Obtenir une position faciale avec visème
Notes
Pour explorer les paramètres régionaux pris en charge pour un ID de visème et des fusions de formes (« blend shapes »), consultez la liste de tous les paramètres régionaux pris en charge. Les images vectorielles évolutives (SVG, Scalable Vector Graphics) sont prises en charge uniquement pour le paramètre régional en-US.
Un visème est la description visuelle d’un phonème dans le langage parlé. Il définit la position du visage et de la bouche quand une personne parle. Chaque visème représente les caractéristiques principales du visage pour un ensemble spécifique de phonèmes.
Vous pouvez utiliser les visèmes pour contrôler le mouvement des modèles d’avatar 2D et 3D, afin que les positions du visage soient alignées au mieux avec la parole synthétique. Par exemple, vous pouvez :
- créer un assistant vocal virtuel animé pour les kiosques intelligents en générant des services intégrés multimode pour vos clients ;
- générer des diffusions d’actualités immersives et améliorer les expériences des auditeurs avec des mouvements naturels du visage et de la bouche ;
- générer plus d’avatars de gaming et personnages de dessins animés qui peuvent parler avec un contenu dynamique ;
- Créez des vidéos d’enseignement des langues plus efficaces pour aider les étudiants à comprendre les mouvements de la bouche spécifiques à chaque mot et phonème.
- Les sourds et malentendants peuvent également repérer les sons visuellement et « lire sur les lèvres » du contenu qui affiche des visèmes sur un visage animé.
Pour plus d’informations sur les visèmes, visionnez cette vidéo d’introduction.
Flux de travail global de production de visème avec reconnaissance vocale
La synthèse vocale neuronale transforme le texte d’entrée ou le contenu SSML (Speech Synthesis Markup Language) en voix synthétique réaliste. La sortie audio vocale peut être accompagnée d’UN ID de visème, de graphiques vectoriels évolutifs (SVG) ou de formes de fusion. À l’aide d’un moteur de rendu 2D ou 3D, vous pouvez utiliser ces événements de visèmes pour animer votre avatar.
Le workflow global du visème est illustré dans l’organigramme suivant :
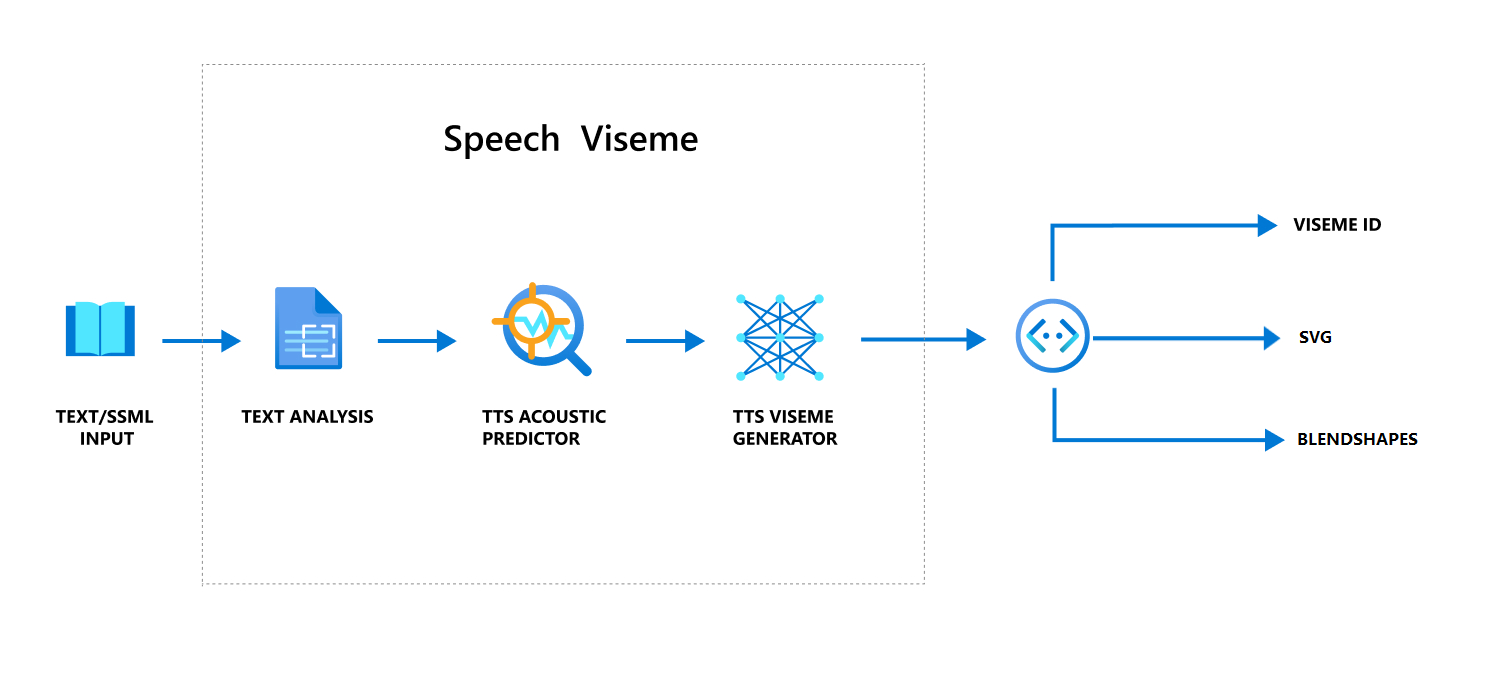
ID de visème
L’ID Visème fait référence à un nombre entier qui spécifie un visème. Nous proposons 22 visèmes différents, chacun représentant la forme de la bouche pour un ensemble spécifique de phonèmes. Il n’existe pas de correspondance un-à-un entre les visèmes et les phonèmes. Plusieurs phonèmes correspondent souvent à un seul visème parce qu’ils renvoient la même expression sur le visage de l’orateur au moment où ils sont produits, par exemple s et z. Pour obtenir des informations plus spécifiques, consultez le tableau de mappage des phonèmes en ID de visèmes.
La sortie audio vocale peut être accompagnée d’ID de visèmes et Audio offset. La valeur Audio offset indique l’horodatage de décalage qui représente l’heure de début de chaque visème, en cycles (100 nanosecondes).
Mapper les phonèmes à des visèmes
Les visèmes varient selon la langue et le lieu. Chaque langue a un ensemble de visèmes qui correspondent à ses phonèmes spécifiques. La documentation sur les alphabets phonétiques SSML mappe les ID de visème aux phonèmes phonétiques (IPA) correspondants. Le tableau de cette section établit les correspondances entre les ID de visème et les positions de la bouche, en listant les phonèmes API typiques pour chaque ID de visème.
| ID de visème | IPA | Forme de la bouche |
|---|---|---|
| 0 | Silence |  |
| 1 | æ, ə, ʌ |
 |
| 2 | ɑ |
 |
| 3 | ɔ |
 |
| 4 | ɛ, ʊ |
 |
| 5 | ɝ |
 |
| 6 | j, i, ɪ |
 |
| 7 | w, u |
 |
| 8 | o |
 |
| 9 | aʊ |
 |
| 10 | ɔɪ |
 |
| 11 | aɪ |
 |
| 12 | h |
 |
| 13 | ɹ |
 |
| 14 | l |
 |
| 15 | s, z |
 |
| 16 | ʃ, tʃ, dʒ, ʒ |
 |
| 17 | ð |
 |
| 18 | f, v |
 |
| 19 | d, t, n, θ |
 |
| 20 | k, g, ŋ |
 |
| 21 | p, b, m |
 |
Animation SVG 2D
Pour les personnages 2D, vous pouvez concevoir un personnage adapté à votre scénario et utiliser SVG (Scalable Vector Graphics) pour chaque ID de visème pour obtenir une position du visage basée sur le temps.
Avec les étiquettes temporelles fournies dans un événement de visème, ces SVG bien conçus sont traités avec des modifications de lissage et offrent une animation robuste aux utilisateurs. Par exemple, l’illustration suivante montre un visage aux lèvres rouges conçu pour l’apprentissage des langues.

Animation de fusion de formes 3D
Vous pouvez utiliser une combinaison de formes pour conduire les mouvements du visage d’un caractère 3D que vous avez conçu.
La chaîne JSON de formes de fusion est représentée sous la forme d’une matrice 2 dimensions. Chaque ligne représente un image. Chaque image(en 60 FPS) contient un tableau de 55 positions faciales.
Recevoir des événements de visème avec le kit de développement logiciel (SDK) Speech
Pour obtenir un visème avec la voix synthétique, abonnez-vous à l’événement VisemeReceived dans le kit SDK Speech.
Notes
Pour demander la sortie SVG ou fusionner des formes, vous devez utiliser l’élément mstts:viseme dans SSML. Pour plus d’informations, consultez comment utiliser l’élément visème dans SSML.
L’extrait suivant montre comment s’abonner à l’événement de visème :
using (var synthesizer = new SpeechSynthesizer(speechConfig, audioConfig))
{
// Subscribes to viseme received event
synthesizer.VisemeReceived += (s, e) =>
{
Console.WriteLine($"Viseme event received. Audio offset: " +
$"{e.AudioOffset / 10000}ms, viseme id: {e.VisemeId}.");
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
var result = await synthesizer.SpeakSsmlAsync(ssml);
}
auto synthesizer = SpeechSynthesizer::FromConfig(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer->VisemeReceived += [](const SpeechSynthesisVisemeEventArgs& e)
{
cout << "viseme event received. "
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
<< "Audio offset: " << e.AudioOffset / 10000 << "ms, "
<< "viseme id: " << e.VisemeId << "." << endl;
// `Animation` is an xml string for SVG or a json string for blend shapes
auto animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
auto result = synthesizer->SpeakSsmlAsync(ssml).get();
SpeechSynthesizer synthesizer = new SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.VisemeReceived.addEventListener((o, e) -> {
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
System.out.print("Viseme event received. Audio offset: " + e.getAudioOffset() / 10000 + "ms, ");
System.out.println("viseme id: " + e.getVisemeId() + ".");
// `Animation` is an xml string for SVG or a json string for blend shapes
String animation = e.getAnimation();
});
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
SpeechSynthesisResult result = synthesizer.SpeakSsmlAsync(ssml).get();
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
def viseme_cb(evt):
print("Viseme event received: audio offset: {}ms, viseme id: {}.".format(
evt.audio_offset / 10000, evt.viseme_id))
# `Animation` is an xml string for SVG or a json string for blend shapes
animation = evt.animation
# Subscribes to viseme received event
speech_synthesizer.viseme_received.connect(viseme_cb)
# If VisemeID is the only thing you want, you can also use `speak_text_async()`
result = speech_synthesizer.speak_ssml_async(ssml).get()
var synthesizer = new SpeechSDK.SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.visemeReceived = function (s, e) {
window.console.log("(Viseme), Audio offset: " + e.audioOffset / 10000 + "ms. Viseme ID: " + e.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.animation;
}
// If VisemeID is the only thing you want, you can also use `speakTextAsync()`
synthesizer.speakSsmlAsync(ssml);
SPXSpeechSynthesizer *synthesizer =
[[SPXSpeechSynthesizer alloc] initWithSpeechConfiguration:speechConfig
audioConfiguration:audioConfig];
// Subscribes to viseme received event
[synthesizer addVisemeReceivedEventHandler: ^ (SPXSpeechSynthesizer *synthesizer, SPXSpeechSynthesisVisemeEventArgs *eventArgs) {
NSLog(@"Viseme event received. Audio offset: %fms, viseme id: %lu.", eventArgs.audioOffset/10000., eventArgs.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
NSString *animation = eventArgs.Animation;
}];
// If VisemeID is the only thing you want, you can also use `SpeakText`
[synthesizer speakSsml:ssml];
Voici un exemple de sortie de visème.
(Viseme), Viseme ID: 1, Audio offset: 200ms.
(Viseme), Viseme ID: 5, Audio offset: 850ms.
……
(Viseme), Viseme ID: 13, Audio offset: 2350ms.
Une fois que vous avez obtenu la sortie du visème, vous pouvez utiliser ces événements pour piloter l’animation des personnages. Vous pouvez créer vos propres personnages et les animer automatiquement.