Exemple de Registre des modèles d’espaces de travail
Notes
Cette documentation concerne le Registre des modèles d’espaces de travail. Azure Databricks recommande l’utilisation des modèles dans Unity Catalog. Les modèles dans Unity Catalog fournissent une gouvernance de modèles centralisée, un accès à travers les espaces de travail, une traçabilité et des déploiements. Le Registre des modèles d’espace de travail sera déconseillé à l’avenir.
Cet exemple illustre comment utiliser Workspace Model Registry pour créer une application d'apprentissage automatique qui prévoit la puissance de sortie quotidienne d'un parc éolien. Cet exemple indique comment effectuer les opérations suivantes :
- Suivre et journaliser des modèles avec MLflow
- Inscrire des modèles dans le registre des modèles
- Désinscrire des modèles et créer des transitions échelonnées de version de modèle
- Intégrer des modèles inscrits avec des applications de production
- Rechercher et découvrir des modèles dans le registre de modèles
- Archiver et supprimer des modèles
L’article explique comment accomplir ces étapes à l’aide des interfaces utilisateur et APIS de MLflow Tracking et du Registre de modèles MLflow.
Pour un notebook accomplissant toutes ces étapes à l’aide des API de MLflow Tracking et du Registre, consultez l’exemple de notebook Registre de modèles.
Charger un jeu de données, effectuer l'apprentissage d’un modèle et suivre avec MLflow Tracking
Avant de pouvoir inscrire un modèle dans le Registre de modèles, vous devez effectuer l'apprentissage la journalisation du modèle pendant un cycle d’expérimentation. Cette section montre comment charger le jeu de données du parc éolien, effectuer l'apprentissage un modèle et journaliser le cycle d’apprentissage sur MLflow.
Charger un jeu de données
Le code suivant charge un jeu de données contenant des données météorologiques et des informations sur la production d’énergie d’un parc éolien aux États-Unis. Le jeu de données contient des métriques wind direction, wind speed et air temperature échantillonnées toutes les six heures (à 00:00, 08:00 et 16:00), ainsi qu’une production d’énergie agrégée quotidienne (power) sur plusieurs années.
import pandas as pd
wind_farm_data = pd.read_csv("https://github.com/dbczumar/model-registry-demo-notebook/raw/master/dataset/windfarm_data.csv", index_col=0)
def get_training_data():
training_data = pd.DataFrame(wind_farm_data["2014-01-01":"2018-01-01"])
X = training_data.drop(columns="power")
y = training_data["power"]
return X, y
def get_validation_data():
validation_data = pd.DataFrame(wind_farm_data["2018-01-01":"2019-01-01"])
X = validation_data.drop(columns="power")
y = validation_data["power"]
return X, y
def get_weather_and_forecast():
format_date = lambda pd_date : pd_date.date().strftime("%Y-%m-%d")
today = pd.Timestamp('today').normalize()
week_ago = today - pd.Timedelta(days=5)
week_later = today + pd.Timedelta(days=5)
past_power_output = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(today)]
weather_and_forecast = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(week_later)]
if len(weather_and_forecast) < 10:
past_power_output = pd.DataFrame(wind_farm_data).iloc[-10:-5]
weather_and_forecast = pd.DataFrame(wind_farm_data).iloc[-10:]
return weather_and_forecast.drop(columns="power"), past_power_output["power"]
Effectuer l'apprentissage du modèle
Le code suivant effectue l'apprentissage d’un réseau neural en utilisant TensorFlow Keras pour prédire la production d’énergie en fonction des caractéristiques météorologiques contenues dans le jeu de données. MLflow est utilisé pour suivre les hyperparamètres, les métriques de performances, le code source et les artefacts du modèle.
def train_keras_model(X, y):
import tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(100, input_shape=(X_train.shape[-1],), activation="relu", name="hidden_layer"))
model.add(Dense(1))
model.compile(loss="mse", optimizer="adam")
model.fit(X_train, y_train, epochs=100, batch_size=64, validation_split=.2)
return model
import mlflow
X_train, y_train = get_training_data()
with mlflow.start_run():
# Automatically capture the model's parameters, metrics, artifacts,
# and source code with the `autolog()` function
mlflow.tensorflow.autolog()
train_keras_model(X_train, y_train)
run_id = mlflow.active_run().info.run_id
Inscrire et gérer le modèle à l’aide de l’interface utilisateur de MLflow
Dans cette section :
- Créer un model inscrit
- Explorer l’interface utilisateur du Registre de modèles
- Ajouter des descriptions de modèle
- Opérer la transition d’une version de modèle
Créer un model inscrit
Accédez à la barre latérale des cycles d’expérience de MLflow en cliquant sur l’icône Expérience
 dans l’interface utilisateur du notebook Azure Databricks.
dans l’interface utilisateur du notebook Azure Databricks.
Localisez l’exécution de MLflow correspondant à la session d’apprentissage du modèle TensorFlow Keras, puis ouvrez-la dans l’interface utilisateur d’exécution de MLflow en cliquant sur l’icône Voir les détails de l'exécution.
Dans l’interface utilisateur de MLflow, faites défiler jusqu’à la section Artefacts, puis cliquez sur le répertoire nommé model. Cliquez sur le bouton Inscrire le modèle qui s’affiche.

