Exemple Apache Spark Streaming (DStream) avec Apache Kafka sur HDInsight
Découvrez comment utiliser Apache Spark pour diffuser des données vers ou à partir d’Apache Kafka sur HDInsight à l’aide de DStreams. Cet exemple utilise un bloc-notes Jupyter Notebook qui s’exécute sur le cluster Spark.
Notes
Les étapes décrites dans ce document créent un groupe de ressources Azure qui contient à la fois un Spark sur HDInsight et un Kafka sur un cluster HDInsight. Ces clusters sont tous deux situés dans un réseau virtuel Azure, ce qui permet au cluster Spark de communiquer directement avec le cluster Kafka.
Lorsque vous avez terminé les étapes décrites dans ce document, n’oubliez pas de supprimer les clusters pour éviter les frais supplémentaires.
Important
Cet exemple utilise DStreams, une technologie de diffusion en continu Spark plus ancienne. Pour obtenir un exemple utilisant des fonctionnalités de streaming Spark plus récentes, consultez le document Spark Structured Streaming avec Apache Kafka.
Création des clusters
Apache Kafka sur HDInsight ne donne pas accès aux répartiteurs Kafka sur l’Internet public. Tout ce qui communique avec Kafka doit se trouver sur le même réseau virtuel Azure que les nœuds du cluster Kafka. Pour cet exemple, les clusters Kafka et Spark sont situés dans un réseau virtuel Azure. Le diagramme suivant illustre le flux de communication entre les clusters :
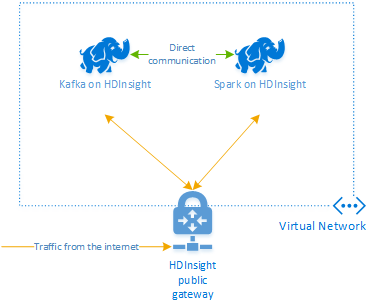
Remarque
Bien que Kafka soit lui-même limité à la communication au sein du réseau virtuel, d’autres services sur le cluster comme SSH et Ambari sont accessibles sur Internet. Pour plus d’informations sur les ports publics disponibles avec HDInsight, consultez Ports et URI utilisés par HDInsight.
Même si vous pouvez créer un réseau virtuel Azure, et des clusters Kafka et Spark manuellement, il est plus facile d’utiliser un modèle Azure Resource Manager. Utilisez les étapes suivantes pour déployer un réseau virtuel Azure et des clusters Kafka et Spark sur votre abonnement Azure.
Utilisez le bouton suivant pour vous connecter à Azure et ouvrir le modèle dans le portail Azure.

Avertissement
Pour garantir la disponibilité de Kafka sur HDInsight, votre cluster doit contenir au moins quatre nœuds Worker. Ce modèle crée un cluster Kafka qui contient quatre nœuds Worker.
Ce modèle crée un cluster HDInsight 4.0 pour Kafka et Spark.
