opérateur make-series
Créez une série de valeurs agrégées spécifiées le long d'un axe donné.
Syntaxe
T| make-series [MakeSeriesParameters] [Column=] Aggregation [default=DefaultValue] [, ...] onAxisColumn [fromstart] [toend] stepstep [by [Column=] GroupExpression [, ...]]
En savoir plus sur les conventions de syntaxe.
Paramètres
| Nom | Type | Obligatoire | Description |
|---|---|---|---|
| Colonne | string |
Le nom de la colonne de résultat. Prend par défaut un nom dérivé de l’expression. | |
| DefaultValue | scalaire | Valeur par défaut à utiliser à la place des valeurs manquantes. En l’absence de ligne comportant des valeurs spécifiques pour AxisColumn et GroupExpression, une valeur par défaut (DefaultValue) est attribuée à l’élément correspondant du tableau. La valeur par défaut est 0. | |
| Agrégation | string |
✔️ | Appel d’une fonction d’agrégation comme count() ou avg(), avec des noms de colonne comme arguments. Voir la liste des fonctions d’agrégation. Seules les fonctions d'agrégation qui renvoient des résultats numériques peuvent être utilisées avec l'opérateur make-series. |
| AxisColumn | string |
✔️ | Colonne selon laquelle la série est classée. Les valeurs de colonne sont généralement de type datetime ou timespan, mais tous les types numériques sont acceptés. |
| start | scalaire | ✔️ | Valeur limite inférieure de AxisColumn pour chacune des séries à générer. Si start n’est pas spécifié, il s’agit de la première classe, ou step, qui contient des données dans chaque série. |
| end | scalaire | ✔️ | Valeur limite supérieure non inclusive de AxisColumn. Le dernier index de la série chronologique est inférieur à cette valeur et correspond à start plus un multiple entier de step inférieur à end. Si end n’est pas spécifié, il s’agit de la limite supérieure de la dernière classe, ou step, qui contient des données pour chaque série. |
| step | scalaire | ✔️ | Différence, ou taille de la classe, entre deux éléments consécutifs du tableau AxisColumn. Pour obtenir la liste des intervalles de temps possibles, consultez timespan. |
| Expression_groupe | expression sur les colonnes qui fournit un ensemble de valeurs distinctes. En règle générale, il s’agit d’un nom de colonne qui fournit déjà un ensemble limité de valeurs. | ||
| MakeSeriesParameters | Zéro ou plusieurs paramètres séparés par un espace, sous la forme Nom=Valeur, qui contrôlent le comportement. Consultez paramètres make-series pris en charge. |
Notes
Les paramètres start, end et step sont utilisés pour générer un tableau de valeurs AxisColumn. Le tableau se compose de valeurs comprises entre start et end, la valeur step représentant la différence entre un élément de tableau et l’élément suivant. Toutes les valeurs Aggregation sont respectivement classées dans ce tableau.
Paramètres make-series pris en charge
| Nom | Description |
|---|---|
kind |
Produit un résultat par défaut quand l’entrée de l’opérateur make-series est vide. Valeur: nonempty |
hint.shufflekey=<key> |
La requête shufflekey partage la charge de requête sur les nœuds de cluster à l’aide d’une clé pour partitionner les données. Voir requête de lecture aléatoire |
Notes
Les tableaux générés par make-series sont limités à 1 048 576 valeurs (2^20). Toute tentative de génération d’un tableau plus grand avec make-series produit une erreur ou un tableau tronqué.
Syntaxe alternative
T| make-series [Column=] Aggregation [default=DefaultValue] [, ...] onAxisColumninrange(start,stop,step) [by [Column=] GroupExpression [, ...]]
Une série générée à partir de la syntaxe alternative diffère d'une série générée à partir de la syntaxe principale par deux aspects :
- La valeur stop est inclusive.
- Le binning de l'axe d'indexation est généré avec bin() et non bin_at(), ce qui signifie que start peut ne pas être inclus dans la série générée.
Il est recommandé d’utiliser la syntaxe principale make-series plutôt que la syntaxe alternative.
Retours
Les lignes d'entrée sont organisées en groupes qui ont les mêmes valeurs que les expressions by et que l'expression bin_at(AxisColumn,step,start). Ensuite, les fonctions d’agrégation spécifiées sont calculées sur chaque groupe, générant une ligne pour chaque groupe. Le résultat contient les colonnes by, la colonne AxisColumn et au moins une colonne pour chaque agrégation calculée. (Les agrégations de plusieurs colonnes ou de résultats non numériques ne sont pas prises en charge.)
Ce résultat intermédiaire comporte autant de lignes qu'il y a de combinaisons distinctes de valeurs by et bin_at(AxisColumn,step,start).
Enfin, les lignes du résultat intermédiaire sont organisées en groupes qui ont les mêmes valeurs que les expressions by, et toutes les valeurs agrégées sont organisées en tableaux (valeurs de type dynamic). Pour chaque agrégation, il existe une colonne contenant le tableau correspondant du même nom. La dernière colonne est un tableau contenant les valeurs d’AxisColumn compartimentées en fonction de l’étape spécifiée.
Notes
Bien que vous puissiez fournir des expressions arbitraires pour les expressions d'agrégation et de regroupement, il est plus efficace d'utiliser des noms de colonne simples.
Liste des fonctions d'agrégation
| Fonction | Description |
|---|---|
| avg() | Renvoie une valeur moyenne pour l'ensemble du groupe |
| avgif() | Renvoie une moyenne avec le prédicat du groupe |
| count() | Renvoie un nombre du groupe |
| countif() | Renvoie un nombre avec le prédicat du groupe |
| dcount() | Retourne un nombre approximatif distinct des éléments de groupe |
| dcountif() | Renvoie un compte distinct approximatif avec le prédicat du groupe |
| max() | Retourne la valeur maximale dans l'ensemble du groupe |
| maxif() | Renvoie la valeur maximale avec le prédicat du groupe |
| min() | Retourne la valeur minimale dans l'ensemble du groupe |
| minif() | Renvoie la valeur minimale avec le prédicat du groupe |
| percentile() | Retourne la valeur de percentile dans l’ensemble du groupe |
| take_any() | Retourne une valeur non vide aléatoire pour le groupe |
| stdev() | Renvoie l'écart type dans l'ensemble du groupe |
| sum() | Renvoie la somme des éléments du groupe |
| sumif() | Renvoie la somme des éléments avec le prédicat du groupe |
| variance() | Renvoie la variance dans l'ensemble du groupe |
Liste des fonctions d'analyse de séries
| Fonction | Description |
|---|---|
| series_fir() | Applique un filtre à réponse impulsionnelle finie |
| series_iir() | Applique un filtre à réponse impulsionnelle infinie |
| series_fit_line() | Recherche une ligne droite qui représente la meilleure approximation de l'entrée |
| series_fit_line_dynamic() | Recherche une ligne qui représente la meilleure approximation de l'entrée, en renvoyant l'objet dynamique |
| series_fit_2lines() | Recherche deux lignes qui représentent la meilleure approximation de l'entrée |
| series_fit_2lines_dynamic() | Recherche deux lignes qui représentent la meilleure approximation de l'entrée, en renvoyant l'objet dynamique |
| series_outliers() | Note les points d'anomalie dans une série |
| series_periods_detect() | Recherche les périodes les plus significatives qui existent dans une série chronologique |
| series_periods_validate() | Vérifie si une série chronologique contient des modèles périodiques de longueurs données |
| series_stats_dynamic() | Renvoie plusieurs colonnes comportant les statistiques courantes (min/max/variance/stdev/average) |
| series_stats() | Génère une valeur dynamique avec les statistiques courantes (min/max/variance/stdev/average) |
Pour une liste complète des fonctions d’analyse de séries, consultez : Fonctions de traitement des séries
Liste des fonctions d'interpolation des séries
| Fonction | Description |
|---|---|
| series_fill_backward() | Effectue une interpolation de remplissage vers l'arrière des valeurs manquantes d'une série |
| series_fill_const() | Remplace les valeurs manquantes d'une série par une valeur constante spécifiée |
| series_fill_forward() | Effectue une interpolation de remplissage vers l'avant des valeurs manquantes d'une série |
| series_fill_linear() | Effectue une interpolation linéaire des valeurs manquantes d'une série |
- Remarque : par défaut, les fonctions d'interpolation considèrent
nullcomme une valeur manquante. Par conséquent, spécifiezdefault=double(null) dansmake-seriessi vous envisagez d'utiliser des fonctions d'interpolation pour la série.
Exemples
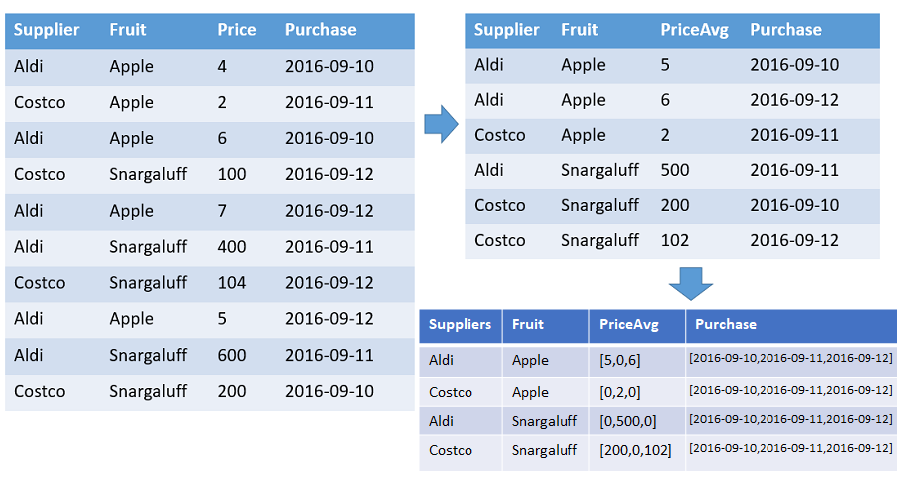
Table présentant des nombres et des prix moyens par fruit et par fournisseur, classés en fonction du timestamp avec la plage spécifiée. La sortie contient une ligne pour chaque combinaison de fruits et de fournisseurs. Les colonnes de la sortie présentent les fruits, les fournisseurs et les tableaux : nombre, moyenne et ensemble de la chronologie (du 2016-01-01 au 2016-01-10). Tous les tableaux sont classés en fonction du timestamp, et tous les espaces vides sont remplis avec les valeurs par défaut (0 dans cet exemple). Toutes les autres colonnes d’entrée sont supprimées.
T | make-series PriceAvg=avg(Price) default=0
on Purchase from datetime(2016-09-10) to datetime(2016-09-13) step 1d by Supplier, Fruit
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| make-series avg(metric) on timestamp from stime to etime step interval
| avg_metric | timestamp |
|---|---|
| [ 4.0, 3.0, 5.0, 0.0, 10.5, 4.0, 3.0, 8.0, 6.5 ] | [ "2017-01-01T00:00:00.0000000Z", "2017-01-02T00:00:00.0000000Z", "2017-01-03T00:00:00.0000000Z", "2017-01-04T00:00:00.0000000Z", "2017-01-05T00:00:00.0000000Z", "2017-01-06T00:00:00.0000000Z", "2017-01-07T00:00:00.0000000Z", "2017-01-08T00:00:00.0000000Z", "2017-01-09T00:00:00.0000000Z" ] |
Quand l’entrée de make-series est vide, le comportement par défaut de make-series produit un résultat vide.
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| take 0
| make-series avg(metric) default=1.0 on timestamp from stime to etime step interval
| count
Sortie
| Count |
|---|
| 0 |
L'utilisation de kind=nonempty dans make-series produit un résultat non vide pour les valeurs par défaut :
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| take 0
| make-series kind=nonempty avg(metric) default=1.0 on timestamp from stime to etime step interval
Sortie
| avg_metric | timestamp |
|---|---|
| [ 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0 ] |
[ "2017-01-01T00:00:00.0000000Z", "2017-01-02T00:00:00.0000000Z", "2017-01-03T00:00:00.0000000Z", "2017-01-04T00:00:00.0000000Z", "2017-01-05T00:00:00.0000000Z", "2017-01-06T00:00:00.0000000Z", "2017-01-07T00:00:00.0000000Z", "2017-01-08T00:00:00.0000000Z", "2017-01-09T00:00:00.0000000Z" ] |
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour