Optimisation des hyperparamètres d’un modèle (v2)
S’APPLIQUE À : Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Automatisez l’optimisation efficace des hyperparamètres à l’aide du SDK Azure Machine Learning v2 et de CLI v2 à l’aide du type SweepJob.
- Définir l’espace de recherche de paramètres pour votre essai
- Spécifier l’algorithme d’échantillonnage pour votre travail de balayage
- Spécifier l’objectif à optimiser
- Spécifier la stratégie d’arrêt précoce pour les travaux à faibles performances
- Définir les limites du travail de balayage
- Lancer une expérience avec la configuration définie
- Visualiser les travaux d’entraînement
- Sélectionner la meilleure configuration pour votre modèle
Qu’est-ce que l’optimisation des hyperparamètres ?
Les hyperparamètres sont des paramètres réglables qui vous permettent de contrôler le processus d’entraînement du modèle. Par exemple, avec des réseaux neuronaux, vous déterminez le nombre de couches masquées et le nombre de nœuds dans chaque couche. Les performances du modèle dépendent fortement des hyperparamètres.
L’optimisation des hyperparamètres est le processus de recherche de la configuration des hyperparamètres qui produit les meilleures performances. Le processus est généralement manuel et gourmand en ressources informatiques.
Azure Machine Learning vous permet d’automatiser l’optimisation des hyperparamètres et d’exécuter des expérimentations parallèles pour optimiser efficacement les hyperparamètres.
Définir l’espace de recherche
Optimisez les hyperparamètres en explorant la plage de valeurs définie pour chaque hyperparamètre.
Les hyperparamètres peuvent être discrets ou continus et ont une distribution des valeurs décrite par une expression de paramètre.
Hyperparamètres discrets
Les hyperparamètres discrets sont spécifiés en tant que Choice parmi des valeurs discrètes. Voici à quoi Choice peut correspondre :
- une ou plusieurs valeurs séparées par une virgule
- un objet
range - un objet
listarbitraire
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32, 64, 128]),
number_of_hidden_layers=Choice(values=range(1,5)),
)
Dans ce cas, batch_size prend l’une des valeurs [16, 32, 64, 128] et number_of_hidden_layers prend l’une des valeurs [1, 2, 3, 4].
Les hyperparamètres discrets avancés suivants peuvent également être spécifiés en utilisant une distribution.
QUniform(min_value, max_value, q)- Retourne une valeur telle que round(Uniform(min_value, max_value) / q) * qQLogUniform(min_value, max_value, q)- Retourne une valeur telle que round(exp(Uniform(min_value, max_value)) / q) * qQNormal(mu, sigma, q)- Retourne une valeur telle que round(Normal(mu, sigma) / q) * qQLogNormal(mu, sigma, q)- Retourne une valeur telle que round(exp(Normal(mu, sigma)) / q) * q
Hyperparamètres continus
Les hyperparamètres continus sont spécifiés comme une distribution sur une plage continue de valeurs :
Uniform(min_value, max_value)- Retourne une valeur répartie uniformément entre min_value et max_valueLogUniform(min_value, max_value)- Retourne une valeur calculée en fonction de exp(uniform(min_value, max_value)), de sorte que le logarithme de la valeur de retour présente une distribution uniforme.Normal(mu, sigma): retourne une valeur réelle qui est normalement distribuée avec la moyenne mu et l’écart type sigmaLogNormal(mu, sigma): retourne une valeur calculée en fonction de exp(normal(mu, sigma)), de sorte que le logarithme de la valeur de retour est normalement distribué
Voici un exemple de définition d’espace de paramètres :
from azure.ai.ml.sweep import Normal, Uniform
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
)
Ce code définit un espace de recherche avec deux paramètres : learning_rate et keep_probability. learning_rate présente une distribution normale avec une valeur moyenne de 10 et un écart type de 3. keep_probability présente une distribution uniforme avec une valeur minimale de 0,05 et une valeur maximale de 0,1.
