Exemples sur Data Science Virtual Machine
Les machines Azure Data Science Virtual Machine (DSVM) incluent un ensemble complet d’exemple de code. Ces exemples incluent des blocs-notes Jupyter et des scripts dans des langages tels que Python et R.
Notes
Pour plus d’informations sur l’exécution de blocs-notes Jupyter Notebook sur vos machines DSVM, consultez la section Accéder à Jupyter.
Prérequis
Pour exécuter ces exemples, vous devez avoir approvisionné une Data Science Virtual Machine Ubuntu.
Exemples disponibles
| Catégorie d’exemples | Description | Emplacements |
|---|---|---|
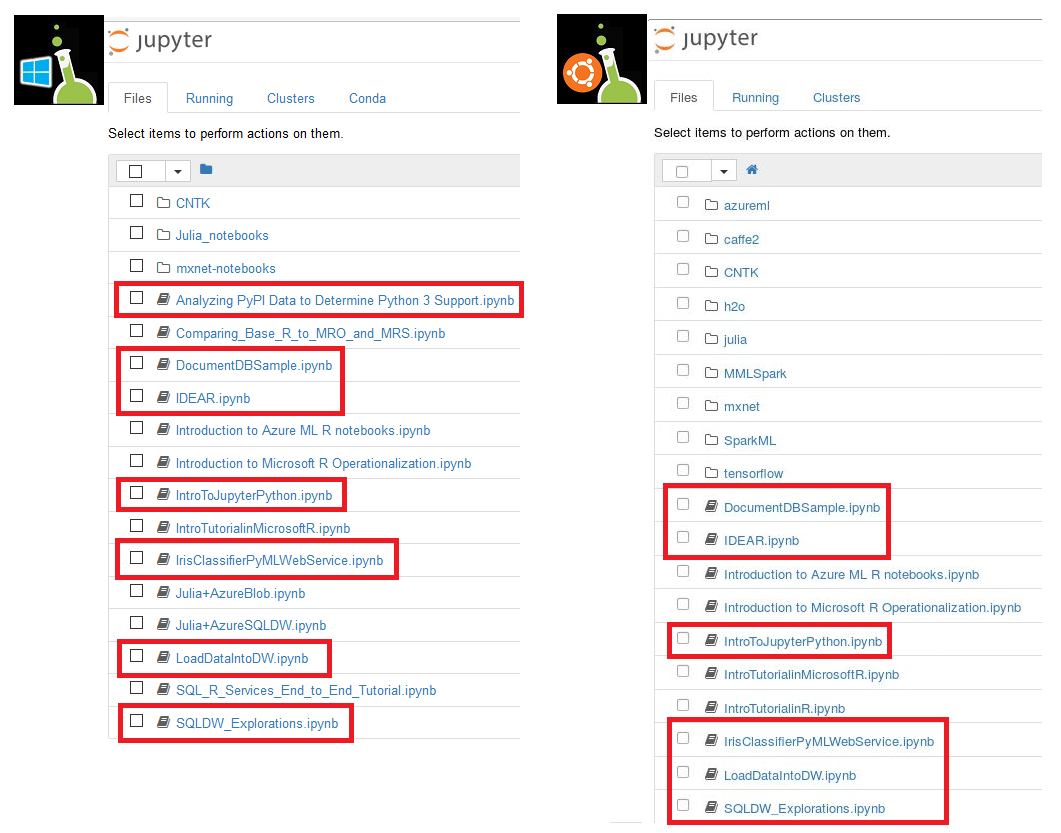
| Langage Python | Les exemples décrivent des scénarios tels que la connexion aux magasins de données cloud basés sur Azure et l’utilisation d’Azure Machine Learning. Langage Python |
~notebooks |
| Langage Julia | Fournit une description détaillée du traçage et du Deep Learning dans Julia. Explique également comment appeler les langages C et Python à partir de Julia. Langage Julia |
Windows : ~notebooks/Julia_notebooksLinux : ~notebooks/julia |
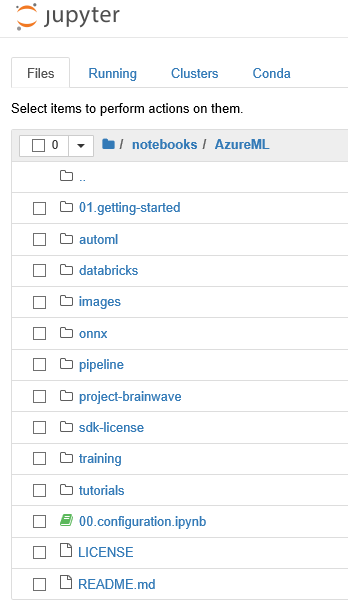
| Azure Machine Learning | Générez des modèles Machine Learning et d’apprentissage profond avec Machine Learning. Déployez-les n’importe où. Utilisez le réglage intelligent des hyperparamètres et le réglage Machine Learning automatisé, ainsi que la gestion des modèles et la formation distribuée. Machine Learning |
~notebooks/AzureML |
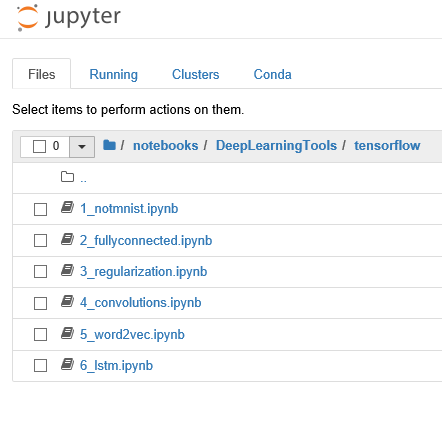
| Blocs-notes PyTorch | Exemples Deep Learning qui utilisent des réseaux neuronaux basés sur PyTorch. La gamme des blocs-notes s’étend des scénarios pour débutants aux scénarios pour utilisateurs avancés. Blocs-notes PyTorch |
