Février 2019
Ces fonctionnalités et améliorations de la plateforme Azure Databricks ont été publiées en février 2019.
Notes
Les publications se font par étapes. Votre compte Azure Databricks peut ne pas être mis à jour jusqu’à une semaine après la date de publication initiale.
Databricks Light en disponibilité générale
26 février au 5 mars 2019 : version 2.92
Databricks Light (également appelé Data Engineering Light) est désormais disponible. Databricks Light est le package Databricks du runtime Apache Spark open source. Il fournit une option d’exécution pour les travaux qui n’ont pas besoin des avantages avancés en matière de performances, de fiabilité ou de mise à l’échelle automatique fournis par Databricks Runtime. Vous pouvez sélectionner Databricks Light uniquement quand vous créez un cluster pour exécuter un travail JAR, Python ou spark-submit ; vous ne pouvez pas sélectionner ce runtime pour les clusters sur lesquels vous exécutez des charges de travail liées à des travaux interactifs ou de notebook. Consultez Databricks Light.
MLflow en mode managé sur Azure Databricks (préversion publique)
26 février au 5 mars 2019 : version 2.92
MLflow est une plateforme open source qui permet de gérer le cycle de vie du machine learning de bout en bout. Elle s’attaque à trois fonctions principales :
- Suivi des expériences pour enregistrer et comparer des paramètres et des résultats.
- Gestion et déploiement de modèles de diverses bibliothèques ML sur de nombreuses plateformes d’inférence et Model Serving.
- Création de package de code ML dans un format réutilisable et reproductible en vue de le partager avec d’autres scientifiques des données ou de le passer en production.
Azure Databricks fournit à présent une version complètement managée et hébergée de MLflow, qui intègre des fonctionnalités de sécurité d’entreprise, une haute disponibilité et d’autres fonctionnalités d’espace de travail Azure Databricks telles que la gestion des expériences et des exécutions ainsi que la capture des révisions de notebook. MLflow sur Azure Databricks offre une expérience intégrée pour le suivi et la sécurisation des exécutions d’entraînement des modèles Machine Learning et des projets de machine learning exécutés. En utilisant MLflow en mode managé sur Azure Databricks, vous bénéficiez des avantages des deux plateformes, notamment :
- Espaces de travail : Suivez et organisez de façon collaborative les expériences et les résultats dans les espaces de travail Azure Databricks avec un serveur de suivi MLflow hébergé et une interface utilisateur de l’expérience intégrée. Lorsque vous utilisez MLflow dans des notebooks, Azure Databricks capture automatiquement les révisions de notebook pour vous permettre de reproduire les mêmes code et exécutions ultérieurement.
- Sécurité : Tirez parti d’un modèle de sécurité commun pour l’ensemble du cycle de vie ML via des ACL.
- Travaux : Exécutez des projets MLflow en tant que travaux Azure Databricks à distance et directement à partir de notebooks Azure Databricks.
Voici une démonstration d’un workflow de suivi dans un espace de travail Azure Databricks :
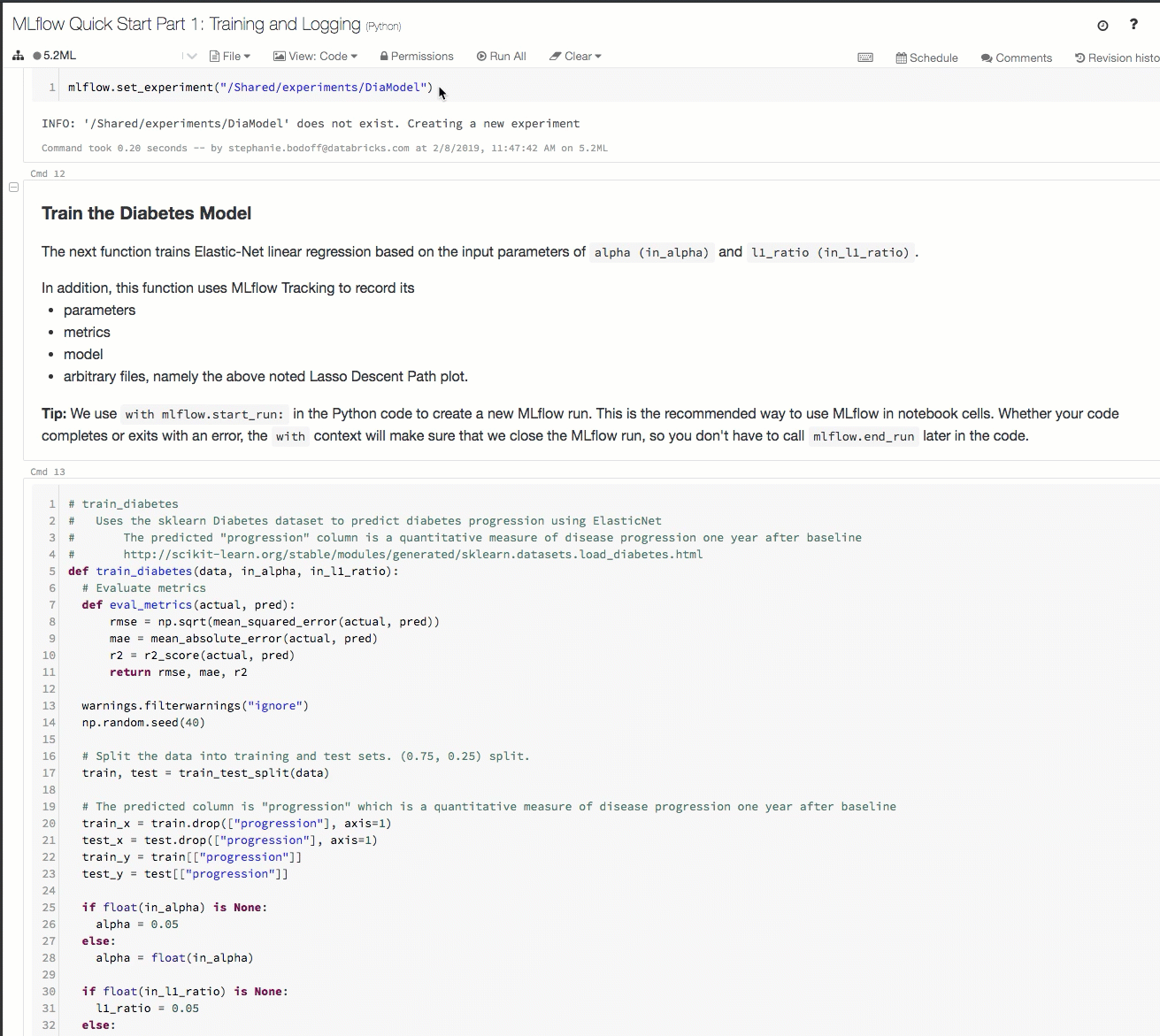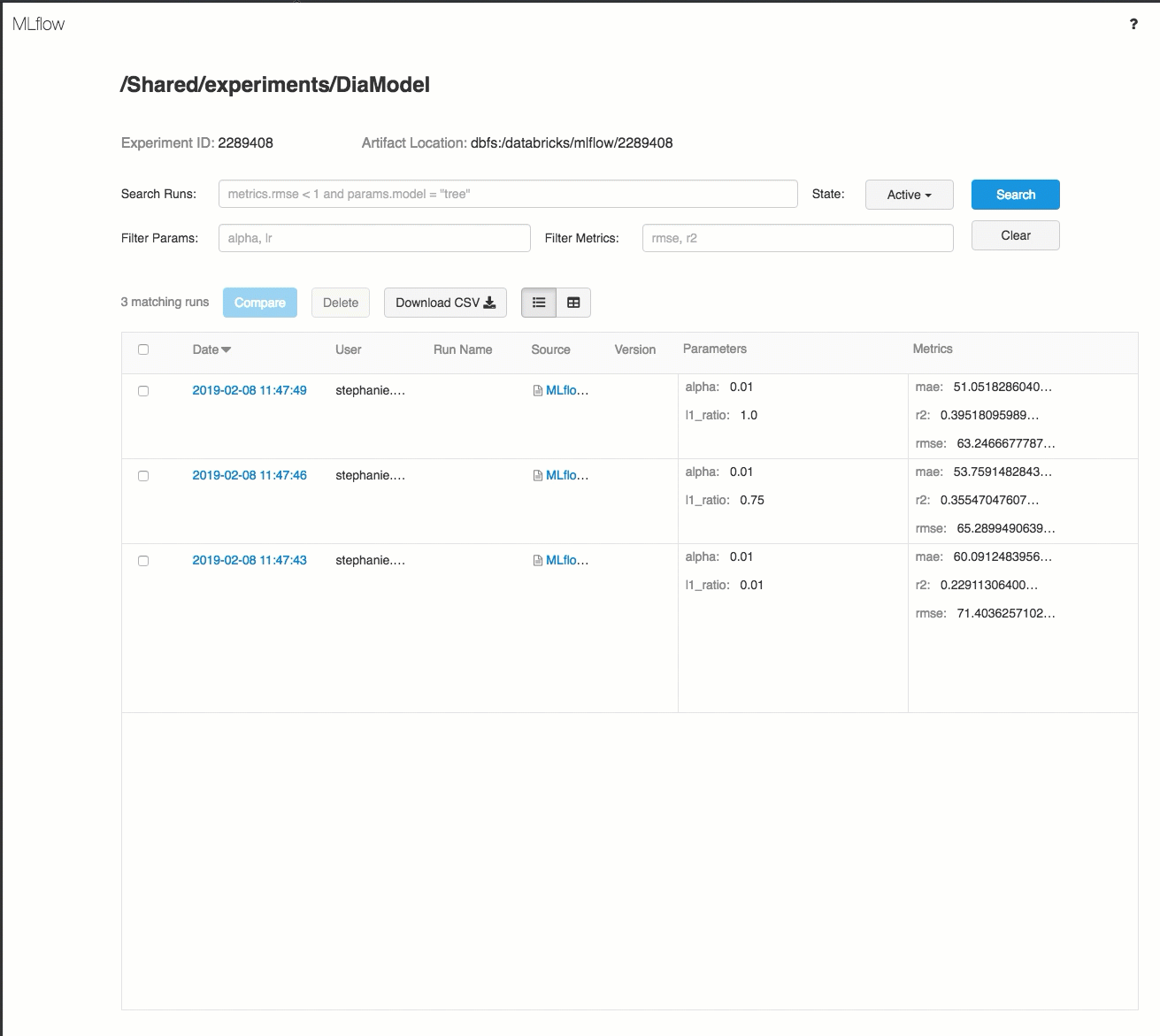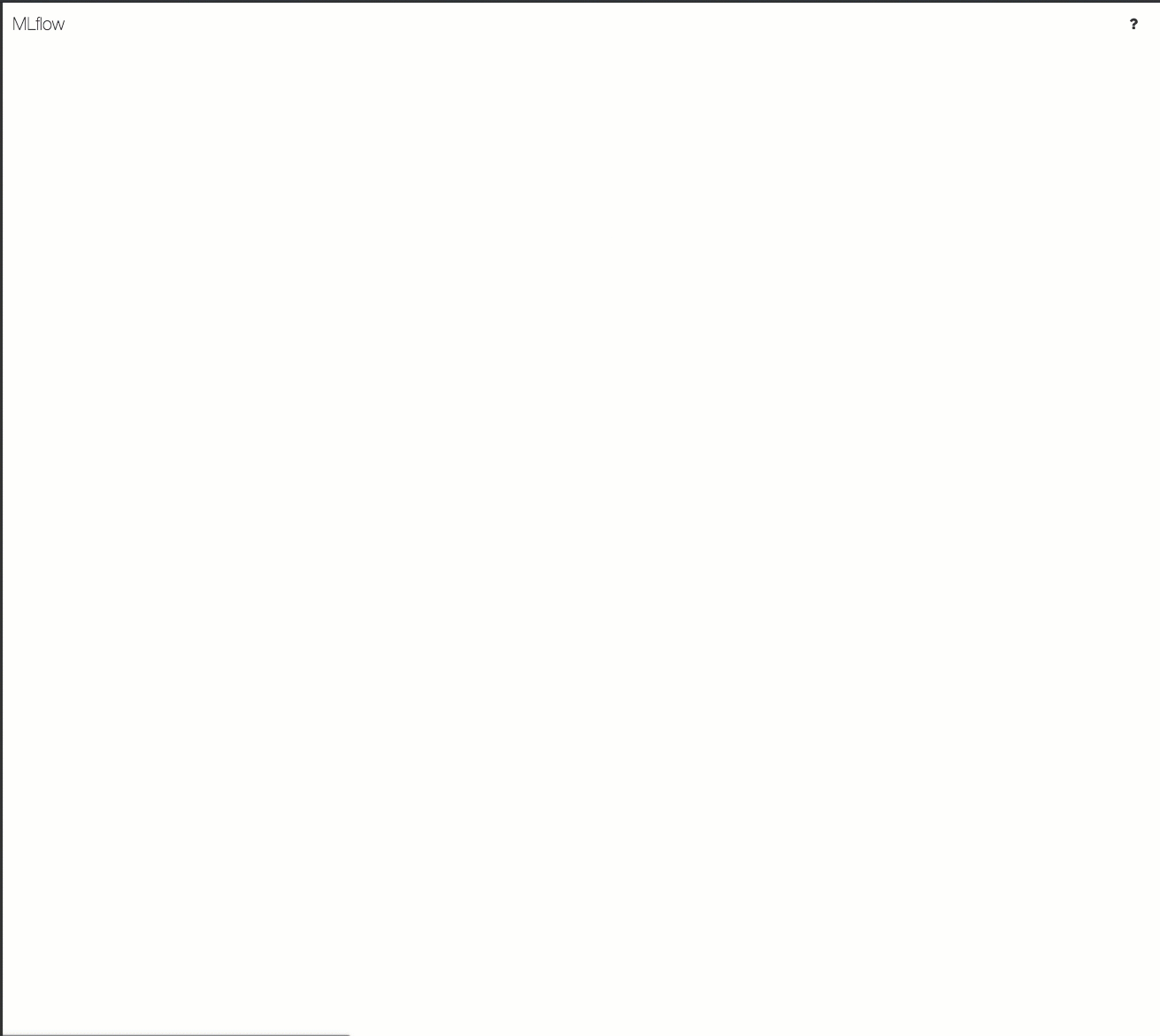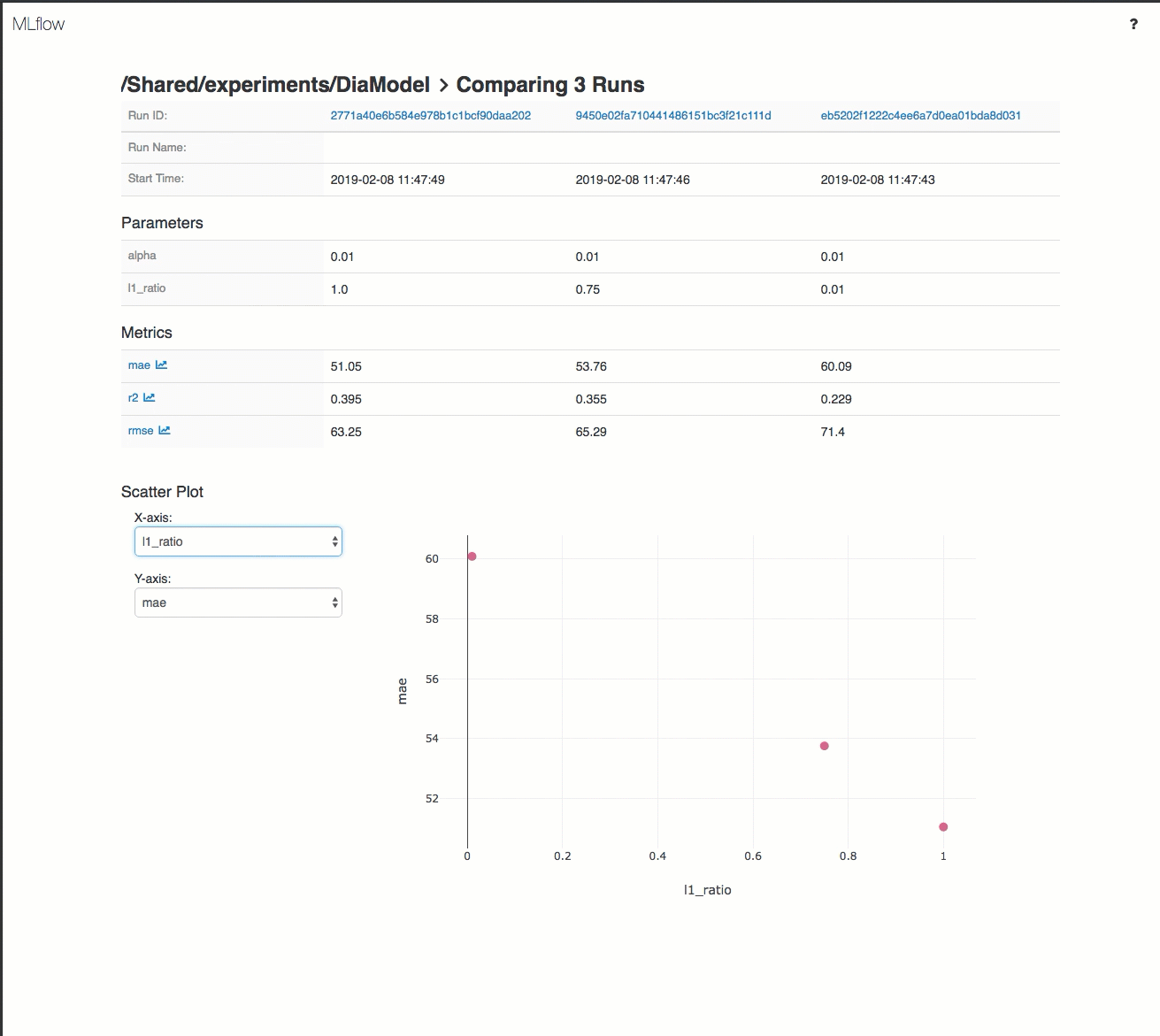
Pour plus de détails, consultez Suivre les exécutions d’entraînement de Machine Learning et Deep Learning et Exécuter des projets MLflow sur Azure Databricks.
Le connecteur Azure Data Lake Storage Gen2 est en disponibilité générale
15 février 2019
Azure Data Lake Storage Gen2 (ADLS Gen2), la solution Data Lake de nouvelle génération pour l’analytique Big Data, est désormais en disponibilité générale, tout comme le connecteur ADLS Gen2 pour Azure Databricks. Nous sommes également heureux d’annoncer qu’ADLS Gen2 prend en charge Databricks Delta quand vous exécutez des clusters sur Databricks Runtime 5.2 et versions ultérieures.
Python 3 est désormais la version par défaut lors de la création de clusters
12 au 19 février 2019 : version 2.91
La version Python par défaut pour les clusters créés à l’aide de l’interface utilisateur est passée de Python 2 à Python 3. La version par défaut pour les clusters créés à l’aide de l’API REST est toujours Python 2.
Les clusters existants ne modifieront pas leurs versions Python. Toutefois, si vous avez pris l’habitude d’utiliser la version par défaut Python 2 quand vous créez des clusters, vous devez commencer à faire attention au choix de votre version Python.

Delta Lake en disponibilité générale
1er février 2019
Désormais, tout le monde peut bénéficier des avantages de la couche de stockage transactionnel puissante et des lectures super rapides de Databricks Delta : depuis le 1er février, Delta Lake est en disponibilité générale sur toutes les versions prises en charge de Databricks Runtime. Pour plus d’informations sur Delta, consultez Présentation de Delta Lake.