Sélectionner des algorithmes Azure Machine Learning
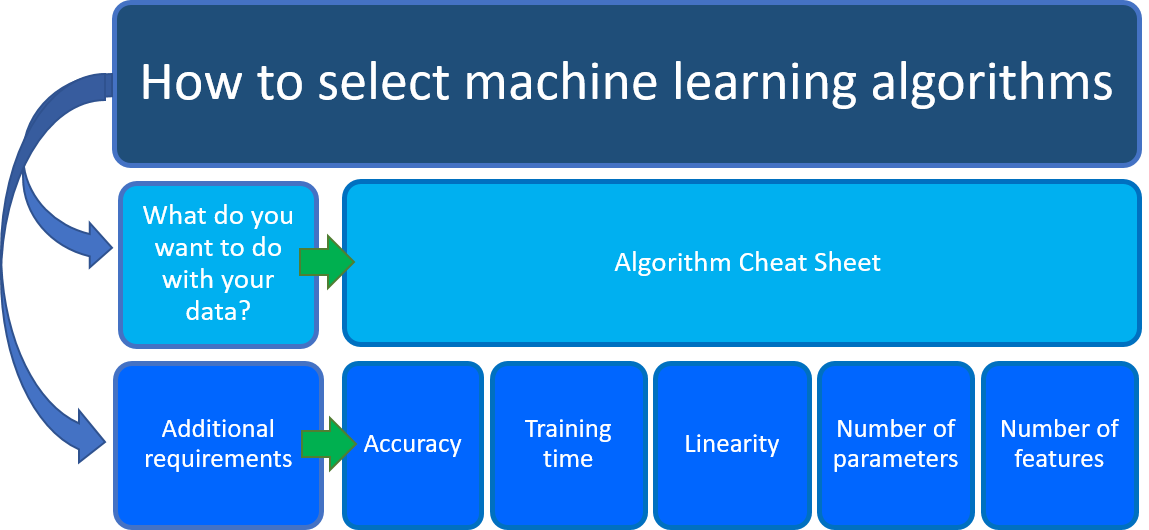
Vous êtes nombreux à vous poser la question suivante : « Quel algorithme d'apprentissage automatique dois-je utiliser ? ». Le choix de l'algorithme repose principalement sur deux aspects distincts de votre scénario de science des données :
Que voulez-vous faire avec vos données ? Plus précisément, quelle est la question à laquelle vous souhaitez répondre à partir de vos données passées ?
Quelles sont les exigences propres à votre scénario de science des données ? Plus précisément, quels sont la précision, la durée d'apprentissage, la linéarité, le nombre de paramètres et le nombre de fonctionnalités pris en charge par votre solution ?
Remarque
Le concepteur prend en charge deux types de composants, les composants prédéfinis classiques (v1) et les composants personnalisés (v2). Ces deux types de composants ne sont PAS compatibles.
Les composants prédéfinis classiques fournissent principalement des composants prédéfinis utilisés pour le traitement des données et les tâches de Machine Learning traditionnelles telles que la régression et la classification. Ce type de composant continue d’être pris en charge, mais aucun nouveau composant n’est ajouté.
Les composants personnalisés vous permettent d’encapsuler votre propre code en tant que composant. Ils vous permettent de partager des composants dans des espaces de travail et de créer en toute transparence dans des interfaces Studio, CLI v2 et le Kit de développement logiciel (SDK) v2.
Pour les nouveaux projets, nous vous suggérons vivement d’utiliser un composant personnalisé et compatible avec AzureML V2 qui va continuer à recevoir de nouvelles mises à jour.
Cet article s’applique aux composants classiques, prédéfinis et non compatibles avec l’interface CLI v2 et le kit de développement logiciel (SDK) v2.
Scénarios d'entreprise et Aide-mémoire sur les algorithmes Machine Learning
L'Aide-mémoire sur les algorithmes Azure Machine Learning vous permet de répondre à la première question : Que voulez-vous faire avec vos données ? ? Utilisez l’Aide-mémoire sur les algorithmes Machine Learning pour rechercher la tâche que vous souhaitez effectuer, puis recherchez un algorithme de concepteur Azure Machine Learning pour la solution d’analyse prédictive.
Le concepteur Machine Learning fournit une gamme complète d'algorithmes, tels que Forêt d'arbres de décision multiclasse, Systèmes de recommandation, Régression de réseau neuronal, Réseau neuronal multiclasse et Clustering k-moyennes. Chaque algorithme est conçu pour traiter un type particulier de problème d'apprentissage automatique. Consultez Référence sur les algorithmes et composants du concepteur Machine Learning pour obtenir une liste complète ainsi que de la documentation sur le fonctionnement de chaque algorithme et le réglage des paramètres pour l’optimiser.
Notes
Téléchargez l’aide-mémoire ici : Aide-mémoire d’algorithme Machine Learning (11x17 pouces)
Outre les conseils fournis par l'Aide-mémoire sur les algorithmes Azure Machine Learning, vous devez tenir compte d'autres exigences lors du choix d'un algorithme d'apprentissage automatique pour votre solution. Vous trouverez ci-dessous d'autres facteurs à prendre en compte, comme la précision, la durée d'apprentissage, la linéarité, le nombre de paramètres et le nombre de fonctionnalités.
Comparaison des algorithmes d’apprentissage automatique
Certains algorithmes d'apprentissage effectuent des hypothèses particulières sur la structure des données ou les résultats souhaités. Si vous pouvez en trouver un qui répond à vos besoins, il peut vous donner des résultats plus pertinents, des prévisions plus précises ou des durées d'apprentissage plus courtes.
Le tableau suivant résume certaines des caractéristiques les plus importantes des algorithmes des familles de classification, régression et clustering :
| Algorithme | Précision | Durée d’apprentissage | Linéarité | Paramètres | Remarques |
|---|---|---|---|---|---|
| Famille de classification | |||||
| Régression logistique à deux classes | Bonne | Rapide | Oui | 4 | |
| Forêt d’arbres décisionnels à deux classes | Excellent | Modéré | Non | 5 | Affiche des temps de scoring plus lents. Suggestion de ne pas travailler avec One-vs-All Multiclass, en raison des temps de scoring plus lents causé par le verrouillage des threads lors de l’accumulation des prédictions d’arborescence |
| Arbre de décision optimisé à deux classes | Excellent | Modéré | Non | 6 | Encombrement de mémoire important |
| Réseau neuronal à deux classes | Bonne | Modéré | Non | 8 | |
| Perceptron moyenné à deux classes | Bonne | Modéré | Oui | 4 | |
| Machine à vecteurs de support à deux classes | Bonne | Rapide | Oui | 5 | Idéal pour les ensembles de fonctionnalités de grande taille |
| Régression logistique multiclasse | Bonne | Rapide | Oui | 4 | |
| Forêt d’arbres de décision multiclasse | Excellent | Modéré | Non | 5 | Affiche des temps de scoring plus lents. |
| Arbre de décision multiclasse optimisé | Excellent | Modéré | Non | 6 | A tendance à améliorer la précision avec un léger risque de diminution de la couverture |
| Réseau neuronal multiclasse | Bonne | Modéré | Non | 8 | |
| One-vs-all multiclass | - | - | - | - | Consultez les propriétés de la méthode à deux classes sélectionnée |
| Famille de régression | |||||
| Régression linéaire | Bonne | Rapide | Oui | 4 | |
| Régression de forêt d’arbres de décision | Excellent | Modéré | Non | 5 | |
| Régression d’arbre de décision boosté | Excellent | Modéré | Non | 6 | Encombrement de mémoire important |
| Régression de réseau neuronal | Bonne | Modéré | Non | 8 | |
| Famille de clustering | |||||
| Clustering k-moyennes | Excellent | Modéré | Oui | 8 | Un algorithme de clustering |
Exigences d’un scénario de science des données
Après avoir déterminé ce que vous voulez faire avec vos données, vous devez tenir compte d'autres exigences pour votre solution.
