Observabilité dans la supervision cloud
Cet article fait partie d’une série du guide de supervision du cloud.
Les sections suivantes visent à dynamiser la maturité opérationnelle via l’observabilité et l’itération permanente pour améliorer la façon dont vous supervisez vos services. Découvrez comment les organisations implémentent plus rapidement une stratégie de monitoring cohérente en établissant l’observabilité pour chaque solution de monitoring.
Définition de l’observabilité
Même si l’observabilité et le monitoring se complètent, il existe une distinction notable :
- Monitoring : collecte des informations et vous informe qu’il a détecté un problème en fonction de la façon dont vous l’avez configuré pour des conditions spécifiques. Vous monitorez la présence éventuelle de défaillances connues ou prévisibles.
- Observabilité : capacité à comprendre ce qui se passe à l’intérieur d’un système en examinant les données de sortie. Une solution d’observabilité vous aide à analyser ces données pour évaluer l’intégrité du système et trouver des moyens de résoudre les problèmes dans votre infrastructure informatique.
L’observabilité pousse d’abord le consommateur de monitoring à comprendre ce qui est considéré comme le fonctionnement normal d’un service. En d’autres termes, vous recherchez à atteindre une visibilité totale dès que possible.
Une fois l’observabilité initiale effectuée, vous exploitez ce niveau initial de visibilité pour développer des alertes exploitables, créer des tableaux de bord utiles et évaluer des solutions AIOps. Ces insights vous permettent de vous familiariser avec les données de monitoring de métrique et de journal sous-jacentes.
Notes
C’est l’opposé de l’approche adoptée par le passé, lorsque les équipes commençaient par définir toutes les exigences de monitoring sur le papier, avant de générer, de tester et de déployer.
Que votre plan de monitoring cible une application, l’infrastructure cloud ou la plateforme Azure, la première étape consiste à établir l’observabilité.
Cette approche simplifie également vos plans. Dans tous les cas, la visibilité totale signifie d’atteindre et de conserver une visibilité suffisante sur trois dimensions ou aspects :
- Monitoring en profondeur : collecte des signaux significatifs et pertinents.
- Monitoring de bout en bout ou en largeur : de la couche la plus basse de la pile jusqu'à l'application.
- Monitoring du modèle d’intégrité : concentrez-vous sur les aspects d’intégrité, tels que la disponibilité, les performances, la sécurité et la continuité.
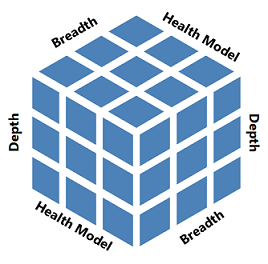
L’observabilité est plus qu’une simple priorité pour vos équipes informatiques. Un objectif essentiel est de s’assurer que les utilisateurs finaux peuvent utiliser les systèmes et que vos objectifs de niveau de service (SLO) sont atteints.
Solutions de monitoring et observabilité
Le monitoring de l’infrastructure et des applications peut être compliqué. La transformation de l’entreprise applique la technologie pour atteindre et aider à concevoir ses stratégies. Le cloud a aussi influencé la nature compliquée de la supervision.
Cela est démontré des manières suivantes :
- Transformation numérique : les efforts de transformation numérique des entreprises tendent vers l’hyper-exploitation de la technologie cloud.
- Monitoring intégré : le monitoring devient intégré aux ressources et aux groupes de ressources Azure, contrairement à l’utilisation d’outils distincts que vous gérez localement.
- Monitoring étendu : les architectures natives du cloud, comme Azure Monitor, sont similaires aux outils SIEM (Security Incident and Event Management). Azure Monitor est étendu, piloté par les journaux et des ordres de grandeur plus flexibles que les outils locaux traditionnels.
Les architectes doivent, comme les opérateurs, comprendre les informations de diagnostic émises par une application ou un composant de l’infrastructure.
La combinaison de flux de journalisation à plusieurs variantes, dynamiques, de série chronologique, avec événement, avec état et télémétriques pour créer des renseignements exploitables dépend des éléments suivants :
- Connaissance de l’équipe : les connaissances et l’expérience du développeur ou de l’ingénieur système qui a une compréhension approfondie de la cible du monitoring.
- Expérience de résolution des problèmes : une expérience dans la prise en charge et la résolution des problèmes à l’aide des données, pour trouver un problème ou rechercher les causes d’un problème.
- Apprentissage de l’historique : passez en revue les incidents passés pour trouver des raisons non technologiques qui peuvent être corrigées automatiquement ultérieurement.
