Tutoriel : implémenter Azure Databricks avec un point de terminaison Azure Cosmos DB
Ce tutoriel explique comment implémenter un environnement Databricks injecté sur un réseau virtuel avec un point de terminaison de service activé pour Azure Cosmos DB.
Ce didacticiel vous montre comment effectuer les opérations suivantes :
- Créer un espace de travail Azure Databricks dans un réseau virtuel
- Créer un point de terminaison de service Azure Cosmos DB
- Créer un compte Azure Cosmos DB et importer des données
- Créer un cluster Azure Databricks
- Interroger Azure Cosmos DB à partir d’un notebook Azure Databricks
Prérequis
Avant de commencer, procédez comme suit :
Créez un espace de travail Azure Databricks dans un réseau virtuel.
Téléchargez le connecteur Spark.
Télécharger les exemples de données à partir de NOAA National Centers for Environmental Information. Sélectionnez un état ou une zone, puis Rechercher. À la page suivante, acceptez les valeurs par défaut et sélectionnez Rechercher. Sélectionnez ensuite Téléchargement du fichier CSV sur le côté gauche de la page pour télécharger les résultats.
Téléchargez le fichier binaire précompilée de l’outil de migration de données Azure Cosmos DB.
Créer un point de terminaison de service Azure Cosmos DB
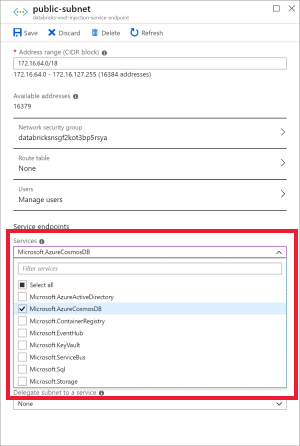
Une fois que vous avez déployé un espace de travail Azure Databricks dans un réseau virtuel, accédez au réseau virtuel dans le portail Azure. Notez les sous-réseaux publics et privés qui ont été créés via le déploiement de Databricks.
Sélectionnez le sous-réseau public et créez un point de terminaison de service Azure Cosmos DB. Enregistrez.
Création d’un compte Azure Cosmos DB
Ouvrez le portail Azure. Dans le coin supérieur gauche de l’écran, sélectionnez Créer une ressource > Bases de données > Azure Cosmos DB.
Renseignez les Détails de l’instance sur l’onglet De base avec les paramètres suivants :
Paramètre Valeur Abonnement votre abonnement Groupe de ressources votre groupe de ressources Nom du compte db-vnet-service-endpoint API Core (SQL) Emplacement USA Ouest Géoredondance Disable Écritures multirégions Activer 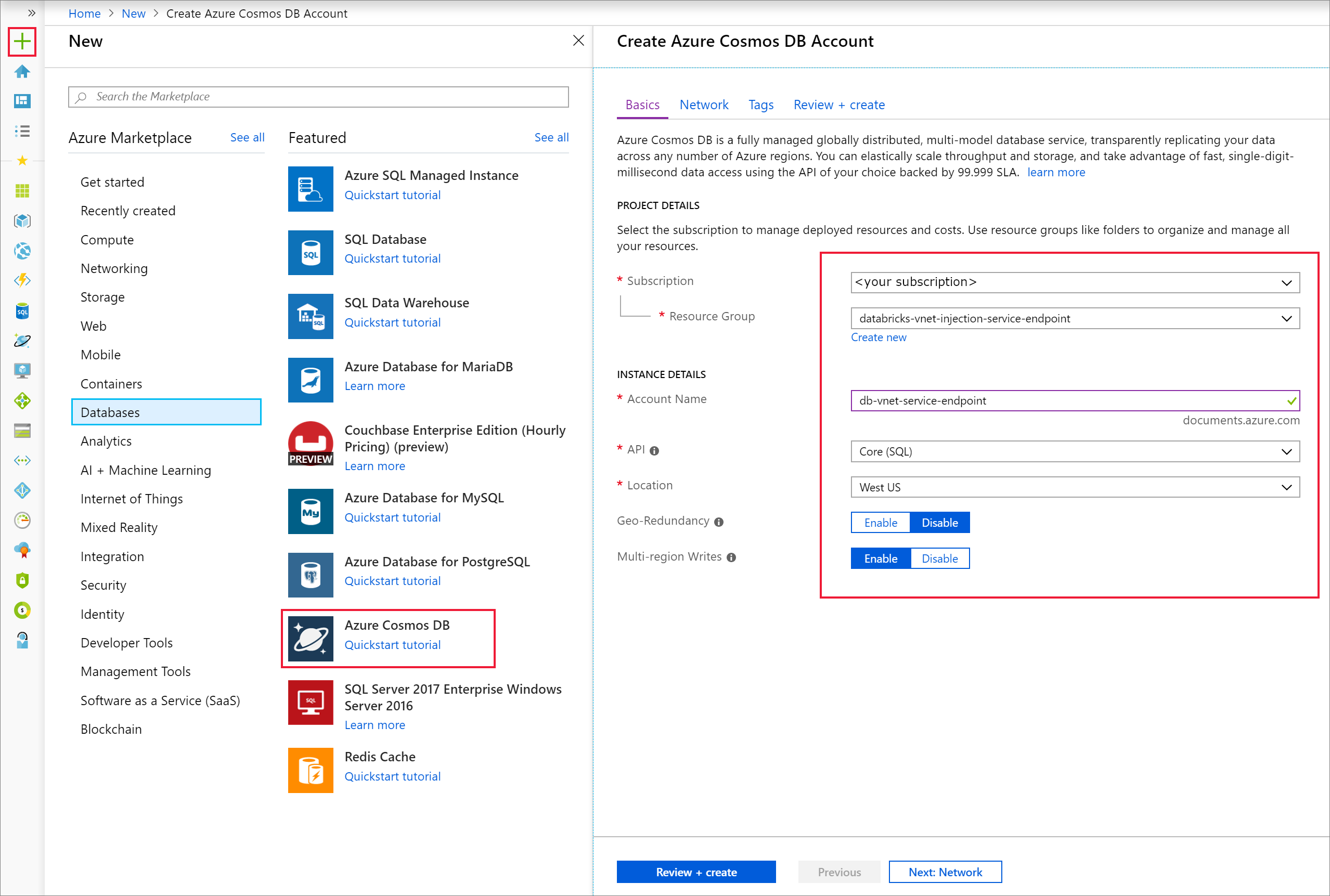
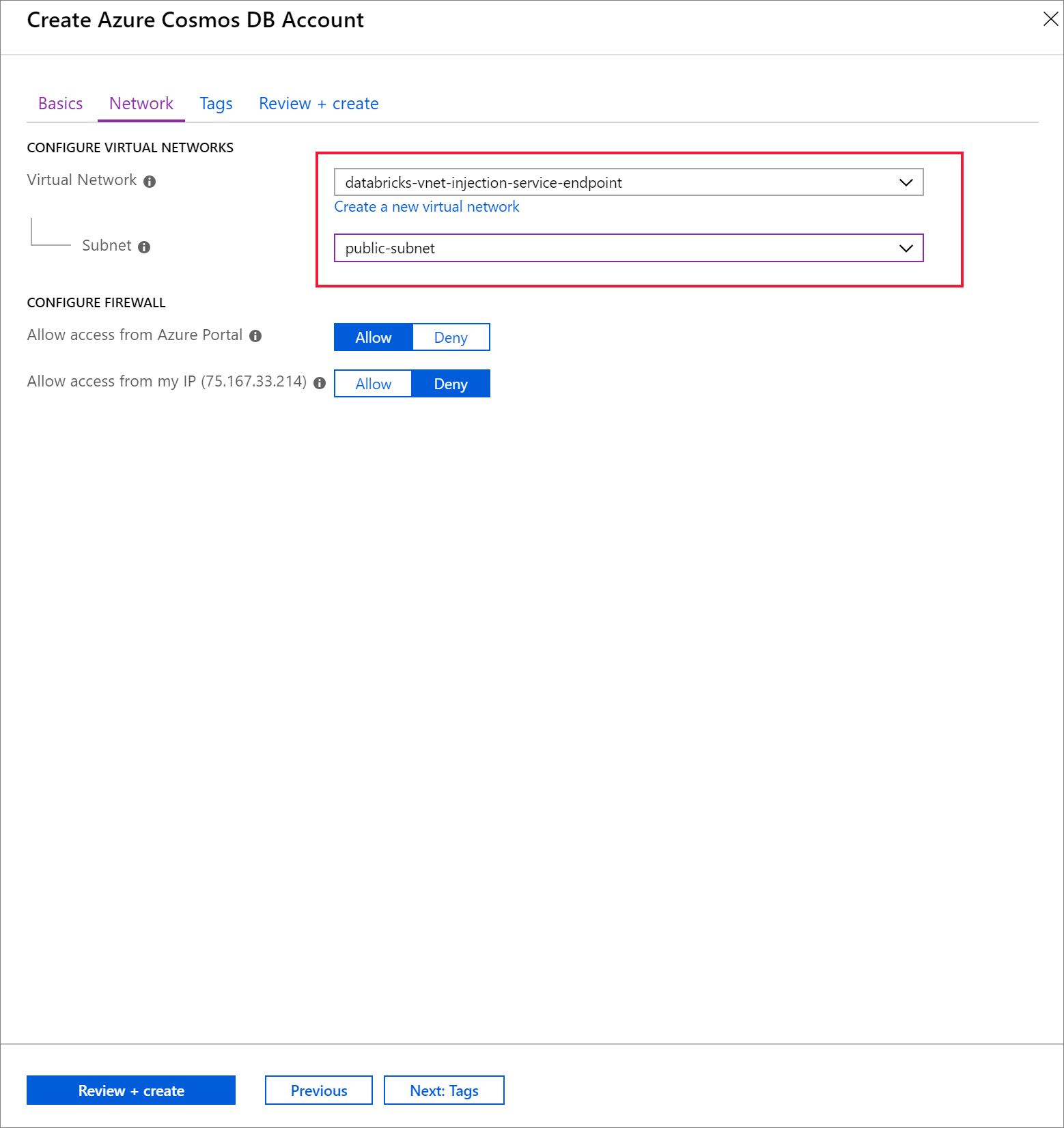
Sélectionnez l’onglet Réseau et configurez votre réseau virtuel.
a. Choisissez le réseau virtuel créé comme composant requis, puis sélectionnez public-subnet. Notez que private-subnet a la note Point de terminaison « Microsoft AzureCosmosDB » manquant. En effet, vous avez activé uniquement le point de terminaison de service Azure Cosmos DB sur le sous-réseau public.
b. Assurez-vous d’avoir activé Autoriser l’accès à partir du portail Azure. Ce paramètre vous permet d’accéder à votre compte Azure Cosmos DB à partir du portail Azure. Si cette option est définie sur Deny, vous recevrez des erreurs si vous tentez d’accéder à votre compte.
Notes
Ce n’est pas nécessaire pour ce tutoriel, mais vous pouvez également activer Autoriser l’accès à partir de mon adresse IP si vous souhaitez pouvoir accéder à votre compte Azure Cosmos DB à partir de votre ordinateur local. Par exemple, si vous vous connectez à votre compte à l’aide du kit de développement logiciel (SDK) Azure Cosmos DB, vous devez activer ce paramètre. S’il est désactivé, vous recevrez des erreurs « Accès refusé ».
Sélectionnez Vérifier + Créer, puis Créer pour créer votre compte Azure Cosmos DB à l’intérieur du réseau virtuel.
