La géoréplication active
S’applique à ![]() Azure SQL Database
Azure SQL Database
La géoréplication active est une fonctionnalité qui vous permet de créer une base de données secondaire accessible en lecture et synchronisée en continu pour une base de données primaire. La base de données secondaire accessible en lecture peut être dans la même région Azure que la base de données primaire, ou, plus communément, dans une autre région. Ce type de base de données secondaire accessible en lecture est également appelé géosecondaire ou géoréplica.
La géoréplication active est configurée par base de données et ne prend en charge que le basculement manuel. Pour basculer sur un groupe de bases de données, ou si votre application nécessite un point de terminaison de connexion stable, envisagez plutôt des groupes de basculement.
Vous pouvez également utiliser Effectuer une migration SQL Database avec la géoréplication active.
Vue d’ensemble
La géoréplication active est conçue comme une solution de continuité d'activité. La géoréplication active vous permet d'effectuer une récupération d'urgence rapide des bases de données individuelles en cas de sinistre régional ou de panne à grande échelle. Une fois la géoréplication configurée, vous pouvez lancer un basculement géographique vers une zone géographique secondaire dans une autre région Azure. Le géo-basculement est initié par programme par l’application ou manuellement par l’utilisateur.
Le diagramme suivant illustre la configuration standard d’une application cloud géoredondante avec la géoréplication active.
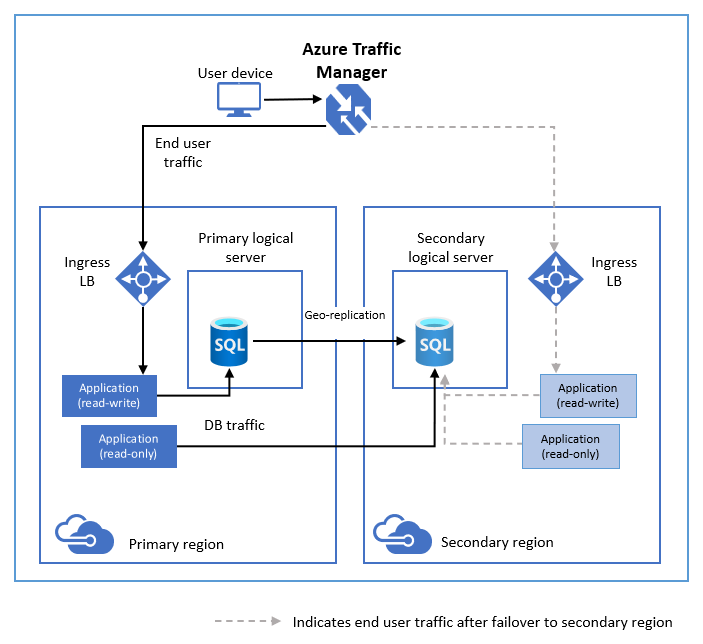
Si, pour une raison quelconque, votre base de données primaire échoue, vous pouvez lancer un basculement géographique vers l’une de vos bases de données secondaires. Quand une base de données secondaire est promue au rôle principal, tous les autres réplicas secondaires sont automatiquement liés à la nouvelle base de données primaire.
Vous pouvez gérer la géoréplication et initier un basculement géographique à l'aide de l'une des méthodes suivantes :
- Portail Azure
- PowerShell : base de données unique
- PowerShell : pool élastique
- Transact-SQL : base de données unique ou pool élastique
- API REST : base de données unique
La géoréplication active utilise la technologie du Groupe de disponibilité Always On pour répliquer de manière asynchrone le journal des transactions généré sur le réplica principal vers toutes les réplicas de zone géographique. À un moment donné, une base de données secondaire peut être légèrement en retard sur la base de données primaire, mais les données secondaires restent cohérentes au niveau transactionnel. En d'autres termes, les modifications effectuées par les transactions non validées ne sont pas visibles.
Remarque
La géoréplication active réplique les modifications en diffusant le journal des transactions de la base de données du réplica principal vers les réplicas secondaires. Elle n’est pas liée à la réplication transactionnelle, qui réplique les modifications en exécutant des commandes DML (INSERT, UPDATE, DELETE) sur les abonnés.