- Documentation : des conseils sous la forme d’une documentation, d’un logiciel, d’une formation ou de conseils proposés par le fournisseur de logiciels ou de matériel.
Microsoft et ses partenaires proposent des packs d’administration pour SCOM. Les packs d’administration sont spécifiques à la technologie ; par exemple, vous importez un pack d’administration SQL, Operations Manager détecte et cible automatiquement les serveurs hébergeant SQL Server et commence leur monitoring. Ici, l’observabilité est plus ou moins prédéfinie. Operations Manager est principalement conçu pour l’infrastructure locale, qui tend à être fixe dans les composants et les modèles de conception architecturale relatifs aux services cloud.
Dans le cloud, vous bénéficiez d’une très grande flexibilité dans le choix des types de services. Le monitoring inclut la manière dont ils évoluent au fil du temps. Ils peuvent être dynamiques, globaux et résilients. Avec Azure Monitor, vous pouvez tirer parti des classeurs existants qui sont inclus dans Azure Monitor Insights, qui offrent des fonctionnalités similaires à celles d’un pack d’administration dans Operations Manager.
L’art de l’observation
L’observabilité repose sur ce qui est supervisé et de quelle manière.
Dans Azure, il existe plusieurs sources de données de monitoring et chacune offre une perspective différente du comportement d’un élément. Azure inclut plusieurs outils permettant d’analyser les différents aspects de ces données.
Observez la plateforme
Dans Azure, Microsoft fournit le point de vue du fournisseur de services par le biais de différents journaux de plateforme.
Les services dans Azure peuvent changer de manière différente et imprévisible au fil du temps. Nous définissons ce comportement comme dynamique. Les managers de services cloud qui observent le service au fil du temps doivent prendre en compte les éléments suivants :
- Déplacement des ressources : les ressources peuvent migrer ou se déplacer entre des emplacements ou des zones géographiques.
- Modifications des ressources : des ressources sont ajoutées, supprimées ou modifiées.
- Consommation : la consommation varie selon les services et les implémentations. Veillez à surveiller le coût, la consommation et les dépenses prévues.
Voici quelques exemples d’outils qui permettent l’observabilité de votre plateforme :
| Source de journal | Description |
|---|---|
| Service de contrôle d’intégrité | Incidents de service et maintenance planifiée signalés par Microsoft. |
| Azure Resource Health | Rapports sur l’intégrité actuelle et passée de vos ressources. |
| Journal d’activité Azure Monitor | Rend compte des événements au niveau de l’abonnement pour toutes les ressources déployées dans l’abonnement. |
| Analyse des changements d’Azure Monitor | Signale les modifications apportées à vos applications Azure et réduit le temps moyen de réparation (MTTR). |
| Journaux de ressources Azure | Précédemment appelés journaux de diagnostic, les journaux de ressources rendent compte des opérations effectuées au sein d’une ressource Azure, sur le plan de données. |
| Rapports (AzureAD) des journaux Microsoft Entra | Rend compte de l’historique de l’activité de connexion et la piste d’audit des modifications apportées dans Microsoft Entra ID pour un locataire particulier. |
| Azure Advisor | Utilisez Azure Advisor pour recevoir des solutions recommandées basées sur les meilleures pratiques afin d’optimiser vos déploiements Azure. |
| Journaux de transparence de Microsoft Cloud for Sovereignty | Ils indiquent le moment auquel il a été accédé aux ressources et identifient l'ingénieur Microsoft concerné. Les journaux de transparence fournissent des détails sur l’accès aux ressources du client. Ces journaux d'activité vous informent également lorsqu’il n’y a pas eu d’accès, ce qui est fréquent. |
L’observabilité évolue progressivement, en commençant par un plan de supervision minimal viable, et l’effort d’intégration des outils et des processus. À mesure que vous vous familiarisez avec les données (les métriques, les journaux et les transactions), vous êtes en mesure de comprendre le comportement et les signes des symptômes ou des problèmes liés à ces ressources ou applications. En vous familiarisant avec les données, vous prenez confiance dans l’utilisation d’Azure Monitor et des données.
Gagner en confiance grâce à l’observabilité
Grâce à une observabilité appropriée, vous gagnez en confiance, et vous êtes en mesure de déterminer la cause et de trouver les réponses qui peuvent vous aider. Plus vous en apprenez sur vos données, plus vos processus évoluent et vos équipes obtiennent des insights.
Pour planter le décor, voici quelques façons de gagner en confiance à partir de l’observabilité :
Augmenter la prévisibilité : un monitoring amélioré des ressources et des services permet d’identifier les problèmes de manière proactive, ce qui les rend prévisibles et gérables à l’avenir.
Détection précoce des anomalies : l’observabilité permet de détecter rapidement les anomalies ou les écarts par rapport au comportement attendu, ce qui réduit l’impact des problèmes potentiels.
Identification de la cause racine : les données d’observabilité détaillées permettent d’identifier les causes racines des problèmes, ce qui permet une résolution plus rapide et empêche la récurrence.
Améliorer l’efficacité de la résolution des problèmes : grâce à l’observabilité, les équipes peuvent rapidement diagnostiquer et résoudre les problèmes complexes en analysant les données pertinentes et en corrélant les événements.
Améliorer la fiabilité du système : en identifiant les goulots d’étranglement, les problèmes de performances et les points de défaillance potentiels, l’observabilité permet d’optimiser les performances du système et d’améliorer la fiabilité globale.
Améliorer l’expérience client : l’observabilité permet de mieux comprendre comment les performances du système affectent les utilisateurs finaux, ce qui permet des mesures proactives pour améliorer la satisfaction des clients.
Faciliter la collaboration : les plateformes d’observabilité offrent une visibilité partagée et un accès aux données, favorisant la coopération entre différentes équipes, telles que les développeurs, les opérations et le support.
Conformité réglementaire : l’observabilité permet de répondre aux exigences réglementaires en fournissant une traçabilité, des journaux d’audit et en garantissant le respect des normes de sécurité et de confidentialité.
Délai de résolution plus rapide : en fournissant des données et des insights enrichis, l’observabilité accélère le diagnostic et la résolution des problèmes, ce qui réduit les temps d’arrêt et les interruptions de service.
Gestion proactive de la capacité : les données d’observabilité permettent de prédire les demandes de ressources, d’identifier les écarts de capacité et d’ajuster de manière proactive les ressources pour maintenir des performances optimales.
Atténuation des risques : grâce à l’observabilité, vous pouvez identifier les risques potentiels plus tôt, en permettant des mesures d’atténuation proactives et en réduisant la probabilité d’impacts graves.
Surveillance et apprentissage continus : l’observabilité permet une surveillance et un apprentissage continus, aidant les équipes à s’adapter à l’évolution des environnements, des exigences et du comportement des utilisateurs.
Optimisation des performances : en analysant les données d’observabilité, les équipes peuvent identifier et optimiser les goulots d’étranglement des performances, ce qui améliore l’efficacité du système.
Hiérarchisation des efforts : les insights d’observabilité permettent aux équipes de hiérarchiser les tâches et d’allouer des ressources en fonction du caractère critique et de l’impact des problèmes identifiés.
Confiance dans la gestion des changements : l’observabilité offre une visibilité sur l’impact des modifications, garantissant ainsi que les nouveaux déploiements ou mises à jour n’introduisent pas de problèmes imprévus.
Amélioration de la réponse aux incidents : grâce à l’observabilité, les équipes de réponse aux incidents peuvent rapidement collecter des informations pertinentes, comprendre le contexte et lancer les actions appropriées.
Plan de supervision
Vous créez un plan de monitoring pour décrire les objectifs, les exigences et d’autres détails importants. Ensuite, vous travaillez à l’élaboration d’un accord entre toutes les parties prenantes concernées dans l’organisation.
Un plan de supervision doit expliquer comment développer et faire fonctionner une ou plusieurs solutions de supervision. Commencez à développer vos plans de monitoring tôt au cours des phases de stratégie et de planification du projet.
Lors de la création du plan, il est essentiel de mémoriser les cinq disciplines du monitoring moderne, comme indiqué dans la documentation sur la stratégie de monitoring du cloud : monitorer, mesurer, répondre, apprendre et améliorer.
Les éléments suivants constituent un plan initial recommandé pour un plan de monitoring et sont considérés comme les principales considérations dans un plan individuel pour des services ou lors de la standardisation de fonctionnalités de service cloud, comme les types de ressources Azure ou les services Microsoft 365.
L’essence du plan consiste à définir la ligne de visibilité entre le fournisseur de services (qui fournit les solutions) et les consommateurs (qui exploitent ou obtiennent de la valeur).
Perspective commerciale
Un plan de monitoring complet doit prendre en compte les besoins de l’entreprise en matière de monitoring, et cela doit inclure un secteur d’intérêt centré sur l’utilisateur. Lors de la définition du plan, il est essentiel de documenter et de partager les besoins de l’entreprise, et les éléments suivants suggèrent l’étendue de cette partie du plan.
- Parties prenantes et consommateurs
- Flux et processus de la valeur métier
- Perspective de l’utilisateur final et utilité
- Exigences en matière de mesure et de création de rapports
- Risques identifiés et frameworks de contrôle de la conformité
- Exigences en matière de contrôle et d’accès
- Risque pour l’entreprise
Perspective du service
Un plan de monitoring complet doit prendre en compte les besoins des propriétaires de services en matière de monitoring. Lors de la définition du plan, il est essentiel de documenter et de partager leurs besoins, et les éléments suivants suggèrent l’étendue de cette partie du plan.
- Parties prenantes et consommateurs
- Rôles et responsabilité
- Définition du service
- Exigences en matière de contrôle et d’accès
- Considérations sur l’architecture ?
- Contrats sous-jacents des fournisseur et partenaires
- Contrats de service (SLA, OLA)
- Identifier la couverture de la garantie de service
- Exigences en matière de mesure et de création de rapports
- Risques
Perspective technologique
Cette section du plan représente la solution de supervision avec des informations du point de vue de l’entreprise et du service. Les éléments suivants suggèrent l’étendue de cette partie du plan.
- Témoignages d’utilisateurs et scénarios
- Cibles techniques (par exemple, mise en réseau)
- Mappage des dépendances des composants
- Types (par exemple, natif cloud, hybride, local)
- Observationnel
- Réactif
- Mesure
- Réglage et optimisation
Considérations
Résumez le plan pour vous assurer qu’il informe l’ensemble des consommateurs, des parties prenantes et des niveaux d’administration appropriés. Pour un plan de monitoring réussi, tenez compte des points suivants :
Considérations relatives aux clés
Phases de production : la solution de monitoring doit être prête lorsque le service sera actif. La planification peut inclure une configuration de test ou de préproduction dans un autre abonnement dédié à l’expérimentation et au test de vos hypothèses.
Stratégie : les plans peuvent également être liés à la stratégie informatique et de monitoring afin de renvoyer les objectifs de monitoring à la mission ou à l’activité.
Cibles : dans le plan, décrivez et analysez les ressources ou services cibles envisagés. Si nécessaire, mappez tous les composants à monitorer, y compris les dépendances de service. Identifiez les lacunes de couverture et déterminez les propriétaires de chaque partie du service.
Solution : pour la solution de supervision, identifiez les consommateurs, les parties prenantes, les fournisseurs, les partenaires, l’accès et l’instrumentation. Et également les aspects du monitoring, l’étendue, la réponse, les rapports et les tableaux de bord (disponibilité, sécurité, expérience utilisateur, etc).
Considérations d’ordre général
En plus des considérations clés, essayez de mieux comprendre comment ces points peuvent influencer votre plan de monitoring pour votre organisation.
Produit minimum viable (MVP) : laissez le plan définir à quoi ressemble le succès pour le produit minimum viable. En d’autres termes, qu’est-ce qui est nécessaire initialement pour la mise en production, et pouvons-nous mesurer le succès à ce sujet ? Une fois que vous êtes actif, vous continuez à faire évoluer la solution de monitoring pour optimiser la valeur.
Sécurisez vos données de monitoring : la sécurité est un aspect crucial pour chaque organisation et chaque équipe aujourd’hui. Assurez-vous d’être formé et de connaître les garde-fous, ou laissez les experts vous guider afin de ne pas ajouter de risque à vos solutions de monitoring, par exemple en exposant des données de monitoring sensibles dans les journaux.
Prenez en compte Microsoft 365 : tout bon plan prend en compte votre locataire Azure avec Microsoft 365 comme un acteur majeur. Microsoft 365 dépend de Microsoft Entra ID et Azure Monitor offre l’intégration de Microsoft 365 à la gestion des points de terminaison.
L’observabilité gagnante : concentrez-vous sur la visibilité totale avant de vous concentrer sur les alertes, car les alertes sont un coût et peuvent rapidement entraîner une fatigue liée aux alertes.
Monitoring de l’activité : les journaux d’audit, de connexion et d’activité sont désormais faciles à segmenter pour la sécurité et les propriétaires de services. Assurez-vous que votre plan de monitoring prend en compte la surveillance de l’activité, notamment les insights et les tableaux de bord que vous devez créer pour toutes les parties prenantes concernées.
Étapes suivantes
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour