Présentation du modèle d’achat DTU
S’applique à ![]() Azure SQL Database
Azure SQL Database
Dans cet article, vous allez découvrir le modèle d’achat DTU pour Azure SQL Database.
Pour plus d’informations, consultez Modèle d’achat vCore et Comparer les modèles d’achat.
Unités de transaction de base de données (DTU)
L’unité de transaction de base de données (DTU) correspond à un mélange de mesures d’UC, de mémoire, de lectures et d’écritures. Les niveaux de service du modèle d’achat DTU se distinguent par leur plage de tailles de calcul ayant une quantité fixe de stockage inclus, une période de conservation fixe des sauvegardes, ainsi qu’un prix fixe. Tous les niveaux de service utilisant le modèle d’achat DTU offrent la flexibilité nécessaire pour modifier les tailles de calcul avec un temps d’arrêt minimal. Toutefois, il existe un délai de basculement durant lequel la connectivité à la base de données est perdue pendant un court laps de temps, ce qui peut être atténué à l’aide d’une logique de nouvelle tentative. Les bases de données et les pools élastiques sont facturés en fonction du niveau de service et de la taille du calcul.
Pour les bases de données uniques ayant une taille de calcul spécifique et appartenant à un niveau de service, Azure SQL Database garantit un certain niveau de ressources (indépendamment des autres bases de données). Cela garantit un niveau de performances prévisible. La quantité de ressources allouée est calculée en tant que nombre d’unités de transactions de base de données ou DTU. Il s’agit d’une mesure groupée des ressources de calcul, de stockage et d’E/S.
Le ratio entre ces ressources est déterminé à l’origine par une charge de travail d’évaluation de traitement transactionnel en ligne (OLTP), reflétant les charges de travail de OLTP réelles standard. Quand votre charge de travail dépasse la quantité de ces ressources, le débit est limité, ce qui entraîne un ralentissement des performances et des délais d’attente.
Pour les bases de données uniques, les ressources que votre charge de travail utilise n’ont pas d’incidence sur les ressources disponibles pour d’autres bases de données SQL dans le cloud Azure. De même, les ressources qu’utilisent d’autres charges de travail n’ont pas d’incidence sur les ressources disponibles pour votre base de données SQL.
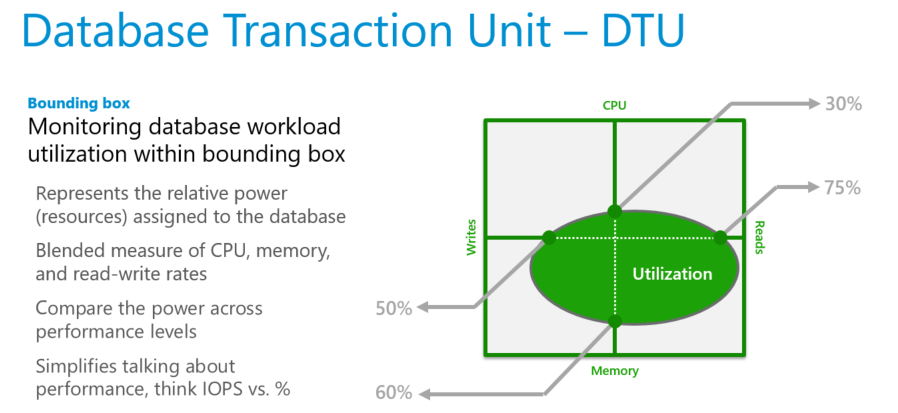
Les DTU sont particulièrement utiles pour comprendre les ressources relatives allouées aux bases de données de tailles de calcul et de niveaux de service variables. Par exemple :
- Le fait de doubler les DTU en augmentant la taille de calcul d’une base de données revient à doubler l’ensemble des ressources disponibles pour cette base de données.
- Une base de données P11 de niveau de service Premium comprenant 1750 DTU fournit une puissance de calcul DTU 350 fois supérieure à celle d’une base de données de base comprenant 5 DTU.
Afin d’avoir une idée plus précise de la consommation de ressources (DTU) de votre charge de travail, utilisez l’analyse des performances des requêtes pour :
- Identifier les principales requêtes par UC/durée/nombre d’exécutions qui peuvent être réglées pour améliorer les performances. Par exemple, une requête nécessitant beaucoup d’E/S peut tirer profit de l’utilisation de techniques d’optimisation en mémoire pour mieux utiliser la mémoire disponible avec un certain niveau de service et une certaine taille de calcul.
- Explorer au niveau du détail une requête afin d’afficher son texte et son historique d’utilisation des ressources.
- Accéder aux recommandations de réglage des performances qui indiquent les actions effectuées par SQL Database Advisor.
Unités de transaction de base de données élastique (eDTU)
Au lieu de fournir un ensemble dédié de ressources (les DTU) qui pourraient ne pas être toujours nécessaires, vous pouvez placer ces bases dans un pool élastique. Les bases de données d’un pool élastique utilisent une seule instance du moteur de base de données et partagent le même pool de ressources.
Les ressources partagées dans un pool élastique sont mesurées en unités de transaction de base de données élastique (eDTU). Les pools élastiques offrent une solution simple et économique pour gérer les objectifs de performance de plusieurs bases de données ayant des modèles d’utilisation variables et non prévisibles. Un pool élastique garantit que les ressources ne peuvent pas être entièrement consommées par une base de données dans le pool, et aussi que chaque base de données dans le pool dispose toujours de la quantité minimale de ressources nécessaires.
Un pool bénéficie d’un nombre défini d’eDTU pour un prix donné. Au sein du pool élastique, les différentes bases de données peuvent se mettre à l’échelle automatiquement dans le respect des limites définies. Une base de données soumise à une charge plus élevée consomme plus d’eDTU pour répondre à la demande. Les bases de données soumises à des charges plus légères consomment moins d’eDTU. Les bases de données qui ne subissent aucune charge ne consomment pas d’eDTU. Les ressources étant approvisionnées pour le pool entier plutôt que pour chaque base de données, les pools élastiques simplifient vos tâches de gestion et fournissent un budget prévisible pour le pool.
Vous pouvez ajouter des eDTU à un pool existant avec un temps d’arrêt minimal pour la base de données. De même, si vous n’avez plus besoin d’eDTU supplémentaires, supprimez-les d’un pool existant à tout moment. Vous pouvez également ajouter ou supprimer des bases de données dans un pool à tout moment. Si vous souhaitez réserver des eDTU pour d’autres bases de données, limitez le nombre d’eDTU que les bases de données peuvent utiliser en cas de charge importante. Si l’utilisation des ressources d’une base de données est constamment élevée et que cela impacte les autres bases de données du pool, déplacez-la en dehors du pool et configurez-la comme une base de données unique avec une quantité prévisible de ressources obligatoires.
Charges de travail tirant avantage d’un pool élastique de ressources
Les pools conviennent parfaitement pour des bases de données avec une utilisation moyenne des ressources faible et des pics d’utilisation relativement peu fréquents. Pour plus d’informations, voir Quand devez-vous envisager d’utiliser un pool élastique SQL Database ?.
Déterminer le nombre de DTU requises par une charge de travail
Si vous souhaitez déplacer une charge de travail de machine virtuelle SQL Server ou locale existante vers SQL Database, consultez les recommandations SKU pour connaître approximativement le nombre de DTU nécessaires. Dans le cas d’une charge de travail SQL Database existante, utilisez l’analyse des performances des requêtes pour évaluer la consommation de ressources (DTU) de votre base de données et obtenir une analyse plus approfondie afin d’optimiser votre charge de travail. La vue de gestion dynamique (DMV) sys.dm_db_resource_stats vous permet de voir la consommation des ressources au cours de la dernière heure. La vue de catalogue sys.resource_stats affiche la consommation des ressources au cours des 14 derniers jours, mais avec une précision inférieure (moyennes de cinq minutes).
Déterminer l’utilisation de DTU
Pour déterminer le pourcentage moyen d’utilisation de DTU/eDTU par rapport à la limite DTU/eDTU d’une base de données ou d’un pool élastique, utilisez la formule suivante :
avg_dtu_percent = MAX(avg_cpu_percent, avg_data_io_percent, avg_log_write_percent)
Les valeurs d’entrée pour cette formule peuvent être obtenues à partir des DMV sys.dm_db_resource_stats, sys.resource_stats et sys.elastic_pool_resource_stats. En d’autres termes, pour déterminer le pourcentage d’utilisation de DTU/eDTU par rapport à la limite DTU/eDTU d’une base de données ou d’un pool élastique, choisissez la plus grande valeur de pourcentage parmi les valeurs suivantes à un moment donné : avg_cpu_percent, avg_data_io_percent et avg_log_write_percent.
Notes
La limite DTU d’une base de données est déterminée par l’UC, les lectures, les écritures et la mémoire disponibles pour la base de données. Toutefois, étant donné que le moteur de base de données SQL Database utilise généralement toute la mémoire disponible pour son cache de données afin d’améliorer les performances, la valeur avg_memory_usage_percent est généralement proche de 100 pour cent, quelle que soit la charge actuelle de la base de données. Par conséquent, même si la mémoire influence indirectement la limite DTU, elle n’est pas utilisée dans la formule d’utilisation de DTU.
Configuration matérielle
Dans le modèle d’achat DTU, les clients ne peuvent pas choisir la configuration de matériel utilisée pour leurs bases de données. Bien qu’une base de données reste généralement sur un type de matériel pendant une longue période (généralement pendant plusieurs mois), certains événements peuvent entraîner le déplacement d’une base de données vers un autre matériel.
Par exemple, une base de données peut être déplacée vers un autre matériel si elle subit un scale-up ou un scale-down pour répondre à un objectif de service différent, si l’infrastructure actuelle dans un centre de données approche ses limites de capacité ou si le matériel utilisé est mis hors service en raison de sa fin de vie.
Si une base de données est déplacée vers un autre matériel, les performances de la charge de travail peuvent changer. Le modèle DTU garantit que le débit et le temps de réponse de la charge de travail du test d’évaluation DTU restent sensiblement identiques quand la base de données passe à un autre type de matériel, à condition que son objectif de service (le nombre de DTU) reste le même.
Toutefois, dans le large éventail des charges de travail des clients qui s’exécutent dans Azure SQL Database, l’impact de l’utilisation d’un matériel différent pour le même objectif de service peut être plus prononcé. Les différentes charges de travail tirent parti de configurations matérielles et de fonctionnalités différentes. Ainsi, pour les charges de travail autres que le test d’évaluation DTU, il est possible de constater des différences de performances si la base de données passe d’un type de matériel à un autre.
Les clients peuvent utiliser le modèle vCore pour choisir leur configuration matérielle préférée lors de la création et de la mise à l’échelle de la base de données. Dans le modèle vCore, les limites de ressources détaillées de chaque objectif de service sur chaque configuration de matériel sont documentées, tant pour les bases de données uniques que pour les pools élastiques. Pour plus d’informations sur le matériel dans le modèle vCore, consultez Configuration matérielle pour SQL Database ou Configuration matérielle pour SQL Managed Instance.
Comparer les niveaux de service
Le choix d’un niveau de service dépend principalement des exigences de continuité d’activité, de stockage et de performance.
| De base | standard | Premium | |
|---|---|---|---|
| Charge de travail cible | Développement et production | Développement et production | Développement et production |
| Contrat SLA de durée de fonctionnement | 99,99 % | 99,99 % | 99,99 % |
| Sauvegarde | Choix d’un stockage de sauvegarde géoredondant, redondant interzone ou localement redondant, conservation des données comprise entre 1 et 7 jours (7 jours par défaut) Conservation à long terme de 10 ans maximum disponible |
Choix d’un stockage de sauvegarde géoredondant, redondant interzone ou localement redondant, conservation des données comprise entre 1 et 35 jours (7 jours par défaut) Conservation à long terme de 10 ans maximum disponible |
Choix entre stockage localement redondant (LRS), redondant interzone (ZRS) et géoredondant (GRS) Conservation de 1 à 35 jours (7 jours par défaut), avec conservation à long terme de 10 ans maximum disponible |
| UC | Faible | Faible, moyen, élevé | Faible, élevé |
| IOPS (approximatif)* | 1-4 IOPS par DTU | 1-4 IOPS par DTU | >25 IOPS par DTU |
| Latence d’E/S (approximative) | 5 ms (lecture), 10 ms (écriture) | 5 ms (lecture), 10 ms (écriture) | 2 ms (lecture/écriture) |
| Indexation Columnstore | N/A | Standard S3 et versions ultérieures | Prise en charge |
| OLTP en mémoire | N/A | N/A | Prise en charge |
* Toutes les IOPS en lecture et écriture sur les fichiers de données, y compris les E/S en arrière-plan (point de contrôle et écriture différée).
Important
Les objectifs de service De base, S0, S1 et S2 fournissent moins d’un seul vCore (UC). Pour les charges de travail gourmandes en ressources processeur, un objectif de service S3 ou supérieur est recommandé.
Dans les objectifs de service De base, S0 et S1, les fichiers de base de données sont stockés dans le Stockage Standard Azure qui utilise un support de stockage basé sur un disque dur (HDD). Ces objectifs de service sont mieux adaptés aux charges de travail de développement, de test et d’accès peu fréquent, qui sont moins sensibles à la variabilité du niveau de performance.