Pour l’interface CLI, vous pouvez utiliser le schéma YAML du travail de balayage pour définir l’espace de recherche dans votre fichier YAML :
search_space:
conv_size:
type: choice
values: [2, 5, 7]
dropout_rate:
type: uniform
min_value: 0.1
max_value: 0.2
Échantillonnage de l’espace des hyperparamètres
Spécifiez la méthode d’échantillonnage des paramètres à utiliser dans l’espace des hyperparamètres. Azure Machine Learning prend en charge les méthodes suivantes :
- Échantillonnage aléatoire
- Échantillonnage par grille
- Échantillonnage bayésien
Échantillonnage aléatoire
L’échantillonnage aléatoire prend en charge les hyperparamètres discrets et continus. Il prend en charge l’arrêt précoce des travaux à faibles performances. Certains utilisateurs effectuent une recherche initiale avec l’échantillonnage aléatoire, puis affinent l’espace de recherche pour améliorer les résultats.
Dans l’échantillonnage aléatoire, les valeurs des hyperparamètres sont sélectionnées de façon aléatoire à partir de l’espace de recherche défini. Après avoir créé votre travail de commande, vous pouvez utiliser le paramètre de balayage pour définir l’algorithme d’échantillonnage.
from azure.ai.ml.sweep import Normal, Uniform, RandomParameterSampling
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "random",
...
)
Sobol
Sobol est un type d’échantillonnage aléatoire pris en charge par les types de travaux de balayage. Vous pouvez utiliser sobol pour reproduire vos résultats à l’aide de l’amorçage et couvrir la distribution de l’espace de recherche plus uniformément.
Pour utiliser sobol, utilisez la classe RandomParameterSampling pour ajouter la valeur initiale et la règle, comme illustré dans l’exemple ci-dessous.
from azure.ai.ml.sweep import RandomParameterSampling
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = RandomParameterSampling(seed=123, rule="sobol"),
...
)
Échantillonnage par grille
L’échantillonnage de grille prend en charge les hyperparamètres discrets. Utilisez l’échantillonnage de grille si vous avez un budget pour effectuer une recherche exhaustive sur l’espace de recherche. Prend en charge l’arrêt précoce des travaux à faibles performances.
L’échantillonnage de grille effectue une recherche par grille simple sur toutes les valeurs possibles. L’échantillonnage de grille ne peut être utilisé qu’avec des hyperparamètres choice. Par exemple, l’espace suivant compte six échantillons :
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32]),
number_of_hidden_layers=Choice(values=[1,2,3]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "grid",
...
)
Échantillonnage bayésien
L’échantillonnage bayésien est basé sur l’algorithme d’optimisation bayésienne. Il choisit des exemples en fonction des performances des exemples précédents, afin que les nouveaux exemples améliorent la métrique principale.
L’échantillonnage bayésien est recommandé si vous disposez d’un budget suffisant pour explorer l’espace hyperparamétrique. Pour de meilleurs résultats, nous recommandons un nombre maximal de travaux supérieur ou égal à 20 fois le nombre d’hyperparamètres configurés.
Le nombre de travaux simultanés a un impact sur l’efficacité du processus d’optimisation. Un nombre inférieur de travaux simultanés peut déboucher sur une meilleure convergence d’échantillonnage, car le plus faible degré de parallélisme accroît le nombre de travaux qui bénéficient des travaux ayant abouti précédemment.
L’échantillonnage bayésien prend en charge seulement les distributions choice, uniform et quniform sur l’espace de recherche.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
...
)
Spécifier l’objectif du balayage
Définissez l’objectif de votre travail de balayage en spécifiant la métrique principale et l’objectif dont vous souhaitez optimiser le réglage des hyperparamètres. Chaque travail d’entraînement est évalué par rapport à la métrique principale. La stratégie d’arrêt anticipé utilise la métrique principale pour identifier les travaux aux faibles performances.
primary_metric: le nom de la métrique principale doit correspondre exactement au nom de la métrique journalisée par le script d’entraînementgoal: il peut s’agir deMaximizeouMinimizeet détermine si la métrique principale est maximisée ou minimisée lors de l’évaluation des travaux.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
primary_metric="accuracy",
goal="Maximize",
)
Cet exemple maximise la « précision ».
Journaliser des métriques pour l’optimisation des hyperparamètres
Le script d’entraînement pour votre modèle doit journaliser la métrique principale lors de l’entraînement du modèle à l’aide du même nom de métrique correspondant, afin que le travail de balayage puisse y accéder pour l’optimisation des hyperparamètres.
Journalisez la métrique principale dans votre script d’entraînement avec l’extrait de code suivant :
import mlflow
mlflow.log_metric("accuracy", float(val_accuracy))
Le script d’entraînement calcule la valeur de val_accuracy et la journalise comme valeur de précision de la métrique principale. Chaque fois que la métrique est journalisée, elle est reçue par le service d’optimisation des hyperparamètres. C’est à vous de déterminer la fréquence des rapports.
Pour plus d’informations sur les valeurs de journalisation pour les travaux d’entraînement, consultez Activer la journalisation dans les travaux d’entraînement Azure Machine Learning.
Spécifier une stratégie d’arrêt anticipé
Une stratégie d’arrêt anticipé permet d’arrêter automatiquement les travaux peu performants. Un arrêt anticipé améliore l’efficacité du calcul.
Vous pouvez configurer les paramètres suivants pour contrôler à quel moment une stratégie s’applique :
evaluation_interval: fréquence d’application de la stratégie. Chaque journalisation de la métrique principale par le script d’entraînement compte pour un intervalle. Une valeur de 1 pourevaluation_intervalapplique la stratégie chaque fois que le script d’entraînement signale la métrique principale. Une valeur de 2 pourevaluation_intervalapplique la stratégie à chaque fois. La valeur par défaut deevaluation_intervalest 0 si ce paramètre n’est pas spécifié.delay_evaluation: retarde la première évaluation de la stratégie pour un nombre d’intervalles spécifié. Il s’agit d’un paramètre facultatif qui évite un arrêt prématuré des travaux d’entraînement en permettant à toutes les configurations de s’exécuter pour un nombre minimal d’intervalles. S’il est spécifié, la stratégie s’applique à chaque multiple de evaluation_interval qui est supérieur ou égal à delay_evaluation. La valeur par défaut dedelay_evaluationest 0 si ce paramètre n’est pas spécifié.
Azure Machine Learning prend en charge les stratégies d’arrêt anticipé suivantes :
- Stratégie Bandit
- Stratégie d’arrêt médiane
- Stratégie de sélection de troncation
- Stratégie sans arrêt
Stratégie Bandit
La stratégie Bandit est une stratégie d’arrêt basée sur le facteur de marge/marge totale et l’intervalle d’évaluation. La stratégie Bandit termine un travail quand la métrique principale n’est pas comprise dans le facteur de marge/marge totale du travail le plus performant.
Spécifiez les paramètres de configuration suivants :
slack_factorouslack_amount: marge autorisée par rapport à le travail d’entraînement le plus performant.slack_factorspécifie la marge autorisée sous forme de ratio.slack_amountspécifie la marge autorisée en valeur absolue, au lieu d’un ratio.Par exemple, considérez une stratégie Bandit appliquée avec un intervalle de 10. Supposez que le travail le plus performant à l’intervalle 10 a signalé une métrique principale de 0,8 avec l’objectif de maximiser la métrique principale. Si la stratégie spécifie avec un
slack_factorde 0,2, les travaux d’entraînement, dont la meilleure mesure à l’intervalle 10 est inférieure à 0,66 (0,8/(1+slack_factor)) seront arrêtés.evaluation_interval: (facultatif) fréquence d’application de la stratégiedelay_evaluation: (facultatif) retarde la première évaluation de la stratégie pour un nombre d’intervalles spécifié
from azure.ai.ml.sweep import BanditPolicy
sweep_job.early_termination = BanditPolicy(slack_factor = 0.1, delay_evaluation = 5, evaluation_interval = 1)
Dans cet exemple, la stratégie d’arrêt anticipé est appliquée à chaque intervalle quand des métriques sont signalées, en commençant à l’intervalle d’évaluation 5. Tout travail dont la meilleure métrique est inférieure à (1/(1+0,1) ou 91 % du meilleur travail sera arrêté.