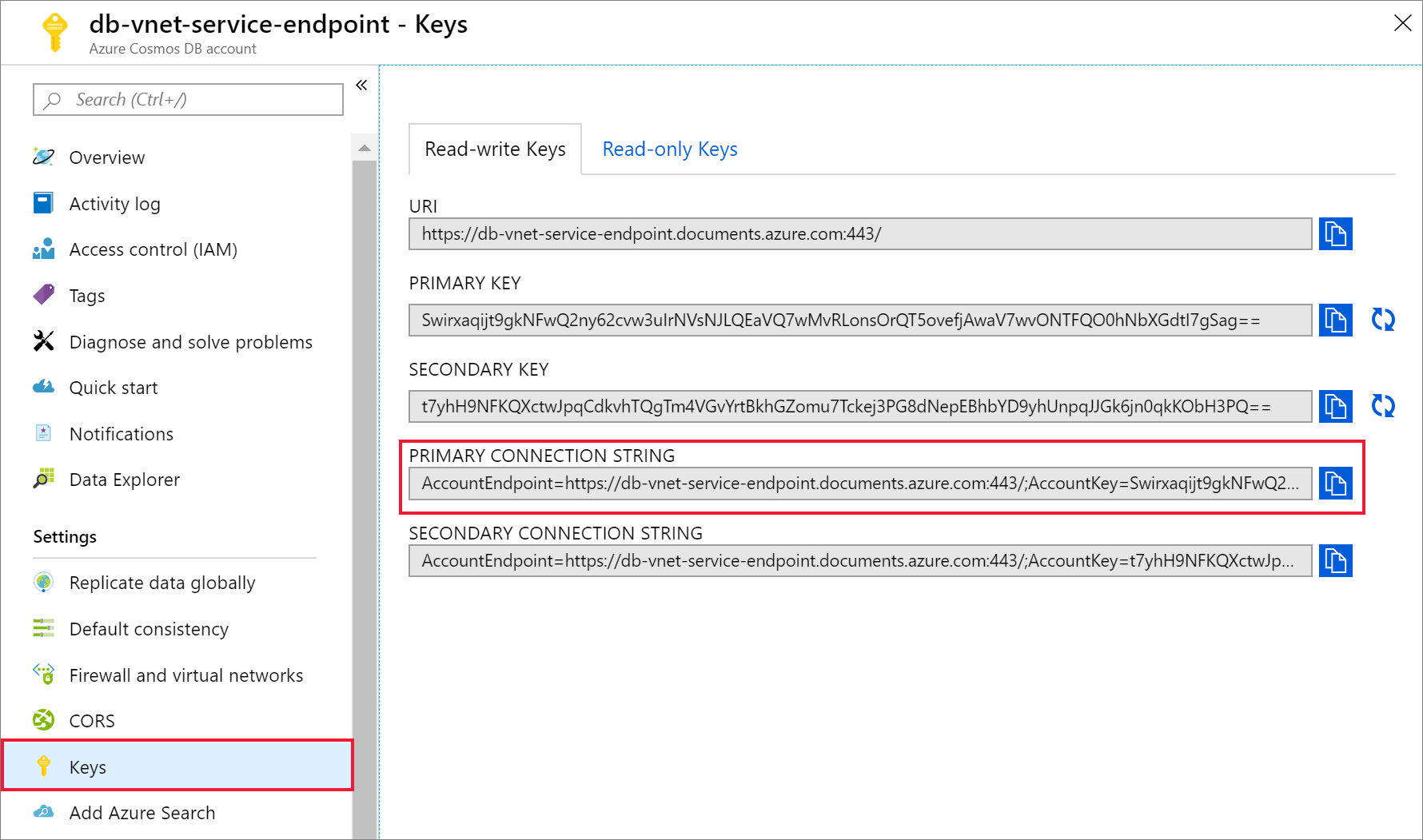
Une fois votre compte Azure Cosmos DB créé, accédez à Clés sous Paramètres. Copiez la chaîne de connexion principale et enregistrez-la dans un éditeur de texte pour une utilisation ultérieure.
Sélectionnez Data Explorer et Nouveau conteneur pour ajouter une base de données et un conteneur à votre compte Azure Cosmos DB.
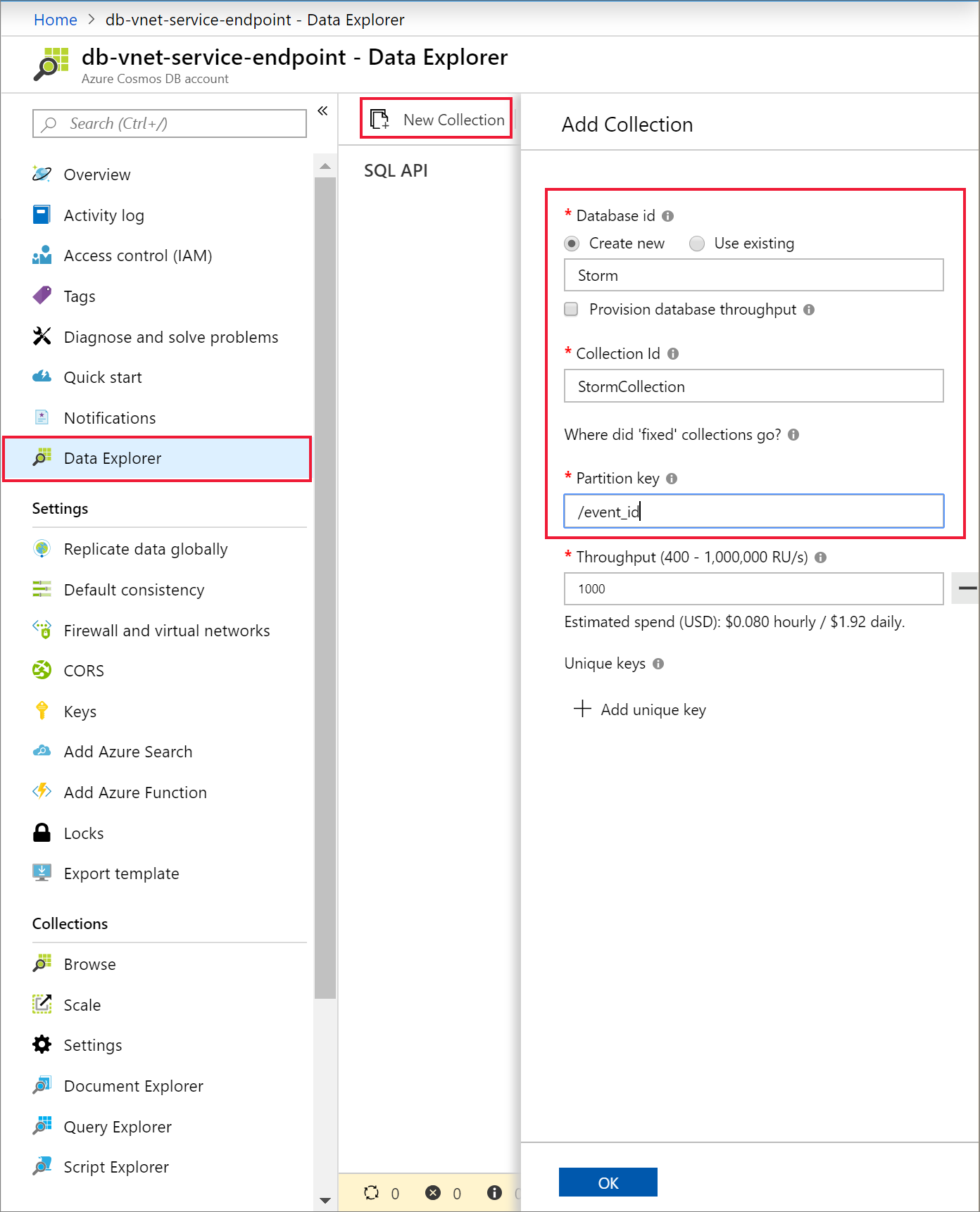
Charger des données dans Azure Cosmos DB
Ouvrez la version d’interface graphique de l’outil de migration de données pour Azure Cosmos DB, Dtui.exe.
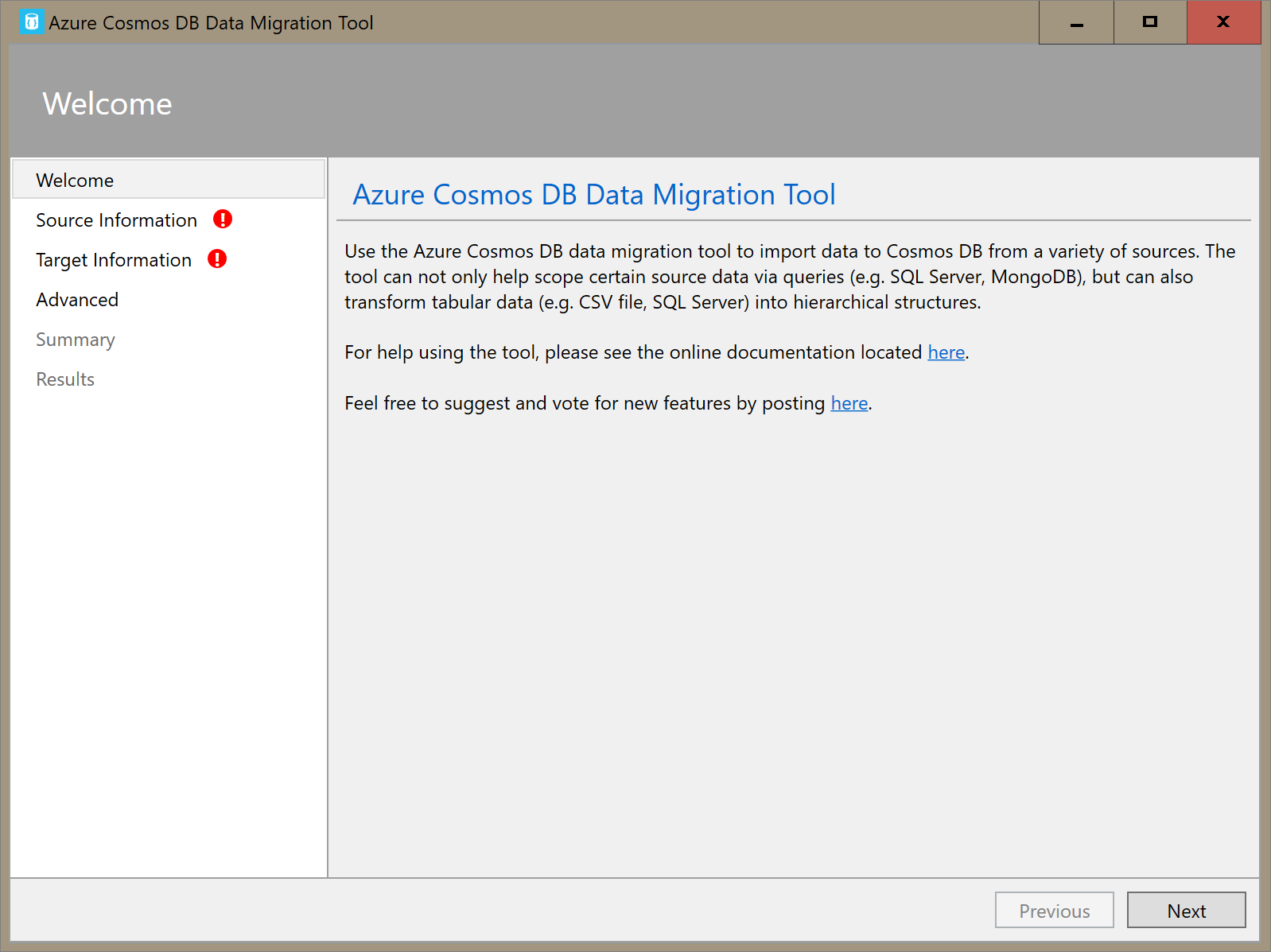
Sur l’onglet Informations sources, sélectionnez Fichier(s) CSV dans la liste déroulante Importer à partir de. Sélectionnez ensuite Ajouter des fichiers et ajoutez les données de tempête CSV que vous avez téléchargées comme condition préalable.
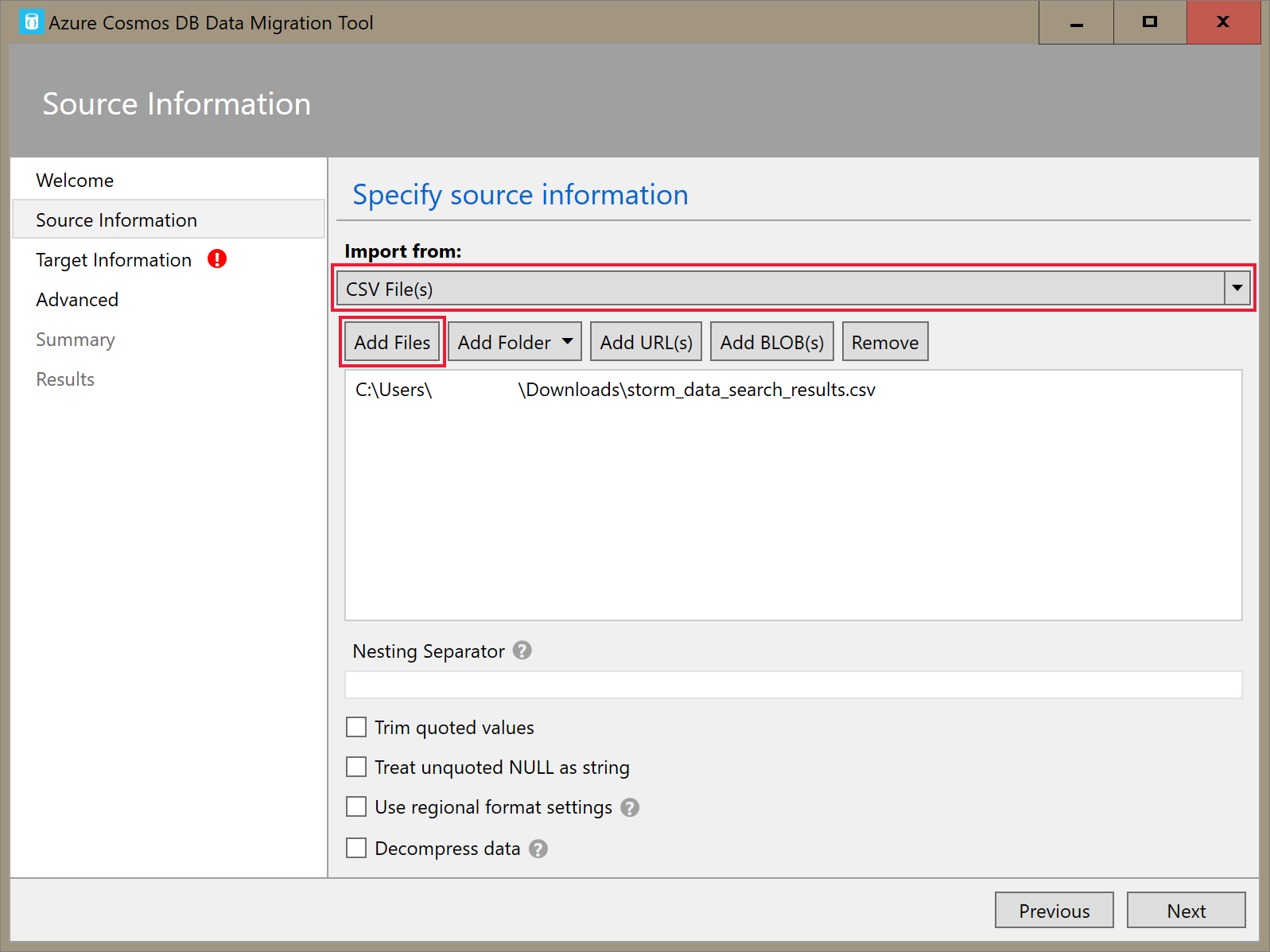
Sur l’onglet Informations cibles, entrez votre chaîne de connexion. Le format de chaîne de connexion est
AccountEndpoint=<URL>;AccountKey=<key>;Database=<database>. AccountEndpoint et AccountKey sont inclus dans la chaîne de connexion principale que vous avez enregistrée dans la section précédente. AjoutezDatabase=<your database name>à la fin de la chaîne de connexion, puis sélectionnez Vérifier. Ensuite, ajoutez le nom du conteneur et la clé de partition.
Sélectionnez Suivant jusqu’à ce que vous atteigniez la section Résumé. Ensuite, sélectionnez Importer.
Créer un cluster et ajouter une bibliothèque
Accédez à votre service Azure Databricks dans le portail Azure et sélectionnez Initialiser l’espace de travail.
Créez un cluster. Choisissez un nom de cluster et acceptez les paramètres par défaut restants.
