Juillet 2018
Ces fonctionnalités et améliorations de la plateforme Azure Databricks ont été publiées en juillet 2018.
L’API Bibliothèques prend en charge les fichiers wheel Python
31 juillet au 7 août 2018 : version 2.77
Vous pouvez maintenant installer des bibliothèques wheel à l’aide de l’API Bibliothèques. Lorsque vous installez une bibliothèque wheel sur un cluster exécutant Databricks Runtime 4.2 ou version ultérieure, toutes les dépendances spécifiées dans le fichier setup.py de la bibliothèque sont incluses. Lorsque vous installez une bibliothèque wheel sur un cluster exécutant Databricks Runtime 4.1 ou version antérieure, le fichier est ajouté à la variable PYTHONPATH, sans installer les dépendances.
Exportation d’un notebook IPython
31 juillet au 7 août 2018 : version 2.77
Lorsque vous exportez un notebook Azure Databricks au format de notebook IPython, les résultats sont désormais inclus dans l’exportation.
Étendues de secrets reposant sur Azure Key Vault
19 au 24 juillet 2018 : version 2.76
Les secrets prennent désormais en charge les étendues reposant sur un coffre de clés Azure. Une fois que vous avez créé l’étendue, vous pouvez accéder à tous les secrets dans le coffre de clés correspondant à partir de cette étendue. Pour plus d’informations, consultez Créer une étendue de secrets reposant sur Azure Key Vault.
Notes
L’étendue de secrets reposant sur Azure Key Vault est une interface en lecture seule du coffre de clés. Pour gérer les secrets dans Azure Key Vault, vous devez utiliser l’API REST Définir le secret Azure ou l’interface utilisateur du portail Azure.
Espaces de travail Premium (évaluation)
20 au 24 juillet 2018 : version 2.76
Azure Databricks propose désormais des espaces de travail Premium d’essai. Pendant une période d’essai de 14 jours, vous avez accès à des unités DBU Azure Databricks gratuites. Pour plus d’informations, consultez Créer un espace de travail.
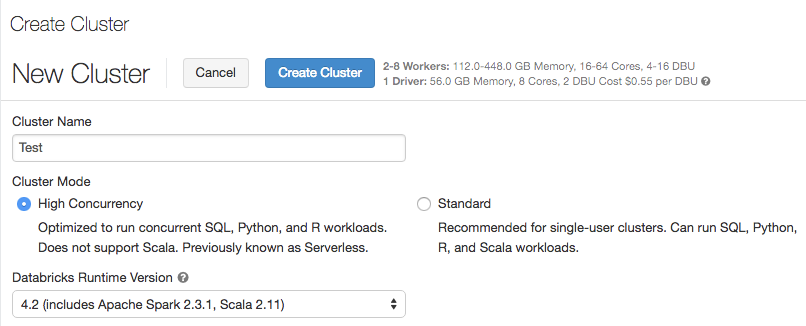
Mode cluster et clusters à concurrence élevée
19 au 24 juillet 2018 : version 2.76
Lors de la création d’un cluster, l’option Type de cluster a été renommée en Mode cluster. L’option Pool serverless a été remplacée par le mode cluster Concurrence élevée. Les clusters Concurrence élevée sont réglés pour fournir une utilisation efficace des ressources, l’isolation, la sécurité et les meilleures performances lorsqu’elles sont partagées par plusieurs utilisateurs actifs simultanément. Un cluster Concurrence élevée prend en charge uniquement les langages SQL, Python et R. Les clusters Concurrence élevée offrent tous les avantages des pools serverless tout en permettant une certaine flexibilité dans la configuration de Spark et des ressources. Pour plus d’informations, consultez Clusters Concurrence élevée.
Contrôle d’accès aux tables
19 au 24 juillet 2018 : version 2.76
La case à cocher Contrôle d’accès aux tables est disponible uniquement pour les clusters Concurrence élevée.

Types de nœud de cluster non disponibles estompés
3 au 10 juillet 2018 : version 2.75
Les types de nœuds de cluster qui ne sont pas disponibles pour votre abonnement et votre région sont désormais grisés, et vous ne pouvez pas les sélectionner lorsque vous créez un cluster.
Prise en charge de R Markdown
3 au 10 juillet 2018 : version 2.75
Les notebooks R Azure Databricks peuvent être exportés au format R Markdown, et les documents R Markdown peuvent être importés en tant que notebooks Azure Databricks.
Page d’accueil repensée, avec la possibilité de déposer des fichiers pour importer des données
3 au 10 juillet 2018 : version 2.75
La nouvelle page d’accueil ajoute une interface plus propre et plus simple, avec des liens vers un tutoriel Prise en main amélioré et la possibilité de glisser-déplacer des fichiers pour importer des données. Consultez Explorer et créer des tables dans DBFS.
Comportement par défaut des widgets
3 au 10 juillet 2018 : version 2.75
Le comportement d’exécution par défaut lorsqu’une nouvelle valeur est sélectionnée pour un widget est désormais de ne rien faire. Vous devez mettre à jour les paramètres du widget si vous souhaitez réexécuter un notebook complet ou uniquement les commandes relatives à la valeur lorsque vous modifiez la valeur d’un widget. Voir Configurer les paramètres des widgets.
Interface utilisateur de création de table
3 au 10 juillet 2018 : version 2.75
Lorsque vous créez une table dans l’interface utilisateur, vous sélectionnez maintenant Ajouter des données à partir de la page Données.
![]()
Consultez Explorer et créer des tables dans DBFS.
Importation de données JSON multilignes
3 au 10 juillet 2018 : version 2.75
Vous pouvez maintenant importer des fichiers de données JSON à plusieurs lignes lorsque vous créez des tables. Auparavant, les fichiers de données JSON devaient être aplatis sur une seule ligne. Consultez Explorer et créer des tables dans DBFS.