Créer des pipelines de copie de données à grande échelle avec une approche pilotée par les métadonnées dans l’outil Copier les données
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Lorsque vous souhaitez copier de grandes quantités d’objets (par exemple, des milliers de tables) ou charger des données à partir d’une grande variété de sources, l’approche appropriée consiste à entrer la liste des noms des objets avec les comportements de copie requis dans une table de contrôle, puis à utiliser des pipelines paramétrables pour lire les mêmes données dans la table de contrôle et les appliquer en conséquence. En procédant ainsi, vous pouvez mettre à jour (par exemple, ajouter/supprimer) la liste d’objets à copier aisément en mettant simplement à jour les noms d’objets dans la table de contrôle au lieu de redéployer les pipelines. De plus, vous disposerez d’un emplacement unique pour vérifier aisément les objets copiés par les pipelines/déclencheurs avec des comportements de copie définis.
L’outil ADF Copier les données facilite la création de ces pipelines de copie de données pilotées par les métadonnées. Après que vous avez suivi un flux intuitif à partir d’un assistant, l’outil peut générer des pipelines paramétrés et des scripts SQL pour que vous puissiez créer des tables de contrôle externes en conséquence. Une fois que vous avez exécuté les scripts générés pour créer la table de contrôle dans votre base de données SQL, vos pipelines lisent les métadonnées à partir de la table de contrôle et les appliquent automatiquement aux travaux de copie.
Créer des travaux de copie pilotés par des métadonnées à partir de l’outil Copier les données
Sélectionnez Metadata-driven copy task (Tâche de copie pilotée par des métadonnées) dans l’outil Copier les données.
Vous devez saisir la connexion et le nom de la table de contrôle, afin que le pipeline généré puisse lire les métadonnées de cette table.
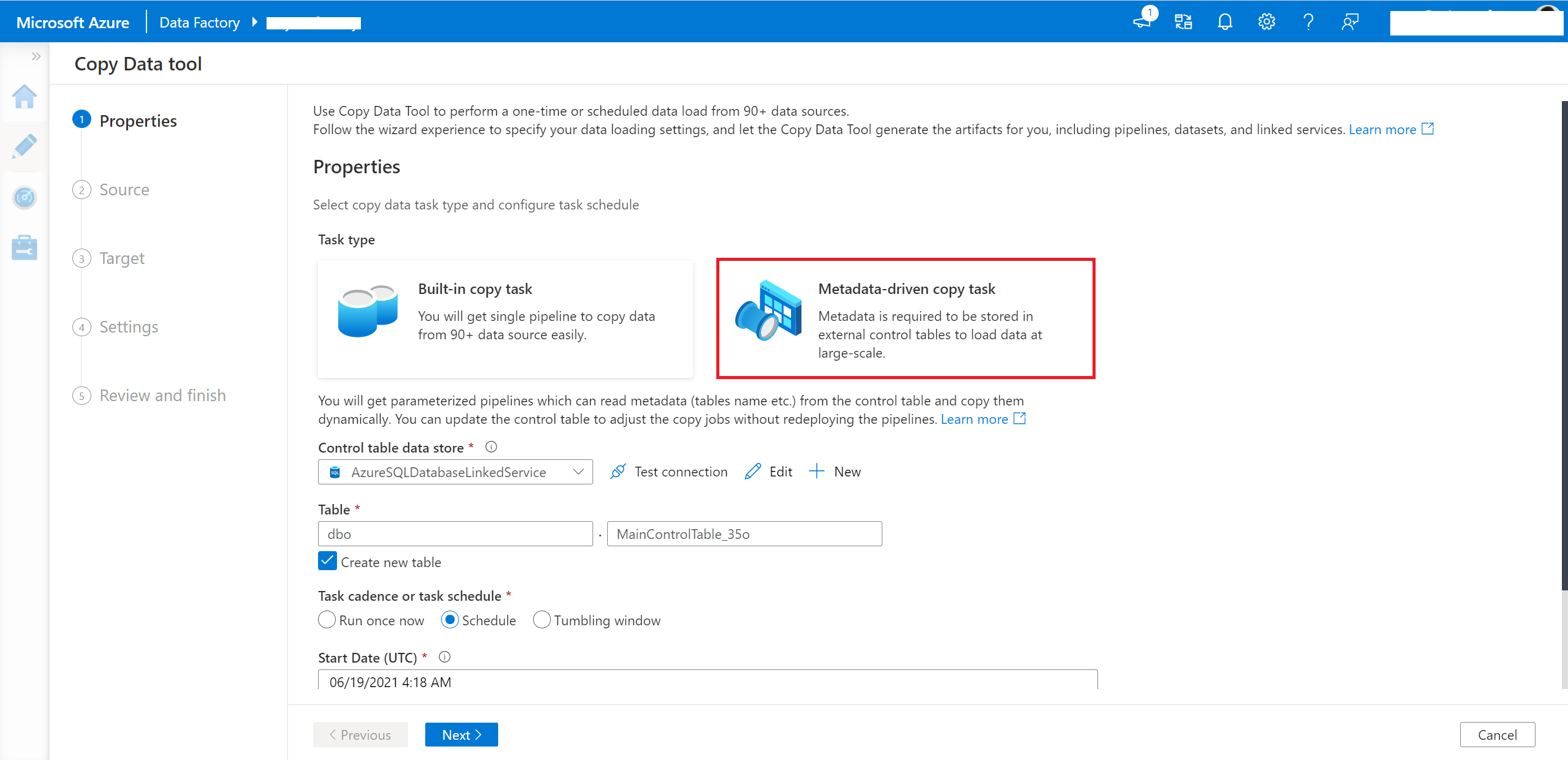
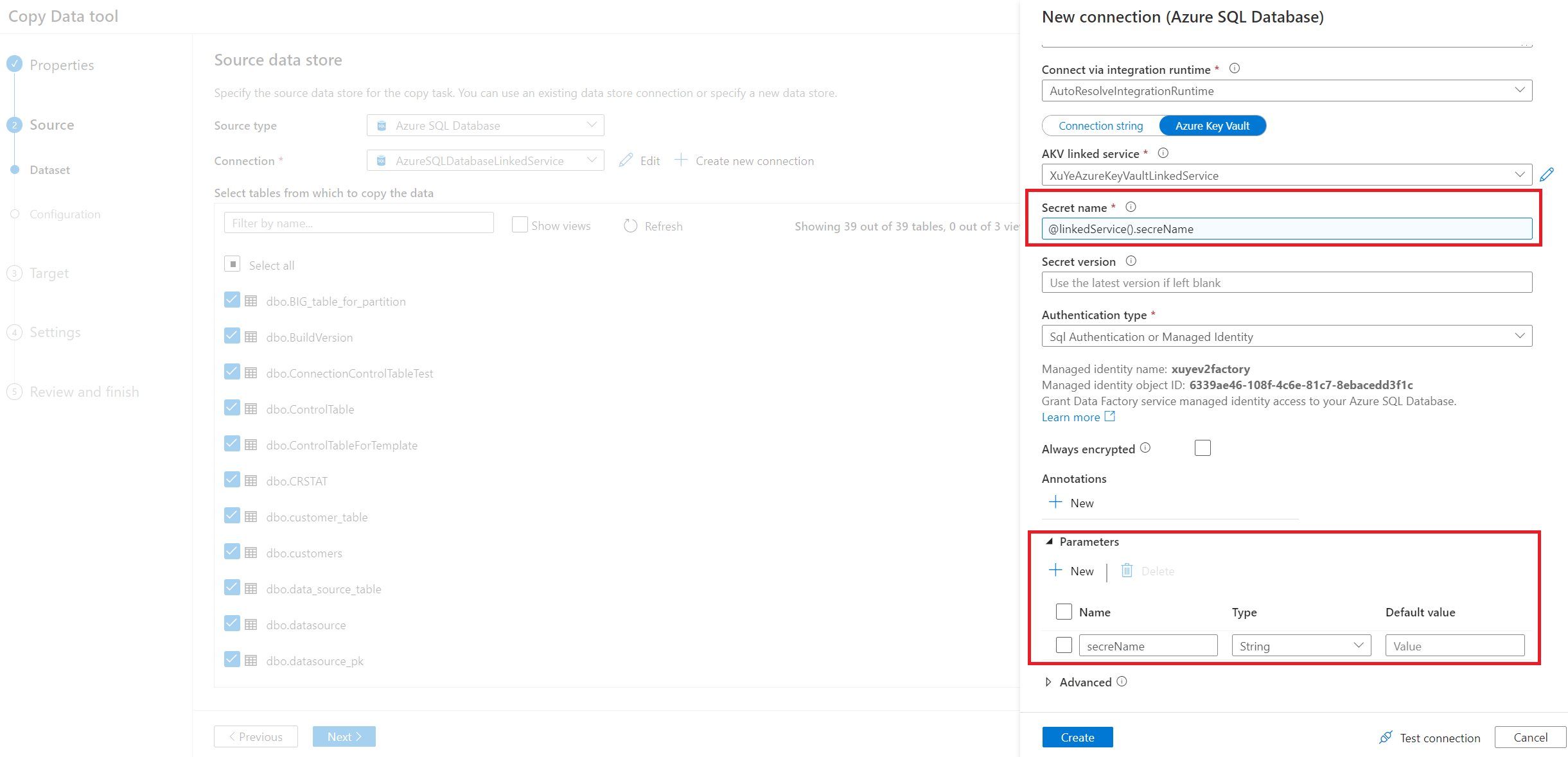
Entrez la connexion de votre base de données source. Vous pouvez également utiliser le service lié paramétré.
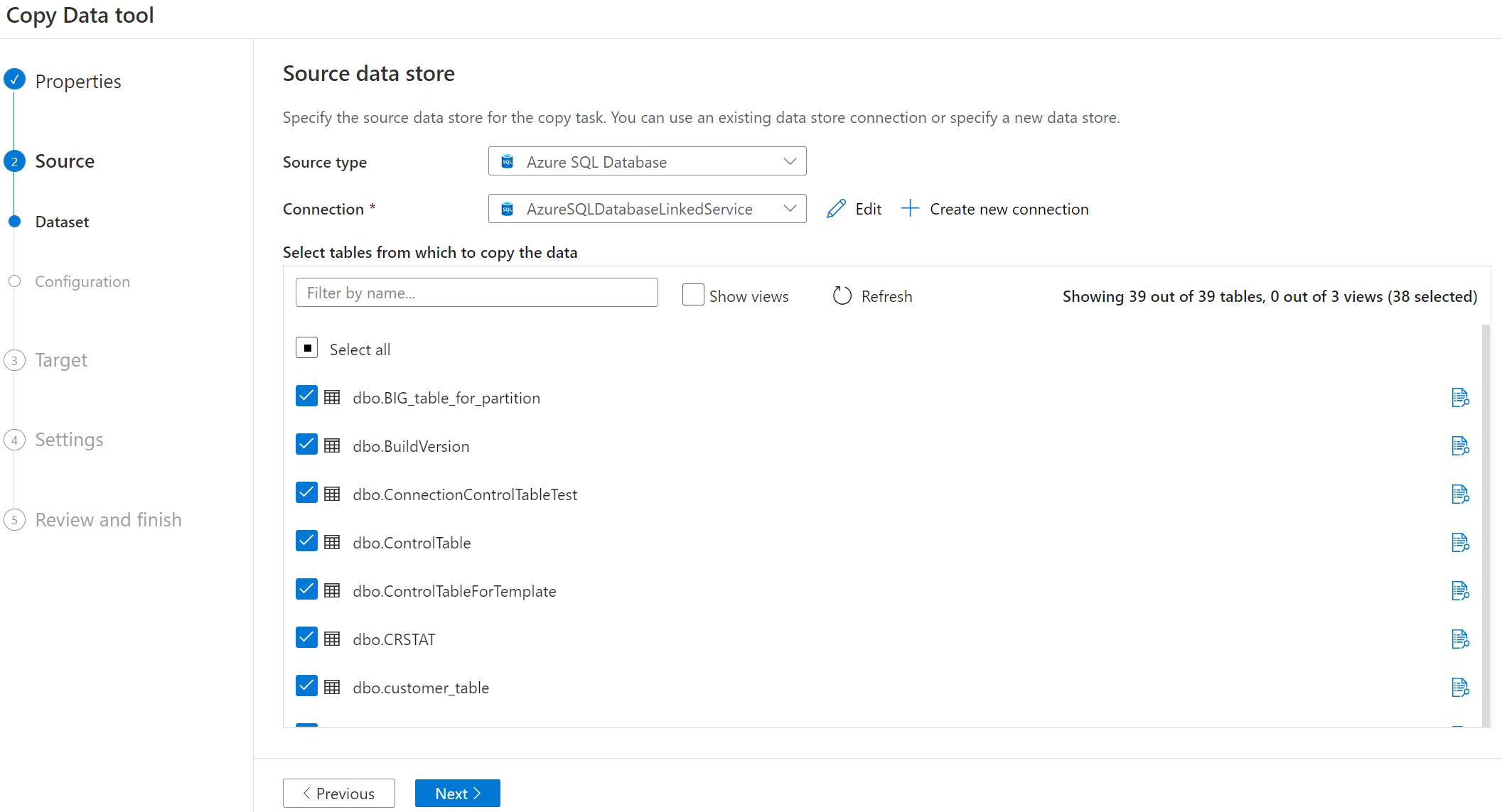
Sélectionnez le nom de table à copier.
Remarque
Si vous sélectionnez le magasin de données tabulaires, vous aurez la possibilité de sélectionner la charge complète ou la charge delta dans la page suivante. Si vous sélectionnez le magasin de stockage, vous pouvez sélectionner la charge complète uniquement dans la page suivante. Le chargement incrémentiel de nouveaux fichiers uniquement à partir du magasin de stockage n’est actuellement pas pris en charge.
Choisissez comportement de chargement.
Conseil
Si vous souhaitez effectuer une copie complète sur toutes les tables, sélectionnez Full load all tables (Téléchargement complet de toutes les tables). Si vous souhaitez effectuer une copie incrémentielle, vous pouvez sélectionner configurer pour chaque table individuellement, puis sélectionner Charge Delta ainsi que le nom de colonne de filigrane et la valeur de démarrage pour chaque table.
Sélectionnez Magasin de données de destination.
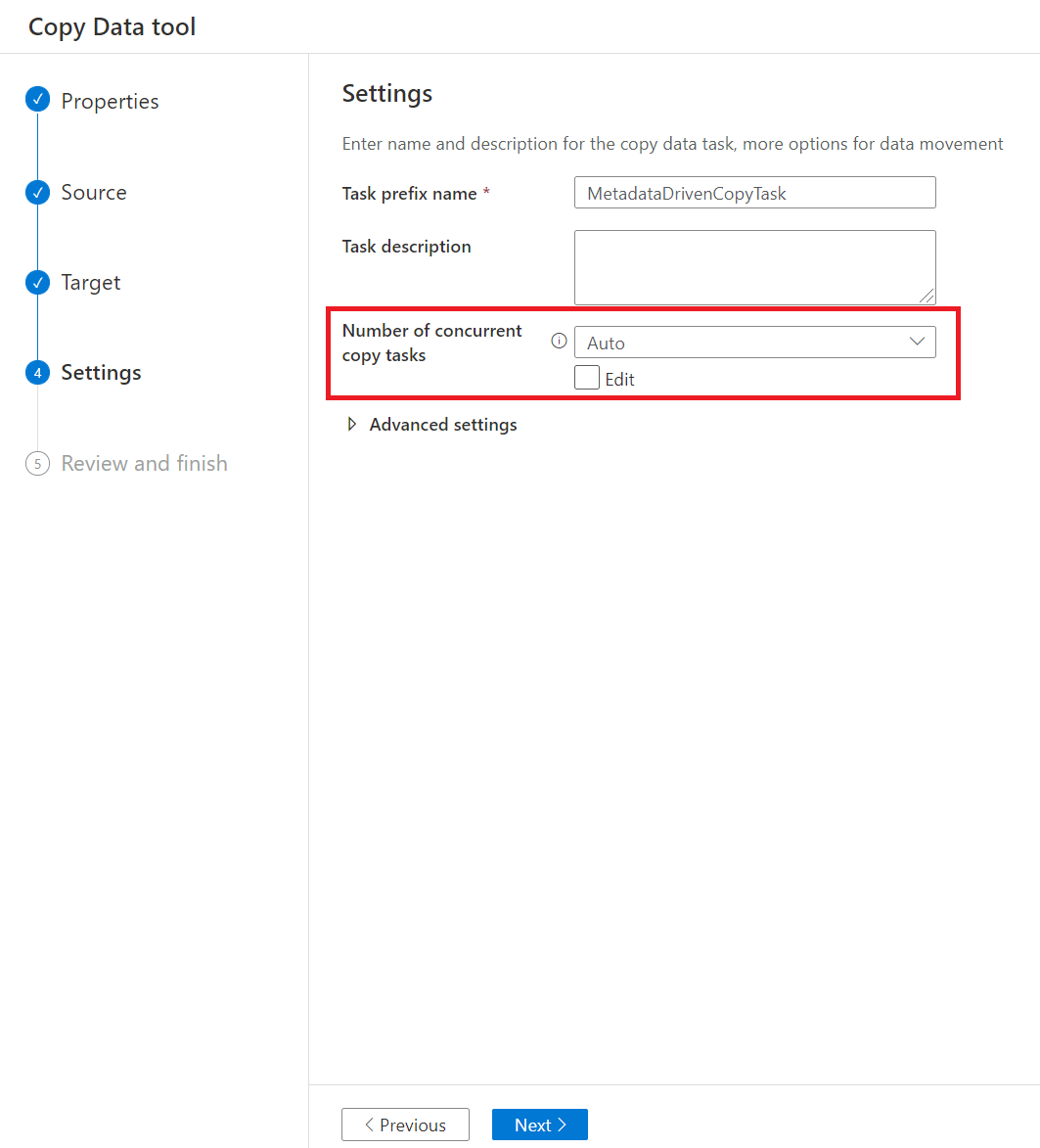
Dans la page Paramètres, vous pouvez choisir le nombre maximal d’activités de copie afin de copier des données à partir de votre magasin source simultanément via le nombre de tâches de copie simultanément. La valeur par défaut est 20.
Après le déploiement du pipeline, vous pouvez copier ou télécharger les scripts SQL à partir de l’interface utilisateur pour créer la table de contrôle et la procédure stockée.
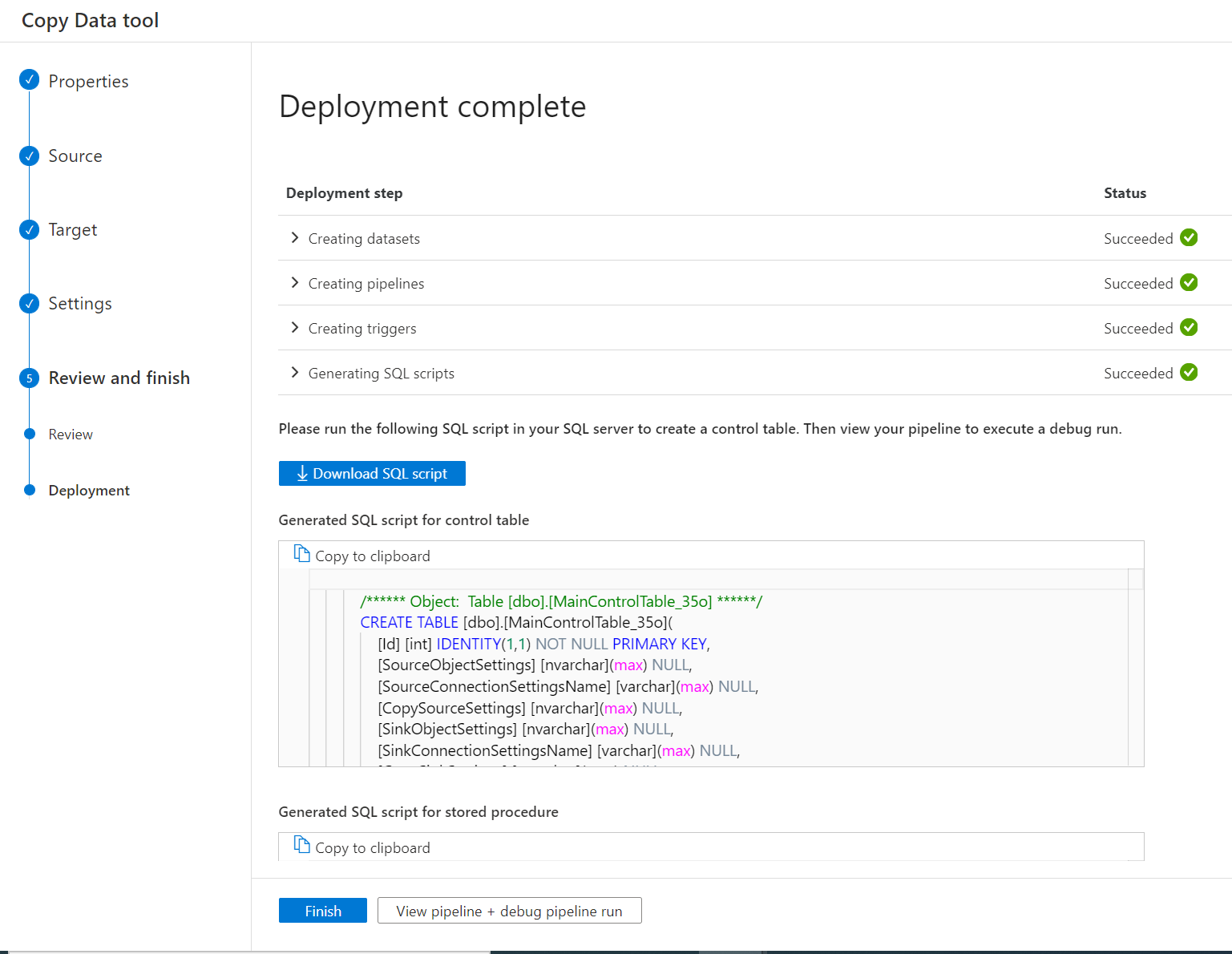
Deux scripts SQL s’affichent.
- Le premier script SQL est utilisé pour créer deux tables de contrôle. La table de contrôle principale stocke la liste des tables, le chemin d’accès du fichier ou les comportements de copie. La table de contrôle de connexion stocke la valeur de connexion de votre magasin de données si vous avez utilisé un service lié paramétré.
- Le deuxième SQL script est utilisé pour créer une procédure stockée. Elle est utilisée pour mettre à jour la valeur de filigrane dans la table de contrôle principale lorsque les travaux de copie incrémentielle se terminent à chaque fois.
Ouvrez SSMS pour vous connecter à votre serveur de tables de contrôle, puis exécutez les deux scripts SQL pour créer des tables de contrôle et une procédure de stockage.
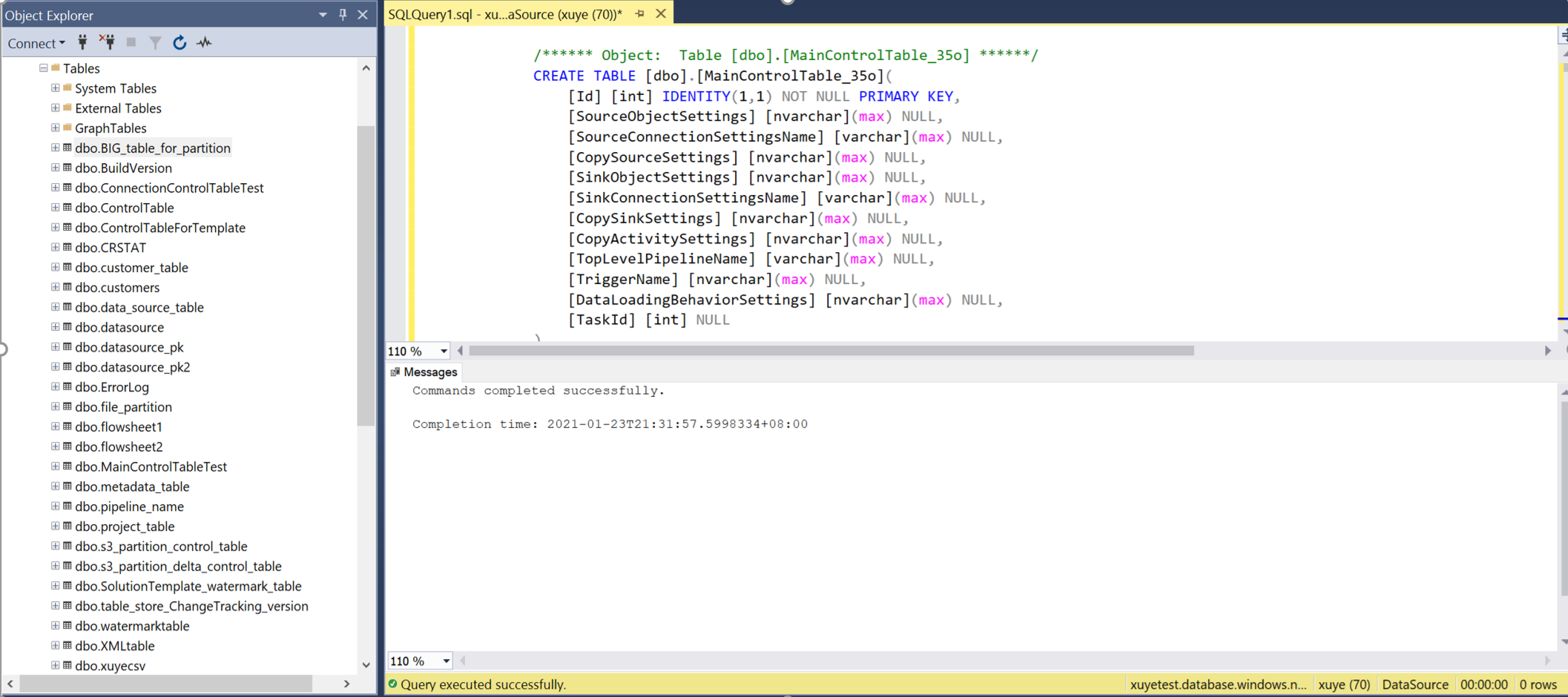
Interrogez la table de contrôle principale et la table de contrôle de connexion pour examiner les métadonnées qu’elle contient.
Table de contrôle principale
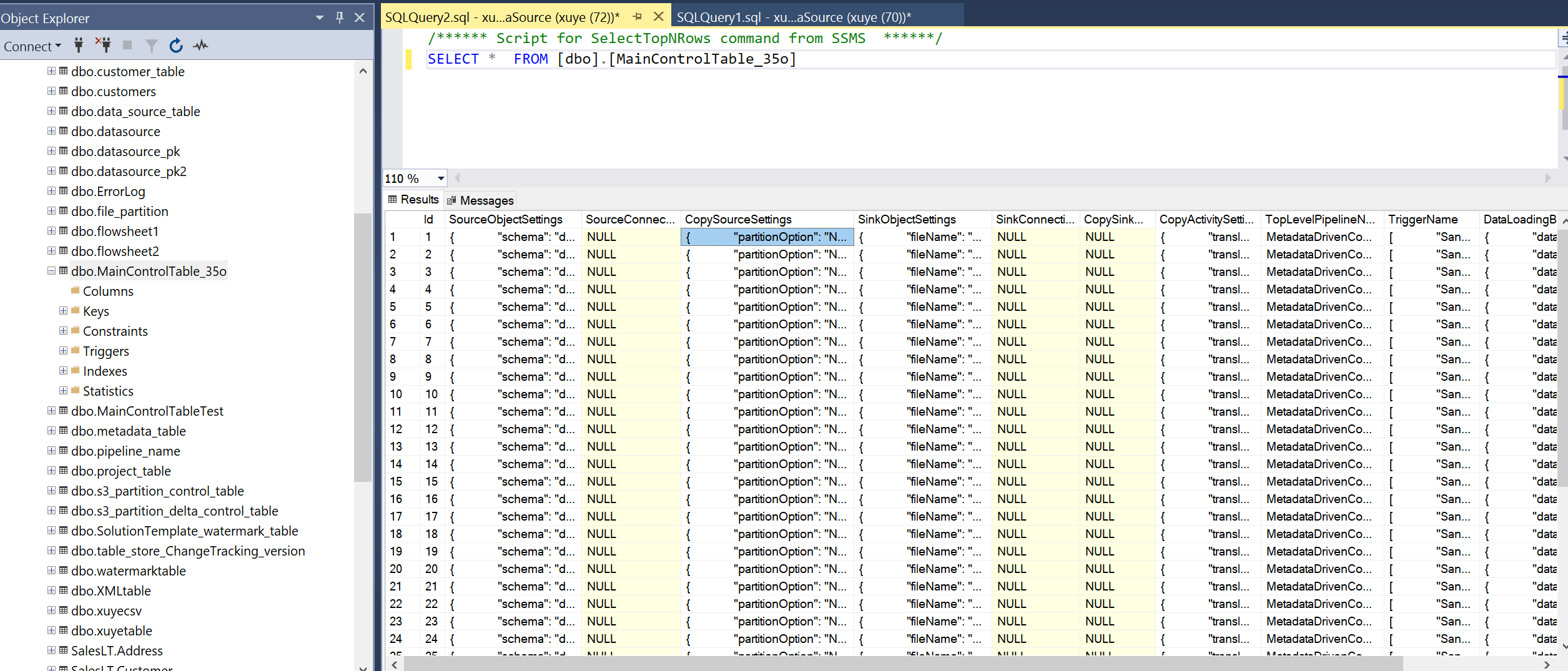
Table de contrôle de connexion

Revenez au portail ADF pour afficher et déboguer les pipelines. Vous verrez un dossier créé en nommant « MetadataDrivenCopyTask_### ###### ». Cliquez sur le nom du pipeline avec « MetadataDrivenCopyTask###_TopLevel », puis cliquez sur debug run.
Vous devez entrer les paramètres suivants :
Nom des paramètres Description MaxNumberOfConcurrentTasks Vous pouvez toujours modifier le nombre maximal d’activités de copie simultanées exécutées avant l’exécution du pipeline. La valeur par défaut est celle que vous entrez dans l’outil Copier les données. MainControlTableName Vous pouvez toujours modifier le nom de la table de contrôle principale afin que le pipeline récupère les métadonnées de cette table avant l’exécution. ConnectionControlTableName Vous pouvez toujours modifier le nom de la table de contrôle de connexion (facultatif) de sorte que le pipeline obtiendra les métadonnées relatives à la connexion du magasin de données avant l’exécution. MaxNumberOfObjectsReturnedFromLookupActivity Afin d’éviter d’atteindre la limite de l’activité de recherche en sortie, il est possible de définir le nombre maximum d’objets renvoyés par l’activité de recherche. Dans la plupart des cas, la modification de la valeur par défaut n’est pas nécessaire. windowStart Lorsque vous saisissez une valeur dynamique (par exemple, aaaa/mm/jj) comme chemin d’accès au dossier, le paramètre permet de transmettre l’heure de déclenchement actuelle au pipeline afin de remplir le chemin dynamique d’accès au dossier. Lorsque le pipeline est déclenché par un déclencheur de planification ou un déclencheur de fenêtre bascule, les utilisateurs n’ont pas besoin d’entrer la valeur de ce paramètre. Exemple de valeur : 2021-01-25T01:49:28Z Activez le déclencheur pour rendre les pipelines opérationnels.
Mettre à jour la table de contrôle par l’outil Copier des données
Vous pouvez toujours mettre à jour directement la table de contrôle en ajoutant ou en supprimant l’objet à copier ou en modifiant le comportement de copie pour chaque table. Nous créons également une expérience d’interface utilisateur dans l’outil Copier les données pour faciliter la modification de la table de contrôle.
Cliquez avec le bouton droit sur le pipeline de niveau supérieur : MetadataDrivenCopyTask_xxx_TopLevel, puis sélectionnez Modifier la table de contrôle.
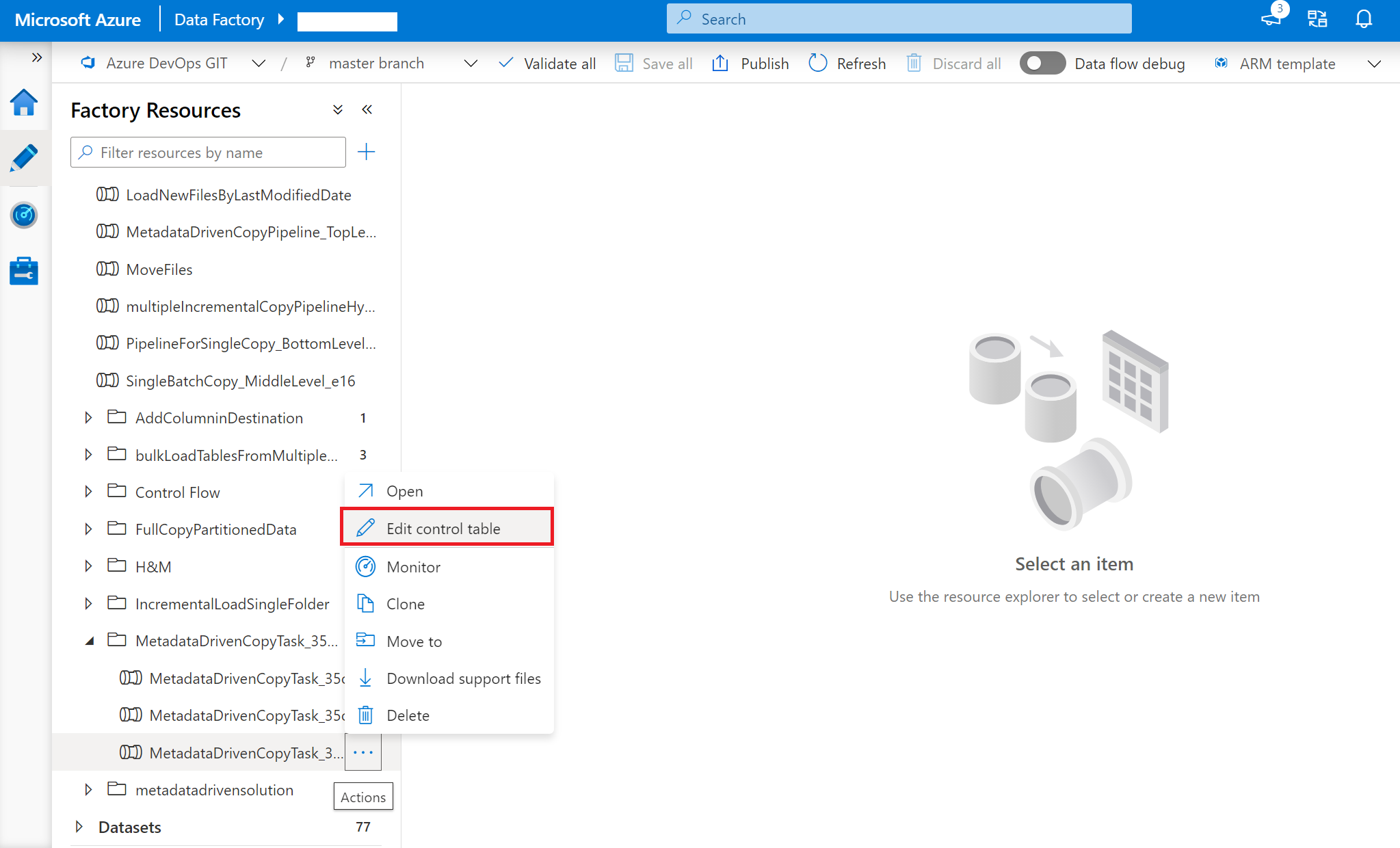
Sélectionnez des lignes dans la table de contrôle à modifier.
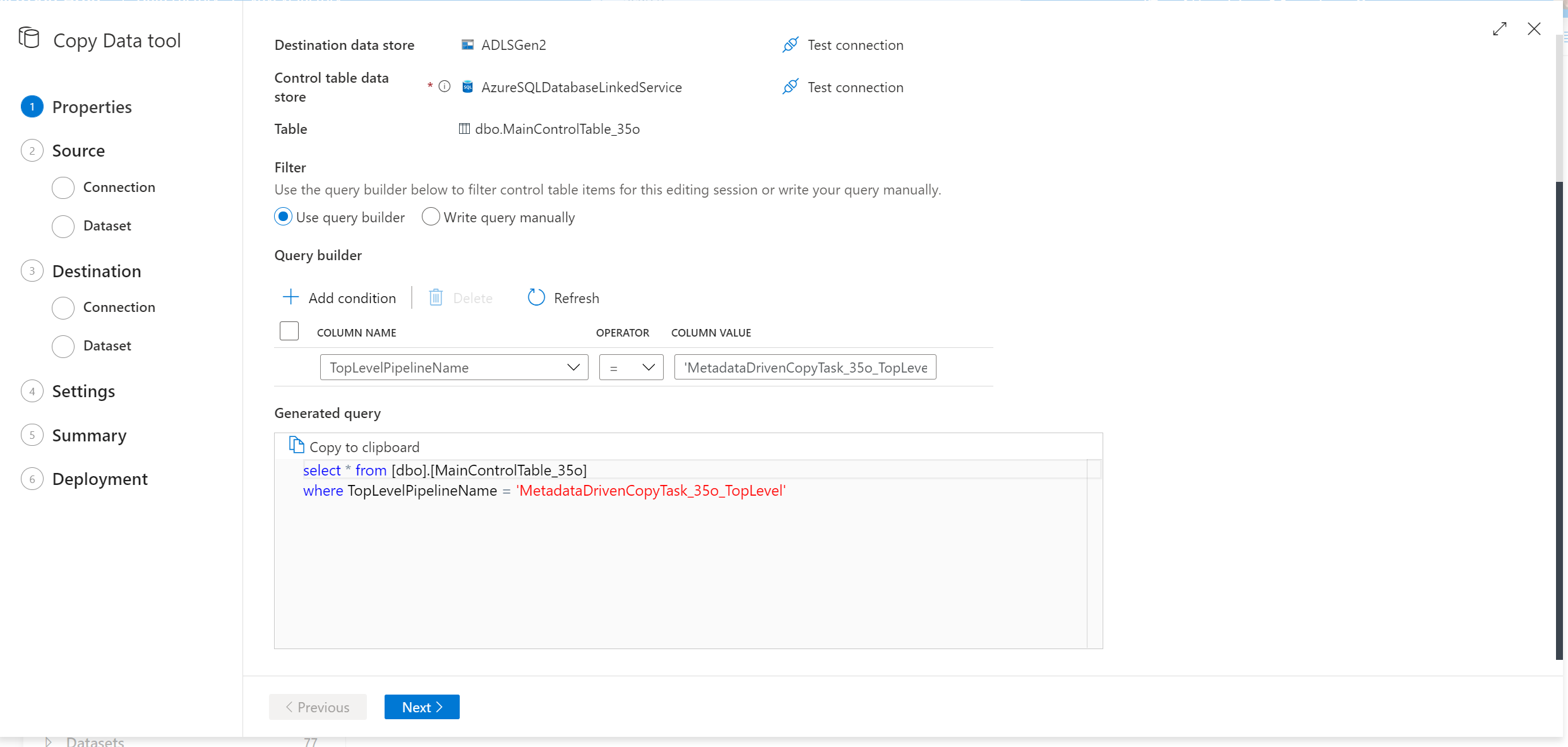
Passez par l’outil Copier les données, qui vous proposera un nouveau script SQL. Réexécutez le script SQL pour mettre à jour votre table de contrôle.
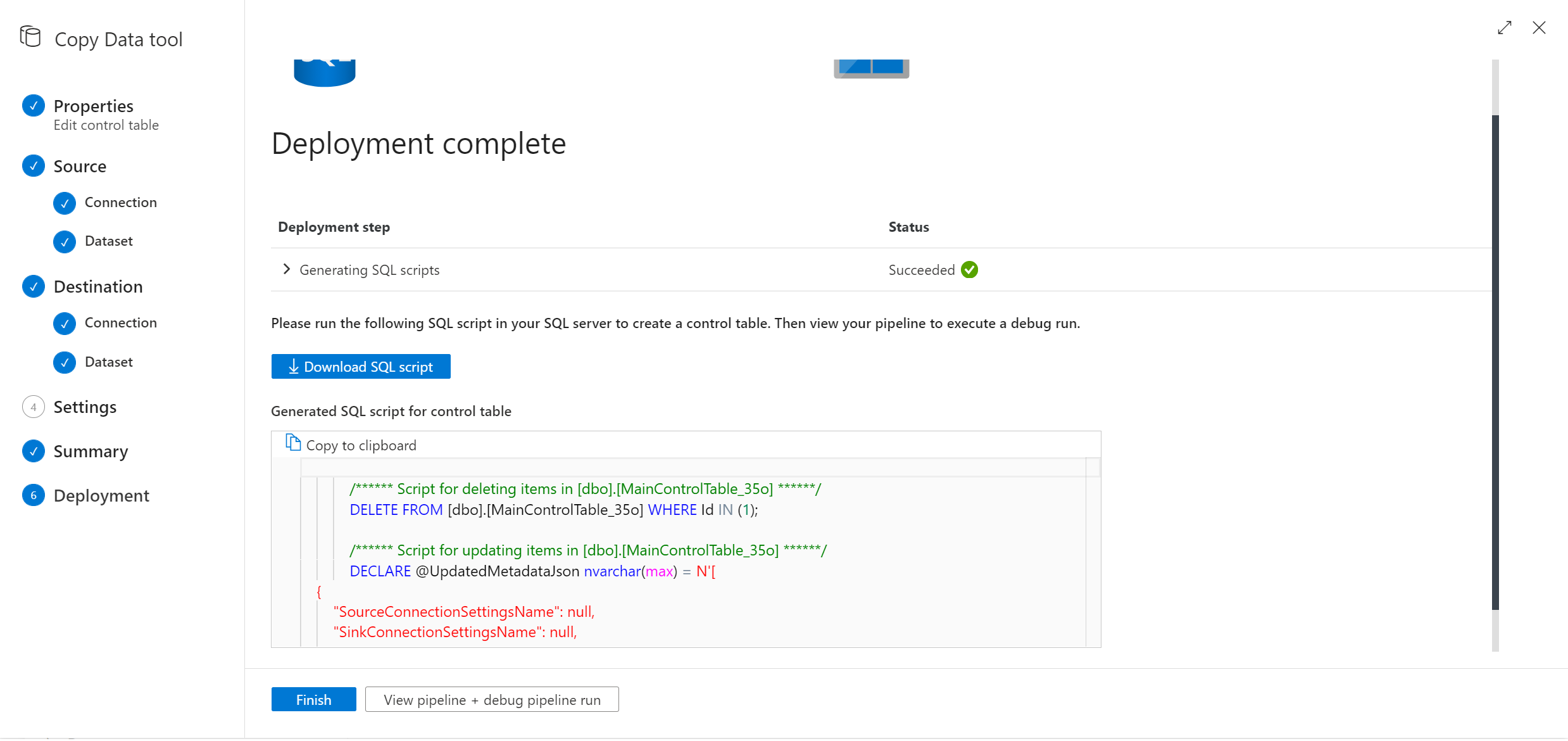
Remarque
Le pipeline ne sera pas redéployé. Le nouveau script SQL créé vous aide à mettre à jour la table de contrôle uniquement.
Tables de contrôle
Table de contrôle principale
Chaque ligne de la table de contrôle contient les métadonnées d’un objet (par exemple, une table) à copier.
| Nom de la colonne | Description |
|---|---|
| id | ID unique de l’objet à copier. |
| SourceObjectSettings | Métadonnées du jeu de données source. Il peut s’agir d’un nom de schéma, d’un nom de table, etc. En voici un exemple. |
| SourceConnectionSettingsName | Nom du paramètre de connexion source dans la table de contrôle de connexion. Ce nom est facultatif. |
| CopySourceSettings | Métadonnées de la propriété source dans l’activité de copie. Il peut s’agir de requêtes, de partitions, etc. En voici un exemple. |
| SinkObjectSettings | Métadonnées du jeu de données de destination. Il peut s’agir d’un nom de fichier, d’un chemin de dossier, d’un nom de table, etc. En voici un exemple. Si le chemin d’accès au dossier dynamique est spécifié, la valeur de la variable ne sera pas écrite ici dans la table de contrôle. |
| SinkConnectionSettingsName | Nom du paramètre de connexion de destination dans la table de contrôle de connexion. Ce nom est facultatif. |
| CopySinkSettings | Métadonnées de la propriété de récepteur dans l’activité de copie. Il peut s’agir de preCopyScript, tableOption, etc. Voici un exemple. |
| CopyActivitySettings | Métadonnées de la propriété Translator dans l’activité de copie. Permet de définir le mappage de colonnes. |
| TopLevelPipelineName | Nom du pipeline supérieur, qui peut copier cet objet. |
| TriggerName | Nom du déclencheur, qui peut déclencher le pipeline pour copier cet objet. Si le débogage s’exécute, le nom est Sandbox. En cas d’exécution manuelle, le nom est Manuel. Si l’exécution est planifiée, le nom est le nom du déclencheur associé. Il peut s’agir d’entrer plusieurs noms. |
| DataLoadingBehaviorSettings | Charge totale et charge Delta. |
| TaskId | Ordre des objets à copier à la suite de la valeur TaskId dans la table de contrôle (ORDER BY [TaskId] DESC). Si vous avez d’énormes quantités d’objets à copier, mais que vous ne disposez que d’un nombre limité de copies simultanées autorisées, vous pouvez modifier le TaskId pour chaque objet afin de déterminer les objets qui peuvent être copiés précédemment. La valeur par défaut est 0. |
| CopyEnabled | Spécifie si l’élément est activé dans le processus d’ingestion de données. Valeurs autorisées : 1 (activé), 0 (désactivé). La valeur par défaut est 1. |
Table de contrôle de connexion
Chaque ligne de la table de contrôle contient un paramètre de connexion pour le magasin de données.
| Nom de la colonne | Description |
|---|---|
| Nom | Nom de la connexion paramétrable dans la table de contrôle principale. |
| ConnectionSettings | Paramètres de connexion. Il peut s’agir du nom de la base de données, du nom du serveur, etc. |
Pipelines
Vous verrez trois niveaux de pipelines générés par l’outil Copier des données.
MetadataDrivenCopyTask_xxx_TopLevel
Ce pipeline calcule le nombre total d’objets (tables, etc.) qui doivent être copiés dans cette exécution, détermine le nombre de lots séquentiels en fonction de la tâche de copie simultanée maximale autorisée, puis exécute un autre pipeline pour copier des lots différents séquentiellement.
Paramètres
| Nom des paramètres | Description |
|---|---|
| MaxNumberOfConcurrentTasks | Vous pouvez toujours modifier le nombre maximal d’activités de copie simultanées exécutées avant l’exécution du pipeline. La valeur par défaut est celle que vous entrez dans l’outil Copier les données. |
| MainControlTableName | Nom de table de la table de contrôle principale. Le pipeline récupère les métadonnées de cette table avant de s'exécuter. |
| ConnectionControlTableName | Nom de table de la table de contrôle de connexion (facultatif). Le pipeline obtient les métadonnées relatives à la connexion du magasin de données avant l’exécution |
| MaxNumberOfObjectsReturnedFromLookupActivity | Afin d’éviter d’atteindre la limite de l’activité de recherche en sortie, il est possible de définir le nombre maximum d’objets renvoyés par l’activité de recherche. Dans la plupart des cas, la modification de la valeur par défaut n’est pas nécessaire. |
| windowStart | Lorsque vous saisissez une valeur dynamique (par exemple, aaaa/mm/jj) comme chemin d’accès au dossier, le paramètre permet de transmettre l’heure de déclenchement actuelle au pipeline afin de remplir le chemin dynamique d’accès au dossier. Lorsque le pipeline est déclenché par un déclencheur de planification ou un déclencheur de fenêtre bascule, les utilisateurs n’ont pas besoin d’entrer la valeur de ce paramètre. Exemple de valeur : 2021-01-25T01:49:28Z |
Activités
| Nom de l’activité | Type d’activité | Description |
|---|---|---|
| GetSumOfObjectsToCopy | Recherche | Calculez le nombre total d’objets (tables, etc.) qui doivent être copiés dans cette série. |
| CopyBatchesOfObjectsSequentially | ForEach | Trouvez le nombre de lots séquentiels basés sur le nombre maximal de tâches de copie simultanées autorisées, puis exécutez un autre pipeline pour copier séquentiellement des lots différents. |
| CopyObjectsInOneBtach | Exécuter le pipeline | Exécutez un autre pipeline pour copier un lot d’objets. Les objets appartenant à ce lot seront copiés en parallèle. |
MetadataDrivenCopyTask_xxx_ MiddleLevel
Ce pipeline copie un lot d’objets. Les objets appartenant à ce lot seront copiés en parallèle.
Paramètres
| Nom des paramètres | Description |
|---|---|
| MaxNumberOfObjectsReturnedFromLookupActivity | Afin d’éviter d’atteindre la limite de l’activité de recherche en sortie, il est possible de définir le nombre maximum d’objets renvoyés par l’activité de recherche. Dans la plupart des cas, la modification de la valeur par défaut n’est pas nécessaire. |
| TopLevelPipelineName | Nom du pipeline de couche supérieure. |
| TriggerName | Nom du déclencheur. |
| CurrentSequentialNumberOfBatch | ID du lot séquentiel. |
| SumOfObjectsToCopy | Nombre total d’objets à copier. |
| SumOfObjectsToCopyForCurrentBatch | Nombre d’objets à copier dans le lot actuel. |
| MainControlTableName | Nom de la table de contrôle principale. |
| ConnectionControlTableName | Nom de la table de contrôle de connexion. |
Activités
| Nom de l’activité | Type d’activité | Description |
|---|---|---|
| DivideOneBatchIntoMultipleGroups | ForEach | Divisez les objets d’un lot en plusieurs groupes parallèles afin d’éviter d’atteindre la limite de sortie de l’activité de recherche. |
| GetObjectsPerGroupToCopy | Recherche | Obtient les objets (tables, etc.) à partir de la table de contrôle qui doivent être copiés dans ce groupe. Ordre des objets à copier à la suite de la valeur TaskId dans la table de contrôle (ORDER BY [TaskId] DESC). |
| CopyObjectsInOneGroup | Exécuter le pipeline | Exécutez un autre pipeline pour copier des objets d’un groupe. Les objets appartenant à ce lot seront copiés en parallèle. |
MetadataDrivenCopyTask_xxx_ BottomLevel
Ce pipeline copie les objets d’un groupe. Les objets appartenant à ce lot seront copiés en parallèle.
Paramètres
| Nom des paramètres | Description |
|---|---|
| ObjectsPerGroupToCopy | Nombre d’objets à copier dans le groupe actuel. |
| ConnectionControlTableName | Nom de la table de contrôle de connexion. |
| windowStart | Il permet de transmettre la durée de déclenchement actuelle au pipeline afin de remplir le chemin de dossier dynamique s’il est configuré par l’utilisateur. |
Activités
| Nom de l’activité | Type d’activité | Description |
|---|---|---|
| ListObjectsFromOneGroup | ForEach | Répertoriez les objets d’un groupe et itérez chacun d’eux sur les activités en aval. |
| RouteJobsBasedOnLoadingBehavior | Commutateur | Vérifiez le comportement de chargement de chaque objet. S’il s’agit d’une valeur par défaut ou d’un cas FullLoad, effectuez une charge complète. S’il s’agit d’un cas DeltaLoad, effectuez un chargement incrémentiel via la colonne de filigrane pour identifier les modifications |
| FullLoadOneObject | Copier | Prenez un instantané complet sur cet objet et copiez-le dans la destination. |
| DeltaLoadOneObject | Copier | Copiez les données modifiées uniquement depuis la dernière fois via la comparaison de la valeur dans la colonne de filigrane pour identifier les modifications. |
| GetMaxWatermarkValue | Recherche | Interrogez l’objet source pour obtenir la valeur maximale de la colonne de filigrane. |
| UpdateWatermarkColumnValue | StoreProcedure | Réécrivez la nouvelle valeur de filigrane pour contrôler la table à utiliser la prochaine fois. |
Limitations connues
- Le nom du runtime d’intégration, du type de base de données, du type de fichier ne peut pas être paramétré dans ADF. Par exemple, si vous souhaitez ingérer des données à la fois à partir d’Oracle Server et de SQL Server, vous avez besoin de deux pipelines paramétrables différents. Toutefois, la table de contrôle unique peut être partagée par deux ensembles de pipelines.
- OPENJSON est utilisé dans les scripts SQL générés par l’outil copier les données. Si vous utilisez SQL Server pour héberger la table de contrôle, celle-ci doit être SQL Server 2016 (13.x) et versions ultérieures afin de prendre en charge la fonction OPENJSON.
Contenu connexe
Essayez ces didacticiels qui utilisent l’outil Copier des données :