Cet article offre une vue d’ensemble technique de l’utilisation de Microsoft Azure pour prendre en charge et améliorer le calculs des risques de Grid Computing dans le secteur bancaire. Il explore les systèmes recommandés et les architectures générales.
Ce document s’adresse aux architectes de solutions, et dans une moindre mesure, aux décideurs techniques, qui souhaitent une présentation approfondie des solutions proposées pour le calcul des risques.
Introduction
Les modèles d’analyse des risques financiers sont généralement traités sous la forme de traitements par lots. Ils comportent des charges de calcul importantes qui génèrent une demande élevée en puissance de calcul, en accès aux données et en analyse. La demande en calculs des risques de Grid Computing augmente souvent avec le temps, et les besoins en ressources de calcul augmentent avec elle.
Grâce au large éventail de produits et services Azure, la plupart des problèmes ont plusieurs solutions. Cet article fournit une vue d’ensemble des technologies, modèles et pratiques qui sont les plus efficaces pour une solution de calcul des risques de Grid Computing dans le secteur bancaire qui utilise Microsoft Azure Batch.
Azure Batch est un service gratuit qui fournit des solutions économiques et sécurisées. Les solutions sont à la fois pour l’infrastructure et pour les diverses étapes du traitement par lots qui sont généralement utilisées avec les modèles de Grid Computing pour le calcul des risques. Azure Batch peut étendre et même remplacer vos ressources de calcul locales actuelles en utilisant des réseaux hybrides ou en déplaçant l’intégralité du traitement par lots vers Azure. Les données peuvent entrer et sortir constamment du cloud, ou rester dans un emplacement local. D’autres données peuvent être traitées par les nœuds de calcul selon un modèle de « cloud bursting » lorsque les ressources locales viennent à manquer.
Anatomie d’une exécution Azure Batch
En général, un minimum de deux applications sont impliquées dans une exécution de Batch. L’une de ces applications, qui est généralement exécutée sur un « nœud principal », envoie le travail au pool et parfois, orchestre les nœuds de calcul. L’orchestration peut également être configurée via le portail Azure. L’autre application est exécutée par les nœuds de calcul en tant que tâche (voir Figure 1).
L’application de nœud de calcul effectue la tâche qui consiste à traiter en parallèle les fichiers de modélisation des risques. Plusieurs applications peuvent être installées et exécutées sur les nœuds de calcul.
Ces applications peuvent être chargées dans l’API Batch, directement à l’aide du portail Azure ou via les commandes Azure CLI pour Batch.

Figure 1 : Grid Computing Azure Batch
Une exécution Azure Batch se compose de plusieurs éléments logiques. La Figure 2 montre le modèle logique d’un traitement par lots. Un pool sert de conteneur pour les machines virtuelles qui sont impliquées dans l’exécution de Batch. Il provisionne les machines virtuelles des nœuds de calcul. Un pool sert également de conteneur pour les applications installées sur les nœuds de calcul. Les travaux sont créés et exécutés dans le pool. Les tâches sont exécutées par les travaux. Les tâches sont une exécution de l’application worker et sont appelées par une instruction de ligne de commande.
L’application worker est installée sur le nœud de calcul lors de sa création.
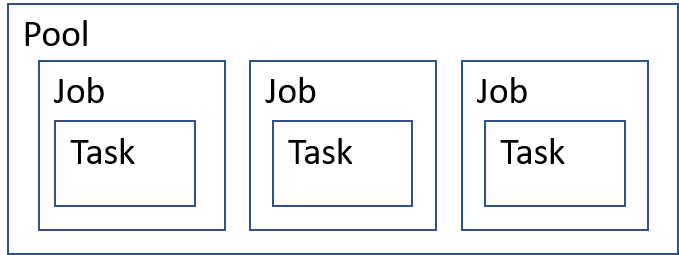
Figure 2 : Modèle de concept Batch logique
Lorsque le travail s’exécute, le pool provisionne toutes les machines virtuelles worker nécessaires, puis installe les applications worker. Le travail affecte des tâches à ces nœuds de calcul qui, à leur tour, exécutent une instruction de ligne de commande. Le script d’interface de ligne de commande appelle généralement les applications ou les scripts installés.
L’utilisation de Batch nécessite généralement de suivre un modèle de prototype, décrit ci-dessous :
- Créez un groupe de ressources pour contenir les ressources Batch.
- Dans le nouveau groupe de ressources, créez un compte Batch.
- Créez un compte de stockage lié.
- Créez un pool dans lequel vous pouvez provisionner les machines virtuelles worker.
- Chargez l’application de nœud de calcul ou les scripts dans le pool.
- Créez un travail pour affecter des tâches aux machines virtuelles du pool.
- Ajoutez le travail au pool.
- Démarrez l’exécution de Batch.
- Le travail place les tâches dans une file d’attente en vue de les exécuter sur les nœuds de calcul.
- Les nœuds de calcul exécutent les tâches au fur et à mesure que les machines virtuelles deviennent disponibles.
Ce processus est illustré à la Figure 3.

Figure 3 : Modèle de concept Batch logique
Une fois que les tâches sont terminées, vous pouvez supprimer les nœuds de calcul que vous n’utilisez pas afin de ne pas payer les frais liés à leur utilisation. Pour les supprimer, par le biais de code ou du portail, vous pouvez supprimer le pool qui contient les machines virtuelles worker.
Pour obtenir des procédures pas à pas sur la façon de bien commencer avec Batch, consultez les Guides de démarrage rapide de 5 minutes, qui vous expliquent le processus dans différentes langues et qui expliquent également comment utiliser le portail Azure.
Planification du processus d’exécution par lots
Azure Batch comprend un planificateur intégré qui vous permet de planifier chaque exécution dans le portail ou via des API. Le planificateur de travaux Batch peut définir plusieurs planifications afin de déclencher plusieurs travaux. Chaque travail a ses propres propriétés, comme son rôle, son début et sa fin. Les planifications de travaux peuvent être définies à intervalles réguliers ou pour une unique exécution.
De nombreux systèmes de Grid Computing pour le secteur bancaire ont déjà leur propre service de planification. Il n’est pas forcément nécessaire de déplacer immédiatement mon planificateur vers Azure. Cela peut fonctionner sans interruption, car Azure Batch peut être appelé manuellement ou par le biais d’un SDK. Cette fonctionnalité permet à la planification de toujours se produire en local et de traiter des charges de travail dans Azure.
Le traitement par lots peut se produire suivant une planification prédéterminée ou à la demande. Dans les deux cas, il est inutile de maintenir les machines virtuelles à nœuds de calcul en activité si vous ne les utilisez pas. Lorsque vous utilisez des centaines, voire des milliers de nœuds de calcul de machine virtuelle, vous pouvez réaliser d’importantes économies en déprovisionnant les serveurs lorsqu’ils ont terminé d’exécuter les tâches de la file d’attente.
Applications de nœud de calcul
Les nœuds de calcul ont besoin d’une application pour s’exécuter quand une tâche est appelée. Ces applications sont écrites par l’entreprise dans le but d’exécuter les travaux de traitement après leur installation sur les workers. Dans les scénarios de Grid Computing pour le calcul des risques dans le secteur bancaire, cette application se charge de convertir les données dans des formats convenant tout particulièrement à l’analytique en aval ou à autres traitements.
Lorsque vous fournissez l’application au pool pour la distribution aux nœuds de calcul, celle-ci est chargée sous la forme d’un package d’application. Il peut s’agir d’une autre version d’un package d’application précédemment chargé. Vous pouvez installer plusieurs packages d’application sur un nœud de calcul. Le travail contient les packages d’application à charger sur les machines worker.
Le déploiement d’un package d’application peut également être géré par version. Si plusieurs versions d’un même package d’application ont été chargées dans un pool, l’une d’elles peut être désignée pour être utilisée dans une exécution de Batch, comme illustré à la Figure 4. Cela peut se révéler nécessaire dans les environnements d’audit ou lorsque l’entreprise souhaite reproduire une exécution précédente. Cela peut également servir à des fins de restauration si un bogue est provoqué dans l’application worker.

Figure 4 : Gestion des versions des applications de tâches des nœuds de calcul
Un package d’application est chargé dans le pool sous la forme d’un fichier .zip. Ce fichier contient les fichiers binaires de l’application et les fichiers de prise en charge dont les tâches ont besoin pour exécuter l’application. Il existe deux étendues pour les packages d’application. Vous pouvez désigner un package d’application dans l’étendue du pool ou dans l’étendue des tâches.
Packages d’application des pools
Ces packages sont déployés sur tous les nœuds d’un pool. Lorsqu’une machine virtuelle à nœuds de calcul est provisionnée, redémarrée ou réinitialisée, une nouvelle copie de tous les packages d’application de pool est installée s’il existe une application mise à jour. Un ou plusieurs packages d’application peuvent être affectés à un pool, ce qui signifie que les nœuds de calcul affecteront tous les packages.
Packages d’application de tâches
Les packages d’application qui ciblent au niveau de la tâche sont uniquement installés sur les nœuds de calcul planifiés pour exécuter une tâche. Les packages d’application de tâches sont destinés à être utilisés lorsque plusieurs travaux sont exécutés dans un pool.
Les applications de tâches sont utiles lors de l’agrégation de données produites par les travaux au niveau du pool. Ces applications peuvent servir dans les scénarios de Grid Computing de calcul des risques. Par exemple, une application de tâches peut exécuter un ensemble de calculs des risques qui génèrent les données à utiliser ultérieurement dans le workflow de calcul des risques.
Mise à l’échelle des traitements par lots
Les banques effectuent souvent leurs exécutions par lots d’analyse des risques pendant le week-end ou pendant la nuit, lorsque les ressources informatiques sont le moins exploitées. Même si ce modèle fonctionne pour certains, il peut rapidement devenir insuffisant et nécessiter l’ajout d’autres machines worker au réseau de machines.
Si l’exécution des travaux Azure Batch est trop longue ou si vous souhaitez davantage de puissance de calcul pour vos exécutions de Batch, Azure vous propose plusieurs options.
- Allouer plus de machines de nœud de calcul pour un scale-out
- Allouer des machines de nœud de calcul plus puissantes pour un scale-up. Les machines Azure peuvent être provisionnées pour répondre aux besoins de hautes performances des cœurs, de la mémoire et même de la puissance de calcul du GPU.
Remarque : L’utilisation du modèle Microsoft HPC Pack avec Batch est plus complexe, et n’est pas abordée dans cet article.
Dans un cluster de traitement Batch, vous pouvez n’avoir que deux machines virtuelles de traitement uniquement. Ou vous pouvez aussi bien avoir des milliers de tâches exécutées simultanément sur des milliers de nœuds de calcul de machine virtuelle comprenant des dizaines de milliers de cœurs. Chaque machine virtuelle est chargée d’exécuter une seule tâche à la fois. Dans un pool, le nombre de machines virtuelles peut être mis à l’échelle manuellement ou automatiquement, selon que la charge augmente ou diminue.
Cloud bursting
Lorsque les ressources de calcul d’un réseau d’ordinateurs local viennent à manquer en raison d’un travail d’analyse volumineux, le « cloud bursting » offre un moyen d’étendre ces ressources en ajoutant des nœuds de calcul dans Azure. Le « cloud bursting » est un modèle dans lequel les clouds privés ou l’infrastructure distribuent leur charge de travail aux serveurs cloud lorsque la demande en ressources locales est élevée.
Ces nœuds de calcul peuvent être préconfigurés comme des machines virtuelles Linux ou Windows devant être provisionnées dans la plateforme IaaS d’Azure. En outre, les serveurs peuvent être provisionnés et automatiquement configurés pour fonctionner avec les systèmes existants, tels que Tibco Gridserver et IBM Symphony.
Formules de mise à l’échelle automatique
Cette flexibilité peut être configurée dans le portail Azure ou à l’aide de formules de mise à l’échelle automatique. Les formules de mise à l’échelle automatique sont des scripts qui sont chargés dans le planificateur de traitement par lots pour un contrôle précis du comportement de Batch. La mise à l’échelle automatique dans un pool de nœuds de calcul est effectuée en associant des nœuds à des formules de mise à l’échelle automatique.
L’exemple suivant est une formule de mise à l’échelle automatique indiquant à la mise à l’échelle automatique de commencer par une machine virtuelle et d’effectuer un scale-up jusqu’à 50 machines virtuelles maximum, selon les besoins. Lorsque les tâches se terminent, les machines virtuelles se libèrent une par une, et la formule de mise à l’échelle automatique réduit le pool.
startingNumberOfVMs = 1;
maxNumberofVMs = 50;
pendingTaskSamplePercent = $PendingTasks.GetSamplePercent(180 * TimeInterval_Second);
pendingTaskSamples = pendingTaskSamplePercent < 70 ? startingNumberOfVMs : avg($PendingTasks.GetSample(180 * TimeInterval_Second));
$TargetDedicatedNodes=min(maxNumberofVMs, pendingTaskSamples);
Autres techniques de mise à l’échelle
La mise à l’échelle automatique peut également être activée par l’applet de commande Enable-AzureBatchAutoScale de PowerShell. L’applet de commande Enable-AzureBatchAutoScale permet la mise à l’échelle automatique du pool spécifié. Un exemple suit.
- La première commande définit une formule, puis l’enregistre dans la variable
$Formula. - La deuxième commande permet la mise à l’échelle automatique du pool nommé
RiskGridPoolà l’aide de la formule de$Formula.
C:\> $Formula = ‘startingNumberOfVMs = 1;
maxNumberofVMs = 50;
pendingTaskSamplePercent = $PendingTasks.GetSamplePercent(180 * TimeInterval_Second?WT.mc_id=gridbanksg-docs-dastarr);
pendingTaskSamples = pendingTaskSamplePercent < 70 ? startingNumberOfVMs : avg($PendingTasks.GetSample(180 * TimeInterval_Second));
$TargetDedicatedNodes=min(maxNumberofVMs, pendingTaskSamples);’;
C:\> Enable-AzureBatchAutoScale -Id "RiskGridPool" -AutoScaleFormula $Formula -BatchContext $Context
La mise à l’échelle peut également être effectuée dans l’interface Azure CLI avec la commande az batch pool resize et à l’aide du portail Azure.
Stockage et conservation des données
Une fois que les données sont ingérées et traitées par un nœud de calcul, les données de sortie obtenues peuvent être stockées dans une base de données. Les données de sortie peuvent être ensuite traitées et analysées ou transformées lors de leur ingestion, avant d’être stockées, pour que leur format soit adapté au traitement en aval. Microsoft Azure offre plusieurs options de stockage. Le choix de la technologie à utiliser pour stocker les données dépend en grande partie de l’analyse ou des besoins en rapports des processus en aval.
Lorsque vous utilisez un réseau hybride, la cible de stockage de données peut être locale. Lorsque vous utilisez Batch sur un réseau hybride, les nœuds de calcul peuvent réécrire des données dans un magasin de données local sans utiliser un emplacement de stockage Azure. Les workers peuvent également écrire des données dans le Stockage Fichier Azure, qui peut être monté en tant que disque sur une machine locale. Cette configuration permet à tous les processus qui utilisent les fichiers localement d’y accéder facilement.