La géoréplication fournit une redondance régionale. La redondance entre régions permet aux applications de récupérer rapidement d'une perte permanente d'une région Azure entière, ou d'une partie d'une région, résultant de catastrophes naturelles, de graves erreurs humaines ou d'actes de malveillance. Le RPO de géoréplication se trouve dans la Vue d’ensemble de la continuité des activités.
La figure suivante présente un exemple de géoréplication active configurée avec une base de données primaire située dans la région USA Centre Nord, ainsi qu’une base de données géosecondaire située dans la région USA Centre Sud.

En plus de la récupération d’urgence, la géoréplication active peut être utilisée dans les scénarios suivants :
- Migration de base de données : vous pouvez vous servir de la géoréplication active pour migrer une base de données d’un serveur vers un autre serveur avec un temps d’arrêt minimal.
- Mises à niveau de l’application : vous pouvez créer une base de données secondaire supplémentaire faisant office de copie de restauration automatique lors des mises à niveau de l’application.
Pour arriver à une continuité d’activité totale, l’ajout d’une redondance régionale de base de données n’est qu’une partie de la solution. La récupération d’une application (service) de bout en bout après une défaillance catastrophique implique la récupération de tous les composants constituant le service et tous les services dépendants. En voici quelques exemples : logiciel client (il peut s’agir par exemple d’un navigateur avec un code JavaScript personnalisé), serveurs web frontaux, ressources de stockage et DNS. Il est essentiel que tous les composants résistent aux mêmes défaillances et redeviennent disponibles dans l'objectif de délai de récupération (RTO) de votre application. Par conséquent, vous devez identifier tous les services dépendants et comprendre les garanties et les fonctionnalités qu’ils fournissent. Ensuite, vous devez prendre les mesures appropriées pour vous assurer que votre service fonctionne pendant le basculement des services dont il dépend. Pour plus d’informations sur la conception de solutions pour la récupération d’urgence, consultez la page Designing Cloud Solutions for Disaster Recovery Using active geo-replication (Conception de solutions cloud pour la récupération d’urgence à l’aide de la géo-réplication active).
Terminologie et fonctionnalités associées à la géoréplication active
Réplication asynchrone automatique
Vous pouvez uniquement créer une zone géographique secondaire pour une base de données existante. La zone géosecondaire peut être créée sur n’importe quel serveur logique, autre que le serveur avec la base de données primaire. Une fois créé, le géo-réplica est rempli avec les données de la base de données primaire. Ce processus est appelé amorçage. Une fois la base de données géosecondaire créée et amorcée, les mises à jour de la base de données primaire sont automatiquement répliquées de manière asynchrone sur le géo-réplica. La réplication asynchrone signifie que les transactions sont validées sur la base de données primaire avant leur réplication.
Accès en lecture aux réplicas géosecondaires
Une application peut accéder à un géo-réplica pour exécuter des requêtes en lecture seule avec des principaux de sécurité identiques ou différents de ceux utilisés pour accéder à la base de données primaire. Pour plus d’informations, consultez Utiliser des réplicas en lecture seule pour décharger des charges de travail de requêtes en lecture seule.
Important
Vous pouvez utiliser la géoréplication pour créer des réplicas secondaires dans la même région que la base de données primaire. Vous pouvez utiliser ces réplicas secondaires pour répondre aux scénarios d’échelle horizontale en lecture dans la même région. Toutefois, un réplica secondaire dans la même région ne fournit pas de résilience supplémentaire aux défaillances catastrophiques ou aux pannes à grande échelle, et n’est donc pas une cible de basculement appropriée à des fins de récupération d’urgence. De même,il ne garantit en rien l’isolation de la zone de disponibilité. Utilisez le niveau de service Critique pour l’entreprise ou Premium avec une configuration de zone redondante ou le niveau de service Usage général avec une configuration de zone redondante pour isoler la zone de disponibilité.
Basculement (aucune perte de données)
Le basculement bascule les rôles des bases de données primaires et géo-secondaires après avoir terminé la synchronisation complète des données afin d’éviter toute perte de données. La durée du basculement dépend de la taille du journal des transactions sur la base de données primaire qui doit être synchronisée avec la base géo-secondaire. Le basculement est conçu pour les scénarios suivants :
- Simuler des récupérations d’urgence (DR) en production lorsque la perte de données n’est pas acceptable
- Déplacer les bases de données vers une autre région
- Renvoyer les bases de données vers la région primaire une fois la panne éliminée (restauration automatique).
Basculement forcé (perte de données potentielle)
Un basculement forcé fait immédiatement basculer la base de données géosecondaire vers le rôle primaire sans attendre une synchronisation avec la base de données primaire. Toutes les transactions validées sur la base de données primaire qui ne sont pas répliquées sur la base de données secondaire sont perdues. Cette opération est conçue comme une méthode de récupération pendant les pannes lorsque le serveur principal n'est pas accessible, mais que la disponibilité de la base de données doit être restaurée rapidement. Lorsque le primaire d’origine est de nouveau en ligne, il est automatiquement reconnecté, réensemencé en utilisant les données actuelles du primaire, et devient le nouveau géo-secondaire.
Important
Après un basculement forcé, le point de terminaison de connexion de la base de données principale est modifié, car le nouveau réplica principal est maintenant situé sur un autre serveur logique.
Bases de données géosecondaires accessibles en lecture
Jusqu’à quatre zones géographiques secondaires peuvent être créées pour une base de données primaire. S'il n'existe qu'une seule base de données secondaire, en cas d'échec de celle-ci, l'application est exposée à un risque plus élevé jusqu'à la création d'une nouvelle base de données secondaire. S’il existe plusieurs bases de données secondaires, l’application reste protégée même en cas d’échec de l’une des bases de données secondaires. Des bases de données secondaires supplémentaires peuvent également être utilisées pour effectuer un scale-out des charges de travail en lecture seule.
Conseil
Si vous utilisez la géoréplication active pour créer une application mondialement distribuée et que vous avez besoin de fournir un accès en lecture seule aux données dans plus de quatre régions, vous pouvez créer une base de données secondaire pour une base de données secondaire (processus connu sous le nom de chaînage), afin de créer des géo-réplicas supplémentaires. Le décalage de réplication sur les réplicas de zone géographique enchaînés peut être plus important que sur les réplicas de zone géographique connectés directement au réplica principal. La configuration des topologies de géoréplication chaînée est prise en charge uniquement par programme, et non à partir du Portail Azure.
Géoréplication des bases de données dans un pool élastique
Chaque base de données géosecondaire peut être une base de données autonome ou une base de données dans un pool élastique. Le choix du pool élastique pour chaque base de données secondaire de zone géographique est distinct et ne dépend pas de la configuration d'un autre réplica dans la topologie (qu'il soit principal ou secondaire). Chaque pool élastique est contenu dans un serveur logique unique. Étant donné que les noms de bases de données sur un serveur logique doivent être uniques, plusieurs géo-réplicas de la même base de données primaire ne peuvent jamais partager un pool élastique.
Géo-basculement et restauration automatique contrôlés par l’utilisateur
Une base de données géosecondaire qui a terminé l’amorçage initial peut être explicitement basculée vers le rôle principal à tout moment par l’application ou par l’utilisateur. Lors d’une panne où le serveur principal est inaccessible, seul le basculement forcé peut être utilisé, ce qui promeut immédiatement un géo-secondaire comme étant le nouveau primaire. Lorsque la panne est atténuée, le système définit automatiquement le serveur principal récupéré comme géo-secondaire et le met à jour avec le nouveau réplica principal. En raison de la nature asynchrone de la géoréplication, des transactions récentes peuvent être perdues lors de basculements forcés si le réplica principal est défaillant avant que ces transactions ne soient répliquées sur un réplica secondaire de zone géograpgique. Quand une base de données primaire avec plusieurs géo-réplicas bascule, le système reconfigure automatiquement les relations de réplication et lie les bases de données géosecondaires restantes à la base de données nouvellement promue comme primaire sans aucune intervention de l’utilisateur. Une fois que la panne à l'origine du basculement géographique a été résolue, il peut être souhaitable de renvoyer le réplica principal dans sa région d'origine. Pour ce faire, effectuez un basculement manuel.
Réplica en attente
Si votre réplica secondaire n'est utilisé que pour la récupération d'urgence (DR) et n'a pas de charge de travail en lecture ou en écriture, vous pouvez désigner le réplica comme étant en attente afin de réduire les coûts de licence.
Préparer le géo-basculement
Pour vous assurer que votre application peut accéder immédiatement au nouveau réplica principal après le géo-basculement, assurez-vous que l’authentification et l’accès réseau de votre serveur secondaire sont correctement configurés. Pour plus d’informations, consultez Gestion de la sécurité de la base de données SQL Azure après la récupération d’urgence. Vérifiez également que la stratégie de rétention de sauvegarde sur la base de données secondaire correspond à celle du réplica principal. Ce paramètre ne fait pas partie de la base de données et n'est pas répliqué à partir du serveur principal. Par défaut, le géo-réplica est configuré avec une période de rétention de récupération jusqu’à une date et heure par défaut de sept jours. Pour plus d’informations, consultez Sauvegardes automatisées d’une base de données SQL.
Important
Si votre base de données est membre d'un groupe de basculement, vous ne pouvez pas lancer son basculement à l'aide de la commande de basculement de la géoréplication. Utilisez la commande de basculement du groupe. Pour basculer une base de données individuelle, vous devez d'abord la supprimer du groupe de basculement. Pour plus d’informations, consultez Groupes de basculement.
Configurer la base de données géosecondaire
Les réplicas principal et secondaire de zone géographique doivent offrir le même niveau de service. Il est également vivement recommandé de configurer la base de données géosecondaire avec les mêmes redondance de stockage de sauvegarde, niveau de calcul (provisionné ou serverless) et taille de calcul (DTU ou vCores) que la base de données primaire. Si le réplica principal est soumis à une charge de travail importante en écriture, un réplica secondaire de zone géographique ayant une taille de calcul inférieure pourrait ne pas être en mesure de suivre. Cette situation entraîne un décalage de réplication sur le réplica secondaire de zone géographique et peut éventuellement entraîner l'indisponibilité du réplica secondaire de zone géographique. Pour atténuer ces risques, la géoréplication active réduit si nécessaire le taux de journalisation des transactions de la base de données primaire pour permettre à ses bases de données secondaires de rattraper le retard.
Une autre conséquence d'une configuration de réplica secondaire de zone géographique déséquilibrée est qu'après le basculement, les performances de l'application peuvent être affectées en raison de la capacité de calcul insuffisante du nouveau réplica principal. Dans ce cas, il est nécessaire d'effectuer un scale-up de la base de données pour disposer de ressources suffisantes, ce qui peut prendre beaucoup de temps et nécessite un basculement à haute disponibilité à la fin du processus de scale-up, ce qui peut interrompre les charges de travail de l'application.
Si vous décidez de créer le géo-réplica avec une configuration différente, vous devez surveiller le taux d'E/S de journal sur le serveur principal dans le temps. Cela vous permet d’estimer la taille de calcul minimale du géo-réplica requis pour supporter la charge de réplication. Par exemple, si votre base de données primaire est P6 (1 000 DTU) et si son taux d’E/S du journal est maintenu à 50 %, la base de données géosecondaire doit être au moins P4 (500 DTU). Pour récupérer les données d’E/S historiques du journal, utilisez la vue sys.resource_stats. Pour récupérer les données d’E/S récentes dans le journal avec une granularité plus élevée qui reflète mieux les pics à court terme, utilisez la vue sys.dm_db_resource_stats.
Conseil
La limitation du nombre d’E/S de journalisation des transactions sur la base de données primaire en raison d’une réduction de la taille de calcul sur une base de données géosecondaire est signalée à l’aide du type d’attente HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO, visible dans les vues de base de données sys.dm_exec_requests et sys.dm_os_wait_stats.
Les entrées-sorties du journal des transactions sur le réplica principal peuvent être limitées pour des raisons indépendantes d'une taille de calcul plus faible sur un réplica secondaire de zone géographique. Ce genre de limitation peut se produire même si le réplica secondaire de zone géographique a une taille de calcul identique ou supérieure à celle du réplica principal. Pour plus d’informations, notamment sur les types d’attente pour les différents genres de limitation de nombre d’E/S de journalisation, consultez Gouvernance relative au taux de journalisation des transactions.
Par défaut, la redondance de stockage de sauvegarde de la base de données géosecondaire est identique à celle de la base de données primaire. Vous pouvez configurer la base de données géosecondaire avec une redondance de stockage de sauvegarde différente. Les sauvegardes sont toujours effectuées sur la base de données primaire. Si la base de données secondaire est configurée avec une redondance de stockage de sauvegarde différente, après le géo-basculement effectué lors de la promotion de la base de données secondaire en base de données primaire, les nouvelles sauvegardes sont stockées et facturées en fonction du type de stockage (RA-GRS, ZRS, LRS) sélectionné sur la nouvelle base de données primaire (ancienne secondaire).
Réduire les coûts avec le réplica en attente
Si votre réplica secondaire n'est utilisé que pour la récupération d'urgence (DR) et n'a pas de charge de travail en lecture ou en écriture, vous pouvez réduire les coûts de licence en désignant la base de données comme base de données en attente lorsque vous configurez une nouvelle relation de géoréplication active.
Pour en savoir plus, reportez-vous au réplica en attente sans licence.
Géoréplication entre abonnements
Utilisez Transact-SQL (T-SQL) pour créer un réplica secondaire de zone géographique dans un abonnement différent de l'abonnement du réplica principal (que ce soit sous le même client de Microsoft Entra ID (anciennement Azure Active Directory) ou non). Pour en savoir plus, reportez-vous à Configurer la géoréplication active.
Synchronisation des informations d’identification et des règles de pare-feu
Lorsque vous utilisez un accès réseau public pour la connexion à la base de données, nous vous recommandons d’utiliser des règles de pare-feu IP au niveau de la base de données pour les bases de données géo-répliquées. Ces règles sont répliquées avec la base de données, ce qui garantit que toutes les bases de données géosecondaires ont les mêmes règles de pare-feu IP que la base de données primaire. Cette approche évite aux clients de devoir configurer et tenir à jour manuellement les règles de pare-feu sur les serveurs hébergeant les bases de données primaire et secondaires. De même, l’utilisation des utilisateurs de base de données autonome pour l’accès aux données garantit que les bases de données primaires et secondaires ont toujours les mêmes informations d’identification d’authentification. Ainsi, après un géobasculement, il n’y a pas d’interruption due à une non-concordance des informations d’identification de l’authentification. Si vous utilisez des identifiants de connexion et des utilisateurs (et non des utilisateurs contenus), vous devez prendre des mesures supplémentaires pour vous assurer que les mêmes identifiants de connexion existent dans la base de données secondaire. Pour plus d’informations sur la configuration, consultez Comment configurer les connexions et les utilisateurs.
Mettre à l’échelle une base de données primaire
Vous pouvez effectuer un scale-up/down sur une base de données primaire avec une taille de calcul différente (au sein du même niveau de service) sans déconnecter les bases de données géosecondaires. Lors du scale-up, nous vous recommandons de commencer par la base de données géosecondaire, puis de terminer avec la base de données primaire. Lors du scale-down, inversez l’ordre : commencez par la base de données primaire, puis terminez par la base de données secondaire.
Notes
Si vous avez créé une base de données géosecondaire dans le cadre de la configuration du groupe de basculement, il n’est pas recommandé d’effectuer un scale-down dessus. En effet, votre couche Données pourrait manquer de capacité pour traiter votre charge de travail normale après un géo-basculement.
Important
Pour permettre la mise à l’échelle vers le niveau de service supérieur (édition) d’une base de données primaire dans un groupe de basculement, la base de données secondaire doit avoir été préalablement mise à l’échelle vers le niveau supérieur. Par exemple, si vous souhaitez mettre à l’échelle la base de données principale de Usage général vers Critique pour l’entreprise, vous devez d’abord mettre à l’échelle la base de données géosecondaire vers Critique pour l’entreprise. Si vous essayez de mettre à l’échelle la base de données primaire ou géosecondaire d’une manière qui enfreint cette règle, vous recevez l’erreur suivante :
The source database 'Primaryserver.DBName' cannot have higher edition than the target database 'Secondaryserver.DBName'. Upgrade the edition on the target before upgrading the source.
Empêcher la perte de données critiques
En raison de la latence élevée des réseaux étendus, la géoréplication utilise un mécanisme de réplication asynchrone. La réplication asynchrone rend la possibilité de perte de données inévitable en cas de défaillance de la base de données primaire. Pour protéger les transactions critiques d’une perte de données, le développeur d’applications peut appeler la procédure stockée sp_wait_for_database_copy_sync immédiatement après la validation de la transaction. L’appel de sp_wait_for_database_copy_sync bloque le thread appelant jusqu’à ce que la dernière transaction validée ait été transmise et renforcée dans le journal des transactions de la base de données secondaire. Toutefois, il n’attend pas que les transactions transmises soient relues (réeffectuées) sur la base de données secondaire. sp_wait_for_database_copy_sync est limité à un lien de géoréplication spécifique. Tout utilisateur disposant de droits de connexion à la base de données primaire peut appeler cette procédure.
Notes
sp_wait_for_database_copy_sync empêche la perte de données après un géobasculement pour des transactions spécifiques, mais ne garantit pas une synchronisation complète pour l’accès en lecture. Le délai causé par un appel de procédure sp_wait_for_database_copy_sync peut être significatif et dépend de la taille du journal des transactions pas encore transmis à la base de données primaire au moment de l’appel.
Supervision du décalage de la géoréplication
Pour surveiller le décalage par rapport au RPO, utilisez la colonne replication_lag_sec de sys.dm_geo_replication_link_status sur la base de données primaire. Elle affiche le décalage en secondes entre les transactions validées sur la base de données primaire et les transactions renforcées dans le journal des transactions sur la base de données secondaire. Par exemple, si le retard est d’une seconde, cela signifie que si la base de données primaire est affectée par une panne à ce moment et qu’un géo-basculement est initié, les transactions validées au cours de la dernière seconde seront perdues.
Pour mesurer le décalage ayant trait aux modifications de la base de données primaire renforcées sur la base de données géosecondaire, comparez la valeur last_commit sur la base de données secondaire avec la même valeur sur la base de données primaire.
Conseil
Sur la base de données primaire, si replication_lag_sec présente une valeur NULL, cela signifie que la base de données primaire ne connaît pas précisément l’état de retard de la base de données géosecondaire. Cela se produit généralement après le redémarrage du processus et relève d'une situation temporaire. Envisagez d’envoyer une alerte si replication_lag_sec présente une valeur NULL pendant une période prolongée. Cette alerte peut indiquer que le réplica secondaire de zone géographique ne peut pas communiquer avec le réplica principal en raison d'une défaillance liée à la connectivité.
D’autres cas de figure peuvent aussi être à l’origine d’une importante différence de valeur last_commit entre les bases de données primaire et secondaire. Par exemple, si une validation intervient sur la base de données primaire après une longue période sans modifications, la différence augmente considérablement avant de redevenir rapidement nulle. Envisagez d’envoyer une alerte si la différence entre ces deux valeurs demeure importante pendant une période prolongée.
Gestion de la géoréplication active par programmation
Comme indiqué plus haut, la géoréplication active peut aussi être gérée par programmation à l’aide de T-SQL, d’Azure PowerShell et de l’API REST. Les tableaux ci-dessous décrivent l’ensemble des commandes disponibles. La géoréplication active comprend un ensemble d’API Azure Resource Manager pour la gestion, notamment l’API REST Azure SQL Database et les applets de commande Azure PowerShell. Ces API prennent en charge le contrôle d’accès en fonction du rôle Azure (Azure RBAC). Pour plus d’informations sur l’implémentation de rôles d’accès, consultez la page sur le contrôle d’accès en fonction du rôle Azure (RBAC Azure).
T-SQL : Gérer le géo-basculement des bases de données uniques et mises en pool
Important
Ces commandes T-SQL s’appliquent uniquement à la géoréplication active et ne s’appliquent pas aux groupes de basculement. Par conséquent, elles ne s’appliquent pas non plus à SQL Managed Instance, qui prend uniquement en charge les groupes de basculement.
| Commande | Description |
|---|---|
| ALTER DATABASE | Utilise l’argument ADD SECONDARY ON SERVER afin de créer une base de données secondaire pour une base de données existante puis lance la réplication des données |
| ALTER DATABASE | Utilise l’argument FAILOVER ou FORCE_FAILOVER_ALLOW_DATA_LOSS pour basculer d’une base de données secondaire à une base de données principale afin de lancer le basculement |
| ALTER DATABASE | Utilise l’argument REMOVE SECONDARY ON SERVER pour mettre fin à une réplication de données entre une base de données SQL et la base de données secondaire spécifiée. |
| sys.geo_replication_links | Retourne des informations concernant tous les liens de réplication existants pour chaque base de données sur un serveur. |
| sys.dm_geo_replication_link_status | Obtient l’heure de la dernière réplication, le dernier décalage de la réplication et d’autres informations sur le lien de réplication pour une base de données spécifique. |
| sys.dm_operation_status | Affiche l’état de toutes les opérations de base de données, y compris les modifications apportées aux liens de réplication. |
| sys.sp_wait_for_database_copy_sync | Entraîne l’attente de l’application jusqu’à ce que toutes les transactions validées soient renforcées dans le journal des transactions d’un géo-réplica. |
PowerShell : Gérer le géo-basculement des bases de données uniques et mises en pool
Notes
Cet article utilise le module Azure Az PowerShell, qui est le module PowerShell recommandé pour interagir avec Azure. Pour démarrer avec le module Az PowerShell, consulter Installer Azure PowerShell. Pour savoir comment migrer vers le module Az PowerShell, consultez Migrer Azure PowerShell depuis AzureRM vers Az.
