Configurer AutoML pour entraîner un modèle de prévision de séries chronologiques avec SDK et CLI
S’APPLIQUE À : Extension Azure ML CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (préversion)
Extension Azure ML CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (préversion)
Dans cet article, vous apprendrez à configurer AutoML pour les prévisions de séries chronologiques avec le ML automatisé Azure Machine Learning dans le SDK Python Azure Machine Learning.
Pour cela, vous devez :
- Préparez les données pour la formation.
- Configurez des paramètres spécifiques de série chronologique dans un travail de prévision.
- Orchestrez la formation, l'inférence et l'évaluation de modèles à l'aide de composants et de pipelines.
Pour une expérience à faible code, consultez le Tutoriel : Prévoir la demande à l’aide du Machine Learning automatisé pour un exemple de prévision de série chronologique utilisant le Machine Learning automatisé dans Azure Machine Learning Studio.
AutoML utilise des modèles Machine Learning standard ainsi que des modèles de série chronologique connus pour créer des prévisions. Notre approche intègre des informations historiques sur la variable cible, des fonctionnalités fournies par l'utilisateur dans les données d'entrée et des fonctionnalités conçues automatiquement. Les algorithmes de recherche de modèles fonctionnent ensuite pour trouver un modèle avec la meilleure précision prédictive. Pour plus de détails, consultez nos articles sur la méthodologie de prévision et la recherche de modèles.
Prérequis
Pour cet article, vous avez besoin des éléments suivants :
Un espace de travail Azure Machine Learning. Pour créer l’espace de travail, consultez Créer des ressources d’espace de travail.
La possibilité de lancer des travaux de formation AutoML. Pour plus d’informations, suivez le guide pratique pour configurer AutoML.
Données de formation et de validation
Les données d’entrée pour les prévisions AutoML doivent contenir des séries chronologiques valides au format tabulaire. Chaque variable doit avoir sa propre colonne correspondante dans la table de données. AutoML nécessite au moins deux colonnes : une colonne de temps représentant l’axe de temps et une colonne cible qui représente la quantité à prévoir. D’autres colonnes peuvent servir de prédicteurs. Pour plus d’informations, consultez comment AutoML utilise vos données.
Important
Lors de l’entraînement d’un modèle pour la prévision de valeurs futures, assurez-vous que toutes les fonctionnalités utilisées pour l’entraînement peuvent être utilisées lors de l’exécution de prédictions à l’horizon prévu.
Par exemple, l’intégration d’une fonctionnalité pour le prix actuel du stock peut augmenter considérablement la précision de la formation. Toutefois, si vous prévoyez à un horizon lointain, vous ne pourrez peut-être pas prévoir avec précision les futures valeurs d’actions correspondant aux points de séries chronologiques futures et la précision du modèle pourrait en pâtir.
Les travaux de prévision AutoML nécessitent que vos données de formation soient représentées sous la forme d’un objet MLTable. Un MLTable spécifie une source de données et les étapes de chargement des données. Pour plus d’informations et de cas d’usage, consultez le guide pratique MLTable. Par exemple, supposons que vos données de formation se trouvent dans le fichier CSV d’un répertoire local, ./train_data/timeseries_train.csv.
Vous pouvez créer un MLTable à l’aide du Kit de développement logiciel (SDK) Python mltable , comme dans l’exemple suivant :
import mltable
paths = [
{'file': './train_data/timeseries_train.csv'}
]
train_table = mltable.from_delimited_files(paths)
train_table.save('./train_data')
Ce code crée un nouveau fichier, ./train_data/MLTable, qui contient le format de fichier et les instructions de chargement.
Vous définissez maintenant un objet de données d'entrée, qui est requis pour démarrer une tâche de formation, à l'aide du SDK Azure Machine Learning Python comme suit :
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml import Input
# Training MLTable defined locally, with local data to be uploaded
my_training_data_input = Input(
type=AssetTypes.MLTABLE, path="./train_data"
)
Vous spécifiez les données de validation de la même manière, en créant un MLTable et en spécifiant une entrée de données de validation. Sinon, si vous ne fournissez pas de données de validation, AutoML crée automatiquement des fractionnements de validation croisée à partir de vos données de formation à utiliser pour la sélection du modèle. Pour plus d’informations, consultez notre article sur la sélection de modèles de prévision. Consultez également les exigences en matière de longueur des données de formation pour plus d’informations sur la quantité de données de formation dont vous avez besoin pour former correctement un modèle de prévision.
Découvrez-en davantage sur la façon dont AutoML applique la validation croisée afin d’empêcher le surajustement.
Capacité de calcul pour exécuter l’expérience
AutoML utilise la capacité de calcul Azure Machine Learning, qui est une ressource de calcul entièrement managée, pour exécuter le travail de formation. Dans l’exemple suivant, un cluster de calcul nommé cpu-compute est créé :
from azure.ai.ml.entities import AmlCompute
# specify aml compute name.
cpu_compute_target = "cpu-cluster"
try:
ml_client.compute.get(cpu_compute_target)
except Exception:
print("Creating a new cpu compute target...")
compute = AmlCompute(
name=cpu_compute_target, size="STANDARD_D2_V2", min_instances=0, max_instances=4
)
ml_client.compute.begin_create_or_update(compute).result()Configurer une expérience
Vous utilisez les fonctions d'usine automl pour configurer les tâches de prévision dans le SDK Python. L'exemple suivant montre comment créer une tâche de prévision en définissant l’indicateur de performance principale et en définissant des limites sur l'exécution de formation :
from azure.ai.ml import automl
# note that the below is a code snippet -- you might have to modify the variable values to run it successfully
forecasting_job = automl.forecasting(
compute="cpu-compute",
experiment_name="sdk-v2-automl-forecasting-job",
training_data=my_training_data_input,
target_column_name=target_column_name,
primary_metric="normalized_root_mean_squared_error",
n_cross_validations="auto",
)
# Limits are all optional
forecasting_job.set_limits(
timeout_minutes=120,
trial_timeout_minutes=30,
max_concurrent_trials=4,
)
Prévision des paramètres de tâche
Les tâches de prévision ont de nombreux paramètres propres à la prévision. Les plus élémentaires de ces paramètres sont le nom de la colonne de temps dans les données de formation et l'horizon de prévision.
Utilisez les méthodes ForecastingJob pour configurer ces paramètres :
# Forecasting specific configuration
forecasting_job.set_forecast_settings(
time_column_name=time_column_name,
forecast_horizon=24
)
Le nom de la colonne de temps est un paramètre obligatoire et vous devez généralement définir l’horizon de prévision en fonction de votre scénario de prédiction. Si vos données contiennent plusieurs séries chronologiques, vous pouvez spécifier le nom des colonnes d’ID de série chronologique. Ces colonnes, lorsqu’elles sont regroupées, définissent la série individuelle. Par exemple, supposons que vous ayez des données composées de ventes horaires de différents magasins et marques. L’exemple suivant montre comment définir les colonnes d’ID de série chronologique en supposant que les données contiennent des colonnes nommées « magasin » et « marque » :
# Forecasting specific configuration
# Add time series IDs for store and brand
forecasting_job.set_forecast_settings(
..., # other settings
time_series_id_column_names=['store', 'brand']
)
AutoML tente de détecter automatiquement les colonnes d’ID de série chronologique dans vos données si aucune n’est spécifiée.
Les autres paramètres sont facultatifs et examinés dans la section suivante.
Paramètres de tâche de prévision facultatifs
Des configurations facultatives sont disponibles pour les tâches de prévisions, telles que l’activation du Deep Learning et la spécification d’une agrégation de fenêtres dynamiques cibles. Une liste complète des paramètres est disponible dans la documentation du référentiel prévisionnel.
Paramètres de recherche de modèle
Il existe deux paramètres facultatifs qui contrôlent l’espace du modèle où AutoML recherche le meilleur modèle : allowed_training_algorithms et blocked_training_algorithms. Pour limiter l'espace de recherche à un ensemble donné de classes de modèle, utilisez le paramètre allowed_training_algorithms comme dans l'exemple suivant :
# Only search ExponentialSmoothing and ElasticNet models
forecasting_job.set_training(
allowed_training_algorithms=["ExponentialSmoothing", "ElasticNet"]
)
Dans ce cas, le travail de prévision recherche uniquement les classes de modèle Smoothing exponentiel et Elastic Net. Pour supprimer un ensemble donné de classes de modèle de l’espace de recherche, utilisez blocked_training_algorithms comme dans l’exemple suivant :
# Search over all model classes except Prophet
forecasting_job.set_training(
blocked_training_algorithms=["Prophet"]
)
À présent, le travail recherche toutes les classes de modèle sauf Prophet. Pour obtenir la liste des noms de modèles de prévision acceptés dans allowed_training_algorithms et blocked_training_algorithms, consultez la documentation de référence sur les propriétés de formation. L'un ou l'autre, mais pas les deux, de allowed_training_algorithms et blocked_training_algorithms peut être appliqué à une course de formation.
Activez le Deep Learning
AutoML est fourni avec un modèle de réseau neuronal profond (DNN) personnalisé appelé TCNForecaster. Ce modèle est un réseau convolutif temporel, ou TCN, qui applique des méthodes de tâche d’imagerie courantes à la modélisation des séries chronologiques. Notez que les convolutions « causales » unidimensionnelles forment l’épine dorsale du réseau et permettent au modèle d’apprendre des modèles complexes sur de longues durées dans l’historique de formation. Pour plus d’informations, consultez notre article TCNForecaster.
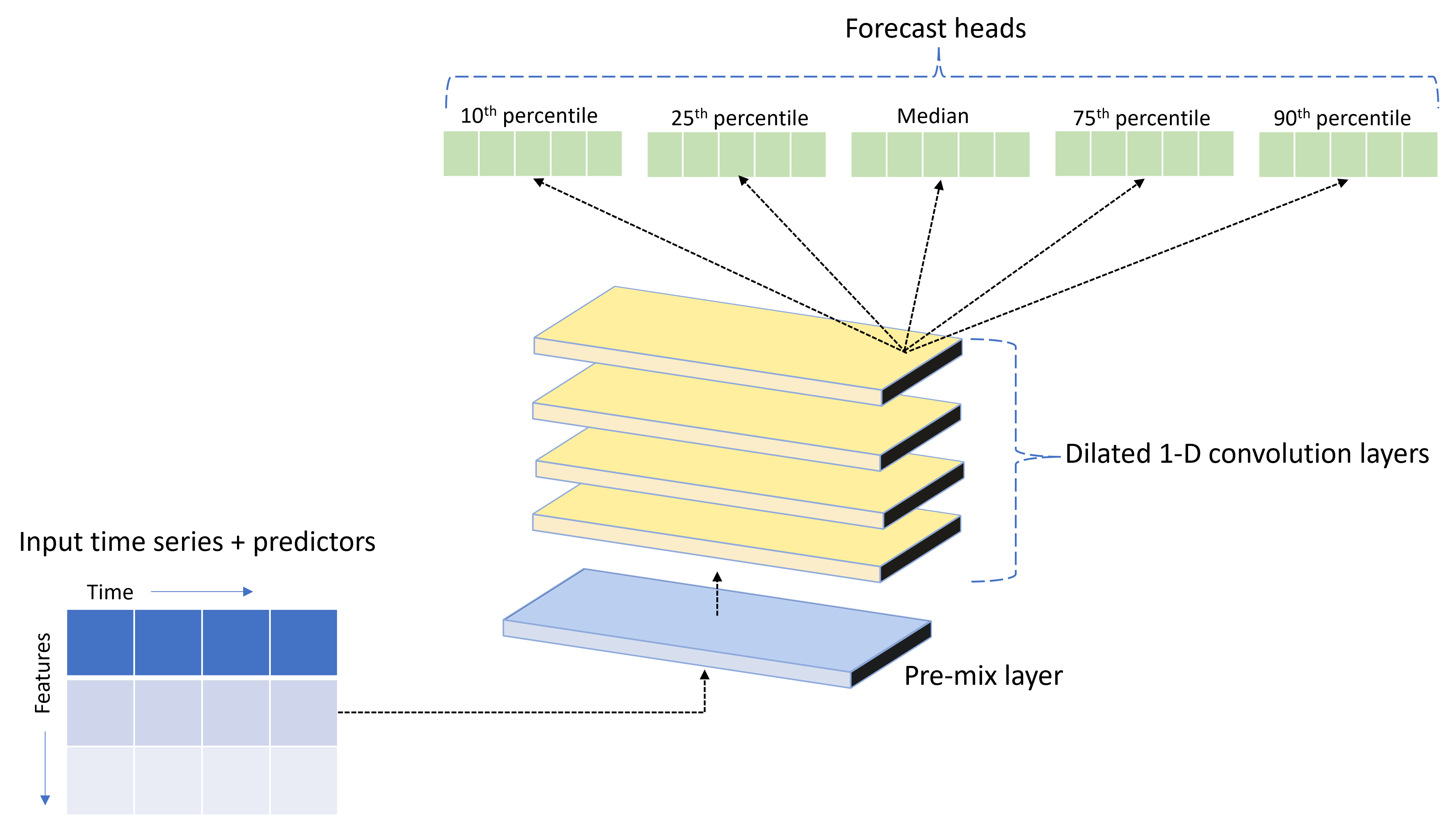
Le TCNForecaster obtient souvent une précision supérieure à celle des modèles de série chronologique standard lorsqu’il y a des milliers d’observations dans l’historique de formation. Toutefois, la formation et le nettoyage des modèles TCNForecaster prennent également plus de temps en raison de leur capacité plus élevée.
Vous pouvez activer le TCNForecaster dans AutoML en définissant l'indicateur enable_dnn_training dans la configuration de formation comme suit :
# Include TCNForecaster models in the model search
forecasting_job.set_training(
enable_dnn_training=True
)
Par défaut, la formation TCNForecaster est limitée à un seul nœud de calcul et à un seul GPU, si disponible, par modèle d'essai. Pour les scénarios de données volumineuses, nous vous recommandons de distribuer chaque essai TCNForecaster sur plusieurs cœurs/GPU et nœuds. Consultez notre section d'articles sur la formation distribuée pour plus d'informations et des exemples de code.
Pour activer DNN pour une expérience AutoML créée dans le studio Azure Machine Learning, consultez les paramètres de type de tâche dans la procédure de l’interface utilisateur Studio.
Notes
- Lorsque vous activez DNN pour les expériences créées avec le Kit de développement logiciel (SDK), les meilleures explications des modèles sont désactivées.
- La prise en charge de DNN pour les prévisions dans le Machine Learning automatisé n’est pas pris en charge pour les exécutions initiées dans Databricks.
- Les types de calcul GPU sont recommandés lorsque la formation DNN est activée
Fonctionnalités de décalage et de fenêtre glissante
Les valeurs récentes de la cible sont souvent des fonctionnalités impactantes dans un modèle de prévision. En conséquence, AutoML peut créer des fonctionnalités d'agrégation de fenêtres décalées et glissantes afin d'améliorer potentiellement la précision du modèle.
Envisagez un scénario de prévision de la demande d’énergie dans lequel des données météorologiques et une demande historique sont disponibles. Le tableau montre l’ingénierie de caractéristiques obtenue qui se produit lors de l’application de l’agrégation de fenêtres sur les trois dernières heures. Les colonnes pour minimum, maximum et somme sont générées sur une fenêtre glissante de trois heures en fonction des paramètres définis. Par exemple, pour l’observation valide du 8 septembre 2017 à 4 h, les valeurs maximum, minimum et somme sont calculées suivant les valeurs de la demande du 8 septembre 2017 entre 1 h et 3 h. Cette fenêtre de trois heures se déplace de façon à remplir les données des lignes restantes. Pour plus de détails et d'exemples, consultez l'article sur les décalages.

Vous pouvez activer les fonctionnalités d'agrégation de décalage et de fenêtre glissante pour la cible en définissant la taille de la fenêtre glissante, qui était de trois dans l'exemple précédent, et les ordres de décalage que vous souhaitez créer. Vous pouvez également activer les décalages pour les fonctionnalités avec le paramètre feature_lags. Dans l'exemple suivant, nous définissons tous ces paramètres sur auto afin qu'AutoML détermine automatiquement les paramètres en analysant la structure de corrélation de vos données :
forecasting_job.set_forecast_settings(
..., # other settings
target_lags='auto',
target_rolling_window_size='auto',
feature_lags='auto'
)
Gestion des séries courtes
Le ML automatisé considère une série chronologique comme une série courte si le nombre de points de données est insuffisant pour mener les phases de formation et de validation du développement du modèle. Pour plus d’informations sur les exigences en matière de longueur des données, consultez Exigences en matière de longueur des données de formation.
AutoML a plusieurs actions qu’il peut effectuer pour les séries courtes. Ces actions sont configurables avec le paramètre short_series_handling_config. La valeur par défaut est « auto ». Le tableau suivant décrit les paramètres :
| Paramètre | Description |
|---|---|
auto |
Valeur par défaut pour la gestion des séries courtes. - Si toutes les séries sont courtes, remplissez les données. - Si toutes les séries ne sont pas courtes, supprimez les séries courtes. |
pad |
Si short_series_handling_config = pad, le ML automatisé ajoute des valeurs aléatoires à chaque série courte trouvée. Vous trouverez ci-dessous la liste des types de colonnes et de leur contenu : - Colonnes d'objets avec « n'est pas un nombre » (NAN) - Colonnes numériques avec 0 - Colonnes booléennes/logiques avec False – La colonne cible est remplie de bruit blanc. |
drop |
Si short_series_handling_config = drop, le ML automatisé supprime la série courte ; celle-ci ne sera donc pas utilisée pour l'apprentissage ou la prédiction. Les prédictions de ces séries renverront NAN. |
None |
Aucune série n'est remplie ou supprimée |
Dans l’exemple suivant, nous définissons la gestion des séries courtes afin que toutes les séries courtes soient remplies jusqu’à la longueur minimale :
forecasting_job.set_forecast_settings(
..., # other settings
short_series_handling_config='pad'
)
Avertissement
Le rembourrage peut avoir un impact sur la précision du modèle résultant, car nous introduisons des données artificielles pour éviter les échecs de formation. Si la plupart des séries sont courtes, vous pouvez également constater un impact sur les résultats de l'explicabilité.
Fréquence et agrégation des données cibles
Utilisez les options de fréquence et d’agrégation de données pour éviter les défaillances causées par des données irrégulières. Vos données sont irrégulières si elles ne suivent pas une cadence définie dans le temps, par exemple toutes les heures ou tous les jours. Les données de point de vente sont un bon exemple de données irrégulières. Dans ce cas, AutoML peut agréger vos données à une fréquence souhaitée, puis générer un modèle de prévision à partir des agrégats.
Vous devez définir les paramètres frequency et target_aggregate_function pour gérer les données irrégulières. Le paramètre de fréquence accepte les chaînes Pandas DateOffset comme entrée. Les valeurs prises en charge pour la fonction d’agrégation sont les suivantes :
| Fonction | Description |
|---|---|
sum |
Somme des valeurs cibles |
mean |
Moyenne des valeurs cibles |
min |
Valeur minimale d’une cible |
max |
Valeur maximale d’une cible |
- Les valeurs de la colonne cible sont agrégées selon l’opération spécifiée. En général, la somme est appropriée pour la plupart des scénarios.
- Les colonnes de prédiction numériques dans vos données sont agrégées par somme, moyenne, valeur minimale et valeur maximale. Par conséquent, le ML automatisé génère de nouvelles colonnes suffixées avec le nom de la fonction d’agrégation et applique l’opération d’agrégation sélectionnée.
- Pour les colonnes de prédiction catégoriques, les données sont agrégées par mode, la catégorie la plus visible dans la fenêtre.
- Les colonnes de prédiction de date sont agrégées par valeur minimale, valeur maximale et mode.
L’exemple suivant définit la fréquence sur toutes les heures et la fonction d’agrégation sur la somme :
# Aggregate the data to hourly frequency
forecasting_job.set_forecast_settings(
..., # other settings
frequency='H',
target_aggregate_function='sum'
)
Paramètres de validation croisée personnalisés
Il existe deux paramètres personnalisables qui contrôlent la validation croisée pour les travaux de prévision : le nombre de replis, n_cross_validations, et la taille d’étape définissant le décalage de temps entre les replis, cv_step_size. Pour plus d’informations sur la signification de ces paramètres, consultez Sélection de modèles de prévision. Par défaut, AutoML définit les deux paramètres automatiquement en fonction des caractéristiques de vos données, mais les utilisateurs avancés peuvent vouloir les définir manuellement. Par exemple, supposons que vous disposez de données de ventes quotidiennes et que votre configuration de validation se compose de cinq replis avec un décalage de sept jours entre les replis adjacents. L’exemple de code suivant montre comment les définir :
from azure.ai.ml import automl
# Create a job with five CV folds
forecasting_job = automl.forecasting(
..., # other training parameters
n_cross_validations=5,
)
# Set the step size between folds to seven days
forecasting_job.set_forecast_settings(
..., # other settings
cv_step_size=7
)
Caractérisation personnalisée
Par défaut, AutoML augmente les données de formation avec des fonctionnalités développées pour augmenter la précision des modèles. Pour plus d’informations, consultez Ingénierie de caractéristiques automatisée. Certaines des étapes de prétraitement peuvent être personnalisées à l'aide de la configuration de caractéristiques de la tâche de prévision.
Les personnalisations prises en charge pour les prévisions sont répertoriées dans le tableau suivant :
| Personnalisation | Description | Options |
|---|---|---|
| Mise à jour de l’objectif de la colonne | Remplacer le type de caractéristique détecté automatiquement pour la colonne spécifiée. | "Catégorique", "DateHeure", "Numérique" |
| Mise à jour des paramètres du transformateur | Mettez à jour les paramètres du processeur d’imputation spécifié. | {"strategy": "constant", "fill_value": <value>}, {"strategy": "median"}, {"strategy": "ffill"} |
Par exemple, supposons que vous ayez un scénario de demande de vente au détail dans lequel les données incluent des prix, un indicateur "en vente" et un type de produit. L’exemple suivant montre comment définir des types et des processus d’imputation personnalisés pour ces fonctionnalités :
from azure.ai.ml.automl import ColumnTransformer
# Customize imputation methods for price and is_on_sale features
# Median value imputation for price, constant value of zero for is_on_sale
transformer_params = {
"imputer": [
ColumnTransformer(fields=["price"], parameters={"strategy": "median"}),
ColumnTransformer(fields=["is_on_sale"], parameters={"strategy": "constant", "fill_value": 0}),
],
}
# Set the featurization
# Ensure that product_type feature is interpreted as categorical
forecasting_job.set_featurization(
mode="custom",
transformer_params=transformer_params,
column_name_and_types={"product_type": "Categorical"},
)
Si vous utilisez le studio Azure Machine Learning pour votre expérience, consultez l’article sur la personnalisation de la caractérisation dans le studio.
Soumettre une tâche de prévision
Une fois tous les paramètres configurés, lancez la tâche de prévision comme suit :
# Submit the AutoML job
returned_job = ml_client.jobs.create_or_update(
forecasting_job
)
print(f"Created job: {returned_job}")
# Get a URL for the job in the AML studio user interface
returned_job.services["Studio"].endpoint
Une fois la tâche soumise, AutoML provisionne les ressources de calcul, applique la caractérisation et d'autres étapes de préparation aux données d'entrée, puis commence à balayer les modèles de prévision. Pour plus de détails, consultez nos articles sur la méthodologie de prévision et la recherche de modèles.
Orchestration de la formation, de l'inférence et de l'évaluation avec des composants et des pipelines
Important
Cette fonctionnalité est actuellement disponible en préversion publique. Cette préversion est fournie sans contrat de niveau de service et n’est pas recommandée pour les charges de travail de production. Certaines fonctionnalités peuvent être limitées ou non prises en charge.
Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Votre flux de travail ML nécessite probablement plus qu'une simple formation. L'inférence ou la récupération des prédictions du modèle sur des données plus récentes et l'évaluation de la précision du modèle sur un ensemble de tests avec des valeurs cibles connues sont d'autres tâches courantes que vous pouvez orchestrer dans AzureML avec les tâches de formation. Pour prendre en charge les tâches d'inférence et d'évaluation, AzureML fournit des composants, qui sont des éléments de code autonomes qui effectuent une étape dans un pipeline AzureML .
