Introduction aux flux de travail Azure Databricks
Azure Databricks Workflows orchestre les pipelines de traitement des données, de Machine Learning et d’analytique dans la plateforme Databricks Data Intelligence. Workflows dispose de services d’orchestration entièrement managés intégrés à la plateforme Databricks, notamment des travaux Azure Databricks pour exécuter du code non interactif dans votre espace de travail Azure Databricks et Delta Live Tables pour créer des pipelines ETL fiables et maintenables.
Pour en savoir plus sur les avantages de l’orchestration de vos flux de travail avec la plateforme Databricks, consultez Databricks Workflows.
Un exemple de flux de travail Azure Databricks
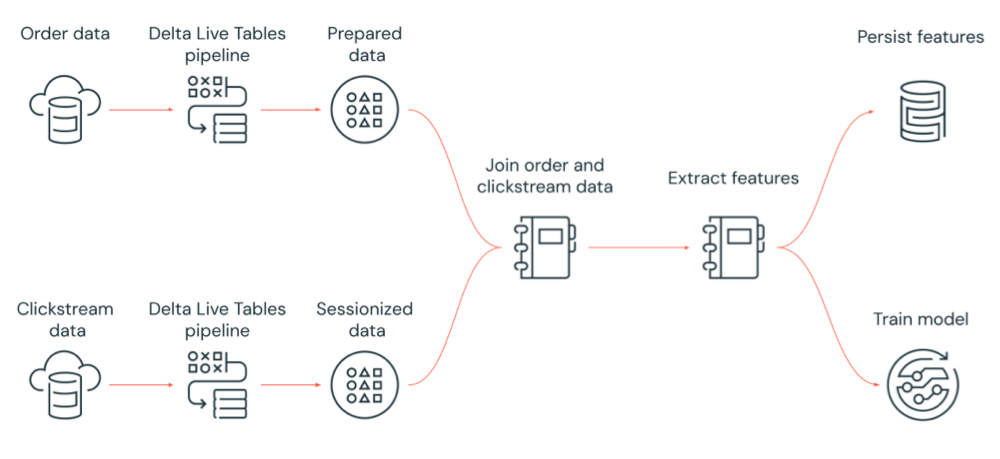
Le diagramme suivant illustre un workflow orchestré par un travail Azure Databricks pour :
- Exécuter un pipeline Delta Live Tables qui ingère des données de flux de navigation brutes à partir du stockage cloud, nettoie et prépare les données, sessionise les données et conserve le jeu de données sessionisé final dans Delta Lake.
- Exécuter un pipeline Delta Live Tables qui ingère les données d’ordre à partir du stockage cloud, nettoie et transforme les données à des fins de traitement et conserve le jeu de données final dans Delta Lake.
- Joindre l’ordre et les données de parcours sessionisées pour créer un jeu de données à des fins d’analyse.
- Extraire les fonctionnalités des données préparées.
- Effectuer des tâches en parallèle pour conserver les fonctionnalités et entraîner un modèle Machine Learning.
Que sont les travaux Azure Databricks ?
Un travail Azure Databricks est un moyen d’exécuter vos applications de traitement et d’analyse des données dans un espace de travail Azure Databricks. Votre travail peut être constitué d’une seule tâche ou être un grand workflow multitâche avec des dépendances complexes. Azure Databricks gère l’orchestration des tâches, la gestion des clusters, la surveillance et les rapports d’erreurs pour tous vos travaux. Vous pouvez exécuter vos travaux immédiatement et régulièrement par le biais d’un système de planification facile à utiliser, chaque fois que de nouveaux fichiers arrivent dans un emplacement externe, ou en continu pour vous assurer qu’une instance du travail est toujours en cours d’exécution. Vous pouvez également exécuter des travaux de manière interactive dans l'interface utilisateur du notebook.
Vous pouvez créer et exécuter un travail à l’aide de l’interface utilisateur des travaux, de l’interface CLI Databricks ou en appelant l’API Travaux. Vous pouvez réparer et réexécuter un travail en échec ou annulé en utilisant l’interface utilisateur ou l’API. Vous pouvez superviser les résultats de l’exécution du travail à l’aide de l’interface utilisateur, de l’interface CLI, de l’API et des notifications (par exemple e-mail, destination webhook ou notifications Slack).
Pour plus d’informations sur l’utilisation de la CLI Databricks, consultez l’article Qu’est-ce que la CLI Databricks ? Pour en savoir plus sur l’utilisation de l’API Travaux, consultez API Travaux.
Les sections suivantes couvrent les fonctionnalités importantes des travaux Azure Databricks.
