Exécution de requêtes Apache Hive à l’aide des outils Data Lake pour Visual Studio
Découvrez comment utiliser les outils Data Lake pour Visual Studio pour interroger Apache Hive. Les outils Data Lake vous permettent de facilement créer, soumettre et surveiller les requêtes Hive à Apache Hadoop sur Azure HDInsight.
Prérequis
Un cluster Apache Hadoop sur HDInsight. Pour plus d’informations sur la création de cet élément, consultez Créer un cluster Apache Hadoop dans Azure HDInsight avec un modèle Resource Manager.
Visual Studio. Dans le cadre de cet article, Visual Studio 2019 a été utilisé.
Outils HDInsight pour Visual Studio ou Outils Azure Data Lake pour Visual Studio. Pour plus d’informations sur l’installation et la configuration des outils, consultez Installer les outils Data Lake pour Visual Studio.
Exécuter des requêtes Apache Hive avec Visual Studio
Vous pouvez créer et exécuter des requêtes Hive de deux façons :
- Créer des requêtes ad hoc.
- Créer une application Hive.
Créer une requête Hive ad-hoc.
Les requêtes ad hoc peuvent être exécutées dans le mode Batch ou Interactive.
Lancez Visual Studio et sélectionnez Continuer sans code.
À partir de l’Explorateur de serveurs, faites un clic droit sur Azure, sélectionnez Se connecter à un abonnement Microsoft Azure..., puis terminez le processus de connexion.
Développez HDInsight, cliquez avec le bouton droit sur le cluster dans lequel vous souhaitez exécuter la requête, puis sélectionnez Écrire une requête Hive.
Exécutez la requête Hive suivante :
SELECT * FROM hivesampletable;Sélectionnez Exécuter. Le mode d’exécution par défaut est Interactive.
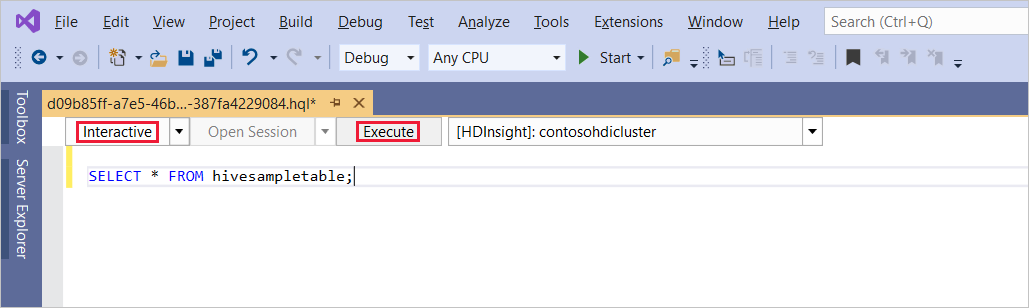
Pour exécuter la même requête dans le mode Batch, utilisez la liste déroulante pour passer de Interactive à Batch. Le bouton d’exécution Exécuter devient Envoyer.

L’éditeur Hive prend en charge IntelliSense. Data Lake Tools pour Visual Studio prend en charge le chargement des métadonnées distantes pendant la modification d’un script Hive. Par exemple, si vous tapez
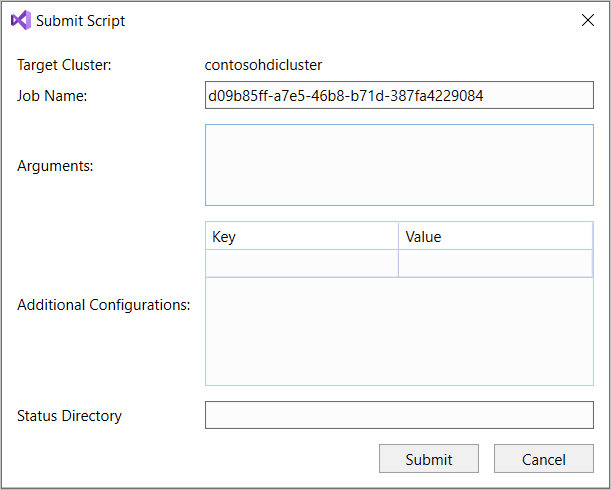
SELECT * FROM, IntelliSense répertorie tous les noms de table suggérés. Lorsqu’un nom de table est spécifié, IntelliSense répertorie les noms de colonne. Les outils prennent en charge la plupart des instructions DML, sous-requêtes et fonctions définies par l’utilisateur intégrées de Hive. IntelliSense propose uniquement les métadonnées du cluster sélectionné dans la barre d’outils HDInsight.Dans la barre d’outils de la requête (la zone située sous l’onglet de la requête et au-dessus du texte de la requête), sélectionnez Envoyer ou sélectionnez la flèche déroulante à côté d’Envoyer, puis choisissez Avancé dans la liste déroulante. Si vous sélectionnez cette dernière option,
Si vous avez sélectionné l’option d’envoi avancé, configurez les éléments Nom du travail, Arguments, Configurations supplémentaires et Répertoire d’état dans la boîte de dialogue Envoyer le script. Ensuite, sélectionnez Envoyer.
Création d’une application Hive
Pour exécuter une requête Hive en créant une application Hive, procédez comme suit :
Ouvrez Visual Studio.
Dans la fenêtre Démarrer, sélectionnez Créer un projet.
Dans la fenêtre Créer un nouveau projet, dans la zone Rechercher des modèles, entrez Hive. Choisissez ensuite Application Hive, puis sélectionnez Suivant.
Dans la fenêtre Configurer votre nouveau projet, entrez un Nom de projet, sélectionnez ou créez un Emplacement pour le nouveau projet, puis sélectionnez Créer.
Ouvrez le fichier Script.hql créé avec ce projet et collez les instructions HiveQL suivantes :
set hive.execution.engine=tez; DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4jLogs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS sev, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log' GROUP BY t4;Ces instructions effectuent les opérations suivantes :
DROP TABLE: supprime la table si elle existe.CREATE EXTERNAL TABLE: crée une table externe dans Hive. Les tables externes stockent uniquement la définition de table dans Hive. (Les données restent à l’emplacement d’origine.)Notes
Les tables externes doivent être utilisées lorsque vous vous attendez à ce que les données sous-jacentes soient mises à jour par une source externe, telles qu’un travail MapReduce ou un service Azure.
La suppression d'une table externe ne supprime pas les données, mais seulement la définition de la table.
ROW FORMAT: indique à Hive le mode de formatage des données. Dans ce cas, les champs de chaque journal sont séparés par un espace.STORED AS TEXTFILE LOCATION: indique à Hive que les données sont stockées dans le répertoire example/data sous forme de texte.SELECT:sélectionne toutes les lignes dont la colonnet4contient la valeur[ERROR]. Cette instruction renvoie la valeur3, car trois lignes contiennent cette valeur.INPUT__FILE__NAME LIKE '%.log': indique à Hive de retourner uniquement des données provenant de fichiers se terminant par .log. Cette clause limite la recherche au fichier sample.log qui contient les données.
À partir de la barre d’outils du fichier de requête (ressemble à la barre d’outils de requête ad hoc), sélectionnez le cluster HDInsight que vous souhaitez utiliser pour cette requête. Modifiez ensuite Interactive en Batch (le cas échéant), puis sélectionnez Envoyer pour exécuter les instructions en tant que travail Hive.
Le résumé de tâche Hive apparaît et affiche des informations sur la tâche en cours d’exécution. Utilisez le lien Actualiser pour actualiser les informations sur la tâche, jusqu’à ce que l’état de la tâche passe à Terminé.
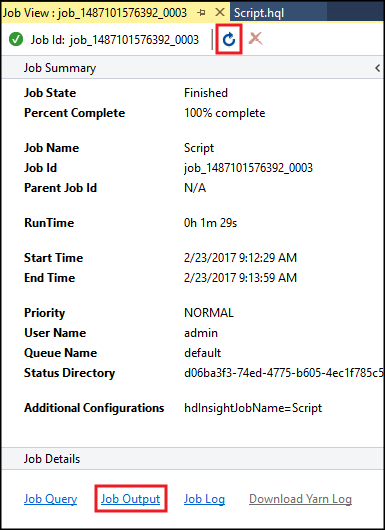
Sélectionnez Sortie du travail pour afficher la sortie de ce travail. Il affiche
[ERROR] 3, soit la valeur retournée par cette requête.
Exemple supplémentaire
L’exemple suivant s’appuie sur la table log4jLogs créée lors de la procédure précédente, Créer une application Hive.
À partir de l’Explorateur de serveurs, faites un clic droit sur votre cluster et sélectionnez Écrire une requête Hive.
Exécutez la requête Hive suivante :
set hive.execution.engine=tez; CREATE TABLE IF NOT EXISTS errorLogs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) STORED AS ORC; INSERT OVERWRITE TABLE errorLogs SELECT t1, t2, t3, t4, t5, t6, t7 FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log';Ces instructions effectuent les opérations suivantes :
CREATE TABLE IF NOT EXISTS: crée une table, si elle n’existe pas déjà. Étant donné que le mot cléEXTERNALn’est pas utilisé, cette instruction crée une table interne. Les tables internes sont stockées dans l’entrepôt de données Hive et gérées par Hive.Notes
Contrairement aux tables
EXTERNAL, la suppression d’une table interne entraîne également la suppression des données sous-jacentes.STORED AS ORC: stocke les données dans un format ORC (Optimized Row Columnar). ORC est un format particulièrement efficace et optimisé pour le stockage de données Hive.INSERT OVERWRITE ... SELECT: sélectionne des lignes de la tablelog4jLogsqui contiennent[ERROR], puis insère les données dans la tableerrorLogs.
Modifiez Interactive en Batch le cas échéant, puis sélectionnez Envoyer.
Pour vérifier que le travail a créé la table, accédez à Explorateur de serveurs et développez Azure>HDInsight. Développez votre cluster HDInsight, puis Bases de données Hive>par défaut. La table errorLogs et la table log4jLogs sont répertoriées.
Étapes suivantes
Comme vous pouvez le voir, les outils HDInsight pour Visual Studio fournissent un moyen simple de travailler avec des requêtes Hive sur HDInsight.
Pour des informations générales sur Hive dans HDInsight, consultez Présentation d’Apache Hive et HiveQL sur Azure HDInsight
Pour des informations sur les autres façons de travailler avec Hadoop sur HDInsight, consultez Utiliser MapReduce dans Apache Hadoop sur HDInsight
Pour plus d’informations sur les outils HDInsight pour Visual Studio, consultez Utiliser les outils Data Lake pour Visual Studio afin de se connecter à Azure HDInsight et exécuter des requêtes Apache Hive