Utilisez les informations suivantes pour remplir les entrées dans la section Déploiement personnalisé :
Propriété Valeur Resource group créez un groupe ou sélectionnez un groupe existant. Location choisissez un emplacement géographiquement proche de vous. Nom du cluster de base cette valeur est utilisée comme nom de base pour les clusters Spark et Kafka. Par exemple, si vous entrez hdistreaming, un cluster Spark nommé spark-hdistreaming et un cluster Kafka nommé kafka-hdistreaming sont créés. Nom d’utilisateur de connexion au cluster nom de l’utilisateur administrateur pour les clusters Spark et Kafka. Mot de passe de connexion au cluster mot de passe de l’utilisateur administrateur pour les clusters Spark et Kafka. Nom d’utilisateur SSH utilisateur SSH à créer pour les clusters Spark et Kafka. Mot de passe SSH mot de passe de l’utilisateur SSH pour les clusters Spark et Kafka. 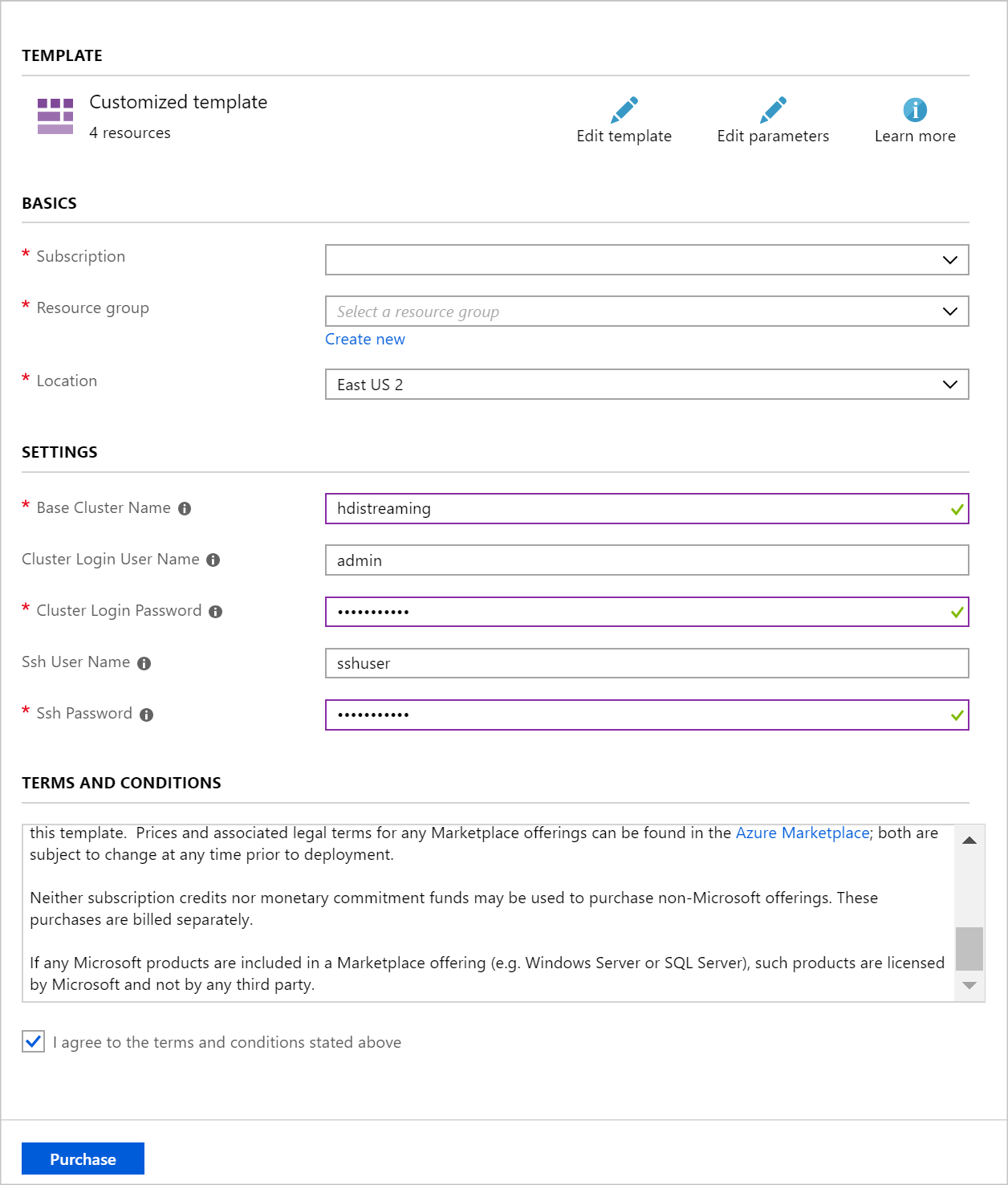
Passez en revue les termes et conditions, puis cochez la case J’accepte les termes et conditions mentionnés ci-dessus.
Enfin, sélectionnez Achat. La création des clusters prend environ 20 minutes.
Dès que les ressources sont créées, une page de résumé s’affiche.

Important
Les noms des clusters HDInsight sont spark-BASENAME et kafka-BASENAME, où BASENAME est le nom que vous avez fourni pour le modèle. Vous utilisez ces noms dans les étapes ultérieures, lors de la connexion aux clusters.
Obtenir les blocs-notes
Le code de l’exemple décrit dans ce document est disponible à l’adresse https://github.com/Azure-Samples/hdinsight-spark-scala-kafka.
Supprimer le cluster
Avertissement
La facturation des clusters HDInsight est calculée au prorata des minutes écoulées, que vous les utilisiez ou non. Veillez à supprimer votre cluster une fois que vous avez terminé de l’utiliser. Consultez Guide pratique pour supprimer un cluster HDInsight.
Étant donné que les étapes décrites dans ce document créent deux clusters dans le même groupe de ressources Azure, vous pouvez supprimer le groupe de ressources du portail Azure. La suppression de ce groupe supprime toutes les ressources créées par la suite dans ce document, le réseau virtuel Azure et le compte de stockage utilisé par les clusters.
Étapes suivantes
Dans ce document, vous avez appris à utiliser Spark pour lire et écrire dans Kafka. Utilisez les liens suivants pour découvrir d’autres façons de travailler avec Kafka :