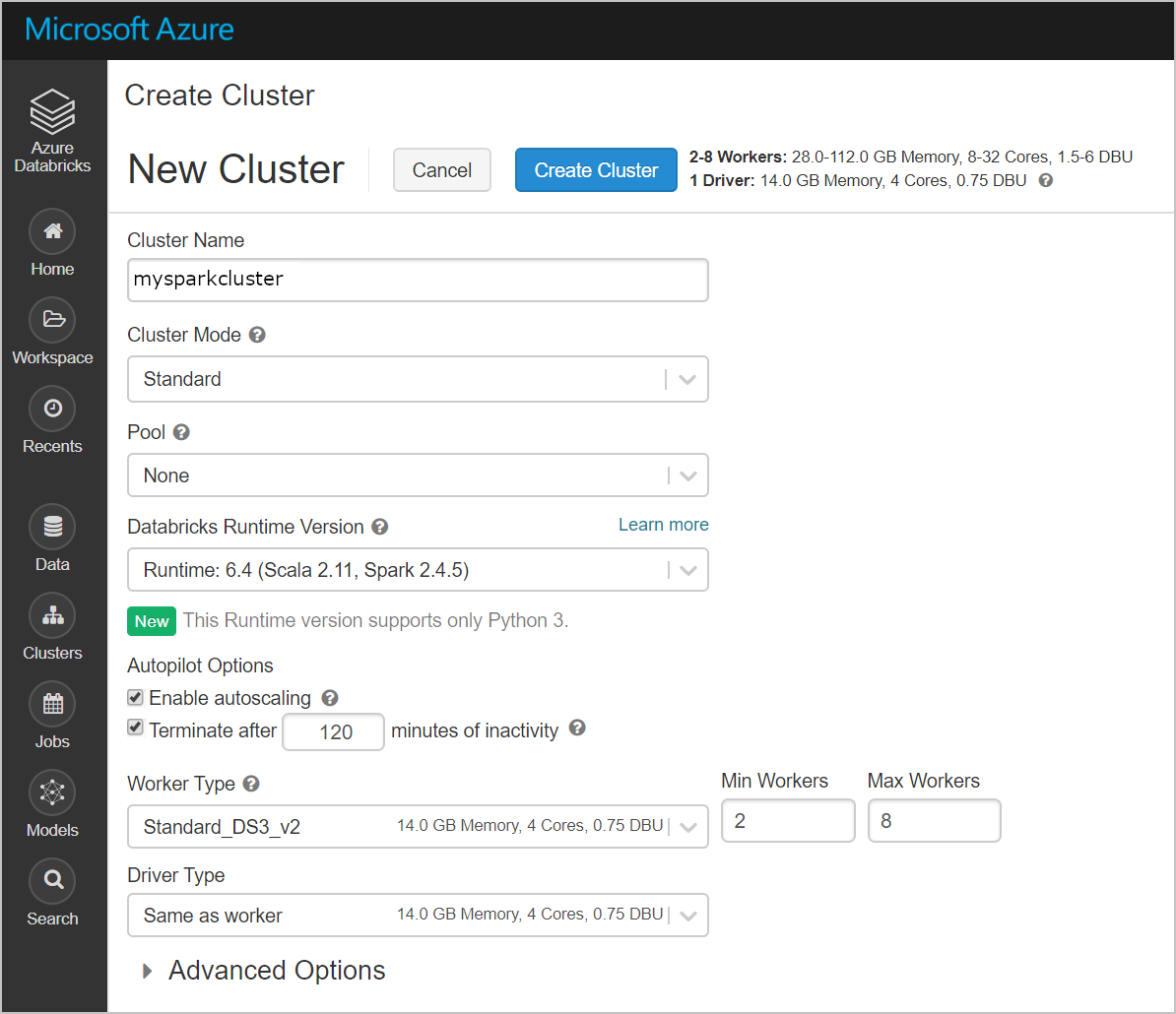
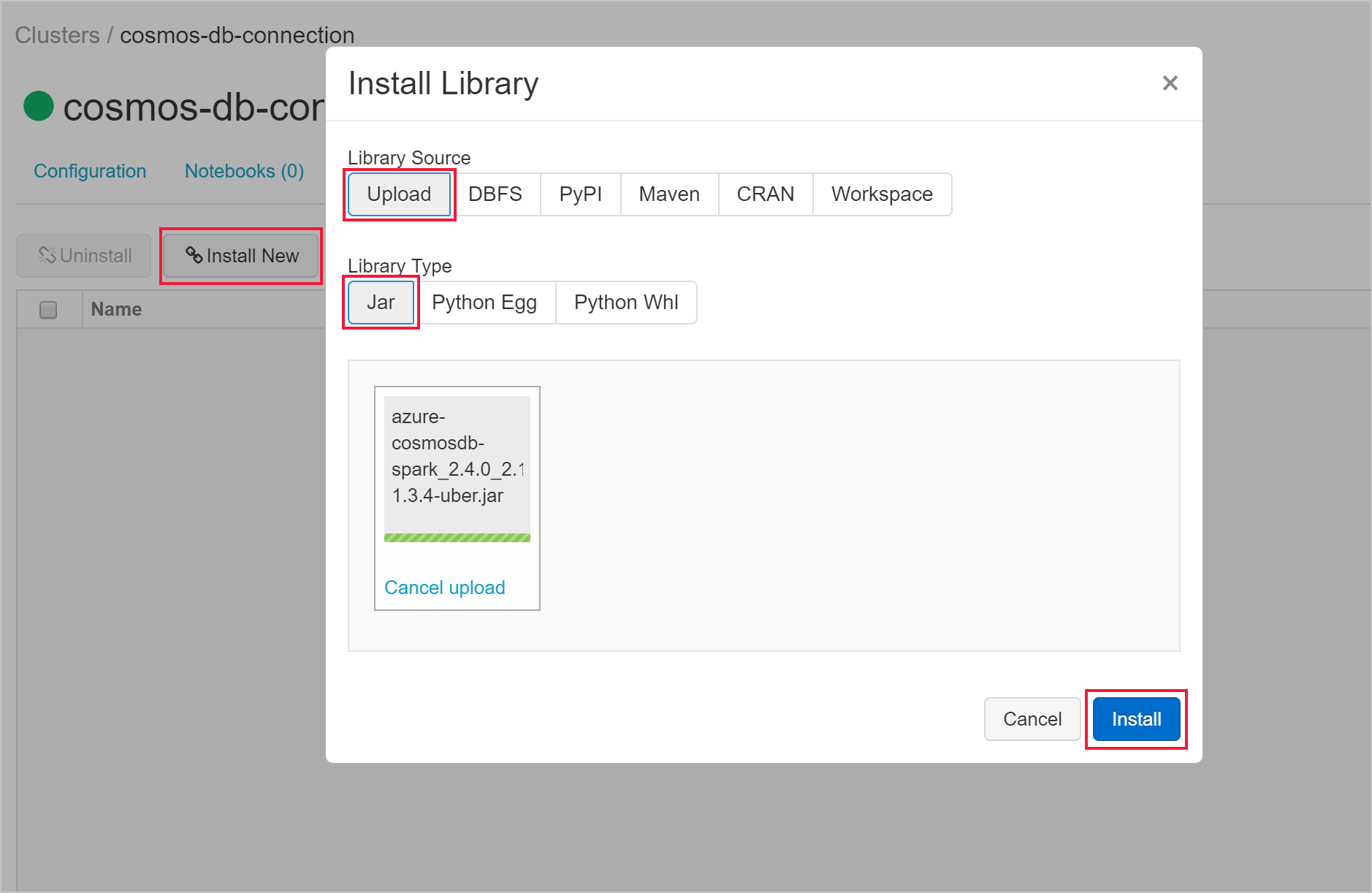
Une fois votre cluster créé, accédez à la page du cluster et sélectionnez l’onglet Bibliothèques. Sélectionnez Installer nouveau et chargez le fichier jar du connecteur Spark pour installer la bibliothèque.
