Composant Exécuter un script R
Cet article explique comment utiliser le composant Exécuter un script R pour exécuter du code R dans votre pipeline de concepteur Azure Machine Learning.
R vous permet d’effectuer des tâches qui ne sont pas prises en charge par les composants existants, telles que :
- Créer des transformations de données personnalisées
- Utiliser vos propres métriques pour évaluer des prédictions
- Générer des modèles à l’aide d’algorithmes qui ne sont pas implémentés en tant que composants autonomes dans le concepteur
Prise en charge de la version de R
Le concepteur Azure Machine Learning utilise la distribution CRAN (Comprehensive R Archive Network) de R. La version actuellement utilisée est CRAN 3.5.1.
Packages R pris en charge
L’environnement R est préinstallé avec plus de 100 packages. Pour obtenir la liste complète, consultez la section Packages R préinstallés.
Vous pouvez également ajouter le code suivant à tout composant Exécuter un script R pour afficher les packages installés.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
dataframe1 <- data.frame(installed.packages())
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Notes
Si votre pipeline contient plusieurs composants Execute R Script et que vous avez besoin de packages qui ne figurent pas dans la liste préinstallée, installez les packages dans chaque composant.
Installation des packages R
Pour installer des packages R supplémentaires, utilisez la méthode install.packages(). Les packages sont installés pour chaque composant Exécuter un script R. Elles ne sont pas partagées entre les autres composants Exécuter un script R.
Notes
Il n’est PAS recommandé d’installer le package R à partir du groupe de scripts. Il est recommandé d’installer les packages directement dans l’éditeur de script.
Spécifiez le référentiel CRAN lors de l’installation de packages, par exemple : install.packages("zoo",repos = "https://cloud.r-project.org").
Avertissement
Le composant d’exécution de script R ne prend pas en charge l’installation de packages pour lesquels une compilation native est nécessaire (par exemple le package qdap qui exige Java et le package drc qui exige C++). En effet, il est exécuté dans un environnement préinstallé avec une autorisation non administrateur.
N’installez pas de packages prédéfinis sous/pour Windows, car les composants du concepteur s’exécutent sous Ubuntu. Pour vérifier si un package est préconfiguré sous Windows, vous pouvez accéder à CRAN et rechercher votre package, télécharger un fichier binaire en fonction de votre système d’exploitation et vérifier la partie Conception : dans le fichier DESCRIPTION. Vous trouverez ci-dessous un exemple : 
Cet exemple montre comment installer Zoo :
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
if(!require(zoo)) install.packages("zoo",repos = "https://cloud.r-project.org")
library(zoo)
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Notes
Avant d’installer un package, vérifiez s’il existe déjà, afin de ne pas répéter l’installation. Les installations répétées peuvent entraîner un dépassement du délai d’attente des demandes de service web.
Accès au jeu de données inscrit
Vous pouvez vous référer à l’exemple de code suivant pour accéder aux jeux de données inscrits dans votre espace de travail :
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
run = get_current_run()
ws = run$experiment$workspace
dataset = azureml$core$dataset$Dataset$get_by_name(ws, "YOUR DATASET NAME")
dataframe2 <- dataset$to_pandas_dataframe()
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Comment configurer le module Exécuter un script R
Le composant Exécuter un script R contient un exemple de code comme point de départ.
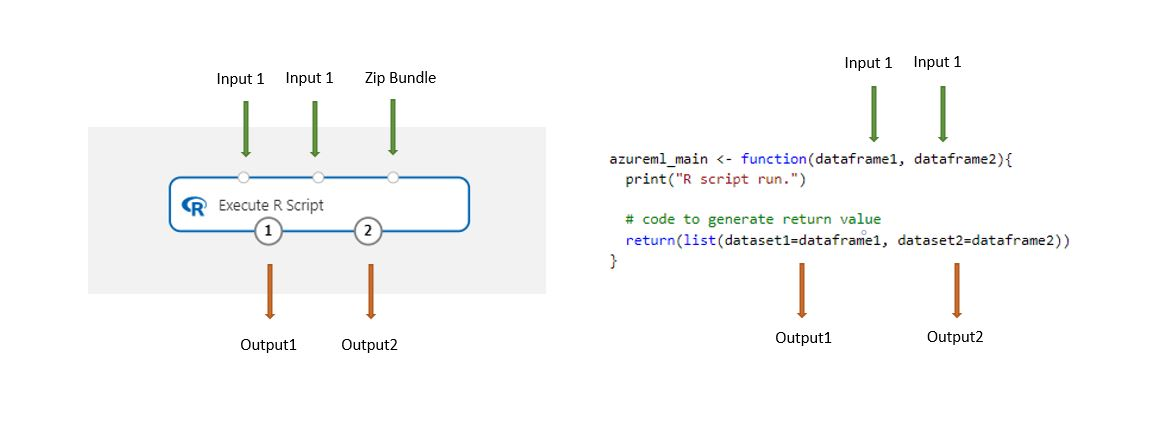
Les jeux de données stockés dans le concepteur sont automatiquement convertis en trame de données R quand ils sont chargés avec ce composant.
Ajoutez le composant Exécuter un script R à votre pipeline.
Connectez les entrées dont le script a besoin. Les entrées sont facultatives et peuvent inclure des données ainsi que du code R supplémentaire.
Dataset1 : Référencez la première entrée en tant que
dataframe1. Le jeu de données d’entrée doit être au format CSV, TSV ou ARFF. Ou vous pouvez connecter un jeu de données Azure Machine Learning.Dataset2 : Référencez la deuxième entrée en tant que
dataframe2. Ce jeu de données doit également se présenter sous la forme d’un fichier CSV, TSV, ARFF, ou d’un jeu de données Azure Machine Learning.ScriptBundle : La troisième entrée accepte des fichiers .zip. Un fichier compressé peut contenir plusieurs fichiers et plusieurs types de fichiers.
Dans la zone de texte Script R, tapez ou collez un script R valide.
Notes
Faites preuve de prudence lors de l’écriture de votre script. Assurez-vous qu’il n’existe pas d’erreurs de syntaxe, comme l’utilisation de variables non déclarées ou de composants ou fonctions non importés. Faites également attention à la liste des packages préinstallés à la fin de cet article. Pour utiliser des packages qui ne sont pas répertoriés, installez-les dans votre script. par exemple
install.packages("zoo",repos = "https://cloud.r-project.org").Pour vous aider à commencer, la zone de texte Script R est préremplie avec un exemple de code, que vous pouvez modifier ou remplacer.
# R version: 3.5.1 # The script MUST contain a function named azureml_main, # which is the entry point for this component. # Note that functions dependent on the X11 library, # such as "View," are not supported because the X11 library # is not preinstalled. # The entry point function MUST have two input arguments. # If the input port is not connected, the corresponding # dataframe argument will be null. # Param<dataframe1>: a R DataFrame # Param<dataframe2>: a R DataFrame azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # If a .zip file is connected to the third input port, it's # unzipped under "./Script Bundle". This directory is added # to sys.path. # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }La fonction de point d’entrée doit avoir les arguments d’entrée :
Param<dataframe1>etParam<dataframe2>, même lorsque ces arguments ne sont pas utilisés dans la fonction.Notes
Les données passées au composant Exécuter le script R sont référencées en tant que
dataframe1etdataframe2, ce qui est différent du concepteur Azure Machine Learning (référence de concepteur en tant quedataset1,dataset2). Vérifiez que les données d’entrée sont référencées correctement dans votre script.Notes
Vous devrez peut-être apporter des modifications mineures au code R existant pour qu’il s’exécute dans un pipeline de concepteur. Par exemple, les données d’entrée que vous fournissez au format CSV doivent être explicitement converties en un jeu de données avant de pouvoir les utiliser dans votre code. Les types de données et de colonnes utilisés dans le langage R diffèrent également à certains égards des types de données et de colonnes utilisés dans le concepteur.
Si la taille de votre script est supérieure à 16 Ko, utilisez le port Script Bundle pour éviter des erreurs comme La ligne de commande dépasse la limite de 16597 caractères.
- Regroupez le script et d'autres ressources personnalisées dans un fichier zip.
- Chargez le fichier zip en tant que jeu de données dans Studio.
- Faites glisser le composant du jeu de données de la liste Jeux de données vers le volet de composant de gauche sur la page de création du concepteur.
- Connectez le composant de jeu de données au port Script Bundle du composant Exécuter le script R.
Voici l’exemple de code permettant d’utiliser le script dans le groupe de scripts :
azureml_main <- function(dataframe1, dataframe2){ # Source the custom R script: my_script.R source("./Script Bundle/my_script.R") # Use the function that defined in my_script.R dataframe1 <- my_func(dataframe1) sample <- readLines("./Script Bundle/my_sample.txt") return (list(dataset1=dataframe1, dataset2=data.frame("Sample"=sample))) }Pour Valeur de départ aléatoire, entrez une valeur à utiliser dans l’environnement R en tant que valeur de départ aléatoire. Ce paramètre revient à appeler
set.seed(value)dans le code R.Envoyez le pipeline.
Résultats
Les composants Exécuter un script R peuvent retourner plusieurs sorties, mais elles doivent être fournies sous forme de trames de données R. Le concepteur convertit automatiquement les trames de données en jeux de données pour assurer la compatibilité avec d’autres composants.
Les erreurs et messages standard de R sont retournés dans le journal du composant.
S’il vous faut imprimer les résultats dans le script R, les résultats imprimés sont disponibles dans 70_driver_log sous l’onglet Sorties + journaux du panneau droit du composant.
Exemples de scripts
Il existe de nombreuses façons d’étendre votre pipeline à l’aide de scripts R personnalisés. Cette section fournit un exemple de code pour les tâches courantes.
Ajouter un script R en tant qu’entrée
Le composant Exécuter un script R prend en charge des fichiers de script R arbitraires en tant qu’entrées. Pour les utiliser, vous devez les télécharger sur votre espace de travail en tant que partie du fichier .zip.
Pour télécharger un fichier. zip contenant du code R dans votre espace de travail, accédez à la page de ressources Jeux de données. Sélectionnez Créer un jeu de données, puis sélectionnez À partir d’un fichier local et l’option de type de jeu de données Fichier.
Vérifiez que le fichier compressé apparaît dans Mes jeux de données sous la catégorie Jeux de données de l’arborescence du composant de gauche.
Connectez le jeu de données au port d’entrée ScriptBundle.
Tous les fichiers dans le fichier .zip sont disponibles pendant la durée d’exécution du pipeline.
Si le fichier de script groupé est contenu dans une structure de répertoires, la structure est conservée. Mais vous devez modifier votre code pour ajouter le répertoire ./ScriptBundle au chemin.
Traitement des données
L’exemple suivant montre comment mettre à l’échelle et normaliser les données d’entrée :
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
# If a .zip file is connected to the third input port, it's
# unzipped under "./Script Bundle". This directory is added
# to sys.path.
series <- dataframe1$width
# Find the maximum and minimum values of the width column in dataframe1
max_v <- max(series)
min_v <- min(series)
# Calculate the scale and bias
scale <- max_v - min_v
bias <- min_v / dis
# Apply min-max normalizing
dataframe1$width <- dataframe1$width / scale - bias
dataframe2$width <- dataframe2$width / scale - bias
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Lire un fichier .zip en tant qu’entrée
Cet exemple montre comment utiliser un jeu de données dans un fichier .zip en tant qu’entrée pour le composant Exécuter un script R.
- Créez le fichier de données au format CSV et nommez-le mydatafile.csv.
- Créez un fichier .zip et ajoutez le fichier CSV à l’archive.
- Chargez le fichier compressé sur votre espace de travail Azure Machine Learning.
- Connectez le jeu de données obtenu à l’entrée ScriptBundle de votre composant Exécuter un script R.
- Utilisez le code suivant pour lire les données CSV du fichier compressé.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
mydataset<-read.csv("./Script Bundle/mydatafile.csv",encoding="UTF-8");
# Return datasets as a Named List
return(list(dataset1=mydataset, dataset2=dataframe2))
}
Répliquer des lignes
Cet exemple montre comment répliquer des enregistrements positifs dans un jeu de données pour équilibrer l’échantillon :
azureml_main <- function(dataframe1, dataframe2){
data.set <- dataframe1[dataframe1[,1]==-1,]
# positions of the positive samples
pos <- dataframe1[dataframe1[,1]==1,]
# replicate the positive samples to balance the sample
for (i in 1:20) data.set <- rbind(data.set,pos)
row.names(data.set) <- NULL
# Return datasets as a Named List
return(list(dataset1=data.set, dataset2=dataframe2))
}
Passer des objets R entre des composants Exécuter un script R
Vous pouvez passer des objets R entre des instances du composant Exécuter un script R en utilisant le mécanisme de sérialisation interne. Cet exemple suppose que vous souhaitez déplacer l’objet R nommé A entre deux composants Exécuter un script R.
Ajoutez le premier composant Exécuter un script R à votre pipeline. Puis, dans la zone de texte Script R, entrez le code suivant pour créer un objet sérialisé
Aen tant que colonne dans la table de données de sortie du composant :azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # some codes generated A serialized <- as.integer(serialize(A,NULL)) data.set <- data.frame(serialized,stringsAsFactors=FALSE) return(list(dataset1=data.set, dataset2=dataframe2)) }La conversion explicite en type entier est effectuée, car la fonction de sérialisation génère des données au format R
Raw, qui n’est pas pris en charge par le concepteur.Ajoutez une deuxième instance du composant Exécuter un script R et connectez-la au port de sortie du composant précédent.
Tapez le code suivant dans la zone de texte Script R pour extraire l’objet
Ade la table de données d’entrée.azureml_main <- function(dataframe1, dataframe2){ print("R script run.") A <- unserialize(as.raw(dataframe1$serialized)) # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }
Packages R préinstallés
Les packages R préinstallés suivants sont actuellement disponibles :
| Package | Version |
|---|---|
| askpass | 1.1 |
| assertthat | 0.2.1 |
| backports | 1.1.4 |
| base | 3.5.1 |
| base64enc | 0.1-3 |
| BH | 1.69.0-1 |
| bindr | 0.1.1 |
| bindrcpp | 0.2.2 |
| bitops | 1.0-6 |
| boot | 1.3-22 |
| broom | 0.5.2 |
| callr | 3.2.0 |
| caret | 6.0-84 |
| caTools | 1.17.1.2 |
| cellranger | 1.1.0 |
| class | 7.3-15 |
| cli | 1.1.0 |
| clipr | 0.6.0 |
| cluster | 2.0.7-1 |
| codetools | 0.2-16 |
| colorspace | 1.4-1 |
| compiler | 3.5.1 |
| crayon | 1.3.4 |
| curl | 3.3 |
| data.table | 1.12.2 |
| jeux de données | 3.5.1 |
| DBI | 1.0.0 |
| dbplyr | 1.4.1 |
| digest | 0.6.19 |
| dplyr | 0.7.6 |
| e1071 | 1.7-2 |
| evaluate | 0.14 |
| fansi | 0.4.0 |
| forcats | 0.3.0 |
| foreach | 1.4.4 |
| foreign | 0.8-71 |
| fs | 1.3.1 |
| gdata | 2.18.0 |
| generics | 0.0.2 |
| ggplot2 | 3.2.0 |
| glmnet | 2.0-18 |
| glue | 1.3.1 |
| gower | 0.2.1 |
| gplots | 3.0.1.1 |
| graphics | 3.5.1 |
| grDevices | 3.5.1 |
| grid | 3.5.1 |
| gtable | 0.3.0 |
| gtools | 3.8.1 |
| haven | 2.1.0 |
| highr | 0,8 |
| hms | 0.4.2 |
| htmltools | 0.3.6 |
| httr | 1.4.0 |
| ipred | 0.9-9 |
| iterators | 1.0.10 |
| jsonlite | 1.6 |
| KernSmooth | 2.23-15 |
| knitr | 1.23 |
| labeling | 0.3 |
| lattice | 0.20-38 |
| lava | 1.6.5 |
| lazyeval | 0.2.2 |
| lubridate | 1.7.4 |
| magrittr | 1.5 |
| markdown | 1 |
| MASS | 7.3-51.4 |
| Matrix | 1.2-17 |
| methods | 3.5.1 |
| mgcv | 1.8-28 |
| mime | 0,7 |
| ModelMetrics | 1.2.2 |
| modelr | 0.1.4 |
| munsell | 0.5.0 |
| nlme | 3.1-140 |
| nnet | 7.3-12 |
| numDeriv | 2016.8-1.1 |
| openssl | 1.4 |
| parallel | 3.5.1 |
| pillar | 1.4.1 |
| pkgconfig | 2.0.2 |
| plogr | 0.2.0 |
| plyr | 1.8.4 |
| prettyunits | 1.0.2 |
| processx | 3.3.1 |
| prodlim | 2018.04.18 |
| progress | 1.2.2 |
| ps | 1.3.0 |
| purrr | 0.3.2 |
| quadprog | 1.5-7 |
| quantmod | 0.4-15 |
| R6 | 2.4.0 |
| randomForest | 4.6-14 |
| RColorBrewer | 1.1-2 |
| Rcpp | 1.0.1 |
| RcppRoll | 0.3.0 |
| readr | 1.3.1 |
| readxl | 1.3.1 |
| recipes | 0.1.5 |
| rematch | 1.0.1 |
| reprex | 0.3.0 |
| reshape2 | 1.4.3 |
| reticulate | 1.12 |
| rlang | 0.4.0 |
| rmarkdown | 1.13 |
| ROCR | 1.0-7 |
| rpart | 4.1-15 |
| rstudioapi | 0.1 |
| rvest | 0.3.4 |
| scales | 1.0.0 |
| selectr | 0.4-1 |
| spatial | 7.3-11 |
| splines | 3.5.1 |
| SQUAREM | 2017.10-1 |
| stats | 3.5.1 |
| stats4 | 3.5.1 |
| stringi | 1.4.3 |
| stringr | 1.3.1 |
| survival | 2.44-1.1 |
| sys | 3.2 |
| tcltk | 3.5.1 |
| tibble | 2.1.3 |
| tidyr | 0.8.3 |
| tidyselect | 0.2.5 |
| tidyverse | 1.2.1 |
| timeDate | 3043.102 |
| tinytex | 0,13 |
| outils | 3.5.1 |
| tseries | 0.10-47 |
| TTR | 0.23-4 |
| utf8 | 1.1.4 |
| utils | 3.5.1 |
| vctrs | 0.1.0 |
| viridisLite | 0.3.0 |
| whisker | 0.3-2 |
| withr | 2.1.2 |
| xfun | 0,8 |
| xml2 | 1.2.0 |
| xts | 0.11-2 |
| yaml | 2.2.0 |
| zeallot | 0.1.0 |
| zoo | 1.8-6 |
Étapes suivantes
Consultez les composants disponibles pour Azure Machine Learning.