Informations de référence sur le composant d’extraction des caractéristiques de N-grammes du texte
Cet article décrit un composant dans le concepteur Azure Machine Learning. Utilisez le composant d’extraction des caractéristiques de N-grammes du texte pour caractériser des données texte non structurées.
Configuration du composant d’extraction des caractéristiques de N-grammes du texte
Le composant prend en charge les scénarios suivants pour l’utilisation d’un dictionnaire de N-grammes :
Créer un dictionnaire de N-grammes à partir d’une colonne de texte libre.
Utiliser un ensemble existant de caractéristiques de texte pour caractériser une colonne de texte libre.
Noter ou déployer un modèle qui utilise des N-grammes.
Créer un dictionnaire de N-grammes
Ajoutez le composant d’extraction des caractéristiques de N-grammes du texte à votre pipeline et connectez le jeu de données contenant le texte que vous souhaitez traiter.
Utilisez Text column (Colonne Texte) pour choisir une colonne de type chaîne contenant le texte à extraire. Étant donné que les résultats sont détaillés, vous ne pouvez traiter qu’une seule colonne à la fois.
Définissez Vocabulary mode (Mode vocabulaire) sur Create (Créer) pour indiquer que vous créez une liste de caractéristiques de N-grammes.
Définissez N-Grams size (Taille de N-grammes) pour indiquer la taille maximale de N-grammes à extraire et à stocker.
Par exemple, si vous entrez 3, des unigrammes, des digrammes et des trigrammes sont créés.
Weighting function de (Fonction de pondération) spécifie comment générer le vecteur de caractéristique de document et comment extraire le vocabulaire des documents.
Binary Weight (Pondération binaire) : affecte une valeur de présence binaire aux N-grammes extraits. La valeur de chaque N-gramme est 1 quand celui-ci existe dans le document, et 0 dans le cas contraire.
TF Weight (Pondération TF) : attribue un score de fréquence du terme (TF) aux N-grammes extraits. La valeur de chaque N-gramme est sa fréquence d’occurrence dans le document.
IDF Weight (Pondération IDF) : attribue un score de fréquence de document inverse (IDF) aux N-grammes extraits. La valeur de chaque N-grammes est le journal de taille de corpus divisé par sa fréquence d’occurrence dans le corpus.
IDF = log of corpus_size / document_frequencyTF-IDF Weight (Pondération TF-IDF) : attribue un score de fréquence de terme/fréquence de document inverse (TF/IDF) aux N-grammes extraits. La valeur de chaque N-grammes est son score TF multiplié par son score IDF.
Définissez Minimum word length (Longueur minimale du mot) sur le nombre minimal de lettres qui peuvent être utilisées dans un mot unique dans un N-gramme.
Utlisez Minimum word length (Longueur minimale du mot) pour définir le nombre minimal de lettres qui peuvent être utilisées dans un mot unique dans un N-gramme.
Par défaut, jusqu’à 25 caractères par mot ou par jeton sont autorisés.
Avec l’option Minimum n-gram document absolute frequency (Fréquence absolue minimale de document N-grammes), définissez le nombre minimal d’occurrences d’un N-gramme pour que celui-ci soit inclus dans le dictionnaire de N-grammes.
Par exemple, si vous utilisez la valeur par défaut 5, tout N-grammes doit apparaître au moins cinq fois dans le corpus pour être inclus dans le dictionnaire de N-grammes.
Définissez Maximum n-gram document ratio (Ratio maximal de document N-grammes) sur le ratio maximal du nombre de lignes contenant un N-grammes particulier, sur le nombre de lignes dans le corpus global.
Par exemple, un ratio de 1 indique que, même si un N-grammes spécifique est présent dans chaque ligne, le N-grammes peut être ajouté au dictionnaire de N-grammes. Plus généralement, un mot qui apparaît dans chaque ligne est considéré comme un mot parasite et est supprimé. Pour filtrer les mots parasites dépendants du domaine, essayez de réduire ce ratio.
Important
Le taux d’occurrence de mots particuliers n’est pas uniforme. Il varie d’un document à l’autre. Par exemple, si vous analysez des commentaires de clients sur un produit spécifique, la fréquence du nom du produit peut être très élevée et se rapprocher de celle d’un mot parasite, mais être un terme significatif dans d’autres contextes.
Sélectionnez l’option Normalize n-gram feature vectors (Normaliser les vecteurs de caractéristique N-grammes) pour normaliser les vecteurs de caractéristique. Si cette option est activée, chaque vecteur de caractéristiques de N-grammes est divisé par sa norme L2.
Envoyez le pipeline.
Utiliser un dictionnaire de N-grammes existant
Ajoutez le composant d’extraction des caractéristiques de N-grammes du texte à votre pipeline et connectez le jeu de données contenant le texte à traiter au port Jeu de données.
Utilisez Text column (Colonne Texte) pour sélectionner la colonne de texte contenant le texte que vous souhaitez caractériser. Par défaut, le composant sélectionne toutes les colonnes de type chaîne. Pour des résultats optimaux, traitez une seule colonne à la fois.
Ajoutez le jeu de données enregistré qui contient un dictionnaire de N-grammes généré précédemment et connectez-le au port Input vocabulary (Vocabulaire d’entrée). Vous pouvez également connecter la sortie Vocabulaire de résultat d’une instance en amont du composant d’extraction des caractéristiques de N-grammes du texte.
Pour Vocabulary mode (Mode vocabulaire), sélectionnez l’option de mise à jour ReadOnly (Lecture seule) dans la liste déroulante.
L’option ReadOnly représente le corpus d’entrée pour le vocabulaire d’entrée. Au lieu de calculer les fréquences de termes à partir du nouveau jeu de données texte (sur l’entrée de gauche), les pondérations N-grammes du vocabulaire d’entrée sont appliquées telles quelles.
Conseil
Utilisez cette option lorsque vous calculez le score d’un classifieur de texte.
Pour toutes les autres options, consultez les descriptions des propriétés dans la section précédente.
Envoyez le pipeline.
Créer un pipeline d’inférence qui utilise des N-grammes pour déployer un point de terminaison en temps réel
Un pipeline d’entraînement qui contient un module d’extraction des caractéristiques de N-grammes du texte et un module Modèle de score pour effectuer une prédiction sur le jeu de données de test, est construit dans la structure suivante :
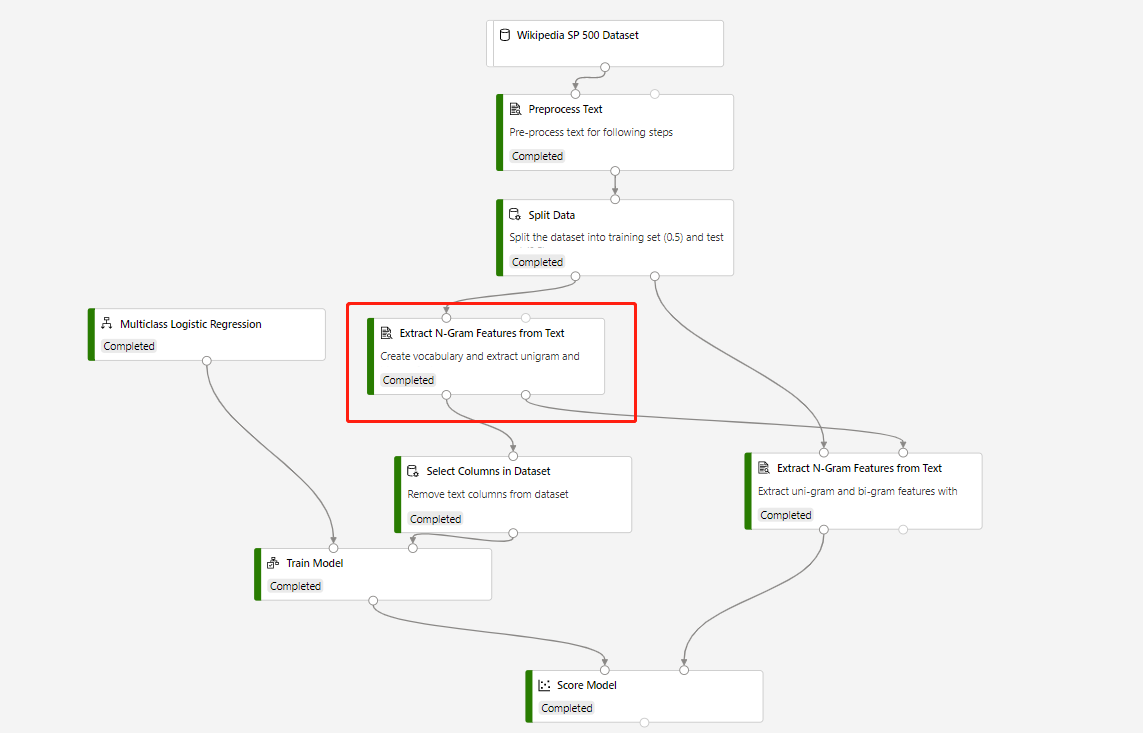
Le Mode vocabulaire du composant d’extraction des caractéristiques de N-grammes du texte entouré est Créer, et le Mode vocabulaire du composant qui se connecte au composant Modèle de scoring est Lecture seule.
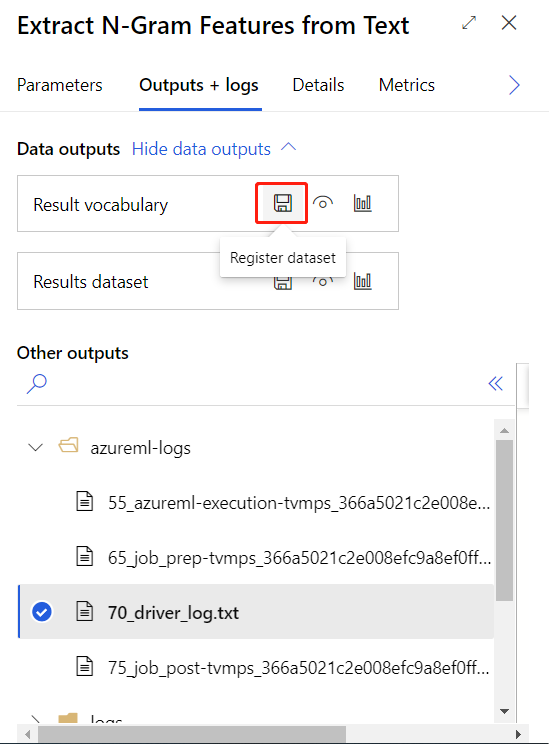
Une fois que vous avez envoyé le pipeline d’apprentissage ci-dessus, vous pouvez enregistrer la sortie du composant entouré en tant que jeu de données.
Vous pouvez ensuite créer un pipeline d’inférence en temps réel. Après avoir créé un pipeline d’inférence, vous devez l’ajuster manuellement comme suit :
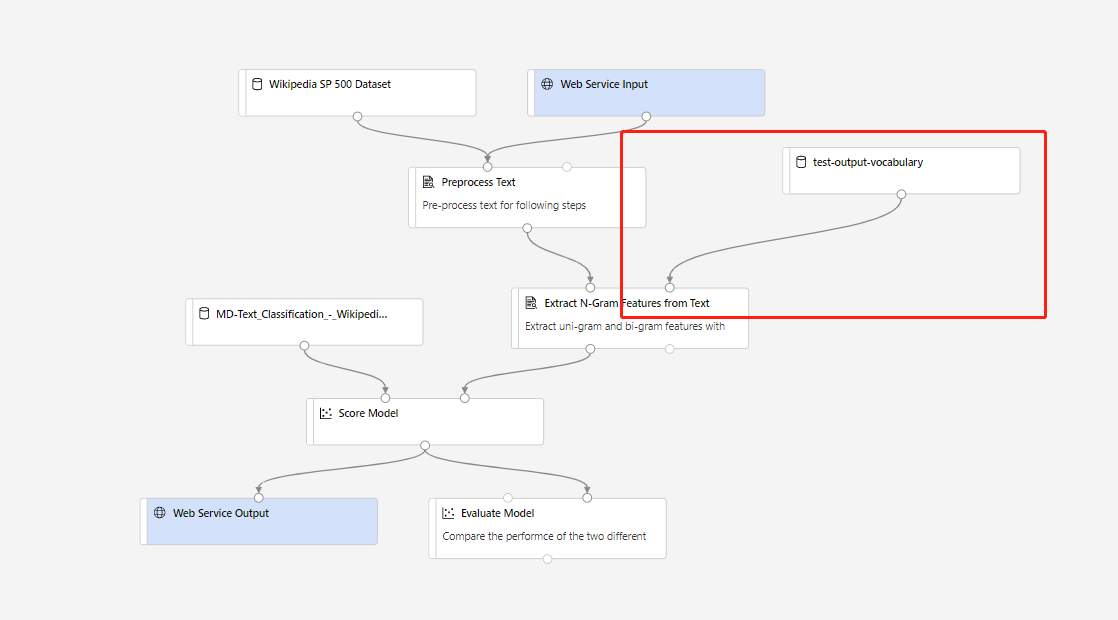
Ensuite, soumettez le pipeline d’inférence et déployez un point de terminaison en temps réel.
Résultats
Le module d’extraction des caractéristiques de N-grammes du texte crée deux types de sortie :
Results dataset (Jeu de données de résultats) : cette sortie est un résumé du texte analysé combiné avec les N-grammes extraits. Les colonnes que vous n’avez pas sélectionnées dans l’option Text column (Colonne Texte) sont transmises à la sortie. Pour chaque colonne de texte que vous analysez, le composant génère ces colonnes :
- Matrice d’occurrences de N-grammes : le composant génère une colonne pour chaque N-gramme trouvé dans le corpus total, et ajoute un scoring dans chaque colonne pour indiquer la pondération du N-gramme pour cette ligne.
Result vocabulary (Vocabulaire de résultat) : Le vocabulaire contient le dictionnaire de N-grammes réel, ainsi que les notes de fréquence de termes qui sont générées dans le cadre de l’analyse. Vous pouvez enregistrer le jeu de données pour le réutiliser avec un autre ensemble d’entrées ou en vue d’une mise à jour ultérieure. Vous pouvez également réutiliser le vocabulaire pour la modélisation et la notation.
Vocabulaire de résultat
Le vocabulaire contient le dictionnaire de N-grammes, ainsi que les notes de fréquence de termes qui sont générées dans le cadre de l’analyse. Les scores DF et IDF sont générés indépendamment des autres options.
- ID : Identificateur généré pour chaque N-grammes.
- nGram (N-grammes) : le N-grammes. Les espaces ou autres séparateurs de mots sont remplacés par le caractère de soulignement.
- DF : Note de fréquence de terme pour le N-grammes dans le corpus d’origine.
- IDF : Note de fréquence de document inverse pour le N-grammes dans le corpus d’origine.
Vous pouvez mettre à jour ce jeu de données manuellement, mais vous risquez d’introduire des erreurs. Par exemple :
- Une erreur est signalée si le composant trouve des lignes dupliquées avec la même clé dans le vocabulaire d’entrée. Veillez à ce qu’il n’y ait pas deux lignes contenant le même mot dans vocabulaire.
- Le schéma d’entrée des jeux de données de vocabulaire doit correspondre exactement, y compris les noms de colonnes et les types de colonnes.
- La colonne ID et la colonne DF doivent être de type entier (integer).
- La colonne IDF doit être de type flottant (float).
Notes
Ne connectez pas la sortie de données directement au composant Effectuer l’apprentissage du modèle. Vous devez supprimer les colonnes de texte libre avant qu’elles ne soient incluses dans le module. Sinon, les colonnes de texte libre seront traitées comme des caractéristiques de catégorie.
Étapes suivantes
Consultez les composants disponibles pour Azure Machine Learning.