Faites des choix, voire des compromis, pour les exigences suivantes :
- Précision
- Durée d’apprentissage
- Linéarité
- Nombre de paramètres
- Nombre de fonctionnalités
Précision
Dans le domaine de l'apprentissage automatique, la précision mesure l'efficacité d'un modèle sous forme de proportion de résultats réels sur le nombre total de cas. Dans le concepteur Machine Learning, le composant Évaluer le modèle calcule un ensemble de métriques d’évaluation standard. Vous pouvez utiliser ce composant pour mesurer la précision d’un modèle formé.
Il n'est pas toujours nécessaire d'obtenir la réponse la plus exacte possible. Parfois, en fonction de votre utilisation, une approximation suffit. Dans ce cas, vous réduirez probablement considérablement le temps de traitement en ayant recours à des méthodes plus approximatives. Les méthodes approximatives tendent aussi naturellement à éviter le surajustement.
Il existe trois façons d’utiliser le composant Évaluer le modèle :
- Générer des scores sur vos données d'apprentissage afin d'évaluer le modèle
- Générer des scores sur le modèle, mais comparer ces scores à ceux d’un jeu de tests réservé
- Comparer les scores de deux modèles différents mais liés, en utilisant le même jeu de données
Pour obtenir la liste complète des métriques et approches disponibles afin d’évaluer la précision des modèles Machine Learning, consultez Composant Évaluer le modèle.
Durée d’apprentissage
Dans le cadre d'un apprentissage supervisé, la formation consiste à utiliser des données historiques pour créer un modèle Machine Learning qui réduit les risques d'erreurs. Le nombre de minutes ou d'heures nécessaires pour l'apprentissage d'un modèle varie beaucoup selon les algorithmes. La durée d'apprentissage est souvent étroitement liée à la précision : l'une accompagne généralement l'autre.
En outre, certains algorithmes sont plus sensibles au nombre de points de données que d'autres. Vous pouvez être amené à choisir un algorithme spécifique parce que le temps dont vous disposez est limité, en particulier lorsque le jeu de données est volumineux.
Dans le concepteur Machine Learning, la création et l'utilisation d'un modèle Machine Learning s'effectuent généralement en trois étapes :
Configurez un modèle en choisissant un type d'algorithme particulier et en définissant ses paramètres ou hyperparamètres.
Fournissez un jeu de données doté d'une étiquette et dont les données sont compatibles avec l'algorithme. Connectez les données et le modèle au composant Effectuer l’apprentissage du modèle.
Au terme de l’apprentissage, utilisez le modèle formé avec l’un des composants de scoring pour effectuer des prédictions sur de nouvelles données.
Linéarité
Dans les domaines des statistiques et de l'apprentissage automatique, le terme « linéarité » signifie qu'il existe une relation linéaire entre une variable et une constante de votre jeu de données. Par exemple, les algorithmes de classification linéaires supposent que les classes peuvent être séparées par une ligne droite (ou son analogue de dimension supérieure).
Un grand nombre d'algorithmes d'apprentissage automatique utilisent la linéarité. Dans le concepteur Azure Machine Learning, ces algorithmes sont les suivants :
- Régression logistique multiclasse
- Régression logistique à deux classes
- Machines à vecteurs de support
Les algorithmes de régression linéaire supposent que les tendances des données suivent une ligne droite. Ce postulat convient à certains problèmes, mais pour d'autres, il réduit la précision. Malgré leurs inconvénients, les algorithmes linéaires constituent une première stratégie très prisée. Ils ont tendance à être des algorithmes simples et à apprentissage rapide.

Limite de classe non linéaire : l’utilisation d’un algorithme de classification linéaire entraînerait une justesse faible.
