Décalage vers la droite pour le test en production
Le décalage à droite est la pratique de déplacer des tests plus loin dans le processus DevOps pour tester en production. Le test en production utilise des déploiements réels pour valider et mesurer le comportement et les performances d’une application dans l’environnement de production.
L’une des façons dont les équipes DevOps peuvent améliorer la vitesse consiste à utiliser une stratégie de test décalée vers la gauche. Le décalage à gauche pousse la plupart des tests plus tôt dans le pipeline DevOps, afin de réduire le temps nécessaire pour que le nouveau code atteigne la production et fonctionne de manière fiable.
Toutefois, bien que de nombreux types de tests, tels que les tests unitaires, puissent facilement basculer vers la gauche, certaines classes de tests ne peuvent pas s’exécuter sans déployer une partie ou toute une solution. Le déploiement sur un service d’assurance qualité ou intermédiaire peut simuler un environnement comparable, mais il n’existe aucun substitut complet à l’environnement de production. Les équipes constatent que certains types de tests doivent être effectués en production.
Le test en production fournit :
- L’étendue et la diversité complètes de l’environnement de production.
- La charge de travail réelle du trafic client.
- Profils et comportements à mesure que la demande de production évolue au fil du temps.
L’environnement de production continue de changer. Même si une application ne change pas, l’infrastructure sur laquelle elle repose change constamment. Le test en production valide l’intégrité et la qualité d’un déploiement de production donné et de l’environnement de production en constante évolution.
Le passage direct au test en production est particulièrement important pour les scénarios suivants :
Déploiements de microservices
Les solutions basées sur des microservices peuvent avoir un grand nombre de microservices développés, déployés, et gérés indépendamment. Le décalage des tests sur la droite est particulièrement important pour ces projets, car différentes versions et configurations peuvent atteindre la production de plusieurs façons. Quelle que soit la couverture des tests de pré-production, il est nécessaire de tester la compatibilité en production.
Garantir la qualité après le déploiement
La mise en production n’est que la moitié de la livraison de logiciels. L’autre moitié consiste à garantir la qualité à grande échelle avec une charge de travail réelle en production. Parce que l’environnement ne cesse de changer, une équipe n’en a jamais fini avec le test en production.
Les données de test de la production sont littéralement les résultats de test de la charge de travail réelle du client. Le test en production comprend la surveillance, le test de basculement et l’injection de pannes. Ce test effectue le suivi des échecs, des exceptions, des métriques de performances et des événements de sécurité. Le télémétrie de test permet également de détecter les anomalies.
Anneaux de déploiement
Pour protéger l’environnement de production, les équipes peuvent effectuer des modifications de manière progressive et contrôlée à l’aide de déploiements en anneau et d’indicateurs de fonctionnalités. Par exemple, il est préférable de détecter un bogue qui empêche un acheteur de finaliser son achat lorsque moins de 1 % des clients sont sur cet anneau de déploiement, plutôt qu’après avoir basculé tous les clients à la fois. La valeur de fonctionnalité avec les défaillances détectées doit dépasser les pertes nettes de ces défaillances, mesurées de manière significative pour l’entreprise donnée.
Le premier anneau doit être de la plus petite taille nécessaire pour exécuter la suite d’intégration standard. Les tests peuvent être similaires à ceux déjà exécutés plus tôt dans le pipeline contre d’autres environnements, mais les tests valident que le comportement est le même dans l’environnement de production. Cet anneau identifie les erreurs évidentes, telles que les erreurs de configuration, avant qu’elles n’affectent les clients.
Une fois l’anneau initial validé, l’anneau suivant peut s’élargir pour inclure un sous-ensemble d’utilisateurs réels pour l’exécution de test. Si tout semble correct, le déploiement peut progresser à travers d’autres anneaux et tests jusqu’à ce que tout le monde l’utilise. Le déploiement complet ne signifie pas que les tests sont terminés. La télémétrie de suivi est essentielle pour le test en production.
Injection d’erreurs
Les équipes utilisent souvent l'injection de pannes et l’ingénierie du chaos pour voir comment un système se comporte dans des conditions de défaillance. Ces pratiques aident à :
- Valider que les mécanismes de résilience mis en œuvre fonctionnent réellement.
- Valider qu’une défaillance dans un sous-système est contenue dans ce sous-système et ne se répercute pas pour produire une panne majeure.
- Prouver que les travaux de réparation d’un incident antérieur ont l’effet souhaité, sans avoir à attendre qu’un autre incident se produise.
- Créer des exercices de formation plus réalistes pour les ingénieurs de site en direct afin qu’ils puissent mieux se préparer à faire face aux incidents.
C'est une bonne pratique d’automatiser les expériences d’injection de pannes, car ce sont des tests coûteux qui doivent être exécutés sur des systèmes en constante évolution.
L’ingénierie du chaos peut être un outil efficace, mais doit être limité aux environnements canaris qui ont peu ou pas d’impact sur le client.
Test de basculement
Une forme d’injection de pannes est le test de basculement pour prendre en charge la continuité d’activité et la reprise d'activité après sinistre (BCDR). Les équipes doivent avoir des plans de basculement pour tous les services et sous-systèmes. Les plans devraient inclure :
- Une explication claire de l’impact commercial de la panne du service.
- Une carte de toutes les dépendances en termes de plateforme, de technologie et de personnes concevant les plans BCDR.
- Documentation formelle des procédures de reprise d'activité après sinistre.
- Une cadence d’exécution régulière des exercices de reprise d'activité après sinistre.
