Créer votre premier workflow avec un travail Azure Databricks
Cet article présente un travail Azure Databricks qui orchestre des tâches afin de lire et de traiter un exemple de jeu de données. Dans ce guide de démarrage rapide, vous allez :
- Créez un nouveau notebook et ajoutez du code pour récupérer un exemple de jeu de données contenant des noms de bébé populaires par année.
- Enregistrez le jeu de données d’exemple dans Unity Catalog.
- Créez un nouveau notebook et ajoutez du code pour lire le jeu de données depuis Unity Catalog, le filtrer par année et afficher les résultats.
- Créez un nouveau travail et configurez deux tâches à l’aide des notebooks.
- Exécutez le travail et affichez les résultats.
Spécifications
Si votre espace de travail est compatible avec Unity Catalog et que l’option Flux de travail serverless est activé, la tâche est exécutée par défaut sur un calcul serverless. Vous n’avez pas besoin d’autorisation de création de cluster pour exécuter votre tâche avec le calcul serverless.
Dans le cas contraire, vous devez disposer d’une autorisation de création de clusterpour créer un calcul de tâches ou des autorisations pour des ressources de calcul polyvalentes.
Vous devez disposer d’un volume dans Unity Catalog. Cet article utilise un volume nommé my-volume dans un schéma nommé default dans un catalogue nommé main. Vous devez également disposer des autorisations suivantes dans Unity Catalog :
READ VOLUMEetWRITE VOLUME, ouALL PRIVILEGES, pour le volumemy-volume.USE SCHEMAouALL PRIVILEGESpour le schémadefault.USE CATALOGouALL PRIVILEGESpour le cataloguemain.
Pour définir ces autorisations, contactez votre administrateur Databricks ou consultez Privilèges et objets sécurisables dans Unity Catalog.
Créer les notebooks
Récupérer et enregistrer des données
Pour créer un notebook afin de récupérer l’exemple de jeu de données et le sauvegarder dans Unity Catalog :
Accédez à la page d’arrivée Azure Databricks, cliquez sur
 Nouveau dans la barre latéral, puis sélectionnez Notebook. Databricks crée et ouvre un notebook vide dans votre dossier par défaut. La langage par défaut est celui que vous avez utilisé en dernier, et le notebook est automatiquement attaché à la ressource de calcul que vous avez utilisée en dernier.
Nouveau dans la barre latéral, puis sélectionnez Notebook. Databricks crée et ouvre un notebook vide dans votre dossier par défaut. La langage par défaut est celui que vous avez utilisé en dernier, et le notebook est automatiquement attaché à la ressource de calcul que vous avez utilisée en dernier.Si nécessaire, choisissez Python comme langage par défaut.
Copiez le code Python suivant et collez-le dans la première cellule du notebook.
import requests response = requests.get('https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv') csvfile = response.content.decode('utf-8') dbutils.fs.put("/Volumes/main/default/my-volume/babynames.csv", csvfile, True)
Lire et afficher des données filtrées
Pour créer un notebook afin de lire et de présenter les données à filtrer
Accédez à la page d’arrivée Azure Databricks, cliquez sur
Nouveau dans la barre latéral, puis sélectionnez Notebook. Databricks crée et ouvre un notebook vide dans votre dossier par défaut. La langage par défaut est celui que vous avez utilisé en dernier, et le notebook est automatiquement attaché à la ressource de calcul que vous avez utilisée en dernier.Si nécessaire, choisissez Python comme langage par défaut.
Copiez le code Python suivant et collez-le dans la première cellule du notebook.
babynames = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/Volumes/main/default/my-volume/babynames.csv") babynames.createOrReplaceTempView("babynames_table") years = spark.sql("select distinct(Year) from babynames_table").toPandas()['Year'].tolist() years.sort() dbutils.widgets.dropdown("year", "2014", [str(x) for x in years]) display(babynames.filter(babynames.Year == dbutils.widgets.get("year")))
Créer un travail
Cliquez sur
 Workflows dans la barre latérale.
Workflows dans la barre latérale.Cliquez sur
 .
.L’onglet Tasks s’affiche avec la boîte de dialogue de création de tâche.
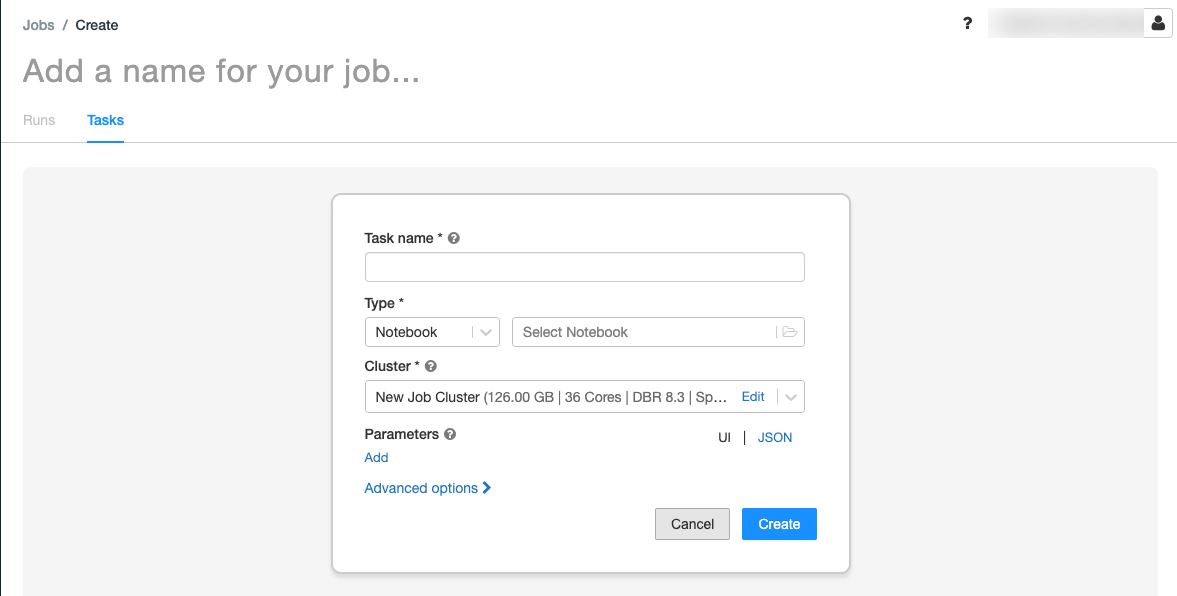
Remplacez Add a name for your job… (Ajoutez un nom pour votre travail) par le nom de votre travail.
Dans le champ Task name, entrez un nom pour la tâche, par exemple récupérer-noms-bébés.
Dans le menu déroulant Type, sélectionnez Notebook .
Utilisez l’Explorateur de fichiers pour rechercher le premier notebook que vous avez créé, cliquez sur le nom du notebook, puis cliquez sur Confirm.
Cliquez sur Create task.
Cliquez sur
 sous la tâche que vous venez de créer pour ajouter une autre tâche.
sous la tâche que vous venez de créer pour ajouter une autre tâche.Dans le champ Task name, entrez un nom pour la tâche, par exemple filtrer-noms-bébés.
Dans le menu déroulant Type, sélectionnez Notebook .
Utilisez l’Explorateur de fichiers pour rechercher le deuxième notebook que vous avez créé, cliquez sur le nom du notebook, puis cliquez sur Confirm.
Cliquez sur Add sous Parameters. Dans le champ Key, entrez
year. Dans le champ Value, entrez2014.Cliquez sur Create task.
Exécuter le travail
Pour exécuter le travail immédiatement, cliquez sur  en haut à droite. Vous pouvez également exécuter le travail en cliquant sur l’onglet Runs, puis sur Run Now dans la table Active Runs.
en haut à droite. Vous pouvez également exécuter le travail en cliquant sur l’onglet Runs, puis sur Run Now dans la table Active Runs.
Afficher les détails de l’exécution
Cliquez sur l’onglet Runs, puis sur le lien pour l’exécution dans la table Active Runs ou la table Completed Runs (past 60 days).
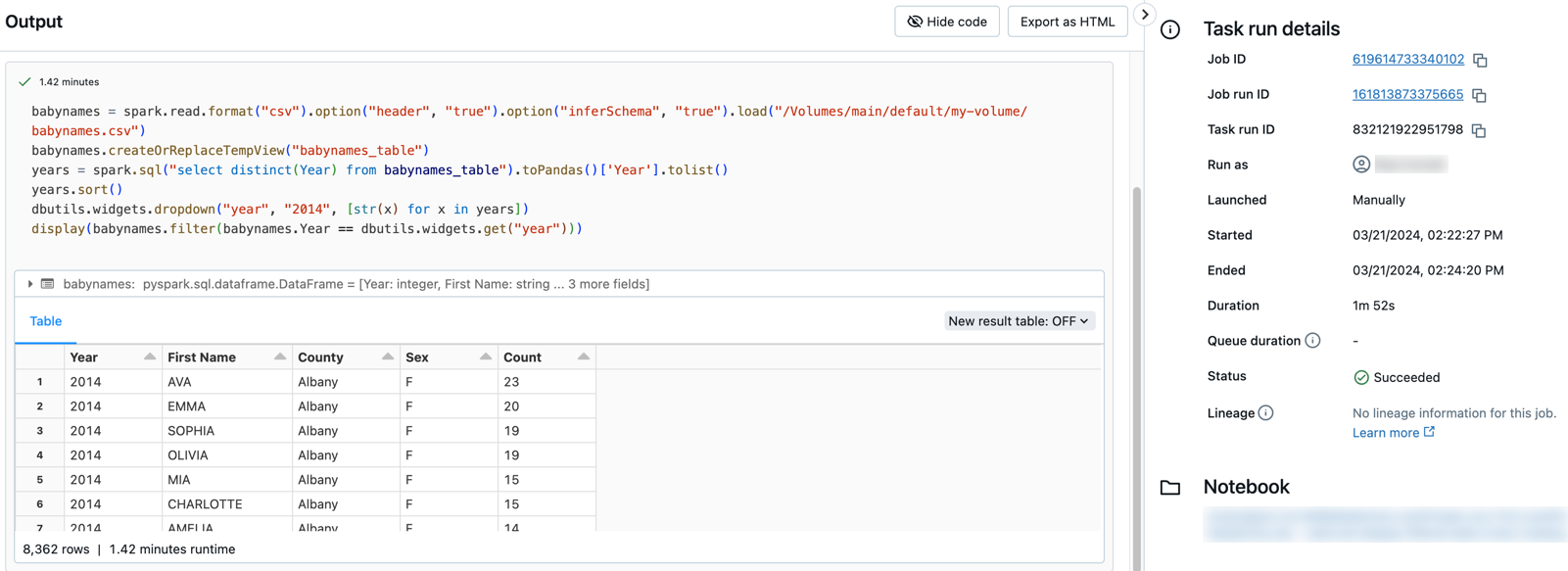
Cliquez sur l’une des tâches pour voir la sortie et les détails. Par exemple, cliquez sur la tâche filtrer-noms-bébés pour voir la sortie et les détails d’exécution de la tâche de filtre :
Exécuter avec des paramètres différents
Pour réexécuter le travail et filtrer les noms des bébés pour une autre année :
- Cliquez sur
 en regard de Run Now et sélectionnez Run Now with Different Parameters ou cliquez sur Run Now with Different Parameters dans la table Active Runs.
en regard de Run Now et sélectionnez Run Now with Different Parameters ou cliquez sur Run Now with Different Parameters dans la table Active Runs. - Dans le champ Value, entrez
2015. - Cliquez sur Exécuter.