Publication automatisée pour l’intégration continue et livraison continue (CI/CD)
S’APPLIQUE À : Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Remarque
Synapse Analytics prend également en charge l’intégration continue et la livraison continue. Pour plus d’informations, consultez la documentation Synapse Analytics CI/CD.
Vue d’ensemble
L’intégration continue consiste à tester automatiquement chaque modification apportée à votre codebase. Dès que possible, la livraison continue fait suite au test effectué pendant l’intégration continue et envoie (push) les modifications à un système de mise en lots ou de production.
Dans Azure Data Factory, CI/CD implique le déplacement des pipelines Data Factory d’un environnement (développement, test et production) vers un autre. Data Factory utilise des modèles Azure Resource Manager (modèles ARM) pour stocker la configuration de vos différentes entités Data Factory, telles que les pipelines, les jeux de données et les flux de données.
Deux méthodes sont recommandées pour promouvoir une fabrique de données dans un autre environnement :
- Déploiement automatisé grâce à l’intégration de Data Factory avec Azure Pipelines.
- Chargement manuel d’un modèle ARM en utilisant l’intégration de l’expérience utilisateur de Data Factory à Azure Resource Manager.
Pour plus d’informations, consultez Intégration et livraison continues dans Azure Data Factory.
Cet article se concentre sur les améliorations du déploiement continu et la fonctionnalité de publication automatisée pour CI/CD.
Améliorations du déploiement continu
La fonctionnalité de publication automatisée utilise les fonctionnalités Tout valider et Exporter un modèle ARM de l’expérience utilisateur de Data Factory, puis rend la logique consommable via un package npm accessible publiquement : @microsoft/azure-data-factory-utilities. Pour cette raison, vous pouvez déclencher ces actions par programmation au lieu d’accéder à l’interface utilisateur de Data Factory et de sélectionner un bouton manuellement. Cette capacité donnera à vos pipelines de CI/CD une expérience d’intégration continue plus vraie.
Remarque
Veillez à utiliser le nœud version 18.x et sa version compatible pour éviter les erreurs pouvant se produire en raison de l’incompatibilité de package avec les versions antérieures.
Flux actuel de CI/CD
- Chaque utilisateur apporte des modifications à ses branches privées.
- L’envoi (push) vers le master n’est pas autorisé. Les utilisateurs doivent créer une demande de tirage (pull request) pour apporter des modifications.
- Les utilisateurs doivent charger l’interface utilisateur de Data Factory et sélectionner Publier pour déployer les modifications apportées à Data Factory et générer les modèles ARM dans la branche de publication.
- Le pipeline de mise en production DevOps est configuré pour créer une nouvelle version et déployer le modèle ARM chaque fois qu’une nouvelle modification est envoyée (push) à la branche de publication.
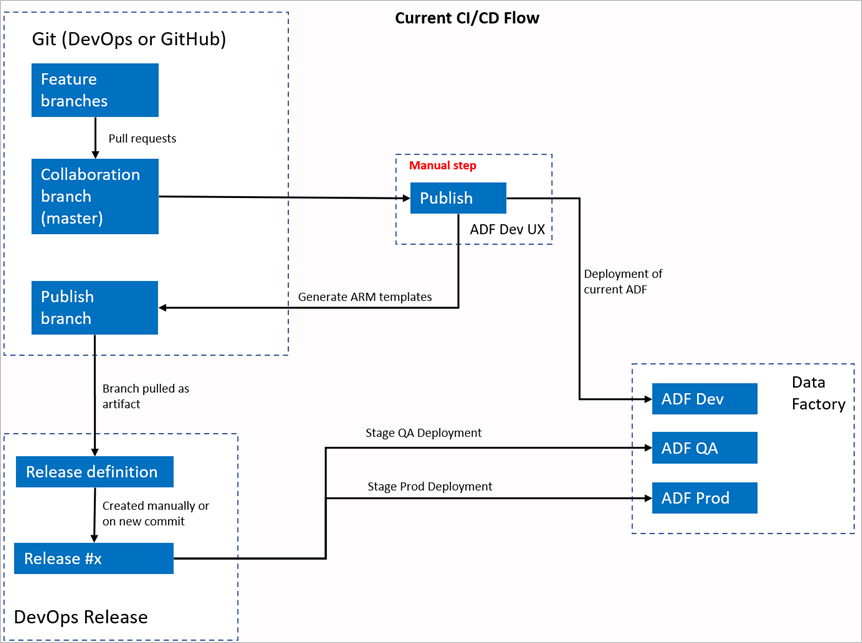
Étape manuelle
Dans le flux de CI/CD actuel, l’expérience utilisateur est l’intermédiaire permettant de créer le modèle ARM. Par conséquent, un utilisateur doit accéder à l’interface utilisateur de Data Factory et sélectionner manuellement Publier pour démarrer la génération du modèle ARM et le déposer dans la branche de publication.
Nouveau flux de CI/CD
- Chaque utilisateur apporte des modifications à ses branches privées.
- L’envoi (push) vers le master n’est pas autorisé. Les utilisateurs doivent créer une demande de tirage (pull request) pour apporter des modifications.
- La création du pipeline Azure DevOps est déclenchée chaque fois qu’une nouvelle validation est effectuée sur le master. Cela valide les ressources et génère un modèle ARM comme artefact si la validation réussit.
- Le pipeline de mise en production DevOps est configuré pour créer une nouvelle version et déployer le modèle ARM chaque fois qu’une nouvelle BLD est disponible.
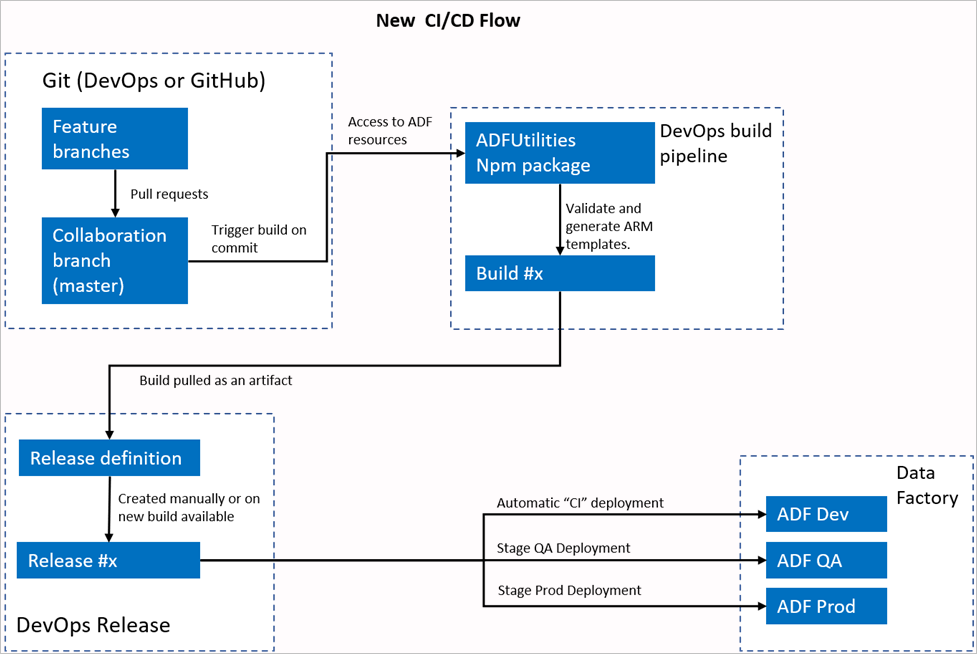
Qu’est ce qui a changé ?
- Nous disposons maintenant d’un processus de génération qui utilise un pipeline de build DevOps.
- Le pipeline de build utilise le package NPM ADFUtilities, qui valide toutes les ressources et génère les modèles ARM. Ces modèles peuvent être uniques et liés.
- Le pipeline de build est responsable de la validation des ressources Data Factory et de la génération du modèle ARM à la place de l’interface utilisateur de Data Factory (boutonPublier).
- La définition de mise en production DevOps consomme désormais ce nouveau pipeline de build au lieu de l’artefact Git.
Notes
Vous pouvez continuer à utiliser le mécanisme existant, qui est la branche adf_publish, ou vous pouvez utiliser le nouveau flux. Les deux sont pris en charge.
Vue d’ensemble du package
Deux commandes sont actuellement disponibles dans le package :
- Exporter un modèle ARM
- Valider
Exporter un modèle ARM
Exécutez npm run build export <rootFolder> <factoryId> [outputFolder] pour exporter le modèle ARM en utilisant les ressources d’un dossier donné. Cette commande exécute également une vérification de la validation avant de générer le modèle ARM. Voici un exemple utilisant un groupe de ressources nommé testResourceGroup :
npm run build export C:\DataFactories\DevDataFactory /subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/testResourceGroup/providers/Microsoft.DataFactory/factories/DevDataFactory ArmTemplateOutput
RootFolderest un champ obligatoire qui indique où se trouvent les ressources Data Factory.FactoryIdest un champ obligatoire qui représente l’ID de la ressource Data Factory au format/subscriptions/<subId>/resourceGroups/<rgName>/providers/Microsoft.DataFactory/factories/<dfName>.OutputFolderest un paramètre facultatif qui spécifie le chemin d’accès relatif pour enregistrer le modèle ARM généré.
La possibilité d’arrêter/démarrer uniquement les déclencheurs mis à jour est désormais en disponibilité générale et est fusionnée dans la commande indiquée ci-dessus.
Notes
Le modèle ARM généré n’est pas publié dans la version en ligne de la fabrique. Le déploiement doit être effectué à l’aide d’un pipeline de CI/CD.
Valider
Exécutez npm run build validate <rootFolder> <factoryId> pour valider toutes les ressources d’un dossier donné. Voici un exemple :
npm run build validate C:\DataFactories\DevDataFactory /subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/testResourceGroup/providers/Microsoft.DataFactory/factories/DevDataFactory
RootFolderest un champ obligatoire qui indique où se trouvent les ressources Data Factory.FactoryIdest un champ obligatoire qui représente l’ID de la ressource Data Factory au format/subscriptions/<subId>/resourceGroups/<rgName>/providers/Microsoft.DataFactory/factories/<dfName>.
Créer un pipeline Azure
Bien que les packages npm puissent être consommés de différentes façons, l’un des principaux avantages est d’être consommé via Azure Pipelines. À chaque fusion dans votre branche de collaboration, vous pouvez déclencher un pipeline qui valide d’abord tout le code, puis exporte le modèle ARM dans un artefact de build qui peut être consommé par un pipeline de mise en production. La différence avec le processus actuel de CI/CD est que vous pointerez votre pipeline de mise en production sur cet artefact au lieu de la branche adf_publish existante.
Effectuez d’abord ces étapes :
Ouvrez un projet Azure DevOps et accédez à Pipelines. Sélectionnez Nouveau pipeline.
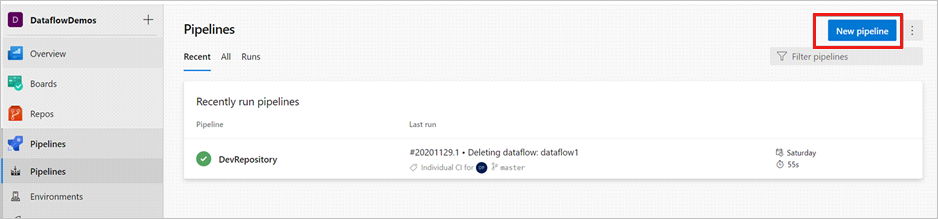
Sélectionnez le référentiel dans lequel vous souhaitez enregistrer le script YAML de votre pipeline. Nous vous recommandons de l’enregistrer dans un dossier build au sein du même référentiel que vos ressources Data Factory. Assurez-vous qu’il existe un fichier package.json dans le référentiel qui contient le nom du package, comme indiqué dans l’exemple suivant :
{ "scripts":{ "build":"node node_modules/@microsoft/azure-data-factory-utilities/lib/index" }, "dependencies":{ "@microsoft/azure-data-factory-utilities":"^1.0.0" } }Sélectionnez Pipeline de démarrage. Si vous avez chargé ou fusionné le fichier YAML, comme indiqué dans l’exemple suivant, vous pouvez également pointer directement sur ce fichier et le modifier.

# Sample YAML file to validate and export an ARM template into a build artifact # Requires a package.json file located in the target repository trigger: - main #collaboration branch pool: vmImage: 'ubuntu-latest' steps: # Installs Node and the npm packages saved in your package.json file in the build - task: UseNode@1 inputs: version: '18.x' displayName: 'Install Node.js' - task: Npm@1 inputs: command: 'install' workingDir: '$(Build.Repository.LocalPath)/<folder-of-the-package.json-file>' #replace with the package.json folder verbose: true displayName: 'Install npm package' # Validates all of the Data Factory resources in the repository. You'll get the same validation errors as when "Validate All" is selected. # Enter the appropriate subscription and name for the source factory. Either of the "Validate" or "Validate and Generate ARM temmplate" options are required to perform validation. Running both is unnecessary. - task: Npm@1 inputs: command: 'custom' workingDir: '$(Build.Repository.LocalPath)/<folder-of-the-package.json-file>' #replace with the package.json folder customCommand: 'run build validate $(Build.Repository.LocalPath)/<Root-folder-from-Git-configuration-settings-in-ADF> /subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/<Your-ResourceGroup-Name>/providers/Microsoft.DataFactory/factories/<Your-Factory-Name>' displayName: 'Validate' # Validate and then generate the ARM template into the destination folder, which is the same as selecting "Publish" from the UX. # The ARM template generated isn't published to the live version of the factory. Deployment should be done by using a CI/CD pipeline. - task: Npm@1 inputs: command: 'custom' workingDir: '$(Build.Repository.LocalPath)/<folder-of-the-package.json-file>' #replace with the package.json folder customCommand: 'run build export $(Build.Repository.LocalPath)/<Root-folder-from-Git-configuration-settings-in-ADF> /subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/<Your-ResourceGroup-Name>/providers/Microsoft.DataFactory/factories/<Your-Factory-Name> "ArmTemplate"' #For using preview that allows you to only stop/ start triggers that are modified, please comment out the above line and uncomment the below line. Make sure the package.json contains the build-preview command. #customCommand: 'run build-preview export $(Build.Repository.LocalPath) /subscriptions/222f1459-6ebd-4896-82ab-652d5f6883cf/resourceGroups/GartnerMQ2021/providers/Microsoft.DataFactory/factories/Dev-GartnerMQ2021-DataFactory "ArmTemplate"' displayName: 'Validate and Generate ARM template' # Publish the artifact to be used as a source for a release pipeline. - task: PublishPipelineArtifact@1 inputs: targetPath: '$(Build.Repository.LocalPath)/<folder-of-the-package.json-file>/ArmTemplate' #replace with the package.json folder artifact: 'ArmTemplates' publishLocation: 'pipeline'Entrez votre code YAML. Nous vous recommandons d’utiliser le fichier YAML comme point de départ.
Enregistrez et exécutez. Si vous avez utilisé le YAML, il se déclenche à chaque mise à jour de la branche primaire.
Notes
Les artefacts générés contiennent déjà des scripts de prédéploiement et post-déploiement pour les déclencheurs afin qu’il ne soit pas nécessaire d’ajouter ces éléments manuellement. Toutefois, lors du déploiement, vous devez toujours référencer la documentation sur l’arrêt et le démarrage des déclencheurs pour exécuter le script fourni.
Contenu connexe
Pour plus d’informations sur l’intégration et la livraison continues dans Data Factory : Intégration et livraison continues dans Azure Data Factory.