L'intelligence artificielle (IA) et le Machine Learning (ML) offrent des opportunités et des défis uniques pour les opérations qui couvrent les mondes virtuel et physique. L'IA et le ML peuvent identifier les corrélations entre les données d'entrée et les résultats obtenus dans le monde réel, et prendre des décisions qui automatisent les systèmes industriels physiques complexes. Mais les systèmes de Machine Learning de l'IA ne sont pas en mesure d'exécuter des fonctions cognitives de niveau supérieur comme l'exploration, l'improvisation, la pensée créative ou la détermination de la causalité.
Le Machine Teaching est un nouveau paradigme pour systèmes de Machine Learning qui :
- insuffle de l'expertise technique dans les modèles des systèmes d'IA automatisés ;
- utilise l'apprentissage par renforcement profond pour identifier les schémas du processus d'apprentissage et adopter des comportements positifs pour ses propres méthodes ;
- tire parti d'environnements simulés afin de générer de grandes quantités de données synthétiques pour des cas d'usage et des scénarios spécifiques à un domaine.
Le Machine Learning se concentre sur le développement de nouveaux algorithmes d'apprentissage ou sur l'amélioration des algorithmes existants. Le Machine Teaching se concentre sur l'efficacité des enseignants proprement dits. Le fait de faire abstraction de la complexité de l'IA pour se concentrer sur l'expertise technique et les conditions réelles crée de puissants modèles d'IA et de ML qui transforment les systèmes de contrôle automatisés en systèmes autonomes.
Cet article traite des développements historiques de l'intelligence artificielle et des concepts utilisés dans le Machine Teaching. Un article connexe traite en détail des systèmes autonomes.
Histoire de l'automatisation
Depuis des milliers d'années, l'homme conçoit des outils et des machines physiques pour gagner en efficacité. Ces technologies visent à obtenir une production plus régulière, à moindre coût et avec moins de main-d'œuvre directe.
Lors de la première révolution industrielle, de la fin du XVIIIe au milieu du XIXe siècle, des machines ont commencé à remplacer les méthodes manuelles dans la fabrication. La révolution industrielle s'est traduite par une augmentation du rendement grâce à l'automatisation par la vapeur, et par un regroupement en déplaçant la production des foyers vers des usines organisées. La deuxième révolution industrielle, du milieu du XIXe au début du XXe siècle, a été marquée par une amélioration des capacités de production grâce à l'électrification et à l'apparition des chaînes de production.
Les Première et Deuxième Guerres mondiales ont donné lieu à des avancées majeures dans les domaines de la théorie de l'information, des communications et du traitement des signaux. Le développement du transistor a permis d'appliquer la théorie de l'information au contrôle des systèmes physiques. Cette troisième révolution industrielle a permis aux systèmes informatiques d'effectuer des incursions dans le domaine du contrôle codé en dur de systèmes physiques (production, transport, santé, etc.). La cohérence, la fiabilité et la sécurité figuraient parmi les avantages de l'automatisation programmée.
Avec la quatrième révolution industrielle sont nées les notions de systèmes cyberphysiques et d'Internet des objets (IoT) industriel. Les systèmes que l'homme cherche à contrôler sont devenus trop vastes et trop complexes pour lui permettre de rédiger des règles entièrement prescrites. L'intelligence artificielle permet à des machines intelligentes d'effectuer des tâches qui relèvent généralement de l'intelligence humaine. Le Machine Learning permet aux machines d'apprendre et d'améliorer leur expérience de façon automatique sans programmation explicite.
IA et ML
Les concepts d'IA et de ML ne sont pas nouveaux, et de nombreuses théories subsistent depuis des décennies, mais les récentes avancées technologiques en matière de stockage, de bande passante et de calcul permettent aux algorithmes d'effectuer des prédictions plus fines et plus utiles. L'augmentation de la capacité de traitement des appareils, de la miniaturisation, de la capacité de stockage et de la capacité des réseaux permet d'aller plus loin en termes d'automatisation des systèmes et des équipements. Ces avancées permettent également de collecter et de classer de grandes quantités de données de capteurs en temps réel.
L'automatisation cognitive désigne l'application de logiciels et de l'IA à des processus et systèmes nécessitant beaucoup d'informations. L'IA cognitive peut améliorer la productivité de la main-d'œuvre manuelle, remplacer des travailleurs humains dans des secteurs monotones ou dangereux, et fournir de nouveaux insights grâce aux énormes volumes de données qu'elle peut traiter. Les technologies cognitives comme la vision par ordinateur, le traitement du langage naturel, les bots conversationnels et la robotique peuvent accomplir des tâches auparavant réservées aux humains.
De nombreux systèmes de production actuels automatisent les tâches et réalisent des prouesses d'ingénierie et de fabrication à l'aide de robots industriels. L'utilisation et l'évolution de l'automatisation dans les industries manufacturières permettent d'obtenir des produits de meilleure qualité, plus sûrs, avec une consommation plus efficace de l'énergie et des matières premières. Cela dit, dans la plupart des cas, les robots ne fonctionnent que dans des environnements hautement structurés. Ils sont généralement peu flexibles et hautement spécialisés dans des tâches immédiates. Le développement des robots peut également être très coûteux compte tenu des règles matérielles et logicielles qui régissent leurs comportements.
Selon le paradoxe de l'automatisation, plus un système automatisé est efficace, plus la composante humaine est essentielle pour assurer son fonctionnement. Le rôle de l'homme passe d'un travail banal par unité de travail à l'amélioration et à la gestion du système automatisé, ainsi qu'à l'apport d'une expertise essentielle. Souvent plus efficace, un système automatisé peut néanmoins produire des déchets et engendrer des problèmes s'il est mal conçu ou s'il fonctionne mal. Une utilisation efficace de l'automatisation renforce l'importance de l'homme, et non l'inverse.
Cas d'usage de l'IA
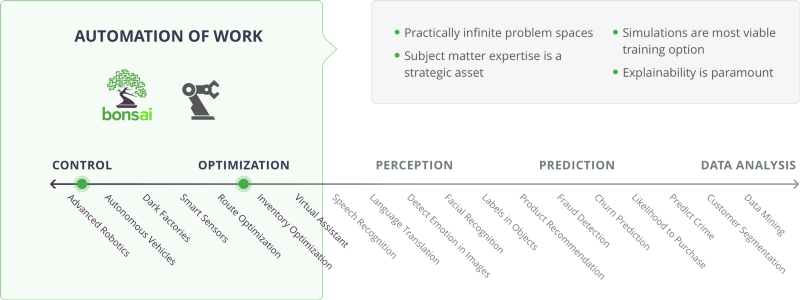
Dans le diagramme précédent, les catégories Contrôle et Optimisation concernent l'automatisation du travail. De ce côté du spectre, il existe des espaces à problèmes pratiquement infinis. L'expertise technique est un atout stratégique, les simulations constituent l'option d'apprentissage la plus réalisable et l'explicabilité est primordiale.
Les orchestrateurs incluent la fabrication intelligente et la plateforme de Machine Teaching Bonsai. Les cas d'usage incluent la robotique avancée, les véhicules autonomes, les usines entièrement robotisées, les capteurs intelligents, l'optimisation d'itinéraire, l'optimisation des stocks et les assistants virtuels.
Apprentissage par renforcement
Le Machine Teaching utilise l'apprentissage par renforcement (Reinforcement Learning - RL) pour former des modèles, identifier des schémas dans le cadre du processus d'apprentissage et adopter des comportements positifs pour ses propres méthodes. L'apprentissage par renforcement profond (Deep Reinforcement Learning - DRL) applique l'apprentissage par renforcement à des réseaux neuronaux de Deep Learning complexes.
Dans le cadre du Machine Learning, le RL porte sur la façon dont les agents logiciels apprennent à maximiser les récompenses et les résultats souhaités dans leur environnement. Le RL correspond à l'un des trois paradigmes de Machine Learning de base suivants :
- L'apprentissage supervisé se généralise à partir de données étiquetées ou structurées.
- L'apprentissage non supervisé compresse les données non étiquetées ou non structurées.
- L'apprentissage par renforcement agit par tâtonnements.
Tandis que l'apprentissage supervisé repose sur l'exemple, l'apprentissage par renforcement s'appuie sur l'expérience. Contrairement à l'apprentissage supervisé, qui met l'accent sur la recherche et l'étiquetage des jeux de données appropriés, le RL se concentre sur la conception de modèles de réalisation de tâches.
Les principaux composants du RL sont les suivants :
- Agent : entité qui peut prendre la décision de changer l'environnement actuel.
- Environnement : monde physique ou simulé dans lequel l'agent opère.
- État : situation actuelle de l'agent et de son environnement.
- Action : interaction de l'agent sur son environnement.
- Récompense : feedback de l'environnement, suite à une action de l'agent.
- Stratégie : méthode ou fonction permettant de mettre l'état actuel de l'agent et de son environnement en correspondance avec des actions.