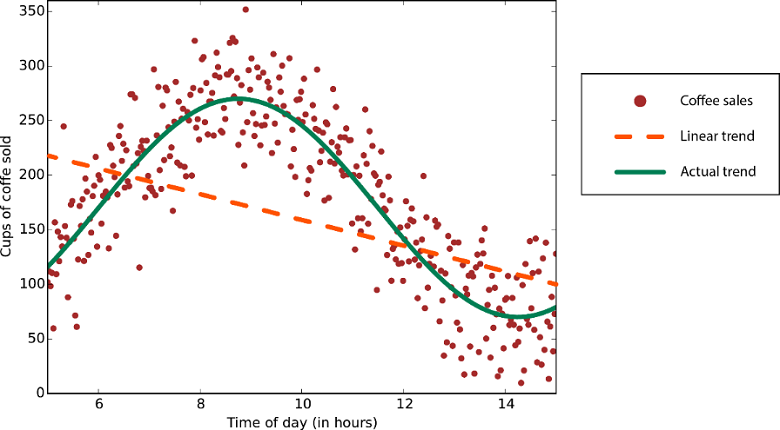
Données avec une tendance non linéaire : l’utilisation d’une méthode de régression linéaire entraînerait plus d’erreurs.
Nombre de paramètres
Les paramètres sont les boutons que les scientifiques des données règlent lorsqu’ils configurent un algorithme. Ce sont des nombres qui affectent le comportement de l'algorithme, comme la tolérance aux erreurs ou le nombre d'itérations, ou les variantes du comportement de l'algorithme. La durée d'apprentissage et la précision de l'algorithme peuvent parfois dépendre du choix des paramètres appropriés. En règle générale, les algorithmes avec des paramètres à grands nombres nécessitent plus d’essais pour trouver la bonne combinaison.
Vous pouvez également utiliser le composant Optimiser les hyperparamètres du modèle dans le concepteur Machine Learning : l’objectif de ce composant est de déterminer les hyperparamètres optimaux pour un modèle Machine Learning. Le composant génère et teste plusieurs modèles avec différentes combinaisons de paramètres. Il compare les métriques à tous les modèles pour obtenir les combinaisons de paramètres.
Même si c'est un excellent moyen de vous assurer que vous avez examiné l'espace de paramétrage, le temps nécessaire pour former un modèle augmente de façon exponentielle avec le nombre de paramètres. Avoir de nombreux paramètres indique généralement qu'un algorithme a une plus grande flexibilité. Cette méthode donne souvent une excellente précision, une fois que vous avez trouvé la bonne combinaison de paramètres.
Nombre de fonctionnalités
Dans le domaine de l'apprentissage automatique, une fonctionnalité est une variable quantifiable du phénomène que vous essayez d'analyser. Pour certains types de données, le nombre de fonctionnalités peut être très important par rapport au nombre de points de données. C'est souvent le cas avec les données génétiques ou textuelles.
La présence d'un grand nombre de fonctionnalités peut ralentir certains algorithmes d'apprentissage et se traduire par une durée d'apprentissage ingérable. Les machines à vecteurs de support sont particulièrement bien adaptées aux scénarios comportant un grand nombre de fonctionnalités. C'est la raison pour laquelle elles sont utilisées dans de nombreuses applications, de la récupération d'informations à la classification de textes et d'images. Les machines à vecteurs de support peuvent être utilisées pour les tâches de classification et de régression.
Le terme « sélection de fonctionnalités » fait référence au processus d'application de tests statistiques à des entrées, en fonction d'une sortie donnée. L’objectif est de déterminer quelles colonnes prédisent le mieux la sortie. Le composant Sélection de fonctionnalités basée sur les filtres dans le concepteur Machine Learning permet de choisir parmi plusieurs algorithmes de sélection de fonctionnalités. Le composant inclut des méthodes de corrélation telles que les valeurs de corrélation de Pearson et de test du khi-deux.
Vous pouvez également utiliser le composant Importance de la fonctionnalité de permutation pour calculer un ensemble de scores d’importance de fonctionnalité pour votre jeu de données. Vous pouvez ensuite vous aider de ces scores pour déterminer les meilleures fonctionnalités à utiliser dans un modèle.
Étapes suivantes
- En savoir plus sur le concepteur Azure Machine Learning
- Pour des descriptions de tous les algorithmes d’apprentissage automatique disponibles dans le concepteur Azure Machine Learning, consultez Référence sur les algorithmes et composants du concepteur Machine Learning
- Pour en savoir plus sur la relation entre le Deep Learning, le Machine Learning et l'IA, consultez Deep Learning et Machine Learning