API table et SQL dans des clusters Apache Flink® sur HDInsight sur AKS
Important
Cette fonctionnalité est disponible actuellement en mode Aperçu. Les Conditions d’utilisation supplémentaires pour les préversions de Microsoft Azure contiennent davantage de conditions légales qui s’appliquent aux fonctionnalités Azure en version bêta, en préversion ou ne se trouvant pas encore en disponibilité générale. Pour plus d’informations sur cette préversion spécifique, consultez les Informations sur la préversion d’Azure HDInsight sur AKS. Pour toute question ou pour des suggestions à propos des fonctionnalités, veuillez envoyer vos requêtes et leurs détails sur AskHDInsight, et suivez-nous sur la Communauté Azure HDInsight pour plus de mises à jour.
Apache Flink propose deux API relationnelles (l’API Table et SQL) pour le traitement unifié par flux et par lots. L’API Table est une API LINQ (Language Integrated Query) qui permet la composition de requêtes à partir d’opérateur de relation tels que la sélection, le filtre et la jointure intuitivement. La prise en charge SQL de Flink est basée sur Apache Calcite, qui implémente la norme SQL.
Les interfaces TABLE et SQL s’intègrent en toute transparence avec l’API DataStream de Flink. Vous pouvez facilement basculer entre toutes les API et bibliothèques, qui s’appuient sur elles.
SQL Apache Flink
Comme d’autres moteurs SQL, les requêtes Flink fonctionnent sur des tables. Flink diffère d’une base de données traditionnelle, car il ne gère pas les données au repos localement. Au lieu de cela, ses requêtes fonctionnent en continu sur des tables externes.
Les pipelines de traitement des données Flink commencent par les tables sources et se terminent par des tables récepteurs. Les tables sources produisent des lignes exploitées pendant l’exécution de la requête ; il s’agit des tables référencées dans la clause FROM d’une requête. Les connecteurs peuvent être de type HDInsight Kafka, HDInsight HBase, Azure Event Hubs, bases de données, systèmes de fichiers ou tout autre système dont le connecteur se trouve dans le classpath.
Utilisation du client SQL Flink dans des clusters HDInsight sur AKS
Vous pouvez consulter cet article pour savoir comment utiliser la CLI à partir de Secure Shell sur le Portail Microsoft Azure. Voici quelques exemples rapides de la prise en main.
Pour démarrer le client SQL
./bin/sql-client.shPour passer un fichier sql d’initialisation à exécuter avec sql-client
./sql-client.sh -i /path/to/init_file.sqlPour définir une configuration dans sql-client
SET execution.runtime-mode = streaming; SET sql-client.execution.result-mode = table; SET sql-client.execution.max-table-result.rows = 10000;
DDL SQL
Flink SQL prend en charge les instructions CREATE suivantes
- CREATE TABLE
- CREATE DATABASE
- CRÉER UN CATALOGUE
Voici un exemple de syntaxe permettant de définir une table source à l’aide du connecteur jdbc pour se connecter à MSSQL, avec id, nom en tant que colonnes dans une instruction CREATE TABLE
CREATE TABLE student_information (
id BIGINT,
name STRING,
address STRING,
grade STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:sqlserver://servername.database.windows.net;database=dbname;encrypt=true;trustServerCertificate=true;create=false;loginTimeout=30',
'table-name' = 'students',
'username' = 'username',
'password' = 'password'
);
CREATE DATABASE :
CREATE DATABASE students;
CREATE CATALOG :
CREATE CATALOG myhive WITH ('type'='hive');
Vous pouvez exécuter des requêtes continues sur ces tables
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
Écrire dans la table récepteur à partir de la table source :
INSERT INTO grade_counts
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
Ajout de dépendances
Les instructions JAR sont utilisées pour ajouter des fichiers jar utilisateur dans le classpath ou supprimer des fichiers jar utilisateur du classpath ou afficher les fichiers jar ajoutés au classpath dans le runtime.
Flink SQL prend en charge les instructions JAR suivantes :
- ADD JAR
- SHOW JARS
- REMOVE JAR
Flink SQL> ADD JAR '/path/hello.jar';
[INFO] Execute statement succeed.
Flink SQL> ADD JAR 'hdfs:///udf/common-udf.jar';
[INFO] Execute statement succeed.
Flink SQL> SHOW JARS;
+----------------------------+
| jars |
+----------------------------+
| /path/hello.jar |
| hdfs:///udf/common-udf.jar |
+----------------------------+
Flink SQL> REMOVE JAR '/path/hello.jar';
[INFO] The specified jar is removed from session classloader.
Metastore Hive dans des clusters Apache Flink® sur HDInsight sur AKS
Les catalogues fournissent des métadonnées, telles que des bases de données, des tables, des partitions, des vues et des fonctions et des informations nécessaires pour accéder aux données stockées dans une base de données ou dans d’autres systèmes externes.
Dans HDInsight sur AKS, Flink nous prenons en charge deux options de catalogue :
GenericInMemoryCatalog
GenericInMemoryCatalog est une implémentation en mémoire d’un catalogue. Tous les objets sont disponibles uniquement pour la durée de vie de la session sql.
HiveCatalog
HiveCatalog remplit deux fonctions : le stockage persistant pour les métadonnées Flink pures et l’interface pour la lecture et l’écriture de métadonnées Hive existantes.
Remarque
Les clusters HDInsight sur AKS sont fournis avec une option intégrée de Metastore Hive pour Apache Flink. Vous pouvez opter pour le metastore Hive lors de la création du cluster
Guide pratique pour créer et inscrire des bases de données Flink dans des catalogues
Vous pouvez consulter cet article sur l’utilisation de l’interface CLI et commencer à utiliser Flink SQL Client à partir de Secure Shell sur le portail Azure.
Démarrer
sql-client.shsession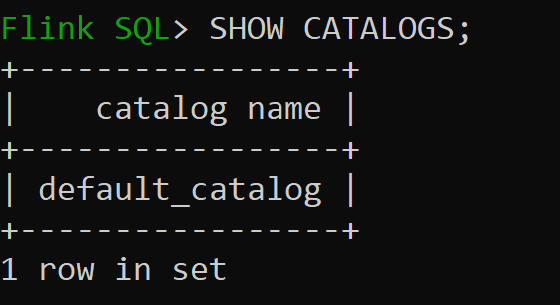
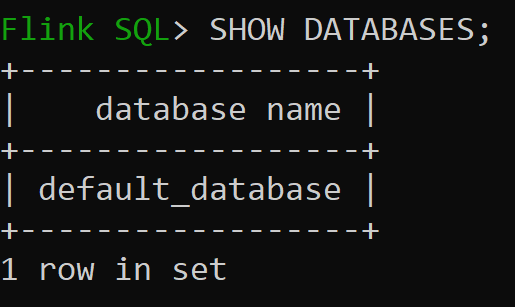
Default_catalog est le catalogue en mémoire par défaut
Vérifions maintenant la base de données par défaut du catalogue en mémoire
Nous allons créer le catalogue Hive de la version 3.1.2 et l’utiliser
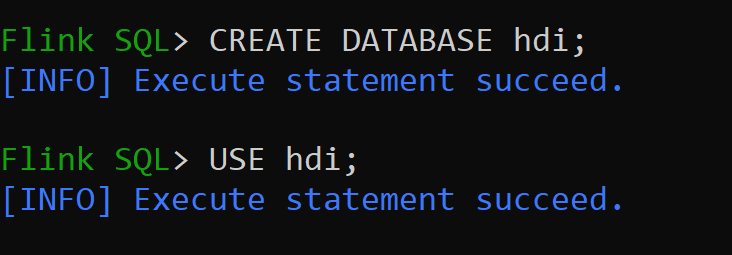
CREATE CATALOG myhive WITH ('type'='hive'); USE CATALOG myhive;Remarque
HDInsight sur AKS prend en charge Hive 3.1.2 et Hadoop 3.3.2. La valeur
hive-conf-direst définie sur l’emplacement/opt/hive-confNous allons créer la base de données dans le catalogue hive et la définir par défaut pour la session (sauf modification).
Guide pratique pour créer et inscrire des tables Hive dans le catalogue Hive
Suivez les instructions sur la création et l’inscription de bases de données Flink dans le catalogue
Nous allons créer une table Flink de type de connecteur Hive sans partition
CREATE TABLE hive_table(x int, days STRING) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');Insérer des données dans hive_table
INSERT INTO hive_table SELECT 2, '10'; INSERT INTO hive_table SELECT 3, '20';Lire des données de hive_table
Flink SQL> SELECT * FROM hive_table; 2023-07-24 09:46:22,225 INFO org.apache.hadoop.mapred.FileInputFormat[] - Total input files to process : 3 +----+-------------+--------------------------------+ | op | x | days | +----+-------------+--------------------------------+ | +I | 3 | 20 | | +I | 2 | 10 | | +I | 1 | 5 | +----+-------------+--------------------------------+ Received a total of 3 rowsRemarque
Le répertoire de l’entrepôt Hive se trouve dans le conteneur désigné du compte de stockage choisi lors de la création du cluster Apache Flink, à l’adresse hive/warehouse/ du répertoire
Nous allons créer une table Flink de type de connecteur Hive avec partition
CREATE TABLE partitioned_hive_table(x int, days STRING) PARTITIONED BY (days) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');
Important
Il existe une limitation connue dans Apache Flink. Les dernières colonnes « n » sont choisies pour les partitions, quelle que soit la colonne de partition définie par l’utilisateur. FLINK-32596 La clé de partition est incorrecte lors de l’utilisation du dialecte Flink pour créer une table Hive.
Référence
- API Table Apache Flink et SQL
- Apache, Apache Flink, Flink et les noms de projet open source associés sont des marques de commerce d’Apache Software Foundation (ASF).