Le RL utilise des fonctions et des stratégies de récompense pour évaluer les actions des agents et fournir un feedback. Grâce à une prise de décision séquentielle basée sur l'environnement actuel, les agents apprennent peu à peu à maximiser la récompense et à prédire les meilleures actions possibles dans des situations spécifiques.
Le RL apprend à l'agent à atteindre un objectif en récompensant le comportement souhaité et en ne récompensant pas un comportement non souhaité. Le diagramme suivant illustre le flux conceptuel du RL et la manière dont les composants clés interagissent :
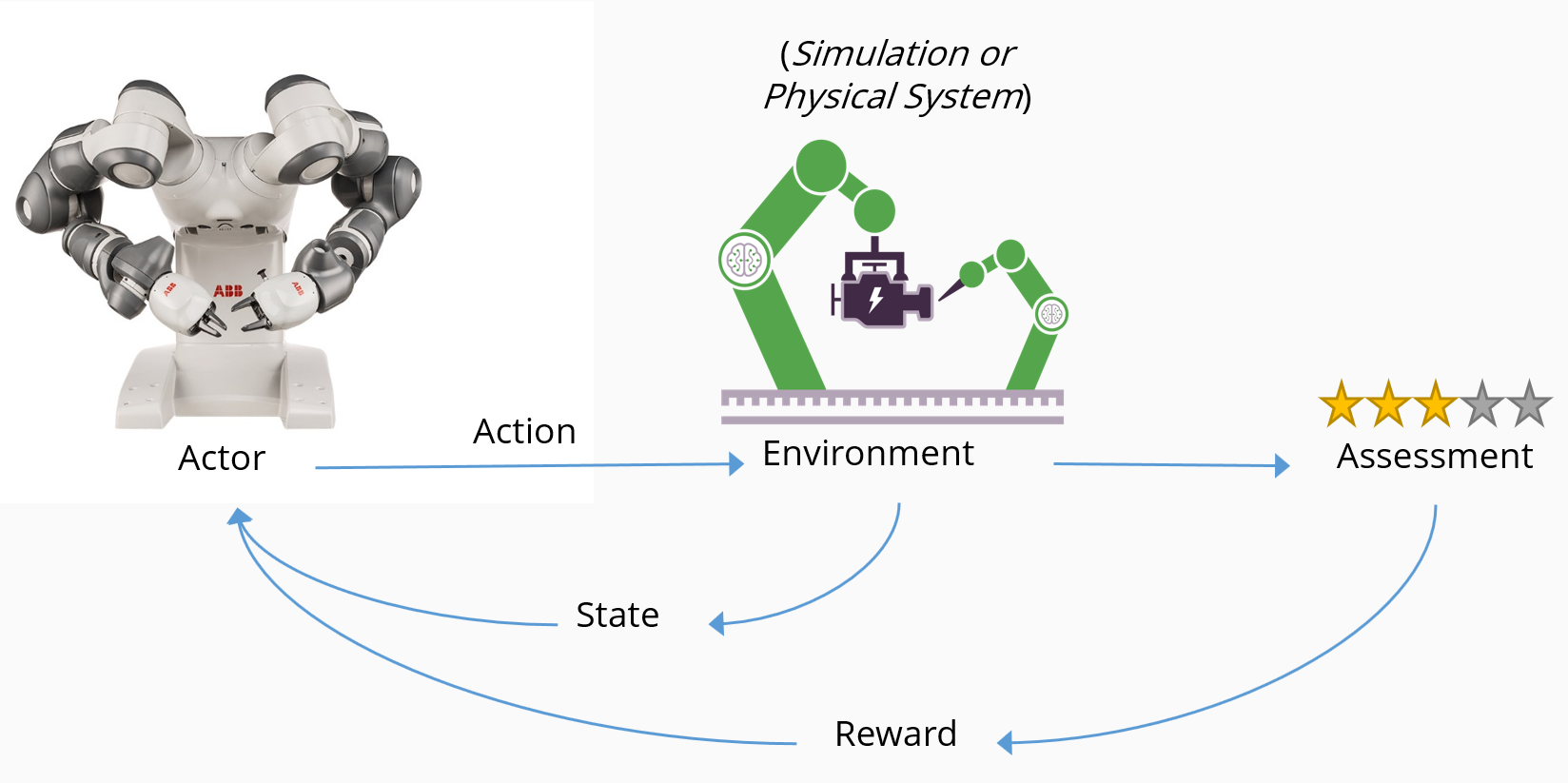
- Un agent, dans ce cas un robot, effectue une action dans un environnement, dans ce cas une chaîne de fabrication intelligente.
- L'action provoque un changement d'état de l'environnement, et ce changement est communiqué à l'agent.
- Un mécanisme d'évaluation applique une stratégie pour déterminer la conséquence à fournir à l'agent.
- Le mécanisme de récompense encourage les actions bénéfiques en offrant une récompense positive, et peut décourager les actions négatives en infligeant une pénalité.
- Les récompenses entraînent une augmentation des actions souhaitées, tandis que les pénalités entraînent une diminution des actions non souhaitées.
Un problème peut être de nature stochastique (aléatoire) ou déterministe. Bien qu'il n'y ait généralement qu'un seul agent, la présence de plusieurs agents dans l'environnement est possible. L'agent analyse l'environnement en l'observant. L'environnement peut être totalement ou partiellement observable, comme le déterminent les capteurs de l'agent, et les observations peuvent être discrètes ou continues.
Chaque observation est suivie d'une action qui fait évoluer l'environnement. Ce cycle se répète jusqu'à ce qu'un état terminal soit atteint. En règle générale, le système n'a pas de mémoire, et l'algorithme s'intéresse uniquement à l'état initial, à l'état terminal et à la récompense reçue.
À mesure que l'agent apprend par tâtonnements, il lui faut de grandes quantités de données pour évaluer ses actions. La RL s'applique surtout aux domaines qui disposent de grandes structures de données historiques, ou qui peuvent facilement produire des données simulées.
Fonctions de récompense
Une fonction de récompense détermine à quelle hauteur une action particulière doit être récompensée et quand cette récompense doit être attribuée. La structure de la récompense est normalement laissée à l'appréciation du propriétaire du système. L'ajustement de ce paramètre peut avoir un impact significatif sur les résultats.
L'agent utilise la fonction de récompense pour en savoir plus sur la physique et la dynamique du monde qui l'entoure. Le processus de base par lequel un agent apprend à maximiser sa récompense, du moins au début, n'est autre que le tâtonnement.
Compromis entre exploration et exploitation
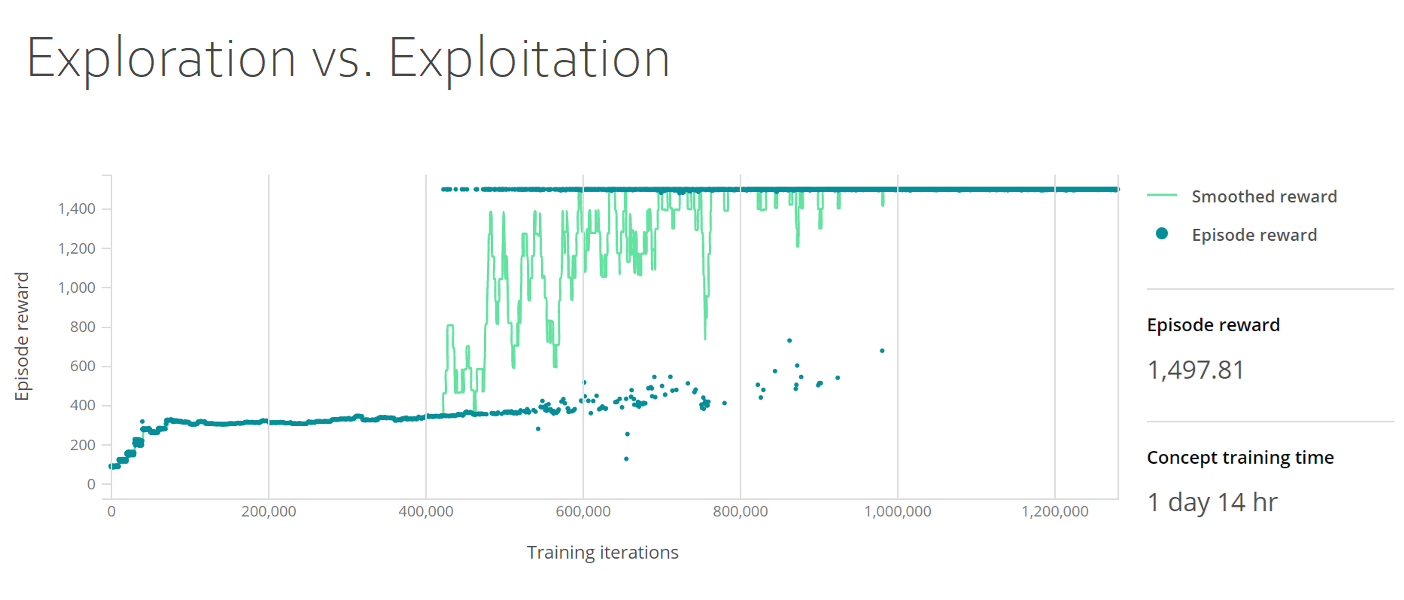
Selon l'objectif et la fonction de récompense, l'agent doit trouver un équilibre entre l'exploration et la maximisation de sa récompense. Ce choix est appelé compromis entre exploration et exploitation. Comme c'est souvent le cas dans le monde réel, l'agent doit trouver un équilibre entre les mérites d'une exploration plus approfondie de l'environnement, qui peut mener à des décisions plus pertinentes à l'avenir, et l'exploitation de l'environnement, en utilisant toutes les connaissances dont l'agent dispose sur le monde pour maximiser la récompense. Le choix d'actions différentes peut offrir une nouvelle perspective, surtout si ces actions n'ont encore jamais été essayées.