~notebooks/Deep_learning_frameworks/pytorch |
| TensorFlow | Variété d’exemples et techniques de réseau neuronal implémentés à l’aide de l’infrastructure TensorFlow. TensorFlow |
~notebooks/Deep_learning_frameworks/tensorflow |
| H2O | Exemples basés sur Python qui utilisent H2O pour des scénarios problématiques concrets. H2O |
~notebooks/h2o |
| Langage SparkML | Exemples utilisant les fonctionnalités de la boîte à outils Apache Spark MLLib via pySpark et MMLSpark : Microsoft Machine Learning pour Apache Spark sur Apache Spark 2.x. Langage SparkML |
~notebooks/SparkML/pySpark~notebooks/MMLSpark |
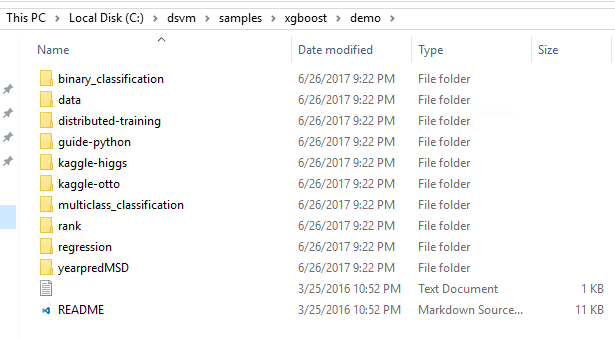
| XGBoost | Exemples d’apprentissage automatique standard dans XGBoost pour les scénarios tels que la classification et la régression. XGBoost |
Windows : \dsvm\samples\xgboost\demo |
Accéder à Jupyter
Pour accéder à Jupyter, sélectionnez l’icône Jupyter sur le Bureau ou dans le menu de l’application. Vous pouvez également accéder à Jupyter sur une édition Linux d’une machine DSVM. Pour accéder à distance à partir d’un navigateur web, accédez à https://<Full Domain Name or IP Address of the DSVM>:8000 sur Ubuntu.
Pour ajouter des exceptions et permettre l’accès à Jupyter via un navigateur, suivez les instructions suivantes :

Connectez-vous avec le mot de passe que vous utilisez pour vous connecter à la machine Data Science Virtual Machine.
Page d’accueil de Jupyter

Langage R

Langage Python
Langage Julia

Azure Machine Learning
PyTorch

TensorFlow
H2O
SparkML

XGBoost