Sélectionnez Créer un modèle dans le menu déroulant, puis entrez le nom de modèle suivant :
power-forecasting-model.Cliquez sur S'inscrire. Cela a pour effet d’inscrire un nouveau modèle appelé
power-forecasting-modelet de créer une nouvelle version du modèle :Version 1.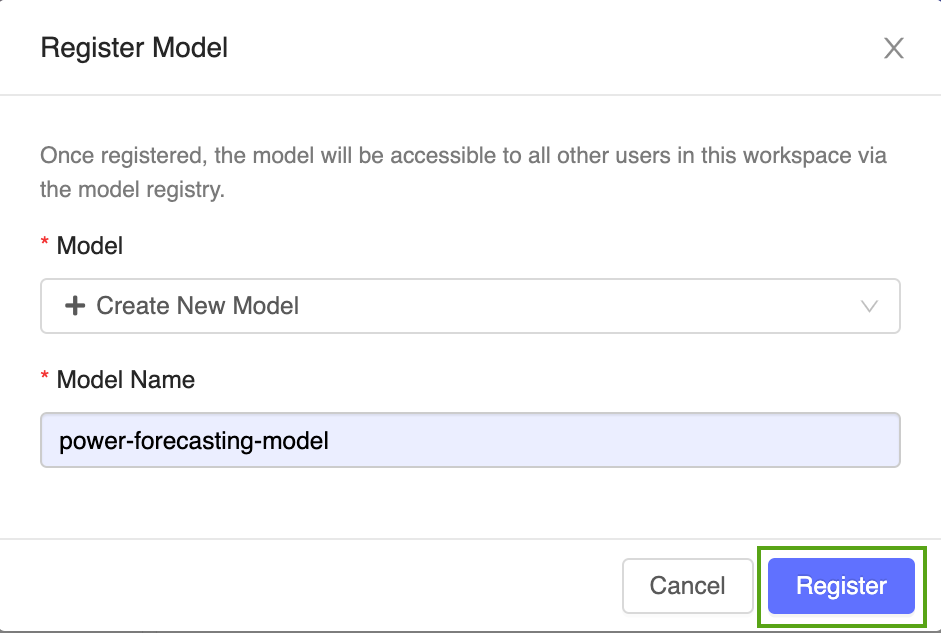
Après quelques instants, l’interface utilisateur de MLflow affiche un lien pointant vers le nouveau modèle inscrit. Cliquez sur ce lien pour ouvrir la nouvelle version du modèle dans l’interface utilisateur du Registre des modèles de MLflow.
Explorer l’interface utilisateur du Registre de modèles
La page de version du modèle de l’interface utilisateur du Registre de modèles MLflow fournit des informations sur la Version 1 du modèle de prévision inscrit, notamment son auteur, son heure de création et sa phase actuelle.
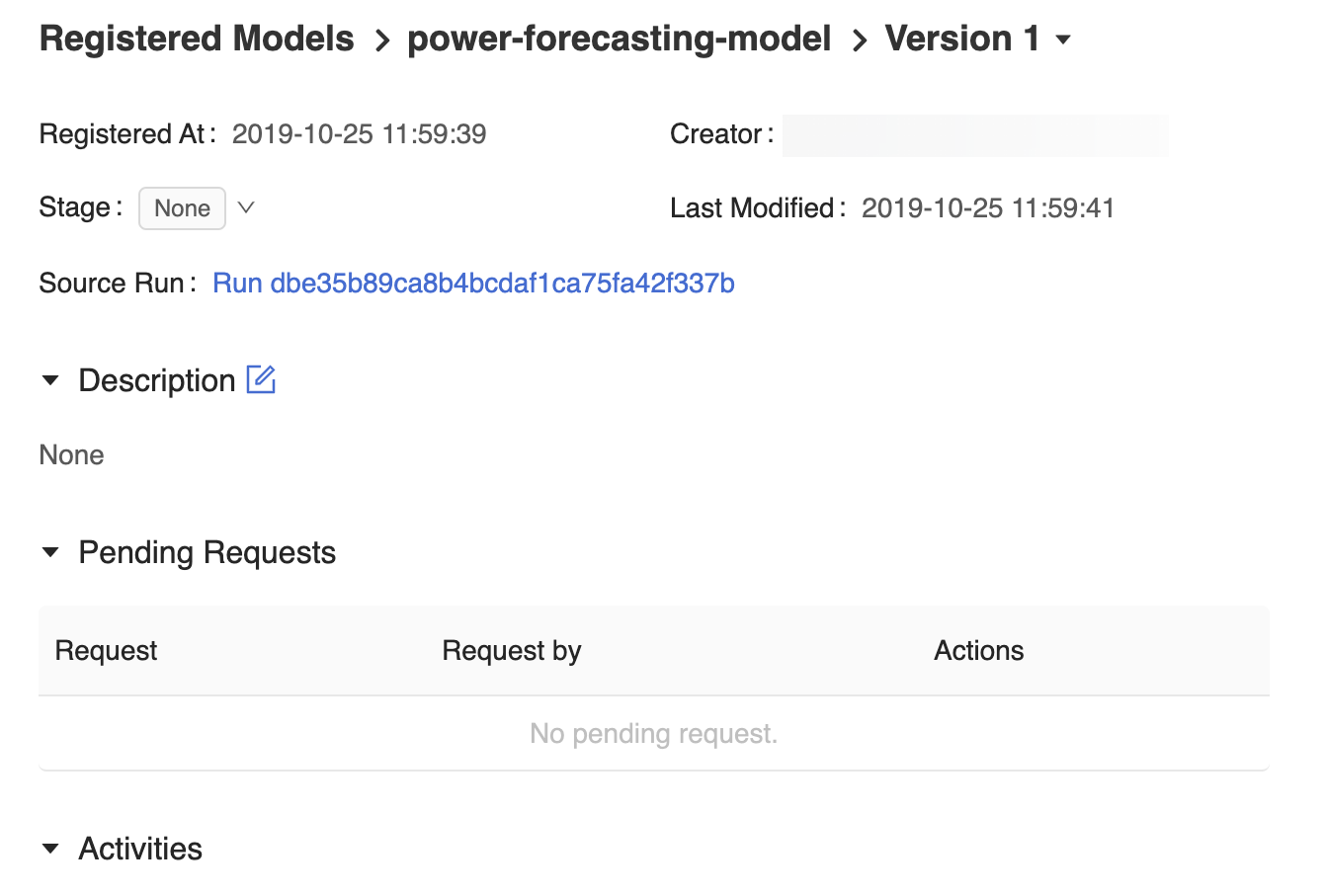
La page de version du modèle fournit également un lien Cycle source qui ouvre le cycle de MLflow utilisé pour créer le modèle dans l’interface utilisateur d’exécution de MLflow. À partir de l’interface utilisateur d’exécution de MLflow, vous pouvez accéder au lien du notebook Source pour afficher un instantané du notebook Azure Databricks utilisé pour effectuer l'apprentissage du modèle.