Conseil
Pour voir les limites de gouvernance des ressources réelles pour une base de données ou un pool élastique, interrogez l’affichage sys.dm_user_db_resource_governance. Pour une base de données unique, une ligne est retournée. Pour une base de données dans un pool élastique, une ligne est retournée pour chaque base de données du pool.
Notes
Vous pouvez obtenir une base de données Azure SQL Database gratuite au niveau de service De base avec un compte Azure gratuit. Pour plus d’informations, rendez-vous sur la page Créer une base de données cloud managée avec votre compte gratuit Azure.
Limites des ressources
Les limites de ressources varient selon que les bases de données sont uniques ou mises en pool.
Limites de stockage d’une base de données unique
Dans Azure SQL Database, les tailles de calcul sont exprimées en unités de transaction de base de données (DTU) pour les bases de données uniques, et en unités de transaction de base de données élastique (eDTU) pour les pools élastiques. Pour en savoir plus, consultez Limites de ressources pour les bases de données uniques.
| De base | standard | Premium | |
|---|---|---|---|
| Taille de stockage maximale | 2 Go | 1 To | 4 To |
| DTU maximales | 5 | 3000 | 4000 |
Important
Dans certaines circonstances, vous devrez peut-être réduire une base de données pour récupérer l’espace inutilisé. Pour plus d’informations, consultez Gérer l’espace des fichiers dans Azure SQL Database.
Limites d’un pool élastique
Pour en savoir plus, consultez Limites de ressources pour les bases de données mises en pool.
| De base | Standard | Premium | |
|---|---|---|---|
| Taille de stockage maximale par base de données | 2 Go | 1 To | 1 To |
| Taille de stockage maximale par pool | 156 Go | 4 To | 4 To |
| Nombre maximal d’eDTU par base de données | 5 | 3000 | 4000 |
| eDTU maximales par pool | 1 600 | 3000 | 4000 |
| Nombre maximal de bases de données par pool | 500 | 500 | 100 |
Important
Un espace de stockage supérieur à 1 To au niveau Premium est actuellement disponible dans les toutes régions sauf les suivantes : Chine Est, Chine Nord, Allemagne Centre et Allemagne Nord-Est. Dans ces régions, l’espace de stockage maximal au niveau Premium est limité à 1 To. Pour plus d’informations, voir les limitations actuelles P11-P15.
Important
Dans certaines circonstances, vous devrez peut-être réduire une base de données pour récupérer l’espace inutilisé. Pour plus d’informations, consultez Gérer l’espace des fichiers dans Azure SQL Database.
Référence DTU
Les caractéristiques physiques (processeur, mémoire, E/S) associées à chaque mesure DTU sont étalonnées à l’aide d’un test d’évaluation qui simule une charge de travail de base de données réelle.
Découvrez le schéma, les types de transactions utilisés, la combinaison de charges de travail, les utilisateurs et le rythme, les règles de mise à l’échelle et les métriques associées au benchmark DTU.
Comparer les modèles d’achat DTU et vCore
Bien que le modèle d’achat DTU soit basé sur une mesure groupée des ressources de calcul, de stockage et d’E/S, le modèle d’achat vCore pour Azure SQL Database vous permet de son côté de choisir et de mettre à l’échelle les ressources de calcul et de stockage indépendamment.
Le modèle d’achat vCore vous permet également d’utiliser Azure Hybrid Benefit pour SQL Server pour réduire les coûts, et offre des options Serverless et Hyperscale pour Azure SQL Database qui ne sont pas disponibles dans le modèle d’achat DTU.
Apprenez-en davantage dans Comparer les modèles d’achat vCore et DTU d’Azure SQL Database.
Étapes suivantes
Pour en savoir plus sur les modèles d’achat et les concepts associés, consultez les articles suivants :
- Pour plus d’informations sur les tailles de calcul et les tailles de stockage disponibles pour les bases de données uniques, consultez Limites des ressources DTU SQL Database pour les bases de données uniques.
- Pour plus d’informations sur les tailles de calcul et les tailles de stockage disponibles pour les pools élastiques, consultez Limites des ressources DTU SQL Database pour les pools élastiques.
- Pour plus d’informations sur le benchmark associé au modèle d’achat DTU, consultez le benchmark DTU.
- Comparer les modèles d’achat vCore et DTU d’Azure SQL Database.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour