Activité de copie dans Azure Data Factory et Azure Synapse Analytics
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Dans Azure Data Factory et les pipelines Synapse, vous pouvez utiliser l’activité de copie pour copier des données entre des banques de données locales et dans le cloud. Une fois que vous avez copié les données, vous pouvez utiliser d’autres activités pour les transformer et les analyser ultérieurement. Vous pouvez également utiliser l’activité de copie pour publier les résultats de transformation et d’analyse pour l’aide à la décision (BI) et l’utilisation d’application.
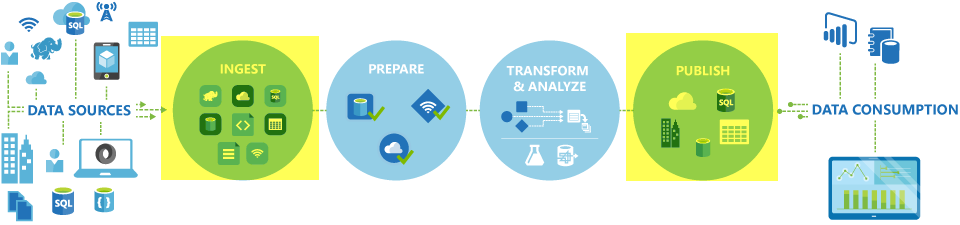
L’activité de copie est exécutée sur un runtime d’intégration. Vous pouvez utiliser différents types de runtimes d’intégration pour différents scénarios de copie de données :
- Lorsque vous copiez des données entre deux magasins de données accessibles publiquement via Internet à partir de n’importe quelle adresse IP, vous pouvez utiliser le runtime d’intégration Azure pour l’activité de copie. Ce runtime d’intégration est sécurisé, fiable, évolutif et disponible dans le monde entier.
- Lorsque vous copiez des données vers et à partir de banques de données situées localement ou dans un réseau avec contrôle d’accès (par exemple, un réseau virtuel Azure), vous devez configurer un runtime d’intégration auto-hébergé.
Un runtime d’intégration doit être associé à chaque magasin de données source et récepteur. Pour plus d’informations sur la façon dont l’activité de copie détermine le runtime d’intégration à utiliser, consultez Choix du runtime d’intégration.
Pour copier des données d’une source vers un récepteur, le service qui exécute l’activité de copie effectue les étapes suivantes :
- Lit les données d’une banque de données source.
- Effectue les opérations de sérialisation/désérialisation, de compression/décompression, de mappage de colonnes, et ainsi de suite. Il effectue ces opérations en se basant sur les configurations du jeu de données d’entrée, du jeu de données de sortie et de l’activité de copie.
- Écrit les données dans la banque de données réceptrice/de destination.

Remarque
Si un runtime d’intégration auto-hébergé est utilisé dans un magasin de données source ou récepteur au sein d’une activité Copy, la source et le récepteur doivent être accessibles à partir du serveur hébergeant le runtime d’intégration pour que l’activité Copy réussisse.
Banques de données et formats pris en charge
Notes
Si un connecteur est marqué en préversion, vous pouvez l’essayer et nous faire part de vos commentaires. Si vous souhaitez établir une dépendance sur les connecteurs en préversion dans votre solution, contactez le support Azure.
Formats de fichiers pris en charge
Azure Data Factory prend en charge les formats de fichier suivants. Reportez-vous à chaque article pour les paramètres basés sur le format.
- Format Avro
- Format binaire
- Format de texte délimité
- Format Excel
- Format JSON
- Format ORC
- Format Parquet
- Format XML
Vous pouvez utiliser l’activité de copie pour copier des fichiers en l'état entre deux banques de données de fichiers, auquel cas les données sont copiées efficacement sans sérialisation ou désérialisation. En outre, vous avez la possibilité d'analyser ou de générer des fichiers d’un format donné. Vous pouvez notamment effectuer ce qui suit :
- Copier des données à partir d'une base de données SQL Server et écrire dans Azure Data Lake Storage Gen2 au format Parquet.
- Copier des fichiers au format texte (CSV) à partir d’un système de fichiers local et les écrire dans le stockage d’objets BLOB Azure au format Avro.
- Copier des fichiers compressés à partir d’un système de fichiers local, les décompresser à la volée et écrire les fichiers extraits dans Azure Data Lake Storage Gen2.
- Copier des données au format de texte compressé Gzip (CSV) à partir du stockage Blob Azure et les écrire dans Azure SQL Database.
- Beaucoup d’autres activités qui nécessitent la sérialisation/désérialisation ou la compression/décompression.
Régions prises en charge
Le service qui permet l’activité de copie est disponible mondialement, dans les régions et zones géographiques répertoriées dans Emplacements du runtime d’intégration Azure. La topologie globalement disponible garantit le déplacement efficace des données en évitant généralement les sauts entre régions. Consultez Produits par région pour vérifier la disponibilité de Data Factory, les espaces de travail Synapse et le déplacement des données dans une région spécifique.
Configuration
Pour effectuer l’activité Copie avec un pipeline, vous pouvez vous servir de l’un des outils ou kits SDK suivants :
- L’outil Copier des données
- Le portail Azure
- Le kit SDK .NET
- Le kit SDK Python
- Azure PowerShell
- L’API REST
- Le modèle Azure Resource Manager
En règle générale, pour utiliser l’activité de copie dans Azure Data Factory ou les pipelines Synapse, vous devez :
- Créer des services liés pour le magasin de données source et le magasin de données récepteur. Vous trouverez la liste des connecteurs pris en charge dans la section Magasins de données et formats pris en charge dans cet article. Reportez-vous à la section « Propriétés du service lié » de l’article relatif au connecteur pour obtenir des informations sur la configuration et les propriétés prises en charge.
- Créer des jeux de données pour la source et le récepteur. Pour plus d’informations sur la configuration et les propriétés prises en charge, reportez-vous aux sections « Propriétés du jeu données » des articles relatifs au connecteur source et récepteur.
- Créer un pipeline avec l’activité de copie. La section suivante fournit un exemple.
Syntaxe
Le modèle suivant d’activité de copie contient une liste complète des propriétés prises en charge. Spécifiez celles qui correspondent à votre scénario.
"activities":[
{
"name": "CopyActivityTemplate",
"type": "Copy",
"inputs": [
{
"referenceName": "<source dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<sink dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>",
<properties>
},
"sink": {
"type": "<sink type>"
<properties>
},
"translator":
{
"type": "TabularTranslator",
"columnMappings": "<column mapping>"
},
"dataIntegrationUnits": <number>,
"parallelCopies": <number>,
"enableStaging": true/false,
"stagingSettings": {
<properties>
},
"enableSkipIncompatibleRow": true/false,
"redirectIncompatibleRowSettings": {
<properties>
}
}
}
]
Détails de la syntaxe
| Propriété | Description | Requis ? |
|---|---|---|
| type | Pour une activité de copie, définissez sur Copy |
Oui |
| inputs | Spécifiez le jeu de données que vous avez créé qui pointe vers les données sources. L’activité de copie ne prend en charge qu’une seule entrée. | Oui |
| outputs | Spécifiez le jeu de données que vous avez créé qui pointe vers les données de récepteur. L’activité de copie ne prend en charge qu’une seule sortie. | Oui |
| typeProperties | Spécifiez les propriétés pour configurer l’activité de copie. | Oui |
| source | Spécifiez le type de source de copie et les propriétés correspondantes pour la récupération des données. Pour plus d’informations, consultez la section « Propriétés de l’activité de copie » de l’article sur le connecteur répertorié dans Magasins de données et formats pris en charge. |
Oui |
| sink | Spécifiez le type de récepteur de copie et les propriétés correspondantes pour l’écriture des données. Pour plus d’informations, consultez la section « Propriétés de l’activité de copie » de l’article sur le connecteur répertorié dans Magasins de données et formats pris en charge. |
Oui |
| translator | Spécifiez des mappages de colonnes explicites de la source au récepteur. Cette propriété s’applique lorsque le comportement de copie par défaut ne répond pas à vos besoins. Pour plus d’informations, consultez Mappage de schéma dans l’activité de copie. |
Non |
| dataIntegrationUnits | Spécifiez une mesure qui représente la quantité d’énergie que le runtime d’intégration Azure utilise pour la copie des données. Ces unités étaient auparavant appelées unités de déplacement de données Cloud. Pour plus d’informations, consultez Unités d’intégration de données. |
Non |
| parallelCopies | Spécifiez le parallélisme que l’activité de copie doit utiliser lors de la lecture des données de la source et l’écriture des données vers le récepteur. Pour plus d’informations, voir Copie en parallèle. |
Non |
| conserves | Spécifiez s’il faut conserver les métadonnées/ACL lors de la copie des données. Pour plus d’informations, consultez Conserver les métadonnées. |
Non |
| enableStaging stagingSettings |
Spécifiez s’il faut effectuer une copie intermédiaire des données intermédiaires dans le stockage Blob au lieu de copier directement les données de la source vers le récepteur. Pour plus d’informations sur les scénarios utiles et les détails de la configuration, consultez Copie intermédiaire. |
Non |
| enableSkipIncompatibleRow redirectIncompatibleRowSettings |
Choisissez comment gérer les lignes incompatibles lorsque vous copiez des données de la source vers le récepteur. Pour plus d’informations, consultez Tolérance aux pannes. |
Non |
Surveillance
Vous pouvez surveiller l’exécution de l’activité de copie dans Azure Data Factory et les pipelines Synapse visuellement ou par programmation. Pour plus d’informations, consultez Surveiller l’activité de copie.
Copie incrémentielle
Data Factory et les pipelines Synapse vous permettent de copier de façon incrémentielle des données delta d’un magasin de données source vers un magasin de données récepteur. Pour plus d’informations, consultez Didacticiel : Copier les données de façon incrémentielle.
Performances et réglage
L’expérience de surveillance de l’activité de copie affiche les statistiques des performances de copie pour chaque exécution d’activité. Le Guide des performances et de l’évolutivité de l’activité de copie décrit les facteurs clés qui affectent les performances du déplacement des données par le biais de l’activité de copie. Il répertorie également les valeurs de performances observées pendant le test et explique comment optimiser les performances de l’activité de copie.
Reprendre à partir de la dernière exécution ayant échoué
L’activité de copie prend en charge la reprise après l’échec de la dernière exécution lorsque vous copiez une grande taille de fichiers tels quels avec un format binaire entre les magasins basés sur des fichiers et que vous choisissez de conserver la hiérarchie des dossiers/fichiers de la source au récepteur, par exemple pour migrer des données d’Amazon S3 vers Azure Data Lake Storage Gen2. Elle s’applique aux connecteurs de fichiers suivants : Amazon S3, Amazon S3 Compatible StorageAzure Blob, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, Système de fichiers, FTP, Google Cloud Storage, HDFS, Oracle Cloud Storage et SFTP.
Vous pouvez tirer parti de la reprise de l’activité de copie des deux manières suivantes :
Nouvelle tentative de niveau d’activité : Vous pouvez définir le nombre de nouvelles tentatives sur l’activité de copie. Pendant l’exécution du pipeline, en cas d’échec de l’exécution de l’activité de copie, la nouvelle tentative automatique suivante démarre à partir du point d’échec de la dernière évaluation.
Réexécuter à partir d’une activité ayant échoué : Une fois l’exécution du pipeline terminée, vous pouvez également déclencher une réexécution à partir de l’activité ayant échoué dans la vue d’analyse de l’interface utilisateur ADF ou par programmation. Si l’activité qui a échoué est une activité de copie, le pipeline n’est pas exécuté à nouveau à partir de cette activité, mais reprend également à partir du point d’échec de l’exécution précédente.

Quelques points à noter :
- La reprise se produit au niveau du fichier. Si l’activité de copie échoue lors de la copie d’un fichier, lors de la prochaine exécution, ce fichier spécifique sera recopié.
- Pour que la reprise fonctionne correctement, ne modifiez pas les paramètres de l’activité de copie entre les nouvelles exécutions.
- Lorsque vous copiez des données à partir d’Amazon S3, d’un objet Blob Azure, d’Azure Data Lake Storage Gen2 et de Google Cloud Storage, l’activité de copie peut reprendre à partir d’un nombre arbitraire de fichiers copiés. Alors que pour le reste des connecteurs basés sur des fichiers en tant que source, l’activité de copie prend en charge la reprise à partir d’un nombre limité de fichiers, généralement une plage de dizaines de milliers de fichier, et varie en fonction de la longueur des chemins d’accès aux fichiers. les fichiers au-delà de ce nombre seront copiés à nouveau lors de la réexécution.
Pour les autres scénarios que la copie de fichiers binaires, la réexécution de l’activité de copie commence dès le début.
Conserver les métadonnées avec les données
Lors de la copie des données de la source vers le récepteur, dans des scénarios tels que la migration d'un lac de données, vous pouvez également choisir de conserver les métadonnées et ACL avec les données à l’aide de l’activité de copie. Pour plus d’informations, consultez Conserver les métadonnées.
Ajouter des étiquettes de métadonnées au récepteur basé sur un fichier
Quand le récepteur est basé sur le Stockage Azure (Azure Data Lake Storage ou Stockage Blob Azure), nous pouvons choisir d’ajouter des métadonnées aux fichiers. Ces métadonnées s’affichent dans le cadre des propriétés du fichier sous forme de paires clé-valeur. Pour tous les types de récepteur basé sur un fichier, vous pouvez ajouter des métadonnées impliquant du contenu dynamique en utilisant des paramètres de pipeline, des variables système, des fonctions et des variables. Par ailleurs, pour un récepteur basé sur un fichier binaire, vous avez la possibilité d’ajouter la date et l’heure de dernière modification (du fichier source) en utilisant le mot clé $$LASTMODIFIED, ainsi que des valeurs personnalisées sous forme de métadonnées au fichier récepteur.
Mappage du schéma et du type de données
Pour plus d’informations sur la façon dont l’activité de copie met en correspondance vos données sources et votre récepteur, consultez Mappage de type de données et de schéma.
Ajouter des colonnes supplémentaires pendant la copie
En plus de copier des données d’une banque de données source vers un récepteur, vous pouvez également configurer l’ajout de colonnes de données supplémentaires à copier dans le récepteur. Par exemple :
- Lors de la copie à partir d’une source basée sur un fichier, enregistrez le chemin d’accès relatif du fichier dans une colonne supplémentaire pour savoir de quel fichier proviennent les données.
- Dupliquez la colonne source spécifiée comme une autre colonne.
- Ajoutez une colonne avec l’expression ADF, pour joindre des variables système ADF telles que le nom ou l’ID du pipeline, ou stocker une autre valeur dynamique provenant de la sortie de l’activité en amont.
- Ajoutez une colonne avec une valeur statique pour répondre à votre besoin de consommation en aval.
Vous pouvez trouver la configuration suivante dans l’onglet source de l’activité de copie. Vous pouvez également mapper ces colonnes supplémentaires dans l’activité de copie Mappage de schéma comme d’habitude en utilisant les noms de colonne que vous avez définis.
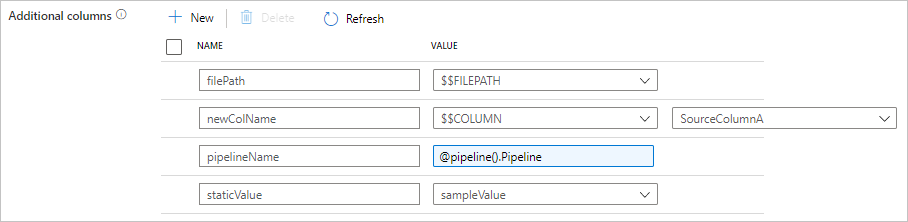
Conseil
Cette fonctionnalité fonctionne avec le modèle de jeu de données le plus récent. Si vous ne voyez pas cette option dans l’interface utilisateur, essayez de créer un nouveau jeu de données.
Pour le configurer par programmation, ajoutez la propriété additionalColumns dans la source de l’activité de copie :
| Propriété | Description | Obligatoire |
|---|---|---|
| additionalColumns | Ajoutez des colonnes de données supplémentaires à copier dans le récepteur. Chaque objet sous le tableau additionalColumns représente une colonne supplémentaire. name définit le nom de la colonne et value indique la valeur des données de cette colonne.Les valeurs de données autorisées sont : - $$FILEPATH : une variable réservée indique de stocker le chemin d’accès relatif des fichiers sources dans le chemin d’accès du dossier spécifié dans le jeu de données. Appliquer à la source basée sur un fichier.- $$COLUMN:<source_column_name> : un modèle de variable réservée indique de dupliquer la colonne source spécifiée comme une autre colonne.- Expression - Valeur statique |
Non |
Exemple :
"activities":[
{
"name": "CopyWithAdditionalColumns",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "<source type>",
"additionalColumns": [
{
"name": "filePath",
"value": "$$FILEPATH"
},
{
"name": "newColName",
"value": "$$COLUMN:SourceColumnA"
},
{
"name": "pipelineName",
"value": {
"value": "@pipeline().Pipeline",
"type": "Expression"
}
},
{
"name": "staticValue",
"value": "sampleValue"
}
],
...
},
"sink": {
"type": "<sink type>"
}
}
}
]
Conseil
Après avoir configuré des colonnes supplémentaires, n’oubliez pas de les mapper au récepteur de destination, sous l’onglet Mappage.
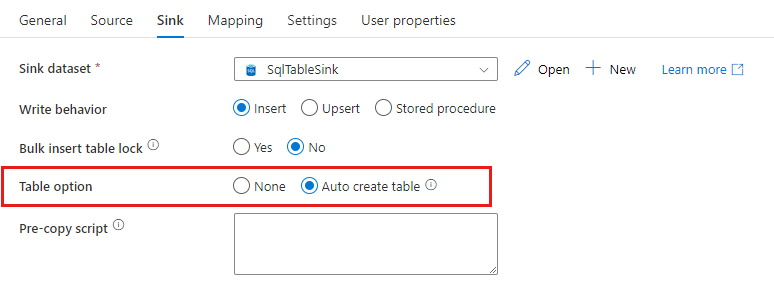
Créer automatiquement des tables de récepteur
Lors de la copie de données dans SQL Database/Azure Synapse Analytics, si la table de destination n’existe pas, l’activité de copie prend en charge sa création automatique en fonction des données sources. Elle vise à vous aider à commencer rapidement à charger les données et à évaluer SQL Database/Azure Synapse Analytics. Après l’ingestion des données, vous pouvez examiner et ajuster le schéma de la table de récepteur en fonction de vos besoins.
Cette fonctionnalité est prise en charge lors de la copie de données à partir de n’importe quelle source vers les magasins de données récepteurs suivants. Vous pouvez trouver l’option sur l’interface utilisateur de création ADF –>Récepteur d’activité de copie –>Option de table –>Créer automatiquement une table, ou via la propriété tableOption dans la charge utile de récepteur d’activité de copie.
Tolérance de panne
Par défaut, l’activité de copie arrête la copie des données et retourne un échec lorsque les lignes de données sources sont incompatibles avec les lignes de données du récepteur. Pour que la copie aboutisse, vous pouvez configurer l’activité de copie afin d’ignorer et de journaliser les lignes incompatibles et de copier uniquement les données compatibles. Pour plus d’informations, consultez Tolérance de panne de l’activité de copie.
Vérification de la cohérence des données
Lorsque vous déplacez des données du magasin source au magasin de destination, l’activité de copie vous offre la possibilité de faire une vérification supplémentaire de la cohérence des données pour vous assurer que les données sont non seulement copiées du magasin source au magasin de destination, mais également que leur cohérence entre les deux magasins de données est vérifiée. Une fois que des fichiers incohérents ont été détectés pendant le déplacement des données, vous pouvez soit abandonner l’activité de copie, soit continuer à copier le reste en activant le paramètre de tolérance de panne afin d’ignorer les fichiers incohérents. Vous pouvez récupérer les noms de fichiers ignorés en activant le paramètre de journal de session dans l’activité de copie. Consultez Vérification de la cohérence des données dans l’activité de copie pour plus d’informations.
Journal de session
Vous pouvez journaliser les noms de fichiers copiés, ce qui peut vous aider à mieux vous assurer que les données sont non seulement bien copiées du magasin source vers le magasin de destination, mais qu’elles sont également cohérentes entre les deux magasins en examinant les journaux de session de l’activité de copie. Consultez Connexion à la session dans l’activité de copie pour plus de détails.
Contenu connexe
Voir les procédures de démarrage rapide, didacticiels et exemples suivants :