Le tableau de bord d'apprentissage suivant illustre le compromis entre exploration et exploitation. Le graphique présente à la fois les récompenses lissées et les récompenses par épisode, avec les récompenses par épisode sur l'axe des Y et les itérations d'apprentissage sur l'axe des X. La densité de récompense par épisode grimpe à 400 pour les 50 000 premières itérations, puis se maintient jusqu'à 400 000 itérations, où elle passe à 1 500 et reste stable.
Effet cobra
Les récompenses sont soumises à ce que l'on appelle en économie l'effet cobra. À l'époque de la domination britannique de l'Inde coloniale, le gouvernement décida de lutter contre la prolifération de cobras sauvages en offrant une récompense en échange de chaque cobra mort. Au départ, cette politique permit d'éliminer un grand nombre de serpents. Mais elle eut rapidement pour effet pervers d'encourager des gens à élever des cobras pour empocher la récompense. Lorsque les autorités prirent conscience de ce phénomène, le programme fut annulé. Privés d'incitations financières, les éleveurs libérèrent leurs serpents dans la nature et la population de cobras sauvages explosa pour atteindre un niveau sans précédent.
Les mesures d'incitation bien intentionnées avaient aggravé la situation au lieu de l'améliorer. Quel enseignement en tirer ? Les agents apprennent le comportement que vous encouragez, mais celui-ci ne produit pas nécessairement le résultat escompté.
Récompenses mises en forme
La création d'une fonction de récompense présentant une forme particulière peut permettre à l'agent d'apprendre une stratégie appropriée plus facilement et plus rapidement.
Une fonction en escalier est un exemple de fonction de récompense limitée qui ne renseigne guère l'agent sur la qualité de son action. Dans la fonction de récompense en escalier suivante, seule une action à distance entre 0.0 et 0.1 génère une récompense complète de 1.0. Lorsque la distance est supérieure à 0.1, il n'y a pas de récompense.

En revanche, une fonction de récompense mise en forme permet à l'agent de déterminer si l'action est proche de la réponse souhaitée. La fonction de récompense mise en forme suivante accorde une plus grande récompense selon la proximité de la réponse par rapport à l'action 0.0 souhaitée. La courbe de la fonction est une hyperbole. La récompense est de 1.0 pour une distance de 0.0 et diminue progressivement jusqu'à 0.0 à mesure que la distance se rapproche de 1.0.
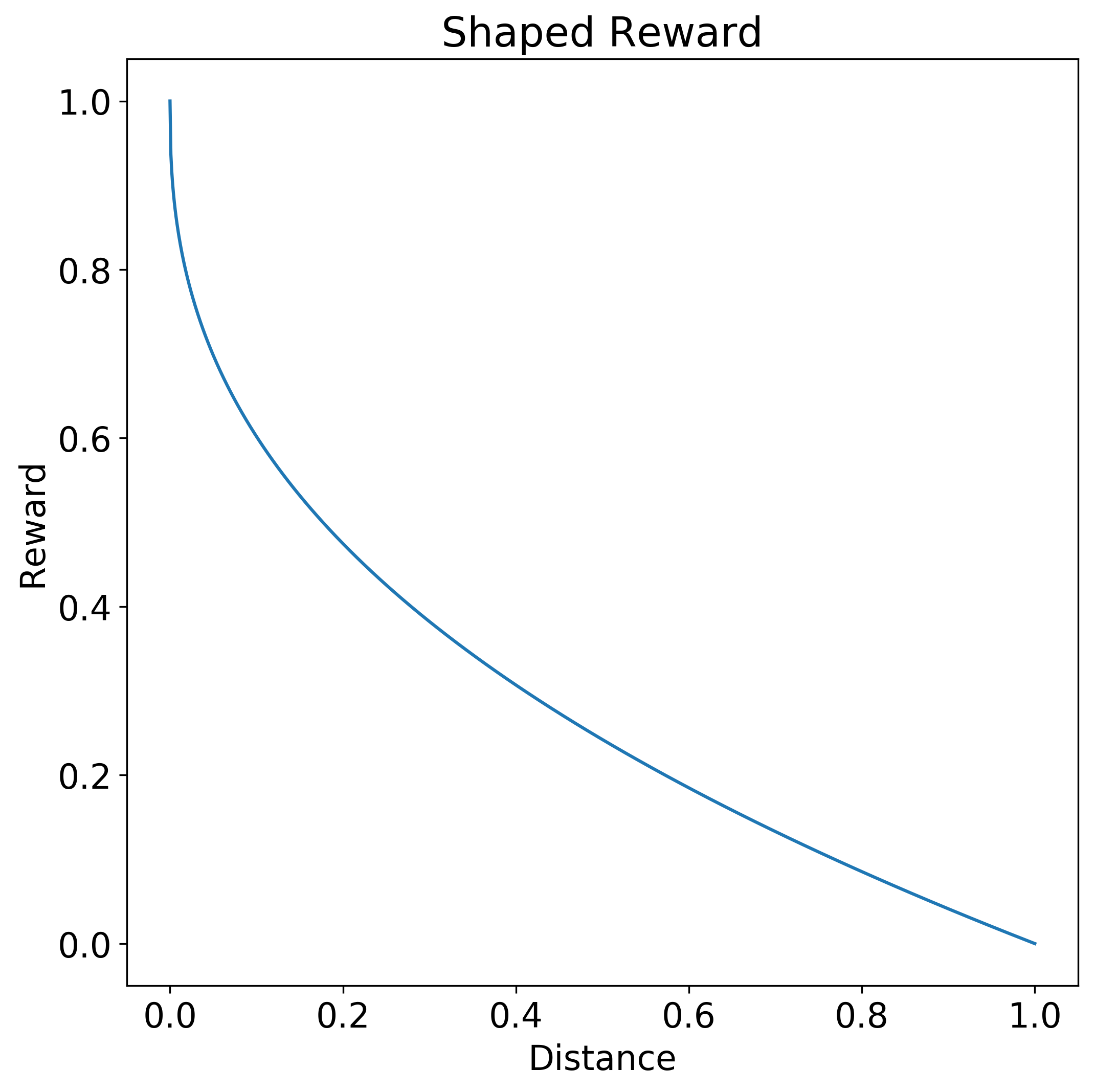
La mise en forme peut réduire la valeur d'une récompense future par rapport à une récompense plus immédiate, ou encourager l'exploration en réduisant la taille des récompenses autour de l'objectif.
Parfois, une fonction de récompense peut spécifier des considérations temporelles et spatiales, pour encourager des séquences d'actions ordonnées. Cependant, si une fonction de récompense mise en forme devient importante et complexe, vous devrez envisager de décomposer le problème en étapes plus petites et d'utiliser des réseaux conceptuels.
Réseaux conceptuels
Les réseaux conceptuels permettent de spécifier et de réutiliser les connaissances spécifiques à un domaine et l'expertise technique pour collecter un ordre de comportement souhaité dans une séquence spécifique de tâches distinctes. Les réseaux conceptuels contribuent à restreindre l'espace de recherche dans lequel l'agent peut opérer et prendre des mesures.
Dans le réseau conceptuel suivant dédié à la saisie et à l'empilement d'objets, la case Saisir et empiler est le parent de deux cases grises, Atteindre et Déplacer, et de trois cases vertes, Orienter, Saisir et Empiler.
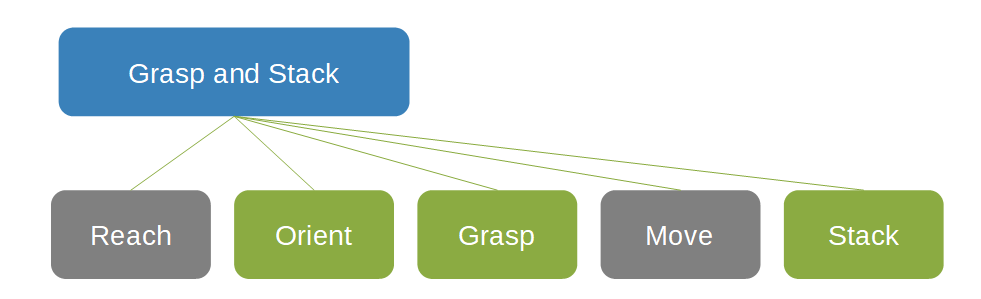
Les réseaux conceptuels facilitent souvent la définition des fonctions de récompense. Chaque concept peut utiliser l'approche la plus appropriée pour la tâche. La notion de réseaux conceptuels permet de décomposer la solution en éléments constitutifs. Les composants peuvent être remplacés sans avoir à reprendre l'apprentissage de l'ensemble du système, ce qui permet de réutiliser des modèles préformés et d'utiliser des contrôleurs existants ou d'autres composants de l'écosystème. Dans les systèmes de contrôle industriels, notamment, une amélioration progressive et fragmentaire peut être plus souhaitable qu'une suppression et un remplacement complets.
Apprentissage via un programme de formation et apprentissage par la pratique
La décomposition du problème en tâches séquentielles distinctes avec des réseaux conceptuels permet de l'aborder par étape et de le présenter à l'agent comme un programme de formation à difficulté croissante. Cette approche échelonnée commence par un problème simple, permet à l'agent de s'exercer, puis accentue la difficulté à mesure que ses capacités augmentent. La fonction de récompense change et évolue à mesure que les compétences de l'agent s'améliorent. Cette approche d'apprentissage via un programme de formation permet de guider l'exploration et réduit considérablement le délai d'apprentissage nécessaire.
Vous pouvez également restreindre l'espace de recherche de stratégie de l'agent en lui demandant d'apprendre en imitant le comportement d'un expert externe. L'apprentissage par la pratique utilise des exemples guidés par des experts pour restreindre l'espace d'état exploré par l'agent. L'apprentissage par la pratique permet d'apprendre plus rapidement des solutions connues, au détriment de la découverte de solutions nouvelles.
L'apprentissage par la pratique peut par exemple consister à apprendre à l'agent d'une voiture autonome à imiter les actions d'un conducteur humain. L'agent apprend à conduire, mais il hérite également des défauts et des manies de l'enseignant.
Conception de systèmes d'IA basés sur le RL
La stratégie suivante est un guide pratique sur la création de systèmes d'IA basés sur le RL :
- Formuler et itérer les états, les conditions terminales, les actions et les récompenses.
- Concevoir des fonctions de récompense, en les mettant en forme selon les besoins.
- Attribuer des récompenses pour des sous-objectifs spécifiques.
- Réduire drastiquement les récompenses si nécessaire.
- Expérimenter les états initiaux.
- Expérimenter un échantillon d'exemples pour l'apprentissage.
- Limiter les variantes au niveau des paramètres de la dynamique de simulation pendant l'apprentissage.
- Généraliser pendant la prédiction et faire en sorte que l'apprentissage soit le plus fluide possible.
- Introduire un bruit physiquement pertinent pour gérer le bruit dans les machines réelles.
Simulations
Les systèmes d'IA sont avides de données et doivent être exposés à de nombreux scénarios pour être formés à la prise de décisions appropriées. Ces systèmes nécessitent souvent des prototypes coûteux qui peuvent être endommagés dans les environnements réels. Le coût de la collecte et de l'étiquetage manuel des données d'apprentissage haute fidélité est élevé, à la fois en termes de temps et de main-d'œuvre directe. L'utilisation de simulateurs et des données d'apprentissage densément étiquetées qu'ils génèrent permet de combler une grande partie de ce déficit de données.
Le fléau de la dimension désigne les phénomènes qui surviennent lors du traitement de grandes quantités de données dans des espaces de grande dimension. Pour modéliser avec précision certains scénarios et ensembles de problèmes, des réseaux neuronaux profonds doivent être utilisés. Ces réseaux sont eux-mêmes hautement dimensionnels, avec de nombreux paramètres qui doivent être ajustés. À mesure que la dimensionnalité s'accroît, le volume de l'espace augmente à un rythme tel que les données réelles disponibles deviennent rares. Il est alors difficile de collecter suffisamment de données pour établir des corrélations statistiquement significatives. Faute de données suffisantes, l'apprentissage aboutit à un modèle qui ne correspond pas aux données et ne se généralise pas bien aux nouvelles données, ce qui va à l'encontre de l'objectif d'un modèle.
Le problème est double :
- L'algorithme dispose d'une grande capacité d'apprentissage pour modéliser avec précision le problème, mais a besoin de plus de données pour éviter un sous-ajustement.
- La collecte et l'étiquetage de cette grande quantité de données, bien que réalisables, s'avèrent néanmoins difficiles, coûteux et sujets à erreurs.
Les simulations offrent une alternative à la collecte d'énormes quantités de données d'apprentissage réelles, en modélisant virtuellement les systèmes dans l'environnement physique prévu pour eux. Les simulations permettent un apprentissage dans des environnements dangereux, ou dans des conditions difficiles à reproduire dans le monde réel, comme différents types de conditions météorologiques. Les données simulées artificiellement contournent la difficulté de la collecte et alimentent les algorithmes de manière appropriée avec des exemples de scénarios qui leur permettent de se généraliser avec précision dans le monde réel.
Les simulations constituent la source d'apprentissage idéale pour le DRL, car elles sont :
- flexibles pour les environnements personnalisés ;
- sûres et économiques pour la génération de données ;
- parallélisables, ce qui permet de réduire les délais d'apprentissage.
Les simulations sont disponibles dans un large éventail de secteurs d'activité et de systèmes, comme le génie mécanique et électrique, les véhicules autonomes, la sécurité et la mise en réseau, le transport et la logistique, et la robotique.
Exemples d'outils de simulation :
- Simulink, outil de programmation graphique développé par MathWorks pour la modélisation, la simulation et l'analyse de systèmes dynamiques
- Gazebo, outil permettant de simuler avec précision des populations de robots dans des environnements intérieurs et extérieurs complexes
- Microsoft AirSim, plateforme de simulation robotique open source
Paradigme du Machine Teaching
Le Machine Teaching offre un nouveau paradigme dédié à la création de systèmes ML qui se concentre sur la génération et le déploiement de modèles, au détriment des algorithmes. Le Machine Teaching identifie les modèles du processus d'apprentissage proprement dit et adopte un comportement positif dans sa propre méthode. Une grande partie de l'activité du Machine Learning se concentre sur l'amélioration des algorithmes existants ou sur le développement de nouveaux algorithmes d'apprentissage. En revanche, le Machine Teaching se concentre sur l'efficacité des enseignants.
Le Machine Teaching :
- combine l'expertise technique acquise par des experts humains du domaine avec l'IA et le ML :
- automatise la génération et la gestion des algorithmes et des modèles d'apprentissage par renforcement profond ;
- intègre des simulations pour l'optimisation et la scalabilité des modèles ;
- fournit une meilleure explicabilité du comportement des modèles obtenus.
L'état du Machine Learning a été largement déterminé par quelques experts en algorithmes. Ces experts ont une connaissance approfondie du ML et peuvent modifier un algorithme ou une architecture de ML pour répondre aux métriques de performance ou de précision requises. Les experts en ML ne sont que quelques dizaines de milliers dans le monde entier, ce qui freine l'adoption des solutions ML. Compte tenu de l'incroyable complexité des modèles, les fonctionnalités ML sont souvent hors de portée.
Contrairement aux experts en ML qui sont rares, les experts techniques sont quant à eux très nombreux. À l'échelle mondiale, ils se comptent en dizaines de millions. Le Machine Teaching fait appel à ce vaste réservoir d'experts qui comprennent la sémantique des problèmes et peuvent fournir des exemples, mais sans avoir à connaître les subtilités du ML. Le Machine Teaching est l'abstraction fondamentale nécessaire à une programmation efficace de l'expertise technique par la codification ce qu'il faut enseigner et de la façon de l'enseigner. Les experts techniques sans expérience en IA peuvent décomposer leur expertise en étapes, tâches, critères et résultats souhaités.
Pour les ingénieurs, le Machine Teaching élève la barre de l'abstraction au-delà de la sélection des algorithmes d'IA et du réglage des hyperparamètres pour se concentrer sur des problèmes de domaine d'application plus importants. Les ingénieurs qui conçoivent des systèmes autonomes peuvent créer des modèles précis et détaillés de systèmes et d'environnements, et les rendre intelligents à l'aide de méthodes telles que l'apprentissage profond, l'apprentissage par imitation et l'apprentissage par renforcement. Le Machine Teaching raccourcit également le délai de modélisation du déploiement, en réduisant ou en éliminant la nécessité d'intervention manuelle d'experts en Machine Learning pendant le développement.
Le Machine Teaching rationalise le processus de création de solutions de ML en examinant les pratiques courantes de ML et en adoptant des stratégies bénéfiques dans ses propres méthodes. Avec les instructions et la configuration du développeur, Bonsai, le service de Machine Teaching de la plateforme Microsoft Autonomous Systems Platform, peut automatiser le développement de modèles IA dans un système d'IA.
