Composant Partition et échantillon
Cet article décrit un composant dans le concepteur Azure Machine Learning.
Utilisez le composant Partition et échantillon pour effectuer un échantillonnage sur un jeu de données ou pour créer des partitions à partir de votre jeu de données.
L’échantillonnage est un outil important dans l’apprentissage automatique, car il permet de réduire la taille d’un jeu de données tout en conservant le même rapport de valeurs. Ce composant prend en charge plusieurs tâches associées qui sont importantes dans le machine learning :
Diviser vos données en plusieurs sous-sections de la même taille.
Vous pouvez utiliser les partitions pour la validation croisée ou pour attribuer des cas à des groupes aléatoires.
Séparer des données dans des groupes et ensuite utiliser des données à partir d’un groupe spécifique.
Après avoir attribué des cas de façon aléatoire à différents groupes, vous devez peut-être modifier les fonctionnalités qui sont associées à un seul groupe.
Échantillonner.
Vous pouvez extraire un pourcentage de données, appliquer un échantillonnage aléatoire ou choisir une colonne à utiliser pour l’équilibrage du jeu de données et effectuer un échantillonnage stratifié sur ses valeurs.
Créer un plus petit jeu de données à des fins de test.
Si vous avez une grande quantité de données, vous souhaiterez peut-être utiliser uniquement les n premières lignes lors de la configuration du pipeline, puis utiliser le jeu de données complet lors de la génération de votre modèle. Vous pouvez également utiliser l’échantillonnage pour créer un jeu de données plus petit pour une utilisation en développement.
Configurer le composant
Ce composant prend en charge les méthodes suivantes permettant de diviser vos données en partitions ou destinées à l’échantillonnage. Commencez par choisir la méthode, puis définissez les options supplémentaires requises par la méthode.
- Head
- échantillonnage
- Attribuer à des plis
- Choisir le pli
Récupérer les N PREMIÈRES lignes d’un jeu de données
Utilisez ce mode si vous souhaitez obtenir uniquement la n premières lignes. Cette option est utile si vous souhaitez tester un pipeline sur un petit nombre de lignes et si vous n’avez pas besoin que les données soient équilibrées ni échantillonnées.
Ajoutez le composant Partition et échantillon à votre pipeline dans l’interface et connectez le jeu de données.
Mode de partition ou d’échantillon: définissez cette option sur Head.
Nombre de lignes à sélectionner: entrez le nombre de lignes à retourner.
Le nombre de lignes doit être un entier non négatif. Si le nombre de lignes sélectionnées est supérieur au nombre de lignes du jeu de données, l’intégralité du jeu de données est renvoyée.
Envoyez le pipeline.
Le composant génère un jeu de données unique qui contient uniquement le nombre de lignes spécifié. Les lignes sont toujours lues à partir du haut du jeu de données.
Créer un exemple de données
Cette option prend en charge l’échantillonnage aléatoire simple ou l’échantillonnage aléatoire stratifié. Elle est utile si vous souhaitez créer un jeu de données d’échantillon représentatif plus petit à des fins de test.
Ajoutez le composant Partition et échantillon à votre pipeline et connectez le jeu de données.
Mode de partition ou d’échantillon : définissez cette option sur Échantillonnage.
Taux d’échantillonnage: entrez une valeur comprise entre 0 et 1. Cette valeur spécifie le pourcentage de lignes du jeu de données source qui doivent être incluses dans le jeu de données de sortie.
Par exemple, si vous ne souhaitez que la moitié du jeu de données d’origine, entrez
0.5pour indiquer que le taux d’échantillonnage doit être de 50 %.Les lignes du jeu de données d’entrée sont mélangées et placées sélectivement dans le jeu de données de sortie, en fonction du rapport spécifié.
Valeur initiale aléatoire pour l’échantillonnage: Si vous le souhaitez, entrez un entier à utiliser comme valeur initiale.
Cette option est importante si vous souhaitez que les lignes soient divisées de la même façon à chaque fois. La valeur par défaut est 0, ce qui signifie qu’une valeur de départ est générée en fonction de l’horloge système. Cette valeur peut entraîner des résultats légèrement différents chaque fois que vous exécutez le pipeline.
Répartition stratifiée pour l'échantillonnage : Sélectionnez cette option s’il est important que les lignes du jeu de données soient divisées uniformément par colonne clé avant l’échantillonnage.
Pour Stratification key column for sampling (Colonne clé de stratification pour l’échantillonnage), sélectionnez une seule colonne de strate à utiliser lors de la division du jeu de données. Les lignes dans le jeu de données sont divisées comme suit :
Toutes les lignes d’entrée sont regroupées (stratifiées) par les valeurs dans la colonne de strate spécifiée.
Les lignes sont mélangées au sein de chaque groupe.
Chaque groupe est ajouté sélectivement au jeu de données de sortie pour respecter le rapport spécifié.
Envoyez le pipeline.
Avec cette option, le composant génère un jeu de données unique contenant un échantillon représentatif des données. La partie restante, c’est-à-dire la partie non échantillonnée du jeu de données, n’est pas générée.
Fractionner les données en partitions
Utilisez cette option lorsque vous souhaitez diviser le jeu de données en sous-ensembles de données. Cette option est également utile lorsque vous souhaitez créer un nombre de plis personnalisé pour la validation croisée, ou pour fractionner des lignes en plusieurs groupes.
Ajoutez le composant Partition et échantillon à votre pipeline et connectez le jeu de données.
Pour Partition or sample mode (Mode de partitionnement ou d’échantillonnage), sélectionnez Assign to Folds (Attribuer à des plis).
Utiliser le remplacement dans le partitionnement : Sélectionnez cette option si vous souhaitez que la ligne échantillonnée soit replacée dans le pool de lignes pour une réutilisation potentielle. Par conséquent, la même ligne peut être attribuée à plusieurs plis.
Si vous n’utilisez pas le remplacement (l’option par défaut), la ligne échantillonnée n’est pas replacée dans le pool de lignes pour une réutilisation potentielle. Par conséquent, chaque ligne peut être uniquement attribuée à un pli.
Fractionnement aléatoire : sélectionnez cette option si vous souhaitez que des lignes soient attribuées de façon aléatoire à des plis.
Si vous ne sélectionnez pas cette option, les lignes sont attribuées à des plis au moyen de la méthode tourniquet (round-robin).
Seed aléatoire : Si vous le souhaitez, entrez un entier à utiliser comme valeur de départ. Cette option est importante si vous souhaitez que les lignes soient divisées de la même façon à chaque fois. Sinon, la valeur par défaut 0 signifie qu’une valeur de départ aléatoire sera utilisée.
Spécifier la méthode de partition : indiquez comment répartir les données dans chaque partition à l’aide des options ci-après :
Partitionner de manière égale : utilisez cette option pour placer un nombre égal de lignes dans chaque partition. Pour spécifier le nombre de partitions de sortie, entrez un nombre entier dans la zone Specify number of folds to split evenly into (Spécifier le nombre de plis pour un fractionnement uniforme).
Partition avec proportions personnalisées: utilisez cette option pour spécifier la taille de chaque partition sous la forme d’une liste séparée par des virgules.
Supposons que vous souhaitiez créer trois partitions. La première partition contient 50 % des données. Les deux partitions restantes contiennent chacune 25 % des données. Dans la zone List of proportions separated by comma (Liste des proportions séparées par des virgules), entrez les valeurs suivantes : .5, .25, .25.
La somme de toutes les tailles de partition doit être de 1.
Si vous entrez des nombres dont le total estinférieur à 1, une partition supplémentaire est créée pour héberger les lignes restantes. Par exemple, si vous entrez les valeurs .2 et .3, une troisième partition est créée pour héberger les 50 % restants de toutes les lignes.
Si vous entrez des nombres dont le total est supérieur à 1, une erreur est générée lorsque vous exécutez le pipeline.
Fractionnement stratifié : sélectionnez cette option si vous souhaitez que les lignes soient stratifiées lors du fractionnement, puis choisissez la colonne de strate.
Envoyez le pipeline.
Avec cette option, le composant génère plusieurs jeux de données. Les jeux de données sont partitionnés en fonction des règles que vous avez spécifiées.
Utiliser les données d’une partition prédéfinie
Utilisez cette option quand vous avez divisé un jeu de données en plusieurs partitions et que vous voulez charger chaque partition tour à tour pour aller plus loin dans le traitement ou l’analyse.
Ajoutez le composant Partition et échantillon au pipeline.
Connectez le composant à la sortie d’une instance précédente du composant Partition et échantillon. Cette instance doit avoir utilisé l’option Assign to Folds (Attribuer à des plis) pour générer un certain nombre de partitions.
Mode de partition ou d’échantillon: sélectionnez Pick Fold.
Spécifiez le pli à échantillonner à partir de: sélectionnez une partition à utiliser en entrant son index. Les index de partition sont basés sur 1. Par exemple, si vous avez divisé le jeu de données en trois parties, les partitions auraient les index 1, 2 et 3.
Si vous entrez une valeur d’index non valide, une erreur au moment de la conception est générée : « erreur 0018 : le jeu de données contient des données non valides. »
En plus de regrouper le jeu de données en plis, vous pouvez séparer le jeu de données en deux groupes : un pli cible et tout le reste. Pour ce faire, entrez l’index d’un pli unique, puis sélectionnez l’option Pick complement of the selected fold (Choisir le complément du pli sélectionné), afin d’obtenir toutes les données, à l’exception de celles dans le pli spécifié.
Si vous utilisez plusieurs partitions, vous devez ajouter des instances supplémentaires du composant Partition et échantillon pour gérer chaque partition.
Par exemple, le composant Partition et échantillon de la deuxième ligne est défini sur Assign to Folds (Attribuer à des plis), et le composant de la troisième ligne est défini sur Pick Fold (Choisir le pli).
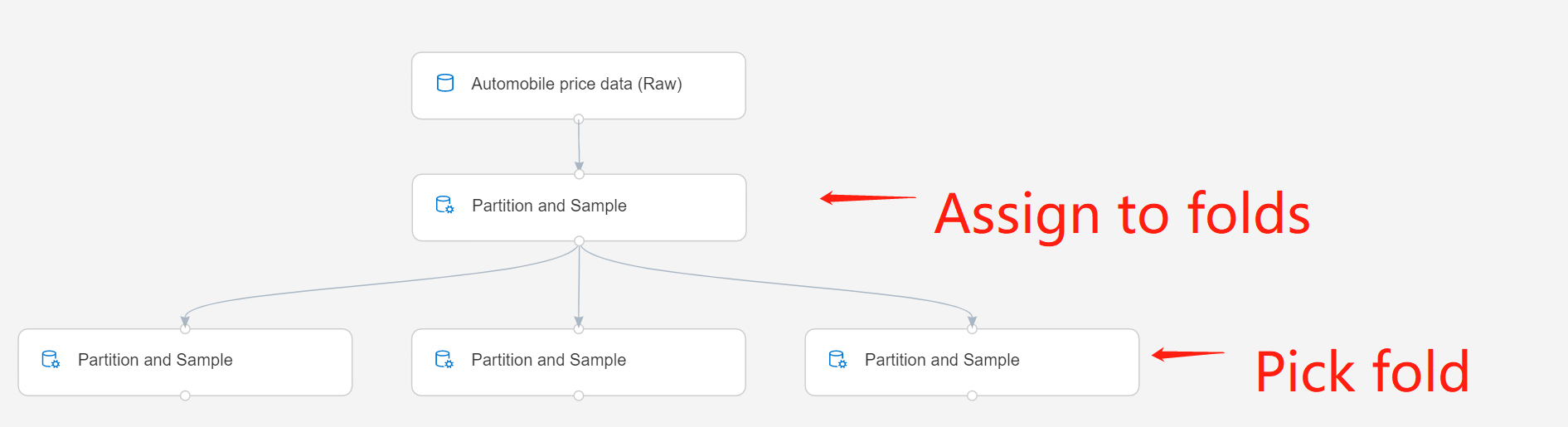
Envoyez le pipeline.
Avec cette option, le composant génère un jeu de données unique qui contient seulement les lignes attribuées à ce pli.
Notes
Vous ne pouvez pas voir les désignations de pli directement. Elles sont uniquement présentes dans les métadonnées.
Étapes suivantes
Consultez les composants disponibles pour Azure Machine Learning.