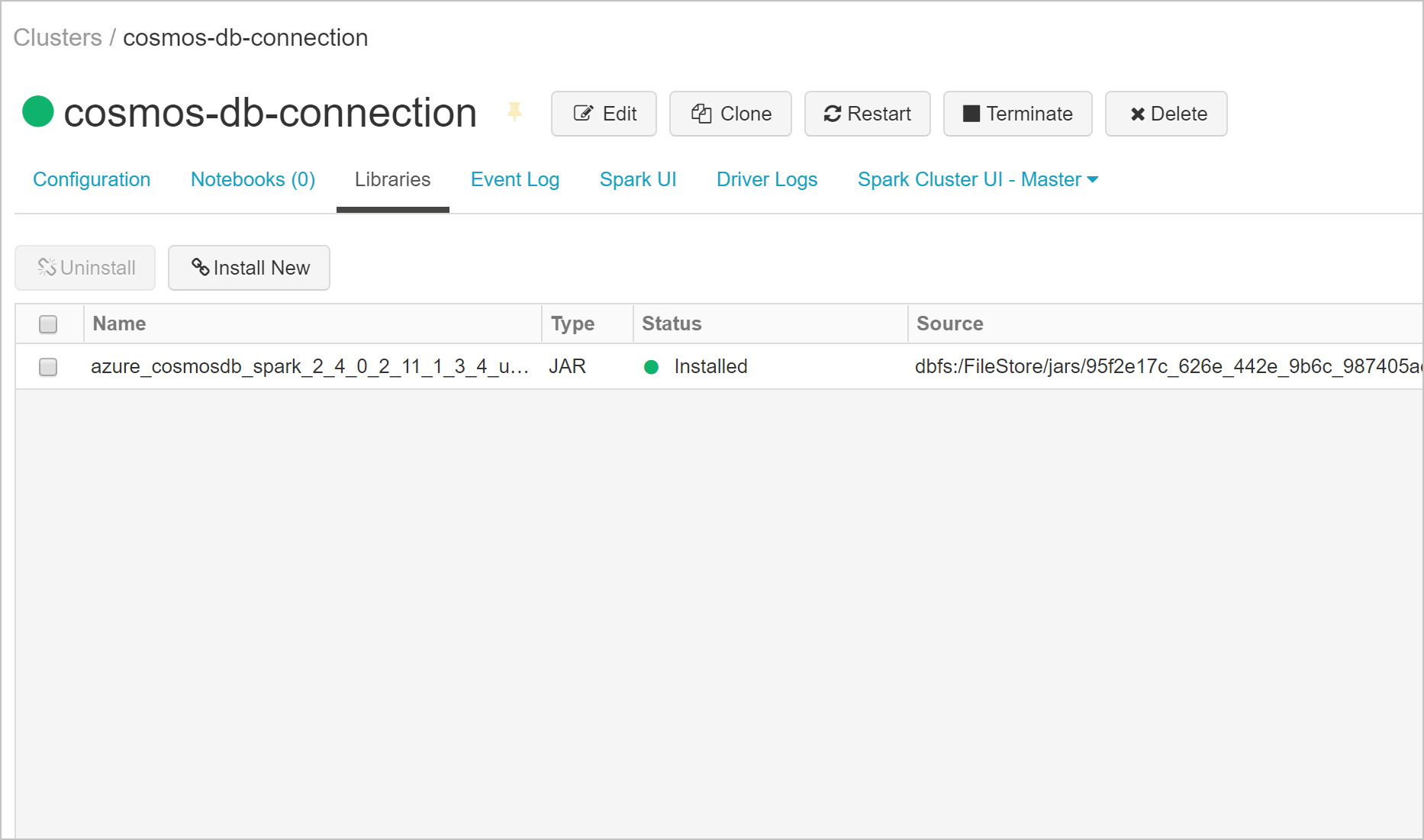
Vous pouvez vérifier que la bibliothèque a été installée sur l’onglet Bibliothèques.
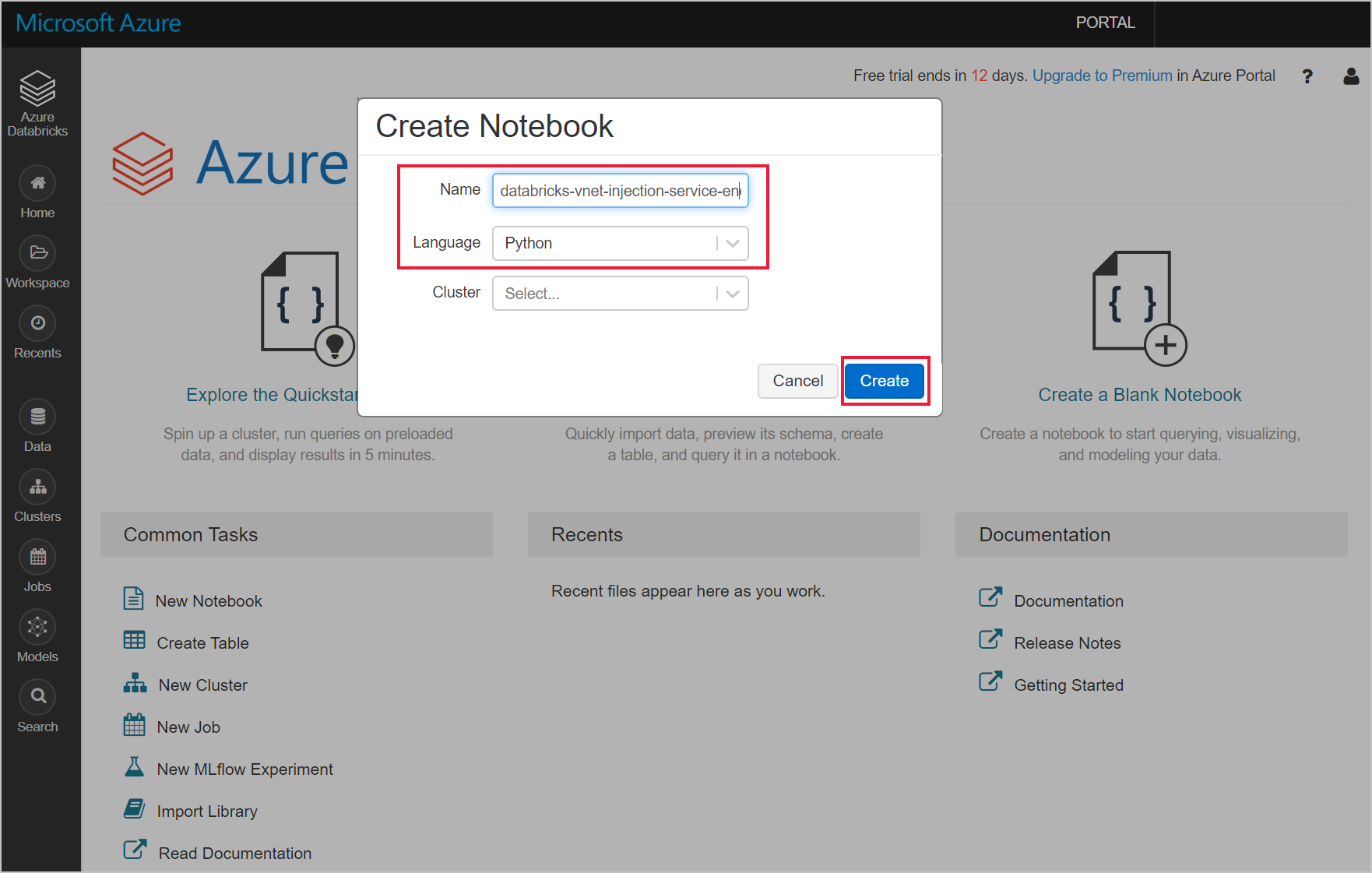
Interroger Azure Cosmos DB à partir d’un notebook Databricks
Accédez à votre espace de travail Azure Databricks et créez une bibliothèque python.
Exécutez le code Python suivant pour définir la configuration de connexion Azure Cosmos DB. Changez Point de terminaison, Masterkey, Base de données et Conteneur en conséquence.
connectionConfig = { "Endpoint" : "https://<your Azure Cosmos DB account name.documents.azure.com:443/", "Masterkey" : "<your Azure Cosmos DB primary key>", "Database" : "<your database name>", "preferredRegions" : "West US 2", "Container": "<your container name>", "schema_samplesize" : "1000", "query_pagesize" : "200000", "query_custom" : "SELECT * FROM c" }Utilisez le code python suivant pour charger les données et créer un affichage temporaire.
users = spark.read.format("com.microsoft.azure.cosmosdb.spark").options(**connectionConfig).load() users.createOrReplaceTempView("storm")Utilisez la commande magic suivante pour exécuter une instruction SQL qui retourne des données.
%sql select * from stormVous avez correctement connecté votre espace de travail Databricks injecté dans un réseau virtuel à une ressource Azure Cosmos DB avec point de terminaison de service. Pour en savoir plus sur la connexion à Azure Cosmos DB, consultez Connecteur Azure Cosmos DB pour Apache Spark.
Nettoyer les ressources
Lorsque vous n’en avez plus besoin, supprimez le groupe de ressources, l’espace de travail Azure Databricks et toutes les ressources associées. La suppression du travail évite une facturation inutile. Si vous avez l’intention d’utiliser l’espace de travail Azure Databricks à l’avenir, vous pouvez arrêter le cluster et le redémarrer ultérieurement. Si vous ne pensez pas continuer à utiliser cet espace de travail Azure Databricks, supprimez toutes les ressources créées au cours de ce tutoriel en procédant comme suit :
Dans le menu de gauche du portail Azure, cliquez sur Groupes de ressources, puis sur le nom de ressources que vous avez créé.
Sur la page de votre groupe de ressources, sélectionnez Supprimer, saisissez le nom de la ressource à supprimer dans la zone de texte, puis sélectionnez à nouveau Supprimer.
Étapes suivantes
Dans ce tutoriel, vous avez déployé un espace de travail Azure Databricks sur un réseau virtuel et utilisé le connecteur Spark Azure Cosmos DB pour interroger des données Azure Cosmos DB à partir de Databricks. Pour en savoir plus sur l’utilisation d’Azure Databricks dans un réseau virtuel, passez au tutoriel d’utilisation de SQL Server avec Azure Databricks.