Important
Le module PowerShell Azure Resource Manager est toujours pris en charge par Azure SQL Database, mais tous les développements futurs sont destinés au module Az.Sql. Pour ces cmdlets, voir AzureRM.Sql. Les arguments des commandes dans le module Az sont sensiblement identiques à ceux des modules AzureRm.
| Applet de commande | Description |
|---|---|
| Get-AzSqlDatabase | Obtient une ou plusieurs bases de données. |
| New-AzSqlDatabaseSecondary | Crée une base de données secondaire pour une base de données existante puis lance la réplication des données. |
| Set-AzSqlDatabaseSecondary | Bascule d’une base de données secondaire à une base de données principale afin de lancer le basculement. |
| Remove-AzSqlDatabaseSecondary | Met fin à une réplication de données entre une base de données SQL et la base de données secondaire spécifiée. |
| Get-AzSqlDatabaseReplicationLink | Obtient les liens de géoréplication pour une base de données. |
Conseil
Pour plus d’exemples de scripts, consultez Configurer et basculer une base de données unique à l’aide de la géoréplication active et Configurer et basculer une base de données mise en pool à l’aide de la géoréplication active.
API REST : Gérer le géo-basculement des bases de données uniques et mises en pool
| API | Description |
|---|---|
| .Créer ou mettre à jour la base de données (createMode=Restore) | Crée, met à jour ou restaure une base de données principale ou secondaire. |
| Créer ou mettre à jour l’état de la base de données | Retourne l’état durant une opération de création. |
| Définir la base de données secondaire comme principale (basculement planifié) | Définit la base de données secondaire principale via basculement à partir de la base de données primaire actuelle. Cette option n’est pas prise en charge pour SQL Managed Instance. |
| Définir la base de données secondaire comme principale (basculement non planifié) | Définit la base de données secondaire principale via basculement à partir de la base de données primaire actuelle. Cette opération peut entraîner une perte de données. Cette option n’est pas prise en charge pour SQL Managed Instance. |
| Obtenir un lien de réplication | Obtient un liens de réplication spécifique pour une base de données particulière dans un partenariat de géo-réplication. Récupère les informations visibles dans la vue de catalogue sys.geo_replication_links. Cette option n’est pas prise en charge pour SQL Managed Instance. |
| Liens de réplication - Liste par base de données | Obtient tous les liens de réplication pour une base de données donnée dans un partenariat de géo-réplication. Récupère les informations visibles dans la vue de catalogue sys.geo_replication_links. |
| Supprimer un lien de réplication | Supprime un lien de réplication de base de données. Opération impossible pendant le basculement. |
Étapes suivantes
- Pour obtenir des exemples de scripts, consultez :
- SQL Database prend également en charge les groupes de basculement. Pour plus d’informations, voir la section sur l’utilisation des Groupes de basculement.
- Pour une vue d’ensemble de la continuité des activités et des scénarios, consultez Vue d’ensemble de la continuité des activités.
- Réduisez les coûts de licence en désignant votre réplica DR secondaire comme réplica en attente.
- Pour en savoir plus sur la géoréplication Azure SQL Database Hyperscale, consultez Géoréplica Hyperscale
- Pour en savoir plus sur les sauvegardes automatisées d’une base de données Azure SQL, consultez Sauvegardes automatisées d’une base de données SQL.
- Pour en savoir plus sur l’utilisation des sauvegardes automatisées pour la récupération, consultez Restaurer une base de données à partir des sauvegardes initiées par le service.
- Pour en savoir plus sur les exigences d’authentification pour de nouveaux serveurs et bases de données primaires, consultez Gestion de la sécurité de la base de données SQL Azure après la récupération d’urgence.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour