Approfondissement - Analytique avancée
Présentation de l’analytique avancée pour HDInsight
HDInsight fournit la possibilité d’obtenir des insights pertinents à partir de grandes quantités de données structurées, non structurées et extrêmement dynamiques. L’analytique avancée est l’utilisation d’architectures hautement scalables, de modèles statistiques et Machine Learning et de tableaux de bord intelligents pour fournir des insights pertinents. Le Machine Learning, ou l’analytique prédictive, utilise des algorithmes qui identifient et intègrent les relations dans vos données pour élaborer des prédictions et guider vos décisions.
Processus d’analytique avancée
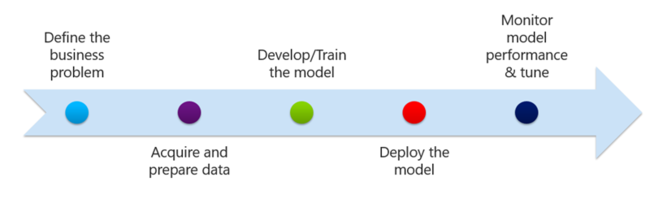
Une fois que vous avez identifié le problème de l’entreprise et que vous avez démarré la collecte et le traitement de vos données, vous devez créer un modèle qui représente la question à propos de laquelle vous souhaitez établir des prédictions. Votre modèle utilise un ou plusieurs algorithmes Machine Learning pour restituer le type de prédiction qui répond le mieux aux besoins de votre entreprise. La majorité de vos données doit être utilisée pour l’apprentissage de votre modèle, le reste étant utilisé à des fins de test ou d’évaluation.
Une fois que vous avez créé, chargé, testé et évalué votre modèle, l’étape suivante consiste à déployer votre modèle afin qu’il commence à fournir des réponses à vos questions. La dernière étape consiste à analyser les performances de votre modèle et à les ajuster au besoin.
Types courants d’algorithmes
La solution d’analytique avancée fournit un ensemble d’algorithmes Machine Learning. Voici un résumé des catégories d’algorithmes et des exemples d’utilisation courants associés.
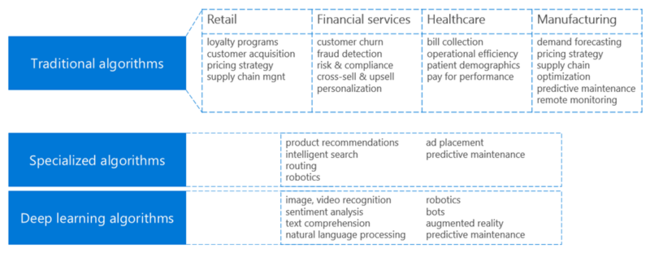
Une fois que vous avez sélectionné l’algorithme le mieux adapté, vous devez définir si vous avez besoin de fournir des données pour l’apprentissage. Les algorithmes Machine Learning sont classés comme suit :
- Supervisés : l’algorithme doit être formé sur un jeu de données étiquetées avant de pouvoir fournir des résultats.
- Semi-supervisés : l’algorithme peut être complété par des cibles supplémentaires via une requête interactive par un formateur, ce qui n’était pas possible pendant la phase initiale d’entraînement.
- Non supervisés : l’algorithme ne nécessite pas de données d’entraînement.
- Renforcement : l’algorithme utilise des agents logiciels pour déterminer le comportement idéal dans un contexte spécifique (comme c’est le cas en robotique).
| Catégorie d’algorithme | Utilisation | Type d’apprentissage | Algorithmes |
|---|---|---|---|
| classification ; | Classer des personnes ou des éléments en groupes | Supervisé | Arbres de décision, régression logistique, réseaux neuronaux |
| Clustering | Division d’un ensemble d’exemples en groupes homogènes | Non supervisé | Clustering (K-moyennes) |
| Détection de modèles | Identifier les associations fréquentes dans les données | Non supervisé | Règles d’association |
| régression ; | Prédire des résultats numériques | Supervisé | Régression linéaire, réseaux neuronaux |
| Renforcement | Déterminer le comportement optimal pour les robots | Renforcement | Simulations Monte-Carlo, DeepMind |
Machine Learning sur HDInsight
HDInsight dispose de plusieurs options Machine Learning pour un flux de travail d’analytique avancée :
- Machine Learning et Apache Spark
- Azure Machine Learning et Apache Hive
- Apache Spark et Deep Learning
Machine Learning et Apache Spark
HDInsight Spark est une offre hébergée sur Azure incluant Apache Spark, une infrastructure de traitement des données parallèle open source qui utilise le traitement en mémoire pour améliorer les performances de l’analytique Big Data. Le moteur de traitement Spark est élaboré pour permettre des analyses rapides, simples d’utilisation et sophistiquées. De par ses capacités de calcul distribué en mémoire, Spark constitue le choix idéal pour les algorithmes itératifs utilisés dans l’apprentissage automatique et les calculs de graphiques.
Il existe trois bibliothèques Machine Learning scalables qui apportent des fonctionnalités de modélisation d’algorithme à cet environnement distribué :
- MLlib -MLlib contient l’API d’origine reposant sur Spark RDDs.
- SparkML -SparkML est un package plus récent qui fournit une API de niveau supérieur reposant sur les trames de données Spark pour construire des pipelines ML.
- MMLSpark - La bibliothèque Machine Learning de Microsoft pour Apache Spark (MMLSpark) est conçue pour améliorer la productivité des chercheurs de données sur Spark, pour accroître le taux d’expérimentation et pour tirer parti de techniques Machine Learning de pointe, notamment l’apprentissage profond, sur les jeux de données très volumineux. La bibliothèque MMLSpark simplifie les tâches de modélisation courantes pour générer des modèles dans PySpark.
Azure Machine Learning et Apache Hive
Azure Machine Learning Studio (classique) fournit des outils de modélisation d’analytique prédictive, ainsi qu’un service complètement managé permettant de déployer des modèles prédictifs sous la forme de services web prêts à l’emploi. Azure Machine Learning fournit des outils pour créer des solutions complètes d’analyse prédictive sur le cloud afin de créer, tester, mettre en service et gérer rapidement des modèles prédictifs. Effectuez une sélection dans une volumineuse bibliothèque d’algorithmes, utilisez un studio web pour générer des modèles et déployez facilement votre modèle en tant que service web.
Apache Spark et Deep Learning
L’apprentissage profond est une branche du Machine Learning qui utilise les réseaux neuronaux profonds (DNN), inspirés par les processus biologiques du cerveau humain. De nombreux chercheurs voient le Deep Learning comme une approche prometteuse de l’intelligence artificielle. Voici quelques exemples d’apprentissage profond : traducteurs de langue parlée, systèmes de reconnaissance d’image et raisonnement de l’ordinateur. Dans le cadre de son travail sur l’apprentissage profond, Microsoft a développé Microsoft Cognitive Toolkit, open source, gratuit et facile à utiliser. Ce Toolkit est largement utilisé par un grand nombre de produits Microsoft, par des entreprises du monde entier ayant besoin de déployer l’apprentissage profond à l’échelle et par des étudiants intéressés par les algorithmes et techniques les plus récents.
Scénario - Noter des images pour identifier les tendances en développement urbain
Examinons un exemple de pipeline Machine Learning d’analytique avancée utilisant HDInsight.
Ce scénario montre comment les réseaux neuronaux profonds produits dans un framework de deep learning, Microsoft Cognitive Toolkit (CNTK), peuvent être exploités pour noter de grandes collections d’images stockées dans un compte de stockage Blob Azure à l’aide de PySpark sur un cluster HDInsight Spark. Cette approche est appliquée à un cas d’usage courant des réseaux neuronaux (la classification d’images aériennes) et peut être utilisée pour identifier les tendances récentes en développement urbain. Vous allez utiliser un modèle de classification d’image préentraîné. Le modèle est préformé sur le jeu de données CIFAR-10 et a été appliqué à 10 000 images retenues.
Il existe trois tâches clés dans ce scénario d’analytique avancée :
- Créer un cluster Azure HDInsight Hadoop avec une distribution Apache Spark 2.1.0.
- Exécuter un script personnalisé pour installer Microsoft Cognitive Toolkit sur tous les nœuds d’un cluster Azure HDInsight Spark.
- Charger un notebook Jupyter préconfiguré sur le cluster HDInsight Spark pour appliquer un modèle Deep Learning Microsoft Cognitive Toolkit entraîné aux fichiers d’un compte Stockage Blob Azure avec l’API Spark Python (PySpark).
Cet exemple utilise le jeu d’images CIFAR-10 compilé et distribué par Alex Krizhevsky, Vinod Nair et Geoffrey Hinton. Le jeu de données CIFAR-10 contient 60 000 images en couleur de 32 x 32 pixels appartenant à 10 classes qui s’excluent mutuellement :

Pour plus d’informations sur le jeu de données, consultez l’article Learning Multiple Layers of Features from Tiny Images rédigé par Alex Krizhevsky.
Le jeu de données a été partitionné en un jeu d’apprentissage de 50 000 images et un jeu de test de 10 000 images. Le premier jeu a été utilisé pour former un modèle de réseau résiduel à convolution à vingt couches (ResNet) à l’aide de Microsoft Cognitive Toolkit en suivant ce didacticiel à partir du dépôt Cognitive Toolkit GitHub. Les 10 000 images restantes ont été utilisées pour tester la précision du modèle. C’est là que le calcul distribué entre en jeu : la tâche de prétraitement et de notation des images est hautement parallélisable. Avec le modèle formé enregistré, nous avons utilisé :
- PySpark pour distribuer les images et le modèle formé aux nœuds Worker du cluster.
- Python pour prétraiter les images sur chaque nœud du cluster HDInsight Spark.
- Cognitive Toolkit pour charger le modèle et noter les images prétraitées sur chaque nœud.
- Des Notebooks Jupyter pour exécuter le script PySpark, agréger les résultats et utiliser Matplotlib pour visualiser les performances du modèle.
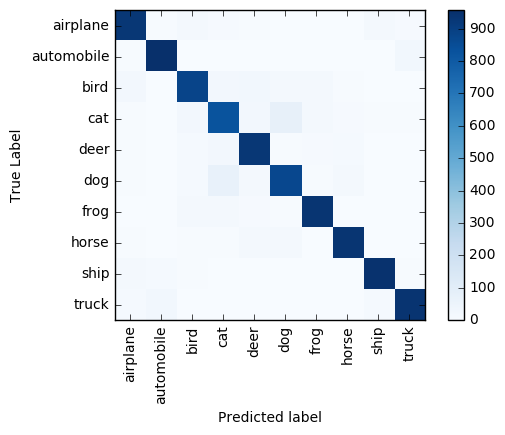
L’ensemble du processus de prétraitement/notation des 10 000 images prend moins d’une minute sur un cluster avec 4 nœuds Worker. Le modèle prédit correctement les étiquettes d’environ 9 100 images (91 %). Une matrice de confusion illustre les erreurs de classification les plus courantes. Par exemple, la matrice montre qu’un étiquetage erroné d’images de chiens et de chats se produit plus fréquemment que pour les autres paires d’étiquette.
Faites un essai.
Suivez ce tutoriel pour implémenter cette solution de bout en bout : configurez un cluster HDInsight Spark, installez Cognitive Toolkit et exécutez le notebook Jupyter qui note 10 000 images CIFAR.
Étapes suivantes
Apache Hive et Azure Machine Learning
- Apache Hive et Azure Machine Learning de bout en bout
- Utilisation d’un cluster Azure HDInsight Hadoop sur un jeu de données de 1 To
Apache Spark et MLlib
- Machine Learning avec Apache Spark sur HDInsight
- Apache Spark avec Machine Learning : utilisez Apache Spark dans HDInsight pour l’analyse de la température des bâtiments à l’aide des données des systèmes HVAC
- Apache Spark avec Machine Learning : utilisez Apache Spark dans HDInsight pour prédire les résultats de l’inspection des aliments
Apprentissage profond, Cognitive Toolkit et autres