Présentation de Databricks Lakehouse Monitoring
Important
Cette fonctionnalité est disponible en préversion publique.
Cet article décrit Databricks Lakehouse Monitoring. Il décrit les avantages de l’analyse de vos données et donne une vue d’ensemble des composants et de l’utilisation de Databricks Lakehouse Monitoring.
Databricks Lakehouse Monitoring vous permet d’analyser les propriétés statistiques et la qualité des données dans toutes les tables de votre compte. Vous pouvez également l’utiliser pour suivre les performances des modèles Machine Learning et des points de terminaison de service de modèle en analysant les tables d’inférence qui contiennent les entrées et les prévisions du modèle. Le diagramme montre le flux de données via les pipelines de données et ML dans Databricks, ainsi que la façon dont vous pouvez utiliser l’analyse pour suivre en continu la qualité des données et les performances des modèles.

Pourquoi utiliser Databricks Lakehouse Monitoring ?
Pour tirer des insights utiles de vos données, vous devez avoir confiance en la qualité de vos données. La surveillance de vos données fournit des mesures quantitatives qui vous aident à suivre et à confirmer la qualité et la cohérence de vos données au fil du temps. Lorsque vous détectez des modifications dans la distribution des données de votre table ou les performances du modèle correspondant, les tables créées par Databricks Lakehouse Monitoring peuvent capturer et vous avertir de la modification et vous aider à en identifier la cause.
Databricks Lakehouse Monitoring vous aide à répondre à des questions telles que les suivantes :
- À quoi ressemble l’intégrité des données et comment change-t-elle au fil du temps ? Par exemple, quelle est le pourcentage de valeurs nulles ou zéro dans les données actuelles et a-t-il augmenté ?
- À quoi ressemble la distribution statistique des données et comment change-t-elle au fil du temps ? Par exemple, quel est le 90e centile d’une colonne numérique ? Ou, quelle est la distribution des valeurs dans une colonne catégorielle et en quoi diffère-t-elle d’hier ?
- Existe-t-il une dérive entre les données actuelles et une base de référence connue, ou entre les fenêtres de temps successives des données ?
- À quoi ressemble la distribution statistique ou la dérive d’un sous-ensemble ou d’une tranche de données ?
- Comment les entrées et les prédictions de modèle ML évoluent-elles au fil du temps ?
- Comment les performances du modèle évoluent-elles au fil du temps ? La version A du modèle est-elle plus performante que la version B ?
En outre, Databricks Lakehouse Monitoring vous permet de contrôler la granularité temporelle des observations et de configurer des métriques personnalisées.
Spécifications
Les éléments suivants sont requis pour utiliser Databricks Lakehouse Monitoring :
- Votre espace de travail doit être activé pour Unity Catalog et vous devez avoir accès à Databricks SQL.
- Pour la supervision, seules les tables Delta, y compris les tables managées, les tables externes, les vues, les vues matérialisées et les tables de diffusion en continu sont prises en charge. Les analyses créées à partir de vues matérialisées et de tables de diffusion en continu ne prennent pas en charge le traitement incrémentiel.
- Toutes les régions ne sont pas prises en charge. Pour la prise en charge régionale, consultez Régions Azure Databricks.
Remarque
Databricks Lakehouse Monitoring utilise le calcul serverless pour les flux de travail. Pour plus d’informations sur le suivi des dépenses de Lakehouse Monitoring, consultez Afficher les dépenses de Lakehouse Monitoring.
Fonctionnement de Lakehouse Monitoring sur Databricks
Pour surveiller une table dans Databricks, vous créez un moniteur attaché à la table. Pour surveiller les performances d’un modèle Machine Learning, vous attachez le moniteur à une table d’inférence qui contient les entrées du modèle et les prédictions correspondantes.
Databricks Lakehouse Monitoring fournit les types d’analyse suivants : série chronologique, instantané et inférence.
| Type de profil | Description |
|---|---|
| série chronologique | À utiliser pour les tables contenant un jeu de données de série chronologique basé sur une colonne timestamp. Le monitoring calcule les métriques de qualité des données sur des fenêtres temporelles de la série chronologique. |
| Inférence | À utiliser pour les tables contenant le journal des requêtes d’un modèle. Chaque ligne est une requête, avec des colonnes pour le timestamp, les entrées du modèle, la prédiction correspondante et, en option, l’étiquette de vérité au sol. Le monitoring compare les métriques de performances du modèle et de qualité des données sur des fenêtres temporelles du journal des requêtes. |
| Instantané | À utiliser pour tous les autres types de tables. Le monitoring calcule les métriques de qualité des données sur toutes les données de la table. La table complète est traitée à chaque actualisation. |
Cette section décrit brièvement les tables d’entrée utilisées par Databricks Lakehouse Monitoring et les tables de métriques qu’il produit. Le diagramme montre la relation entre les tables d’entrée, les tables de métriques, le moniteur et le tableau de bord.
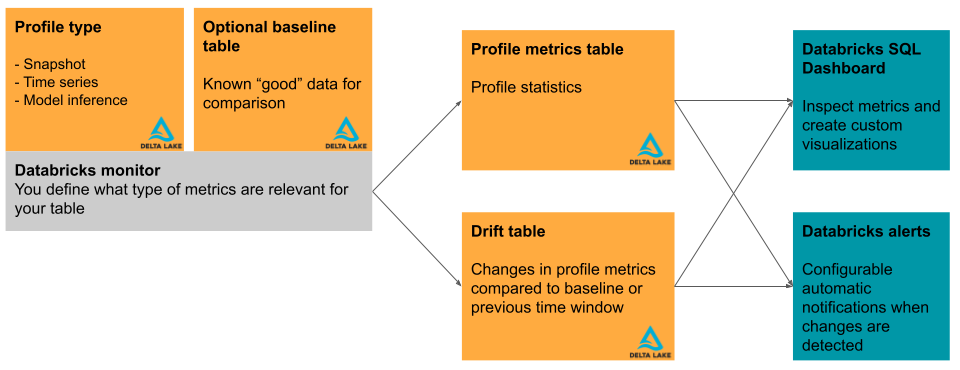
Table primaire et table de base
En plus de la table à surveiller, appelée « table primaire », vous pouvez éventuellement spécifier une table de base à utiliser comme référence pour mesurer la dérive ou la modification des valeurs au fil du temps. Une table de base est utile lorsque vous disposez d’un exemple de ce à quoi vos données doivent ressembler. L’idée est que la dérive est ensuite calculée par rapport aux valeurs et distributions de données attendues.
La table de base doit contenir un jeu de données qui reflète la qualité attendue des données d’entrée, en termes de distributions statistiques, de distributions de colonnes individuelles, de valeurs manquantes et d’autres caractéristiques. Il doit correspondre au schéma de la table surveillée. L’exception est la colonne timestamp pour les tables utilisées avec des profils de série chronologique ou d’inférence. Si des colonnes sont manquantes dans la table primaire ou la table de base, la surveillance utilise l’heuristique du meilleur effort pour calculer les métriques de sortie.
Pour les moniteurs qui utilisent un profil instantané, la table de base doit contenir un instantané des données où la distribution représente une norme de qualité acceptable. Par exemple, sur des données de distribution de notes, vous pouvez définir la base de référence sur une classe précédente où les notes étaient distribuées uniformément.
Pour les moniteurs qui utilisent un profil de série chronologique, la table de référence doit contenir des données qui représentent une ou des fenêtres de temps où les distributions de données représentent une norme de qualité acceptable. Par exemple, sur les données météorologiques, vous pouvez définir la base de référence sur une semaine, un mois ou une année où la température était proche des températures normales attendues.
Pour les moniteurs qui utilisent un profil d’inférence, les données utilisées pour entraîner ou valider le modèle surveillé constituent un bon choix pour une base de référence. De cette façon, les utilisateurs peuvent être alertés quand les données ont dérivé par rapport à ce sur quoi le modèle a été entraîné et validé. Cette table doit contenir les mêmes colonnes de caractéristiques que la table primaire, et doit également avoir le même model_id_col que celui spécifié pour InferenceLog dans la table primaire afin que les données soient agrégées de manière cohérente. Dans l’idéal, le jeu de test ou de validation utilisé pour évaluer le modèle doit être utilisé pour garantir des métriques de qualité de modèle comparables.
Tables de métriques et tableau de bord
Un moniteur de table crée deux tables de métriques et un tableau de bord. Les valeurs de métriques sont calculées pour l’ensemble de la table et pour les fenêtres de temps et les sous-ensembles de données (ou « tranches ») que vous spécifiez lorsque vous créez le moniteur. En outre, pour l’analyse de l’inférence, les métriques sont calculées pour chaque ID de modèle. Pour plus d’informations sur les tables de métriques, consultez Tables de métriques du moniteur.
- La table de métriques de profil contient des statistiques récapitulatives. Consultez le schéma de table de métriques de profil.
- La table de métriques de dérive contient des statistiques relatives à la dérive des données au fil du temps. Si une table de référence est fournie, la dérive est également surveillée par rapport aux valeurs de base. Consultez le schéma de table de métriques de dérive.
Les tables de métriques sont des tables Delta stockées dans un schéma Unity Catalog que vous spécifiez. Vous pouvez afficher ces tables à l’aide de l’interface utilisateur Databricks, les interroger à l’aide de Databricks SQL et créer des tableaux de bord et des alertes en fonction de celles-ci.
Pour chaque moniteur, Databricks crée automatiquement un tableau de bord pour vous aider à visualiser et à présenter les résultats du moniteur. Le tableau de bord est entièrement personnalisable comme tout autre tableau de bord hérité.
Commencer à utiliser Lakehouse Monitoring sur Databricks
Pour démarrer, consultez les articles suivants :
- Créer un moniteur à l’aide de l’interface utilisateur Databricks.
- Créer un moniteur à l’aide de l’API.
- Comprendre les tables de métriques du moniteur.
- Utiliser le tableau de bord du moniteur.
- Créer des alertes SQL basées sur un moniteur.
- Créer des métriques personnalisées.
- Surveillance des points de terminaison de service de modèle.
- Surveiller l’impartialité et le biais des modèles de classification.
- Consultez les documents de référence pour l’API Databricks Lakehouse Monitoring.
- Exemples de notebooks.