Cet article décrit comment une équipe de développement a utilisé des métriques pour détecter des goulets d’étranglement et améliorer les performances d’un système distribué. L'article est basé sur des tests de charge réels que nous avons effectués pour un exemple d'application. L'application provient de la Base de référence Azure Kubernetes Service (AKS) pour les microservices, ainsi que d'un projet de test de charge Visual Studio utilisé pour générer les résultats.
Cet article fait partie d’une série. Lisez la première partie ici.
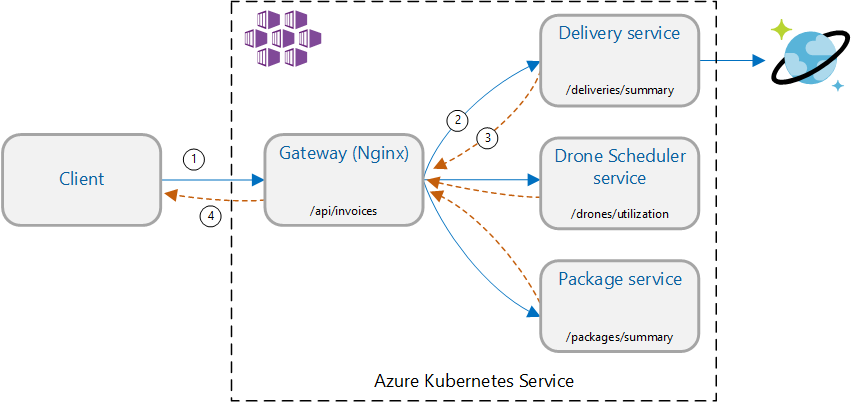
Scénario : Appeler plusieurs services back-end pour récupérer des informations, puis agréger les résultats
Ce scénario implique une application de livraison par drone. Les clients peuvent interroger une API REST pour obtenir leurs dernières informations de facturation. La facture comprend un récapitulatif des livraisons, des colis et de l'utilisation totale des drones par le client. Cette application utilise une architecture de microservices exécutée sur AKS, et les informations nécessaires à la facturation sont réparties sur plusieurs microservices.
Plutôt que de laisser le client appeler directement chaque service, l'application implémente le modèle Agrégation de passerelle. Grâce à ce modèle, le client n'adresse qu'une seule requête à un service de passerelle. En parallèle, la passerelle appelle les services back-end, puis agrège les résultats en une seule charge utile de réponse.
Test 1 : Performances de base
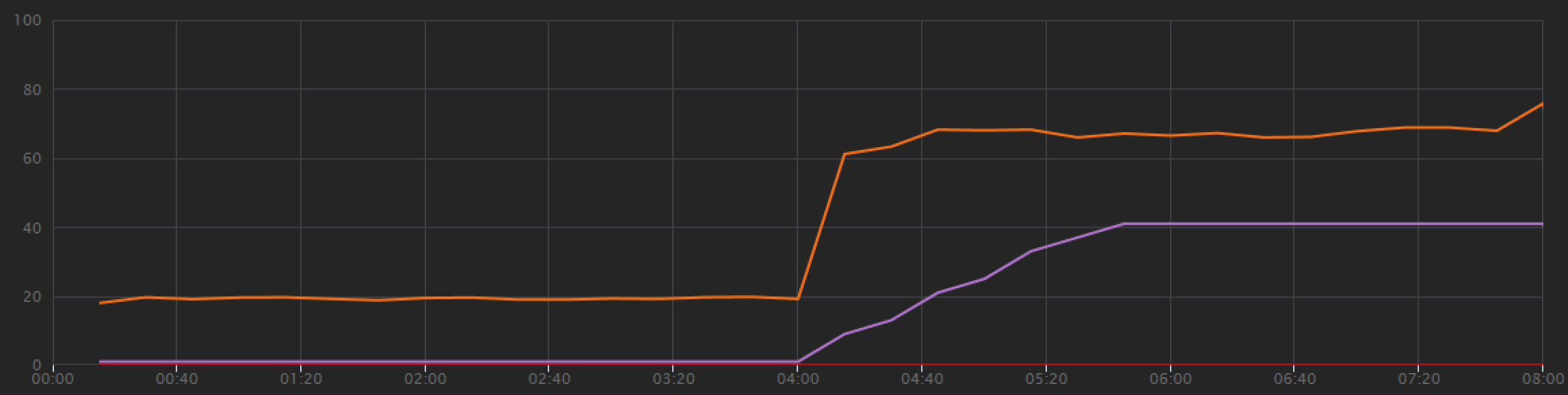
Pour établir une base de référence, l'équipe de développement a d'abord effectué un test de charge par étapes, passant d'un utilisateur simulé à 40 utilisateurs, sur une durée totale de 8 minutes. Le graphique suivant, extrait de Visual Studio, présente les résultats. La ligne violette indique la charge utilisateur et la ligne orange le débit (nombre moyen de requêtes par seconde).
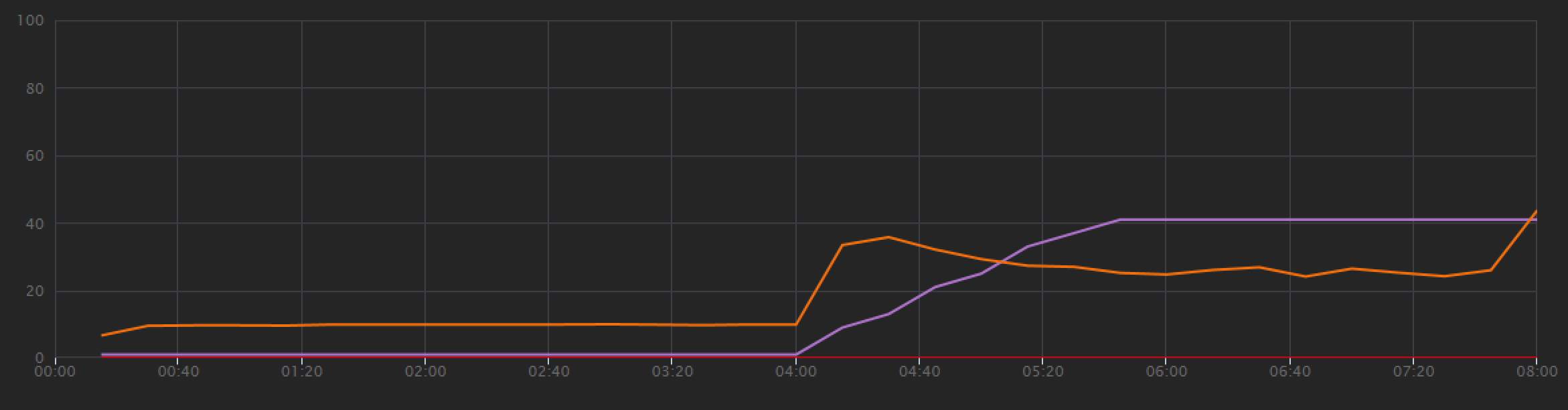
La ligne rouge du bas du graphique montre qu'aucune erreur n'a été renvoyée au client, ce qui est encourageant. Toutefois, le débit moyen atteint un pic à la moitié du test, puis diminue, même si la charge continue d'augmenter. Cela indique que le back-end n'est pas en mesure de suivre. Le modèle présenté ici est courant lorsqu’un système commence à atteindre les limites en termes de ressources ; après avoir atteint un maximum, le débit diminue de manière significative. Les conflits de ressources, les erreurs temporaires ou l'augmentation de la fréquence des exceptions peuvent tous contribuer à ce modèle.
Examinons les données de surveillance pour savoir ce qui se passe à l'intérieur du système. Le graphique suivant est extrait d'Application Insights. Il indique la durée moyenne des appels HTTP entre la passerelle et les services back-end.
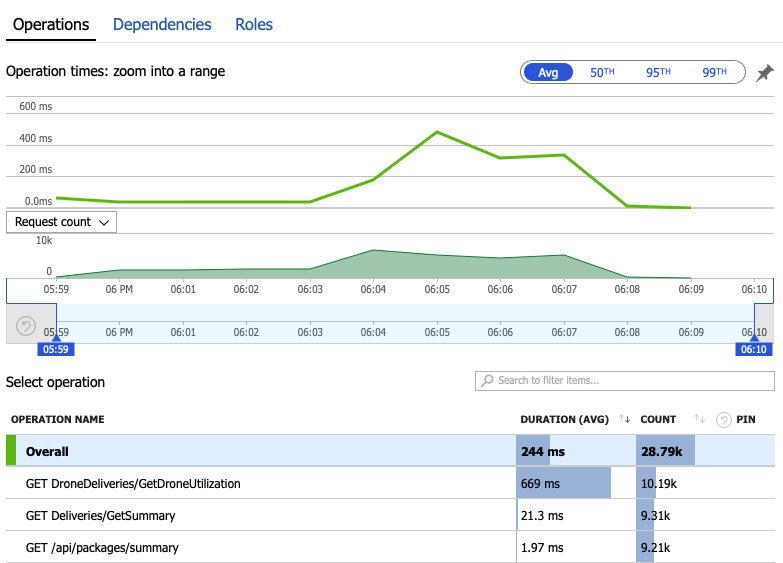
Ce graphique montre qu’une opération en particulier, GetDroneUtilization, prend en moyenne beaucoup plus de temps que les autres, par ordre de grandeur. La passerelle passe ces appels en parallèle, de sorte que l'opération la plus lente détermine le temps nécessaire à l'ensemble de la requête.
L'étape suivante consiste à examiner l'opération GetDroneUtilization et à rechercher les éventuels goulots d'étranglement. L'insuffisance de ressources est une possibilité. Ce service back-end particulier est peut-être à court d'UC ou de mémoire. Pour un cluster AKS, ces informations sont disponibles sur le portail Azure via la fonctionnalité Azure Monitor Container Insights. Les graphiques suivants présentent l'utilisation des ressources au niveau du cluster :
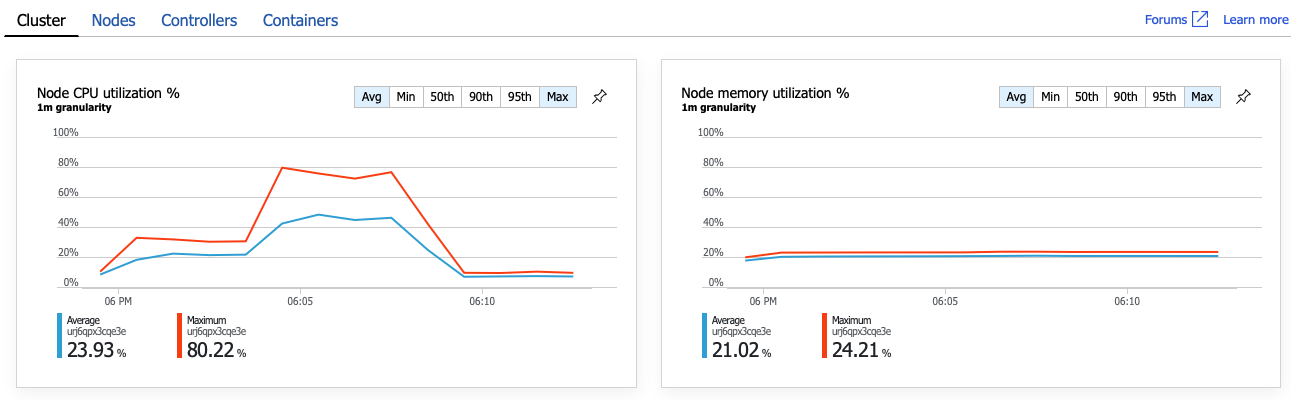
Dans cette capture d'écran, les valeurs moyennes et maximum sont affichées. Il est important de ne pas se limiter à la moyenne, car celle-ci peut masquer des pics de données. Ici, l'utilisation moyenne de l'UC reste inférieure à 50 %, mais il y a quelques pics à 80 %. Nous sommes proches de la capacité maximum, mais toujours dans les limites de tolérance. Un autre problème est à l'origine du goulot d'étranglement.
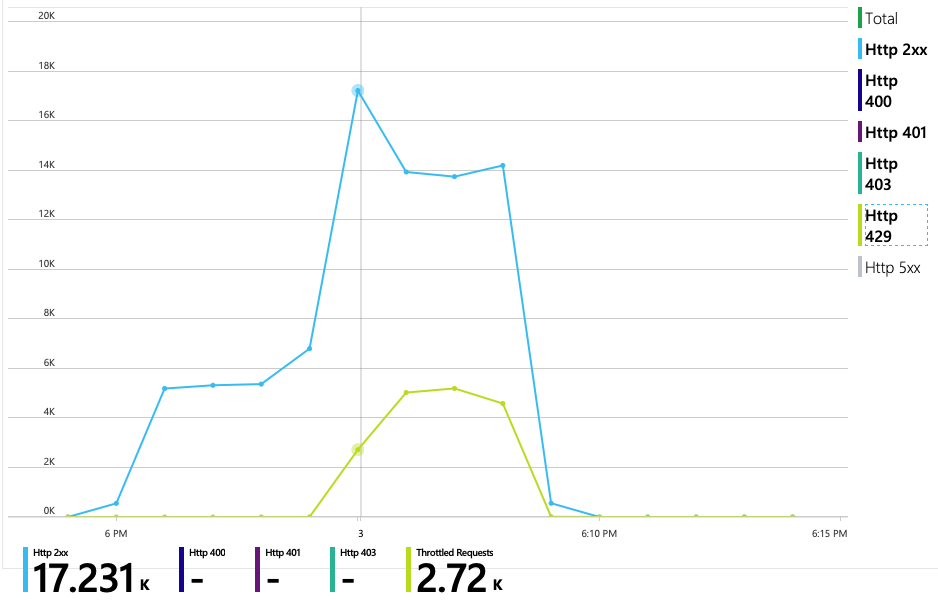
Le graphique suivant révèle le véritable coupable. Ce graphique présente les codes de réponse HTTP de la base de données back-end du service de livraison, qui dans ce cas est Azure Cosmos DB. La ligne bleue représente les codes de réussite (HTTP 2xx) et la ligne verte les erreurs HTTP 429. Un code de retour HTTP 429 signifie qu’Azure Cosmos DB limite temporairement les requêtes, car l'appelant consomme plus d'unités de ressources (RU) que prévu.
Afin d'obtenir des insights supplémentaires, l'équipe de développement a utilisé Application Insights pour afficher la télémétrie de bout en bout sur un échantillon représentatif de requêtes. En voici un exemple :
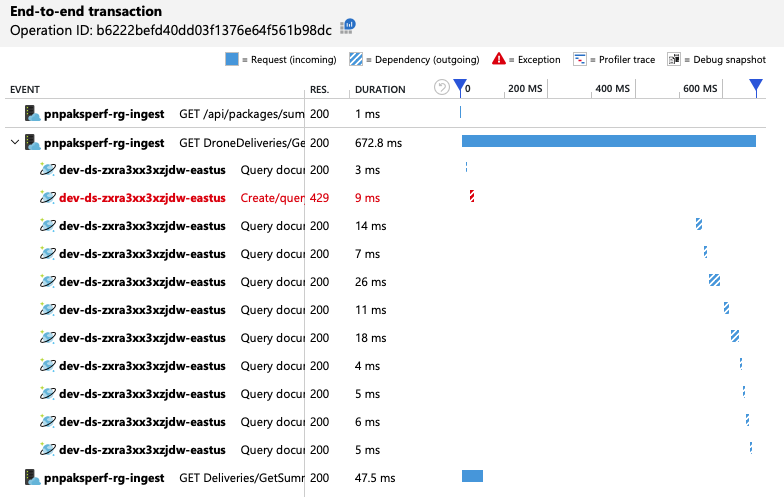
Cette vue présente les appels liés à une seule requête client, ainsi que des informations sur la durée et les codes de réponse. Les appels de niveau supérieur se font de la passerelle vers les services back-end. L'appel à GetDroneUtilization est développé pour présenter les appels aux dépendances externes - dans ce cas, à Azure Cosmos DB. L'appel en rouge a renvoyé une erreur HTTP 429.
Notez l'écart important entre l'erreur HTTP 429 et l'appel suivant. Lorsque la bibliothèque cliente Azure Cosmos DB reçoit une erreur HTTP 429, elle est automatiquement désactivée et attend avant de retenter l'opération. Cette vue montre que la majeure partie des 672 ms qu'a duré l'opération a été consacrée à l'attente d'une nouvelle tentative d'Azure Cosmos DB.
Voici un autre graphique intéressant pour cette analyse. Il présente la consommation de RU par partition physique et les RU approvisionnées par partition physique :
Pour comprendre ce graphique, vous devez savoir comment Azure Cosmos DB gère les partitions. Dans Azure Cosmos DB, les collections peuvent disposer d'une clé de partition. Chaque valeur de clé possible définit une partition logique des données au sein de la collection. Azure Cosmos DB distribue ces partitions logiques sur une ou plusieurs partitions physiques. La gestion des partitions physiques est automatiquement assurée par Azure Cosmos DB. Au fur et à mesure que vous stockez des données, Azure Cosmos DB peut déplacer les partitions logiques vers de nouvelles partitions physiques, afin de répartir la charge sur celles-ci.
Pour ce test de charge, la collection Azure Cosmos DB a été approvisionnée avec 900 RU. Le graphique montre 100 RU par partition physique, ce qui implique un total de neuf partitions physiques. Bien qu’Azure Cosmos DB gère automatiquement le partitionnement, le fait de connaître le nombre de partitions physiques peut donner un aperçu des performances. L'équipe de développement utilisera ces informations ultérieurement, au fil de leur optimisation. Lorsque la ligne bleue coupe la ligne horizontale violette, cela signifie que la consommation de RU a dépassé les RU approvisionnées. C'est à ce moment qu’Azure Cosmos DB commence à limiter les appels.
Test 2 : Augmenter les unités de ressource
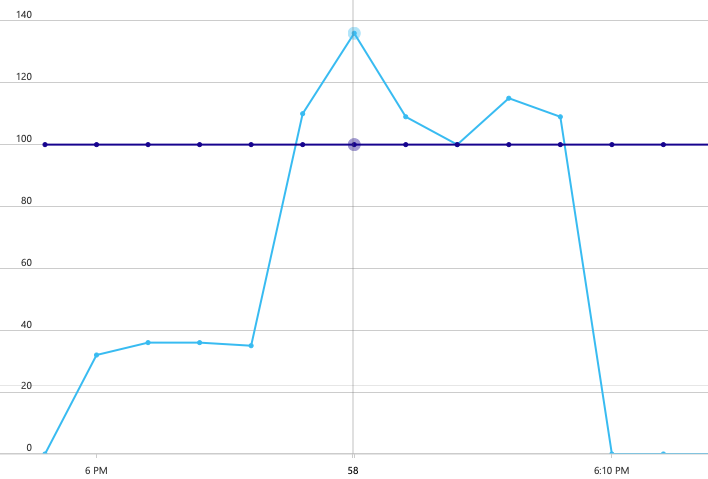
Pour le deuxième test de charge, l'équipe a fait passer la collection Azure Cosmos DB de 900 à 2 500 RU. Le débit est passé de 19 à 23 requêtes/seconde, et la latence moyenne est passée de 669 à 569 ms.
| Métrique | Test 1 | Test 2 |
|---|---|---|
| Débit (requêtes/s) | 19 | 23 |
| Latence moyenne (ms) | 669 | 569 |
| Demandes ayant réussi | 9,8 K | 11 K |
Ce ne sont pas des gains énormes, mais en observant l'évolution du graphique dans le temps, on obtient une image plus complète :

Alors que le test précédent montrait un pic initial suivi d'une forte baisse, ce test montre un débit plus régulier. Cela dit, le débit maximal n'est pas significativement plus élevé.
Toutes les requêtes adressées à Azure Cosmos DB ont renvoyé un état 2xx et les erreurs HTTP 429 ont disparu :

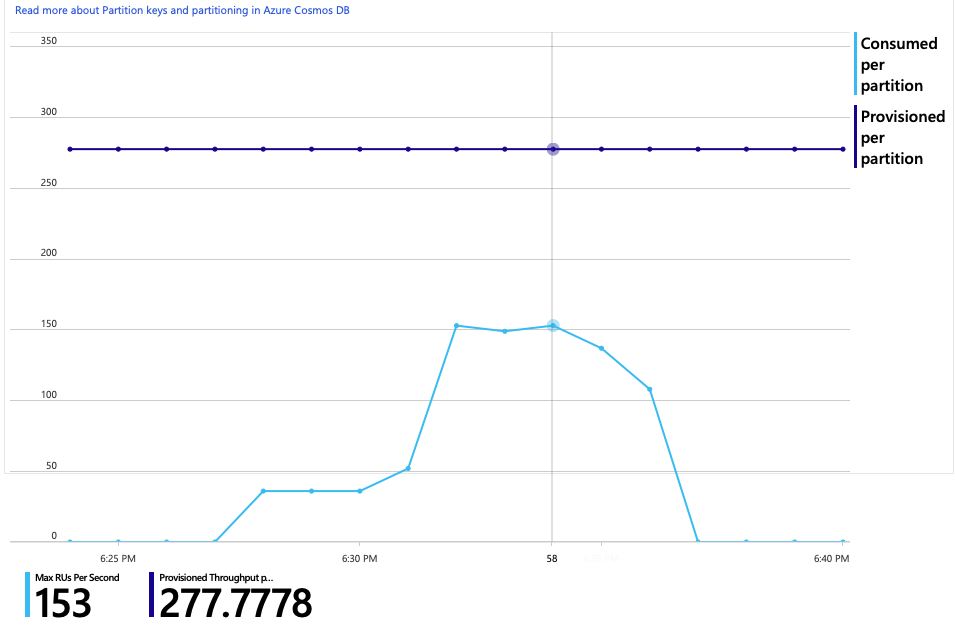
Le graphique présentant la consommation de RU et les RU approvisionnées montre qu'il existe une marge importante. Il y a environ 275 RU par partition physique, et le test de charge a culminé à environ 100 RU consommées par seconde.
Le nombre d'appels à Azure Cosmos DB par opération réussie est également une métrique intéressante :
| Métrique | Test 1 | Test 2 |
|---|---|---|
| Appels par opération | 11 | 9 |
En supposant qu'il n'y ait pas d'erreurs, le nombre d'appels doit correspondre au plan de requête réel. Dans ce cas, l'opération implique une requête qui soit adressée aux neuf partitions physiques. La valeur plus élevée du premier test de charge reflète le nombre d'appels qui ont renvoyé une erreur 429.
Cette métrique a été calculée en exécutant une requête Log Analytics personnalisée :
let start=datetime("2020-06-18T20:59:00.000Z");
let end=datetime("2020-07-24T21:10:00.000Z");
let operationNameToEval="GET DroneDeliveries/GetDroneUtilization";
let dependencyType="Azure DocumentDB";
let dataset=requests
| where timestamp > start and timestamp < end
| where success == true
| where name == operationNameToEval;
dataset
| project reqOk=itemCount
| summarize
SuccessRequests=sum(reqOk),
TotalNumberOfDepCalls=(toscalar(dependencies
| where timestamp > start and timestamp < end
| where type == dependencyType
| summarize sum(itemCount)))
| project
OperationName=operationNameToEval,
DependencyName=dependencyType,
SuccessRequests,
AverageNumberOfDepCallsPerOperation=(TotalNumberOfDepCalls/SuccessRequests)
Pour résumer, le deuxième test de charge montre une amélioration. Mais l'opération GetDroneUtilization se situe toujours dans un ordre de grandeur supérieur à celui de l'opération la plus lente suivante. L'examen des transactions de bout en bout permet d'obtenir une explication :

Comme mentionné précédemment, l'opération GetDroneUtilization implique une requête Azure Cosmos DB sur plusieurs partitions. Cela signifie que le client Azure Cosmos DB doit répartir la requête sur les différentes partitions physiques et collecter les résultats. Comme le montre la vue des transactions de bout en bout, ces requêtes sont effectuées en série. L’opération dure aussi longtemps que la somme de toutes les requêtes, et ce problème ne fait qu’empirer à mesure que la taille des données augmente et que de nouvelles partitions physiques sont ajoutées.
