Apache Phoenix dans Azure HDInsight
Apache Phoenix est une couche de base de données relationnelle massivement parallèle open source basée sur Apache HBase. Phoenix vous donne les moyens d’utiliser des requêtes de type SQL sur HBase. Phoenix utilise en dessous des pilotes JDBC pour permettre aux utilisateurs de créer, supprimer et modifier des tables SQL, index, vues et séquences, ainsi que des lignes d’upsert individuellement et en bloc. Phoenix utilise une compilation native noSQL au lieu de MapReduce pour compiler les requêtes, ce qui permet de créer des applications à faible latence sur HBase. Phoenix ajoute des co-processeurs pour prendre en charge le code fourni par le client en cours d’exécution dans l’espace d’adressage du serveur, en exécutant le code colocalisé avec les données. Cette approche réduit le transfert de données client/serveur.
Apache Phoenix affiche des requêtes Big Data aux utilisateurs non-développeurs, qui peuvent recourir à une syntaxe de type SQL en lieu et place de la programmation. Phoenix est hautement optimisé pour HBase, contrairement à d’autres outils comme Apache Hive et Apache Spark SQL. Cela permet aux développeurs d’écrire des requêtes hautement performantes avec un volume de code bien moindre.
Quand vous envoyez une requête SQL, Phoenix la compile en appels natifs HBase et exécute l’analyse (ou le plan) en parallèle à des fins d’optimisation. Grâce à cette couche d’abstraction, les développeurs n’ont pas à écrire de tâches MapReduce, et peuvent ainsi se concentrer sur la logique métier et le workflow de leur application vis-à-vis du stockage des Big Data de Phoenix.
Optimisation des performances de requête et autres fonctionnalités
Apache Phoenix ajoute plusieurs améliorations de performance et fonctionnalités aux requêtes HBase.
Index secondaires
HBase possède un seul index qui est trié lexicographiquement sur la clé de ligne principale. Ces enregistrements sont accessibles uniquement via la clé de ligne. L’accès aux enregistrements via toute autre colonne différente de la clé de ligne nécessite d’analyser l’ensemble des données tout en appliquant le filtre requis. Dans un index secondaire, les colonnes ou expressions indexées constituent une clé de ligne de remplacement, permettant les recherches et les analyses de plage sur cet index.
Créez un index secondaire avec la commande CREATE INDEX :
CREATE INDEX ix_purchasetype on SALTEDWEBLOGS (purchasetype, transactiondate) INCLUDE (bookname, quantity);
Cette approche peut générer une augmentation significative des performances par rapport à l’exécution des requêtes avec index unique. Ce type d’index secondaire est un index couvrant comportant l’ensemble des colonnes incluses dans la requête. Par conséquent, aucune recherche de tableau n’est requise et l’index satisfait l’intégralité de la requête.
Les vues
Les vues de Phoenix fournissent un moyen de surmonter une limite de HBase, où les performances commencent à se dégrader lorsque vous créez plus de 100 tables physiques. Avec les vues de Phoenix, plusieurs tables virtuelles peuvent partager une table HBase physique sous-jacente.
La création d’une vue Phoenix est similaire à l’utilisation d’une syntaxe de vue SQL standard. La différence réside dans le fait que vous définissez des colonnes pour votre vue, en plus des colonnes héritées de sa table de base. Vous pouvez également ajouter de nouvelles colonnes KeyValue.
Par exemple, voici une table physique nommée product_metrics avec la définition suivante :
CREATE TABLE product_metrics (
metric_type CHAR(1) NOT NULL,
created_by VARCHAR,
created_date DATE NOT NULL,
metric_id INTEGER NOT NULL
CONSTRAINT pk PRIMARY KEY (metric_type, created_by, created_date, metric_id));
Définissez une vue sur cette table, avec des colonnes supplémentaires :
CREATE VIEW mobile_product_metrics (carrier VARCHAR, dropped_calls BIGINT) AS
SELECT * FROM product_metrics
WHERE metric_type = 'm';
Pour ajouter plus de colonnes ultérieurement, utilisez l’instruction ALTER VIEW.
Analyse d’évitement
Ce type d’analyse utilise une ou plusieurs colonnes d’un index composite pour rechercher des valeurs distinctes. Contrairement à une analyse de plage, l’analyse d’évitement implémente un examen interligne, ce qui génère des performances améliorées. Durant l’analyse, la première valeur correspondante est ignorée avec l’index jusqu’à identification de la valeur suivante.
Une analyse d’évitement utilise l’énumération SEEK_NEXT_USING_HINT du filtre HBase. À l’aide de SEEK_NEXT_USING_HINT, l’analyse d’évitement effectue le suivi des ensembles ou des plages de clés recherchés pour chaque colonne. L’analyse d’évitement utilise ensuite une clé qui lui a été passée durant l’évaluation de filtre et détermine s’il s’agit de l’une des combinaisons. Si ce n’est pas le cas, l’analyse d’évitement identifie la clé supérieure suivante à laquelle accéder.
Transactions
Si HBase fournit des transactions de niveau ligne, Phoenix s’intègre avec Tephra pour ajouter une prise en charge des transactions interlignes et inter-tables avec une sémantique ACID complète.
Comme cela se passe avec les transactions SQL traditionnelles, les transactions générées via le gestionnaire de transactions Phoenix vous permettent de garantir qu’une unité atomique des données fait effectivement bien l’objet d’une opération upsert ; vous pouvez ici annuler la transaction si l’opération upsert est mise en échec sur une table de transactions.
Pour activer les transactions Phoenix, consultez la documentation sur les transactions Apache Phoenix.
Pour créer une table de transactions, définissez la propriété TRANSACTIONAL sur true dans une instruction CREATE :
CREATE TABLE my_table (k BIGINT PRIMARY KEY, v VARCHAR) TRANSACTIONAL=true;
Pour modifier une table existante afin qu’elle prenne en charge les transactions, utilisez la même propriété dans une instruction ALTER :
ALTER TABLE my_other_table SET TRANSACTIONAL=true;
Notes
Vous ne pouvez pas modifier une table transactionnelle de manière à ce qu’elle ne prenne plus en charge les transactions.
Tables « salted »
Un hotspotting du serveur de la région peut se produire lors de l’écriture d’enregistrements avec des clés séquentielles sur HBase. Bien que vous puissiez disposer de plusieurs serveurs de région dans votre cluster, vos écritures s’exécutent toutes dans un seul d’entre eux. Cette concentration génère la problématique du « hotspotting » au cours de laquelle un seul serveur gère la charge de travail des écritures, qui n’est donc pas distribuée entre toutes les instances disponibles. Dans la mesure où chaque région présente une taille maximale prédéfinie, une région atteignant sa taille limite est divisée en plusieurs régions de taille plus réduite. Le cas échéant, l’une de ces nouvelles régions stocke l’ensemble des nouveaux enregistrements, en devenant de fait le nouveau point d’accès.
Pour pallier ce problème et atteindre de meilleures performances, divisez au préalable les tables de manière à ce que l’ensemble des serveurs de région soient utilisés de la même manière. Phoenix fournit des tables « salted », qui ajoutent de manière transparente l’octet de « salting » à la clé de ligne d’une table particulière. La table est pré-fractionnée sur les limites de l’octet de « salting », ceci pour garantir une distribution égale de la charge entre les serveurs de région durant la phase initiale de la table. Cette approche distribue la charge de travail d’écriture entre tous les serveurs de région disponibles, améliorant de fait les performances d’écriture et de lecture. Pour saler une table, spécifiez la propriété de table SALT_BUCKETS une fois que la table est créée :
CREATE TABLE Saltedweblogs (
transactionid varchar(500) Primary Key,
transactiondate Date NULL,
customerid varchar(50) NULL,
bookid varchar(50) NULL,
purchasetype varchar(50) NULL,
orderid varchar(50) NULL,
bookname varchar(50) NULL,
categoryname varchar(50) NULL,
invoicenumber varchar(50) NULL,
invoicestatus varchar(50) NULL,
city varchar(50) NULL,
state varchar(50) NULL,
paymentamount DOUBLE NULL,
quantity INTEGER NULL,
shippingamount DOUBLE NULL) SALT_BUCKETS=4;
Activer et paramétrer Phoenix avec Apache Ambari
Un cluster HDInsight HBase comprend l’interface utilisateur Ambari permettant d’effectuer des modifications de configuration.
Pour activer ou désactiver Phoenix, et contrôler les paramètres de temporisation des requêtes Phoenix, connectez-vous à l’interface utilisateur web Ambari (
https://YOUR_CLUSTER_NAME.azurehdinsight.net) à l’aide de vos informations d’identification utilisateur Hadoop.Sélectionnez HBase dans la liste des services du menu de gauche, puis sélectionnez l’onglet Configurations.
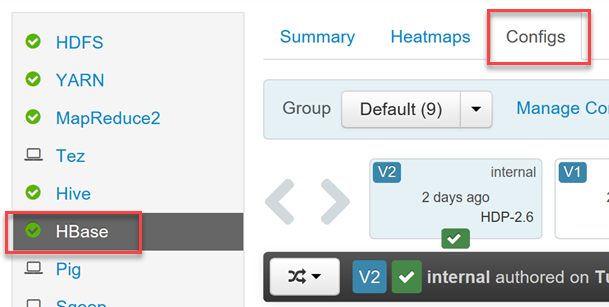
Recherchez la section de configuration Phoenix SQL pour activer ou désactiver Phoenix, puis définissez la temporisation des requêtes.