Bonsai fournit un tableau de bord central facile à comprendre qui suit l'état actuel de chaque projet grâce à des outils de gestion de version. L'utilisation de cette infrastructure de Machine Teaching garantit la possibilité de reproduire les résultats des modèles, et permet aux développeurs d'actualiser facilement les systèmes d'IA en cas d'innovations algorithmiques.
Un changement de perspective vers une méthodologie de Machine Teaching favorise l'adoption du ML avec un processus plus rationalisé et plus accessible pour la génération et le déploiement de modèles ML. Le Machine Teaching permet aux experts du domaine d'appliquer le DRL en tant qu'outil. Avec le Machine Teaching, les algorithmes et techniques de ML sont appliqués par des experts du domaine pour résoudre les problèmes réels.
Processus de Machine Teaching
Le développement et le déploiement du Machine Teaching se décomposent en trois phases : Créer, Effectuer l'apprentissage et Déployer
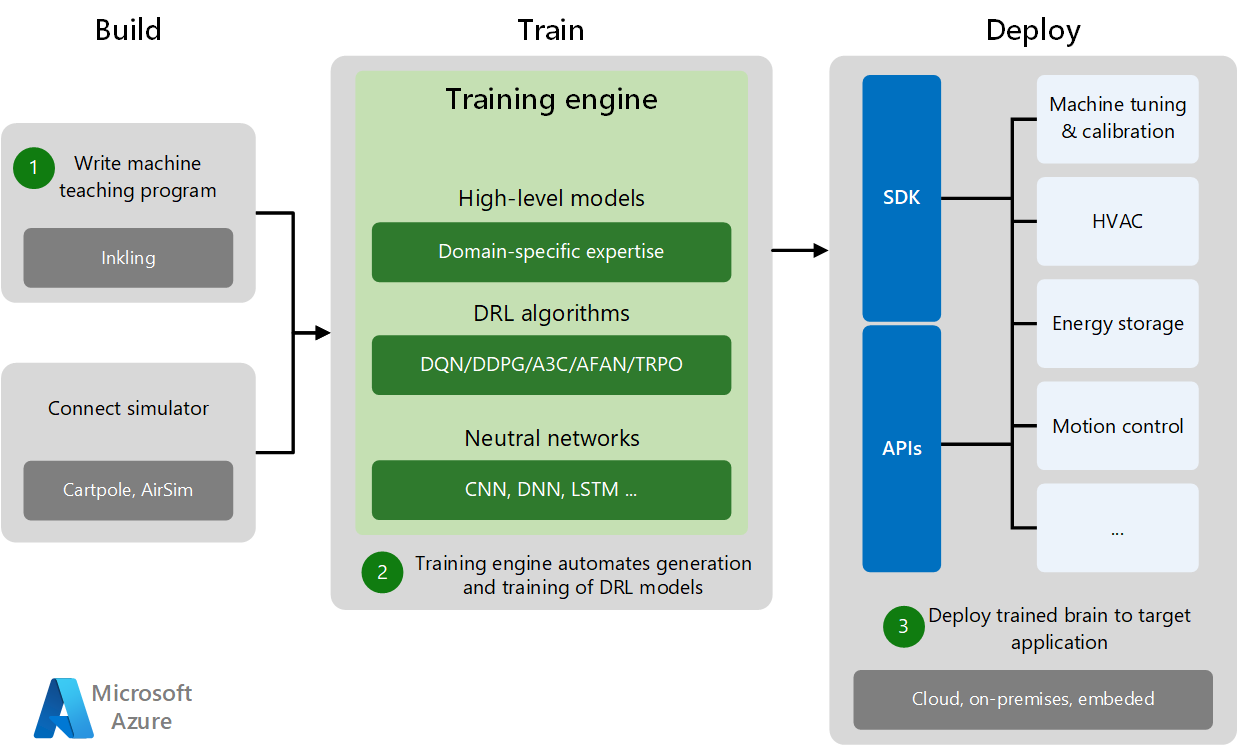
- La phase Créer consiste à concevoir le programme de Machine Teaching et à se connecter à un simulateur d'apprentissage spécifique au domaine. Les simulateurs génèrent suffisamment de données d'apprentissage pour les expériences et la pratique.
- Au cours de la phase Effectuer l'apprentissage, le moteur d'apprentissage automatise la génération et l'apprentissage des modèles DRL en combinant des modèles de domaine de haut niveau avec des algorithmes DRL appropriés et des réseaux neuronaux.
- La phase Déployer déploie le modèle formé sur l'application cible du cloud, l'application cible locale ou l'application cible intégrée localement. Des kits de développement logiciel (SDK) et des API de déploiement spécifiques permettent de déployer des systèmes d'IA formés sur diverses applications cibles, d'effectuer le réglage des machines et de contrôler les systèmes physiques.
Les environnements simulés génèrent de grandes quantités de données synthétiques couvrant de nombreux cas d'usage et scénarios. Les simulations permettent de générer des données sûres et rentables pour l'apprentissage des algorithmes des modèles, et de réduire le délai d'apprentissage grâce à la parallélisation des simulations. Les simulations contribuent à l'apprentissage des modèles dans différents types de scénarios et de conditions environnementales, beaucoup plus rapidement que ce qui est possible dans le monde réel, et en toute sécurité.
Les experts techniques peuvent superviser les agents qui travaillent à la résolution de problèmes dans les environnements simulés, et fournir un feedback et des conseils afin de permettre aux agents de s'adapter de façon dynamique dans le cadre de la simulation. Au terme de l'apprentissage, les ingénieurs déploient les agents formés sur du matériel réel, où ils peuvent utiliser leurs connaissances pour alimenter des systèmes autonomes dans le monde réel.
Machine Learning et Machine Teaching
Le Machine Teaching et le Machine Learning sont complémentaires et peuvent évoluer indépendamment. La recherche en matière de Machine Learning vise à améliorer l'apprentissage en perfectionnant les algorithmes. La recherche en matière de Machine Teaching vise à rendre l'enseignant plus productif lors de la création de modèles Machine Learning. Les solutions de Machine Teaching nécessitent différents algorithmes de Machine Teaching pour produire et tester des modèles tout au long du processus d'apprentissage.
Le diagramme suivant illustre un pipeline représentatif pour la création d'un modèle Machine Learning :
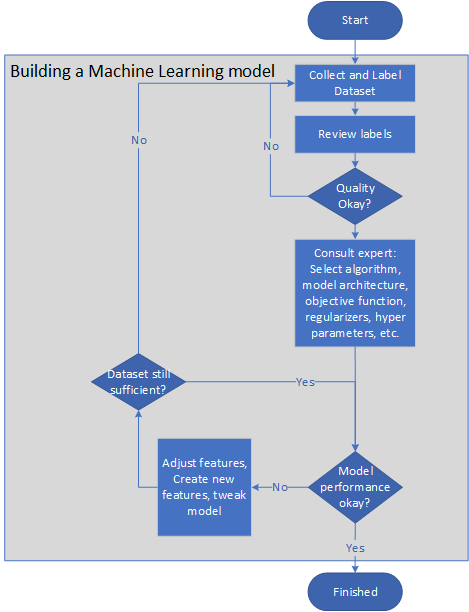
- Le propriétaire du problème collecte et étiquette les jeux de données, ou élabore une ligne directrice sur l'étiquetage afin que la tâche d'étiquetage puisse être externalisée.
- Le propriétaire du problème examine les étiquettes jusqu'à ce que leur qualité soit satisfaisante.
- Les experts en Machine Learning sélectionnent un algorithme, une architecture de modèle, une fonction objective, des régularisateurs et des ensembles de validation croisée.
- Les ingénieurs effectuent l'apprentissage du modèle de façon cyclique, en ajustant les fonctionnalités ou en créant de nouvelles fonctionnalités pour améliorer la précision et la vitesse du modèle.
- Le modèle est testé sur un petit échantillon. Si le système ne fonctionne pas bien lors du test, les étapes précédentes sont répétées.
- Les performances du modèle sont supervisées sur le terrain. Si elles sont inférieures à un seuil critique, le modèle est modifié en répétant les étapes précédentes.
Le Machine Teaching automatise la création de ce type de modèles, ce qui réduit le besoin d'intervention manuelle dans le cadre du processus d'apprentissage pour améliorer la sélection des fonctionnalités ou des exemples, ou peaufiner les hyperparamètres. En effet, le Machine Teaching introduit un niveau d'abstraction dans les éléments d'IA du modèle, ce qui permet au développeur de se concentrer sur la connaissance du domaine. Cette abstraction permet également de remplacer l'algorithme d'IA par de nouveaux algorithmes plus innovants, sans qu'il soit nécessaire de respécifier le problème.
Le rôle de l'enseignant est d'optimiser le transfert des connaissances vers l'algorithme d'apprentissage afin qu'il puisse générer un modèle utile. Les enseignants jouent également un rôle central dans la collecte et l'étiquetage des données. Les enseignants peuvent filtrer les données non étiquetées pour sélectionner des exemples spécifiques, ou consulter les données des exemples disponibles et deviner leur étiquette en se basant sur leur propre intuition ou sur leurs propres biais. De même, en présence de deux fonctionnalités sur un grand ensemble sans étiquette, les enseignants peuvent supposer que l'une est meilleure que l'autre.
L'image suivante illustre le processus de Machine Teaching :
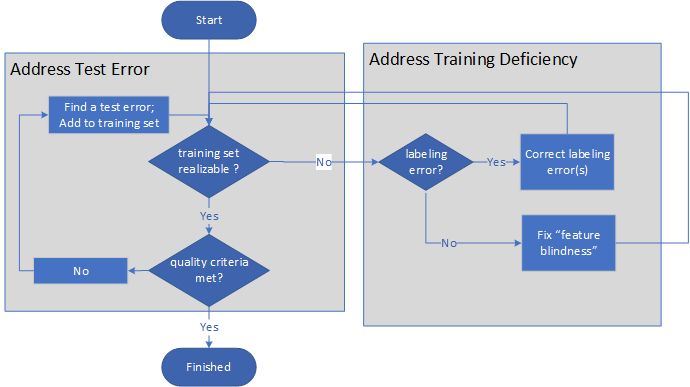
- L'enseignant se demande d'abord si un ensemble d'apprentissage est réalisable.
- Si l'ensemble d'apprentissage n'est pas réalisable, l'enseignant détermine si le problème est dû à un étiquetage inadéquat ou à des lacunes au niveau des fonctionnalités. Après avoir corrigé l'étiquetage ou ajouté des fonctionnalités, l'enseignant évalue à nouveau si l'ensemble d'apprentissage est réalisable.
- S'il l'est, l'enseignant détermine si les critères de qualité de l'apprentissage sont remplis.
- Si ces critères ne sont pas remplis, l'enseignant recherche les erreurs de test et ajoute les corrections à l'ensemble d'apprentissage, puis répète les étapes d'évaluation.
- Une fois l'ensemble d'apprentissage réalisable et les critères de qualité remplis, le processus prend fin.
Le processus est une paire de boucles indéfinies, ne se terminant que lorsque le modèle et l'apprentissage proprement dit sont de qualité suffisante.
La capacité d'apprentissage du modèle augmente à la demande. Il n'est pas nécessaire de procéder à une régularisation traditionnelle, car l'enseignant contrôle la capacité du système d'apprentissage en ajoutant des fonctionnalités uniquement lorsque cela s'avère nécessaire.
Machine Teaching et programmation traditionnelle
Le Machine Teaching est une forme de programmation. Comme pour la programmation, l'objectif du Machine Teaching est de créer une fonction. Les étapes de création d'une fonction cible sans état qui renvoie la valeur Y à partir d'une entrée X sont similaires pour les deux processus :
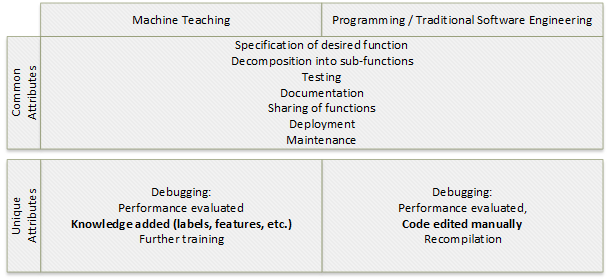
- Spécifiez la fonction cible.
- Décomposez la fonction cible en sous-fonctions, le cas échéant.
- Déboguez et testez les fonctions et sous-fonctions.
- Documentez les fonctions.
- Partagez les fonctions.
- Déployez les fonctions.
- Gérez les fonctions avec des cycles de débogage planifiés et non planifiés.
Le débogage ou l'évaluation des performances de la solution présente des attributs différents selon le processus. En programmation, le débogage implique la modification et la recompilation manuelles du code. En Machine Teaching, le débogage comprend l'ajout de fonctionnalités et d'étiquettes de connaissance, ainsi qu'un apprentissage complémentaire.
La création d'une fonction de classification cible qui renvoie la classe Y à partir d'une entrée X implique un algorithme de Machine Learning, tandis que le processus de Machine Teaching est similaire à l'ensemble des étapes de programmation ci-dessus.
Le tableau suivant illustre certaines similitudes conceptuelles entre la programmation traditionnelle et le Machine Teaching :
| Programmation | Apprentissage de machine |
|---|---|
| Compilateur | Algorithmes de Machine Learning, machines à vecteurs de support, réseaux neuronaux, moteur d'apprentissage |
| Systèmes d'exploitation, services, environnements de développement intégrés (IDE) | Apprentissage, échantillonnage, sélection des fonctionnalités, service d'apprentissage automatique |
| Frameworks | ImageNet, word2vec |
| Langages de programmation tels que Python et C# | Inkling, étiquettes, fonctionnalités, schémas |
| Expertise en programmation | Expertise en enseignement |
| Gestion de versions | Gestion de versions |
| Processus de développement (spécifications, tests unitaires, déploiement, supervision, etc.) | Processus d'enseignement (collecte de données, tests, publication, etc.) |
La décomposition est un puissant concept qui permet aux ingénieurs logiciels de concevoir des systèmes capables de résoudre des problèmes complexes. La décomposition utilise des concepts simples pour exprimer des concepts complexes. Les enseignants peuvent apprendre à décomposer des problèmes de Machine Learning complexes avec les bons outils et les expériences adéquates. La discipline de Machine Teaching peut permettre d'atteindre un niveau comparable à celui de la programmation en termes d'enseignement.
Projets de Machine Teaching
Configuration requise :
- Expérience en matière de collecte, d'exploration, de nettoyage, de préparation et d'analyse des données
- Connaissance des concepts de base du ML, comme les fonctions objectives, l'apprentissage, la validation croisée et la régularisation
Lors de l'élaboration d'un projet de Machine Teaching, commencez par un modèle réaliste mais relativement simple, pour permettre une itération et une formulation rapides. Ensuite, améliorez de manière itérative la fidélité du modèle, et rendez celui-ci plus généralisable grâce à une meilleure couverture des scénarios.
Le diagramme suivant illustre les phases du développement d'un modèle Machine Teaching itératif. Chacune des étapes successives nécessite un plus grand nombre d'échantillons d'apprentissage.
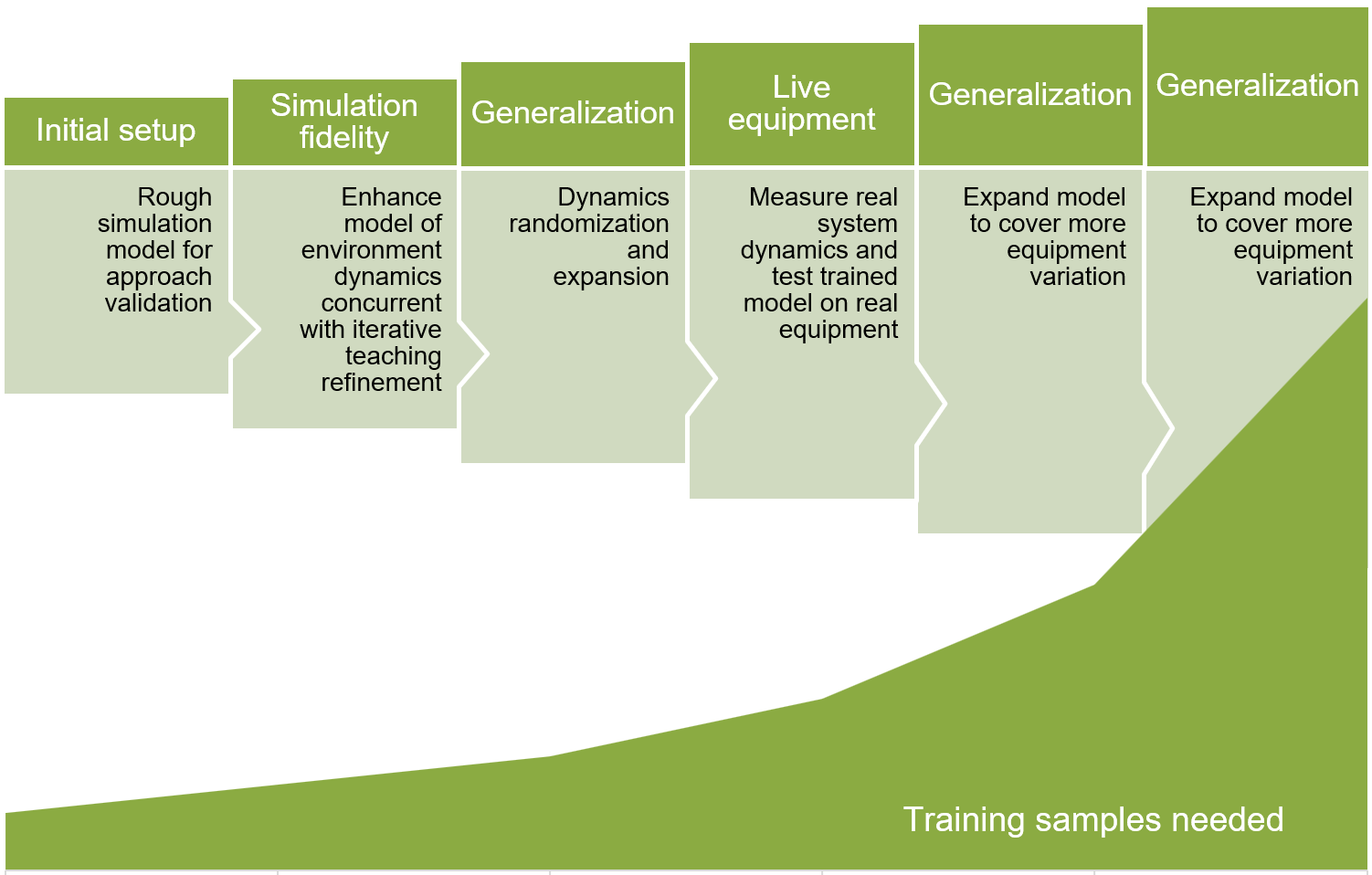
- Configurez un premier modèle de simulation grossier pour la validation de l'approche.