Pour revenir au Registre de modèles MLflow, cliquez sur ![]() Modèles dans la barre latérale.
Modèles dans la barre latérale.
La page d’accueil du Registre de modèles MLflow qui en résulte affiche la liste de tous les modèles inscrits dans votre espace de travail Azure Databricks, y compris leurs versions et phases.
Cliquez sur le lien power-forecasting-model pour ouvrir la page du modèle inscrit, qui affiche toutes les versions du modèle de prévision.
Ajouter des descriptions de modèle
Vous pouvez ajouter des descriptions aux modèles inscrits et aux versions de modèle. Les descriptions de modèles inscrits sont utiles pour enregistrer des informations qui s’appliquent à plusieurs versions d’un modèle (par exemple, une vue d’ensemble générale du problème de modélisation et du jeu de données). Les descriptions de version de modèle sont utiles pour détailler les attributs uniques d’une version de modèle particulière (par exemple, la méthodologie et l’algorithme utilisés pour développer le modèle).
Ajoutez une description générale au modèle de prévision de d’alimentation inscrit. Cliquez sur l’icône
 , puis entrez la description suivante:
, puis entrez la description suivante:This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature.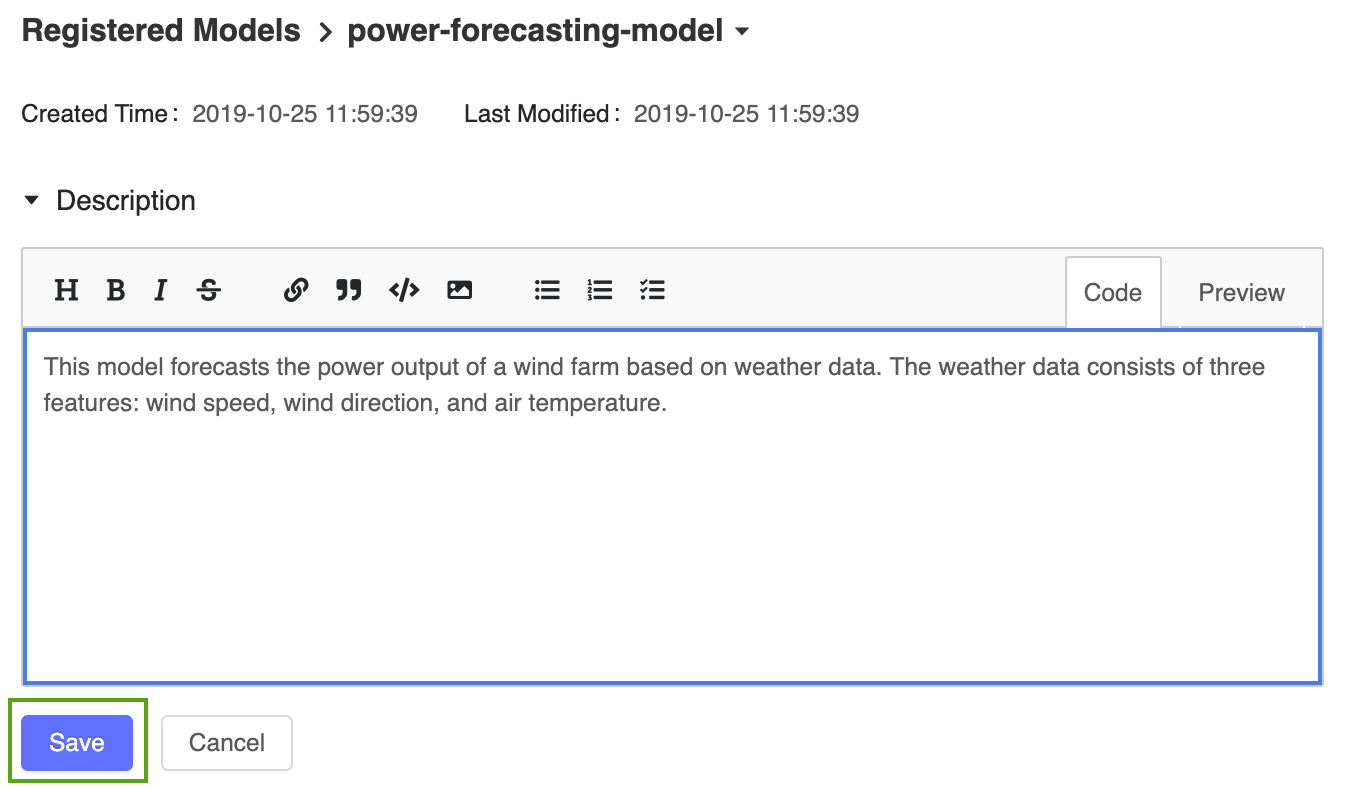
Cliquez sur Enregistrer.
Cliquez sur le lien version 1 dans la page du modèle inscrit pour revenir à la page de version du modèle.
Cliquez sur l’icône
, puis entrez la description suivante:This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer.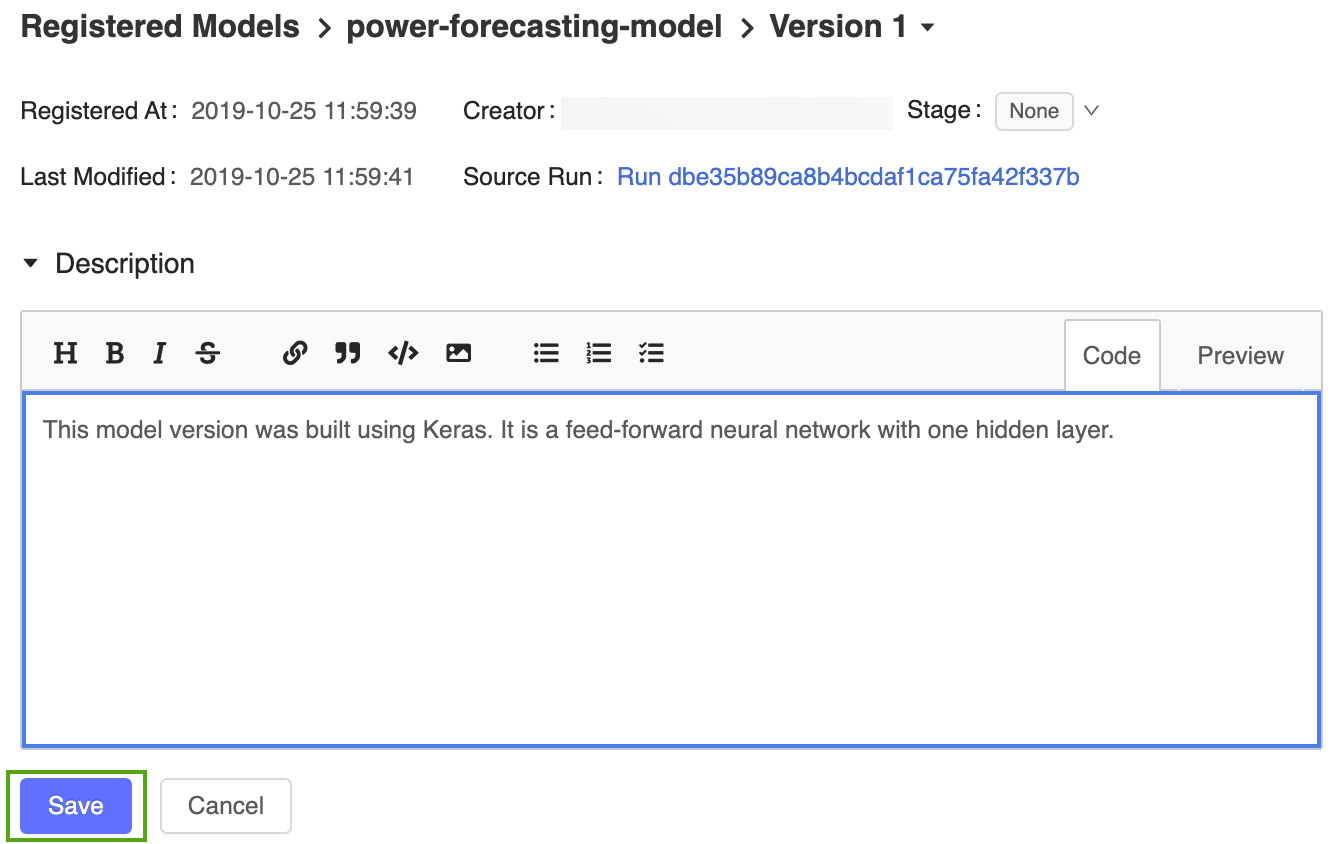
Cliquez sur Enregistrer.
Opérer la transition d’une version de modèle
Le Registre de modèles MLflow définit plusieurs phases de modèle : Aucun, Intermédiaire, Production et Archived. Chaque phase a une signification unique. Par exemple, la phase Intermédiaire est destinée à tester le modèle, alors que la phase Production est destinée aux modèles dont les processus de test ou de révision sont accomplis et qui ont été déployés dans des applications.
Cliquez sur le bouton Intermédiaire pour afficher la liste des phases de modèle disponibles et les options de transition de phase disponibles.
Sélectionnez Transition vers -> Production, puis appuyez sur OK dans la fenêtre de confirmation de transition de la phase afin d’opérer la transition du modèle vers la Production.
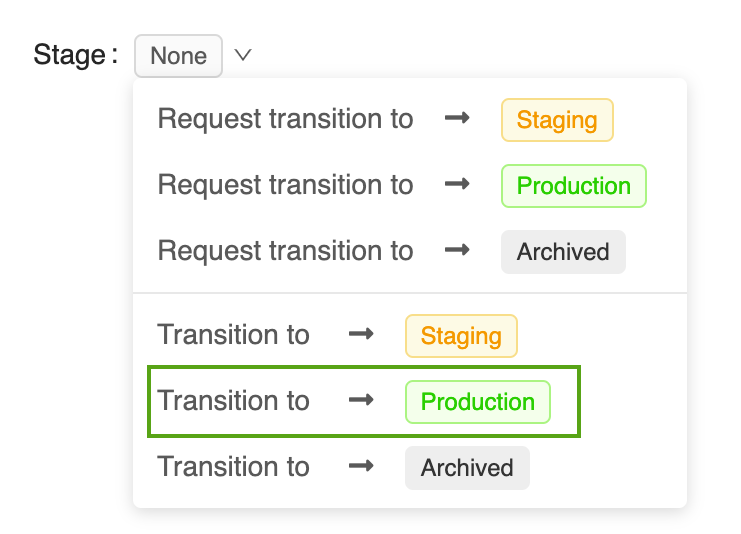
Une fois la transition de la version du modèle opérée vers la Production, la phase actuelle est affichée dans l’interface utilisateur et une entrée est ajoutée au Journal d’activité pour refléter la transition.


Le Registre de modèles MLflow permet à plusieurs versions du modèle de partager la même phase. Lors du référencement d’un modèle par phase, le Registre de modèles utilise la dernière version du modèle (version dont l’ID de version est le plus grand). La page du modèle inscrit affiche toutes les versions d’un modèle particulier.
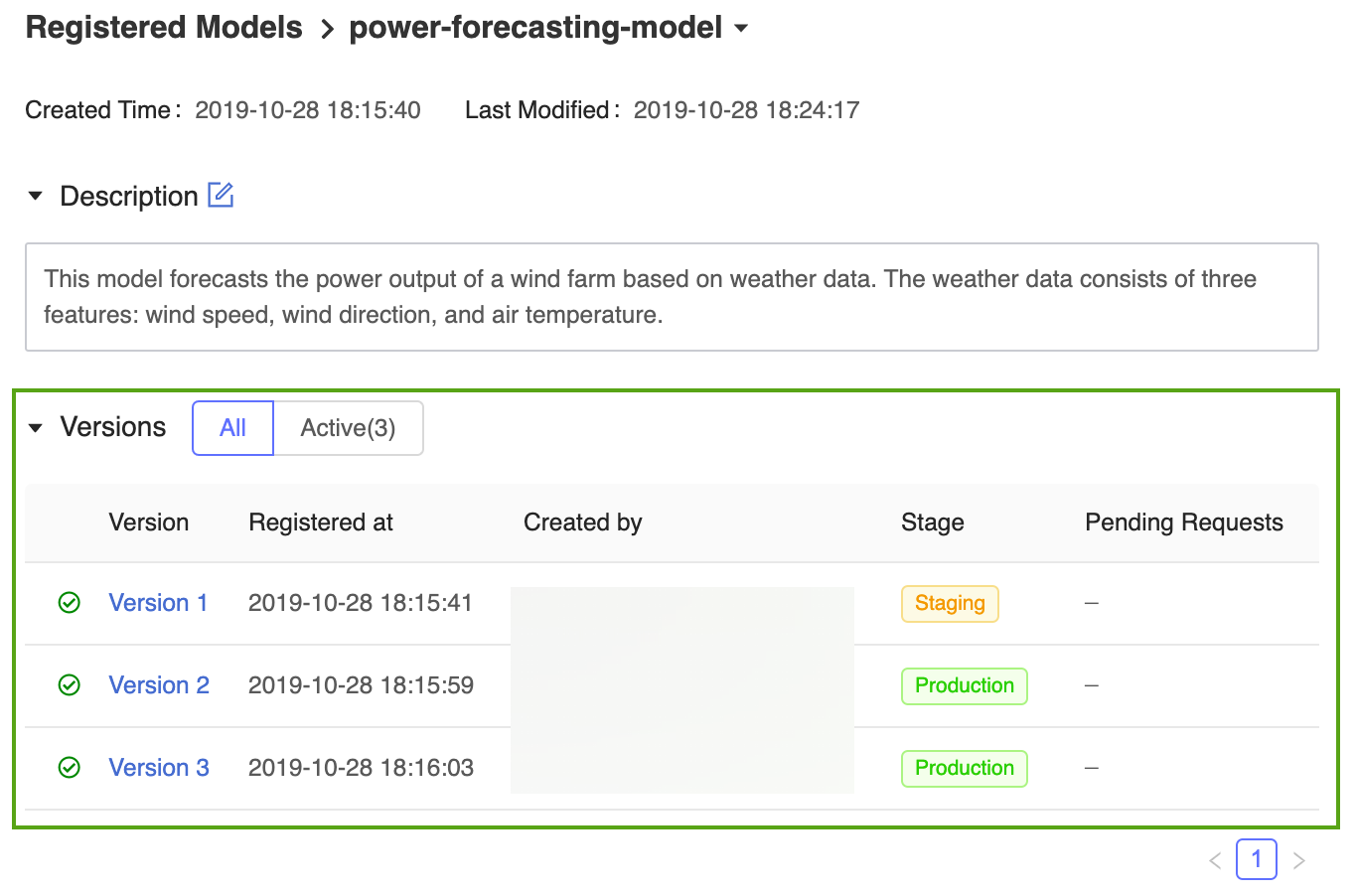
Inscrire et gérer le modèle à l’aide de l’API de MLflow
Dans cette section :
- Définir le nom du modèle par programme
- Inscrire le modèle
- Ajouter un modèle et des descriptions de version de celui-ci à l’aide de l’API
- Opérer la transition d’une version du modèle et récupérer les détails à l’aide de l’API
Définir le nom du modèle par programme
Maintenant que le modèle a été inscrit et sa transition opérée vers la phase Production, vous pouvez le référencer à l’aide d’API de programmation de MLflow. Définissez le nom du modèle inscrit comme suit :
model_name = "power-forecasting-model"
Inscrire le modèle
model_name = get_model_name()
import mlflow
# The default path where the MLflow autologging function stores the TensorFlow Keras model
artifact_path = "model"
model_uri = "runs:/{run_id}/{artifact_path}".format(run_id=run_id, artifact_path=artifact_path)
model_details = mlflow.register_model(model_uri=model_uri, name=model_name)
import time
from mlflow.tracking.client import MlflowClient
from mlflow.entities.model_registry.model_version_status import ModelVersionStatus
# Wait until the model is ready
def wait_until_ready(model_name, model_version):
client = MlflowClient()
for _ in range(10):
model_version_details = client.get_model_version(
name=model_name,
version=model_version,
)
status = ModelVersionStatus.from_string(model_version_details.status)
print("Model status: %s" % ModelVersionStatus.to_string(status))
if status == ModelVersionStatus.READY:
break
time.sleep(1)
wait_until_ready(model_details.name, model_details.version)
Ajouter un modèle et des descriptions de version de celui-ci à l’aide de l’API
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.update_registered_model(
name=model_details.name,
description="This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature."
)
client.update_model_version(
name=model_details.name,
version=model_details.version,
description="This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer."
)
Opérer la transition d’une version du modèle et récupérer les détails à l’aide de l’API
client.transition_model_version_stage(
name=model_details.name,
version=model_details.version,
stage='production',
)
model_version_details = client.get_model_version(
name=model_details.name,
version=model_details.version,
)
print("The current model stage is: '{stage}'".format(stage=model_version_details.current_stage))
latest_version_info = client.get_latest_versions(model_name, stages=["production"])
latest_production_version = latest_version_info[0].version
print("The latest production version of the model '%s' is '%s'." % (model_name, latest_production_version))
Charger les versions du modèle inscrit à l’aide de l’API
Le composant Modèles MLflow définit des fonctions pour charger des modèles à partir de plusieurs infrastructures de Machine Learning. Par exemple, mlflow.tensorflow.load_model() est utilisé pour charger des modèles TensorFlow enregistrés au format MLflow, et mlflow.sklearn.load_model() pour charger des modèles scikit-learn enregistrés au format MLflow.
Ces fonctions peuvent charger des modèles à partir du Registre de modèles MLflow.
import mlflow.pyfunc
model_version_uri = "models:/{model_name}/1".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_version_uri))
model_version_1 = mlflow.pyfunc.load_model(model_version_uri)
model_production_uri = "models:/{model_name}/production".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_production_uri))
model_production = mlflow.pyfunc.load_model(model_production_uri)
Prévoir la production d’énergie avec le modèle de production
Dans cette section, le modèle de production est utilisé pour évaluer les données de prévisions météorologiques pour le parc éolien. L’application forecast_power() charge la dernière version du modèle de prévision à partir de la phase spécifiée et l’utilise pour prévoir la production d’énergie au cours des cinq prochains jours.
def plot(model_name, model_stage, model_version, power_predictions, past_power_output):
import pandas as pd
import matplotlib.dates as mdates
from matplotlib import pyplot as plt
index = power_predictions.index
fig = plt.figure(figsize=(11, 7))
ax = fig.add_subplot(111)
ax.set_xlabel("Date", size=20, labelpad=20)
ax.set_ylabel("Power\noutput\n(MW)", size=20, labelpad=60, rotation=0)
ax.tick_params(axis='both', which='major', labelsize=17)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))
ax.plot(index[:len(past_power_output)], past_power_output, label="True", color="red", alpha=0.5, linewidth=4)
ax.plot(index, power_predictions.squeeze(), "--", label="Predicted by '%s'\nin stage '%s' (Version %d)" % (model_name, model_stage, model_version), color="blue", linewidth=3)
ax.set_ylim(ymin=0, ymax=max(3500, int(max(power_predictions.values) * 1.3)))
ax.legend(fontsize=14)
plt.title("Wind farm power output and projections", size=24, pad=20)
plt.tight_layout()
display(plt.show())
def forecast_power(model_name, model_stage):
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version = client.get_latest_versions(model_name, stages=[model_stage])[0].version
model_uri = "models:/{model_name}/{model_stage}".format(model_name=model_name, model_stage=model_stage)
model = mlflow.pyfunc.load_model(model_uri)
weather_data, past_power_output = get_weather_and_forecast()
power_predictions = pd.DataFrame(model.predict(weather_data))
power_predictions.index = pd.to_datetime(weather_data.index)
print(power_predictions)
plot(model_name, model_stage, int(model_version), power_predictions, past_power_output)
Créer une nouvelle version du modèle
Les techniques de Machine Learning classiques sont également efficaces pour la prévision de l’alimentation. Le code suivant effectue l'apprentissage d’un modèle de forêt aléatoire à l’aide de scikit-learn, et l’inscrit auprès du Registre de modèles MLflow via la fonction mlflow.sklearn.log_model().
import mlflow.sklearn
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
with mlflow.start_run():
n_estimators = 300
mlflow.log_param("n_estimators", n_estimators)
rand_forest = RandomForestRegressor(n_estimators=n_estimators)
rand_forest.fit(X_train, y_train)
val_x, val_y = get_validation_data()
mse = mean_squared_error(rand_forest.predict(val_x), val_y)
print("Validation MSE: %d" % mse)
mlflow.log_metric("mse", mse)
# Specify the `registered_model_name` parameter of the `mlflow.sklearn.log_model()`
# function to register the model with the MLflow Model Registry. This automatically
# creates a new model version
mlflow.sklearn.log_model(
sk_model=rand_forest,
artifact_path="sklearn-model",
registered_model_name=model_name,
)
Extraire le nouvel ID de version de modèle à l’aide d’une recherche dans le Registre de modèles MLflow
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version_infos = client.search_model_versions("name = '%s'" % model_name)
new_model_version = max([model_version_info.version for model_version_info in model_version_infos])
wait_until_ready(model_name, new_model_version)
Ajouter une description à la nouvelle version du modèle
client.update_model_version(
name=model_name,
version=new_model_version,
description="This model version is a random forest containing 100 decision trees that was trained in scikit-learn."
)
Opérer la transition de la nouvelle version du modèle vers la phase Intermédiaire et tester le modèle
Avant de déployer un modèle dans une application de production, la meilleure pratique consiste souvent à le tester dans un environnement intermédiaire. Le code suivant opère la transition de la nouvelle version du modèle vers la phase Intermédiaire et évalue ses performances.
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="Staging",
)
forecast_power(model_name, "Staging")
Déployer la nouvelle version du modèle en Production
Après avoir vérifié que la nouvelle version du modèle fonctionne correctement dans la phase intermédiaire, le code suivant opère la transition du modèle vers la phase Production et utilise exactement le même code d’application que celui décrit dans la section Prévoir la production d’énergie avec le modèle de production pour produire une prévision d’alimentation.
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="production",
)
forecast_power(model_name, "production")
Il existe désormais deux versions du modèle de prévision en phase de Production : celle dont l’apprentissage a été effectué dans le modèle Keras, et celle dont l’apprentissage a été effectué dans scikit-learn.
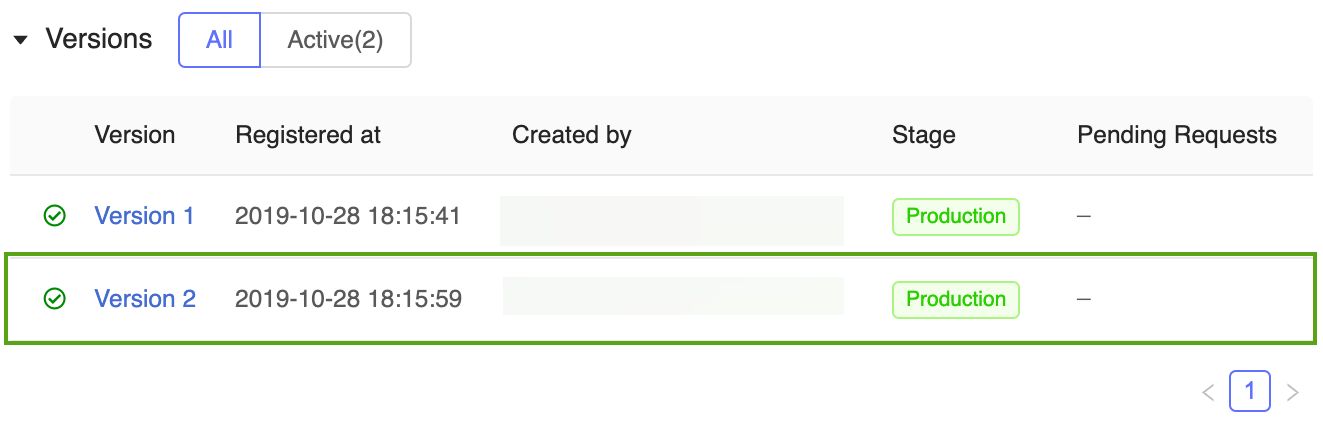
Notes
Lors du référencement d’un modèle par phase, le Registre de modèles MLflow utilise automatiquement la dernière version de production. Cela vous permet de mettre à jour vos modèles de production sans modifier le moindre code d’application.
Archiver et supprimer des modèles
Quand une version du modèle n’est plus utilisée, vous pouvez l’archiver ou la supprimer. Vous pouvez également supprimer un modèle inscrit tout entier, ce qui a pour effet de supprimer toutes les versions du modèle associées.
Archiver la Version 1 du modèle de prévision de l’alimentation
Archivez la Version 1 du modèle de prévision de l’alimentation parce qu’elle n’est plus utilisée. Vous pouvez archiver des modèles dans l’interface utilisateur du Registre de modèles MLflow ou via l’API MLflow.
Archiver la Version 1 dans l’interface utilisateur MLflow
Archivez la Version 1 du modèle de prévision de l’alimentation :
Ouvrez la page de la version du modèle correspondante dans l’interface utilisateur du Registre de modèles MLflow :
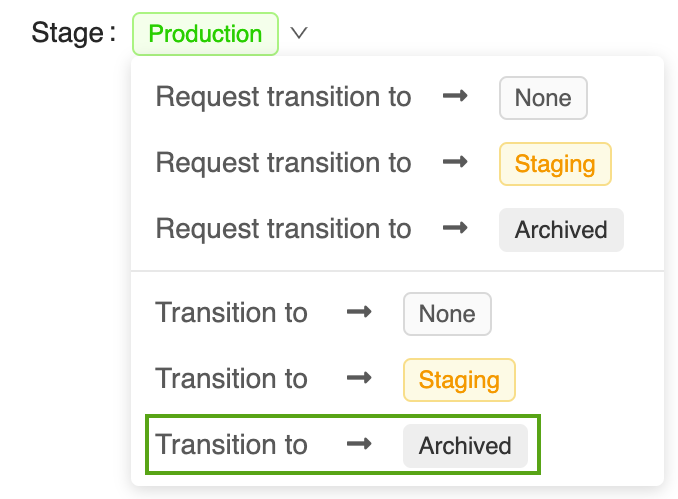
Cliquez sur le bouton Phase, puis sélectionnez Transition vers -> Archivé :
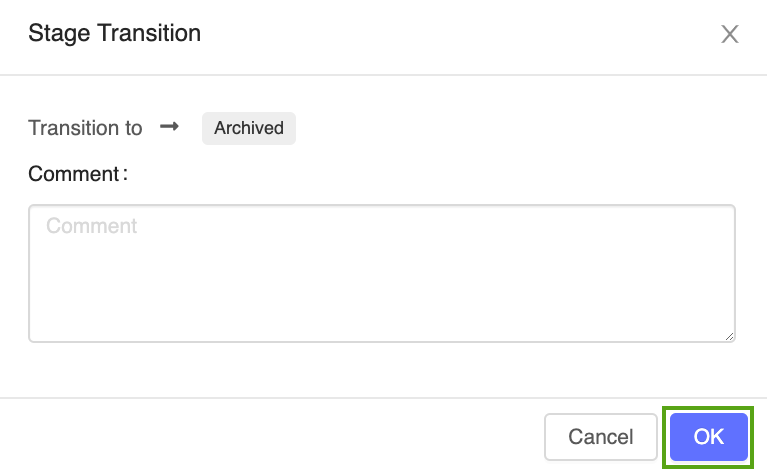
Appuyez sur OK dans la fenêtre de confirmation de transition de phase.

Archiver la Version 1 à l’aide de l’API MLflow
Le code suivant utilise la fonction MlflowClient.update_model_version() pour archiver la Version 1 du modèle de prévision de l’alimentation.
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=1,
stage="Archived",
)
Supprimer la Version 1 du modèle de prévision de l’alimentation
Vous pouvez également utiliser l’interface utilisateur ou l’API MLflow pour supprimer des versions du modèle.
Avertissement
La suppression d’une version du modèle est permanente et ne peut pas être annulée.
Supprimer la Version 1 dans l’interface utilisateur MLflow
Pour supprimer la Version 1 du modèle de prévision de l’alimentation :
Ouvrez la page de la version du modèle correspondante dans l’interface utilisateur du Registre de modèles MLflow.
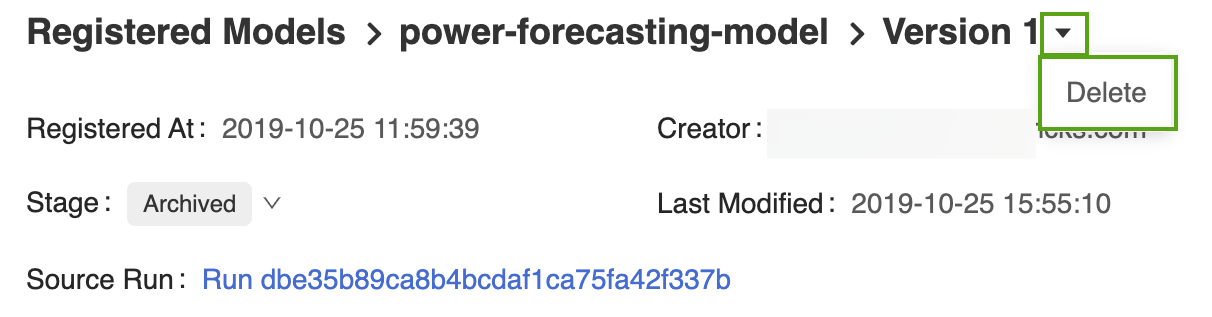
Sélectionnez la flèche de déroulement en regard de l’identificateur de version, puis cliquez sur Supprimer.
Supprimer la Version 1 à l’aide de l’API MLflow
client.delete_model_version(
name=model_name,
version=1,
)
Supprimer le modèle à l’aide de l’API MLflow
Vous devez d’abord opérer la transition de toutes les phases de version du modèle restantes vers Aucun ou Archivé.
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=2,
stage="Archived",
)
client.delete_registered_model(name=model_name)