
Ces défaillances se corrigent généralement d’elles-mêmes, et si l’action qui a déclenché une défaillance est répétée après un délai approprié, il est probable qu’elle aboutisse. Par exemple, un service de base de données qui traite un grand nombre de requêtes simultanées peut implémenter une stratégie de limitation qui rejette temporairement toute requête supplémentaire jusqu’à allègement de sa charge de travail. Il est possible qu’une application qui tente d’accéder à la base de données ne parvienne pas à se connecter, mais si elle tente à nouveau après un certain délai, elle peut réussir.
Solution
Dans le cloud, les défaillances temporaires ne sont pas rares et une application doit être conçue pour les gérer avec soin et en toute transparence. Cela permet de limiter les conséquences que peuvent avoir les défaillances sur les tâches professionnelles exécutées par l’application.
Si une application détecte un échec lorsqu’elle tente d’envoyer une requête à un service distant, elle peut gérer l’échec à l’aide des méthodes suivantes :
Annulation. Si l’erreur indique que l’échec n’est pas temporaire ou qu’il est probable qu’il se répète, l’application doit annuler l’opération et générer une exception. Par exemple, il est fort probable qu’un échec d’authentification dû à la saisie d’informations d’identification non valides se répète, peu importe le nombre de tentatives.
Nouvelle tentative. Si l’erreur spécifique signalée est inhabituelle ou rare, elle peut avoir été provoquée par des circonstances inhabituelles telles qu’un paquet réseau endommagé au cours de sa transmission. Dans ce cas, l’application pourrait relancer immédiatement la requête ayant échoué, car la même erreur est peu susceptible de se reproduire et qu’il est probable que la requête aboutisse.
Nouvelle tentative après un délai. Si l’échec est causé par un problème courant de connectivité ou de disponibilité, le réseau ou le service nécessitera certainement un certain délai le temps que les problèmes de connectivité soient corrigés ou que la file d’attente de tâches soit vidée. L’application doit attendre un délai approprié avant de relancer la requête.
Pour les échecs temporaires les plus courants, le délai entre chaque tentative doit être choisi de façon à pouvoir répartir les requêtes provenant de plusieurs instances de l’application de manière aussi équitable que possible. Cela réduit le risque de surcharger encore davantage un service déjà occupé. Si de nombreuses instances d’une application inondent en permanence un service de demandes de nouvelles tentatives, le service aura besoin de plus de temps pour récupérer un fonctionnement normal.
Si la demande n’aboutit toujours pas, l’application peut attendre et effectuer une nouvelle tentative. Le cas échéant, ce processus peut être répété en augmentant le délai d’attente entre chaque nouvelle tentative, jusqu’à ce qu’un nombre maximal de demandes a été atteint. Le délai d’attente peut être augmenté de façon incrémentielle ou exponentielle, selon le type d’échec et la probabilité de résolution de l’erreur dans le délai spécifié.
Le diagramme suivant illustre l’appel d’une opération dans un service hébergé à l’aide de ce modèle. Si la requête échoue après un nombre prédéfini de tentatives, l’application doit traiter l’erreur en tant qu’exception et la gérer en conséquence.
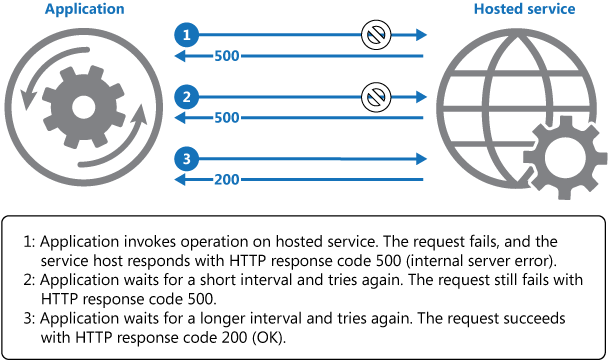
L’application doit inclure toutes les tentatives d’accès à un service distant dans un code qui implémente une stratégie de nouvelle tentative correspondant à l’une des méthodes répertoriées ci-dessus. Les requêtes envoyées aux différents services peuvent être soumises à des stratégies différentes. Certains éditeurs proposent des bibliothèques qui implémentent des stratégies de nouvelle tentative, où l’application peut spécifier le nombre maximal de nouvelles tentatives, le délai d’attente entre chaque tentative, ainsi que d’autres paramètres.
Une application doit consigner les détails des erreurs et des opérations ayant échoué. Ces informations sont utiles pour les opérateurs. Cela dit, afin d’éviter l’inondation d’opérateurs avec des alertes sur les opérations pour lesquelles de nouvelles tentatives ont été effectuées avec succès, il est préférable de consigner les premiers échecs comme des entrées d’informations, et l’échec de la dernière tentative en tant qu’erreur réelle. Voici à quoi peut ressembler un exemple de modèle de journalisation.
Si un service est fréquemment occupé ou indisponible, cela signifie souvent que le service a épuisé ses ressources. Vous pouvez réduire la fréquence de ces erreurs en procédant à une montée en charge du service. Par exemple, si un service de base de données est surchargé en permanence, il peut être utile de partitionner la base de données et de répartir la charge sur plusieurs serveurs.
Microsoft Entity Framework fournit des fonctionnalités pour relancer les opérations de base de données. De même, la plupart des services Azure et des kits de développement logiciel (SDK) clients incluent un mécanisme de nouvelle tentative. Pour plus d’informations, consultez Guide du mécanisme de nouvelle tentative relatif aux différents services.
Problèmes et considérations
Prenez en compte les points suivants quand vous choisissez comment implémenter ce modèle.
La stratégie de nouvelle tentative doit être configurée en fonction des exigences métiers de l’application et de la nature de l’échec. Pour certaines opérations non critiques, il est préférable d’effectuer un Fail-fast plutôt que d’effectuer plusieurs autres tentatives qui peuvent avoir un impact sur le débit de l’application. Par exemple, dans une application web interactive accédant à un service distant, il est préférable d'échouer après un petit nombre de tentatives, avec un court délai d'attente entre les tentatives, et d'afficher un message approprié à l'intention de l'utilisateur (par exemple, « Veuillez réessayer ultérieurement »). Pour une application de traitement par lot, il peut être plus judicieux d’augmenter le nombre de tentatives de connexion en augmentant de manière exponentielle le délai d’attente entre chaque tentative.
Une stratégie de relance agressive avec un délai minimal entre les tentatives et un grand nombre de nouvelles tentatives peut affecter encore davantage les performances d’un service occupé qui a déjà atteint ou est sur le point d’atteindre sa capacité maximale. Cette stratégie de relance peut également affecter la réactivité de l’application si elle tente en permanence de relancer une opération ayant échoué.
Si une requête continue d’échouer après un nombre important de nouvelles tentatives, il est préférable que l’application cesse d’envoyer de nouvelles requêtes à la même ressource et qu’elle signale immédiatement l’erreur. Lorsque le délai expire, l’application peut, à titre d’essai, envoyer une ou plusieurs requêtes pour voir si elles aboutissent. Pour plus d’informations sur cette stratégie, consultez l’article Modèle Disjoncteur.
Déterminez si l’opération est idempotente. Si c’est le cas, une nouvelle tentative peut être lancée sans risque. Dans le cas contraire, les nouvelles tentatives pourraient entraîner plusieurs exécutions de la même opération, causant des effets secondaires inattendus. Par exemple, un service peut recevoir la requête, la traiter avec succès, mais ne pas parvenir à envoyer une réponse. À ce stade, la logique de nouvelle tentative peut consister à renvoyer la requête en supposant que la première requête n’a pas été reçue.
Une requête envoyée à un service peut échouer pour diverses raisons et déclencher différentes exceptions selon la nature de l’échec. Certaines exceptions indiquent un échec qui peut être résolu rapidement, tandis que d’autres indiquent une défaillance plus complexe. Il est recommandé que la stratégie de relance configure le délai d’attente entre les nouvelles tentatives en fonction du type d’exception générée.