- Améliorez la fidélité de la simulation en modélisant la dynamique de l'environnement tout en affinant l'apprentissage itératif.
- Généralisez le modèle avec une randomisation et une expansion dynamiques.
- Mesurez la dynamique du système réel et testez le modèle formé sur un équipement réel.
- Développez le modèle pour couvrir plus de variantes d'équipement.
La définition de paramètres exacts pour des projets de Machine Teaching nécessite un peu d'expérimentation et d'exploration empirique. Une plateforme de Machine Teaching comme Bonsai sur la plateforme des systèmes autonomes Microsoft utilise les innovations et simulations DRL pour simplifier le développement de modèles IA.
Exemple de projet
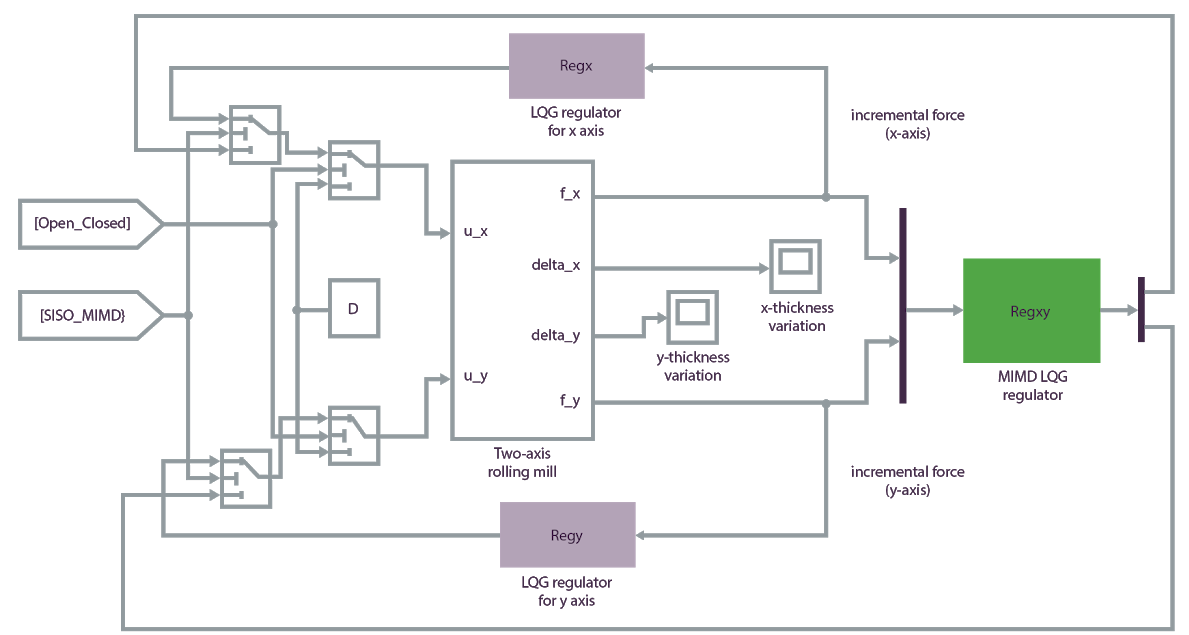
Le cas d'usage d'une optimisation de processus de fabrication est un exemple de projet d'IA de systèmes autonomes. L'objectif est d'optimiser la tolérance d'épaisseur d'une poutre en acier fabriquée sur une chaîne de production. Les rouleaux exercent une pression sur une pièce d'acier pour lui donner l'épaisseur voulue.
Les entrées d'état de la machine dans le système d'IA sont la force de laminage, l'erreur liée au rouleau et le bruit du rouleau. Les actions de contrôle du système d'IA sont des commandes d'actionneur permettant de contrôler le fonctionnement et le mouvement des rouleaux, et d'optimiser la tolérance d'épaisseur de la poutre en acier.
Tout d'abord, recherchez ou développez un simulateur capable de simuler des agents, des capteurs et l'environnement. Le modèle de simulation Matlab suivant fournit un environnement d'apprentissage précis pour ce système d'IA :
Utilisez le service de Machine Teaching Bonsai de la plateforme Microsoft Autonomous Systems Platform pour créer un plan de Machine Teaching dans un modèle, effectuer l'apprentissage du modèle par rapport au simulateur et déployer le système d'IA formé sur le site de production réel. Inkling est un langage spécifique qui permet de décrire de façon formelle les plans de Machine Teaching. Dans Bonsai, vous pouvez utiliser Inkling pour décomposer le problème en schéma :

Définissez ensuite les concepts clés et créez un programme de formation pour effectuer l'apprentissage du système d'IA, en spécifiant la fonction de récompense pour l'état de simulation :

Le système d'IA apprend en effectuant la tâche d'optimisation dans le cadre de la simulation, en suivant les concepts de Machine Teaching. Vous pouvez charger la simulation dans Bonsai, où des visualisations sont disponibles sur la progression de l'apprentissage.
Après avoir créé et formé le modèle ou cerveau, vous pouvez l'exporter pour le déployer sur le site de production, où les commandes d'actionneur optimales sont transmises par le moteur d'IA pour prendre en charge les décisions de l'opérateur en temps réel.
Autres exemples d'applications
Les exemples de Machine Teaching suivants permettent de créer des stratégies pour contrôler les mouvements des systèmes physiques. Dans les deux cas, la création manuelle d'une stratégie pour l'agent est irréalisable ou très difficile. Le fait de permettre à l'agent d'explorer l'espace en simulation et de le guider pour faire des choix grâce aux fonctions de récompense produit des solutions précises.
Cartpole
Dans l'exemple de projet Cartpole de Bonsai, l'objectif est d'apprendre à un mât à rester debout sur un chariot mobile. Le mât est attaché (via une charnière non activée) au chariot, qui se déplace le long d'une piste sans frottement. Les informations disponibles sur les capteurs sont la position et la vitesse du chariot, ainsi que l'angle du mât et la vitesse angulaire.
L'application d'une force sur le chariot permet de contrôler le système. Les actions prises en charge par l'agent consistent à pousser le chariot vers la gauche ou la droite. Le programme prévoit une récompense positive chaque fois que le mât reste debout. L'épisode se termine lorsque le mât est à plus de 15 degrés de la verticale ou que le chariot se déplace à plus d'un nombre prédéfini d'unités du centre.
L'exemple utilise le langage Inkling pour écrire le programme de Machine Teaching ainsi que le simulateur Cartpole fourni pour accélérer et améliorer l'apprentissage.
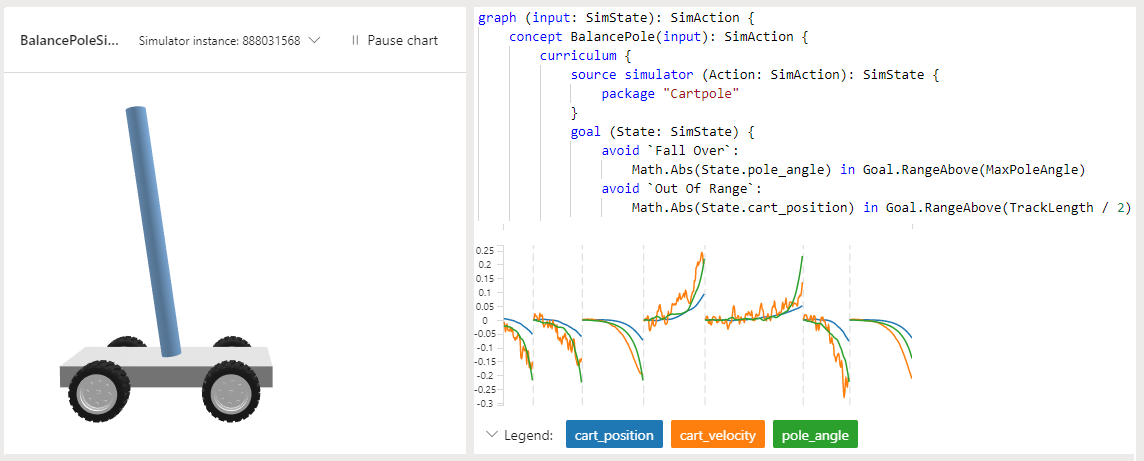
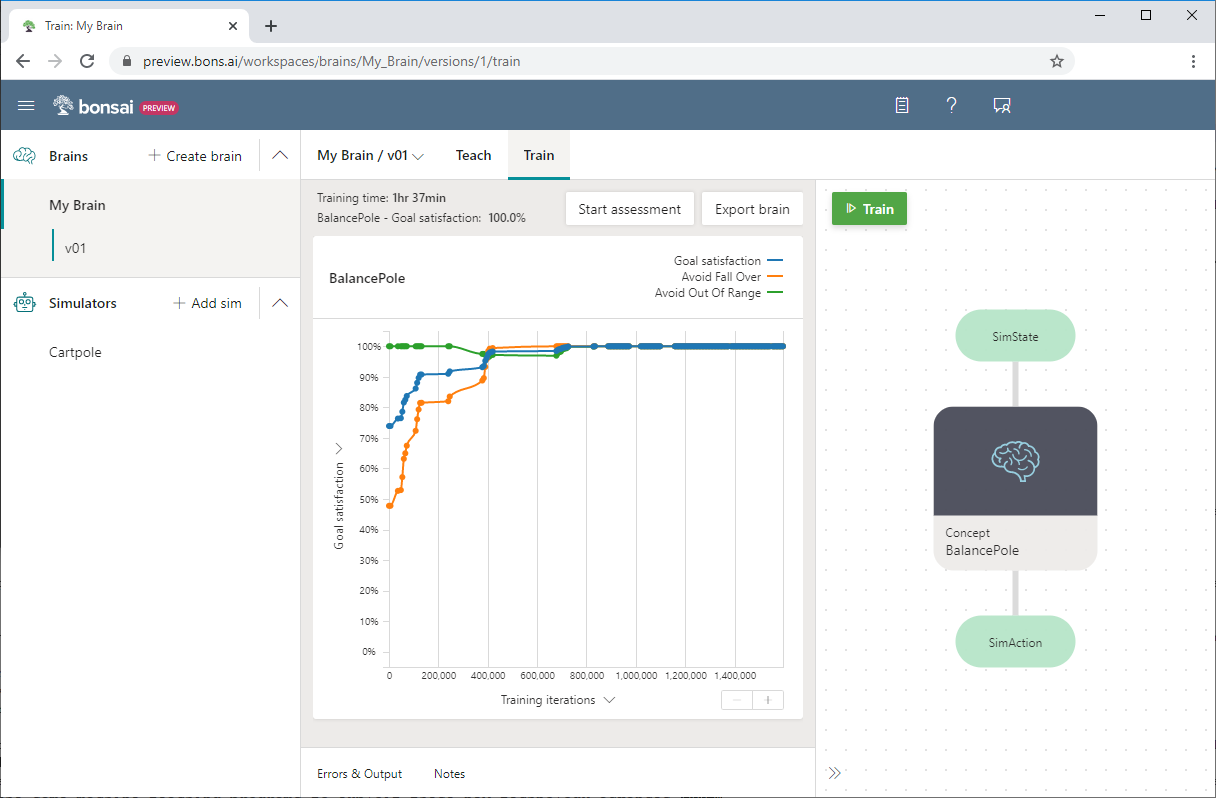
La capture d'écran suivante de Bonsai illustre un apprentissage Cartpole, avec la Satisfaction de l'objectif sur l'axe des Y et les Itérations d'apprentissage sur l'axe des X. Le tableau de bord Bonsai indique également le pourcentage de satisfaction de l'objectif et le temps total d'apprentissage.

Pour plus d’informations sur l’exemple Cartpole ou pour l’essayer vous-même, consultez Découvrez comment vous pouvez enseigner à un agent IA pour équilibrer un pôle.
Forage pétrolier
L'application Forage pétrolier horizontal est un contrôleur de mouvement permettant d'automatiser les plateformes pétrolières qui forent horizontalement sous terre. Un opérateur contrôle la foreuse à l'aide d'un joystick pour la maintenir à l'intérieur du schiste bitumineux tout en évitant les obstacles. La foreuse effectue le moins d'actions de pilotage possible, pour un forage plus rapide. L'objectif est d'utiliser l'apprentissage par renforcement pour automatiser le contrôle du forage pétrolier horizontal.
Les informations disponibles sur les capteurs sont la direction de la force de l'outil, le poids de l'outil, la force latérale et l'angle de forage. Les actions prises en charge par l'agent consistent à déplacer l'outil vers le haut, le bas, la gauche ou la droite. Le programme offre une récompense positive lorsque la foreuse se trouve dans la distance de tolérance des parois de la chambre. Le modèle apprend à s'adapter à différents plans de puits, à différentes positions de départ de forage et aux imprécisions des capteurs.
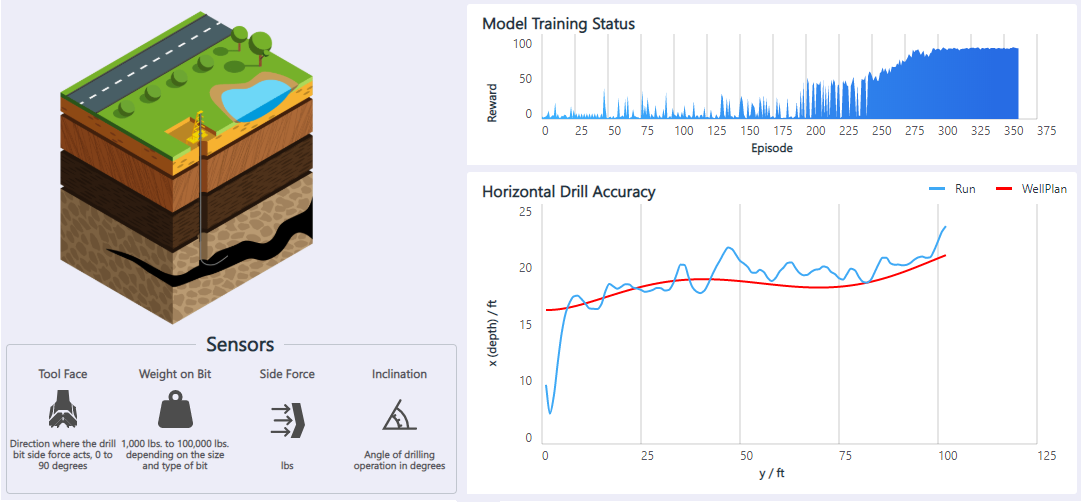
Pour plus d'informations et pour obtenir une démonstration de cette solution, consultez Contrôle des mouvements : forage pétrolier horizontal.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteur principal :
- Jose Contreras | Principal Software Engineering Manager
Pour afficher les profils LinkedIn non publics, connectez-vous à LinkedIn.
Étapes suivantes
- Machine Teaching pour les systèmes autonomes
- Systèmes autonomes avec l'IA Microsoft
- Autonomie des systèmes de contrôle industriels
- Machine Teaching : Comment l'expertise humaine renforce la puissance de l'IA
- Microsoft élargit la disponibilité des outils de systèmes autonomes pour ingénieurs et développeurs
- Espace d'innovation : systèmes autonomes (vidéo)
- Blog consacré à l'IA Microsoft
- AirSim (Aerial Informatics and Robotics Simulation)
- Gazebo
- Simulink
En savoir plus sur le Machine Teaching :
- « Bonsai, AI for Everyone » (Bonsai, l'IA pour tous), 2 mars 2016
- « AI use cases: innovations solving more than just toy problems » (Cas d'usage de l'IA : des innovations qui résolvent bien plus que de simples problèmes de jouets), 2 mars 2017
- Patrice Y. Simard, Saleema Amershi, David M. Chickering, et al., « Machine Teaching: A New Paradigm for Building Machine Learning Systems » (Machine Teaching : un nouveau paradigme pour la création de systèmes de Machine Learning), 2017
- Carlos E. Perez, « Deep Teaching: The Sexiest Job of the Future » (Le Deep Teaching : le métier le plus passionnant du futur), 29 juillet 2017
- Tambet Matiisen, « Demystifying deep reinforcement learning » (Démystifier l'apprentissage par renforcement profond), 19 décembre 2015
- Andrej Karpathy, « Deep Reinforcement Learning: Pong from Pixels » (Apprentissage par renforcement profond : Pong de Pixels), 31 mai 2016
- David Kestenbaum, « Pop Quiz: How Do You Stop Sea Captains From Killing Their Passengers? » (Comment empêcher des capitaines de tuer leurs passagers ?) 10 septembre 2010