Test de défaut de disjoncteur
Un mécanisme de disjoncteur coupe un composant donné d’un système plus grand, généralement pour empêcher les défaillances de ce composant de se propager en dehors de ses limites. Vous pouvez déclencher intentionnellement des disjoncteurs pour tester les scénarios suivants :
Si un secours fonctionne lorsque le disjoncteur s’ouvre. La solution de secours peut fonctionner avec des tests unitaires, mais la seule façon de savoir si elle se comportera comme prévu en production est d'injecter un défaut pour la déclencher.
Si le disjoncteur a le seuil de sensibilité approprié pour s'ouvrir quand il le faut. L’injection de pannes peut forcer la latence ou déconnecter les dépendances pour observer la réactivité du disjoncteur. Il est important de vérifier non seulement que le comportement correct se produit, mais aussi qu’il se produit assez rapidement.
Exemple : Tester un disjoncteur de cache Redis
Le cache Redis améliore les performances du produit en accélérant l’accès aux données couramment utilisées. Considérez un scénario qui prend une dépendance non critique sur Redis. Si Redis tombe en panne, le système doit continuer à fonctionner, car il peut revenir à l’utilisation de la source de données d’origine pour les requêtes. Pour confirmer qu’une défaillance Redis déclenche un disjoncteur et que le secours fonctionne en production, exécutez régulièrement des tests contre ces comportements.
Le diagramme suivant montre les tests du comportement de secours du disjoncteur Redis. L’objectif est de s’assurer que lorsque le disjoncteur s’ouvre, les appels sont finalement passés à SQL.
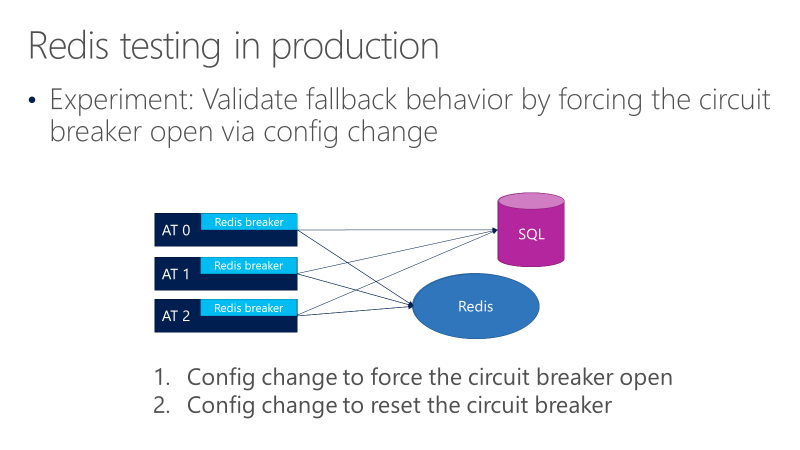
Le diagramme précédent montre trois AT, avec les disjoncteurs devant les appels à Redis. Un test force le disjoncteur à s’ouvrir par le biais d’une modification de configuration, puis observe si les appels sont dirigés vers SQL. Un autre test vérifie ensuite le changement de configuration opposé, en fermant le disjoncteur pour confirmer que les appels reviennent à Redis.
Ce test valide que le comportement de secours fonctionne lorsque le disjoncteur s’ouvre, mais il ne valide pas que la configuration du disjoncteur ouvre le disjoncteur quand il le devrait. Tester ce comportement nécessite de simuler des pannes réelles.
Un agent de défaut peut introduire des défauts dans les appels dirigés vers Redis. Le diagramme suivant montre les tests avec injection de défauts.
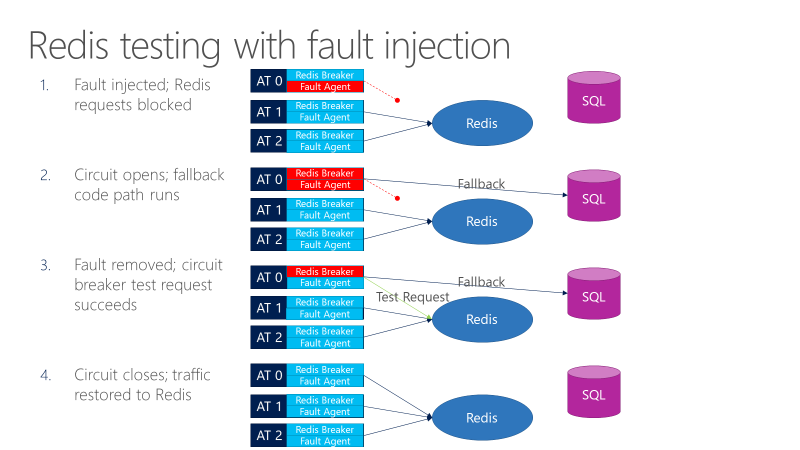
- L’injecteur de pannes bloque les requêtes Redis.
- Le disjoncteur s’ouvre et le test peut observer si le secours fonctionne.
- Le défaut est supprimé et le disjoncteur envoie une requête de test à Redis.
- Si la requête réussit, les appels reviennent à Redis.
D’autres étapes peuvent tester la sensibilité du disjoncteur, si le seuil est trop élevé ou trop bas, et si d’autres délais d’attente du système interfèrent avec le comportement du disjoncteur.
Dans cet exemple, si le disjoncteur ne s’ouvre pas ou ne se ferme pas comme prévu, il peut provoquer un incident de site en direct (LSI). Sans le test d’injection de pannes, le problème peut ne pas être détecté, car il est difficile d’effectuer ce type de test dans un environnement de lab.
Étapes suivantes
- [Décaler les tests à gauche avec les tests unitaires]décalage à gauche
- Que sont les microservices ?
- Exécuter un test de basculement (exercice de récupération d'urgence) sur Azure
- Pratiques de déploiement sécurisé
- Qu’est-ce que la supervision ?
- Qu’est-ce que l’ingénierie de plateforme ?
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour