Transformation de sélection de colonnes
Cet article décrit comment utiliser le composant Transformation de sélection de colonnes dans le concepteur Azure Machine Learning. L’objectif du composant Transformation de sélection de colonnes consiste à s’assurer qu’un ensemble de colonnes prévisible et cohérent est utilisé dans les opérations de machine learning en aval.
Ce composant est utile pour des tâches telles que le scoring, qui nécessitent des colonnes spécifiques. Les modifications apportées aux colonnes disponibles peuvent rompre le pipeline ou changer les résultats.
Vous utilisez le module Transformation de sélection de colonnes pour créer et enregistrer un ensemble de colonnes. Ensuite, vous utilisez le composant Appliquer une transformation pour appliquer ces sélections aux nouvelles données.
Utilisation du module Transformation de sélection de colonnes
Ce scénario suppose que vous souhaitez utiliser la sélection de caractéristiques pour générer un ensemble dynamique de colonnes qui seront utilisées afin d’entraîner un modèle. Pour vous assurer que les sélections de colonnes soient identiques pour le processus de scoring, utilisez le composant Transformation de sélection de colonnes afin de capturer les sélections de colonnes et de les appliquer ailleurs dans le pipeline.
Ajoutez un jeu de données d’entrée à votre pipeline dans le concepteur.
Ajoutez une instance du module Sélection de caractéristiques par filtrage.
Connectez les composants et configurez le composant de sélection de caractéristiques pour rechercher automatiquement un certain nombre de caractéristiques optimales dans le jeu de données d’entrée.
Ajoutez une instance du module Entraîner un modèle et utilisez la sortie du module Sélection de caractéristiques par filtrage comme entrée pour l’entraînement.
Important
Étant donné que l’importance d’une caractéristique est basée sur les valeurs de la colonne, vous ne pouvez pas connaître à l’avance les colonnes éventuellement disponibles en entrée pour le module Entraîner un modèle.
Attachez une instance du composant Transformation de sélection de colonnes.
Cette étape génère une sélection de colonnes sous la forme d’une transformation qui peut être enregistrée ou appliquée à d’autres jeux de données. Cette étape garantit que les colonnes identifiées dans la sélection des caractéristiques sont enregistrées en vue de leur réutilisation par d’autres composants.
Ajoutez le composant Noter le modèle.
Ne connectez pas le jeu de données d’entrée. Au lieu de cela, ajoutez le composant Appliquer une transformation et connectez la sortie de la transformation de sélection de caractéristiques.
La structure du pipeline doit être similaire à ce qui suit :
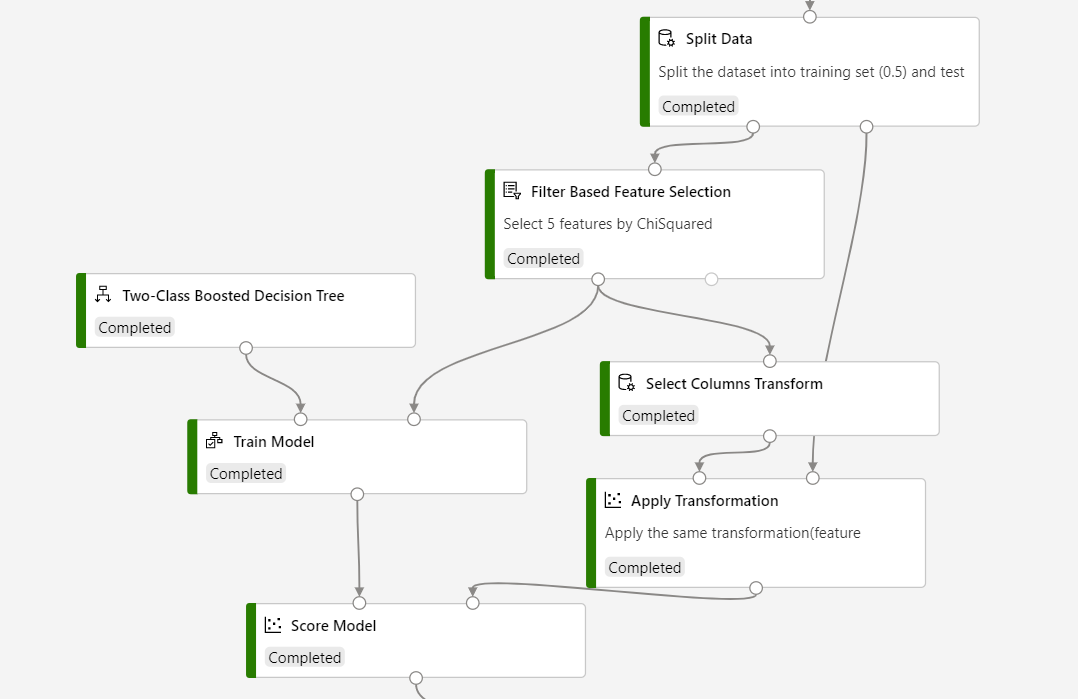
Important
Vous ne pouvez pas escompter les mêmes résultats si vous appliquez le module Sélection de caractéristiques par filtrage au jeu de données de scoring. Comme la sélection des caractéristiques est basée sur des valeurs, elle peut choisir un autre ensemble de colonnes, ce qui entraînerait l’échec de l’opération de scoring.
Envoyez le pipeline.
Ce processus d’enregistrement, puis d’application d’une sélection de colonnes garantit que le même schéma de données est disponible pour l’entraînement et le scoring.
Étapes suivantes
Consultez les composants disponibles pour Azure Machine Learning.