Tenez compte de la manière dont la relance d’une opération faisant partie d’une transaction affectera la cohérence globale de la transaction. Ajustez la stratégie de relance pour les opérations transactionnelles afin de maximiser les chances de réussite et d’éviter autant que possible d’avoir à annuler toutes les étapes de la transaction.
Vérifiez que l’ensemble du code de relance a été testé pour un large éventail de conditions d’échec. Vérifiez qu’il ne nuit pas gravement aux performances ou à la fiabilité de l’application, qu’il ne créé pas une charge excessive au niveau des services et des ressources, et qu’il ne génère pas des conditions de concurrence ou des goulots d’étranglement.
Implémentez la logique de nouvelle tentative uniquement lorsque vous avez identifié le contexte à l’origine de l’échec d’une opération. Par exemple, si une tâche qui contient une stratégie de nouvelle tentative appelle une autre tâche qui contient également une stratégie de nouvelle tentative, cette couche supplémentaire de nouvelles tentatives peut retarder de manière considérable le processus de traitement. Il peut être préférable d’effectuer un Fail-fast de la tâche de niveau inférieur et d’indiquer la raison de l’échec à la tâche qui l’a appelée. Cette tâche de niveau supérieur peut alors gérer l’échec en fonction de sa propre stratégie.
Il est important de consigner tous les échecs de connexion qui entraînent une nouvelle tentative afin que les problèmes sous-jacents liés à l’application, aux services ou aux ressources puissent être identifiés.
Recherchez les erreurs qui sont les plus susceptibles de se produire pour un service ou une ressource afin de découvrir si elles sont susceptibles d’être longues ou définitives. Si elles le sont, il est préférable de gérer l’erreur comme une exception. L’application peut signaler ou consigner l’exception, puis retenter l’opération en appelant un autre service (le cas échéant) ou en fournissant un niveau de fonctionnalité inférieur. Pour plus d’informations sur la façon de détecter et de gérer les erreurs de longue durée, consultez l’article Modèle Disjoncteur.
Quand utiliser ce modèle
Utilisez ce modèle lorsqu’une application rencontre des erreurs temporaires au moment d’interagir avec un service distant ou d’accéder à une ressource distante. Ces erreurs sont normalement de courte durée et une requête ayant échoué précédemment peut aboutir lors d’une nouvelle tentative.
Ce modèle peut ne pas avoir d’utilité dans les cas suivants :
- Lorsqu’une erreur est susceptible d’être de longue durée, car cela peut affecter la réactivité d’une application. L’application peut perdre du temps et des ressources à essayer de répéter une requête qui est susceptible d’échouer.
- Pour gérer les échecs qui ne sont pas dus à des erreurs temporaires, tels que les exceptions internes générées par des erreurs dans la logique métier d’une application.
- Pour éviter de résoudre les problèmes d’extensibilité dans un système. Si une application génère fréquemment des erreurs liées à la disponibilité, cela indique souvent que le service ou la ressource concerné(e) doit être mis(e) à l’échelle.
Conception de la charge de travail
Un architecte doit évaluer comment le modèle de Réessai (Retry) peut être utilisé dans la conception de leur charge de travail pour répondre aux objectifs et principes couverts par les piliers d’Azure Well-Architected Framework. Par exemple :
| Pilier | Comment ce modèle soutient les objectifs des piliers. |
|---|---|
| Les décisions relatives à la fiabilité contribuent à rendre votre charge de travail résiliente aux dysfonctionnements et à s’assurer qu’elle retrouve un état de fonctionnement optimal après une défaillance. | Réduire les fautes transitoires dans un système distribué est une technique fondamentale pour améliorer la résilience d’une charge de travail. - RE :07 Auto-conservation - RE :07 Erreurs temporaires |
Comme pour toute autre décision de conception, il convient de prendre en compte les compromis par rapport aux objectifs des autres piliers qui pourraient être introduits avec ce modèle.
Exemple
Cet exemple en C# illustre une implémentation du modèle Nouvelle tentative. La méthode OperationWithBasicRetryAsync, illustrée ci-dessous, appelle un service externe en mode asynchrone via la méthode TransientOperationAsync. Les détails de la méthode TransientOperationAsync sont propres au service et ne sont donc pas spécifiés dans l’exemple de code.
private int retryCount = 3;
private readonly TimeSpan delay = TimeSpan.FromSeconds(5);
public async Task OperationWithBasicRetryAsync()
{
int currentRetry = 0;
for (;;)
{
try
{
// Call external service.
await TransientOperationAsync();
// Return or break.
break;
}
catch (Exception ex)
{
Trace.TraceError("Operation Exception");
currentRetry++;
// Check if the exception thrown was a transient exception
// based on the logic in the error detection strategy.
// Determine whether to retry the operation, as well as how
// long to wait, based on the retry strategy.
if (currentRetry > this.retryCount || !IsTransient(ex))
{
// If this isn't a transient error or we shouldn't retry,
// rethrow the exception.
throw;
}
}
// Wait to retry the operation.
// Consider calculating an exponential delay here and
// using a strategy best suited for the operation and fault.
await Task.Delay(delay);
}
}
// Async method that wraps a call to a remote service (details not shown).
private async Task TransientOperationAsync()
{
...
}
L’instruction qui appelle cette méthode se trouve dans un bloc try/catch encapsulé dans une boucle for. La boucle for s’arrête si l’appel envoyé à la méthode TransientOperationAsync aboutit sans générer d’exception. Si la méthode TransientOperationAsync échoue, le bloc catch recherche la raison de l’échec. Si l’erreur est considérée comme temporaire, le code attend un court délai avant de retenter l’opération.
La boucle for enregistre également le nombre de fois où l’opération a été tentée. Si le code échoue à trois reprises, l’exception est considérée comme plus longue. Si l’exception n’est pas temporaire ou qu’elle est de longue durée, le gestionnaire catch génère une exception. Cette exception ferme la boucle for et doit être interceptée par le code qui appelle la méthode OperationWithBasicRetryAsync.
La méthode IsTransient, illustrée ci-dessous, recherche un ensemble spécifique d’exceptions en fonction de l’environnement dans lequel le code est exécuté. La définition d’une exception temporaire varie selon les ressources ciblées et l’environnement dans lequel l’opération est exécutée.
private bool IsTransient(Exception ex)
{
// Determine if the exception is transient.
// In some cases this is as simple as checking the exception type, in other
// cases it might be necessary to inspect other properties of the exception.
if (ex is OperationTransientException)
return true;
var webException = ex as WebException;
if (webException != null)
{
// If the web exception contains one of the following status values
// it might be transient.
return new[] {WebExceptionStatus.ConnectionClosed,
WebExceptionStatus.Timeout,
WebExceptionStatus.RequestCanceled }.
Contains(webException.Status);
}
// Additional exception checking logic goes here.
return false;
}
Étapes suivantes
Avant d’écrire une logique de nouvelle tentative personnalisée, envisagez d’utiliser une infrastructure générale comme Polly pour .NET ou Resilience4j pour Java.
Lors du traitement des commandes qui modifient les données d’entreprise, sachez que les nouvelles tentatives peuvent entraîner l’exécution de l’action à deux reprises, ce qui peut être problématique si cette action est semblable à la facturation de la carte de crédit d’un client. L’utilisation du modèle Idempotence décrit dans ce billet de blog peut vous aider à gérer ces situations.
Ressources associées
Le modèle d’application web fiable vous montre comment appliquer le modèle cache-aside aux applications web convergeant vers le cloud.
Pour la plupart des services Azure, les kits de développement logiciel (SDK) clients incluent une logique de nouvelle tentative intégrée. Pour plus d’informations, consultez Guide du mécanisme de nouvelle tentative relatif aux services Azure.
Modèle Disjoncteur. Lorsque l’erreur semble être de plus longue durée, il peut être plus judicieux d’implémenter le modèle Disjoncteur. La combinaison des modèles Nouvelle tentative et Disjoncteur offre une approche complète de la gestion des erreurs.