Notes de publication Azure DevOps Server 2020
| Developer Community Exigences du système Termes | du contrat de licence | DevOps Blog | SHA-1 Hachages
Dans cet article, vous trouverez des informations sur la dernière version pour Azure DevOps Server.
Pour en savoir plus sur l’installation ou la mise à niveau d’un déploiement de Azure DevOps Server, consultez Azure DevOps Server Configuration requise. Pour télécharger des produits Azure DevOps, accédez à la page Téléchargements Azure DevOps Server.
La mise à niveau directe vers Azure DevOps Server 2020 est prise en charge à partir de Azure DevOps Server 2019 ou de Team Foundation Server 2015 ou version ultérieure. Si votre déploiement TFS est sur TFS 2010 ou une version antérieure, vous devez effectuer certaines étapes intermédiaires avant de procéder à la mise à niveau vers Azure DevOps Server 2019. Pour plus d’informations, consultez Installer et configurer Azure DevOps en local.
Mise à niveau sécurisée de Azure DevOps Server 2019 vers Azure DevOps Server 2020
Azure DevOps Server 2020 introduit un nouveau modèle de rétention d’exécution de pipeline (build) qui fonctionne en fonction des paramètres au niveau du projet.
Azure DevOps Server 2020 gère différemment la rétention des build, en fonction des stratégies de rétention au niveau du pipeline. Certaines configurations de stratégie entraînent la suppression des exécutions de pipeline après la mise à niveau. Les exécutions de pipeline qui ont été conservées manuellement ou qui sont conservées par une version ne seront pas supprimées après la mise à niveau.
Lisez notre billet de blog pour plus d’informations sur la mise à niveau sécurisée de Azure DevOps Server 2019 à Azure DevOps Server 2020.
Azure DevOps Server 2020 Update 0.2 Patch 6 Date de publication : 14 novembre 2023
Nous avons publié un correctif pour Azure DevOps Server 2020 Update 0.2 qui inclut les correctifs suivants.
- Extension de la liste de caractères autorisée des tâches PowerShell pour la validation des paramètres Activer les arguments des tâches de l’interpréteur de commandes.
Notes
Pour implémenter des correctifs pour ce correctif, vous devez suivre un certain nombre d’étapes pour mettre à jour manuellement les tâches.
Installer les correctifs
Important
Nous avons publié des mises à jour de l’agent Azure Pipelines avec le correctif 4 publié le 12 septembre 2023. Si vous n’avez pas installé les mises à jour de l’agent comme décrit dans les notes de publication du correctif 4, nous vous recommandons d’installer ces mises à jour avant d’installer le correctif 6. La nouvelle version de l’agent après l’installation du correctif 4 sera 3.225.0.
Configurer TFX
- Suivez les étapes décrites dans la documentation de chargement des tâches dans la collection de projets pour installer et vous connecter avec tfx-cli.
Mettre à jour des tâches à l’aide de TFX
| Fichier | Hachage SHA-256 |
|---|---|
| Tasks20231103.zip | 389BA66EEBC32622FB83402E21373CE20AE040F70461B9F9AF9EFCED5034D2E5 |
- Téléchargez et extrayezTasks20231103.zip.
- Remplacez le répertoire par les fichiers extraits.
- Exécutez les commandes suivantes pour charger les tâches :
tfx build tasks upload --task-zip-path AzureFileCopyV1.1.230.0.zip
tfx build tasks upload --task-zip-path AzureFileCopyV2.2.230.0.zip
tfx build tasks upload --task-zip-path AzureFileCopyV3.3.230.0.zip
tfx build tasks upload --task-zip-path AzureFileCopyV4.4.230.0.zip
tfx build tasks upload --task-zip-path AzureFileCopyV5.5.230.0.zip
tfx build tasks upload --task-zip-path BashV3.3.226.2.zip
tfx build tasks upload --task-zip-path BatchScriptV1.1.226.0.zip
tfx build tasks upload --task-zip-path PowerShellV2.2.230.0.zip
tfx build tasks upload --task-zip-path SSHV0.0.226.1.zip
tfx build tasks upload --task-zip-path WindowsMachineFileCopyV1.1.230.0.zip
tfx build tasks upload --task-zip-path WindowsMachineFileCopyV2.2.230.0.zip
Configuration requise du pipeline
Pour utiliser le nouveau comportement, une variable AZP_75787_ENABLE_NEW_LOGIC = true doit être définie dans les pipelines qui utilisent les tâches affectées.
Sur classique :
Définissez la variable dans l’onglet variable du pipeline.
Exemple YAML :
variables:
- name: AZP_75787_ENABLE_NEW_LOGIC
value: true
Azure DevOps Server 2020 Update 0.2 Patch 5 Date de publication : 10 octobre 2023
Important
Nous avons publié des mises à jour de l’agent Azure Pipelines avec le correctif 4 publié le 12 septembre 2023. Si vous n’avez pas installé les mises à jour de l’agent comme décrit dans les notes de publication du correctif 4, nous vous recommandons d’installer ces mises à jour avant d’installer le correctif 5. La nouvelle version de l’agent après l’installation du correctif 4 sera 3.225.0.
Nous avons publié un correctif pour Azure DevOps Server 2020 Update 0.2 qui inclut les correctifs suivants.
- Correction d’un bogue où l’identité « Propriétaire de l’analyse » s’affiche en tant qu’identité inactive sur les machines de mise à niveau corrective.
Azure DevOps Server 2020 Update 0.2 Patch 4 Date de publication : 12 septembre 2023
Nous avons publié un correctif pour Azure DevOps Server 2020 Update 0.2 qui inclut les correctifs suivants.
- CVE-2023-33136 : Azure DevOps Server vulnérabilité d’exécution de code à distance.
- CVE-2023-38155 : vulnérabilité d’élévation de privilèges Azure DevOps Server et Team Foundation Server.
Important
Déployez le correctif dans un environnement de test et assurez-vous que les pipelines de l’environnement fonctionnent comme prévu avant d’appliquer le correctif en production.
Notes
Pour implémenter des correctifs pour ce correctif, vous devez suivre un certain nombre d’étapes pour mettre à jour manuellement l’agent et les tâches.
Installer les correctifs
- Téléchargez et installez Azure DevOps Server 2020 Update 0.2 patch 4.
Mettre à jour l’agent Azure Pipelines
- Téléchargez l’agent à partir de : https://github.com/microsoft/azure-pipelines-agent/releases/tag/v3.225.0 - Agent_20230825.zip
- Utilisez les étapes décrites dans la documentation des agents Windows auto-hébergés pour déployer l’agent.
Notes
Le AZP_AGENT_DOWNGRADE_DISABLED doit être défini sur « true » pour empêcher le rétrogradé de l’agent. Sur Windows, la commande suivante peut être utilisée dans une invite de commandes d’administration, suivie d’un redémarrage. setx AZP_AGENT_DOWNGRADE_DISABLED true /M
Configurer TFX
- Suivez les étapes décrites dans la documentation de chargement des tâches dans la collection de projets pour installer et vous connecter avec tfx-cli.
Mettre à jour des tâches à l’aide de TFX
- Téléchargez et extrayezTasks_20230825.zip.
- Remplacez le répertoire par les fichiers extraits.
- Exécutez les commandes suivantes pour charger les tâches :
tfx build tasks upload --task-zip-path AzureFileCopyV1.1.226.3.zip
tfx build tasks upload --task-zip-path AzureFileCopyV2.2.226.2.zip
tfx build tasks upload --task-zip-path AzureFileCopyV3.3.226.2.zip
tfx build tasks upload --task-zip-path AzureFileCopyV4.4.226.2.zip
tfx build tasks upload --task-zip-path AzureFileCopyV5.5.226.2.zip
tfx build tasks upload --task-zip-path BashV3.3.226.2.zip
tfx build tasks upload --task-zip-path BatchScriptV1.1.226.0.zip
tfx build tasks upload --task-zip-path PowerShellV2.2.226.1.zip
tfx build tasks upload --task-zip-path SSHV0.0.226.1.zip
tfx build tasks upload --task-zip-path WindowsMachineFileCopyV1.1.226.2.zip
tfx build tasks upload --task-zip-path WindowsMachineFileCopyV2.2.226.2.zip
Configuration requise du pipeline
Pour utiliser le nouveau comportement, une variable AZP_75787_ENABLE_NEW_LOGIC = true doit être définie dans les pipelines qui utilisent les tâches affectées.
Sur classique :
Définissez la variable dans l’onglet variable du pipeline.
Exemple YAML :
variables:
- name: AZP_75787_ENABLE_NEW_LOGIC
value: true
Azure DevOps Server 2020 Update 0.2 Patch 3 Date de publication : 8 août 2023
Nous avons publié un correctif pour Azure DevOps Server 2020 Update 0.2 qui inclut les correctifs suivants.
- Correction d’un bogue qui interfère avec l’envoi de packages lors de la mise à niveau à partir de 2018 ou d’une version antérieure.
Azure DevOps Server 2020 Update 0.2 Patch 2 Date de publication : 13 juin 2023
Nous avons publié un correctif pour Azure DevOps Server 2020 Update 0.2 qui inclut les correctifs suivants.
- Correction d’un bogue qui interfère avec l’envoi de packages lors de la mise à niveau à partir de 2018 ou d’une version antérieure.
Azure DevOps Server 2020 Update 0.2 Patch 1 Date de publication : 18 octobre 2022
Nous avons publié un correctif pour Azure DevOps Server 2020 Update 0.2 qui inclut les correctifs suivants.
- Résolvez le problème lié aux identités AD nouvellement ajoutées qui n’apparaissent pas dans les sélecteurs d’identité de boîte de dialogue de sécurité.
- Correction d’un problème avec le filtre Demandé par membre du groupe dans les paramètres du web hook.
- Corrigez l’erreur de génération de case activée-in gated lorsque les paramètres d’organisation du pipeline avaient une étendue d’autorisation de travail configurée comme Limiter l’étendue de l’autorisation de travail au projet actuel pour les pipelines sans mise en production.
Azure DevOps Server 2020.0.2 Date de publication : 17 mai 2022
Azure DevOps Server 2020.0.2 est un cumul de correctifs de bogues. Vous pouvez installer directement Azure DevOps Server 2020.0.2 ou effectuer une mise à niveau à partir de Azure DevOps Server 2020 ou de Team Foundation Server 2013 ou version ultérieure.
Notes
L’outil de migration de données sera disponible pour Azure DevOps Server 2020.0.2 environ trois semaines après cette version. Pour consulter la liste des versions actuellement prises en charge pour l’importation, cliquez ici.
Cette version inclut des correctifs pour les éléments suivants :
Impossible d’ignorer la file d’attente de build à l’aide du bouton « Exécuter ensuite ». Auparavant, le bouton « Exécuter ensuite » était activé uniquement pour les administrateurs de collection de projets.
Révoquez tous les jetons d’accès personnels après la désactivation du compte Active Directory d’un utilisateur.
Azure DevOps Server 2020.0.1 Patch 9 Date de publication : 26 janvier 2022
Nous avons publié un correctif pour Azure DevOps Server 2020.0.1 qui inclut les correctifs suivants.
- Email notifications n’ont pas été envoyées lors de l’utilisation du @mention contrôle dans un élément de travail.
- Correction TF400813 erreur lors du changement de compte. Cette erreur s’est produite lors de la mise à niveau de TFS 2018 vers Azure DevOps Server 2020.0.1.
- Résolution d’un problème lié au chargement de la page résumé De la vue d’ensemble du projet.
- Amélioration de la synchronisation des utilisateurs Active Directory.
- Résolution de la vulnérabilité Elasticsearch en supprimant la classe jndilookup des fichiers binaires log4j.
Procédure d’installation :
- Mettez à niveau le serveur avec le correctif 9.
- Vérifiez la valeur du Registre à l’adresse
HKLM:\Software\Elasticsearch\Version. Si la valeur de Registre n’existe pas, ajoutez une valeur de chaîne et définissez version sur 5.4.1 (Nom = Version, Valeur = 5.4.1). - Exécutez la commande
PS C:\Program Files\{TFS Version Folder}\Search\zip> .\Configure-TFSSearch.ps1 -Operation updateupdate comme indiqué dans le fichier lisez-moi. Il peut renvoyer un avertissement du type : Impossible de se connecter au serveur distant. Ne fermez pas la fenêtre, car la mise à jour effectue de nouvelles tentatives jusqu’à ce qu’elle soit terminée.
Notes
Si Azure DevOps Server et Elasticsearch sont installés sur des ordinateurs différents, suivez les étapes décrites ci-dessous.
- Mettez à niveau le serveur avec patch 9..
- Vérifiez la valeur du Registre à l’adresse
HKLM:\Software\Elasticsearch\Version. Si la valeur de Registre n’existe pas, ajoutez une valeur de chaîne et définissez version sur 5.4.1 (Nom = Version, Valeur = 5.4.1). - Copiez le contenu du dossier nommé zip, situé dans
C:\Program Files\{TFS Version Folder}\Search\ziple dossier de fichiers distants Elasticsearch. - Exécutez
Configure-TFSSearch.ps1 -Operation updatesur l’ordinateur serveur Elasticsearch.
Hachage SHA-256 : B0C05A972C73F253154AEEB7605605EF2E596A96A3720AE942D7A9DDD881545E
Azure DevOps Server 2020.0.1 Patch 8 Date de publication : 15 décembre 2021
Le correctif 8 pour Azure DevOps Server 2020.0.1 inclut des correctifs pour les éléments suivants.
- Problème de localisation pour les états de disposition des éléments de travail personnalisés.
- Problème de localisation dans le modèle de notification par e-mail.
- Problème lié à la troncation des journaux de console lorsqu’il existe plusieurs liens identiques dans une ligne.
- Problème avec l’évaluation des règles NOTSAMEAS lorsque plusieurs règles NOTSAMEAS ont été définies pour un champ.
Azure DevOps Server 2020.0.1 Patch 7 Date de publication : 26 octobre 2021
Le correctif 7 pour Azure DevOps Server 2020.0.1 inclut des correctifs pour les éléments suivants.
- Auparavant, Azure DevOps Server pouviez uniquement créer des connexions à GitHub Enterprise Server. Avec ce correctif, les administrateurs de projet peuvent créer des connexions entre Azure DevOps Server et les dépôts sur GitHub.com. Vous trouverez ce paramètre dans la page connexions GitHub sous Paramètres du projet.
- Résoudre le problème avec le widget Plan de test. Le rapport d’exécution des tests affichait un utilisateur incorrect sur les résultats.
- Résolution d’un problème lié au chargement de la page résumé De la vue d’ensemble du projet.
- Correction du problème lié à l’envoi d’e-mails pour confirmer la mise à niveau du produit.
Azure DevOps Server 2020.0.1 Patch 6 Date de publication : 14 septembre 2021
Le correctif 6 pour Azure DevOps Server 2020.0.1 inclut des correctifs pour les éléments suivants.
- Correction de l’échec de téléchargement/chargement des artefacts.
- Résolvez le problème lié aux données de résultats de test incohérentes.
Azure DevOps Server 2020.0.1 Patch 5 Date de publication : 10 août 2021
Le correctif 5 pour Azure DevOps Server 2020.0.1 inclut des correctifs pour les éléments suivants.
- Correction de l’erreur d’interface utilisateur de définition de build.
- Modification de l’historique de navigation pour afficher les fichiers au lieu du dépôt racine.
- Correction du problème lié aux tâches de remise d’e-mails pour certains types d’éléments de travail.
Azure DevOps Server 2020.0.1 Patch 4 Date de publication : 15 juin 2021
Le correctif 4 pour Azure DevOps Server 2020.0.1 inclut des correctifs pour les éléments suivants.
- Correction du problème lié à l’importation de données. L’importation de données prenait beaucoup de temps pour les clients qui ont beaucoup de cas de test obsolètes. Cela était dû aux références qui ont augmenté la taille de la
tbl_testCaseReferencestable. Avec ce correctif, nous avons supprimé les références aux cas de test obsolètes pour accélérer le processus d’importation des données.
Azure DevOps Server 2020.0.1 Patch 3 Date de publication : 11 mai 2021
Nous avons publié un correctif pour Azure DevOps Server 2020.0.1 qui corrige les problèmes suivants.
- Données de résultats de test incohérentes lors de l’utilisation de Microsoft.TeamFoundation.TestManagement.Client.
Si vous avez Azure DevOps Server 2020.0.1, vous devez installer Azure DevOps Server 2020.0.1 Patch 3.
Vérification de l’installation
Option 1 : exécutez
devops2020.0.1patch3.exe CheckInstall, devops2020.0.1patch3.exe est le fichier téléchargé à partir du lien ci-dessus. La sortie de la commande indique soit que le correctif a été installé, soit qu’il n’est pas installé.Option 2 : Vérifiez la version du fichier suivant :
[INSTALL_DIR]\Azure DevOps Server 2020\Application Tier\bin\Microsoft.Teamfoundation.Framework.Server.dll. Azure DevOps Server 2020.0.1 est installéc:\Program Files\Azure DevOps Server 2020sur par défaut. Après avoir installé Azure DevOps Server 2020.0.1 Patch 3, la version sera 18.170.31228.1.
Azure DevOps Server 2020.0.1 Patch 2 Date de publication : 13 avril 2021
Notes
Si vous avez Azure DevOps Server 2020, vous devez d’abord mettre à jour vers Azure DevOps Server 2020.0.1 . Une fois sur 2020.0.1, installez Azure DevOps Server 2020.0.1 Patch 2
Nous avons publié un correctif pour Azure DevOps Server 2020.0.1 qui corrige les problèmes suivants.
- CVE-2021-27067 : Divulgation d’informations
- CVE-2021-28459 : Élévation de privilèges
Pour implémenter des correctifs pour ce correctif, vous devez suivre les étapes ci-dessous pour l’installation générale des correctifs, les installations de tâches AzureResourceGroupDeploymentV2 et AzureResourceManagerTemplateDeploymentV3 .
Installation générale des correctifs
Si vous avez Azure DevOps Server 2020.0.1, vous devez installer Azure DevOps Server 2020.0.1 Patch 2.
Vérification de l’installation
Option 1 : exécutez
devops2020.0.1patch2.exe CheckInstall, devops2020.0.1patch2.exe est le fichier téléchargé à partir du lien ci-dessus. La sortie de la commande indique soit que le correctif a été installé, soit qu’il n’est pas installé.Option 2 : Vérifiez la version du fichier suivant :
[INSTALL_DIR]\Azure DevOps Server 2020\Application Tier\bin\Microsoft.Teamfoundation.Framework.Server.dll. Azure DevOps Server 2020.0.1 est installéc:\Program Files\Azure DevOps Server 2020sur par défaut. Après avoir installé Azure DevOps Server 2020.0.1 Patch 2, la version sera 18.170.31123.3.
Installation de la tâche AzureResourceGroupDeploymentV2
Notes
Toutes les étapes mentionnées ci-dessous doivent être effectuées sur un ordinateur Windows
Installer
Extrayez le package AzureResourceGroupDeploymentV2.zip dans un nouveau dossier sur votre ordinateur. Par exemple : D :\tasks\AzureResourceGroupDeploymentV2.
Téléchargez et installez Node.js 14.15.1 et npm (inclus avec le téléchargement Node.js) en fonction de votre ordinateur.
Ouvrez une invite de commandes en mode administrateur et exécutez la commande suivante pour installer tfx-cli.
npm install -g tfx-cli
Create un jeton d’accès personnel avec des privilèges d’accès complets et copiez-le. Ce jeton d’accès personnel sera utilisé lors de l’exécution de la commande tfx login .
Exécutez la commande suivante à partir de l’invite de commandes. Lorsque vous y êtes invité, entrez l’URL du service et le jeton d’accès personnel.
~$ tfx login
Copyright Microsoft Corporation
> Service URL: {url}
> Personal access token: xxxxxxxxxxxx
Logged in successfully
- Exécutez la commande suivante pour charger la tâche sur le serveur. Utilisez le chemin d’accès du fichier .zip extrait à l’étape 1.
~$ tfx build tasks upload --task-path *<Path of the extracted package>*
Installation de la tâche AzureResourceManagerTemplateDeploymentV3
Notes
Toutes les étapes mentionnées ci-dessous doivent être effectuées sur un ordinateur Windows
Installer
Extrayez le package AzureResourceManagerTemplateDeploymentV3.zip dans un nouveau dossier sur votre ordinateur. Par exemple : D :\tasks\AzureResourceManagerTemplateDeploymentV3.
Téléchargez et installez Node.js 14.15.1 et npm (inclus avec le téléchargement Node.js) en fonction de votre ordinateur.
Ouvrez une invite de commandes en mode administrateur et exécutez la commande suivante pour installer tfx-cli.
npm install -g tfx-cli
Create un jeton d’accès personnel avec des privilèges d’accès complets et copiez-le. Ce jeton d’accès personnel sera utilisé lors de l’exécution de la commande tfx login .
Exécutez ce qui suit à partir de l’invite de commandes. Lorsque vous y êtes invité, entrez l’URL du service et le jeton d’accès personnel.
~$ tfx login
Copyright Microsoft Corporation
> Service URL: {url}
> Personal access token: xxxxxxxxxxxx
Logged in successfully
- Exécutez la commande suivante pour charger la tâche sur le serveur. Utilisez le chemin du fichier .zip extrait à l’étape 1.
~$ tfx build tasks upload --task-path *<Path of the extracted package>*
Azure DevOps Server 2020.0.1 Patch 1 Date de publication : 9 février 2021
Nous avons publié un correctif pour Azure DevOps Server 2020.0.1 qui corrige ce qui suit. Consultez le billet de blog pour plus d’informations.
- Résoudre le problème signalé dans ce ticket de commentaires Developer Community | Le bouton Nouveau cas de test ne fonctionne pas
- Incluez les correctifs publiés avec Azure DevOps Server Correctif 2 2020.
Azure DevOps Server 2020 Patch 3 Date de publication : 9 février 2021
Nous avons publié un correctif pour Azure DevOps Server 2020 qui corrige ce qui suit. Consultez le billet de blog pour plus d’informations.
- Résoudre le problème signalé dans ce ticket de commentaires Developer Community | Le bouton Nouveau cas de test ne fonctionne pas
Azure DevOps Server 2020.0.1 Date de publication : 19 janvier 2021
Azure DevOps Server 2020.0.1 est un cumul de correctifs de bogues. Vous pouvez installer directement Azure DevOps Server 2020.0.1 ou effectuer une mise à niveau à partir d’une installation existante. Les versions prises en charge pour la mise à niveau sont Azure DevOps Server 2020, Azure DevOps Server 2019 et Team Foundation Server 2012 ou version ultérieure.
Cette version inclut les corrections des bugs suivants :
- Résoudre un problème de mise à niveau à partir de Azure DevOps Server 2019 où le proxy Git peut cesser de fonctionner après la mise à niveau.
- Correction de l’exception System.OutOfMemoryException pour les collections non-ENU avant Team Foundation Server 2017 lors de la mise à niveau vers Azure DevOps Server 2020. Résout le problème signalé dans ce ticket de commentaires Developer Community.
- Échec de maintenance provoqué par des Microsoft.Azure.DevOps.ServiceEndpoints.Sdk.Server.Extensions.dll manquants. Résout le problème signalé dans ce ticket de commentaires Developer Community.
- Correction d’une erreur de nom de colonne non valide dans Analytics lors de la mise à niveau vers Azure DevOps Server 2020. Résout le problème signalé dans ce ticket de commentaires Developer Community.
- XSS stocké lors de l’affichage des étapes de cas de test dans les résultats du cas de test.
- Échec de l’étape de mise à niveau lors de la migration des données de résultats des points vers le TCM.
Azure DevOps Server 2020 Patch 2 Date de publication : 12 janvier 2021
Nous avons publié un correctif pour Azure DevOps Server 2020 qui corrige ce qui suit. Consultez le billet de blog pour plus d’informations.
- Les détails de la série de tests n’affichent pas les détails de l’étape de test pour les données de test migrées à l’aide d’OpsHub Migration
- Exception sur l’initialiseur pour « Microsoft.TeamFoundation.TestManagement.Server.TCMLogger »
- Les builds non conservées sont immédiatement supprimées après la migration vers Azure DevOps Server 2020
- Corriger l’exception du fournisseur de données
Azure DevOps Server 2020 Date du correctif 1 : 8 décembre 2020
Nous avons publié un correctif pour Azure DevOps Server 2020 qui corrige ce qui suit. Consultez le billet de blog pour plus d’informations.
- CVE-2020-17145 : vulnérabilité d’usurpation d’identité Azure DevOps Server et Team Foundation Services
Azure DevOps Server 2020 Date de publication : 6 octobre 2020
Azure DevOps Server 2020 est un cumul de correctifs de bogues. Il inclut toutes les fonctionnalités du Azure DevOps Server RC2 2020 publié précédemment.
Notes
Azure DevOps 2020 Server rencontre un problème lors de l’installation de l’un des assemblys utilisés par le système de fichiers virtuel Git (GVFS).
Si vous effectuez une mise à niveau à partir d’Azure DevOps 2019 (n’importe quelle version) ou d’un candidat de publication Azure DevOps 2020 et que vous effectuez une installation vers le même répertoire que la version précédente, l’assembly Microsoft.TeamFoundation.Git.dll n’est pas installé. Vous pouvez vérifier que vous avez rencontré le problème en recherchant Microsoft.TeamFoundation.Git.dll dans les <Install Dir>\Version Control Proxy\Web Services\bindossiers et <Install Dir>\Application Tier\TFSJobAgent<Install Dir>\Tools . Si le fichier est manquant, vous pouvez exécuter une réparation pour restaurer les fichiers manquants.
Pour exécuter une réparation, accédez à Settings -> Apps & Features la Azure DevOps Server machine/machine virtuelle et exécutez une réparation sur Azure DevOps 2020 Server. Une fois la réparation terminée, vous pouvez redémarrer la machine/machine virtuelle.
Azure DevOps Server 2020 RC2 Date de publication : 11 août 2020
Azure DevOps Server 2020 RC2 est un cumul de correctifs de bogues. Il inclut toutes les fonctionnalités du Azure DevOps Server 2020 RC1 publié précédemment.
Azure DevOps Server 2020 RC1 date de publication : 10 juillet 2020
Nous avons re-publié Azure DevOps Server RC1 2020 pour résoudre ce Developer Community ticket de commentaires.
Auparavant, après la mise à niveau de Azure DevOps Server 2019 Update 1.1 vers Azure DevOps Server 2020 RC1, vous n’étiez pas en mesure d’afficher les fichiers dans Repos, Pipelines et Wiki de l’interface utilisateur web. Un message d’erreur indiquant qu’une erreur inattendue s’est produite dans cette région de la page. Vous pouvez essayer de recharger ce composant ou d’actualiser la page entière. Avec cette version, nous avons résolu ce problème. Consultez le billet de blog pour plus d’informations.
Azure DevOps Server 2020 RC1 Date de publication : 30 juin 2020
Résumé des nouveautés de Azure DevOps Server 2020
Azure DevOps Server 2020 introduit de nombreuses nouvelles fonctionnalités. Voici les principales :
- Pipelines à plusieurs étapes
- Déploiement continu dans YAML
- Suivre la progression des éléments parents à l’aide du backlog Rollup on Boards
- Ajouter le filtre « Élément de travail parent » au tableau des tâches et sprinter le backlog
- Nouvelle interface utilisateur web pour Azure Repos pages d’accueil
- Administration de la stratégie de branche interpo
- Page Nouveau plan de test
- Modification enrichie pour les pages wiki de code
- Rapports d’échec et de durée du pipeline
Vous pouvez également accéder à des sections individuelles pour voir toutes les nouvelles fonctionnalités de chaque service :
Général
Disponibilité générale d’Azure DevOps CLI
En février, nous avons introduit l’extension Azure DevOps pour Azure CLI. L’extension vous permet d’interagir avec Azure DevOps à partir de la ligne de commande. Nous avons collecté vos commentaires qui nous ont aidés à améliorer l’extension et à ajouter d’autres commandes. Nous sommes maintenant heureux d’annoncer que l’extension est en disponibilité générale.
Pour en savoir plus sur l’interface CLI Azure DevOps, consultez la documentation ici.
Utiliser le profil de publication pour déployer Azure WebApps pour Windows à partir du Centre de déploiement
Vous pouvez maintenant utiliser l’authentification basée sur le profil de publication pour déployer vos applications Web Azure pour Windows à partir du Centre de déploiement. Si vous avez l’autorisation de déployer sur une application Web Azure pour Windows à l’aide de son profil de publication, vous pouvez configurer le pipeline à l’aide de ce profil dans les workflows du Centre de déploiement.
Boards
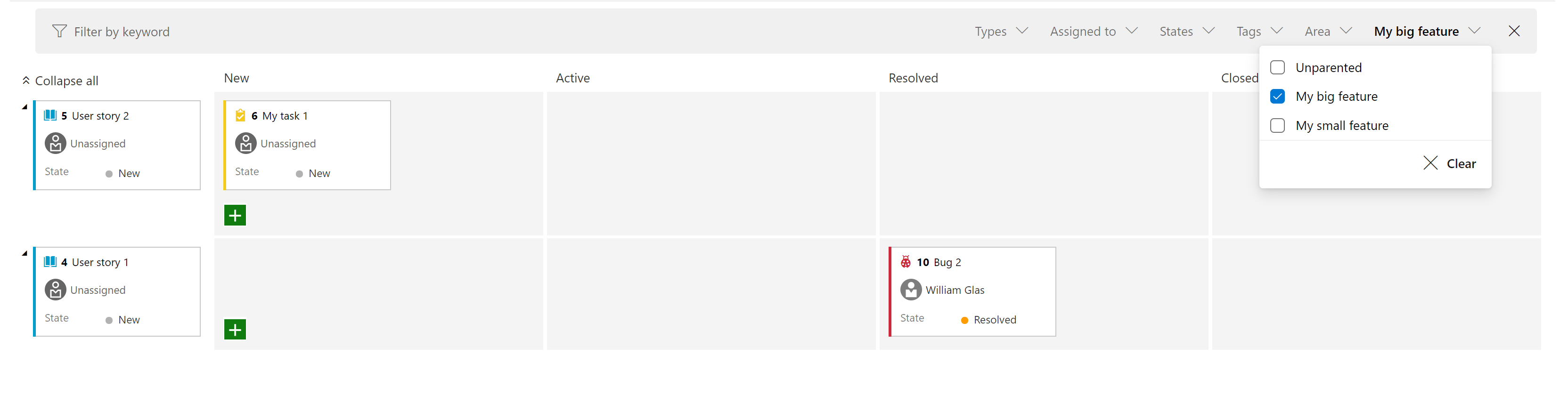
Ajouter le filtre « Élément de travail parent » au tableau des tâches et sprinter le backlog
Nous avons ajouté un nouveau filtre au tableau Sprint et au backlog Sprint. Cela vous permet de filtrer les éléments de backlog au niveau des exigences (première colonne à gauche) par leur parent. Par exemple, dans la capture d’écran ci-dessous, nous avons filtré l’affichage pour afficher uniquement les témoignages d’utilisateurs où le parent est « Ma grande fonctionnalité ».
Améliorer l’expérience de gestion des erreurs : champs obligatoires sur bogue/tâche
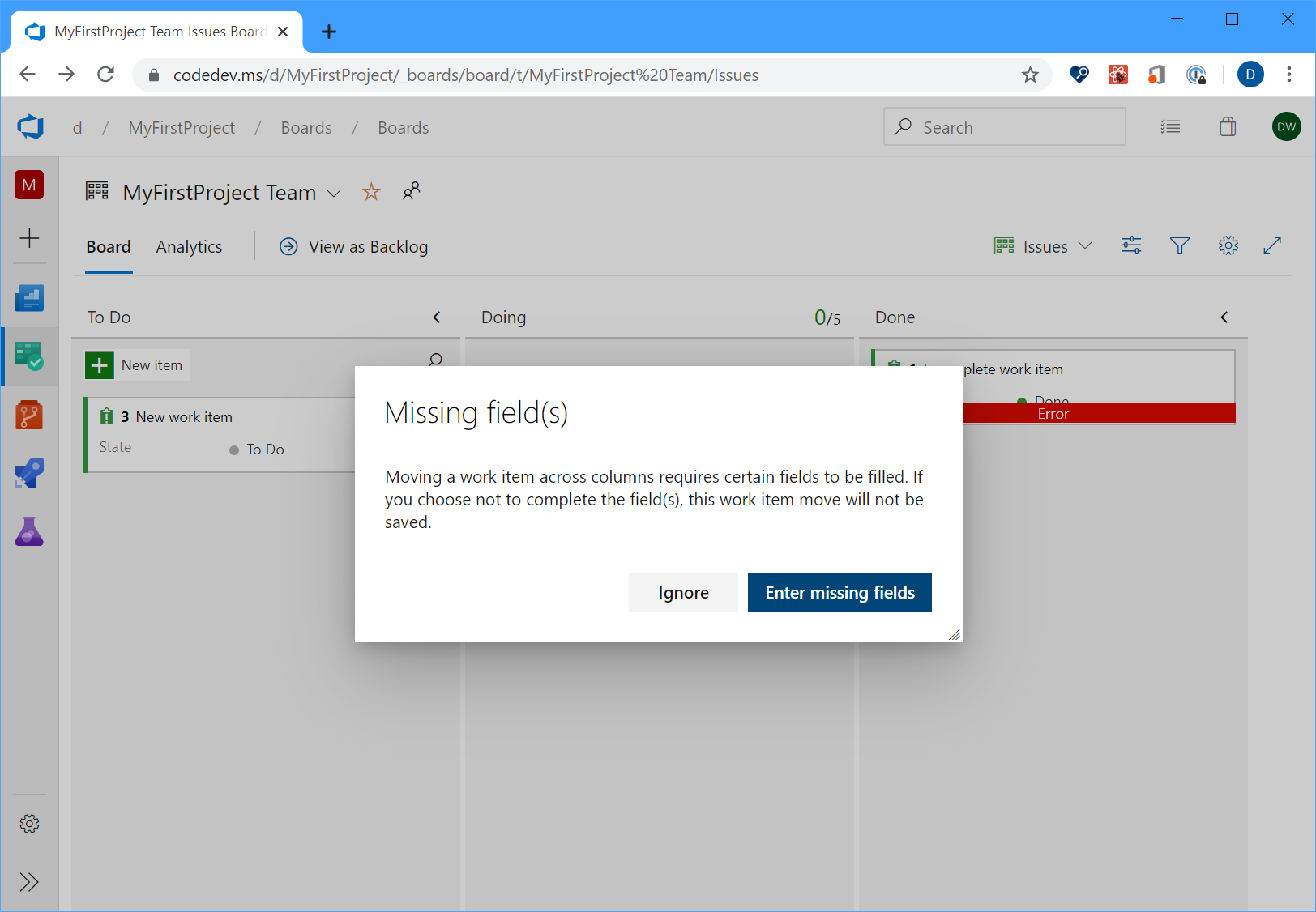
Historiquement, à partir du tableau Kanban, si vous avez déplacé un élément de travail d’une colonne vers une autre où le changement d’état a déclenché des règles de champ, le carte afficherait simplement un message d’erreur rouge qui vous obligera à ouvrir l’élément de travail pour comprendre la cause racine. Dans sprint 170, nous avons amélioré l’expérience afin que vous puissiez maintenant cliquer sur le message d’erreur rouge pour afficher les détails de l’erreur sans avoir à ouvrir l’élément de travail lui-même.
Rechargement dynamique de l’élément de travail
Auparavant, lors de la mise à jour d’un élément de travail et qu’un deuxième membre de l’équipe apportait des modifications au même élément de travail, le deuxième utilisateur perdait ses modifications. Maintenant, tant que vous modifiez tous les deux des champs différents, vous verrez des mises à jour actives des modifications apportées à l’élément de travail.

Gérer les chemins d’itération et de zone à partir de la ligne de commande
Vous pouvez maintenant gérer les chemins d’itération et de zone à partir de la ligne de commande à l’aide des az boards iteration commandes et az boards area . Par exemple, vous pouvez configurer et gérer les chemins d’itération et de zone de manière interactive à partir de l’interface CLI, ou automatiser l’ensemble de l’installation à l’aide d’un script. Pour plus d’informations sur les commandes et la syntaxe, consultez la documentation ici.
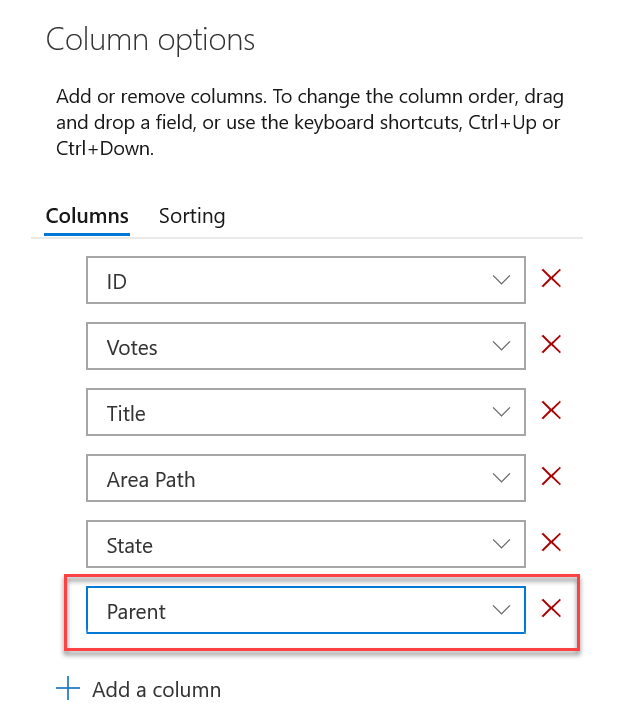
Option colonne parente d’élément de travail en tant que colonne
Vous avez maintenant la possibilité de voir le parent de chaque élément de travail dans votre backlog de produit ou votre backlog de sprint. Pour activer cette fonctionnalité, accédez à Options de colonne dans le backlog souhaité, puis ajoutez la colonne Parent .

Modifier le processus utilisé par un projet
Vos outils doivent changer au fur et à mesure que votre équipe le fait. Vous pouvez maintenant basculer vos projets de n’importe quel modèle de processus prête à l’emploi vers n’importe quel autre processus prête à l’emploi. Par exemple, vous pouvez changer votre projet d’utilisation d’Agile à Scrum, ou de base à Agile. Vous trouverez une documentation détaillée complète ici.

Masquer les champs personnalisés de la disposition
Vous pouvez désormais masquer les champs personnalisés de la disposition du formulaire lors de la personnalisation de votre processus. Le champ sera toujours disponible à partir des requêtes et des API REST. Cela s’avère pratique pour le suivi de champs supplémentaires lors de l’intégration à d’autres systèmes.

Obtenez des informations sur l’intégrité de votre équipe avec trois nouveaux rapports Azure Boards
Vous ne pouvez pas corriger ce que vous ne voyez pas. Par conséquent, vous souhaitez garder un œil attentif sur l’état et l’intégrité de leurs processus de travail. Grâce à ces rapports, nous vous permet de suivre plus facilement les métriques importantes avec un effort minimal dans Azure Boards.
Les trois nouveaux rapports interactifs sont : Burndown, Diagramme de flux cumulé (CFD) et Vitesse. Vous pouvez voir les rapports dans l’onglet Nouvelle analyse.
Les métriques telles que le sprint burndown, le flux de travail et la vélocité de l’équipe vous donnent une visibilité sur la progression de votre équipe et vous aident à répondre à des questions telles que :
- Combien de travail nous reste-t-il dans ce sprint ? Sommes-nous en bonne voie pour le terminer ?
- Quelle étape du processus de développement prend la plus longue ? Pouvons-nous faire quelque chose à ce sujet ?
- Sur la base des itérations précédentes, combien de travail devons-nous planifier pour le prochain sprint ?
Notes
Les graphiques précédemment affichés dans les en-têtes ont été remplacés par ces rapports améliorés.
Les nouveaux rapports sont entièrement interactifs et vous permettent de les ajuster à vos besoins. Vous trouverez les nouveaux rapports sous l’onglet Analyse dans chaque hub.
Le graphique de burndown se trouve sous le hub Sprints .

Les rapports CFD et Velocity sont accessibles à partir de l’onglet Analytique sous Tableaux et backlogs en cliquant sur le carte approprié.

Avec les nouveaux rapports, vous disposez de plus de contrôle et d’informations sur votre équipe. Voici quelques exemples :
- Les rapports Sprint Burndown et Velocity peuvent être définis pour utiliser le nombre d’éléments de travail ou la somme du travail restant.
- Vous pouvez ajuster la durée du burndown du sprint sans affecter les dates du projet. Par conséquent, si votre équipe passe généralement le premier jour de chaque planification de sprint, vous pouvez maintenant faire correspondre le graphique pour le refléter.
- Le graphique Burndown comporte désormais un filigrane montrant les week-ends.
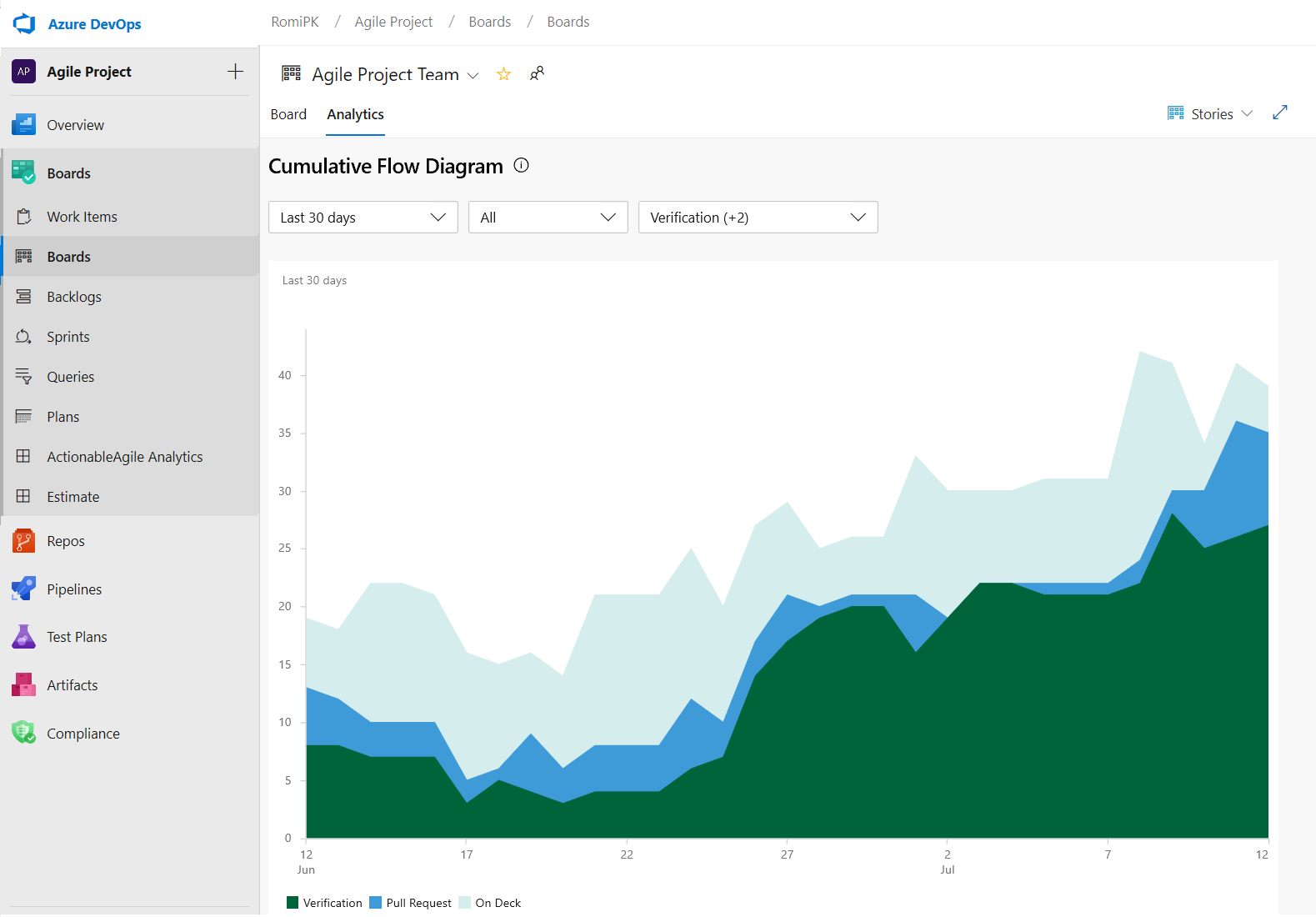
- Le rapport CFD vous permet de supprimer des colonnes de tableau comme La conception pour mieux vous concentrer sur le flux sur lequel les équipes ont le contrôle.
Voici un exemple de rapport CFD montrant le flux des 30 derniers jours du backlog Stories.
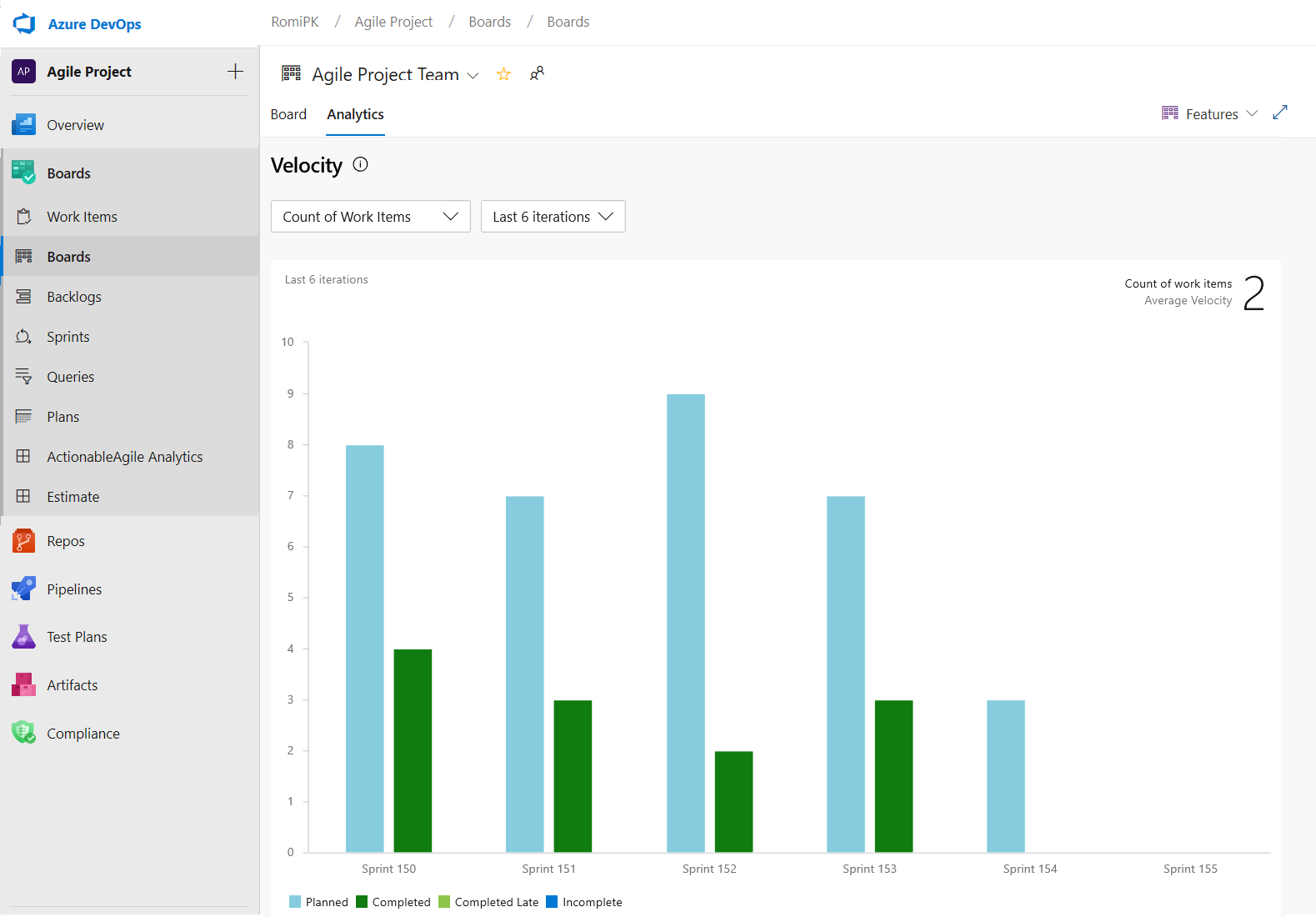
Le graphique De vitesse peut désormais être suivi pour tous les niveaux de backlog. Par exemple, vous pouvez maintenant ajouter des fonctionnalités et des epics, alors qu’avant le graphique précédent ne supportait que les exigences. Voici un exemple de rapport de vitesse pour les 6 dernières itérations du backlog fonctionnalités.
Personnaliser les colonnes du tableau des tâches
Nous sommes heureux d’annoncer que nous avons ajouté une option pour vous permettre de personnaliser les colonnes du tableau des tâches. Vous pouvez maintenant ajouter, supprimer, renommer et réorganiser les colonnes.
Pour configurer les colonnes de votre tableau des tâches, accédez à Options de colonne.

Cette fonctionnalité a été hiérarchisée en fonction d’une suggestion du Developer Community.
Bascule pour afficher ou masquer les éléments de travail enfants terminés dans le backlog
Souvent, lors de l’affinement du backlog, vous souhaitez uniquement voir les éléments qui n’ont pas été terminés. Vous pouvez maintenant afficher ou masquer les éléments enfants terminés dans le backlog.
Si le bouton bascule est activé, vous verrez tous les éléments enfants dans un état terminé. Lorsque le bouton bascule est désactivé, tous les éléments enfants dans un état terminé sont masqués dans le backlog.

Balises les plus récentes affichées lors de l’étiquetage d’un élément de travail
Lors de l’étiquetage d’un élément de travail, l’option de saisie automatique affiche désormais jusqu’à cinq de vos balises les plus récemment utilisées. Cela facilite l’ajout des informations appropriées à vos éléments de travail.

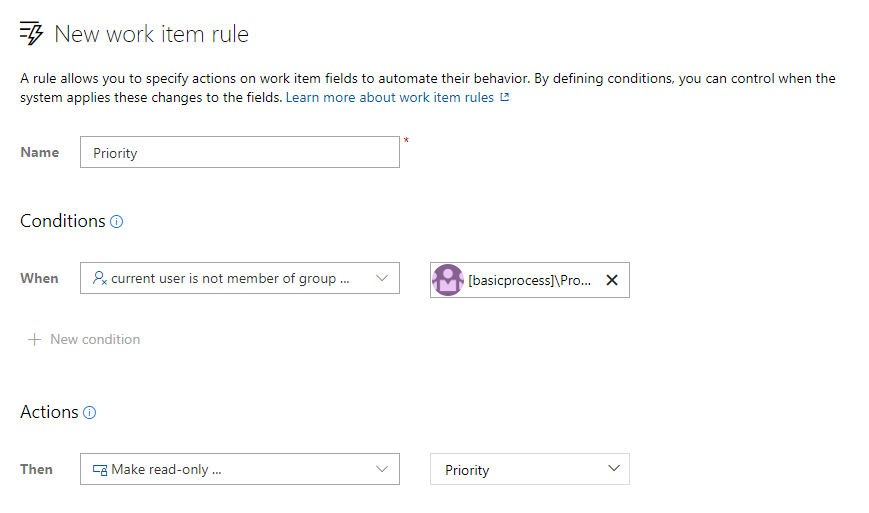
Règles en lecture seule et obligatoires pour l’appartenance à un groupe
Les règles d’élément de travail vous permettent de définir des actions spécifiques sur les champs d’élément de travail pour automatiser leur comportement. Vous pouvez créer une règle pour définir un champ en lecture seule ou obligatoire en fonction de l’appartenance au groupe. Par exemple, vous pouvez accorder aux propriétaires de produits la possibilité de définir la priorité de vos fonctionnalités tout en les rendant en lecture seule pour tout le monde.
Personnaliser les valeurs de la liste de sélection système
Vous pouvez maintenant personnaliser les valeurs de n’importe quelle liste de choix système (à l’exception du champ de raison), comme Gravité, Activité, Priorité, etc. Les personnalisations de la liste de sélection sont limitées afin que vous puissiez gérer des valeurs différentes pour le même champ pour chaque type d’élément de travail.

Nouveau paramètre d’URL d’élément de travail
Partagez des liens vers des éléments de travail avec le contexte de votre tableau ou backlog avec notre nouveau paramètre d’URL d’élément de travail. Vous pouvez maintenant ouvrir une boîte de dialogue d’élément de travail sur votre tableau, votre backlog ou votre expérience de sprint en ajoutant le paramètre ?workitem=[ID] à l’URL.
Toute personne avec laquelle vous partagez le lien atterrira alors avec le même contexte que celui que vous aviez lorsque vous avez partagé le lien !
Mentionnez des personnes, des éléments de travail et des demandes de tirage dans les champs de texte
Lorsque nous avons écouté vos commentaires, nous avons entendu dire que vous souhaitiez pouvoir mention personnes, éléments de travail et demandes de tirage dans la zone description de l’élément de travail (et d’autres champs HTML) sur l’élément de travail et pas seulement dans les commentaires. Parfois, vous collaborez avec quelqu’un sur un élément de travail ou souhaitez mettre en évidence une demande de tirage dans la description de votre élément de travail, mais vous n’avez pas eu le moyen d’ajouter ces informations. Vous pouvez maintenant mention personnes, éléments de travail et demandes de tirage dans tous les champs de texte long de l’élément de travail.
Vous pouvez consulter un exemple ici.
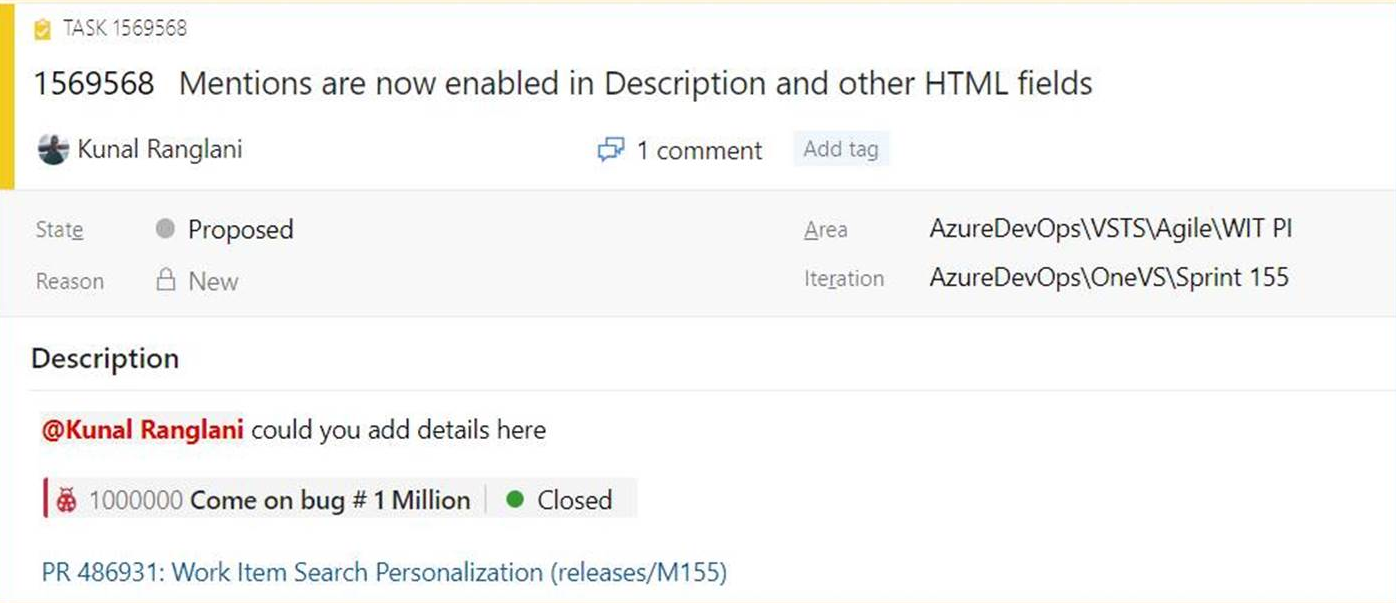
- Pour utiliser des mentions de personnes, tapez le @ signe et le nom de la personne que vous souhaitez mention. @mentionsdans les champs d’élément de travail génèreront des Notifications par e-mail comme ce qu’il fait pour les commentaires.
- Pour utiliser les mentions d’élément de travail, tapez le # signe suivi de l’ID ou du titre de l’élément de travail. #mentions créez un lien entre les deux éléments de travail.
- Pour utiliser les mentions de tirage, ajoutez un ! suivi de votre ID ou nom de demande de tirage.
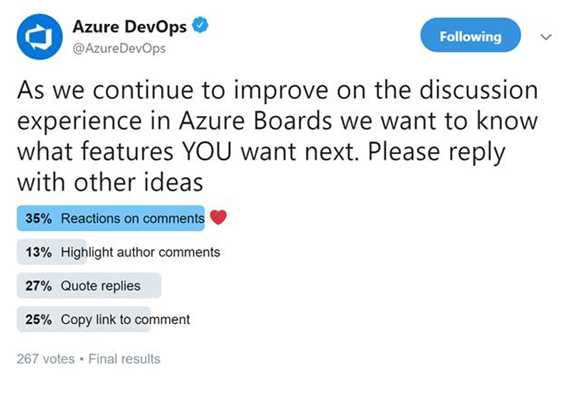
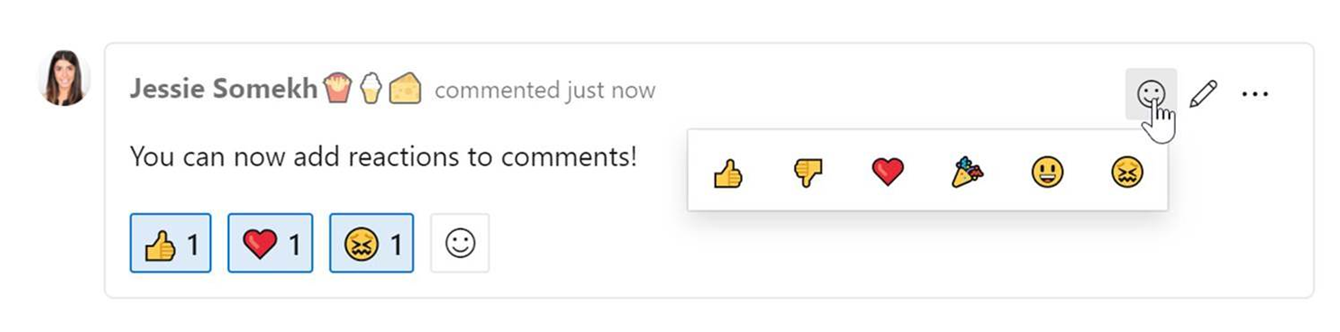
Réactions sur les commentaires de discussion
L’un de nos main objectifs est de rendre les éléments de travail plus collaboratifs pour les équipes. Récemment, nous avons mené un sondage sur Twitter pour savoir quelles fonctionnalités de collaboration vous souhaitez dans les discussions sur l’élément de travail. Apporter des réactions aux commentaires a remporté le sondage, alors nous les ajoutons ! Voici les résultats du sondage Twitter.
Vous pouvez ajouter des réactions à n’importe quel commentaire, et il existe deux façons d’ajouter vos réactions : l’icône smiley en haut à droite de n’importe quel commentaire, ainsi qu’en bas d’un commentaire à côté de toutes les réactions existantes. Vous pouvez ajouter les six réactions si vous le souhaitez, ou juste une ou deux. Pour supprimer votre réaction, cliquez sur la réaction au bas de votre commentaire et elle sera supprimée. Vous pouvez voir ci-dessous l’expérience d’ajout d’une réaction, ainsi que l’apparence des réactions sur un commentaire.
Épingler Azure Boards rapports au tableau de bord
Dans la mise à jour Sprint 155, nous avons inclus des versions mises à jour des rapports CFD et Velocity. Ces rapports sont disponibles sous l’onglet Analytique de Tableaux et backlogs. Vous pouvez maintenant épingler les rapports directement à votre tableau de bord. Pour épingler les rapports, pointez sur le rapport, sélectionnez les points de suspension « ... » et Copier dans le tableau de bord.
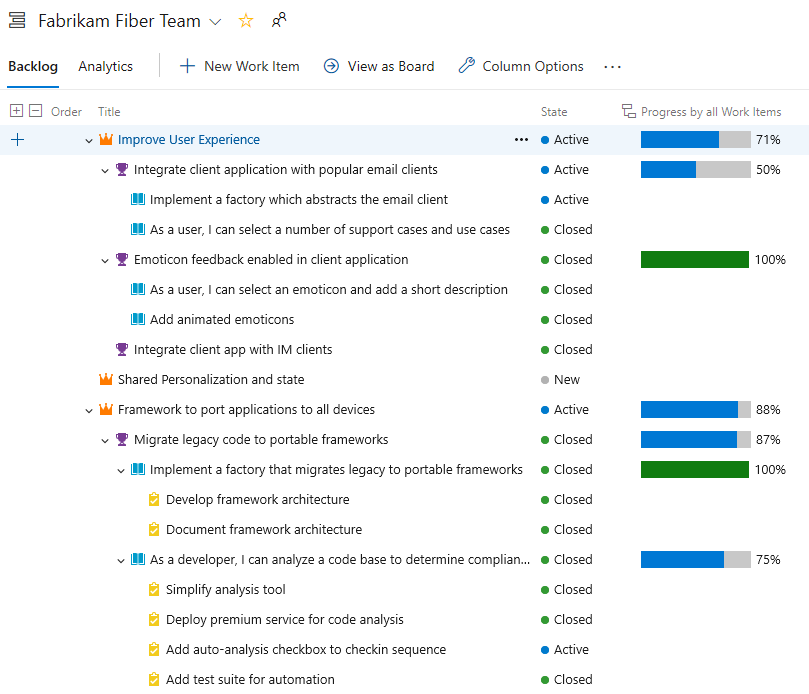
Suivre la progression des éléments parents à l’aide du backlog Rollup on Boards
Les colonnes de cumul affichent des barres de progression et/ou des totaux de champs numériques ou d’éléments descendants au sein d’une hiérarchie. Les éléments descendants correspondent à tous les éléments enfants de la hiérarchie. Une ou plusieurs colonnes de cumul peuvent être ajoutées à un backlog de produit ou de portefeuille.
Par exemple, nous présentons ici Progression par éléments de travail qui affiche les barres de progression des éléments de travail ascendants en fonction du pourcentage d’éléments descendants qui ont été fermés. Les éléments descendants pour Epics incluent toutes les fonctionnalités enfants et leurs éléments de travail enfants ou petits-enfants. Les éléments descendants des fonctionnalités incluent tous les récits utilisateur enfants et leurs éléments de travail enfants.
Mises à jour dynamiques du tableau des tâches
Votre tableau des tâches s’actualise désormais automatiquement lorsque des modifications se produisent ! À mesure que d’autres membres de l’équipe déplacent ou réorganisent des cartes dans le tableau des tâches, votre tableau est automatiquement mis à jour avec ces modifications. Vous n’avez plus besoin d’appuyer sur F5 pour voir les dernières modifications.
Prise en charge des champs personnalisés dans les colonnes de cumul
Le cumul peut désormais être effectué sur n’importe quel champ, y compris les champs personnalisés. Lorsque vous ajoutez une colonne de correctif cumulatif, vous pouvez toujours choisir une colonne de correctif cumulatif dans la liste rapide. Toutefois, si vous souhaitez effectuer un cumul sur des champs numériques qui ne font pas partie du modèle de processus prête à l’emploi, vous pouvez configurer votre propre colonne comme suit :
- Dans votre backlog, cliquez sur « Options de colonne ». Ensuite, dans le panneau, cliquez sur « Ajouter une colonne de correctif cumulatif », puis sur Configurer le correctif cumulatif personnalisé.

- Choisissez entre Barre de progression et Total.
- Sélectionnez un type d’élément de travail ou un niveau Backlog (généralement, les backlogs agrègent plusieurs types d’éléments de travail).
- Sélectionnez le type d’agrégation. Nombre d’éléments de travail ou Somme. Pour Somme, vous devez sélectionner le champ à résumer.
- Le bouton OK vous ramène au volet d’options de colonne où vous pouvez réorganiser votre nouvelle colonne personnalisée.
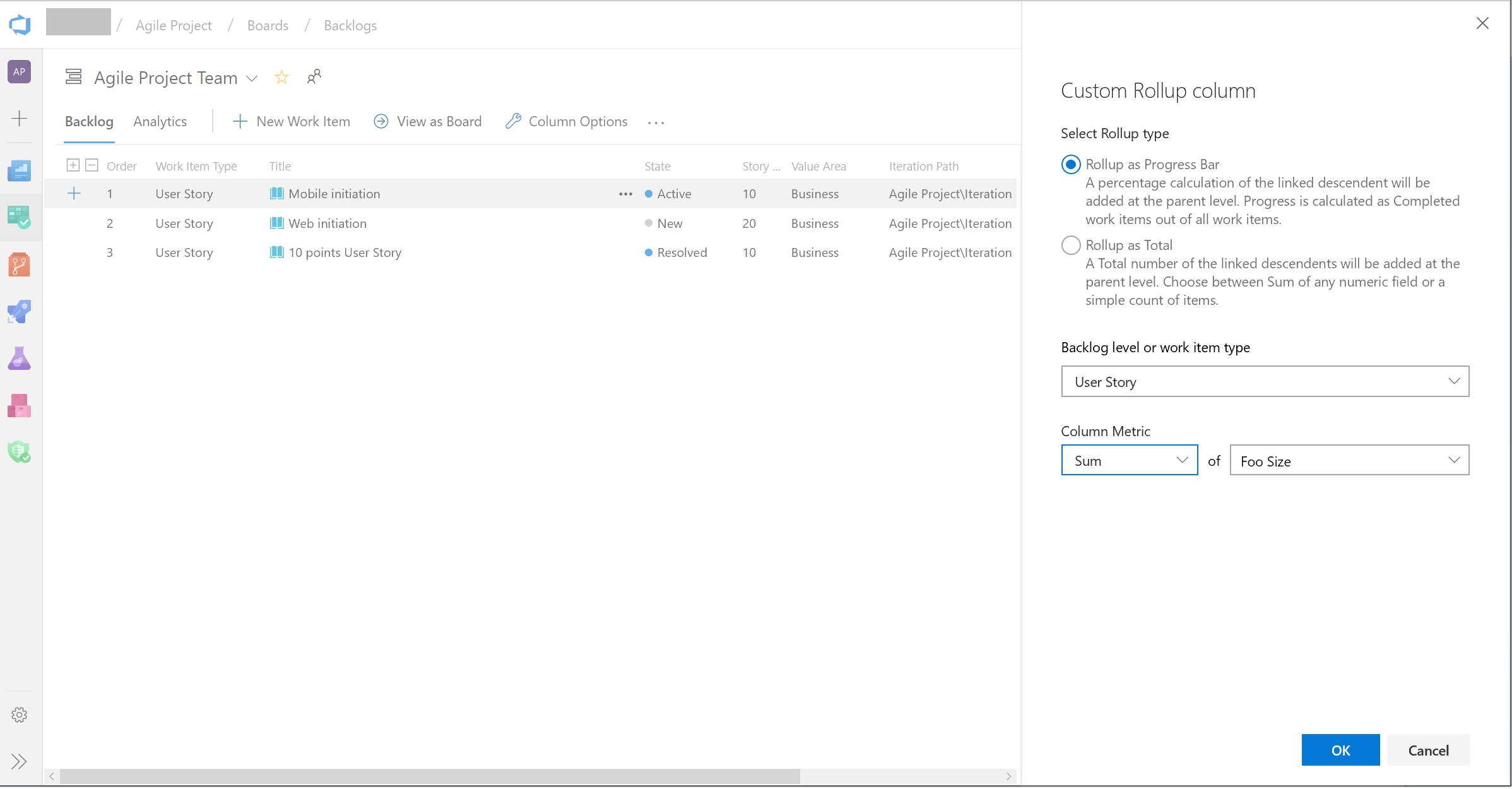
Notez que vous ne pouvez pas modifier votre colonne personnalisée après avoir cliqué sur OK. Si vous devez apporter une modification, supprimez la colonne personnalisée et ajoutez-en une autre comme vous le souhaitez.
Nouvelle règle pour masquer les champs d’un formulaire d’élément de travail en fonction de la condition
Nous avons ajouté une nouvelle règle au moteur de règles hérité pour vous permettre de masquer les champs dans un formulaire d’élément de travail. Cette règle masque les champs en fonction de l’appartenance au groupe d’utilisateurs. Par exemple, si l’utilisateur appartient au groupe « propriétaire du produit », vous pouvez masquer un champ spécifique au développeur. Pour plus d’informations, consultez la documentation ici.
Paramètres de notification d’élément de travail personnalisé
Il est extrêmement important de rester à jour sur les éléments de travail pertinents pour vous ou votre équipe. Il aide les équipes à collaborer et à rester sur la bonne voie avec les projets et s’assure que toutes les bonnes parties sont impliquées. Toutefois, les différents intervenants ont des niveaux d’investissement différents dans différents efforts, et nous croyons que cela devrait se refléter dans votre capacité à suivre les status d’un élément de travail.
Auparavant, si vous vouliez suivre un élément de travail et recevoir des notifications sur les modifications apportées, vous obteniez Notifications par e-mail pour toutes les modifications apportées à l’élément de travail. Après avoir pris en compte vos commentaires, nous rendons le suivi d’un élément de travail plus flexible pour toutes les parties prenantes. Maintenant, vous verrez un nouveau bouton paramètres en regard du bouton Suivre dans le coin supérieur droit de l’élément de travail. Vous accédez alors à une fenêtre contextuelle qui vous permettra de configurer vos options suivantes.

Dans Paramètres de notification, vous pouvez choisir parmi trois options de notification. Tout d’abord, vous pouvez être complètement désinscrit. Deuxièmement, vous pouvez être entièrement abonné, où vous recevez des notifications pour toutes les modifications d’élément de travail. Enfin, vous pouvez choisir d’être averti pour certains des principaux événements de modification d’élément de travail. Vous pouvez sélectionner une seule ou les trois options. Cela permet aux membres de l’équipe de suivre les éléments de travail à un niveau supérieur et de ne pas être distraits par chaque modification effectuée. Avec cette fonctionnalité, nous allons éliminer les e-mails inutiles et vous permettre de vous concentrer sur les tâches cruciales à accomplir.

Lier des éléments de travail à des déploiements
Nous sommes ravis de publier le contrôle de déploiement sur le formulaire d’élément de travail. Ce contrôle lie vos éléments de travail à une mise en production et vous permet de suivre facilement où votre élément de travail a été déployé. Pour en savoir plus, consultez la documentation ici.

Importer des éléments de travail à partir d’un fichier CSV
Jusqu’à présent, l’importation d’éléments de travail à partir d’un fichier CSV dépendait de l’utilisation du plug-in Excel. Dans cette mise à jour, nous fournissons une expérience d’importation de première classe directement à partir de Azure Boards afin que vous puissiez importer de nouveaux éléments de travail ou mettre à jour des éléments de travail existants. Pour plus d’informations, consultez la documentation ici.
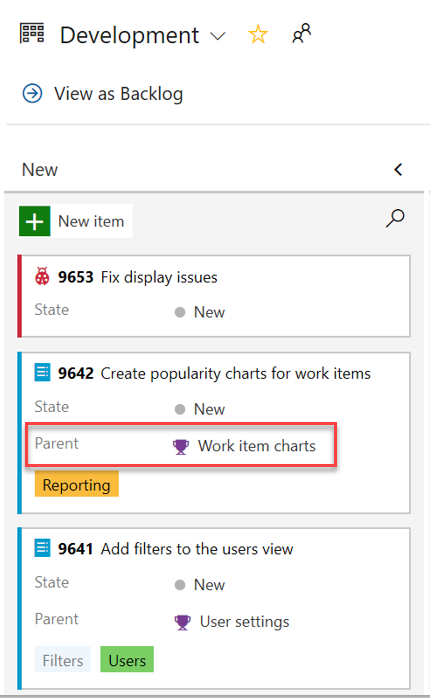
Ajouter un champ parent aux cartes d’élément de travail
Le contexte parent est désormais disponible dans votre tableau Kanban en tant que nouveau champ pour les cartes d’éléments de travail. Vous pouvez maintenant ajouter le champ Parent à vos cartes, en contournant la nécessité d’utiliser des solutions de contournement telles que des balises et des préfixes.
Ajouter un champ parent au backlog et aux requêtes
Le champ parent est désormais disponible lors de l’affichage des backlogs et des résultats de requête. Pour ajouter le champ parent, utilisez la vue Options de colonne .
Repos
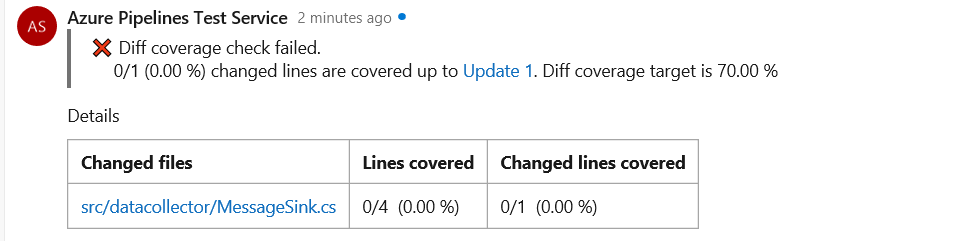
Métriques de couverture du code et stratégie de branche pour les demandes de tirage
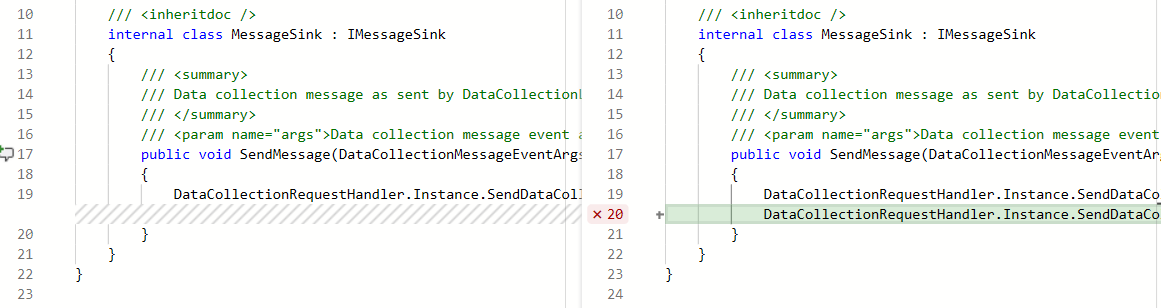
Vous pouvez maintenant voir les métriques de couverture du code pour les modifications dans la vue des demandes de tirage (PR). Cela garantit que vous avez correctement testé vos modifications par le biais de tests automatisés. Les status de couverture s’affichent sous forme de commentaire dans la vue d’ensemble de la demande de tirage. Vous pouvez afficher les détails des informations de couverture pour chaque ligne de code modifiée dans la vue diff fichier.
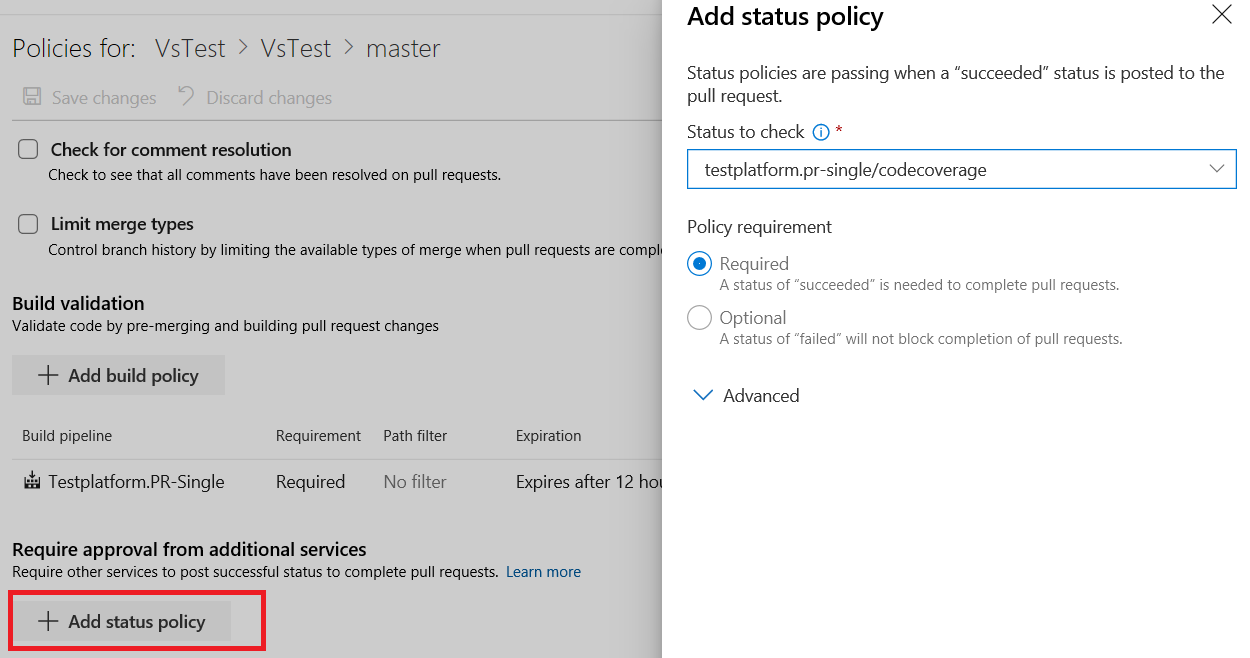
En outre, les propriétaires de référentiels peuvent désormais définir des stratégies de couverture du code et empêcher la fusion de modifications importantes et non testées dans une branche. Les seuils de couverture souhaités peuvent être définis dans un azurepipelines-coverage.yml fichier de paramètres archivé à la racine du dépôt et la stratégie de couverture peut être définie à l’aide de la configuration existante d’une stratégie de branche pour les fonctionnalités de services supplémentaires dans Azure Repos.
Filtrer les notifications de commentaires à partir des demandes de tirage
Les commentaires dans les demandes de tirage peuvent souvent générer beaucoup de bruit en raison des notifications. Nous avons ajouté un abonnement personnalisé qui vous permet de filtrer les notifications de commentaires auxquelles vous vous abonnez en fonction de l’âge du commentaire, du commentaire, du commentaire supprimé, des utilisateurs mentionnés, de l’auteur de la demande de tirage, de la branche cible et des participants au thread. Vous pouvez créer ces abonnements de notification en cliquant sur l’icône utilisateur dans le coin supérieur droit et en accédant à Paramètres utilisateur.


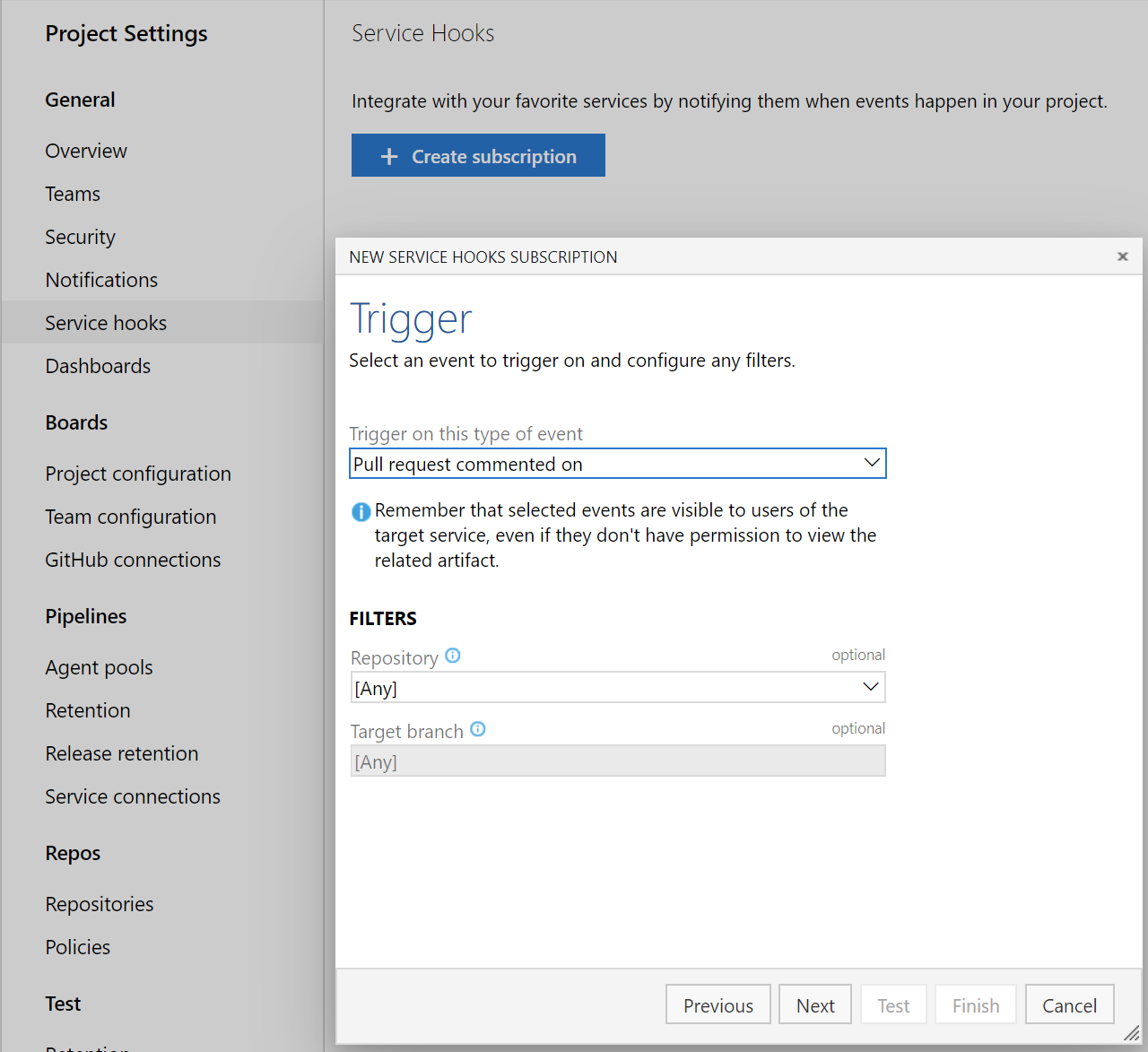
Hooks de service pour les commentaires de demande de tirage
Vous pouvez maintenant créer des hooks de service pour les commentaires dans une demande de tirage en fonction du dépôt et de la branche cible.
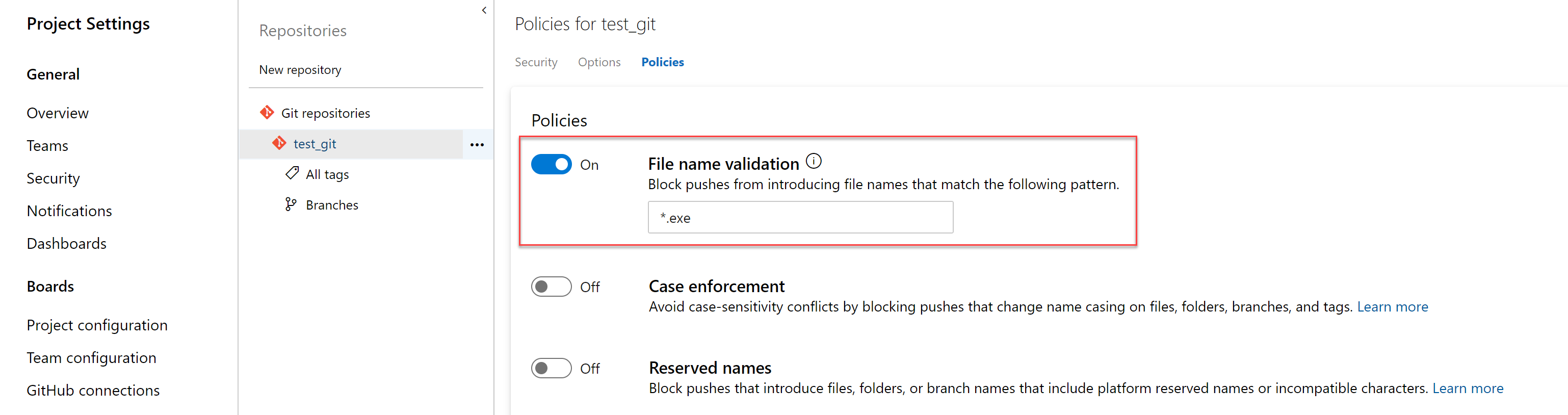
Stratégie de blocage des fichiers avec des modèles spécifiés
Les administrateurs peuvent désormais définir une stratégie pour empêcher les validations d’être envoyées à un dépôt en fonction des types de fichiers et des chemins d’accès. La stratégie de validation de nom de fichier bloque les envois (push) qui correspondent au modèle fourni.
Résoudre les éléments de travail via des commits à l’aide de mots clés
Vous pouvez maintenant résoudre les éléments de travail via des validations effectuées sur le branche par défaut à l’aide de mots clés tels que corriger, corriger ou corriger. Par exemple, vous pouvez écrire : « cette modification corrigée #476 » dans votre message de validation et l’élément de travail #476 sera terminé lorsque la validation est envoyée ou fusionnée dans le branche par défaut. Pour plus d’informations, consultez la documentation ici.
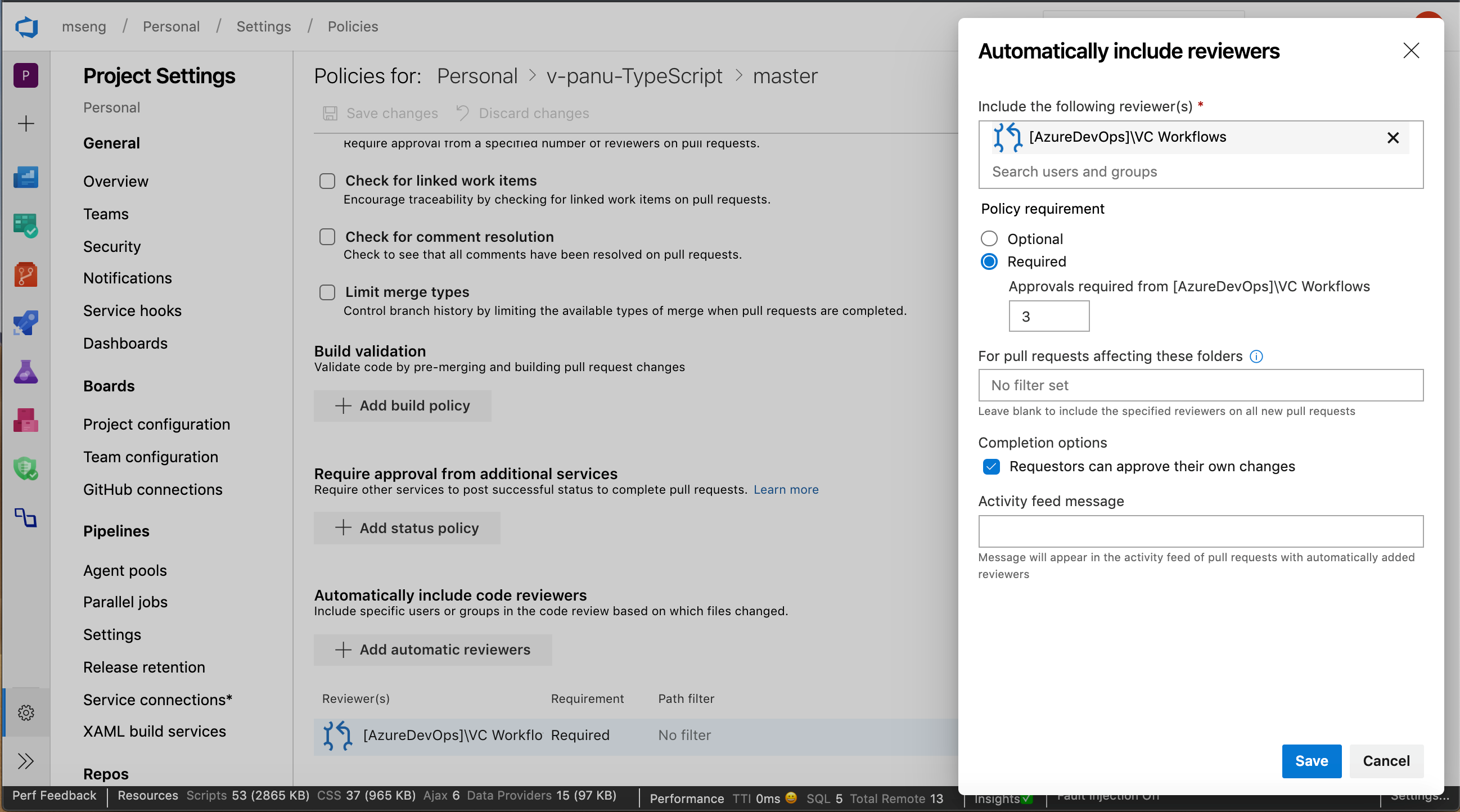
Granularité pour les réviseurs automatiques
Auparavant, lors de l’ajout de réviseurs au niveau du groupe à une demande de tirage, une seule approbation du groupe ajouté était requise. Vous pouvez maintenant définir des stratégies qui nécessitent plusieurs réviseurs d’une équipe pour approuver une demande de tirage lors de l’ajout de réviseurs automatiques. En outre, vous pouvez ajouter une stratégie pour empêcher les demandeurs d’approuver leurs propres modifications.
Utiliser l’authentification basée sur un compte de service pour se connecter à AKS
Auparavant, lors de la configuration d’Azure Pipelines à partir du centre de déploiement AKS, nous utilisions une connexion Azure Resource Manager. Cette connexion avait accès à l’ensemble du cluster et pas seulement à l’espace de noms pour lequel le pipeline a été configuré. Avec cette mise à jour, nos pipelines utiliseront l’authentification basée sur un compte de service pour se connecter au cluster afin qu’il ait uniquement accès à l’espace de noms associé au pipeline.
Aperçu des fichiers Markdown dans la demande de tirage côte à côte diff
Vous pouvez maintenant voir un aperçu de l’apparence d’un fichier markdown à l’aide du nouveau bouton Aperçu . En outre, vous pouvez voir le contenu complet d’un fichier à partir du diff côte à côte en sélectionnant le bouton Afficher.
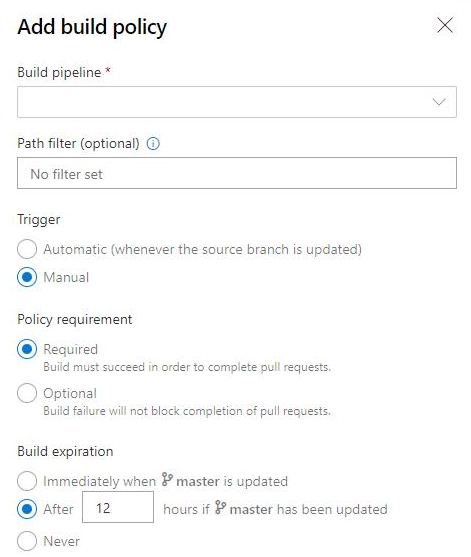
Expiration de la stratégie de génération pour les builds manuelles
Les stratégies appliquent les standards de qualité du code et de gestion des modifications de votre équipe. Auparavant, vous pouviez définir des stratégies d’expiration de build pour les builds automatisées. Maintenant, vous pouvez également définir des stratégies d’expiration de build pour vos builds manuelles.
Ajouter une stratégie pour bloquer les validations en fonction de l’e-mail de l’auteur de la validation
Les administrateurs peuvent désormais définir une stratégie push pour empêcher les validations d’être envoyées à un dépôt pour lequel l’e-mail de l’auteur de la validation ne correspond pas au modèle fourni.
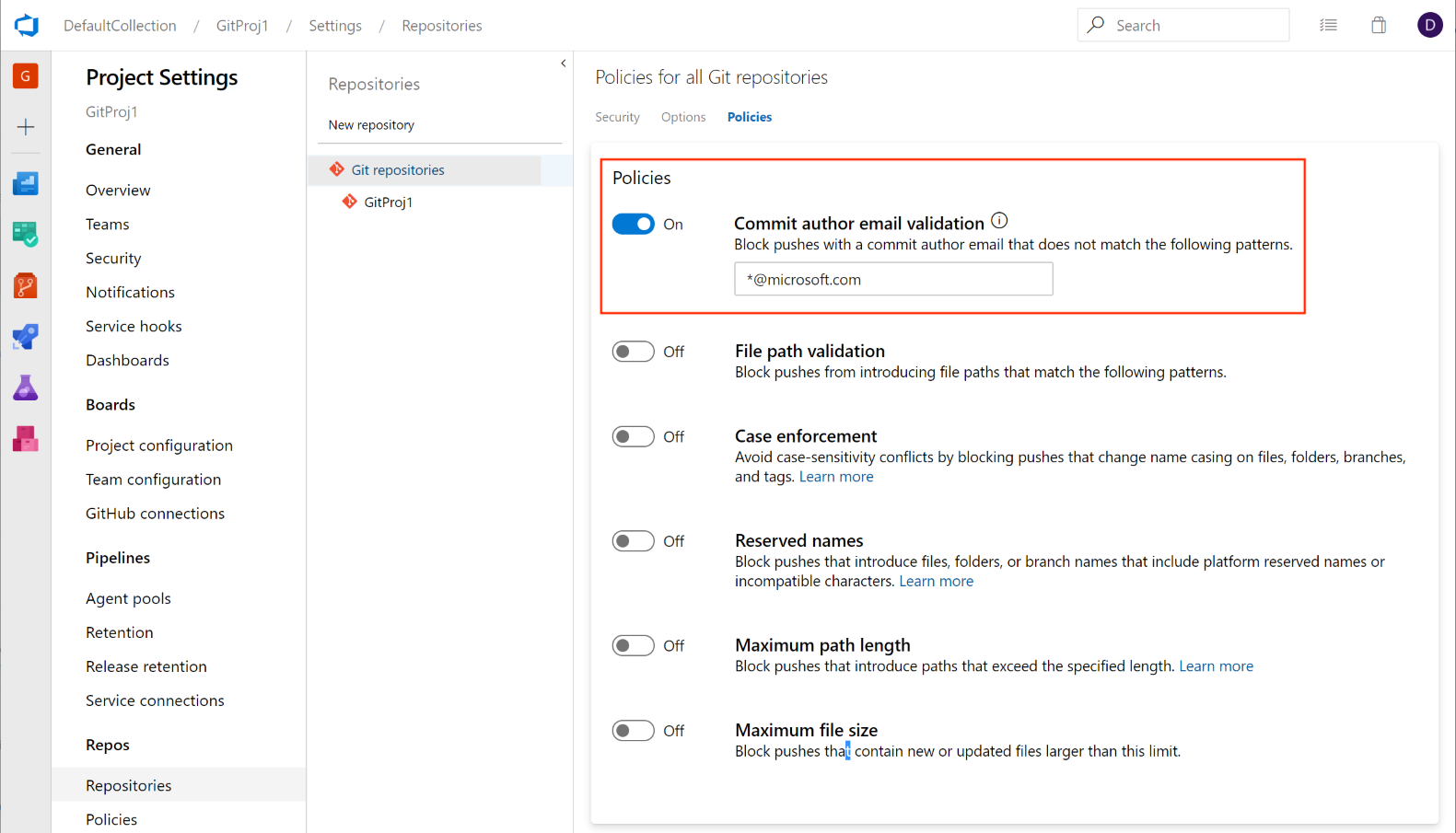
Cette fonctionnalité a été hiérarchisée en fonction d’une suggestion du Developer Community pour offrir une expérience similaire. Nous continuerons à garder le ticket ouvert et à encourager les utilisateurs à nous indiquer les autres types de stratégies push que vous souhaitez voir.
Marquer les fichiers comme révisés dans une demande de tirage
Parfois, vous devez passer en revue les demandes de tirage qui contiennent des modifications apportées à un grand nombre de fichiers et il peut être difficile de suivre les fichiers que vous avez déjà examinés. Vous pouvez maintenant marquer les fichiers comme étant examinés dans une demande de tirage.
Vous pouvez marquer un fichier comme étant révisé à l’aide du menu déroulant en regard d’un nom de fichier ou en pointant et en cliquant sur le nom du fichier.
Notes
Cette fonctionnalité est uniquement destinée à suivre votre progression lorsque vous passez en revue une demande de tirage. Il ne représente pas le vote sur les demandes de tirage. Ces marques ne seront visibles que par le réviseur.
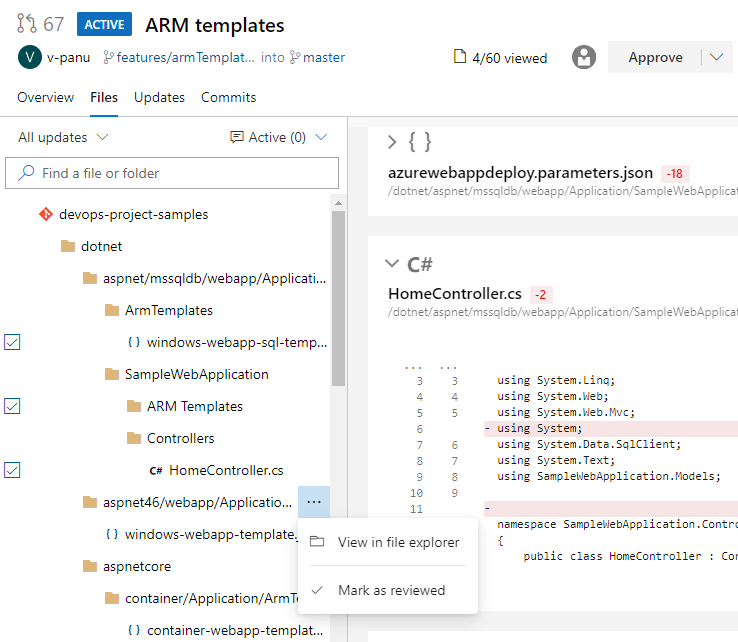
Cette fonctionnalité a été hiérarchisée en fonction d’une suggestion du Developer Community.
Nouvelle interface utilisateur web pour Azure Repos pages d’accueil
Vous pouvez maintenant essayer nos nouvelles pages d’accueil modernes, rapides et conviviales pour les mobiles dans Azure Repos. Ces pages sont disponibles en tant que pages d’accueil New Repos. Les pages d’accueil incluent toutes les pages à l’exception des détails de la demande de tirage, des détails de validation et de la comparaison des branches.
Web
Mobile
Administration de la stratégie de branche interpo
Les stratégies de branche sont l’une des fonctionnalités puissantes de Azure Repos qui vous aident à protéger les branches importantes. Bien que la possibilité de définir des stratégies au niveau du projet existe dans l’API REST, il n’y avait pas d’interface utilisateur pour celle-ci. Désormais, les administrateurs peuvent définir des stratégies sur une branche spécifique ou le branche par défaut sur tous les dépôts de leur projet. Par exemple, un administrateur peut exiger deux réviseurs minimum pour toutes les demandes de tirage effectuées dans chaque branche main dans chaque dépôt de son projet. Vous trouverez la fonctionnalité Ajouter une protection de branche dans les paramètres du projet Repos.

Nouvelles pages d’accueil de conversion de plateforme web
Nous avons mis à jour l’expérience utilisateur des pages d’accueil Repos pour la rendre moderne, rapide et adaptée aux mobiles. Voici deux exemples de pages qui ont été mises à jour. Nous continuerons à mettre à jour d’autres pages dans les mises à jour ultérieures.
Expérience web :
Expérience mobile :
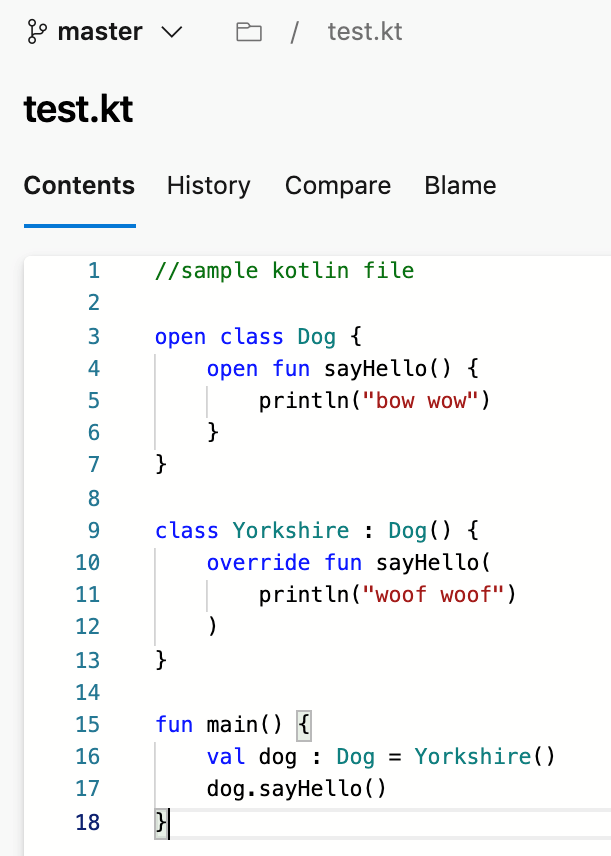
Prise en charge du langage Kotlin
Nous sommes heureux d’annoncer que nous prenons désormais en charge la mise en surbrillance de la langue Kotlin dans l’éditeur de fichiers. La mise en surbrillance améliore la lisibilité de votre fichier texte Kotlin et vous aide à analyser rapidement pour rechercher les erreurs. Nous avons hiérarchisé cette fonctionnalité en fonction d’une suggestion du Developer Community.
Abonnement aux notifications personnalisées pour les brouillons de demandes de tirage
Pour réduire le nombre de Notifications par e-mail des demandes de tirage, vous pouvez maintenant créer un abonnement de notification personnalisé pour les demandes de tirage créées ou mises à jour à l’état brouillon. Vous pouvez obtenir des e-mails spécifiquement pour les brouillons de demandes de tirage ou filtrer les e-mails des brouillons de demandes de tirage afin que votre équipe ne soit pas avertie avant que la demande de tirage soit prête à être examinée.

Amélioration de l’actionabilité des demandes de tirage
Lorsque vous avez de nombreuses demandes de tirage à examiner, il peut être difficile de comprendre où vous devez agir en premier. Pour améliorer l’action des demandes de tirage, vous pouvez maintenant créer plusieurs requêtes personnalisées sur la page de liste des demandes de tirage avec plusieurs nouvelles options à filtrer par exemple l’état brouillon. Ces requêtes créent des sections distinctes et réductibles sur votre page de demande de tirage, en plus de « Créé par moi » et « Attribué à moi ». Vous pouvez également refuser d’examiner une demande de tirage à laquelle vous avez été ajouté via le menu Vote ou le menu contextuel de la page de liste de demandes de tirage. Dans les sections personnalisées, vous voyez maintenant des onglets distincts pour les demandes de tirage sur lesquelles vous avez fourni une révision ou que vous avez refusé de vérifier. Ces requêtes personnalisées fonctionnent entre les référentiels sous l’onglet « Mes demandes de tirage » de la page d’accueil de la collection. Si vous souhaitez revenir à une demande de tirage, vous pouvez la marquer et elles s’afficheront en haut de votre liste. Enfin, les demandes de tirage qui ont été définies sur la saisie semi-automatique seront marquées d’une pilule indiquant « Saisie semi-automatique » dans la liste.
Pipelines
Pipelines à plusieurs étapes
Nous avons travaillé sur une expérience utilisateur mise à jour pour gérer vos pipelines. Ces mises à jour rendent les pipelines modernes et cohérents avec l’orientation d’Azure DevOps. En outre, ces mises à jour regroupent des pipelines de build classiques et des pipelines YAML à plusieurs étapes dans une expérience unique. Il est adapté aux mobiles et apporte diverses améliorations à la façon dont vous gérez vos pipelines. Vous pouvez explorer et afficher les détails du pipeline, les détails de l’exécution, l’analyse du pipeline, les détails du travail, les journaux et bien plus encore.
Les fonctionnalités suivantes sont incluses dans la nouvelle expérience :
- affichage et gestion de plusieurs étapes
- approbation des exécutions de pipeline
- faire défiler tout le chemin dans les journaux pendant qu’un pipeline est toujours en cours
- Intégrité par branche d’un pipeline.
Déploiement continu dans YAML
Nous sommes ravis de fournir des fonctionnalités DE CD YAML Azure Pipelines. Nous offrons désormais une expérience YAML unifiée afin que vous puissiez configurer chacun de vos pipelines pour effectuer ci, CD ou CI et CD ensemble. Les fonctionnalités CD YAML introduisent plusieurs nouvelles fonctionnalités avancées qui sont disponibles pour toutes les collections à l’aide de pipelines YAML à plusieurs étapes. Voici les principales :
- Pipelines YAML multiphases (pour CI et CD)
- Approbations et vérifications des ressources
- Environnements et stratégies de déploiement
- Ressources Kubernetes et machine virtuelle dans l’environnement
- Passer en revue les applications pour la collaboration
- Expérience utilisateur actualisée pour les connexions de service
- Ressources dans les pipelines YAML
Si vous êtes prêt à commencer à créer, case activée la documentation ou le blog pour la création de pipelines CI/CD à plusieurs étapes.
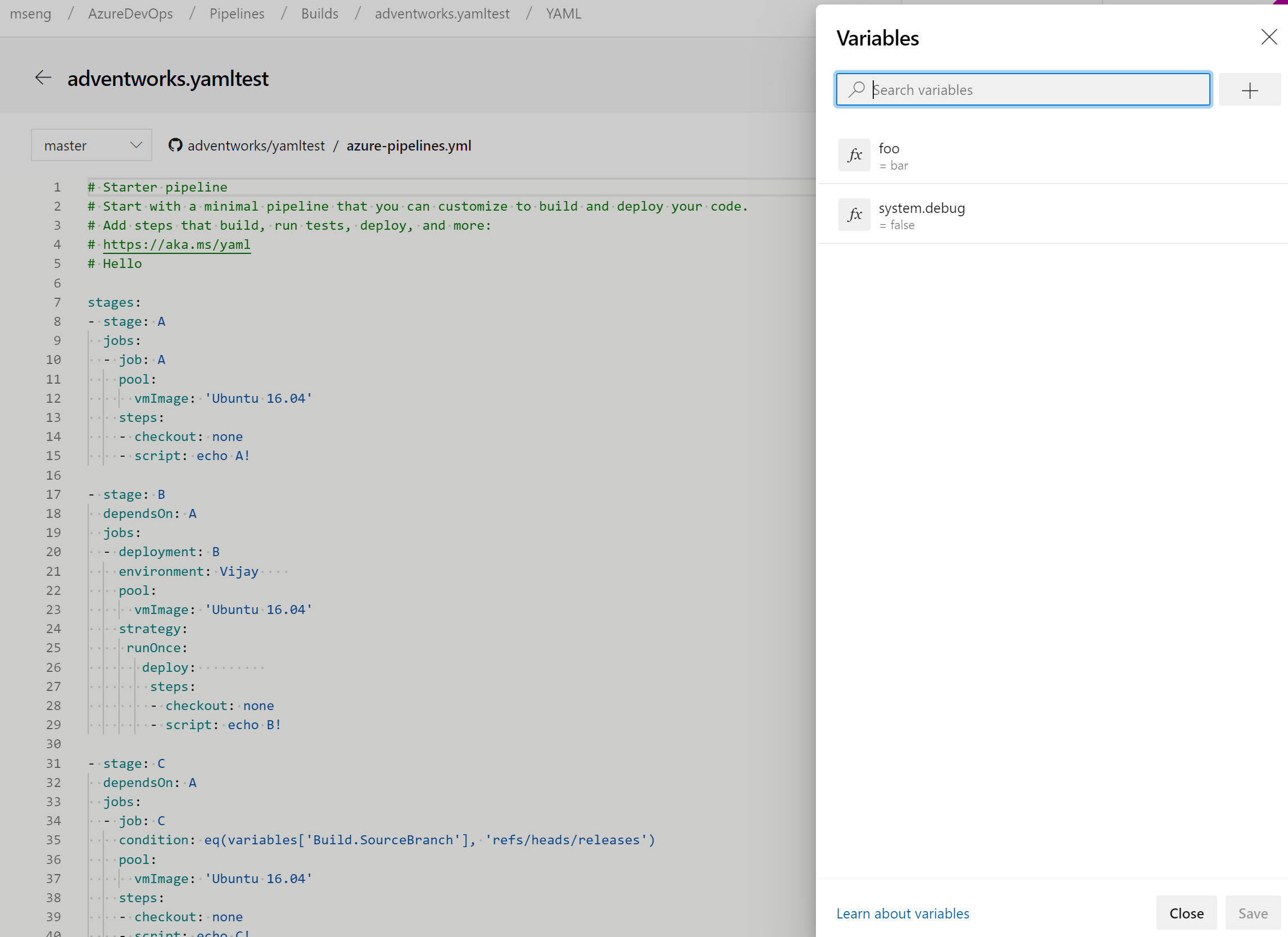
Gérer les variables de pipeline dans l’éditeur YAML
Nous avons mis à jour l’expérience de gestion des variables de pipeline dans l’éditeur YAML. Vous n’avez plus besoin d’accéder à l’éditeur classique pour ajouter ou mettre à jour des variables dans vos pipelines YAML.
Approuver des mises en production directement à partir du hub Des mises en production
L’action sur les approbations en attente a été facilitée. Auparavant, il était possible d’approuver une version à partir de la page de détails de la version. Vous pouvez maintenant approuver les mises en production directement à partir du hub Mises en production.

Améliorations apportées à la prise en main des pipelines
La possibilité de renommer le fichier généré est une question courante de l’Assistant de prise en main. Actuellement, il est archivé comme azure-pipelines.yml à la racine de votre dépôt. Vous pouvez maintenant mettre à jour ce nom de fichier ou un autre emplacement avant d’enregistrer le pipeline.
Enfin, vous aurez plus de contrôle lors de l’archivage du azure-pipelines.yml fichier dans une autre branche, car vous pouvez choisir d’ignorer la création d’une demande de tirage à partir de cette branche.
Afficher un aperçu d’un document YAML entièrement analysé sans valider ou exécuter le pipeline
Nous avons ajouté une préversion, mais nous n’avons pas le mode d’exécution pour les pipelines YAML. À présent, vous pouvez essayer un pipeline YAML sans le valider dans un dépôt ou l’exécuter. Étant donné un pipeline existant et une nouvelle charge utile YAML facultative, cette nouvelle API vous rendra le pipeline YAML complet. Dans les prochaines mises à jour, cette API sera utilisée dans une nouvelle fonctionnalité d’éditeur.
Pour les développeurs : POST vers dev.azure.com/<org>/<project>/_apis/pipelines/<pipelineId>/runs?api-version=5.1-preview avec un corps JSON comme suit :
{
"PreviewRun": true,
"YamlOverride": "
# your new YAML here, optionally
"
}
La réponse contient le YAML rendu.
Planifications Cron dans YAML
Auparavant, vous pouviez utiliser l’éditeur d’interface utilisateur pour spécifier un déclencheur planifié pour les pipelines YAML. Avec cette version, vous pouvez planifier des builds à l’aide de la syntaxe cron dans votre fichier YAML et tirer parti des avantages suivants :
- Configuration en tant que code : vous pouvez suivre les planifications avec votre pipeline dans le cadre du code.
- Expressif : vous avez plus de pouvoir expressif dans la définition des planifications que ce que vous avez pu faire avec l’interface utilisateur. Pour instance, il est plus facile de spécifier une planification unique qui démarre une exécution toutes les heures.
- Standard du secteur : de nombreux développeurs et administrateurs sont déjà familiarisés avec la syntaxe cron.
schedules:
- cron: "0 0 * * *"
displayName: Daily midnight build
branches:
include:
- main
- releases/*
exclude:
- releases/ancient/*
always: true
Nous vous avons également permis de diagnostiquer facilement les problèmes liés aux planifications cron. Les exécutions planifiées dans le menu Exécuter le pipeline vous donnent un aperçu des quelques exécutions planifiées à venir pour votre pipeline afin de vous aider à diagnostiquer les erreurs avec vos planifications cron.
interface utilisateur des connexions Mises à jour au service
Nous avons travaillé sur une expérience utilisateur mise à jour pour gérer vos connexions de service. Ces mises à jour rendent l’expérience de connexion de service moderne et cohérente avec la direction d’Azure DevOps. Nous avons introduit la nouvelle interface utilisateur pour les connexions de service en tant que fonctionnalité en préversion plus tôt cette année. Merci à tous ceux qui ont essayé la nouvelle expérience et nous ont fait part de leurs précieux commentaires.
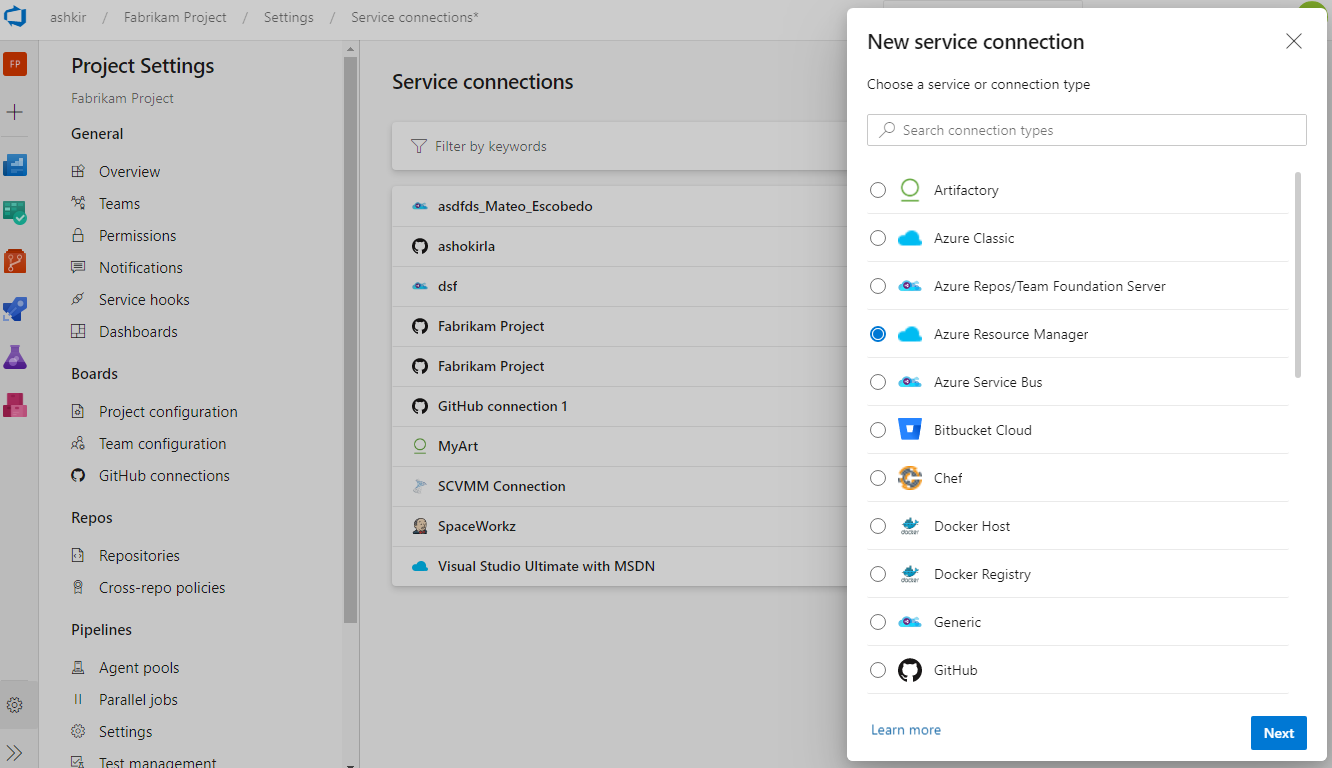
En plus de l’actualisation de l’expérience utilisateur, nous avons également ajouté deux fonctionnalités essentielles pour l’utilisation des connexions de service dans les pipelines YAML : les autorisations de pipeline, les approbations et les vérifications.

La nouvelle expérience utilisateur sera activée par défaut avec cette mise à jour. Vous aurez toujours la possibilité de refuser la préversion.
Notes
Nous prévoyons d’introduire le partage inter-projets de Connections de service en tant que nouvelle fonctionnalité. Vous trouverez plus d’informations sur l’expérience de partage et les rôles de sécurité ici.
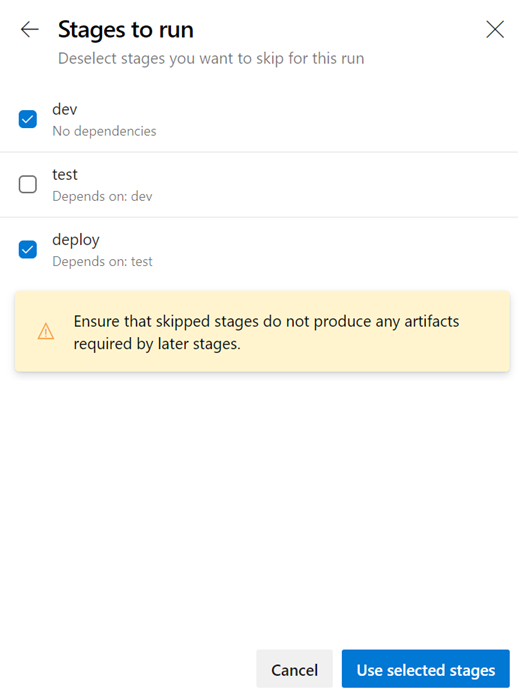
Ignorer des étapes dans un pipeline YAML
Lorsque vous démarrez une exécution manuelle, vous pouvez parfois ignorer quelques étapes dans votre pipeline. Par instance, si vous ne souhaitez pas déployer en production ou si vous souhaitez ignorer le déploiement dans quelques environnements en production. Vous pouvez maintenant effectuer cette opération avec vos pipelines YAML.
Le panneau de pipeline d’exécution mis à jour présente la liste des étapes du fichier YAML, et vous avez la possibilité d’ignorer une ou plusieurs de ces phases. Vous devez faire preuve de prudence lorsque vous ignorez des étapes. Par instance, si votre première étape produit certains artefacts nécessaires aux étapes suivantes, vous ne devez pas ignorer la première étape. Le panneau d’exécution présente un avertissement générique chaque fois que vous ignorez des étapes qui ont des dépendances en aval. Il vous appartient de déterminer si ces dépendances sont de véritables dépendances d’artefacts ou si elles sont simplement présentes pour le séquencement des déploiements.
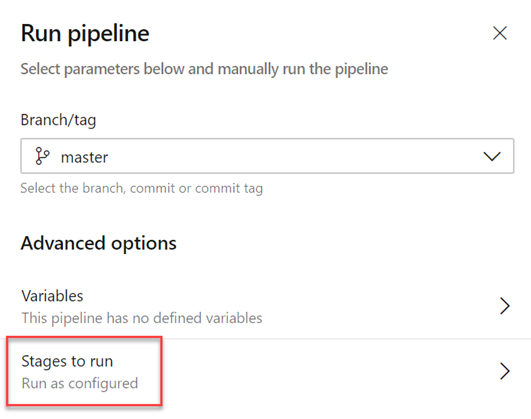
Ignorer une étape revient à ressailler les dépendances entre les phases. Toutes les dépendances immédiates en aval de l’étape ignorée dépendent de l’amont parent de l’étape ignorée. Si l’exécution échoue et si vous tentez de réexécuter une phase ayant échoué, cette tentative aura également le même comportement d’évitement. Pour modifier les étapes ignorées, vous devez commencer une nouvelle exécution.
Nouvelle interface utilisateur des connexions de service en tant qu’expérience par défaut
Il existe une nouvelle interface utilisateur des connexions de service. Cette nouvelle interface utilisateur repose sur des normes de conception modernes et comprend diverses fonctionnalités critiques pour prendre en charge les pipelines CD YAML à plusieurs étapes, comme les approbations, les autorisations et le partage entre projets.
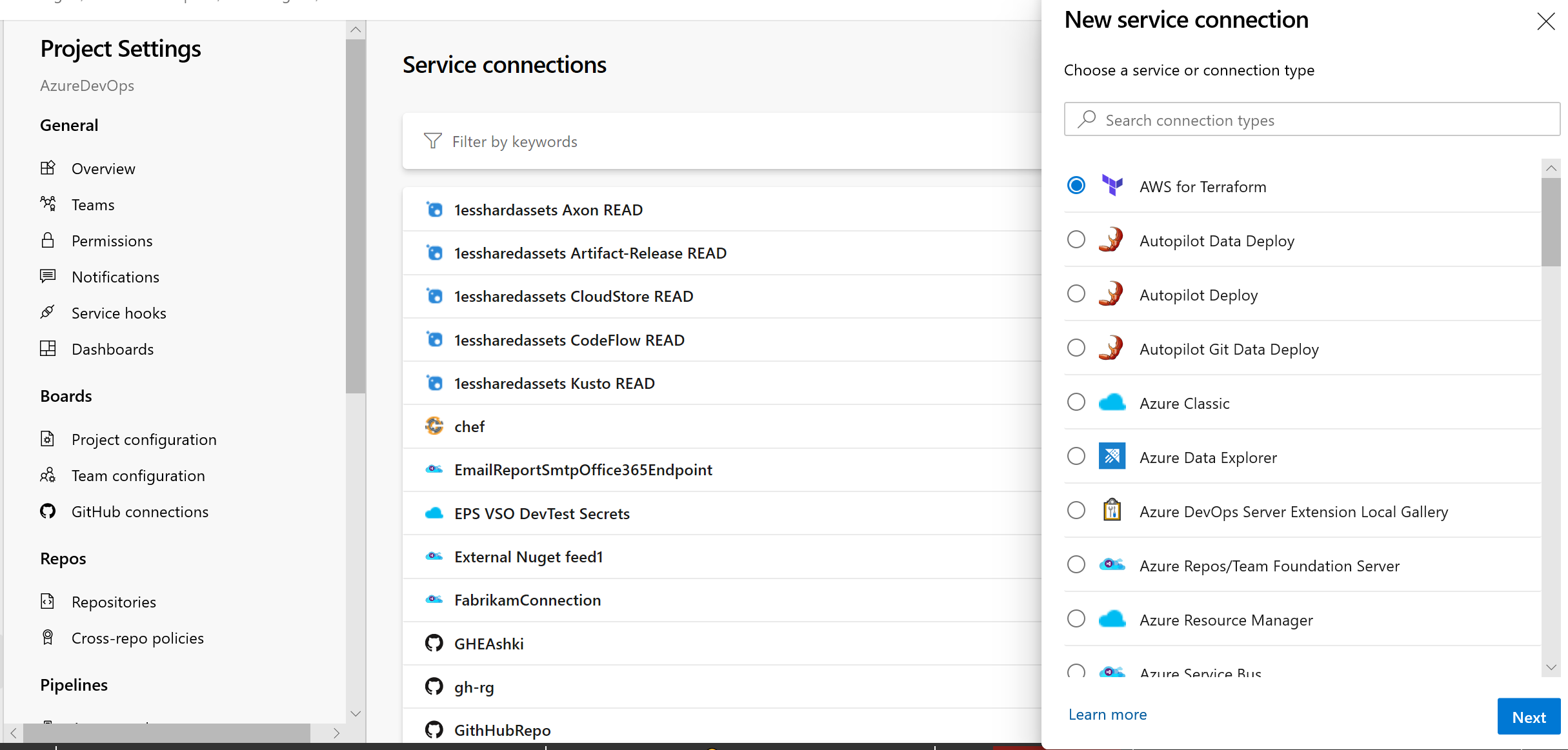
Pour en savoir plus sur les connexions de service, cliquez ici.
Sélecteur de version de ressource de pipeline dans la boîte de dialogue Créer une exécution
Nous avons ajouté la possibilité de récupérer manuellement les versions de ressources de pipeline dans la boîte de dialogue Créer une exécution. Si vous consommez un pipeline en tant que ressource dans un autre pipeline, vous pouvez désormais choisir la version de ce pipeline lors de la création d’une exécution.
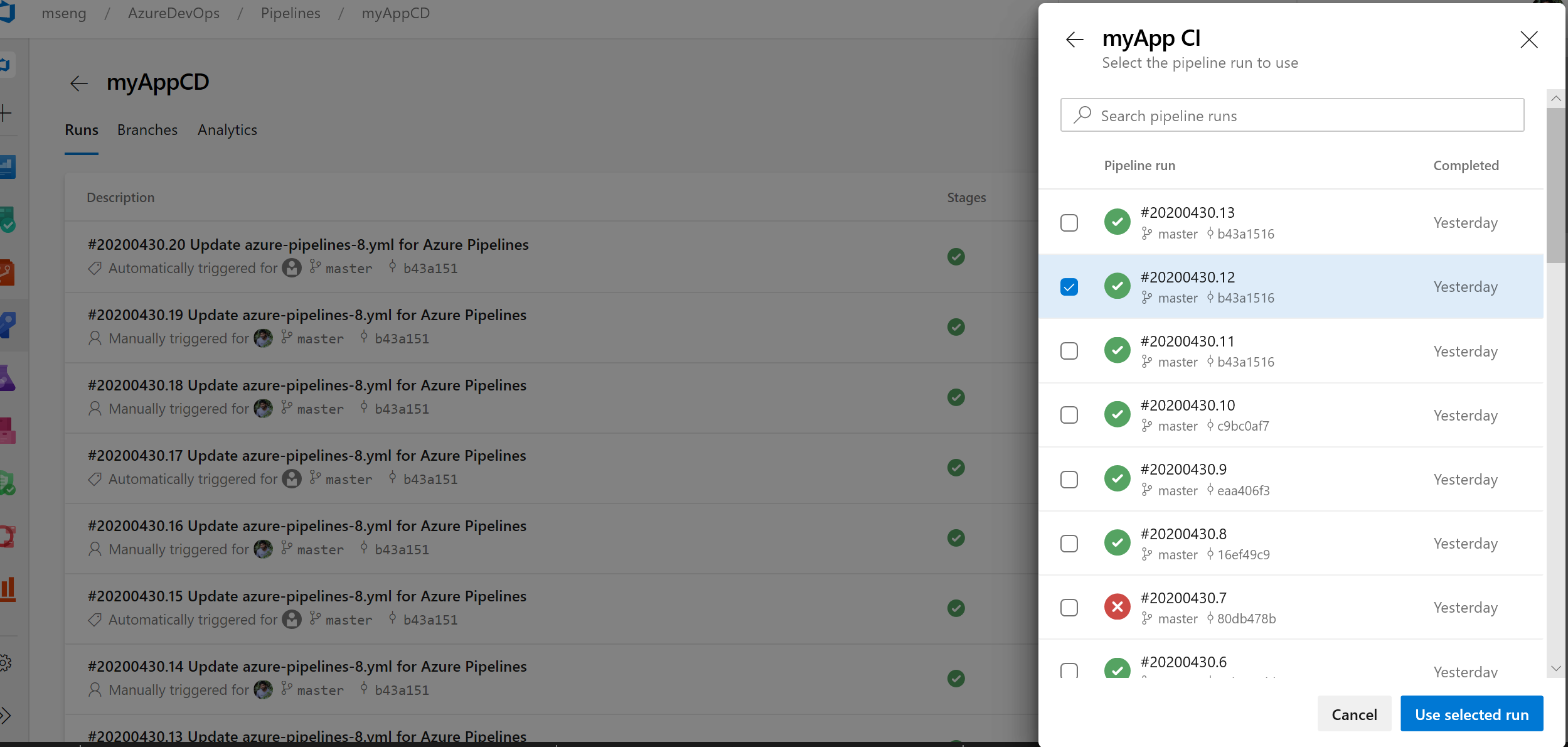
az Améliorations de l’interface CLI pour Azure Pipelines
Groupe de variables de pipeline et commandes de gestion des variables
Il peut être difficile de porter des pipelines basés sur YAML d’un projet vers un autre, car vous devez configurer manuellement les variables de pipeline et les groupes de variables. Toutefois, avec le groupe de variables de pipeline et les commandes de gestion des variables , vous pouvez maintenant créer un script pour configurer et gérer des variables de pipeline et des groupes de variables, qui peuvent à leur tour être contrôlés par version, ce qui vous permet de partager facilement les instructions pour déplacer et configurer des pipelines d’un projet à un autre.
Exécuter le pipeline pour une branche de demande de tirage
Lors de la création d’une demande de tirage, il peut être difficile de vérifier si les modifications peuvent interrompre l’exécution du pipeline sur la branche cible. Toutefois, avec la possibilité de déclencher une exécution de pipeline ou de mettre en file d’attente une build pour une branche de demande de tirage, vous pouvez maintenant valider et visualiser les modifications apportées en l’exécutant sur le pipeline cible. Pour plus d’informations, consultez la documentation sur les commandes az pipelines run et az pipelines build queue .
Ignorer la première exécution du pipeline
Lorsque vous créez des pipelines, vous souhaitez parfois créer et valider un fichier YAML et ne pas déclencher l’exécution du pipeline, car cela peut entraîner une exécution défectueuse pour diverses raisons : l’infrastructure n’est pas prête ou n’a pas besoin de créer et de mettre à jour des groupes de variables/variables, etc. Avec Azure DevOps CLI, vous pouvez maintenant ignorer la première exécution automatisée du pipeline lors de la création d’un pipeline en incluant le paramètre --skip-first-run. Pour plus d’informations, consultez la documentation az pipeline create command .
Amélioration de la commande de point de terminaison de service
Les commandes CLI de point de terminaison de service ne prend en charge que la configuration et la gestion des points de terminaison de service azure rm et github. Toutefois, avec cette version, les commandes de point de terminaison de service vous permettent de créer n’importe quel point de terminaison de service en fournissant la configuration via un fichier et fournissent des commandes optimisées : az devops service-endpoint github et az devops service-endpoint azurerm, qui fournissent une prise en charge de première classe pour créer des points de terminaison de service de ces types. Pour plus d’informations, consultez la documentation sur les commandes .
Travaux de déploiement
Un travail de déploiement est un type spécial de travail utilisé pour déployer votre application dans un environnement. Avec cette mise à jour, nous avons ajouté la prise en charge des références d’étape dans un travail de déploiement. Par exemple, vous pouvez définir un ensemble d’étapes dans un fichier et y faire référence dans un travail de déploiement.
Nous avons également ajouté la prise en charge de propriétés supplémentaires au travail de déploiement. Par exemple, voici quelques propriétés d’un travail de déploiement que vous pouvez désormais définir :
- timeoutInMinutes : durée d’exécution du travail avant l’annulation automatique
- cancelTimeoutInMinutes : le temps nécessaire à l’exécution toujours même en cas d’annulation de tâches avant de les terminer
- condition : exécuter le travail de manière conditionnelle
- variables : les valeurs codées en dur peuvent être ajoutées directement, ou des groupes de variables, un groupe de variables soutenu par un coffre de clés Azure peut être référencé ou vous pouvez faire référence à un ensemble de variables définies dans un fichier.
- continueOnError : si les travaux futurs doivent s’exécuter même en cas d’échec de ce travail de déploiement ; la valeur par défaut est « false »
Pour plus d’informations sur les travaux de déploiement et la syntaxe complète permettant de spécifier un travail de déploiement, consultez Tâche de déploiement.
Affichage des informations sur les pipelines CD associés dans les pipelines CI
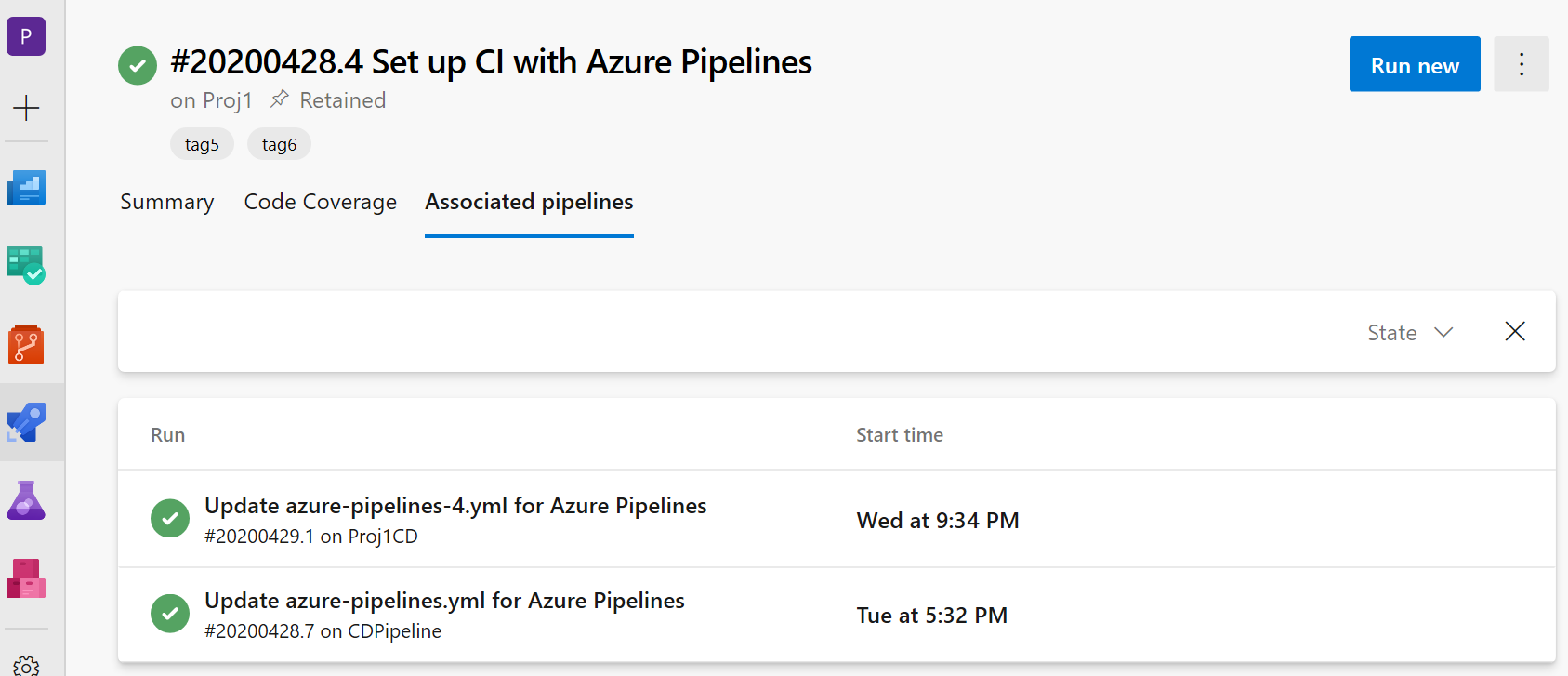
Nous avons ajouté la prise en charge des détails des pipelines CD YAML où les pipelines CI sont appelés ressources de pipeline. Dans la vue d’exécution de votre pipeline CI, vous voyez maintenant un nouvel onglet « Pipelines associés » dans lequel vous pouvez trouver toutes les exécutions de pipeline qui consomment votre pipeline et les artefacts qu’il contient.
Prise en charge des packages GitHub dans les pipelines YAML
Nous avons récemment introduit un nouveau type de ressource appelé packages qui ajoute la prise en charge de l’utilisation des packages NuGet et npm à partir de GitHub en tant que ressource dans les pipelines YAML. Dans le cadre de cette ressource, vous pouvez désormais spécifier le type de package (NuGet ou npm) que vous souhaitez utiliser à partir de GitHub. Vous pouvez également activer les déclencheurs de pipeline automatisés lors de la publication d’une nouvelle version de package. Aujourd’hui, la prise en charge est disponible uniquement pour la consommation de packages à partir de GitHub, mais à l’avenir, nous prévoyons d’étendre la prise en charge pour consommer des packages à partir d’autres référentiels de packages tels que NuGet, npm, AzureArtifacts et bien d’autres. Pour plus d’informations, reportez-vous à l’exemple ci-dessous :
resources:
packages:
- package: myPackageAlias # alias for the package resource
type: Npm # type of the package NuGet/npm
connection: GitHubConn # Github service connection of type PAT
name: nugetTest/nodeapp # <Repository>/<Name of the package>
version: 1.0.9 # Version of the packge to consume; Optional; Defaults to latest
trigger: true # To enable automated triggers (true/false); Optional; Defaults to no triggers
Notes
Aujourd’hui, les packages GitHub prennent uniquement en charge l’authentification basée sur PAT, ce qui signifie que la connexion de service GitHub dans la ressource de package doit être de type PAT. Une fois cette limitation levée, nous fournirons la prise en charge d’autres types d’authentification.
Par défaut, les packages ne sont pas automatiquement téléchargés dans vos travaux, d’où la raison pour laquelle nous avons introduit une macro getPackage qui vous permet de consommer le package défini dans la ressource. Pour plus d’informations, reportez-vous à l’exemple ci-dessous :
- job: job1
pool: default
steps:
- getPackage: myPackageAlias # Alias of the package resource
lien de cluster Azure Kubernetes Service dans la vue de ressources des environnements Kubernetes
Nous avons ajouté un lien vers l’affichage des ressources des environnements Kubernetes afin que vous puissiez accéder au panneau Azure pour le cluster correspondant. Cela s’applique aux environnements mappés à des espaces de noms dans Azure Kubernetes Service clusters.

Filtres de dossiers de mise en production dans les abonnements de notification
Les dossiers permettent d’organiser les pipelines pour faciliter la détectabilité et le contrôle de sécurité. Souvent, vous pouvez configurer des Notifications par e-mail personnalisées pour tous les pipelines de mise en production, qui sont représentés par tous les pipelines sous un dossier. Auparavant, vous deviez configurer plusieurs abonnements ou avoir une requête complexe dans les abonnements pour obtenir des e-mails ciblés. Avec cette mise à jour, vous pouvez maintenant ajouter une clause de dossier de mise en production aux événements de déploiement terminés et d’approbation en attente , et simplifier les abonnements.

Lier des éléments de travail avec des pipelines YAML à plusieurs étapes
Actuellement, vous pouvez lier automatiquement des éléments de travail avec des builds classiques. Toutefois, cela n’a pas été possible avec les pipelines YAML. Avec cette mise à jour, nous avons résolu cette lacune. Lorsque vous exécutez correctement un pipeline à l’aide du code d’une branche spécifiée, Azure Pipelines associe automatiquement l’exécution à tous les éléments de travail (qui sont déduits par le biais des validations dans ce code). Lorsque vous ouvrez l’élément de travail, vous pouvez voir les exécutions dans lesquelles le code de cet élément de travail a été généré. Pour configurer cela, utilisez le panneau des paramètres d’un pipeline.
Annuler une étape dans une exécution de pipeline YAML à plusieurs étapes
Lors de l’exécution d’un pipeline YAML à plusieurs étapes, vous pouvez maintenant annuler l’exécution d’une phase pendant qu’elle est en cours. Cela est utile si vous savez que la phase va échouer ou si vous avez une autre exécution que vous souhaitez démarrer.
Étapes ayant échoué lors de l’échec de la nouvelle tentative
L’une des fonctionnalités les plus demandées dans les pipelines à plusieurs étapes est la possibilité de réessayer une étape ayant échoué sans avoir à commencer par le début. Avec cette mise à jour, nous ajoutons une grande partie de cette fonctionnalité.
Vous pouvez maintenant réessayer une étape de pipeline lorsque l’exécution échoue. Tous les travaux ayant échoué lors de la première tentative et ceux qui dépendent transitivement de ces travaux ayant échoué sont tous tentés de nouveau.
Cela peut vous aider à gagner du temps de plusieurs façons. Par instance, lorsque vous exécutez plusieurs travaux dans une phase, vous souhaiterez peut-être que chaque étape exécute des tests sur une plateforme différente. Si les tests sur une plateforme échouent alors que d’autres réussissent, vous pouvez gagner du temps en ne ré-exécutant pas les travaux qui ont réussi. Autre exemple, une étape de déploiement peut avoir échoué en raison d’une connexion réseau défaillante. La nouvelle tentative de cette étape vous permet de gagner du temps en n’ayant pas à produire une autre build.
Il existe quelques lacunes connues dans cette fonctionnalité. Par exemple, vous ne pouvez pas réessayer une étape que vous annulez explicitement. Nous nous efforçons de combler ces lacunes dans les futures mises à jour.
Approbations dans les pipelines YAML à plusieurs étapes
Vos pipelines CD YAML peuvent contenir des approbations manuelles. Les propriétaires d’infrastructure peuvent protéger leurs environnements et demander des approbations manuelles avant qu’une étape de tout pipeline ne soit déployée sur eux. Grâce à la séparation complète des rôles entre les propriétaires d’infrastructure (environnement) et d’application (pipeline), vous vous assurerez d’une approbation manuelle pour le déploiement dans un pipeline particulier et bénéficierez d’un contrôle central dans l’application des mêmes vérifications sur tous les déploiements dans l’environnement.
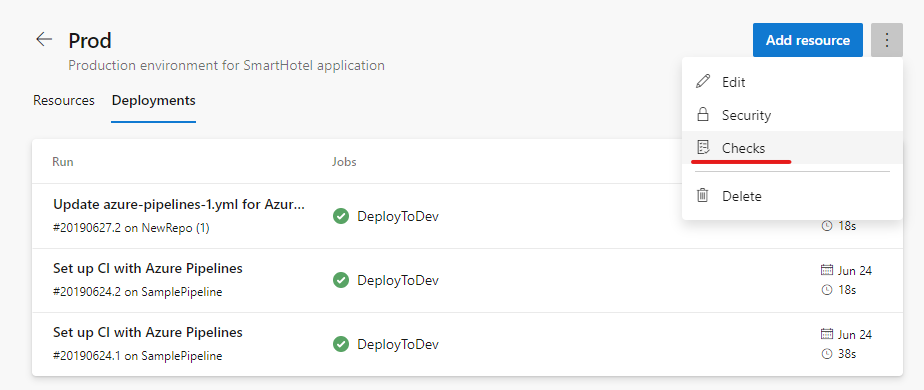
Les exécutions de pipeline déployées sur dev s’arrêtent pour approbation au début de la phase.
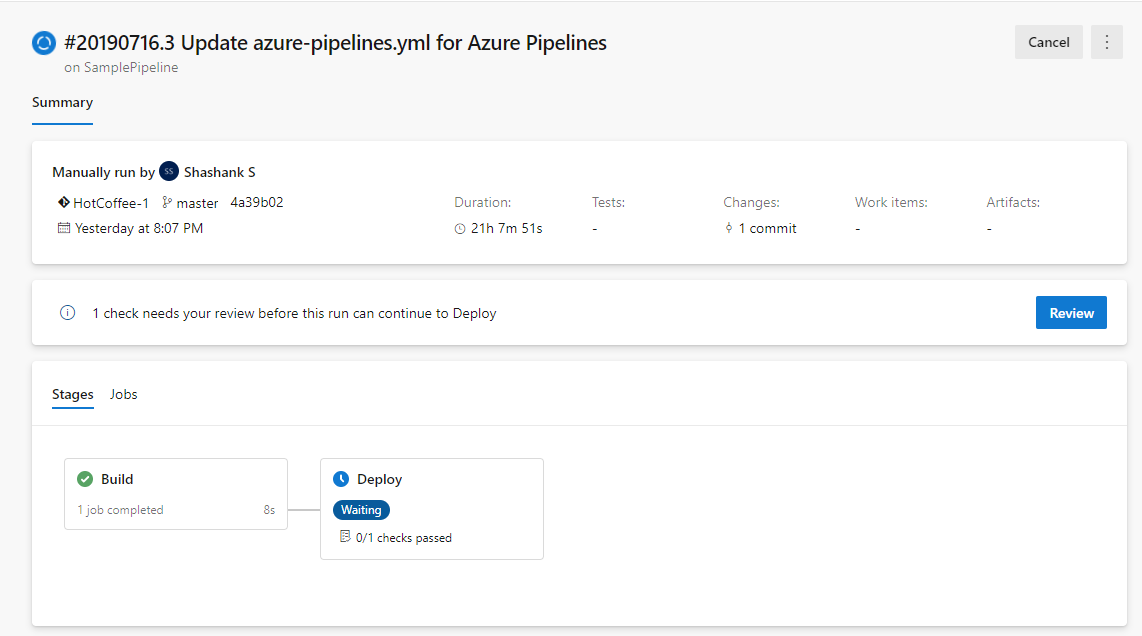
Augmentation de la limite et de la fréquence du délai d’expiration des portes
Auparavant, le délai d’expiration de la porte dans les pipelines de mise en production était de trois jours. Avec cette mise à jour, la limite de délai d’expiration a été augmentée à 15 jours pour autoriser les portes avec des durées plus longues. Nous avons également augmenté la fréquence de la porte à 30 minutes.
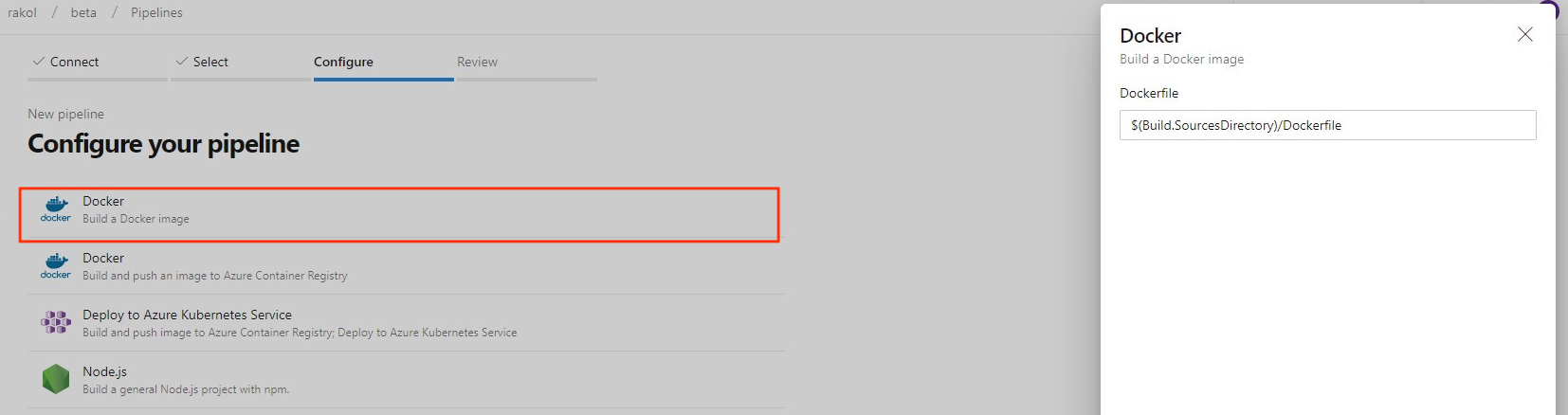
Nouveau modèle d’image de build pour Dockerfile
Auparavant, lors de la création d’un pipeline pour un fichier Dockerfile lors de la création d’un nouveau pipeline, le modèle recommandait d’envoyer l’image à un Azure Container Registry et de la déployer sur un Azure Kubernetes Service. Nous avons ajouté un nouveau modèle pour vous permettre de créer une image à l’aide de l’agent sans avoir à envoyer (push) à un registre de conteneurs.
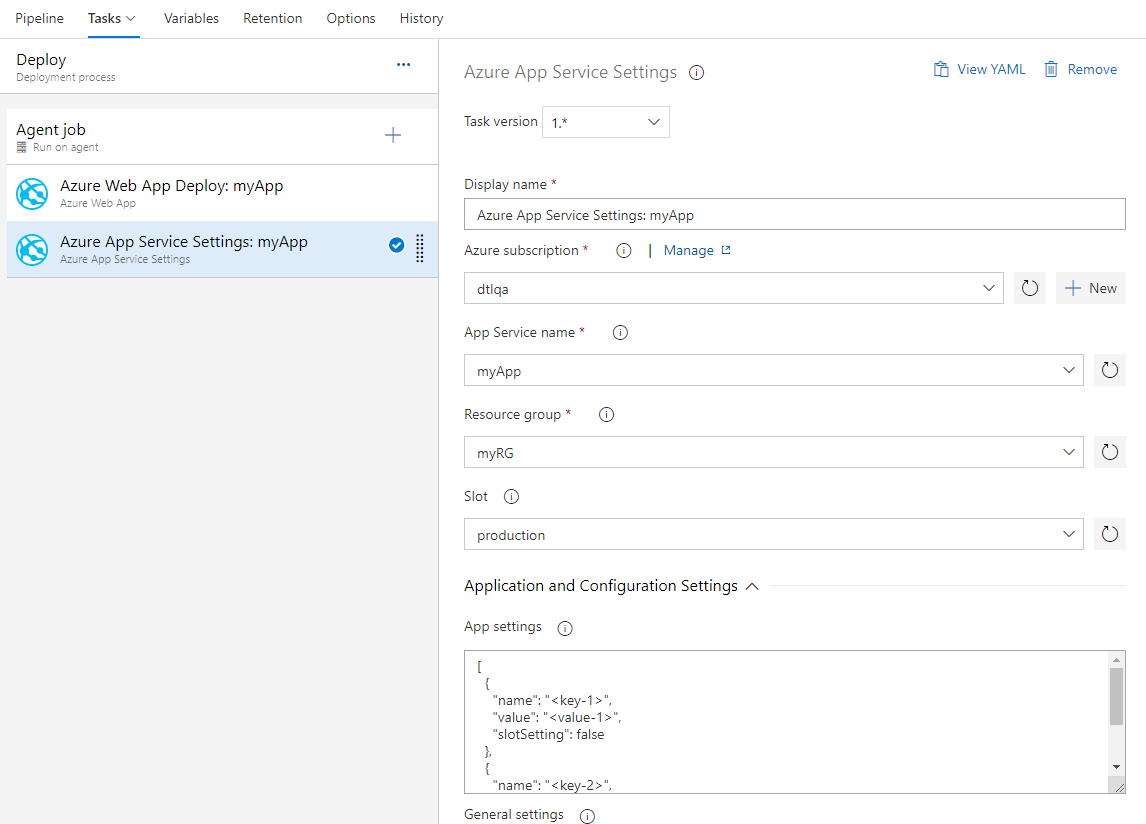
Nouvelle tâche de configuration des paramètres d’application Azure App Service
Azure App Service permet la configuration via différents paramètres tels que les paramètres d’application, les chaînes de connexion et d’autres paramètres de configuration générale. Nous avons maintenant une nouvelle tâche Azure Pipelines Azure App Service Paramètres qui prend en charge la configuration de ces paramètres en bloc à l’aide de la syntaxe JSON sur votre application web ou l’un de ses emplacements de déploiement. Cette tâche peut être utilisée avec d’autres tâches App Service pour déployer, gérer et configurer vos applications web, applications de fonction ou tout autre service App Services conteneurisé.
Azure App Service prend désormais en charge l’échange avec la préversion
Azure App Service prend désormais en charge l’échange avec préversion sur ses emplacements de déploiement. Il s’agit d’un bon moyen de valider l’application avec la configuration de production avant que l’application ne soit réellement échangée d’un emplacement intermédiaire vers un emplacement de production. Cela garantit également que l’emplacement cible/de production ne subit pas de temps d’arrêt.
Azure App Service tâche prend désormais en charge cet échange en plusieurs phases via les nouvelles actions suivantes :
- Démarrer l’échange avec la préversion : lance un échange avec un aperçu (échange multiphase) et applique la configuration de l’emplacement cible (par exemple, l’emplacement de production) à l’emplacement source.
- Terminer l’échange avec la préversion : lorsque vous êtes prêt à terminer l’échange en attente, sélectionnez l’action Terminer l’échange avec l’aperçu.
- Annuler l’échange avec la préversion : pour annuler un échange en attente, sélectionnez Annuler l’échange avec la préversion.
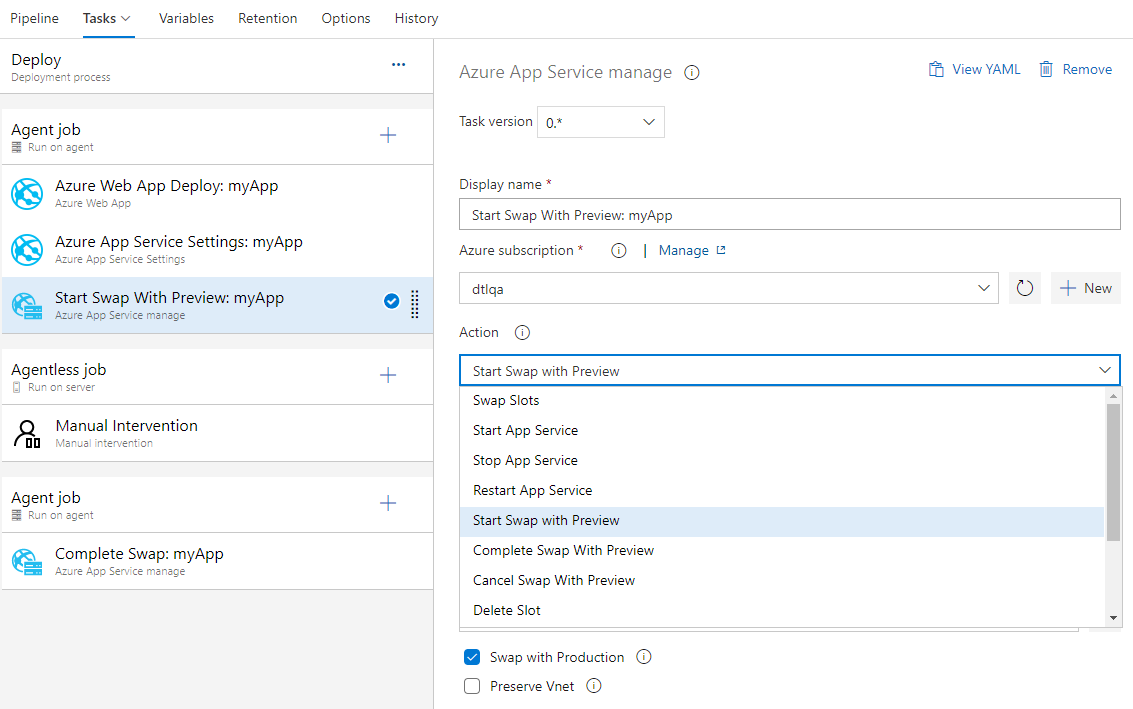
Filtre au niveau de la phase pour les artefacts Azure Container Registry et Docker Hub
Auparavant, les filtres d’expression régulière pour les artefacts Azure Container Registry et Docker Hub étaient disponibles uniquement au niveau du pipeline de mise en production. Elles ont maintenant été ajoutées au niveau de la phase.
Améliorations apportées aux approbations dans les pipelines YAML
Nous avons activé la configuration des approbations sur les connexions de service et les pools d’agents. Pour les approbations, nous suivons la répartition des rôles entre les propriétaires d’infrastructure et les développeurs. En configurant les approbations sur vos ressources, telles que les environnements, les connexions de service et les pools d’agents, vous serez assuré que toutes les exécutions de pipeline qui utilisent des ressources nécessiteront d’abord une approbation.
L’expérience est similaire à la configuration des approbations pour les environnements. Lorsqu’une approbation est en attente sur une ressource référencée dans une phase, l’exécution du pipeline attend que le pipeline soit approuvé manuellement.
Prise en charge des tests de structure de conteneur dans Azure Pipelines
L’utilisation des conteneurs dans les applications augmente et nécessite donc des tests et des validations robustes. Azure Pipelines prend désormais en charge les tests de structure de conteneur. Cette infrastructure offre un moyen pratique et puissant de vérifier le contenu et la structure de vos conteneurs.
Vous pouvez valider la structure d’une image en fonction de quatre catégories de tests qui peuvent être exécutés ensemble : tests de commande, tests d’existence de fichier, tests de contenu de fichier et tests de métadonnées. Vous pouvez utiliser les résultats dans le pipeline pour prendre des décisions go/no go. Les données de test sont disponibles dans l’exécution du pipeline avec un message d’erreur pour vous aider à mieux résoudre les échecs.
Entrez les détails du fichier de configuration et de l’image
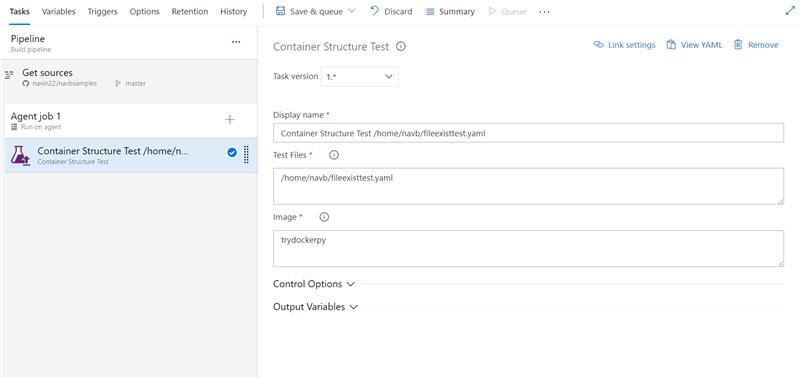
Données de test et résumé
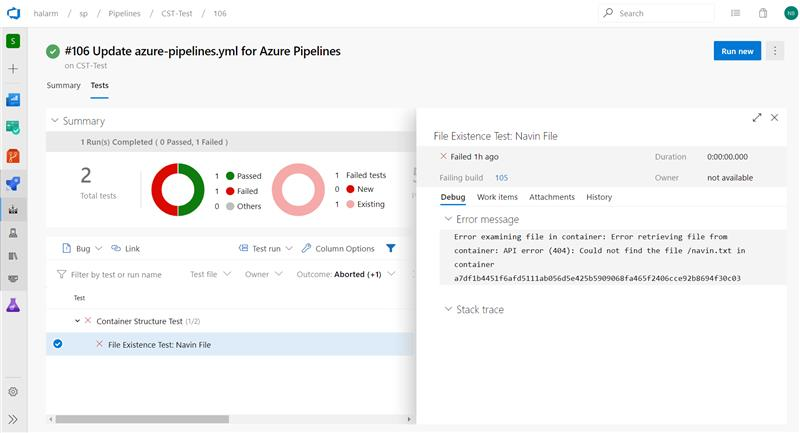
Décorateurs de pipeline pour les pipelines de mise en production
Les décorateurs de pipeline permettent d’ajouter des étapes au début et à la fin de chaque travail. Cela diffère de l’ajout d’étapes à une seule définition, car il s’applique à tous les pipelines d’une collection.
Nous prenons en charge les décorateurs pour les builds et les pipelines YAML, les clients les utilisant pour contrôler de manière centralisée les étapes de leurs travaux. Nous étendons maintenant la prise en charge aux pipelines de mise en production. Vous pouvez créer des extensions pour ajouter des étapes ciblant le nouveau point de contribution et elles seront ajoutées à tous les travaux d’agent dans les pipelines de mise en production.
Déployer Azure Resource Manager (ARM) au niveau de l’abonnement et du groupe d’administration
Auparavant, nous prenions en charge les déploiements uniquement au niveau du groupe de ressources. Avec cette mise à jour, nous avons ajouté la prise en charge du déploiement de modèles ARM aux niveaux de l’abonnement et du groupe d’administration. Cela vous aidera lors du déploiement d’un ensemble de ressources, tout en les plaçant dans différents groupes de ressources ou abonnements. Par exemple, le déploiement de la machine virtuelle de sauvegarde pour Azure Site Recovery sur un groupe de ressources et un emplacement distincts.
Fonctionnalités de CD pour vos pipelines YAML à plusieurs étapes
Vous pouvez maintenant utiliser les artefacts publiés par votre pipeline CI et activer les déclencheurs d’achèvement de pipeline. Dans les pipelines YAML à plusieurs étapes, nous introduisons pipelines en tant que ressource. Dans votre YAML, vous pouvez maintenant faire référence à un autre pipeline et activer également les déclencheurs CD.
Voici le schéma YAML détaillé pour la ressource pipelines.
resources:
pipelines:
- pipeline: MyAppCI # identifier for the pipeline resource
project: DevOpsProject # project for the build pipeline; optional input for current project
source: MyCIPipeline # source pipeline definition name
branch: releases/M159 # branch to pick the artifact, optional; defaults to all branches
version: 20190718.2 # pipeline run number to pick artifact; optional; defaults to last successfully completed run
trigger: # Optional; Triggers are not enabled by default.
branches:
include: # branches to consider the trigger events, optional; defaults to all branches.
- main
- releases/*
exclude: # branches to discard the trigger events, optional; defaults to none.
- users/*
En outre, vous pouvez télécharger les artefacts publiés par votre ressource de pipeline à l’aide de la - download tâche .
steps:
- download: MyAppCI # pipeline resource identifier
artifact: A1 # name of the artifact to download; optional; defaults to all artifacts
Pour plus d’informations, consultez la documentation sur le téléchargement des artefacts ici.
Orchestrer la stratégie de déploiement canary sur l’environnement pour Kubernetes
L’un des principaux avantages de la livraison continue des mises à jour d’application est la possibilité d’envoyer rapidement des mises à jour en production pour des microservices spécifiques. Cela vous donne la possibilité de répondre rapidement aux changements dans les besoins de l’entreprise. L’environnement a été introduit comme un concept de première classe permettant l’orchestration des stratégies de déploiement et facilitant les mises en production sans temps d’arrêt. Auparavant, nous prenions en charge la stratégie runOnce qui exécutait les étapes une fois de manière séquentielle. Avec la prise en charge de la stratégie canary dans les pipelines à plusieurs étapes, vous pouvez désormais réduire le risque en déployant lentement la modification sur un petit sous-ensemble. À mesure que vous gagnez en confiance dans la nouvelle version, vous pouvez commencer à la déployer sur d’autres serveurs de votre infrastructure et y acheminer davantage d’utilisateurs.
jobs:
- deployment:
environment: musicCarnivalProd
pool:
name: musicCarnivalProdPool
strategy:
canary:
increments: [10,20]
preDeploy:
steps:
- script: initialize, cleanup....
deploy:
steps:
- script: echo deploy updates...
- task: KubernetesManifest@0
inputs:
action: $(strategy.action)
namespace: 'default'
strategy: $(strategy.name)
percentage: $(strategy.increment)
manifests: 'manifest.yml'
postRouteTaffic:
pool: server
steps:
- script: echo monitor application health...
on:
failure:
steps:
- script: echo clean-up, rollback...
success:
steps:
- script: echo checks passed, notify...
La stratégie canary pour Kuberenetes déploie d’abord les modifications avec 10 % de pods suivis de 20 % tout en surveillant l’intégrité pendant postRouteTraffic. Si tout se passe bien, il sera promu à 100%.
Nous recherchons des commentaires précoces sur la prise en charge des ressources de machine virtuelle dans les environnements et sur l’exécution d’une stratégie de déploiement propagée sur plusieurs ordinateurs. Contactez-nous pour vous inscrire.
Stratégies d’approbation pour les pipelines YAML
Dans les pipelines YAML, nous suivons une configuration d’approbation contrôlée par le propriétaire des ressources. Les propriétaires de ressources configurent les approbations sur la ressource et tous les pipelines qui utilisent la ressource sont suspendus pour les approbations avant le début de la phase de consommation de la ressource. Il est courant que les propriétaires d’applications basées sur SOX empêchent le demandeur du déploiement d’approuver leurs propres déploiements.
Vous pouvez maintenant utiliser des options d’approbation avancées pour configurer des stratégies d’approbation, comme le demandeur ne doit pas approuver, exiger l’approbation d’un sous-ensemble d’utilisateurs et le délai d’expiration de l’approbation.
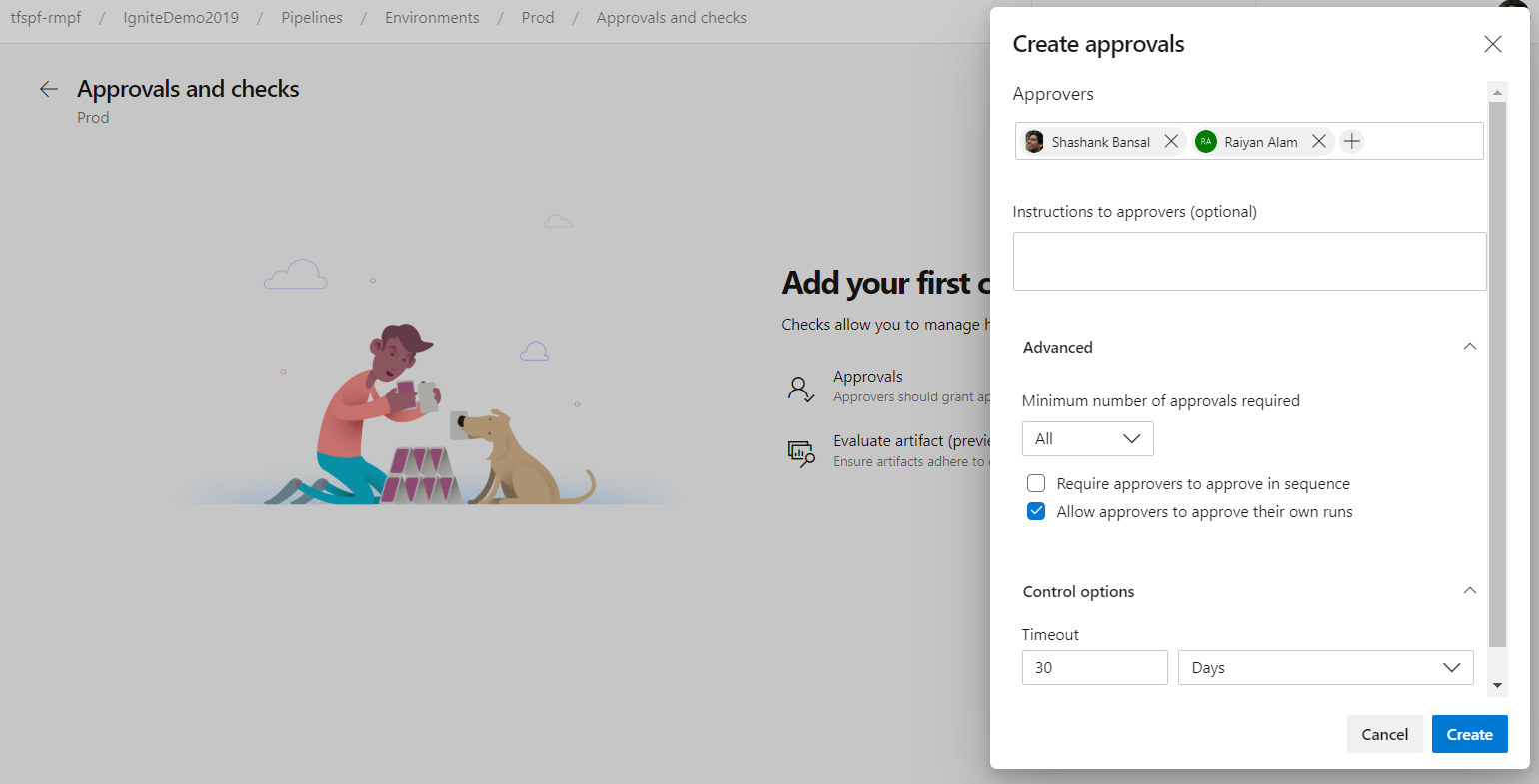
ACR en tant que ressource de pipeline de première classe
Si vous devez utiliser une image conteneur publiée sur ACR (Azure Container Registry) dans le cadre de votre pipeline et déclencher votre pipeline chaque fois qu’une nouvelle image est publiée, vous pouvez utiliser la ressource de conteneur ACR.
resources:
containers:
- container: MyACR #container resource alias
type: ACR
azureSubscription: RMPM #ARM service connection
resourceGroup: contosoRG
registry: contosodemo
repository: alphaworkz
trigger:
tags:
include:
- production
En outre, les métadonnées d’image ACR sont accessibles à l’aide de variables prédéfinies. La liste suivante inclut les variables ACR disponibles pour définir une ressource de conteneur ACR dans votre pipeline.
resources.container.<Alias>.type
resources.container.<Alias>.registry
resources.container.<Alias>.repository
resources.container.<Alias>.tag
resources.container.<Alias>.digest
resources.container.<Alias>.URI
resources.container.<Alias>.location
Améliorations apportées à l’évaluation de la stratégie de vérification des artefacts dans les pipelines
Nous avons amélioré la case activée d’évaluation de l’artefact pour faciliter l’ajout de stratégies à partir d’une liste de définitions de stratégie prêtes à l’emploi. La définition de stratégie est générée automatiquement et ajoutée à la configuration case activée qui peut être mise à jour si nécessaire.
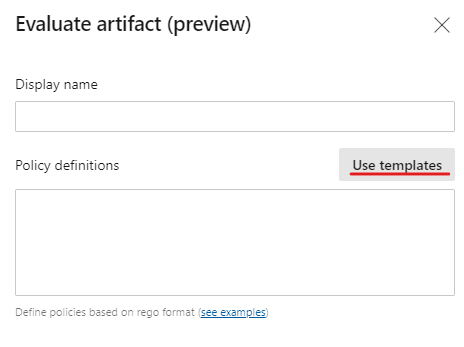

Prise en charge des variables de sortie dans un travail de déploiement
Vous pouvez maintenant définir des variables de sortie dans les hooks de cycle de vie d’un travail de déploiement et les consommer dans d’autres étapes et travaux en aval au sein de la même étape.
Lors de l’exécution de stratégies de déploiement, vous pouvez accéder aux variables de sortie entre les travaux à l’aide de la syntaxe suivante.
- Pour la stratégie runOnce :
$[dependencies.<job-name>.outputs['<lifecycle-hookname>.<step-name>.<variable-name>']] - Pour une stratégie avec contrôle de validité :
$[dependencies.<job-name>.outputs['<lifecycle-hookname>_<increment-value>.<step-name>.<variable-name>']] - Pour la stratégie propagée :
$[dependencies.<job-name>.outputs['<lifecycle-hookname>_<resource-name>.<step-name>.<variable-name>']]
// Set an output variable in a lifecycle hook of a deployment job executing canary strategy
- deployment: A
pool:
vmImage: 'ubuntu-16.04'
environment: staging
strategy:
canary:
increments: [10,20] # creates multiple jobs, one for each increment. Output variable can be referenced with this.
deploy:
steps:
- script: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the deployment variable value"
name: setvarStep
- script: echo $(setvarStep.myOutputVar)
name: echovar
// Map the variable from the job
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-16.04'
variables:
myVarFromDeploymentJob: $[ dependencies.A.outputs['deploy_10.setvarStep.myOutputVar'] ]
steps:
- script: "echo $(myVarFromDeploymentJob)"
name: echovar
En savoir plus sur la définition d’une variable de sortie multi-travaux
Éviter la restauration des modifications critiques
Dans les pipelines de mise en production classiques, il est courant de s’appuyer sur des déploiements planifiés pour les mises à jour régulières. Toutefois, lorsque vous avez un correctif critique, vous pouvez choisir de démarrer un déploiement manuel hors bande. Dans ce cas, les versions antérieures continuent de rester planifiées. Cela a posé un problème, car le déploiement manuel serait restauré lorsque les déploiements ont repris conformément à la planification. Beaucoup d’entre vous ont signalé ce problème et nous l’avons maintenant résolu. Avec le correctif, tous les anciens déploiements planifiés dans l’environnement sont annulés lorsque vous démarrez manuellement un déploiement. Cela s’applique uniquement lorsque l’option de mise en file d’attente est sélectionnée comme « Déployer le plus récent et annuler les autres ».
Autorisation simplifiée des ressources dans les pipelines YAML
Une ressource est tout ce qui est utilisé par un pipeline qui se trouve en dehors du pipeline. Les ressources doivent être autorisées avant de pouvoir être utilisées. Auparavant, lors de l’utilisation de ressources non autorisées dans un pipeline YAML, cela échouait avec une erreur d’autorisation de ressource. Vous deviez autoriser les ressources à partir de la page récapitulative de l’exécution ayant échoué. En outre, le pipeline a échoué s’il utilisait une variable qui faisait référence à une ressource non autorisée.
Nous allons maintenant faciliter la gestion des autorisations de ressources. Au lieu d’échouer l’exécution, l’exécution attend les autorisations sur les ressources au début de la phase de consommation de la ressource. Un propriétaire de ressource peut afficher le pipeline et autoriser la ressource à partir de la page Sécurité.
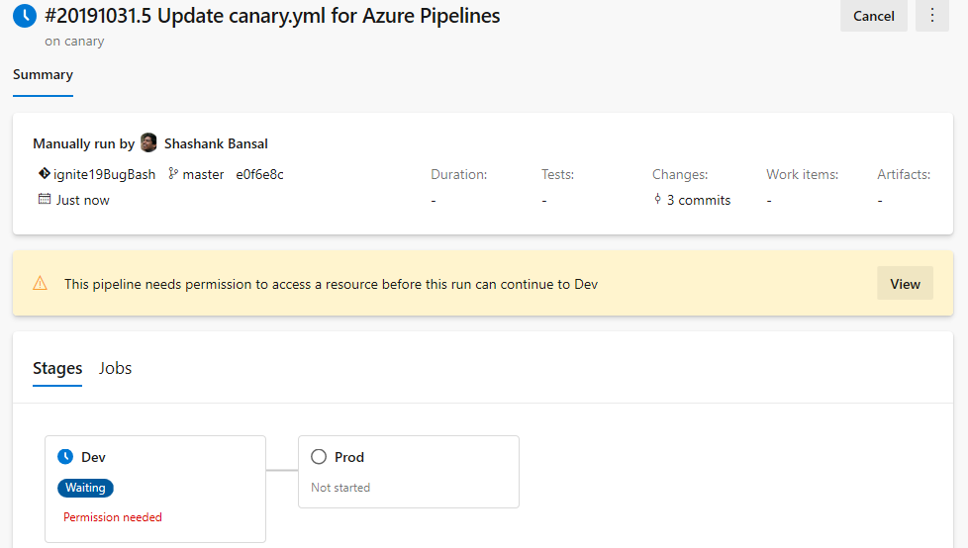
Évaluer les case activée d’artefacts
Vous pouvez maintenant définir un ensemble de stratégies et ajouter l’évaluation de stratégie en tant que case activée sur un environnement pour les artefacts d’images conteneur. Lorsqu’un pipeline s’exécute, l’exécution s’interrompt avant de commencer une étape qui utilise l’environnement. La stratégie spécifiée est évaluée par rapport aux métadonnées disponibles pour l’image en cours de déploiement. Le case activée réussit lorsque la stratégie réussit et marque l’étape comme ayant échoué si le case activée échoue.
Mises à jour à la tâche de déploiement de modèle ARM
Auparavant, nous ne filtions pas les connexions de service dans la tâche de déploiement de modèle ARM. Cela peut entraîner l’échec du déploiement si vous sélectionnez une connexion de service d’étendue inférieure pour effectuer des déploiements de modèles ARM dans une étendue plus large. À présent, nous avons ajouté le filtrage des connexions de service pour filtrer les connexions de service de portée inférieure en fonction de l’étendue de déploiement que vous choisissez.
ReviewApp dans l’environnement
ReviewApp déploie chaque demande de tirage de votre référentiel Git vers une ressource d’environnement dynamique. Les réviseurs peuvent voir à quoi ressemblent ces modifications et travailler avec d’autres services dépendants avant leur fusion dans la branche main et leur déploiement en production. Cela vous permettra de créer et de gérer facilement des ressources reviewApp et de bénéficier de toutes les fonctionnalités de traçabilité et de diagnostic des fonctionnalités de l’environnement. À l’aide de l’mot clé reviewApp, vous pouvez créer un clone d’une ressource (créer dynamiquement une ressource basée sur une ressource existante dans un environnement) et ajouter la nouvelle ressource à l’environnement.
Voici un exemple d’extrait de code YAML de l’utilisation de reviewApp sous les environnements.
jobs:
- deployment:
environment:
name: smarthotel-dev
resourceName: $(System.PullRequest.PullRequestId)
pool:
name: 'ubuntu-latest'
strategy:
runOnce:
pre-deploy:
steps:
- reviewApp: MasterNamespace
Collecter les métadonnées automatiques et spécifiées par l’utilisateur à partir du pipeline
Vous pouvez maintenant activer la collecte automatique et spécifiée par l’utilisateur de métadonnées à partir de tâches de pipeline. Vous pouvez utiliser des métadonnées pour appliquer une stratégie d’artefact à un environnement à l’aide de l’case activée d’évaluation de l’artefact.
Déploiements de machines virtuelles avec des environnements
L’une des fonctionnalités les plus demandées dans les environnements était les déploiements de machines virtuelles. Avec cette mise à jour, nous activons la ressource Machine virtuelle dans les environnements. Vous pouvez désormais orchestrer des déploiements sur plusieurs machines et effectuer des mises à jour propagées à l’aide de pipelines YAML. Vous pouvez également installer l’agent directement sur chacun de vos serveurs cibles et piloter le déploiement propagé sur ces serveurs. En outre, vous pouvez utiliser le catalogue de tâches complet sur vos ordinateurs cibles.
Un déploiement propagé remplace les instances de la version précédente d’une application par des instances de la nouvelle version de l’application sur un ensemble de machines (groupe propagé) dans chaque itération.
Par exemple, ci-dessous, les mises à jour de déploiement propagées jusqu’à cinq cibles dans chaque itération. maxParallel détermine le nombre de cibles pouvant être déployées en parallèle. La sélection prend en compte le nombre de cibles qui doivent rester disponibles à tout moment, à l’exception des cibles sur lesquelles sont déployées. Il est également utilisé pour déterminer les conditions de réussite et d’échec lors d’un déploiement.
jobs:
- deployment:
displayName: web
environment:
name: musicCarnivalProd
resourceType: VirtualMachine
strategy:
rolling:
maxParallel: 5 #for percentages, mention as x%
preDeploy:
steps:
- script: echo initialize, cleanup, backup, install certs...
deploy:
steps:
- script: echo deploy ...
routeTraffic:
steps:
- script: echo routing traffic...
postRouteTaffic:
steps:
- script: echo health check post routing traffic...
on:
failure:
steps:
- script: echo restore from backup ..
success:
steps:
- script: echo notify passed...
Notes
Avec cette mise à jour, tous les artefacts disponibles à partir du pipeline actuel et des ressources de pipeline associées sont téléchargés uniquement dans deploy le hook de cycle de vie. Toutefois, vous pouvez choisir de télécharger en spécifiant la tâche Télécharger l’artefact de pipeline.
Il existe quelques lacunes connues dans cette fonctionnalité. Par exemple, lorsque vous retentez un index, elle va réexécuter le déploiement sur toutes les machines virtuelles, pas seulement sur les cibles ayant échoué. Nous travaillons à combler ces lacunes dans les prochaines mises à jour.
Contrôle supplémentaire de vos déploiements
Azure Pipelines prend en charge les déploiements contrôlés avec des approbations manuelles depuis un certain temps. Avec les dernières améliorations, vous disposez désormais d’un contrôle supplémentaire sur vos déploiements. En plus des approbations, les propriétaires de ressources peuvent désormais ajouter des données automatisées checks pour vérifier les stratégies de sécurité et de qualité. Ces vérifications peuvent être utilisées pour déclencher des opérations, puis attendre qu’elles se terminent. À l’aide des vérifications supplémentaires, vous pouvez désormais définir des critères d’intégrité basés sur plusieurs sources et être sûr que tous les déploiements ciblant vos ressources sont sécurisés, quel que soit le pipeline YAML qui effectue le déploiement. L’évaluation de chaque case activée peut être répétée régulièrement en fonction de l’intervalle de nouvelle tentative spécifié pour le case activée.
Les vérifications supplémentaires suivantes sont désormais disponibles :
- Appeler une API REST et effectuer une validation en fonction du corps de la réponse ou d’un rappel à partir du service externe
- Appeler une fonction Azure et effectuer une validation en fonction de la réponse ou d’un rappel de la fonction
- Interroger les règles Azure Monitor pour les alertes actives
- Vérifiez que le pipeline étend un ou plusieurs modèles YAML
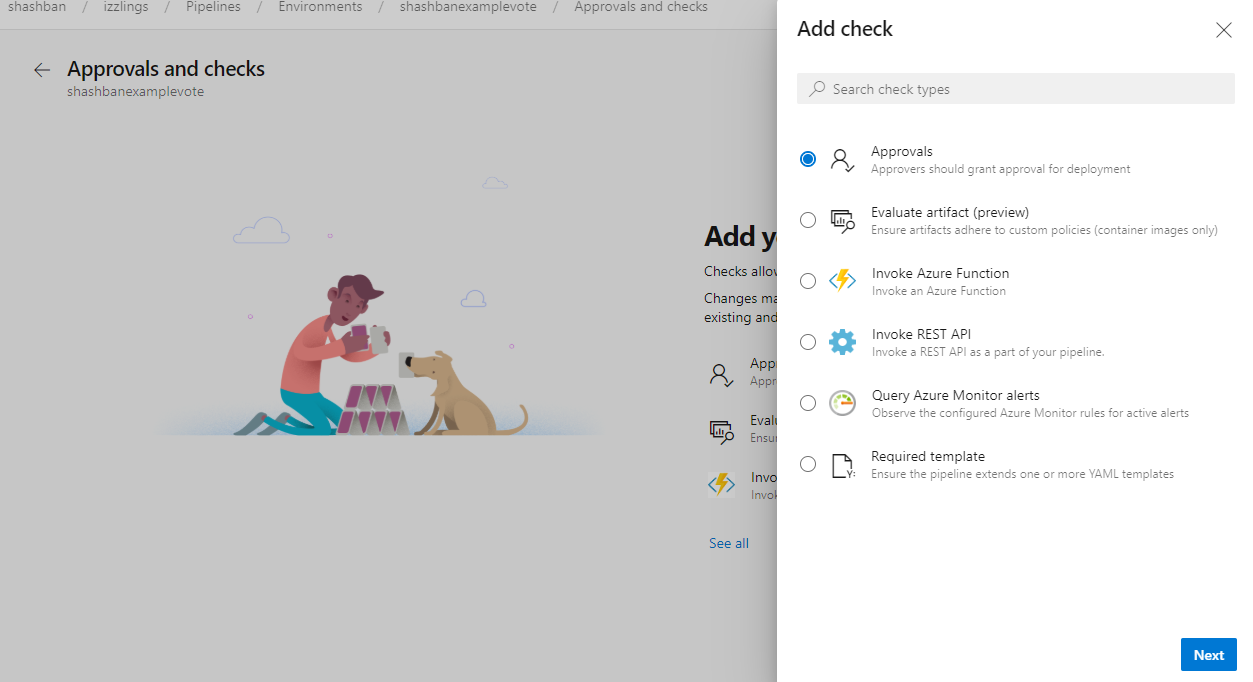
Notification d’approbation
Lorsque vous ajoutez une approbation à un environnement ou à une connexion de service, tous les pipelines à plusieurs étapes qui utilisent la ressource attendent automatiquement l’approbation au début de la phase. Les approbateurs désignés doivent terminer l’approbation avant que le pipeline puisse continuer.
Avec cette mise à jour, les approbateurs reçoivent une notification par e-mail pour l’approbation en attente. Les utilisateurs et les propriétaires d’équipe peuvent désactiver ou configurer des abonnements personnalisés à l’aide des paramètres de notification.
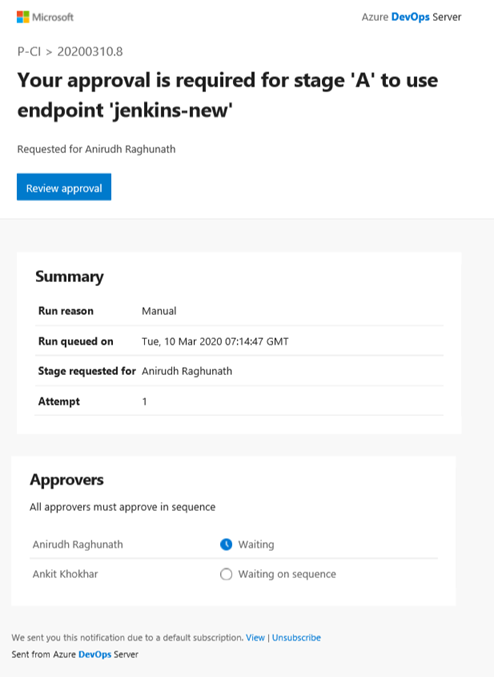
Configurer les stratégies de déploiement à partir de Portail Azure
Grâce à cette fonctionnalité, nous vous avons facilité la configuration des pipelines qui utilisent la stratégie de déploiement de votre choix, par exemple Rolling, Canary ou Blue-Green. À l’aide de ces stratégies prêtes à l’emploi, vous pouvez déployer des mises à jour en toute sécurité et atténuer les risques de déploiement associés. Pour y accéder, cliquez sur le paramètre « Livraison continue » dans une machine virtuelle Azure. Dans le volet de configuration, vous êtes invité à sélectionner des détails sur le projet Azure DevOps dans lequel le pipeline sera créé, le groupe de déploiement, le pipeline de build qui publie le package à déployer et la stratégie de déploiement de votre choix. À l’avenir, vous allez configurer un pipeline entièrement fonctionnel qui déploie le package sélectionné sur cette machine virtuelle.
Pour plus d’informations, case activée notre documentation sur la configuration des stratégies de déploiement.
Paramètres de runtime
Les paramètres de runtime vous permettent d’avoir plus de contrôle sur les valeurs qui peuvent être passées à un pipeline. Contrairement aux variables, les paramètres d’exécution ont des types de données et ne deviennent pas automatiquement des variables d’environnement. Avec des paramètres de runtime, vous pouvez :
- Fournir des valeurs différentes aux scripts et aux tâches au moment de l’exécution
- Contrôler les types de paramètre, les plages autorisées et les valeurs par défaut
- Sélectionner dynamiquement des travaux et des étapes avec l’expression de modèle
Pour en savoir plus sur les paramètres d’exécution, consultez la documentation ici.
Utiliser étend mot clé dans les pipelines
Actuellement, les pipelines peuvent être pris en compte dans des modèles, ce qui favorise la réutilisation et réduit la chaudronnerie. La structure globale du pipeline était toujours définie par le fichier YAML racine. Avec cette mise à jour, nous avons ajouté un moyen plus structuré d’utiliser des modèles de pipeline. Un fichier YAML racine peut désormais utiliser le mot clé s’étend pour indiquer que la structure de pipeline main se trouve dans un autre fichier. Cela vous permet de contrôler les segments qui peuvent être étendus ou modifiés et les segments qui sont corrigés. Nous avons également amélioré les paramètres de pipeline avec des types de données pour effacer les crochets que vous pouvez fournir.
Cet exemple montre comment fournir des crochets simples à l’auteur du pipeline à utiliser. Le modèle exécute toujours une build, exécute éventuellement des étapes supplémentaires fournies par le pipeline, puis exécute une étape de test facultative.
# azure-pipelines.yml
extends:
template: build-template.yml
parameters:
runTests: true
postBuildSteps:
- script: echo This step runs after the build!
- script: echo This step does too!
# build-template.yml
parameters:
- name: runTests
type: boolean
default: false
- name: postBuildSteps
type: stepList
default: []
steps:
- task: MSBuild@1 # this task always runs
- ${{ if eq(parameters.runTests, true) }}:
- task: VSTest@2 # this task is injected only when runTests is true
- ${{ each step in parameters.postBuildSteps }}:
- ${{ step }}
Variables de contrôle qui peuvent être remplacées au moment de la file d’attente
Auparavant, vous pouviez utiliser l’interface utilisateur ou l’API REST pour mettre à jour les valeurs d’une variable avant de commencer une nouvelle exécution. Bien que l’auteur du pipeline puisse marquer certaines variables comme _settable at queue time_, le système n’a pas appliqué ce paramètre et n’a pas empêché la définition d’autres variables. En d’autres termes, le paramètre a uniquement été utilisé pour demander des entrées supplémentaires lors du démarrage d’une nouvelle exécution.
Nous avons ajouté un nouveau paramètre de collection qui applique le _settable at queue time_ paramètre. Cela vous permet de contrôler les variables qui peuvent être modifiées lors du démarrage d’une nouvelle exécution. À l’avenir, vous ne pouvez pas modifier une variable qui n’est pas marquée par l’auteur comme _settable at queue time_.
Notes
Ce paramètre est désactivé par défaut dans les collections existantes, mais il est activé par défaut lorsque vous créez une collection Azure DevOps.
Nouvelles variables prédéfinies dans le pipeline YAML
Les variables sont pratiques pour fournir des bits de données clés dans différentes parties de votre pipeline. Avec cette mise à jour, nous avons ajouté quelques variables prédéfinies à un travail de déploiement. Ces variables sont automatiquement définies par le système, limitées au travail de déploiement spécifique et sont en lecture seule.
- Environment.Id : ID de l’environnement.
- Environment.Name : nom de l’environnement ciblé par le travail de déploiement.
- Environment.ResourceId : ID de la ressource dans l’environnement ciblé par le travail de déploiement.
- Environment.ResourceName : nom de la ressource dans l’environnement ciblé par le travail de déploiement.
Extraction de plusieurs référentiels
Les pipelines s’appuient souvent sur plusieurs référentiels. Vous pouvez avoir différents référentiels avec la source, les outils, les scripts ou d’autres éléments dont vous avez besoin pour générer votre code. Auparavant, vous deviez ajouter ces référentiels en tant que sous-modules ou en tant que scripts manuels pour exécuter git checkout. Vous pouvez maintenant extraire et case activée d’autres dépôts, en plus de celui que vous utilisez pour stocker votre pipeline YAML.
Par exemple, si vous avez un dépôt appelé MyCode avec un pipeline YAML et un deuxième dépôt appelé Outils, votre pipeline YAML se présente comme suit :
resources:
repositories:
- repository: tools
name: Tools
type: git
steps:
- checkout: self
- checkout: tools
- script: dir $(Build.SourcesDirectory)
La troisième étape affiche deux répertoires, MyCode et Tools dans le répertoire sources.
Azure Repos dépôts Git sont pris en charge. Pour plus d’informations, consultez Extraction de plusieurs référentiels.
Obtenir des détails au moment de l’exécution sur plusieurs référentiels
Lorsqu’un pipeline est en cours d’exécution, Azure Pipelines ajoute des informations sur le dépôt, la branche et la validation qui ont déclenché l’exécution. Maintenant que les pipelines YAML prennent en charge l’extraction de plusieurs dépôts, vous pouvez également connaître le dépôt, la branche et la validation qui ont été extraits pour d’autres dépôts. Ces données sont disponibles via une expression runtime, que vous pouvez désormais mapper dans une variable. Par exemple :
resources:
repositories:
- repository: other
type: git
name: MyProject/OtherTools
variables:
tools.ref: $[ resources.repositories['other'].ref ]
steps:
- checkout: self
- checkout: other
- bash: echo "Tools version: $TOOLS_REF"
Autoriser les références de référentiel à d’autres collections Azure Repos
Auparavant, lorsque vous référencez des dépôts dans un pipeline YAML, tous les dépôts Azure Repos devaient se trouver dans la même collection que le pipeline. À présent, vous pouvez pointer vers des dépôts dans d’autres collections à l’aide d’une connexion de service. Par exemple :
resources:
repositories:
- repository: otherrepo
name: ProjectName/RepoName
endpoint: MyServiceConnection
steps:
- checkout: self
- checkout: otherrepo
MyServiceConnection pointe vers une autre collection Azure DevOps et possède des informations d’identification qui peuvent accéder au dépôt dans un autre projet. Les dépôts, self et otherrepo, finissent par être extraits.
Important
MyServiceConnectiondoit être une connexion de service Azure Repos/Team Foundation Server, voir l’image ci-dessous.
Métadonnées de ressources de pipeline en tant que variables prédéfinies
Nous avons ajouté des variables prédéfinies pour les ressources de pipelines YAML dans le pipeline. Voici la liste des variables de ressources de pipeline disponibles.
resources.pipeline.<Alias>.projectName
resources.pipeline.<Alias>.projectID
resources.pipeline.<Alias>.pipelineName
resources.pipeline.<Alias>.pipelineID
resources.pipeline.<Alias>.runName
resources.pipeline.<Alias>.runID
resources.pipeline.<Alias>.runURI
resources.pipeline.<Alias>.sourceBranch
resources.pipeline.<Alias>.sourceCommit
resources.pipeline.<Alias>.sourceProvider
resources.pipeline.<Alias>.requestedFor
resources.pipeline.<Alias>.requestedForID
kustomize and kompose as bake options dans KubernetesManifest task
kustomize (qui fait partie de Kubernetes sig-cli) vous permet de personnaliser des fichiers YAML bruts et sans modèle à plusieurs fins et de laisser le YAML d’origine intact. Une option pour kustomize a été ajoutée sous l’action bake de la tâche KubernetesManifest afin que tout dossier contenant des fichiers kustomization.yaml puisse être utilisé pour générer les fichiers manifeste utilisés dans l’action de déploiement de la tâche KubernetesManifest.
steps:
- task: KubernetesManifest@0
name: bake
displayName: Bake K8s manifests from Helm chart
inputs:
action: bake
renderType: kustomize
kustomizationPath: folderContainingKustomizationFile
- task: KubernetesManifest@0
displayName: Deploy K8s manifests
inputs:
kubernetesServiceConnection: k8sSC1
manifests: $(bake.manifestsBundle)
kompose transforme un fichier Docker Compose en ressource Kubernetes.
steps:
- task: KubernetesManifest@0
name: bake
displayName: Bake K8s manifests from Helm chart
inputs:
action: bake
renderType: kompose
dockerComposeFile: docker-compose.yaml
- task: KubernetesManifest@0
displayName: Deploy K8s manifests
inputs:
kubernetesServiceConnection: k8sSC1
manifests: $(bake.manifestsBundle)
Prise en charge des informations d’identification d’administrateur de cluster dans la tâche HelmDeploy
Auparavant, la tâche HelmDeploy utilisait les informations d’identification utilisateur du cluster pour les déploiements. Cela a entraîné des invites de connexion interactives et des pipelines défaillants pour un cluster RBAC basé sur Azure Active Directory. Pour résoudre ce problème, nous avons ajouté une case à cocher qui vous permet d’utiliser les informations d’identification de l’administrateur de cluster au lieu des informations d’identification d’un utilisateur de cluster.

Entrée d’arguments dans la tâche Docker Compose
Un nouveau champ a été introduit dans la tâche Docker Compose pour vous permettre d’ajouter des arguments tels que --no-cache. L’argument sera transmis par la tâche lors de l’exécution de commandes telles que build.
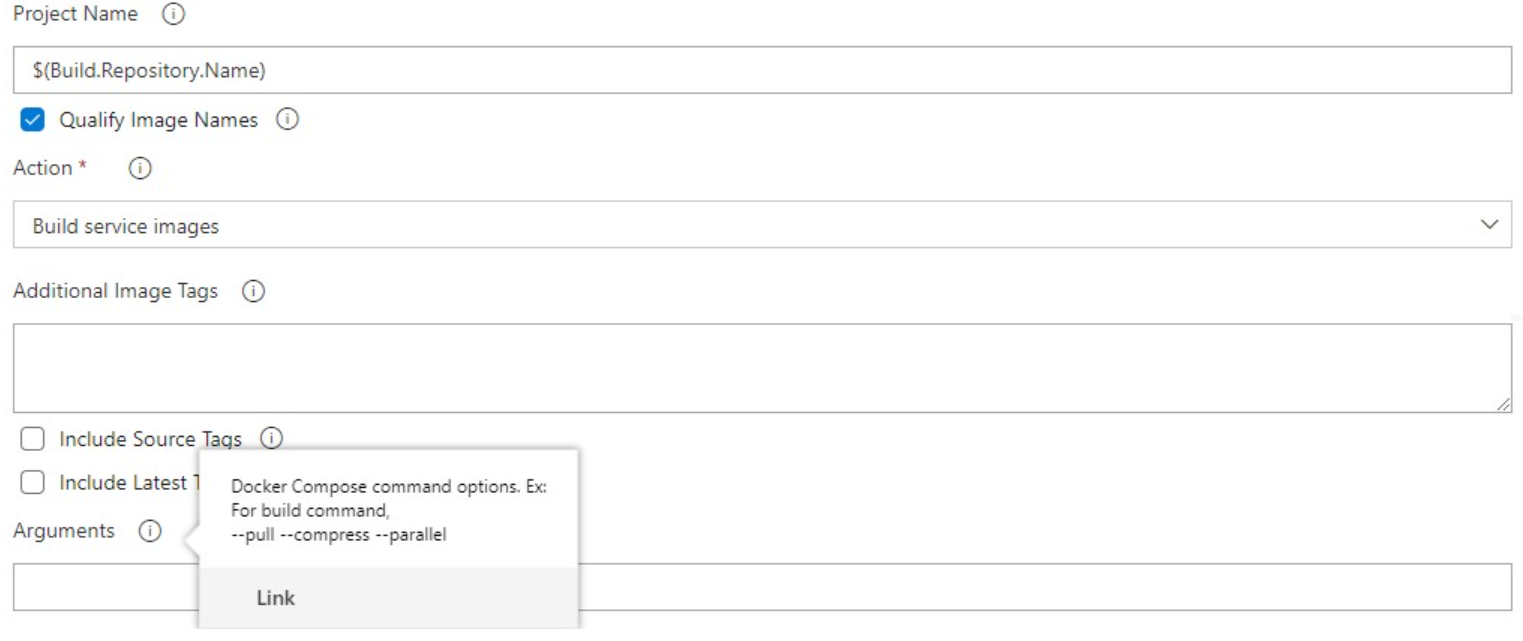
Améliorations de la tâche de mise en production de GitHub
Nous avons apporté plusieurs améliorations à la tâche de mise en production de GitHub. Vous pouvez maintenant avoir un meilleur contrôle sur la création de la mise en production à l’aide du champ de modèle de balise en spécifiant une expression régulière de balise et la version ne sera créée que lorsque le commit déclencheur est marqué avec une chaîne correspondante.

Nous avons également ajouté des fonctionnalités pour personnaliser la création et la mise en forme du journal des modifications. Dans la nouvelle section relative à la configuration du journal des modifications, vous pouvez maintenant spécifier la version à laquelle la version actuelle doit être comparée. Comparer à la version peut être la dernière version complète (exclut les préversions), la dernière version non-brouillon ou toute version précédente correspondant à votre balise de mise en production fournie. En outre, la tâche fournit le champ de type changelog pour mettre en forme le journal des modifications. En fonction de la sélection, le journal des modifications affiche une liste de validations ou une liste de problèmes/demandes de tirage classés en fonction des étiquettes.
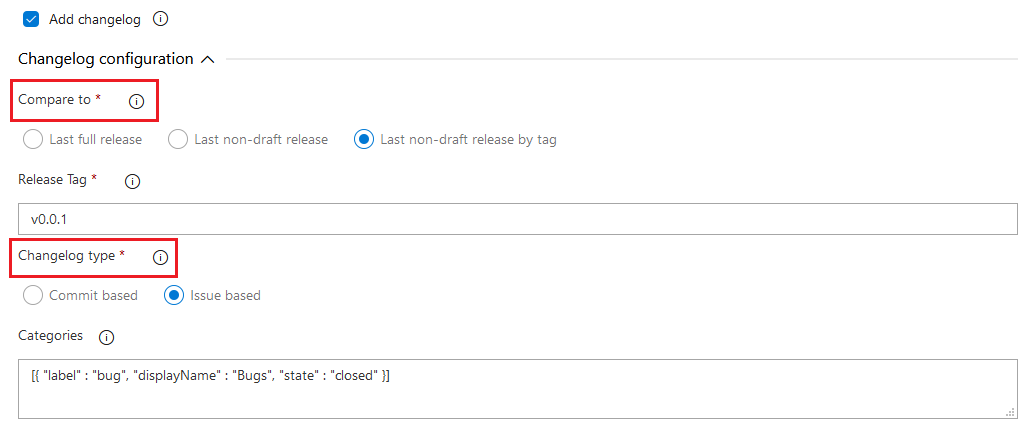
Ouvrir la tâche du programme d’installation de l’Agent de stratégie
Open Policy Agent est un moteur de stratégie à usage général open source qui permet une application de stratégie unifiée et contextuelle. Nous avons ajouté la tâche du programme d’installation de l’Agent Open Policy. Il est particulièrement utile pour l’application de la stratégie dans le pipeline en ce qui concerne les fournisseurs d’infrastructure en tant que code.
Par exemple, Open Policy Agent peut évaluer les fichiers de stratégie Rego et les plans Terraform dans le pipeline.
task: OpenPolicyAgentInstaller@0
inputs:
opaVersion: '0.13.5'
Prise en charge des scripts PowerShell dans la tâche Azure CLI
Auparavant, vous pouviez exécuter des scripts batch et bash dans le cadre d’une tâche Azure CLI. Avec cette mise à jour, nous avons ajouté la prise en charge de PowerShell et des scripts principaux PowerShell à la tâche.

Tâches canary basées sur l’interface Service Mesh dans KubernetesManifest
Auparavant, lorsque la stratégie canary était spécifiée dans la tâche KubernetesManifest, la tâche créait des charges de travail de base et canary dont les réplicas égalaient à un pourcentage des réplicas utilisés pour les charges de travail stables. Cela n’était pas exactement la même chose que le fractionnement du trafic jusqu’au pourcentage souhaité au niveau de la demande. Pour ce faire, nous avons ajouté la prise en charge des déploiements canary basés sur l’interface Service Mesh à la tâche KubernetesManifest.
L’abstraction de l’interface Service Mesh permet une configuration plug-and-play avec des fournisseurs de maillage de services tels que Linkerd et Istio. À présent, la tâche KubernetesManifest enlève le travail difficile de mappage des objets TrafficSplit de SMI aux services stables, de référence et de canaris pendant le cycle de vie de la stratégie de déploiement. Le pourcentage souhaité de fractionnement du trafic entre stable, ligne de base et canary est plus précis, car le pourcentage de fractionnement du trafic est contrôlé sur les requêtes dans le plan de maillage de service.
Voici un exemple d’exécution de déploiements canary basés sur SMI.
- deployment: Deployment
displayName: Deployment
pool:
vmImage: $(vmImage)
environment: ignite.smi
strategy:
canary:
increments: [25, 50]
preDeploy:
steps:
- task: KubernetesManifest@0
displayName: Create/update secret
inputs:
action: createSecret
namespace: smi
secretName: $(secretName)
dockerRegistryEndpoint: $(dockerRegistryServiceConnection)
deploy:
steps:
- checkout: self
- task: KubernetesManifest@0
displayName: Deploy canary
inputs:
action: $(strategy.action)
namespace: smi
strategy: $(strategy.name)
trafficSplitMethod: smi
percentage: $(strategy.increment)
baselineAndCanaryReplicas: 1
manifests: |
manifests/deployment.yml
manifests/service.yml
imagePullSecrets: $(secretName)
containers: '$(containerRegistry)/$(imageRepository):$(Build.BuildId)'
postRouteTraffic:
pool: server
steps:
- task: Delay@1
inputs:
delayForMinutes: '2'
Azure File Copy Task prend désormais en charge AzCopy V10
La tâche de copie de fichiers Azure peut être utilisée dans un pipeline de build ou de mise en production pour copier des fichiers vers des objets blob de stockage Microsoft ou des machines virtuelles. La tâche utilise AzCopy, la build de l’utilitaire en ligne de commande pour la copie rapide des données à partir de et dans des comptes de stockage Azure. Avec cette mise à jour, nous avons ajouté la prise en charge d’AzCopy V10, qui est la dernière version d’AzCopy.
La azcopy copy commande prend uniquement en charge les arguments qui lui sont associés. En raison de la modification de la syntaxe d’AzCopy, certaines des fonctionnalités existantes ne sont pas disponibles dans AzCopy V10. Il s’agit notamment des paramètres suivants :
- Spécification de l’emplacement du journal
- Nettoyage des fichiers journaux et de planification après la copie
- Reprendre la copie en cas d’échec du travail
Les fonctionnalités supplémentaires prises en charge dans cette version de la tâche sont les suivantes :
- Symboles génériques dans le nom de fichier/chemin d’accès de la source
- Inférence du type de contenu en fonction de l’extension de fichier quand aucun argument n’est fourni
- Définition du détail du journal pour le fichier journal en passant un argument
Améliorer la sécurité du pipeline en limitant l’étendue des jetons d’accès
Chaque travail qui s’exécute dans Azure Pipelines obtient un jeton d’accès. Le jeton d’accès est utilisé par les tâches et par vos scripts pour rappeler Azure DevOps. Par exemple, nous utilisons le jeton d’accès pour obtenir du code source, charger des journaux, des résultats de test, des artefacts ou pour effectuer des appels REST dans Azure DevOps. Un nouveau jeton d’accès est généré pour chaque travail et il expire une fois le travail terminé. Avec cette mise à jour, nous avons ajouté les améliorations suivantes.
Empêcher le jeton d’accéder aux ressources en dehors d’un projet d’équipe
Jusqu’à présent, l’étendue par défaut de tous les pipelines était la collection de projets d’équipe. Vous pouvez modifier l’étendue pour qu’elle soit le projet d’équipe dans les pipelines de build classiques. Toutefois, vous ne disposiez pas de ce contrôle pour les pipelines de version classique ou YAML. Avec cette mise à jour, nous introduisons un paramètre de collection pour forcer chaque travail à obtenir un jeton d’étendue de projet, quel que soit ce qui est configuré dans le pipeline. Nous avons également ajouté le paramètre au niveau du projet. À présent, ce paramètre est automatiquement activé pour chaque nouveau projet et collection que vous créez.
Notes
Le paramètre de collection remplace le paramètre de projet.
L’activation de ce paramètre dans des projets et collections existants peut entraîner l’échec de certains pipelines si vos pipelines accèdent à des ressources extérieures au projet d’équipe à l’aide de jetons d’accès. Pour atténuer les défaillances de pipeline, vous pouvez accorder explicitement à Project Build Service Account l’accès à la ressource souhaitée. Nous vous recommandons vivement d’activer ces paramètres de sécurité.
Limiter l’accès à l’étendue des dépôts de service de build
S’appuyant sur l’amélioration de la sécurité du pipeline en limitant l’étendue du jeton d’accès, Azure Pipelines peut désormais limiter l’accès de son dépôt aux dépôts requis pour un pipeline YAML. Cela signifie que si le jeton d’accès des pipelines devait fuir, il ne serait en mesure de voir que le ou les référentiels utilisés dans le pipeline. Auparavant, le jeton d’accès était approprié pour n’importe quel dépôt Azure Repos dans le projet, ou potentiellement pour l’ensemble de la collection.
Cette fonctionnalité est activée par défaut pour les nouveaux projets et collections. Pour les collections existantes, vous devez l’activer dans Paramètres des> collectionsParamètres de pipelines>. Lors de l’utilisation de cette fonctionnalité, tous les dépôts nécessaires à la build (même ceux que vous clonez à l’aide d’un script) doivent être inclus dans les ressources de dépôt du pipeline.
Supprimer certaines autorisations pour le jeton d’accès
Par défaut, nous accordons un certain nombre d’autorisations au jeton d’accès, l’une de ces autorisations étant les builds de file d’attente. Avec cette mise à jour, nous avons supprimé cette autorisation sur le jeton d’accès. Si vos pipelines ont besoin de cette autorisation, vous pouvez l’accorder explicitement au compte de service Project Build ou au comptede service de build de la collection de projets en fonction du jeton que vous utilisez.
Sécurité au niveau du projet pour les connexions de service
Nous avons ajouté la sécurité au niveau du hub pour les connexions de service. Vous pouvez désormais ajouter/supprimer des utilisateurs, attribuer des rôles et gérer l’accès dans un emplacement centralisé pour toutes les connexions de service.
Ciblage des étapes et isolation des commandes
Azure Pipelines prend en charge l’exécution de travaux dans des conteneurs ou sur l’hôte de l’agent. Auparavant, un travail entier était défini sur l’une de ces deux cibles. À présent, des étapes individuelles (tâches ou scripts) peuvent s’exécuter sur la cible que vous choisissez. Les étapes peuvent également cibler d’autres conteneurs, de sorte qu’un pipeline peut exécuter chaque étape dans un conteneur spécialisé et spécialement conçu.
Les conteneurs peuvent servir de limites d’isolation, empêchant le code d’apporter des modifications inattendues sur l’ordinateur hôte. La façon dont les étapes communiquent avec l’agent et accèdent aux services à partir de l’agent n’est pas affectée par l’isolement des étapes dans un conteneur. Par conséquent, nous introduisons également un mode de restriction de commande que vous pouvez utiliser avec des cibles d’étape. L’activation de cette option restreint les services qu’une étape peut demander à l’agent. Il ne sera plus en mesure d’attacher des journaux, de charger des artefacts et de certaines autres opérations.
Voici un exemple complet montrant les étapes d’exécution sur l’hôte dans un conteneur de travaux et dans un autre conteneur :
resources:
containers:
- container: python
image: python:3.8
- container: node
image: node:13.2
jobs:
- job: example
container: python
steps:
- script: echo Running in the job container
- script: echo Running on the host
target: host
- script: echo Running in another container, in restricted commands mode
target:
container: node
commands: restricted
Variables en lecture seule
Les variables système ont été documentées comme étant immuables, mais dans la pratique, elles peuvent être remplacées par une tâche et les tâches en aval récupèrent la nouvelle valeur. Avec cette mise à jour, nous avons renforcé la sécurité autour des variables de pipeline pour rendre les variables système et de file d’attente en lecture seule. En outre, vous pouvez rendre une variable YAML en lecture seule en la marquant comme suit.
variables:
- name: myVar
value: myValue
readonly: true
Accès en fonction du rôle pour les connexions de service
Nous avons ajouté l’accès en fonction du rôle pour les connexions de service. Auparavant, la sécurité des connexions de service ne pouvait être gérée que par le biais de groupes Azure DevOps prédéfinis tels que les administrateurs de point de terminaison et les créateurs de points de terminaison.
Dans le cadre de ce travail, nous avons introduit les nouveaux rôles lecteur, utilisateur, créateur et administrateur. Vous pouvez définir ces rôles via la page connexions de service de votre projet, qui sont hérités par les connexions individuelles. Dans chaque connexion de service, vous avez la possibilité d’activer ou de désactiver l’héritage et de remplacer les rôles dans l’étendue de la connexion de service.
En savoir plus sur la sécurité des connexions de service ici.
Partage entre projets des connexions de service
Nous avons activé la prise en charge du partage de connexion de service entre les projets. Vous pouvez désormais partager vos connexions de service avec vos projets en toute sécurité.
En savoir plus sur le partage des connexions de service ici.
Traçabilité des pipelines et des ressources ACR
Nous garantissons une traçabilité E2E complète lorsque des pipelines et des ressources de conteneur ACR sont utilisés dans un pipeline. Pour chaque ressource consommée par votre pipeline YAML, vous pouvez effectuer le suivi des commits, des éléments de travail et des artefacts.
Dans l’affichage résumé de l’exécution du pipeline, vous pouvez voir :
Version de ressource qui a déclenché l’exécution. À présent, votre pipeline peut être déclenché à l’issue d’une autre exécution de pipeline Azure ou lorsqu’une image conteneur est envoyée à ACR.
Commits consommés par le pipeline. Vous pouvez également trouver la répartition des validations pour chaque ressource consommée par le pipeline.

Éléments de travail associés à chaque ressource consommée par le pipeline.
Artefacts disponibles pour être utilisés par l’exécution.

Dans la vue déploiements de l’environnement, vous pouvez voir les validations et les éléments de travail pour chaque ressource déployée dans l’environnement.
Prise en charge des pièces jointes de test volumineuses
La tâche publier les résultats des tests dans Azure Pipelines vous permet de publier les résultats des tests lorsque des tests sont exécutés pour fournir une expérience de création de rapports et d’analytique de test complète. Jusqu’à présent, il y avait une limite de 100 Mo pour les pièces jointes de test à la fois pour la série de tests et les résultats des tests. Cela a limité le chargement de fichiers volumineux comme les vidages sur incident ou les vidéos. Avec cette mise à jour, nous avons ajouté la prise en charge des pièces jointes de test volumineuses, ce qui vous permet d’avoir toutes les données disponibles pour résoudre les échecs de vos tests.
Vous pouvez voir la tâche VSTest ou la tâche Publier les résultats des tests renvoyant une erreur 403 ou 407 dans les journaux. Si vous utilisez des builds auto-hébergées ou des agents de mise en production derrière un pare-feu qui filtre les demandes sortantes, vous devez apporter des modifications à la configuration pour pouvoir utiliser cette fonctionnalité.
Pour résoudre ce problème, nous vous recommandons de mettre à jour le pare-feu pour les demandes sortantes vers https://*.vstmrblob.vsassets.io. Vous trouverez des informations sur la résolution des problèmes dans la documentation ici.
Notes
Cela n’est nécessaire que si vous utilisez des agents Azure Pipelines auto-hébergés et que vous êtes derrière un pare-feu qui filtre le trafic sortant. Si vous utilisez des agents hébergés par Microsoft dans le cloud ou qui ne filtrent pas le trafic réseau sortant, vous n’avez pas besoin d’effectuer d’action.
Afficher les informations de pool correctes sur chaque travail
Auparavant, lorsque vous utilisiez une matrice pour développer des travaux ou une variable pour identifier un pool, nous avons parfois résolu des informations incorrectes sur le pool dans les pages des journaux. Ces problèmes ont été résolus.
Déclencheurs CI pour les nouvelles branches
Il s’agit d’une longue demande de ne pas déclencher de builds CI lorsqu’une nouvelle branche est créée et lorsque cette branche n’a pas de modifications. Penchez-vous sur les exemples suivants :
- Vous utilisez l’interface web pour créer une branche basée sur une branche existante. Cela déclencherait immédiatement une nouvelle build CI si votre filtre de branche correspond au nom de la nouvelle branche. Cela est indésirable, car le contenu de la nouvelle branche est le même par rapport à la branche existante.
- Vous disposez d’un dépôt avec deux dossiers : application et documents. Vous configurez un filtre de chemin d’accès pour que CI corresponde à « app ». En d’autres termes, vous ne souhaitez pas créer de build si une modification a été envoyée à la documentation. Vous créez une branche localement, apportez des modifications à la documentation, puis envoyez cette branche au serveur. Nous avons l’habitude de déclencher une nouvelle build CI. Cela est indésirable, car vous avez explicitement demandé de ne pas rechercher de modifications dans le dossier docs. Toutefois, en raison de la façon dont nous avons géré un événement de nouvelle branche, il semblerait qu’une modification ait également été apportée au dossier d’application.
À présent, nous avons une meilleure façon de gérer l’intégration continue pour les nouvelles branches afin de résoudre ces problèmes. Lorsque vous publiez une nouvelle branche, nous recherchons explicitement les nouveaux commits dans cette branche et case activée s’ils correspondent aux filtres de chemin d’accès.
Les travaux peuvent accéder aux variables de sortie des étapes précédentes
Les variables de sortie peuvent désormais être utilisées sur plusieurs étapes dans un pipeline YAML. Cela vous permet de passer d’une étape à l’autre des informations utiles, telles qu’une décision go/no go ou l’ID d’une sortie générée. Le résultat (status) d’une étape précédente et de ses travaux est également disponible.
Les variables de sortie sont toujours produites par des étapes à l’intérieur des travaux. Au lieu de faire référence à dependencies.jobName.outputs['stepName.variableName'], les phases font référence à stageDependencies.stageName.jobName.outputs['stepName.variableName'].
Notes
Par défaut, chaque index d’un pipeline dépend de celui qui se trouve juste avant lui dans le fichier YAML. Par conséquent, chaque index peut utiliser des variables de sortie issues de l’index précédent. Vous pouvez modifier la graphe des dépendances, ce qui modifie également les variables de sortie disponibles. Par instance, si l’étape 3 a besoin d’une variable de l’étape 1, elle doit déclarer une dépendance explicite sur l’étape 1.
Désactiver les mises à niveau automatiques des agents au niveau du pool
Actuellement, les agents de pipelines sont automatiquement mis à jour vers la dernière version si nécessaire. Cela se produit généralement lorsqu’il existe une nouvelle fonctionnalité ou tâche qui nécessite une version plus récente de l’agent pour fonctionner correctement. Avec cette mise à jour, nous ajoutons la possibilité de désactiver les mises à niveau automatiques au niveau du pool. Dans ce mode, si aucun agent de la version correcte n’est connecté au pool, les pipelines échouent avec un message d’erreur clair au lieu de demander la mise à jour des agents. Cette fonctionnalité est principalement intéressante pour les clients avec des pools auto-hébergés et des exigences de contrôle des modifications très strictes. Les mises à jour automatiques sont activées par défaut, et nous ne recommandons pas à la plupart des clients de les désactiver.
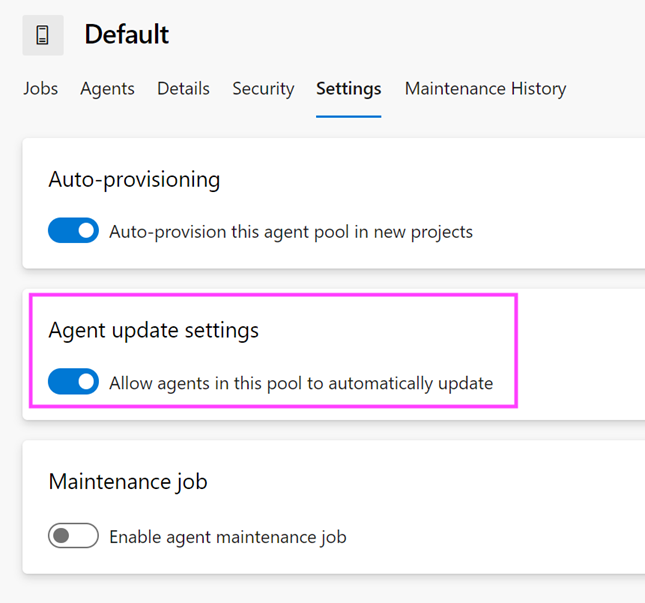
Agent diagnostics
Nous avons ajouté diagnostics pour de nombreux problèmes courants liés à l’agent, tels que de nombreux problèmes de mise en réseau et les causes courantes des échecs de mise à niveau. Pour commencer à utiliser diagnostics, utilisez run.sh --diagnostics ou run.cmd --diagnostics sur Windows.
Hooks de service pour les pipelines YAML
L’intégration de services avec des pipelines YAML s’est simplifiée. À l’aide des événements de hooks de service pour les pipelines YAML, vous pouvez désormais piloter des activités dans des applications ou des services personnalisés en fonction de la progression des exécutions du pipeline. Par exemple, vous pouvez créer un ticket de support technique lorsqu’une approbation est requise, lancer un workflow de supervision une fois qu’une étape est terminée ou envoyer une notification Push aux appareils mobiles de votre équipe en cas d’échec d’une étape.
Le filtrage sur le nom du pipeline et le nom de l’étape est pris en charge pour tous les événements. Les événements d’approbation peuvent également être filtrés pour des environnements spécifiques. De même, les événements de changement d’état peuvent être filtrés en fonction du nouvel état de l’exécution du pipeline ou de la phase.
Optimisation de l’intégration
Optimizely est une plateforme puissante de test A/B et d’indicateur de fonctionnalités pour les équipes de produits. L’intégration d’Azure Pipelines à la plateforme d’expérimentation Optimizely permet aux équipes produit de tester, d’apprendre et de déployer à un rythme accéléré, tout en profitant de tous les avantages DevOps d’Azure Pipelines.
L’extension Optimizely pour Azure DevOps ajoute des étapes d’expérimentation et de déploiement d’indicateur de fonctionnalité aux pipelines de build et de mise en production, afin que vous puissiez itérer, déployer des fonctionnalités et les restaurer en continu à l’aide d’Azure Pipelines.
En savoir plus sur l’extension Azure DevOps Optimizely ici.

Ajouter une version GitHub en tant que source d’artefact
Vous pouvez maintenant lier vos versions GitHub en tant que source d’artefacts dans les pipelines de mise en production Azure DevOps. Cela vous permettra de consommer la version GitHub dans le cadre de vos déploiements.
Lorsque vous cliquez sur Ajouter un artefact dans la définition du pipeline de mise en production, vous trouverez le nouveau type de source De mise en production GitHub . Vous pouvez fournir la connexion de service et le dépôt GitHub pour utiliser la version GitHub. Vous pouvez également choisir une version par défaut pour la version gitHub à utiliser comme dernière version de balise spécifique ou sélectionner au moment de la création de la version. Une fois qu’une version de GitHub est liée, elle est automatiquement téléchargée et mise à disposition dans vos travaux de mise en production.

Intégration de Terraform à Azure Pipelines
Terraform est un outil open source permettant de développer, de modifier et de gérer les versions de l’infrastructure en toute sécurité et efficacement. Terraform codifie les API dans des fichiers de configuration déclaratifs, ce qui vous permet de définir et de provisionner une infrastructure à l’aide d’un langage de configuration de haut niveau. Vous pouvez utiliser l’extension Terraform pour créer des ressources sur tous les principaux fournisseurs d’infrastructure : Azure, Amazon Web Services (AWS) et Google Cloud Platform (GCP).
Pour en savoir plus sur l’extension Terraform, consultez la documentation ici.
Intégration à Google Analytics
L’infrastructure d’expériences Google Analytics vous permet de tester presque n’importe quelle modification ou variation d’un site web ou d’une application pour mesurer son impact sur un objectif spécifique. Par exemple, vous pouvez avoir des activités que vous souhaitez que vos utilisateurs effectuent (par exemple, effectuer un achat, s’inscrire à un bulletin d’information) et/ou des métriques que vous souhaitez améliorer (par exemple, revenus, durée de session, taux de rebond). Ces activités vous permettent d’identifier les modifications qui méritent d’être implémentées en fonction de leur impact direct sur les performances de votre fonctionnalité.
L’extension d’expériences Google Analytics pour Azure DevOps ajoute des étapes d’expérimentation aux pipelines de génération et de mise en production, ce qui vous permet d’itérer, d’apprendre et de déployer à un rythme accéléré en gérant les expériences de manière continue tout en bénéficiant de tous les avantages DevOps d’Azure Pipelines.
Vous pouvez télécharger l’extension des expériences Google Analytics à partir de la Place de marché.
Mise à jour de l’intégration de ServiceNow à Azure Pipelines
L’application Azure Pipelines pour ServiceNow permet d’intégrer Azure Pipelines et ServiceNow Change Management. Avec cette mise à jour, vous pouvez intégrer la version new-yorkaise de ServiceNow. L’authentification entre les deux services peut maintenant être effectuée à l’aide d’OAuth et de l’authentification de base. En outre, vous pouvez maintenant configurer des critères de réussite avancés afin de pouvoir utiliser n’importe quelle propriété de modification pour décider du résultat de la porte.
Create Azure Pipelines à partir de VSCode
Nous avons ajouté une nouvelle fonctionnalité à l’extension Azure Pipelines pour VSCode. Maintenant, vous pouvez créer Azure Pipelines directement à partir de VSCode sans quitter l’IDE.
Gestion et résolution des bogues flaky
Nous avons introduit une gestion des tests flaky pour prendre en charge le cycle de vie de bout en bout avec la détection, la création de rapports et la résolution. Pour l’améliorer davantage, nous ajoutons la gestion et la résolution des bogues de test flaky.
Lors de l’examen du test flaky, vous pouvez créer un bogue à l’aide de l’action Bogue qui peut ensuite être attribuée à un développeur pour examiner plus en détail la cause racine du test d’écaillement. Le rapport de bogue inclut des informations sur le pipeline comme le message d’erreur, le suivi de la pile et d’autres informations associées au test.
Lorsqu’un rapport de bogue est résolu ou fermé, nous désélectionnons automatiquement le test comme étant peu flatky.
Définir l’échec des tâches VSTest si un nombre minimal de tests n’est pas exécuté
La tâche VSTest découvre et exécute des tests à l’aide d’entrées utilisateur (fichiers de test, critères de filtre, etc.) ainsi que d’un adaptateur de test spécifique à l’infrastructure de test utilisée. Les modifications apportées aux entrées utilisateur ou à l’adaptateur de test peuvent entraîner des cas où les tests ne sont pas détectés et où seul un sous-ensemble des tests attendus est exécuté. Cela peut entraîner des situations où les pipelines réussissent parce que les tests sont ignorés plutôt que parce que le code est de qualité suffisamment élevée. Pour éviter cette situation, nous avons ajouté une nouvelle option dans la tâche VSTest qui vous permet de spécifier le nombre minimal de tests à exécuter pour que la tâche réussisse.
L’option VSTest TestResultsDirectory est disponible dans l’interface utilisateur de tâche
La tâche VSTest stocke les résultats des tests et les fichiers associés dans le $(Agent.TempDirectory)\TestResults dossier. Nous avons ajouté une option à l’interface utilisateur de tâche pour vous permettre de configurer un autre dossier pour stocker les résultats des tests. Désormais, toutes les tâches suivantes qui ont besoin des fichiers dans un emplacement particulier peuvent les utiliser.

Prise en charge de Markdown dans les messages d’erreur de test automatisés
Nous avons ajouté la prise en charge markdown aux messages d’erreur pour les tests automatisés. Vous pouvez désormais facilement mettre en forme des messages d’erreur pour la série de tests et les résultats des tests afin d’améliorer la lisibilité et de faciliter l’expérience de résolution des échecs de test dans Azure Pipelines. La syntaxe markdown prise en charge est disponible ici.
Utiliser des décorateurs de pipeline pour injecter automatiquement des étapes dans un travail de déploiement
Vous pouvez maintenant ajouter des décorateurs de pipeline aux travaux de déploiement. Vous pouvez avoir n’importe quelle étape personnalisée (par exemple, le scanneur de vulnérabilités) injectée automatiquement à chaque exécution de hook de cycle de vie de chaque travail de déploiement. Étant donné que les décorateurs de pipeline peuvent être appliqués à tous les pipelines d’une collection, ils peuvent être exploités dans le cadre de l’application de pratiques de déploiement sécurisées.
En outre, les travaux de déploiement peuvent être exécutés en tant que travail de conteneur avec un side-car de services s’il est défini.
Test Plans
Page Nouveau plan de test
Une nouvelle page Test Plans (Test Plans *) est disponible pour toutes les collections Azure DevOps. La nouvelle page fournit des vues simplifiées pour vous aider à vous concentrer sur la tâche à accomplir : planification des tests, création ou exécution. Il est également sans encombrement et cohérent avec le reste de l’offre Azure DevOps.

Aidez-moi à comprendre la nouvelle page
La nouvelle page Test Plans a un total de 6 sections dont les 4 premières sont nouvelles, tandis que les sections Graphiques & extensibilité sont les fonctionnalités existantes.
- En-tête de plan de test : utilisez-le pour localiser, favori, modifier, copier ou cloner un plan de test.
- Arborescence des suites de test : utilisez-la pour ajouter, gérer, exporter ou commander des suites de test. Tirez parti de cela pour également attribuer des configurations et effectuer des tests d’acceptation par l’utilisateur.
- Définir l’onglet : collez, ajoutez et gérez des cas de test dans une suite de tests de votre choix via cet onglet.
- Onglet Exécuter : attribuez et exécutez des tests via cet onglet ou recherchez un résultat de test à explorer.
- Onglet Graphique : suivez l’exécution des tests et status via des graphiques qui peuvent également être épinglés aux tableaux de bord.
- Extensibilité : prend en charge les points d’extensibilité actuels au sein du produit.
Prenons une vue d’ensemble de ces nouvelles sections ci-dessous.
1. En-tête du plan de test

Tâches
L’en-tête Plan de test vous permet d’effectuer les tâches suivantes :
- Marquer un plan de test comme favori
- Annuler le marquage d’un plan de test favori
- Naviguer facilement parmi vos plans de test favoris
- Afficher le chemin d’itération du plan de test, qui indique clairement si le plan de test est Actif ou Passé
- Afficher le résumé rapide du rapport De progression des tests avec un lien pour accéder au rapport
- Revenez à la page All/Mine Test Plans
Options de menu contextuel
Le menu contextuel de l’en-tête Plan de test fournit les options suivantes :
- Copier le plan de test : il s’agit d’une nouvelle option qui vous permet de copier rapidement le plan de test actuel. Vous trouverez plus de détails ci-dessous.
- Modifier le plan de test : cette option vous permet de modifier le formulaire d’élément de travail Plan de test pour gérer les champs d’élément de travail.
- Paramètres du plan de test : cette option vous permet de configurer les paramètres de la série de tests (pour associer des pipelines de build ou de mise en production) et les paramètres résultats des tests
Plan de test de copie (nouvelle fonctionnalité)
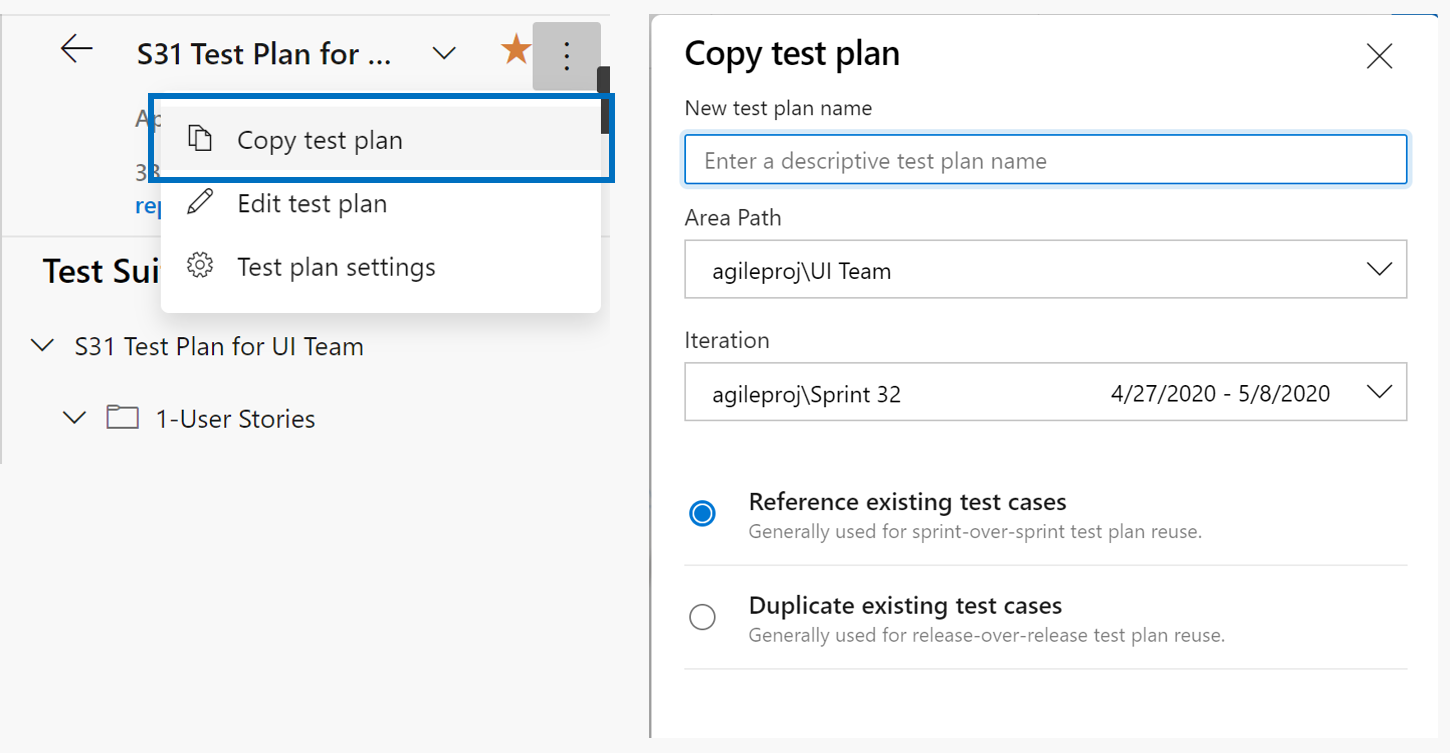
Nous vous recommandons de créer un plan de test par sprint/version. En règle générale, le plan de test du cycle précédent peut être copié et, avec peu de modifications, le plan de test copié est prêt pour le nouveau cycle. Pour faciliter ce processus, nous avons activé une fonctionnalité « Copier le plan de test » sur la nouvelle page. En l’exploitant, vous pouvez copier ou cloner des plans de test. Son API REST de sauvegarde est abordée ici et l’API vous permet également de copier/cloner un plan de test sur plusieurs projets.
Pour plus d’instructions sur l’utilisation de Test Plans, reportez-vous ici.
2. Arborescence des suites de test
Tâches
L’en-tête test suite vous permet d’effectuer les tâches suivantes :
- Développer/réduire : ces options de barre d’outils vous permettent de développer ou de réduire l’arborescence de hiérarchie de la suite.
- Afficher les points de test des suites enfants : cette option de barre d’outils n’est visible que lorsque vous êtes sous l’onglet « Exécuter ». Cela vous permet d’afficher tous les points de test de la suite donnée et de ses enfants dans une seule vue pour faciliter la gestion des points de test sans avoir à accéder à des suites individuelles une par une.
- Suites de commande : vous pouvez faire glisser/déplacer des suites pour réorganiser la hiérarchie des suites ou les déplacer d’une hiérarchie de suite à une autre dans le plan de test.
Options de menu contextuel
Le menu contextuel de l’arborescence Suites de test fournit les options suivantes :
- Create nouvelles suites : vous pouvez créer 3 types de suites différents comme suit :
- Utilisez une suite statique ou une suite de dossiers pour organiser vos tests.
- Utilisez la suite basée sur les exigences pour établir un lien direct vers les exigences/les témoignages utilisateur pour une traçabilité transparente.
- Utilisez basé sur une requête pour organiser dynamiquement les cas de test qui répondent à des critères de requête.
- Attribuer des configurations : vous pouvez attribuer des configurations pour la suite (par exemple, Chrome, Firefox, EdgeChromium) et celles-ci s’appliquent ensuite à tous les cas de test existants ou nouveaux cas de test que vous ajoutez ultérieurement à cette suite.
- Exporter au format pdf/e-mail : exportez les propriétés du plan de test, les propriétés de la suite de tests, ainsi que les détails des cas de test et des points de test sous la forme « email » ou « print to pdf ».
- Ouvrir l’élément de travail de la suite de tests : cette option vous permet de modifier le formulaire d’élément de travail de la suite de tests pour gérer les champs d’élément de travail.
- Affecter des testeurs pour exécuter tous les tests : cette option est très utile pour les scénarios de test d’acceptation des utilisateurs (UAT) où le même test doit être exécuté/exécuté par plusieurs testeurs, généralement appartenant à différents services.
- Renommer/supprimer : ces options vous permettent de gérer le nom de la suite ou de supprimer la suite et son contenu du plan de test.
3. Définir l’onglet
L’onglet Définir vous permet de rassembler, d’ajouter et de gérer des cas de test pour une suite de tests. Tandis que l’onglet d’exécution sert à affecter des points de test et à les exécuter.
L’onglet Définir et certaines opérations sont disponibles uniquement pour les utilisateurs disposant d’un niveau d’accès De base + Test Plans ou équivalent. Tout le reste doit pouvoir être exercé par un utilisateur avec le niveau d’accès « De base ».
Tâches
L’onglet Définir vous permet d’effectuer les tâches suivantes :
- Ajouter un nouveau cas de test à l’aide du formulaire d’élément de travail : cette option vous permet de créer un cas de test à l’aide du formulaire d’élément de travail. Le cas de test créé sera automatiquement ajouté à la suite.
- Ajouter un nouveau cas de test à l’aide de la grille : cette option vous permet de créer un ou plusieurs cas de test à l’aide de la vue grille des cas de test. Les cas de test créés sont automatiquement ajoutés à la suite.
- Ajouter des cas de test existants à l’aide d’une requête : cette option vous permet d’ajouter des cas de test existants à la suite en spécifiant une requête.
- Classer les cas de test par glisser-déplacer : vous pouvez réorganiser les cas de test en faisant glisser/déposer un ou plusieurs cas de test au sein d’une suite donnée. L’ordre des cas de test s’applique uniquement aux cas de test manuels et non aux tests automatisés.
- Déplacer des cas de test d’une suite vers une autre : à l’aide du glisser-déplacer, vous pouvez déplacer des cas de test d’une suite de tests vers une autre.
- Afficher la grille : vous pouvez utiliser le mode grille pour afficher/modifier les cas de test, ainsi que les étapes de test.
- Affichage plein écran : vous pouvez afficher le contenu de l’onglet Définir entier en mode plein écran à l’aide de cette option.
- Filtrage : à l’aide de la barre de filtre, vous pouvez filtrer la liste des cas de test à l’aide des champs « titre du cas de test », « affecté à » et « état ». Vous pouvez également trier la liste en cliquant sur les en-têtes de colonne.
- Options de colonne : vous pouvez gérer la liste des colonnes visibles sous l’onglet Définir à l’aide de « Options de colonne ». La liste des colonnes disponibles pour la sélection est principalement les champs du formulaire d’élément de travail de cas de test.
Options du menu contextuel
Le menu contextuel du nœud Cas de test sous l’onglet Définir fournit les options suivantes :
- Ouvrir/modifier le formulaire d’élément de travail de cas de test : cette option vous permet de modifier un cas de test à l’aide du formulaire d’élément de travail dans lequel vous modifiez les champs d’élément de travail, y compris les étapes de test.
- Modifier les cas de test : cette option vous permet de modifier en bloc les champs d’élément de travail de cas de test. Toutefois, vous ne pouvez pas utiliser cette option pour modifier en bloc des étapes de test.
- Modifier les cas de test dans la grille : cette option vous permet de modifier en bloc les cas de test sélectionnés, y compris les étapes de test à l’aide de la vue grille.
- Attribuer des configurations : cette option vous permet de remplacer les configurations au niveau de la suite par des configurations au niveau du cas de test.
- Supprimer les cas de test : cette option vous permet de supprimer les cas de test de la suite donnée. Cela ne modifie pas l’élément de travail du cas de test sous-jacent.
- Create une copie/clone de cas de test : cette option vous permet de créer une copie/clone des cas de test sélectionnés. Vous trouverez plus de détails à la suite.
- Afficher les éléments liés : cette option vous permet d’examiner les éléments liés pour un cas de test donné. Vous trouverez plus de détails à la suite.
Copier/cloner des cas de test (nouvelle fonctionnalité)

Pour les scénarios où vous souhaitez copier/cloner un cas de test, vous pouvez utiliser l’option « Copier le cas de test ». Vous pouvez spécifier le projet de destination, le plan de test de destination et la suite de tests de destination dans lesquels créer le cas de test copié/cloné. En outre, vous pouvez également spécifier si vous souhaitez inclure des liens/pièces jointes existants à transmettre dans la copie cloné.
Afficher les éléments liés (nouvelle fonctionnalité)
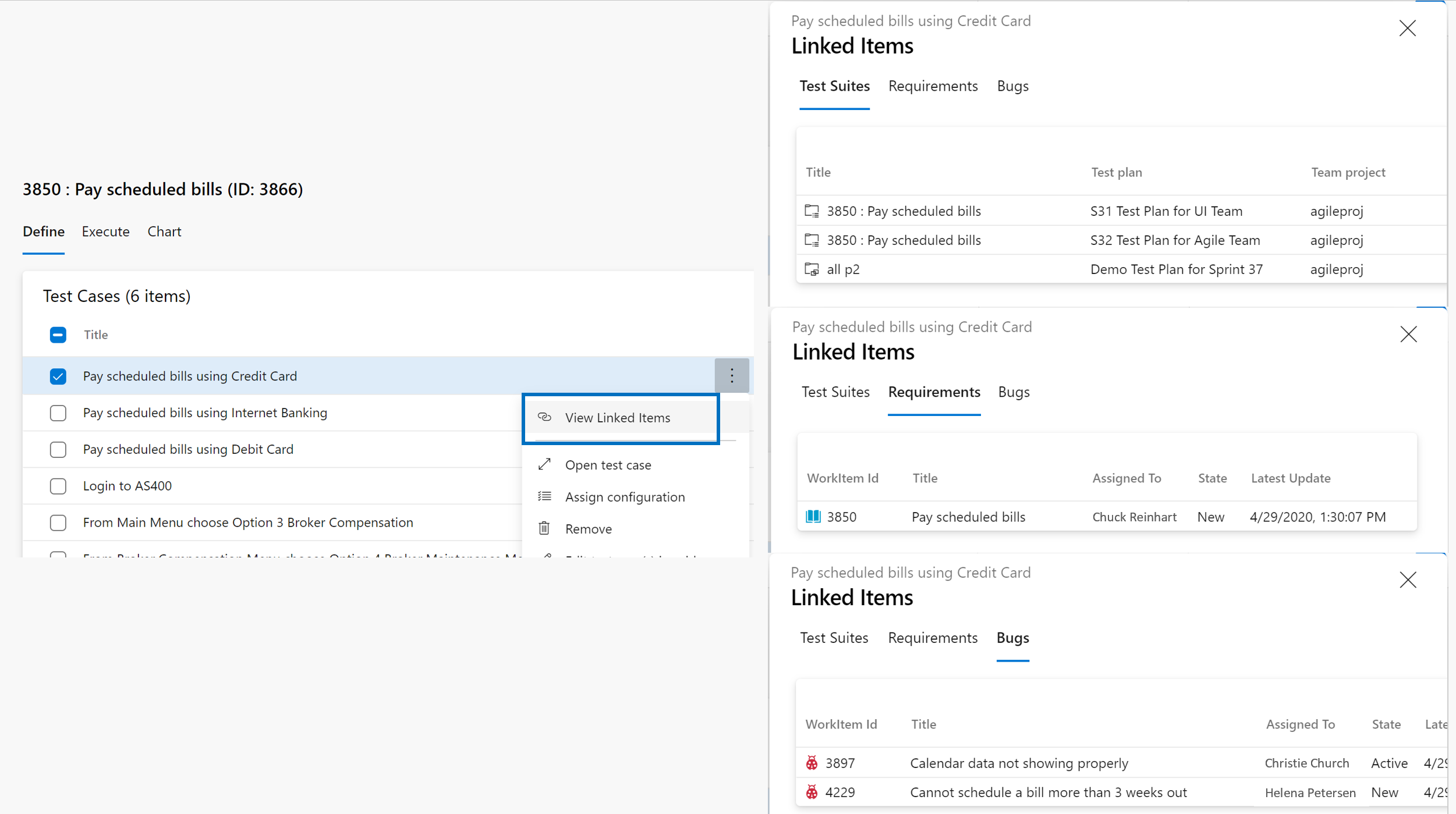
La traçabilité entre les artefacts, les exigences et les bogues de test est une proposition de valeur critique du produit Test Plans. À l’aide de l’option « Afficher les éléments liés », vous pouvez facilement examiner toutes les exigences liées auxquelles ce cas de test est lié, toutes les suites de tests/plans de test où ce cas de test a été utilisé et tous les bogues qui ont été enregistrés dans le cadre de l’exécution du test.
4. Onglet Exécuter
L’onglet Définir vous permet de rassembler, d’ajouter et de gérer des cas de test pour une suite de tests. Tandis que l’onglet d’exécution sert à affecter des points de test et à les exécuter.
Qu’est-ce qu’un point de test ? Les cas de test en eux-mêmes ne sont pas exécutables. Lorsque vous ajoutez un cas de test à une suite de tests, le ou les points de test sont générés. Un point de test est une combinaison unique de cas de test, de suite de tests, de configuration et de testeur. Exemple : si vous avez un cas de test comme « Fonctionnalité de connexion de test » et que vous y ajoutez 2 configurations en tant que Edge et Chrome, cela entraîne 2 points de test. Ces points de test peuvent maintenant être exécutés. Lors de l’exécution, les résultats des tests sont générés. Dans la vue des résultats des tests (historique des exécutions), vous pouvez voir toutes les exécutions d’un point de test. La dernière exécution du point de test est celle que vous voyez sous l’onglet Exécuter.
Par conséquent, les cas de test sont des entités réutilisables. En les incluant dans un plan de test ou une suite, des points de test sont générés. En exécutant des points de test, vous déterminez la qualité du produit ou du service en cours de développement.
L’un des principaux avantages de la nouvelle page est pour les utilisateurs qui effectuent principalement l’exécution/le suivi des tests (ne doivent avoir que le niveau d’accès « De base »), ils ne sont pas submergés par la complexité de la gestion de la suite (l’onglet Définir est masqué pour ces utilisateurs).
L’onglet Définir et certaines opérations sont disponibles uniquement pour les utilisateurs disposant d’un niveau d’accès De base + Test Plans ou équivalent. Tout le reste, y compris l’onglet « Exécuter » doit être exercé par un utilisateur avec le niveau d’accès « De base ».
Tâches
L’onglet Exécuter vous permet d’effectuer les tâches suivantes :
- Points de test de marquage en bloc : cette option vous permet de marquer rapidement le résultat des points de test : réussi, échoué, bloqué ou non applicable, sans avoir à exécuter le cas de test via l’exécuteur de test. Le résultat peut être marqué pour un ou plusieurs points de test en une seule fois.
- Exécuter des points de test : cette option vous permet d’exécuter les cas de test en parcourant individuellement chaque étape de test et en marquant leur réussite/échec à l’aide d’un exécuteur de tests. Selon l’application que vous testez, vous pouvez utiliser « Web Runner » pour tester une « application web » ou l'« exécuteur de bureau » pour tester des applications de bureau et/ou web. Vous pouvez également appeler « Exécuter avec des options » pour spécifier une build sur laquelle vous souhaitez effectuer le test.
- Options de colonne : vous pouvez gérer la liste des colonnes visibles sous l’onglet Exécuter à l’aide de « Options de colonne ». La liste des colonnes disponibles pour la sélection est associée à des points de test, tels que Exécuter par, Tester affecté, Configuration, etc.
- Affichage plein écran : vous pouvez afficher le contenu de l’onglet Exécuter entier en mode plein écran à l’aide de cette option.
- Filtrage : à l’aide de la barre de filtre, vous pouvez filtrer la liste des points de test à l’aide des champs « titre du cas de test », « affecté à », « état », « résultat du test », « Testeur » et « Configuration ». Vous pouvez également trier la liste en cliquant sur les en-têtes de colonne.
Options du menu contextuel
Le menu contextuel du nœud Point de test sous l’onglet Exécuter fournit les options suivantes :
- Marquer le résultat du test : comme ci-dessus, vous permet de marquer rapidement le résultat des points de test : réussite, échec, blocage ou non applicable.
- Exécuter des points de test : identique à ce qui précède, vous permet d’exécuter les cas de test via l’exécuteur de test.
- Rétablir le test sur actif : cette option vous permet de réinitialiser le résultat du test sur actif, ignorant ainsi le dernier résultat du point de test.
- Ouvrir/modifier le formulaire d’élément de travail de cas de test : cette option vous permet de modifier un cas de test à l’aide du formulaire d’élément de travail dans lequel vous modifiez les champs d’élément de travail, y compris les étapes de test.
- Attribuer un testeur : cette option vous permet d’affecter les points de test aux testeurs pour l’exécution des tests.
- Afficher le résultat du test : cette option vous permet d’afficher les derniers détails des résultats du test, y compris le résultat de chaque étape de test, les commentaires ajoutés ou les bogues enregistrés.
- Afficher l’historique d’exécution : cette option vous permet d’afficher l’historique complet des exécutions pour le point de test sélectionné. Il ouvre une nouvelle page dans laquelle vous pouvez ajuster les filtres pour afficher l’historique d’exécution non seulement du point de test sélectionné, mais également pour l’ensemble du cas de test.
rapport d’avancement Test Plans
Ce rapport prête à l’emploi vous permet de suivre l’exécution et la status d’un ou plusieurs Test Plans dans un projet. Consultez Test Plans > rapport d’avancement* pour commencer à utiliser le rapport.
Les trois sections du rapport sont les suivantes :
- Résumé : affiche une vue consolidée pour les plans de test sélectionnés.
- Tendance de résultat : affiche une instantané quotidienne pour vous donner une exécution et status courbe de tendance. Il peut afficher des données pendant 14 jours (valeur par défaut), 30 jours ou une plage personnalisée.
- Détails : cette section vous permet d’explorer chaque plan de test et vous fournit des analyses importantes pour chaque suite de tests.

Artifacts
Notes
Azure DevOps Server 2020 n’importe pas les flux qui se trouvent dans la corbeille lors de l’importation de données. Si vous souhaitez importer des flux qui se trouvent dans la corbeille, restaurez-les à partir de la corbeille avant de commencer l’importation des données.
Expressions de licence et licences incorporées
Vous pouvez maintenant voir les détails des informations de licence pour les packages NuGet stockés dans Azure Artifacts lors de la navigation dans les packages dans Visual Studio. Cela s’applique aux licences représentées à l’aide d’expressions de licence ou de licences incorporées. Vous pouvez maintenant voir un lien vers les informations de licence dans la page des détails du package Visual Studio (flèche rouge dans l’image ci-dessous).
En cliquant sur le lien, vous accédez à une page web où vous pouvez afficher les détails de la licence. Cette expérience est la même pour les expressions de licence et les licences incorporées. Vous pouvez donc voir les détails de licence pour les packages stockés dans Azure Artifacts dans un emplacement unique (pour les packages qui spécifient des informations de licence et sont pris en charge par Visual Studio).
Tâches d’authentification légères
Vous pouvez maintenant vous authentifier auprès des gestionnaires de packages populaires d’Azure Pipelines à l’aide de tâches d’authentification légères. Cela inclut NuGet, npm, PIP, Twine et Maven. Auparavant, vous pouviez vous authentifier auprès de ces gestionnaires de packages à l’aide de tâches qui fournissaient une grande quantité de fonctionnalités, notamment la possibilité de publier et de télécharger des packages. Toutefois, cela nécessite l’utilisation de ces tâches pour toutes les activités qui ont interagi avec les gestionnaires de package. Si vous aviez vos propres scripts à exécuter pour effectuer des tâches telles que la publication ou le téléchargement de packages, vous ne pourrez pas les utiliser dans votre pipeline. À présent, vous pouvez utiliser des scripts de votre propre conception dans votre pipeline YAML et effectuer l’authentification avec ces nouvelles tâches légères. Exemple utilisant npm :

L’utilisation des commandes « ci » et « publish » dans cette illustration est arbitraire. Vous pouvez utiliser toutes les commandes prises en charge par Azure Pipelines YAML. Cela vous permet d’avoir un contrôle total de l’appel de commandes et facilite l’utilisation des scripts partagés dans la configuration de votre pipeline. Pour plus d’informations, consultez la documentation sur les tâches d’authentification NuGet, npm, PIP, Twine et Maven .
Améliorations apportées au temps de chargement de la page de flux
Nous sommes ravis d’annoncer que nous avons amélioré le temps de chargement de la page de flux. En moyenne, les temps de chargement des pages de flux ont diminué de 10 %. Les flux les plus importants ont connu la plus grande amélioration, le temps de chargement de la page de flux au 99e centile (temps de chargement dans les 99 % les plus élevés de tous les flux) a diminué de 75 %.
Partager vos packages publiquement avec des flux publics
Vous pouvez maintenant créer et stocker vos packages dans des flux publics. Les packages stockés dans des flux publics sont disponibles pour tout le monde sur Internet sans authentification, qu’ils soient ou non dans votre collection, ou même connectés à une collection Azure DevOps. Apprenez-en davantage sur les flux publics dans notre documentation sur les flux ou passez directement à notre tutoriel pour partager des packages publiquement.

Configurer des amonts dans différents regroupements au sein d’un locataire AAD
Vous pouvez maintenant ajouter un flux dans une autre collection associée à votre locataire Azure Active Directory (AAD) en tant que source amont à votre flux Artifacts. Votre flux peut rechercher et utiliser des packages à partir des flux configurés en tant que sources amont, ce qui permet de partager facilement les packages entre les collections associées à votre locataire AAD. Découvrez comment le configurer dans la documentation.
Utiliser le fournisseur d’informations d’identification Python pour authentifier pip et twine avec des flux Azure Artifacts
Vous pouvez maintenant installer et utiliser le fournisseur d’informations d’identification Python (artifacts-keyring) pour configurer automatiquement l’authentification afin de publier ou d’utiliser des packages Python vers ou à partir d’un flux Azure Artifacts. Avec le fournisseur d’informations d’identification, vous n’avez pas besoin de configurer des fichiers de configuration (pip.ini/pip.conf/.pypirc), vous serez simplement redirigé vers un flux d’authentification dans votre navigateur web lors de l’appel de pip ou twine pour la première fois. Pour plus d’informations, consultez la documentation.
Flux Azure Artifacts dans le Gestionnaire de package Visual Studio
Nous affichons maintenant des icônes de package, des descriptions et des auteurs dans le Gestionnaire de package NuGet Visual Studio pour les packages pris en charge à partir de flux Azure Artifacts. Auparavant, la plupart de ces métadonnées n’étaient pas fournies à VS.
Mise à jour de l’expérience se connecter au flux
La boîte de dialogue Se connecter au flux est l’entrée d’accès à l’utilisation d’Azure Artifacts ; il contient des informations sur la configuration des clients et des référentiels pour envoyer (push) et extraire des packages à partir de flux dans Azure DevOps. Nous avons mis à jour la boîte de dialogue pour ajouter des informations détaillées sur la configuration et développé les outils pour 2000.
Les flux publics sont désormais en disponibilité générale avec amont support
La préversion publique des flux publics a fait l’objet d’une grande adoption et de commentaires. Dans cette version, nous avons étendu des fonctionnalités supplémentaires à la disponibilité générale. À présent, vous pouvez définir un flux public en tant que source amont à partir d’un flux privé. Vous pouvez simplifier vos fichiers de configuration en étant en mesure d’amont à la fois vers et depuis des flux privés et étendus au projet.
Create des flux étendus au projet à partir du portail
Lorsque nous avons publié des flux publics, nous avons également publié des flux étendus au projet. Jusqu’à présent, les flux étendus au projet pouvaient être créés via des API REST ou en créant un flux public, puis en activant le projet comme privé. À présent, vous pouvez créer des flux délimités au projet directement dans le portail à partir de n’importe quel projet si vous disposez des autorisations requises. Vous pouvez également voir quels flux sont projet et ceux qui sont délimités à la collection dans le sélecteur de flux.
Améliorations des performances de npm
Nous avons apporté des modifications à notre conception de base pour améliorer la façon dont nous stockons et livrons les packages npm dans les flux Azure Artifacts. Cela nous a permis de réduire jusqu’à 10 fois la latence pour certaines des API les plus utilisées pour npm.
Améliorations de l’accessibilité
Nous avons déployé des correctifs pour résoudre les problèmes d’accessibilité sur notre page de flux. Les correctifs sont les suivants :
- expérience de flux Create
- Expérience des paramètres de flux globaux
- Se connecter à l’expérience de flux
Wiki
Édition enrichie pour les pages wiki de code
Auparavant, lors de la modification d’une page wiki de code, vous étiez redirigé vers le hub Azure Repos pour modification. Actuellement, le hub référentiel n’est pas optimisé pour la modification markdown.
Vous pouvez maintenant modifier une page wiki de codes dans l’éditeur côte à côte à l’intérieur du wiki. Cela vous permet d’utiliser la barre d’outils markdown enrichie pour créer votre contenu, ce qui rend l’expérience d’édition identique à celle du wiki du projet. Vous pouvez toujours choisir de modifier dans les dépôts en sélectionnant l’option Modifier dans les dépôts dans le menu contextuel.

Create et incorporer des éléments de travail à partir d’une page wiki
À mesure que nous avons écouté vos commentaires, nous avons entendu que vous utilisiez wiki pour capturer des documents de brainstorming, des documents de planification, des idées sur des fonctionnalités, des documents de spécifications, des minutes de réunion. Vous pouvez désormais facilement créer des fonctionnalités et des récits utilisateur directement à partir d’un document de planification sans quitter la page wiki.
Pour créer un élément de travail, sélectionnez le texte dans la page wiki dans laquelle vous souhaitez incorporer l’élément de travail, puis sélectionnez Nouvel élément de travail. Cela vous fait gagner du temps, car vous n’avez pas à créer d’abord l’élément de travail, à accéder à modifier, puis à trouver l’élément de travail à incorporer. Cela réduit également le changement de contexte, car vous ne sortez pas de l’étendue wiki.

Pour en savoir plus sur la création et l’incorporation d’un élément de travail à partir du wiki, consultez notre documentation ici.
Commentaires dans les pages wiki
Auparavant, vous ne disposiez pas d’un moyen d’interagir avec d’autres utilisateurs du wiki à l’intérieur du wiki. Cela a rendu la collaboration sur le contenu et l’obtention de questions un défi, car les conversations ont dû se produire par courrier ou par des canaux de conversation. Avec les commentaires, vous pouvez désormais collaborer avec d’autres personnes directement dans le wiki. Vous pouvez tirer parti des @mention fonctionnalités des utilisateurs dans les commentaires pour attirer l’attention d’autres membres de l’équipe. Cette fonctionnalité a été hiérarchisée en fonction de ce ticket de suggestion. Pour plus d’informations sur les commentaires, consultez notre documentation ici.

Masquer les dossiers et les fichiers commençant par « ». dans l’arborescence wiki
Jusqu’à présent, l’arborescence wiki affichait tous les dossiers et fichiers commençant par un point (.) dans l’arborescence wiki. Dans les scénarios de wiki de code, des dossiers tels que .vscode, qui sont censés être masqués, s’affichent dans l’arborescence wiki. À présent, tous les fichiers et dossiers commençant par un point restent masqués dans l’arborescence wiki, ce qui réduit l’encombrement inutile.
Cette fonctionnalité a été hiérarchisée en fonction de ce ticket de suggestion.
URL de page Wiki courtes et lisibles
Vous n’avez plus besoin d’utiliser une URL multiligne pour partager des liens de page wiki. Nous tirons parti des ID de page dans l’URL pour supprimer des paramètres, ce qui rend l’URL plus courte et plus facile à lire.
La nouvelle structure des URL se présente comme suit :
https://dev.azure.com/{accountName}/{projectName}/_wiki/wikis/{wikiName}/{pageId}/{readableWiki PageName}
Voici un exemple de la nouvelle URL d’une page Wiki Bienvenue dans Azure DevOps :
https://dev.azure.com/microsoft/ AzureDevOps/_wiki/wikis/AzureDevOps.wiki/1/Welcome-to-Azure-DevOps-Wiki
Cela a été hiérarchisé en fonction de ce ticket de suggestion de fonctionnalités du Developer Community.
Défilement synchrone pour modifier des pages wiki
La modification des pages wiki est désormais plus facile grâce au défilement synchrone entre le volet modifier et le volet d’aperçu. Le défilement d’un côté fait défiler automatiquement l’autre côté pour mapper les sections correspondantes. Vous pouvez désactiver le défilement synchrone avec le bouton bascule.
Notes
L’état du bouton bascule de défilement synchrone est enregistré par utilisateur et par compte.
Visites de pages pour les pages wiki
Vous pouvez maintenant obtenir des informations sur les visites de pages pour les pages wiki. L’API REST vous permet d’accéder aux informations des visites de page au cours des 30 derniers jours. Vous pouvez utiliser ces données pour créer des rapports pour vos pages wiki. En outre, vous pouvez stocker ces données dans votre source de données et créer des tableaux de bord pour obtenir des insights spécifiques tels que les pages les plus consultées.
Vous verrez également un nombre agrégé de visites de pages pour les 30 derniers jours dans chaque page.
Notes
Une visite de page est définie comme une vue de page par un utilisateur donné dans un intervalle de 15 minutes.
Rapports
Rapports d’échec et de durée du pipeline
Les métriques et les insights vous aident à améliorer en permanence le débit et la stabilité de vos pipelines. Nous avons ajouté deux nouveaux rapports pour vous fournir des informations sur vos pipelines.
- Le rapport d’échec du pipeline affiche le taux de réussite de build et la tendance des échecs. En outre, il affiche également la tendance d’échec des tâches pour fournir des informations sur la tâche dans le pipeline qui contribue au nombre maximal d’échecs.
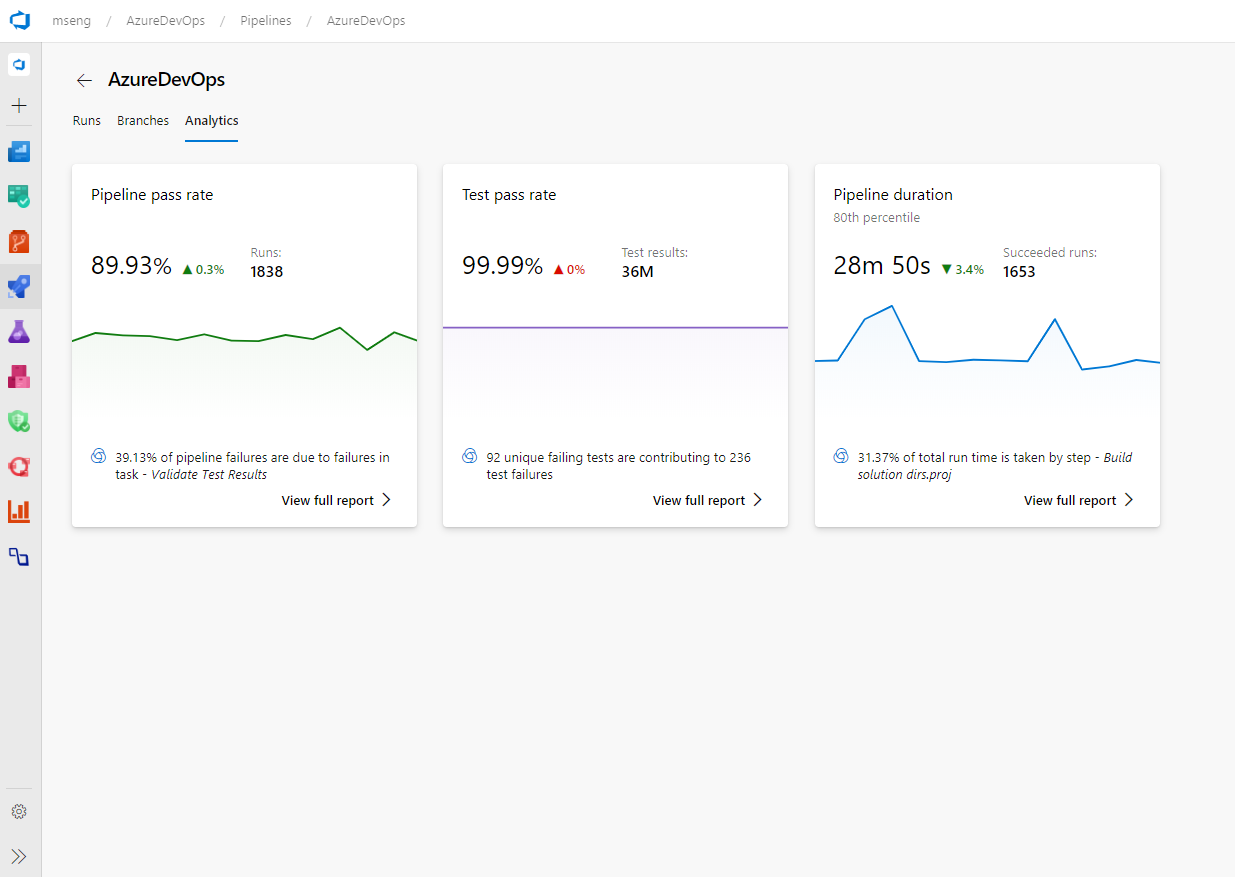
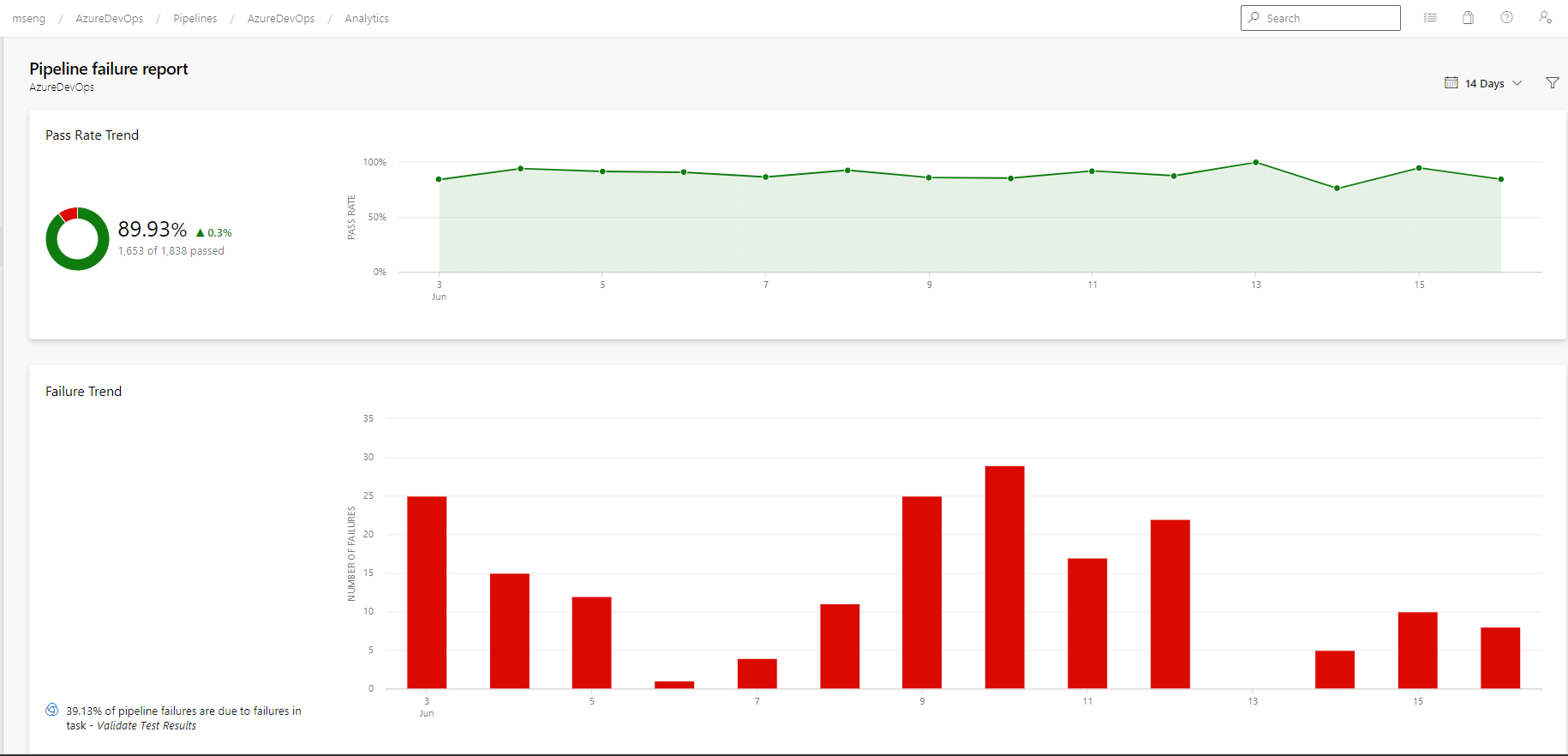
- Le rapport de durée du pipeline montre la tendance du temps nécessaire à l’exécution d’un pipeline. Il indique également les tâches du pipeline qui prennent le plus de temps.
Amélioration du widget Résultats de la requête
Le widget résultats de la requête est l’un de nos widgets les plus populaires, et pour une bonne raison. Le widget affiche les résultats d’une requête directement sur votre tableau de bord et est utile dans de nombreuses situations.
Avec cette mise à jour, nous avons inclus de nombreuses améliorations tant attendues :
- Vous pouvez maintenant sélectionner autant de colonnes que vous souhaitez afficher dans le widget. Plus de limite de 5 colonnes !
- Le widget prend en charge toutes les tailles, de 1x1 à 10x10.
- Lorsque vous redimensionnez une colonne, la largeur de la colonne est enregistrée.
- Vous pouvez développer le widget en mode plein écran. Une fois développée, elle affiche toutes les colonnes retournées par la requête.
Filtrage avancé des widgets Lead et Cycle Time
Les équipes utilisent le temps de prospect et de cycle pour voir combien de temps il faut pour que le travail passe par leurs pipelines de développement et, en fin de compte, fournir de la valeur à leurs clients.
Jusqu’à présent, les widgets de prospect et de temps de cycle ne prenaient pas en charge les critères de filtre avancés pour poser des questions telles que : « Combien de temps mon équipe prend-elle pour fermer les éléments de priorité supérieure ? »
Avec cette mise à jour, vous pouvez répondre à des questions comme celle-ci en filtrant sur le couloir de bord.
Nous avons également inclus des filtres d’éléments de travail afin de limiter les éléments de travail qui apparaissent dans le graphique.
Burndown de sprint inline à l’aide de points d’histoire
Votre Sprint Burndown peut maintenant être brûlé par Stories. Cela répond à vos commentaires du Developer Community.
Dans le hub Sprint, sélectionnez l’onglet Analytics. Configurez ensuite votre rapport comme suit :
- Sélectionner un backlog d’histoires
- Sélectionner pour le burndown sur somme des points d’histoire
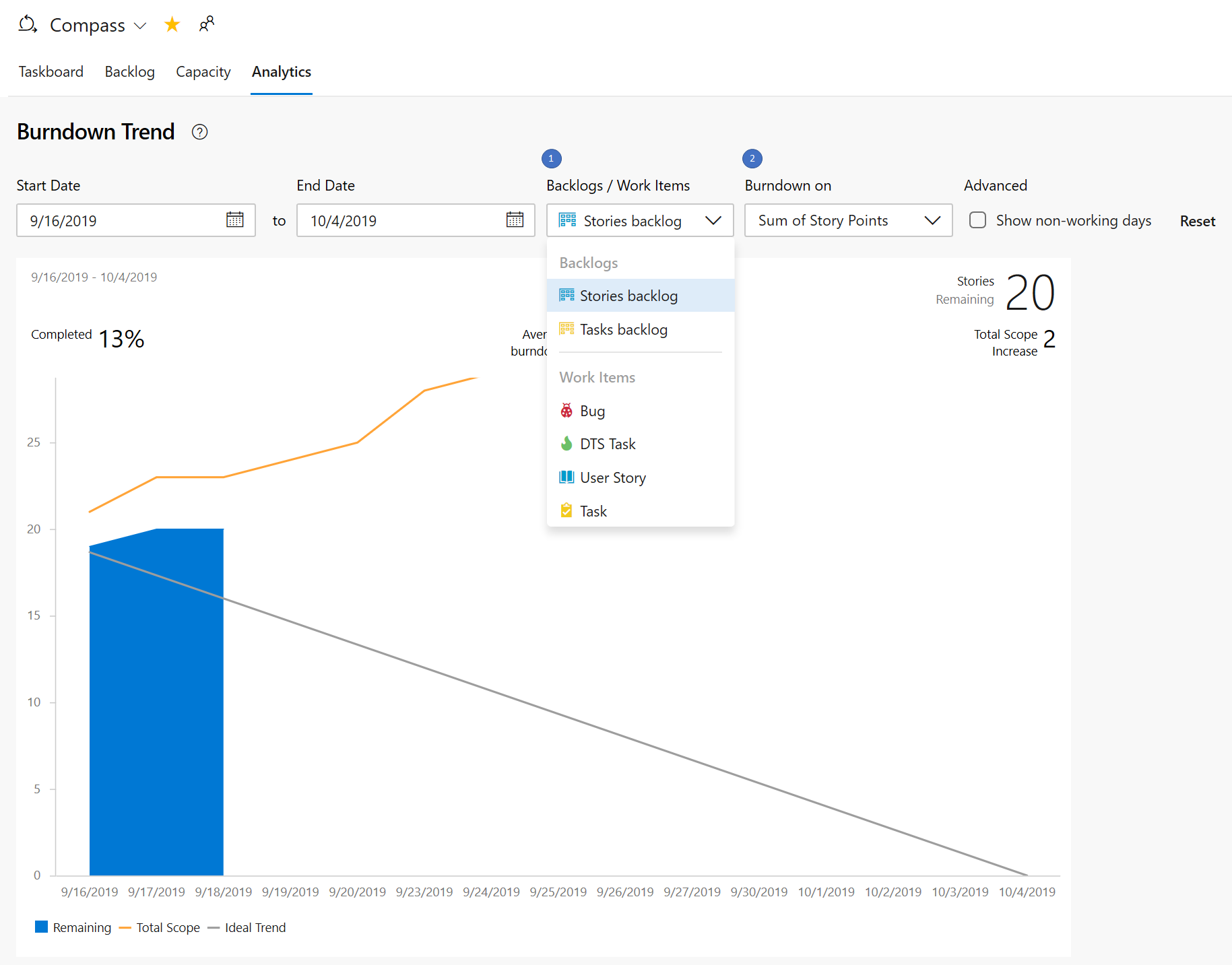
Un widget Sprint Burndown avec tout ce que vous avez demandé
Le nouveau widget Sprint Burndown prend en charge la gravure par points d’histoire, le nombre de tâches ou la somme de champs personnalisés. Vous pouvez même créer un burndown sprint pour les fonctionnalités ou les epics. Le widget affiche le burndown moyen, le % terminé et l’augmentation de l’étendue. Vous pouvez configurer l’équipe, ce qui vous permet d’afficher les burndowns de sprint pour plusieurs équipes sur le même tableau de bord. Avec toutes ces excellentes informations à afficher, nous vous permet de les redimensionner jusqu’à 10x10 sur le tableau de bord.
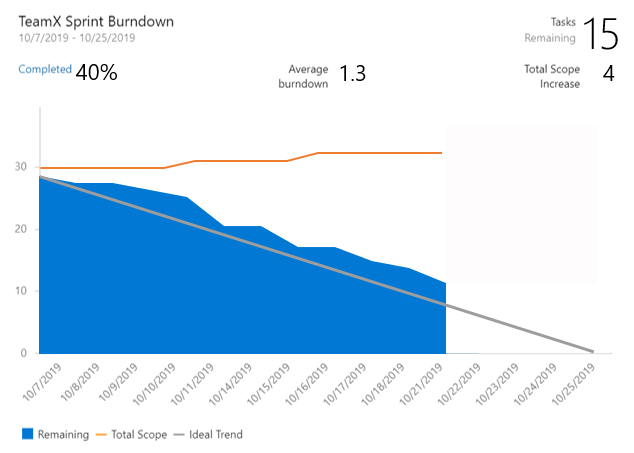
Pour l’essayer, vous pouvez l’ajouter à partir du catalogue de widgets ou en modifiant la configuration du widget Sprint Burndown existant et en cochant la case Essayer la nouvelle version maintenant .
Notes
Le nouveau widget utilise Analytics. Nous avons conservé l’ancien Sprint Burndown si vous n’avez pas accès à Analytics.
Miniature de burndown de sprint inline
Le Sprint Burndown est de retour ! Il y a quelques sprints, nous avons supprimé le burndown de sprint en contexte des en-têtes Sprint Burndown et Taskboard. En fonction de vos commentaires, nous avons amélioré et réintroduit la miniature du sprint burndown.
Cliquez sur la miniature pour afficher immédiatement une version plus grande du graphique avec une option permettant d’afficher le rapport complet sous l’onglet Analytics. Toutes les modifications apportées au rapport complet seront reflétées dans le graphique affiché dans l’en-tête. Vous pouvez donc maintenant le configurer pour qu’il soit brûlé en fonction des récits, des points d’histoire ou du nombre de tâches, plutôt que de la seule quantité de travail restante.
Create un tableau de bord sans équipe
Vous pouvez maintenant créer un tableau de bord sans l’associer à une équipe. Lors de la création d’un tableau de bord, sélectionnez le type Tableau de bord du projet .
Un tableau de bord de projet est semblable à un tableau de bord d’équipe, sauf qu’il n’est pas associé à une équipe et que vous pouvez décider qui peut modifier/gérer le tableau de bord. Tout comme un tableau de bord d’équipe, il est visible par tout le monde dans le projet.
Tous les widgets Azure DevOps qui nécessitent un contexte d’équipe ont été mis à jour pour vous permettre de sélectionner une équipe dans leur configuration. Vous pouvez ajouter ces widgets aux tableaux de bord de projet et sélectionner l’équipe spécifique de votre choix.

Notes
Pour les widgets personnalisés ou tiers, un tableau de bord de projet transmet le contexte de l’équipe par défaut à ces widgets. Si vous avez un widget personnalisé qui s’appuie sur le contexte d’équipe, vous devez mettre à jour la configuration pour vous permettre de sélectionner une équipe.
Commentaires
Nous aimerions connaître votre opinion ! Vous pouvez signaler un problème ou fournir une idée et le suivre dans Developer Community et obtenir des conseils sur Stack Overflow.