Test 3 : Requêtes parallèles
En fonction des résultats précédents, un moyen évident de réduire la latence consiste à émettre les requêtes en parallèle. Le kit de développement logiciel (SDK) du client Azure Cosmos DB dispose d'un paramètre qui contrôle le degré maximum de parallélisme.
| Valeur | Description |
|---|---|
| 0 | Pas de parallélisme (par défaut) |
| > 0 | Nombre maximum d'appels parallèles |
| -1 | Le kit de développement logiciel (SDK) client sélectionne un degré optimal de parallélisme |
Pour le troisième test de charge, ce paramètre est passé de 0 à -1. Le tableau suivant récapitule les résultats :
| Métrique | Test 1 | Test 2 | Test 3 |
|---|---|---|---|
| Débit (requêtes/s) | 19 | 23 | 42 |
| Latence moyenne (ms) | 669 | 569 | 215 |
| Demandes ayant réussi | 9,8 K | 11 K | 20 K |
| Requêtes limitées | 2,72 K | 0 | 0 |
D'après le graphique du test de charge, non seulement le débit global est beaucoup plus élevé (ligne orange), mais le débit suit également le rythme de la charge (ligne violette).
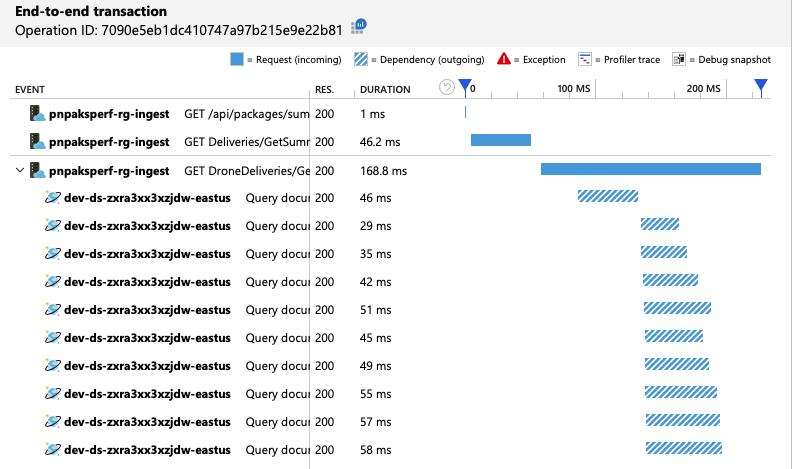
Nous pouvons vérifier que le client Azure Cosmos DB effectue des requêtes en parallèle en examinant la vue des transactions de bout en bout :
Il est intéressant de noter que l'augmentation du débit a pour effet secondaire d'entraîner également une augmentation du nombre de RU consommées par seconde. Bien qu’Azure Cosmos DB n'ait limité aucune requête pendant ce test, la consommation était proche de la limite de RU approvisionnée :

Ce graphique pourrait être un signal pour poursuivre le scale-out de la base de données. Mais il s'avère que nous pouvons optimiser la requête.
Étape 4 : Optimiser la requête
Le test de charge précédent a montré de meilleures performances en termes de latence et de débit. La latence moyenne des requêtes a été réduite de 68 % et le débit a augmenté de 220 %. Toutefois, la requête sur plusieurs partitions pose problème.
Le problème des requêtes sur plusieurs partitions est que vous payez des RU sur chaque partition. Si la requête n’est exécutée qu’occasionnellement (par exemple, une fois par heure), cela n’a pas trop d’importance. Mais chaque fois que vous voyez une charge de travail nécessitant beaucoup de lectures et qui implique une requête sur plusieurs partitions, vous devez déterminer si la requête peut être optimisée en incluant une clé de partition. (Vous devrez peut-être redéfinir la collection pour utiliser une clé de partition différente.)
Voici la requête correspondant à ce scénario particulier :
SELECT * FROM c
WHERE c.ownerId = <ownerIdValue> and
c.year = <yearValue> and
c.month = <monthValue>
Cette requête sélectionne les enregistrements qui correspondent à un ID de propriétaire et à un mois/une année particuliers. Dans la conception d'origine, aucune de ces propriétés n'est la clé de partition. Cela oblige le client à répartir la requête sur les différentes partitions physiques et à collecter les résultats. Pour améliorer les performances des requêtes, l'équipe de développement a modifié la conception afin que l'ID du propriétaire soit la clé de partition de la collection. De cette façon, la requête peut cibler une partition physique spécifique. (Azure Cosmos DB gère cela automatiquement ; vous n'avez pas à gérer le mappage entre les valeurs de clé de partition et les partitions physiques).
Après le basculement de la collection vers la nouvelle clé de partition, la consommation de RU s'améliore considérablement, ce qui se traduit directement par une baisse des coûts.
| Métrique | Test 1 | Test 2 | Test 3 | Test 4 |
|---|---|---|---|---|
| RU par opération | 29 | 29 | 29 | 3.4 |
| Appels par opération | 11 | 9 | 10 | 1 |
La vue des transactions de bout en bout montre que, comme prévu, la requête ne lit qu'une seule partition physique :
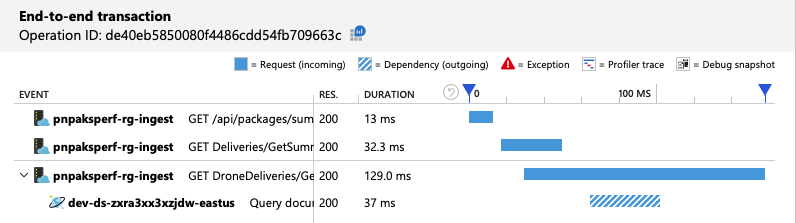
Le test de charge montre une amélioration du débit et de la latence :
| Métrique | Test 1 | Test 2 | Test 3 | Test 4 |
|---|---|---|---|---|
| Débit (requêtes/s) | 19 | 23 | 42 | 59 |
| Latence moyenne (ms) | 669 | 569 | 215 | 176 |
| Demandes ayant réussi | 9,8 K | 11 K | 20 K | 29 K |
| Requêtes limitées | 2,72 K | 0 | 0 | 0 |
L'amélioration des performances se traduit par une très forte utilisation de l'UC des nœuds :
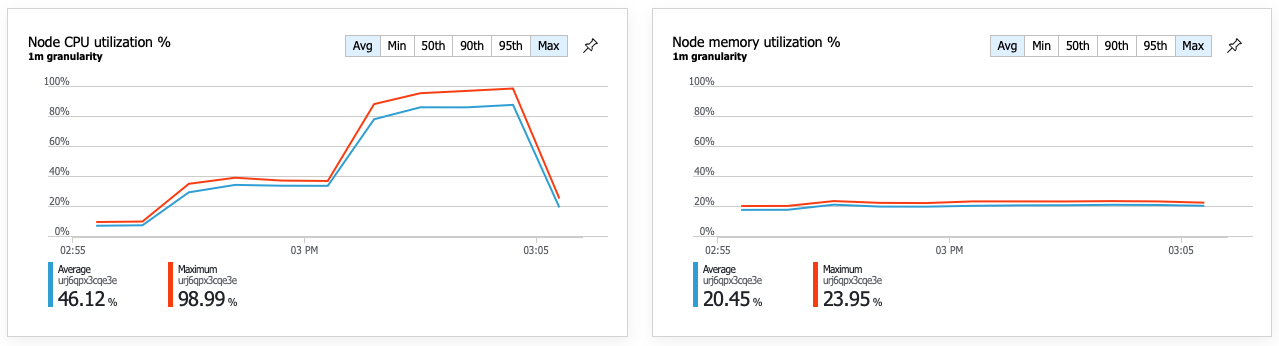
Vers la fin du test de charge, l'UC moyenne a atteint environ 90 %, et l'UC maximum 100 %. Cette métrique indique que l'UC est le goulot d'étranglement suivant du système. Si un débit plus élevé est nécessaire, l'étape suivante pourrait consister à effectuer un scale-out du service de livraison pour intégrer davantage d'instances.
Résumé
Pour ce scénario, les goulets d’étranglement suivants ont été identifiés :
- Requêtes de limitation d’Azure Cosmos DB en raison d'un approvisionnement insuffisant des RU.
- Latence élevée causée par l'interrogation de plusieurs partitions de base de données en série
- Requête sur plusieurs partitions inefficace, car celle-ci n'incluait pas la clé de partition
En outre, l'utilisation de l'UC a été identifiée comme un goulot d'étranglement potentiel à plus grande échelle. Pour diagnostiquer ces problèmes, l'équipe de développement a examiné ce qui suit :
- Latence et débit du test de charge
- Erreurs Azure Cosmos DB et consommation de RU.
- Vue des transactions de bout en bout d'Application Insight
- Utilisation de l’UC et de la mémoire dans Azure Monitor Container Insights.
Étapes suivantes
Consultez Anti-modèles de performance