Surveillance et journalisation
Pour optimiser les futures exécutions du travail Batch, les données doivent être enregistrées afin d’identifier les zones d’optimisation. Par exemple, si l’exécution de workers est proche de la capacité maximale de l’UC, l’ajout de cœurs aux nœuds de calcul permet de ne pas dépendre du processeur et d’exécuter la tâche plus rapidement. Chaque exécution d’application du travail Batch a ses propres caractéristiques. Par conséquent, les optimisations apportées aux machines virtuelles des exécutions de Batch peuvent différer. Pour les tâches utilisant beaucoup de mémoire, vous pouvez allouer davantage de mémoire en configurant les machines différemment lors de l’exécution suivante.
La journalisation peut être effectuée par les applications de nœud de calcul et les applications principales de réseau, ou par un travail utilisant la journalisation des diagnostics Batch. La journalisation des informations concernant les performances des exécutions de Batch peut être configurée pour identifier les zones à améliorer afin d’obtenir de meilleures performances et une exécution des tâches plus rapide.
Supervision et journalisation Batch personnalisées
L’application de contrôle et les applications de nœud de calcul peuvent générer ces données et les stocker pour une analyse plus approfondie. Les données utiles à l’optimisation des travaux Batch sont les suivantes :
- Heure de début et de fin de chaque tâche
- Heure à laquelle chaque nœud de calcul est actif et exécute des tâches
- Heure à laquelle chaque nœud de calcul est inactif et n’exécute pas de tâches
- Durée globale d’exécution des traitements par lots
Journalisation des diagnostics Batch
Il existe une alternative à l’utilisation des applications de contrôleur et de nœud de calcul pour l’émission de données d’instrumentation. La journalisation des diagnostics Batch peut capturer une grande partie des données d’exécution. La journalisation des diagnostics Batch n’est pas activée par défaut et doit être activée pour le compte Batch.
La journalisation des diagnostics Batch fournit une quantité importante de données, ce qui facilite la résolution des problèmes et l’optimisation des exécutions de Batch. Heure de début et de fin des travaux et des tâches, nombre de cœurs, nombre total de nœuds et nombreuses autres métriques.
La journalisation Batch nécessite une destination de stockage pour les journaux émis, les événements de stockage produits par les exécutions de Batch tels que la création de pools, l’exécution de travaux, l’exécution de tâches, etc. Outre le stockage d’événements du journal de diagnostic dans un compte de Stockage Azure, vous pouvez diffuser des événements de journal de service Batch sur une instance d’Azure Event Hubs. Les événements peuvent ensuite être envoyés à Azure Log Analytics.
À l’aide de ces données, vous pouvez optimiser les applications de calcul principales et les applications de nœud principal. Cela vous permet de réduire les coûts, par exemple en déprovisionnant plus rapidement les machines virtuelles worker dont vous n’avez plus besoin, au lieu d’attendre la fin de l’exécution de Batch.
Outils de gestion Batch
Le portail Azure fournit un tableau de bord de supervision Batch où se trouvent des informations concernant Batch, comme les travaux en cours et même l’utilisation du quota de comptes. Il est suffisant pour de nombreuses applications de travaux Batch.
Outre les outils de gestion et de visualisation Batch qui sont disponibles dans le portail Azure, il existe un outil open-source gratuit nommé Batch Explorer pour gérer Batch. Il s’agit d’un outil client autonome qui permet de créer, de déboguer et de superviser les applications Azure Batch. Téléchargez un package d’installation pour Mac, Linux ou Windows.
Modèles de réseaux
L’analyse des risques nécessite souvent l’ingestion de centaines, voire de milliers de documents dans le processus de Grid Computing de calcul des risques. Ces fichiers sont souvent stockés localement dans un magasin de fichiers, un partage réseau ou autre référentiel. Lorsque vous utilisez des machines virtuelles Azure pour accéder à ces fichiers et les traiter, il est souvent utile que le réseau local soit connecté sans interruption au réseau Azure de sorte que l’accès aux fichiers soit simple et rapide. Avec cette méthode, il arrive que vous n’ayez même pas à modifier le code exécutant le processus sur les nœuds de calcul.
Azure propose deux modèles pour connecter de façon fiable et sécurisée les systèmes locaux à Azure : Microsoft Azure ExpressRoute et la passerelle VPN. Il s’agit de solutions de connectivité fiables, qui présentent cependant des différences au niveau de l’implémentation, des performances et autres attributs.
Le nœud principal de Grid Computing pour le calcul des risques peut se trouver à un emplacement local, et exécuter le travail Batch via les API REST ou les SDK, en .NET et dans d’autres langages.
Il existe d’autres techniques qui permettent de combler le fossé entre Azure et les ressources locales sans avoir à utiliser de solution réseau hybride. Pour plus d’informations, consultez les sections ci-dessous.
ExpressRoute
ExpressRoute lie votre réseau local ou votre réseau de centre de données à Azure via une connexion privée assurée par un partenaire de connectivité, tel que votre fournisseur de services Internet. Ainsi, les deux réseaux se voient comme étant une seule et même instance réseau, ce qui facilite l’accès entre les deux réseaux. L’intégration réseau est essentielle si vous souhaitez intégrer des systèmes locaux existants à un réseau Azure, et qu’ExpressRoute propose des connexions les plus rapides possible.
Pour plus d’informations sur les tarifs Azure ExpressRoute, cliquez ici.
Passerelle VPN
Un autre moyen de connecter votre réseau à Azure est d’utiliser une passerelle VPN. L’inconvénient de ce modèle est que le trafic passe par Internet. Par conséquent, la connexion peut être moins résiliente et la vitesse réseau ne peut pas atteindre celle d’ExpressRoute. Toutefois, cela n’est pas nécessairement un obstacle pour les scénarios de Grid Computing de calcul des risques, car la lecture des fichiers de données est généralement rapide.
Pour plus d’informations sur les tarifs de la passerelle VPN, cliquez ici.
Options de connectivité
Il existe essentiellement deux modèles pour étendre votre réseau à Azure, comme illustré à la figure 5.
- Passerelle virtuelle - De site à site
- ExpressRoute – Exchange ou fournisseur de services Internet
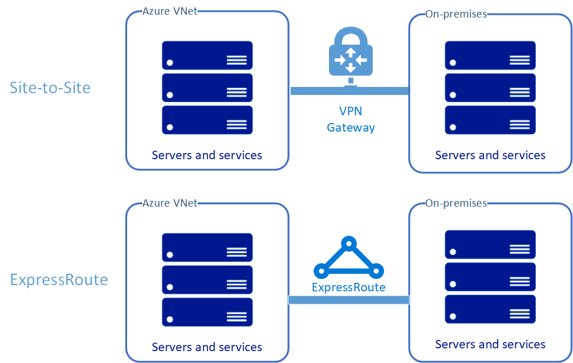
Figure 5 : Site à site et ExpressRoute
Intégration de site à site de la passerelle virtuelle
Une passerelle VPN de site à site connecte votre réseau local au réseau virtuel Azure. Vous réduisez ainsi le fossé entre les réseaux qui font partie d’un même réseau, ce qui fournit un accès bidirectionnel aux ressources, aux serveurs et aux artefacts. Ainsi, vous pouvez accéder directement aux fichiers de données qui se trouvent sur les machines virtuelles worker Azure qui exécutent le traitement par lots de Grid Computing.
Intégration d’ExpressRoute
Une connexion ExpressRoute assurée par un fournisseur de réseau partenaire Azure offre les mêmes avantages qu’une connexion site à site, mais avec une fiabilité et une vitesse supérieures.
Obtenez plus d’informations sur les modèles de connectivité ExpressRoute.
Traitement par lots sans réseau hybride Azure
Un autre scénario de traitement par lots est celui qui implique le chargement de tous les fichiers de données dans le stockage Azure en vue d’un traitement ultérieur par machines virtuelles de calcul Azure. Le Stockage Fichier et le Stockage Blob constituent de bonnes options pour le stockage des données de Grid Computing pour le calcul des risques.
Dans ce scénario, le contrôleur de travaux et tous les nœuds de calcul se trouvent dans Azure, comme illustré à la Figure 6. Pour les données traitées, la destination la plus probable est un magasin de données Azure. Elles y sont stockées en vue d’être traitées ultérieurement par des solutions Azure Machine Learning ou autres systèmes. Ce traitement supplémentaire n’est pas abordé dans cet article.

Figure 6 : Cycle de vie Batch : du chargement à l’exécution
Ressources de connectivité du réseau hybride
Plusieurs configurations peuvent s’appliquer à votre situation. Pour obtenir de l’aide concernant les décisions à prendre ainsi que des conseils d’architecture pour connecter votre réseau à Azure, consultez l’article Connecter un réseau local à Azure, dans le groupe Modèles et pratiques.
- Pour d’autres configurations de passerelle VPN, consultez cet article.
- Consultez des informations supplémentaires sur les modèles de connectivité ExpressRoute.
- Calculez les tarifs ExpressRoute.
- Calculez les tarifs de la passerelle VPN.
Considérations relatives à la sécurité
Vous pouvez créer un réseau virtuel Azure, puis y créer les nœuds de calcul du pool. Cela fournit un niveau supplémentaire d’isolation pour les exécutions de Batch, et permet l’authentification à l’aide de Microsoft Entra ID. Pour plus d’informations, consultez Configuration du réseau de pools.
Il existe deux manières d’authentifier une application Batch à l’aide de Microsoft Entra ID :
L’authentification intégrée. Une application Batch qui utilise des comptes Microsoft Entra peut utiliser ces derniers pour obtenir les ressources des magasins de données et d’autres ressources.
Le principal du service. Les principaux de service Microsoft Entra définissent la stratégie d’accès, et les autorisations des utilisateurs et des applications. Un principal de service permet aux utilisateurs de s’authentifier à l’aide d’une clé secrète liée à cette application. Vous pouvez ainsi authentifier une application sans assistance avec une clé secrète. Un principal de service définit la stratégie et les autorisations pour une application afin de représenter l’application lors de l’accès aux ressources au moment de l’exécution. En savoir plus ici.
Pour plus d’informations sur la sécurité lors des traitements par lots avec Microsoft Entra ID, consultez cet article.
Le service Batch peut également s’authentifier avec une clé partagée. Le service d’authentification nécessite l’ajout de deux valeurs d’en-tête dans la requête HTTP, les données et l’autorisation. Pour plus d’informations sur l’authentification par clé partagée, cliquez ici.
Optimisation des coûts
L’utilisation d’Azure Batch n’engendre pas de frais. Vous payez uniquement pour les ressources sous-jacentes consommées, telles que les machines virtuelles actives, le stockage et le réseau. Toutefois, l’utilisation des machines virtuelles à nœuds de calcul est facturée même lorsque celles-ci sont inactives. Il est donc conseillé de déprovisionner les machines dont vous n’avez plus besoin. Pour cela, la méthode la plus courante consiste à supprimer le pool qui les contient.
Lorsque vous créez un pool, vous pouvez spécifier les types de nœuds de calcul souhaités et leur nombre pour chaque type. Les deux types de nœuds de calcul sont les suivants :
Les nœuds de calcul dédiés sont réservés à vos charges de travail. Ils sont plus chers que les nœuds à faible priorité, mais sont assurés de ne jamais être préemptés.
Les nœuds de calcul à faible priorité tirent profit de la capacité excédentaire dans Azure pour exécuter vos charges de travail Batch. Le coût horaire des nœuds à faible priorité est moins élevé que celui des nœuds dédiés. Par ailleurs, ces nœuds activent des charges de travail nécessitant une importante puissance de calcul. Pour plus d’informations, consultez Utiliser des machines virtuelles à faible priorité avec Batch.
Les nœuds dédiés et à faible priorité peuvent se trouver dans un même pool.
Pour obtenir les informations de tarification des nœuds de calcul dédiés et à faible priorité, consultez Tarification du service Batch.
Lorsque vous utilisez le service de journalisation des diagnostics Batch, les données émises vers le stockage Azure impliquent des frais. Il s’agit de données de stockage ordinaires, et les tarifs sont impactés par la quantité de données de diagnostic conservées.
Prise en main
Même si vous avez plusieurs possibilités pour vous attaquer à un domaine aussi complexe que celui du Batch Computing pour le Grid Computing de calcul des risques, voici quelques points de départ logiques qui vous permettront de mieux comprendre la technologie Batch.
La documentation Azure Batch est un excellent point de départ. La documentation comprend des exemples de portail, des références d’API et des tutoriels pas à pas avec des exemples de code. Les exemples d’applications Azure Batch sont également disponibles gratuitement sur GitHub.
Voici quelques tutoriels rapides qui vous permettront de créer une application simple afin de créer et d’exécuter des travaux de calcul par lots. Voici les options disponibles pour créer l’application :
- API .NET Batch
- SDK Batch pour Python
- SDK Batch pour Node.js
- Gestion de Batch avec PowerShell
- Gestion de Batch avec Azure CLI
Vous pouvez lancer une initiative de preuve de concept. Quelle sera votre approche pour l’ingestion des données dans Azure ? Allez-vous utiliser un réseau hybride, ou charger des données via un SDK ou une interface REST ? Si vous envisagez d’utiliser un réseau hybride, vous pouvez lancer un pilote pour le mettre en place.
Évaluez la taille de vos travaux de calcul Batch, puis sélectionnez la solution de mise à l’échelle adaptée. Les formules de mise à l’échelle automatique conviennent aux scénarios de planification complexes, tandis que les scénarios plus simples peuvent être réalisés à l’aide du portail Azure.
Components
Azure Batch fournit des fonctionnalités permettant d’exécuter des travaux de traitement parallèle à grande échelle dans le cloud.
Microsoft Entra ID est un service multilocataire de gestion des identités basé sur le cloud, qui combine les principaux services d’annuaire, la gestion des accès aux applications et la protection des identités dans une seule solution.
Les formules de mise à l’échelle automatique sont des scripts qui sont chargés dans le planificateur de traitement par lots pour un contrôle précis du comportement de mise à l’échelle de Batch.
La journalisation des diagnostics Batch est une fonctionnalité d’Azure Batch qui permet de créer un journal détaillé à partir de vos exécutions de Batch et des événements générés. Les journaux d’activité sont stockés dans le Stockage Azure.
Batch Explorer est une application autonome qui permet une supervision et une gestion Batch disponibles de Windows, macOS et Linux.
ExpressRoute est une solution réseau hybride ultrarapide et fiable qui permet de joindre des réseaux locaux et Azure.
La passerelle VPN Azure est une solution réseau hybride qui utilise Internet pour joindre des réseaux locaux et Azure.
Conclusion
Ce document vous a fourni une vue d’ensemble des solutions techniques ainsi que des conseils pour l’utilisation d’Azure Batch dans un contexte de Grid Computing pour le calcul des risques dans le secteur bancaire. L’article a abordé un grand nombre de sujets, de la définition d’Azure Batch aux options réseau en passant par les coûts impliqués.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteurs principaux :
- David Starr | Architecte principal de solutions
Étapes suivantes
Si vous souhaitez aller plus loin dans l’évaluation d’Azure Batch pour le Grid Computing de calcul des risques, consultez cette page. Vous y trouverez des tutoriels sur le traitement parallèle des fichiers, qui est inhérent au Grid Computing de calcul des risques. Les tutoriels sont fournis à l’aide du portail Azure, d’Azure CLI, de .NET et de Python.
Documentation du produit :
- Présentation d’Azure Batch
- Qu’est-ce que Microsoft Entra ID ?
- Qu’est-ce qu’Azure ExpressRoute ?
- Qu’est-ce qu’une passerelle VPN ?