Important
- Un espace de travail est limité à 1 000 exécutions de tâches simultanées. Une réponse
429 Too Many Requestsest retournée lorsque vous demandez une exécution qui ne peut pas démarrer immédiatement. - Le nombre de travaux qu’un espace de travail peut créer en une heure est limité à 10 000 (« envoi d’exécutions » inclus). Cette limite affecte également les travaux créés par les workflows de l’API REST et des notebooks.
Implémenter le traitement et l’analyse des données avec des tâches de travail
Vous implémentez votre workflow de traitement et d’analyse des données à l’aide de tâches. Un travail est composé d’une ou plusieurs tâches. Vous pouvez créer des tâches de travail qui exécutent des notebooks, JARS, des pipelines Delta Live Tables, des envois Spark ou des applications Python, Scala et Java. Vos tâches de travail peuvent également orchestrer des requêtes, des alertes et des tableaux de bord Databricks SQL pour créer des analyses et des visualisations, ou vous pouvez utiliser la tâche dbt pour exécuter des transformations dbt dans votre workflow. Les applications Spark Submit héritées sont également prises en charge.
Vous pouvez également ajouter une tâche à un travail qui exécute un autre travail. Cette fonctionnalité vous permet de diviser un processus volumineux en plusieurs tâches plus petites ou de créer des modules généralisés pouvant être réutilisés par plusieurs tâches.
Vous contrôlez l’ordre d’exécution des tâches en spécifiant des dépendances entre les tâches. Vous pouvez configurer les tâches pour qu’elles s’exécutent de façon séquentielle ou parallèle.
Exécuter des travaux de manière interactive, continue ou à l’aide de déclencheurs de travail
Vous pouvez exécuter vos travaux de manière interactive à partir de l’interface utilisateur des travaux, de l’API ou de l’interface CLI, ou vous pouvez exécuter un travail continu. Vous pouvez créer une planification pour exécuter votre travail régulièrement ou à l’arrivée de nouveaux fichiers dans un emplacement externe tel qu’Amazon S3, un stockage Azure ou un stockage Google Cloud.
Superviser la progression du travail avec des notifications
Vous pouvez recevoir des notifications lorsqu’un travail ou une tâche démarre, se termine ou échoue. Vous pouvez envoyer des notifications à une ou plusieurs adresses e-mail ou destinations système (par exemple, des destinations webhook ou Slack). Consultez Ajouter des notifications par e-mail et système pour les événements de travail.
Exécuter vos travaux avec des ressources de calcul Azure Databricks
Les clusters Databricks et les entrepôts SQL fournissent les ressources de calcul pour vos travaux. Vous pouvez exécuter vos travaux avec un cluster de travaux, un cluster à usage général ou un entrepôt SQL :
- Un cluster de travaux est un cluster dédié à votre travail ou à des tâches individuelles. Votre travail peut utiliser un cluster de travaux partagé par toutes les tâches ou vous pouvez configurer un cluster pour des tâches individuelles lorsque vous créez ou modifiez une tâche. Un cluster de travaux est créé lorsque le travail ou la tâche démarre et se termine à la fin du travail ou de la tâche.
- Un cluster à usage général est un cluster partagé qui est démarré et arrêté manuellement et qui peut être partagé par plusieurs utilisateurs et travaux.
Pour optimiser l’utilisation des ressources, Databricks recommande d’utiliser un cluster de travaux pour vos travaux. Pour réduire le temps d’attente pour le démarrage du cluster, envisagez d’utiliser un cluster à usage général. Consultez Utiliser le calcul Azure Databricks avec vos travaux.
Vous utilisez un entrepôt SQL pour exécuter des tâches Databricks SQL telles que des requêtes, des tableaux de bord ou des alertes. Vous pouvez également utiliser un entrepôt SQL pour exécuter des transformations dbt avec la tâche dbt.
Étapes suivantes
Pour bien démarrer avec les travaux Azure Databricks :
Créez votre premier travail Azure Databricks avec ce démarrage rapide.
Découvrez comment créer et exécuter des workflows avec l’interface utilisateur des travaux Azure Databricks.
Découvrez comment exécuter un travail sans avoir à configurer des ressources de calcul Azure Databricks avec des flux de travail serverless.
Découvrez la supervision des exécutions de travaux dans l’interface utilisateur des travaux Azure Databricks.
Découvrez les options de configuration pour les travaux.
En savoir plus sur la création, la gestion et la résolution des problèmes des workflows avec les travaux Azure Databricks :
- Découvrez comment communiquer des informations entre les tâches d’un travail Azure Databricks avec des valeurs de tâche.
- Découvrez comment transmettre le contexte des exécutions de travaux dans des tâches avec des variables de paramètre de tâche.
- Découvrez comment configurer vos tâches pour qu'elles s'exécutent de manière conditionnelle en fonction de l'état des dépendances de la tâche.
- Découvrez comment résoudre les problèmes et corriger les travaux ayant échoué.
- Recevez une notification lorsque vos exécutions de travail démarrent, se terminent ou échouent avec les notifications d’exécution de travaux.
- Déclenchez vos travaux selon une planification personnalisée ou exécuter un travail continu.
- Découvrez comment exécuter votre travail Azure Databricks lorsque de nouvelles données arrivent avec des déclencheurs d’arrivée de fichier.
- Découvrez comment utiliser des ressources de calcul Databricks pour exécuter vos travaux.
- Découvrez les mises à jour de l’API Jobs pour prendre en charge la création et la gestion de flux de travail avec les tâches Azure Databricks.
- Utilisez les guides pratiques et tutoriels pour en savoir plus sur l’implémentation de workflows de données avec les travaux Azure Databricks.
Qu’est-ce que Delta Live Tables ?
Notes
Delta Live Tables nécessite le plan Premium. Contactez l'équipe de votre compte Databricks pour plus d'informations.
Delta Live Tables est un framework qui simplifie le traitement des données ETL et de diffusion en continu. Delta Live Tables fournit une ingestion efficace des données avec une prise en charge intégrée des interfaces Auto Loader, SQL et Python qui prennent en charge l’implémentation déclarative des transformations de données, ainsi que la prise en charge de l’écriture de données transformées dans Delta Lake. Vous définissez les transformations à effectuer sur vos données, tandis que Delta Live Tables gère l’orchestration des tâches, la gestion des clusters, la supervision, la qualité des données et la gestion des erreurs.
Pour commencer, consultez Qu’est-ce que Delta Live Tables ?.
Travaux Azure Databricks et Delta Live Tables
Les tableaux Azure Databricks et Delta Live Tables fournissent une infrastructure complète pour la création et le déploiement de workflows de traitement et d’analyse de données de bout en bout.
Utilisez Delta Live Tables pour l’ensemble des opérations d’ingestion et de transformation des données. Utilisez des tâches Azure Databricks pour orchestrer des charges de travail composées d’une tâche unique ou de plusieurs tâches de traitement et d’analyse des données dans la plateforme Databricks, y compris l’ingestion et la transformation de tables Delta Live.
En tant que système d’orchestration de workflow, les travaux Azure Databricks prennent également en charge :
- Exécution de travaux sur la base d’un déclencheur, par exemple, exécution d’un workflow selon une planification.
- Analyse des données via des requêtes SQL, Machine Learning et analyse de données avec des notebooks, des scripts ou des bibliothèques externes, etc.
- Exécution d’un travail composé d’une seule tâche, par exemple, d’un travail Apache Spark empaqueté dans un fichier JAR.
Orchestration de workflow avec Apache AirFlow
Bien que Databricks recommande d’utiliser des travaux Azure Databricks pour orchestrer vos workflows de données, vous pouvez également utiliser Apache Airflow pour gérer et planifier vos workflows de données. Avec Airflow, vous définissez votre workflow dans un fichier Python et Airflow gère la planification et l’exécution du workflow. Consultez Orchestrer des travaux Azure Databricks avec Apache Airflow.
Orchestration de workflow avec Azure Data Factory
Azure Data Factory (ADF) est un service d’intégration des données cloud permettant de composer des services de stockage, de déplacement et de traitement des données dans des pipelines de données automatisés. Vous pouvez utiliser ADF pour orchestrer un travail Azure Databricks dans le cadre d’un pipeline ADF.
Pour savoir comment exécuter un travail à l’aide de l’activité ADF Web, notamment comment s’authentifier auprès d’Azure Databricks à partir d’ADF, consultez Leverage Azure Databricks jobs orchestration from Azure Data Factory (Tirer parti de l’orchestration des travaux Azure Databricks à partir d’Azure Data Factory).
ADF intègre également la prise en charge de l’exécution de notebooks Databricks, de scripts Python ou de code empaqueté dans des fichiers JAR dans un pipeline ADF.
Pour savoir comment exécuter un notebook Databricks dans un pipeline ADF, consultez Exécuter un notebook Databricks avec l’activité Databricks Notebook dans Azure Data Factory, puis Transformer les données en exécutant un notebook Databricks.
Pour savoir comment exécuter un script Python dans un pipeline ADF, consultez Transformer des données en exécutant une activité Python dans Azure Databricks.
Pour savoir comment exécuter du package de code dans un fichier JAR dans un pipeline ADF, consultez Transformer des données en exécutant une activité JAR dans Azure Databricks.