Dans l'exemple suivant, nous récupérons le code du composant à partir d'un registre client :
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Create a client for accessing assets in the AzureML preview registry
ml_client_registry = MLClient(
credential=credential,
registry_name="azureml-preview"
)
# Create a client for accessing assets in the AzureML preview registry
ml_client_metrics_registry = MLClient(
credential=credential,
registry_name="azureml"
)
# Get an inference component from the registry
inference_component = ml_client_registry.components.get(
name="automl_forecasting_inference",
label="latest"
)
# Get a component for computing evaluation metrics from the registry
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
Ensuite, nous définissons une fonction d'usine qui crée des pipelines orchestrant la formation, l'inférence et le calcul des indicateurs de performance. Voir la section de configuration de la formation pour plus de détails sur les paramètres de formation.
from azure.ai.ml import automl
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml.dsl import pipeline
@pipeline(description="AutoML Forecasting Pipeline")
def forecasting_train_and_evaluate_factory(
train_data_input,
test_data_input,
target_column_name,
time_column_name,
forecast_horizon,
primary_metric='normalized_root_mean_squared_error',
cv_folds='auto'
):
# Configure the training node of the pipeline
training_node = automl.forecasting(
training_data=train_data_input,
target_column_name=target_column_name,
primary_metric=primary_metric,
n_cross_validations=cv_folds,
outputs={"best_model": Output(type=AssetTypes.MLFLOW_MODEL)},
)
training_node.set_forecasting_settings(
time_column_name=time_column_name,
forecast_horizon=max_horizon,
frequency=frequency,
# other settings
...
)
training_node.set_training(
# training parameters
...
)
training_node.set_limits(
# limit settings
...
)
# Configure the inference node to make rolling forecasts on the test set
inference_node = inference_component(
test_data=test_data_input,
model_path=training_node.outputs.best_model,
target_column_name=target_column_name,
forecast_mode='rolling',
forecast_step=1
)
# Configure the metrics calculation node
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
ground_truth=inference_node.outputs.inference_output_file,
prediction=inference_node.outputs.inference_output_file,
evaluation_config=inference_node.outputs.evaluation_config_output_file
)
# return a dictionary with the evaluation metrics and the raw test set forecasts
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result,
"rolling_fcst_result": inference_node.outputs.inference_output_file
}
Maintenant, nous définissons les entrées de données de formation et de test en supposant qu'elles sont contenues dans des dossiers locaux, ./train_data et ./test_data :
my_train_data_input = Input(
type=AssetTypes.MLTABLE,
path="./train_data"
)
my_test_data_input = Input(
type=AssetTypes.URI_FOLDER,
path='./test_data',
)
Enfin, nous construisons le pipeline, définissons son calcul par défaut et soumettons la tâche :
pipeline_job = forecasting_train_and_evaluate_factory(
my_train_data_input,
my_test_data_input,
target_column_name,
time_column_name,
forecast_horizon
)
# set pipeline level compute
pipeline_job.settings.default_compute = compute_name
# submit the pipeline job
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name
)
returned_pipeline_job
Une fois soumis, le pipeline exécute la formation AutoML, l'inférence d'évaluation progressive et le calcul d’indicateurs de performance dans l'ordre. Vous pouvez surveiller et inspecter l'exécution dans l'interface utilisateur du studio. Une fois l'exécution terminée, les prévisions glissantes et les indicateurs de performance d'évaluation peuvent être téléchargées dans le répertoire de travail local :
# Download the metrics json
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='metrics_result')
# Download the rolling forecasts
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='rolling_fcst_result')
Ensuite, vous pouvez trouver les résultats des indicateurs de performance dans ./named-outputs/metrics_results/evaluationResult/metrics.json et les prévisions, au format lignes JSON, dans ./named-outputs/rolling_fcst_result/inference_output_file.
Pour plus de détails sur l'évaluation continue, consultez notre article sur l'évaluation du modèle de prévision.
Prévision à grande échelle : de nombreux modèles
Important
Cette fonctionnalité est actuellement disponible en préversion publique. Cette préversion est fournie sans contrat de niveau de service et n’est pas recommandée pour les charges de travail de production. Certaines fonctionnalités peuvent être limitées ou non prises en charge.
Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Les nombreux composants de modèles d'AutoML vous permettent d'entraîner et de gérer des millions de modèles en parallèle. Pour plus d'informations sur de nombreux concepts de modèles, consultez la section de l'article sur les nombreux modèles.
Configuration de formation de nombreux modèles
Le composant de formation de nombreux modèles accepte un fichier de configuration au format YAML des paramètres de formation AutoML. Le composant applique ces paramètres à chaque instance AutoML qu'il lance. Ce fichier YAML a la même spécification que la tâche de prévision, plus des paramètres supplémentaires partition_column_names et allow_multi_partitions.
| Paramètre | Description |
|---|---|
| partition_column_names | Noms de colonne dans les données qui, lorsqu'ils sont regroupés, définissent les partitions de données. Le composant de formation de nombreux modèles lance une tâche de formation indépendante sur chaque partition. |
| allow_multi_partitions | Un indicateur facultatif qui permet de former un modèle par partition lorsque chaque partition contient plusieurs séries temporelles uniques. La valeur par défaut est False. |
L'exemple suivant fournit un modèle de configuration :
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:<cluster-name>
task: forecasting
primary_metric: normalized_root_mean_squared_error
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: date
time_series_id_column_names: ["state", "store"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
partition_column_names: ["state", "store"]
allow_multi_partitions: false
Dans les exemples suivants, nous supposons que la configuration est stockée dans le chemin, ./automl_settings_mm.yml.
Pipeline de nombreux modèles
Ensuite, nous définissons une fonction d'usine qui crée des pipelines pour l'orchestration de nombreux modèles de formation, d'inférence et de calcul de indicateurs de performance. Les paramètres de cette fonction usine sont détaillés dans le tableau suivant :
| Paramètre | Description |
|---|---|
| max_nodes | Nombre de nœuds de calcul à utiliser dans la tâche de formation |
| max_concurrency_per_node | Nombre de processus AutoML à exécuter sur chaque nœud. Par conséquent, la simultanéité totale d'un grand nombre de travaux de modèles est max_nodes * max_concurrency_per_node. |
| parallel_step_timeout_in_seconds | Délai d'expiration des composants de nombreux modèles exprimé en nombre de secondes. |
| retrain_failed_models | Indicateur pour activer le réentraînement des modèles défaillants. Ceci est utile si vous avez déjà effectué de nombreuses exécutions de modèles qui ont entraîné l'échec de tâches AutoML sur certaines partitions de données. Lorsque cet indicateur est activé, de nombreux modèles lancent uniquement des tâches de formation pour les partitions précédemment défaillantes. |
| forecast_mode | Mode d'inférence pour l'évaluation du modèle. Les valeurs valides sont "recursive" et "rolling". Voir l'article sur l'évaluation du modèle pour plus d'informations. |
| forecast_step | Taille de pas pour les prévisions glissantes. Voir l'article sur l'évaluation du modèle pour plus d'informations. |
L'exemple suivant illustre une méthode d'usine pour la construction de nombreux pipelines de formation et d'évaluation de modèles :
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a many models training component
mm_train_component = ml_client_registry.components.get(
name='automl_many_models_training',
version='latest'
)
# Get a many models inference component
mm_inference_component = ml_client_registry.components.get(
name='automl_many_models_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML Many Models Forecasting Pipeline")
def many_models_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
compute_name,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
retrain_failed_model=False,
forecast_mode="rolling",
forecast_step=1
):
mm_train_node = mm_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
retrain_failed_model=retrain_failed_model,
compute_name=compute_name
)
mm_inference_node = mm_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=mm_train_node.outputs.run_output,
forecast_mode=forecast_mode,
forecast_step=forecast_step,
compute_name=compute_name
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=mm_inference_node.outputs.evaluation_data,
ground_truth=mm_inference_node.outputs.evaluation_data,
evaluation_config=mm_inference_node.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
Maintenant, nous construisons le pipeline via la fonction factory, en supposant que les données de formation et de test se trouvent respectivement dans les dossiers locaux ./data/train et ./data/test. Enfin, nous définissons le calcul par défaut et soumettons la tâche comme dans l'exemple suivant :
pipeline_job = many_models_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_mm.yml"
),
compute_name="<cluster name>"
)
pipeline_job.settings.default_compute = "<cluster name>"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
Une fois la tâche terminée, les indicateurs de performance d'évaluation peuvent être téléchargées localement à l'aide de la même procédure que dans le pipeline d'exécution de formation unique.
Voir également le cahier de prévision de la demande avec de nombreux modèles pour un exemple plus détaillé.
Notes
Les nombreux composants de formation et d'inférence des modèles partitionnent conditionnellement vos données en fonction du paramètre partition_column_names afin que chaque partition se trouve dans son propre fichier. Ce processus peut être très lent ou échouer lorsque les données sont très volumineuses. Dans ce cas, nous vous recommandons de partitionner vos données manuellement avant d'exécuter de nombreux modèles de formation ou d'inférence.
Prévision à grande échelle : séries chronologiques hiérarchiques
Important
Cette fonctionnalité est actuellement disponible en préversion publique. Cette préversion est fournie sans contrat de niveau de service et n’est pas recommandée pour les charges de travail de production. Certaines fonctionnalités peuvent être limitées ou non prises en charge.
Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Les composants de séries chronologiques hiérarchiques (HTS) d'AutoML vous permettent d'entraîner un grand nombre de modèles sur des données à structure hiérarchique. Pour plus d'informations, consultez la section de l'article HTS.
Configuration de la formation HTS
Le composant de formation HTS accepte un fichier de configuration au format YAML des paramètres de formation AutoML. Le composant applique ces paramètres à chaque instance AutoML qu'il lance. Ce fichier YAML a la même spécification que le travail de prévision, plus des paramètres supplémentaires liés aux informations de hiérarchie :
| Paramètre | Description |
|---|---|
| hierarchy_column_names | Une liste de noms de colonnes dans les données qui définissent la structure hiérarchique des données. L'ordre des colonnes dans cette liste détermine les niveaux de hiérarchie ; le degré d'agrégation diminue avec l'indice de liste. Autrement dit, la dernière colonne de la liste définit le niveau feuille (le plus désagrégé) de la hiérarchie. |
| hierarchy_training_level | Le niveau de hiérarchie à utiliser pour la formation du modèle de prévision. |
Voici un exemple de configuration :
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:cluster-name
task: forecasting
primary_metric: normalized_root_mean_squared_error
log_verbosity: info
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: "date"
time_series_id_column_names: ["state", "store", "SKU"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
hierarchy_column_names: ["state", "store", "SKU"]
hierarchy_training_level: "store"
Dans les exemples suivants, nous supposons que la configuration est stockée dans le chemin, ./automl_settings_hts.yml.
Pipeline HTS
Ensuite, nous définissons une fonction d'usine qui crée des pipelines pour l'orchestration de la formation, de l'inférence et du calcul des indicateurs de performance HTS. Les paramètres de cette fonction usine sont détaillés dans le tableau suivant :
| Paramètre | Description |
|---|---|
| forecast_level | Le niveau de la hiérarchie pour récupérer les prévisions pour |
| allocation_method | Méthode de répartition à utiliser lorsque les prévisions sont désagrégées. Les valeurs valides sont "proportions_of_historical_average" et "average_historical_proportions". |
| max_nodes | Nombre de nœuds de calcul à utiliser dans la tâche de formation |
| max_concurrency_per_node | Nombre de processus AutoML à exécuter sur chaque nœud. Par conséquent, la simultanéité totale d'un travail HTS est max_nodes * max_concurrency_per_node. |
| parallel_step_timeout_in_seconds | Délai d'expiration des composants de nombreux modèles exprimé en nombre de secondes. |
| forecast_mode | Mode d'inférence pour l'évaluation du modèle. Les valeurs valides sont "recursive" et "rolling". Voir l'article sur l'évaluation du modèle pour plus d'informations. |
| forecast_step | Taille de pas pour les prévisions glissantes. Voir l'article sur l'évaluation du modèle pour plus d'informations. |
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a HTS training component
hts_train_component = ml_client_registry.components.get(
name='automl_hts_training',
version='latest'
)
# Get a HTS inference component
hts_inference_component = ml_client_registry.components.get(
name='automl_hts_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML HTS Forecasting Pipeline")
def hts_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
forecast_mode="rolling",
forecast_step=1,
forecast_level="SKU",
allocation_method='proportions_of_historical_average'
):
hts_train = hts_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
max_nodes=max_nodes
)
hts_inference = hts_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=hts_train.outputs.run_output,
forecast_level=forecast_level,
allocation_method=allocation_method,
forecast_mode=forecast_mode,
forecast_step=forecast_step
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=hts_inference.outputs.evaluation_data,
ground_truth=hts_inference.outputs.evaluation_data,
evaluation_config=hts_inference.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
Maintenant, nous construisons le pipeline via la fonction factory, en supposant que les données de formation et de test se trouvent respectivement dans les dossiers locaux ./data/train et ./data/test. Enfin, nous définissons le calcul par défaut et soumettons la tâche comme dans l'exemple suivant :
pipeline_job = hts_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_hts.yml"
)
)
pipeline_job.settings.default_compute = "cluster-name"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
Une fois la tâche terminée, les indicateurs de performance d'évaluation peuvent être téléchargées localement à l'aide de la même procédure que dans le pipeline d'exécution de formation unique.
Voir également le bloc-notes de prévision de la demande avec des séries chronologiques hiérarchiques pour un exemple plus détaillé.
Notes
Les composants de formation et d'inférence HTS partitionnent conditionnellement vos données en fonction du paramètre hierarchy_column_names afin que chaque partition se trouve dans son propre fichier. Ce processus peut être très lent ou échouer lorsque les données sont très volumineuses. Dans ce cas, nous vous recommandons de partitionner vos données manuellement avant d'exécuter la formation ou l'inférence HTS.
Prévision à grande échelle : formation DNN distribuée
- Pour savoir comment fonctionne la formation distribuée pour les tâches de prévision, consultez notre article sur les prévisions à grande échelle.
- Consultez notre section d'article de formation distribuée sur la configuration pour les données tabulaires pour des exemples de code.
Exemples de notebooks
Consultez les exemples de notebooks de prévision pour obtenir des exemples de code détaillés de la configuration de prévision avancée, notamment :
- Exemples de pipeline de prévision de la demande
- Modèles d’apprentissage profond
- Détection et personnalisation de congé
- Configuration manuelle des décalages et des fonctionnalités d'agrégation de fenêtres glissantes
Étapes suivantes
- En savoir plus sur Comment déployer un modèle AutoML sur un point de terminaison en ligne.
- Découvrez l’interprétabilité : explications des modèles en machine learning automatisé (préversion).
- Découvrez comment AutoML génère des modèles de prévision.
- En savoir plus sur les prévisions à grande échelle.
- Découvrez comment configurer AutoML pour différents scénarios de prévision.
- En savoir plus sur l'inférence et l'évaluation des modèles de prévision.