Stratégie d’arrêt médiane
La stratégie d’arrêt médiane est une stratégie d’arrêt anticipé basée sur les moyennes mobiles des métriques principales rapportées par les travaux. Cette stratégie calcule les moyennes mobiles pour tous les travaux d’apprentissage et arrête les travaux dont les valeurs de la métrique principale sont moins bonnes que la valeur médiane des moyennes.
Cette stratégie prend les paramètres de configuration suivants :
evaluation_interval: fréquence d’application de la stratégie (paramètre facultatif).delay_evaluation: retarde la première évaluation de la stratégie pour un nombre d’intervalles spécifié (paramètre facultatif).
from azure.ai.ml.sweep import MedianStoppingPolicy
sweep_job.early_termination = MedianStoppingPolicy(delay_evaluation = 5, evaluation_interval = 1)
Dans cet exemple, la stratégie d’arrêt anticipé est appliquée à chaque intervalle, en commençant à l’intervalle d’évaluation 5. Un travail est interrompu à l’intervalle 5 si sa meilleure métrique principale est moins bonne que la valeur médiane des moyennes mobiles sur les intervalles 1 à 5 pour tous les travaux d’apprentissage.
Stratégie de sélection de troncation
La stratégie de sélection de troncation annule un pourcentage des travaux les moins performants à chaque intervalle d’évaluation. Les travaux sont comparés à l’aide de la métrique principale.
Cette stratégie prend les paramètres de configuration suivants :
truncation_percentage: le pourcentage des travaux avec les performances les moins bonnes à arrêter à chaque intervalle d’évaluation. Nombre entier compris entre 1 et 99.evaluation_interval: (facultatif) fréquence d’application de la stratégiedelay_evaluation: (facultatif) retarde la première évaluation de la stratégie pour un nombre d’intervalles spécifiéexclude_finished_jobs: spécifie s’il faut exclure les travaux terminés lors de l’application de la stratégie
from azure.ai.ml.sweep import TruncationSelectionPolicy
sweep_job.early_termination = TruncationSelectionPolicy(evaluation_interval=1, truncation_percentage=20, delay_evaluation=5, exclude_finished_jobs=true)
Dans cet exemple, la stratégie d’arrêt anticipé est appliquée à chaque intervalle, en commençant à l’intervalle d’évaluation 5. Un travail se termine à l’intervalle 5 si ses performances à l’intervalle 5 se situent dans les 20 % les plus bas des performances de tous les travaux à l’intervalle 5 et exclura les travaux terminés lors de l’application de la stratégie.
Aucune stratégie de fin (par défaut)
Si aucune stratégie n’est spécifiée, le service d’optimisation des hyperparamètres permet à tous les travaux d’entraînement d’arriver à leur terme.
sweep_job.early_termination = None
Sélection d’une stratégie d’arrêt anticipé
- Si vous cherchez une stratégie classique qui permet de réaliser des économies, sans arrêter les tâches prometteuses, vous pouvez utiliser une stratégie d’arrêt à la médiane avec un
evaluation_intervalde 1 et undelay_evaluationde 5. Il s’agit de valeurs prudentes, qui peuvent fournir approximativement 25 à 35 % d’économies sans perte sur la métrique principale (d’après nos évaluations). - Pour des économies plus importantes, utilisez une stratégie Bandit avec une plus petite marge autorisée ou une stratégie de sélection de troncation avec un pourcentage de troncation plus élevé.
Définir des limites pour votre travail de balayage
Contrôlez votre budget de ressources en définissant des limites pour votre travail de balayage.
max_total_trials: nombre maximal de travaux d’évaluation. Doit être un entier compris entre 1 et 1000.max_concurrent_trials: (facultatif) nombre maximal de travaux d’évaluation qui peuvent s’exécuter simultanément. S’il n’est pas spécifié, max_total_trials nombre de travaux sont lancés en parallèle. En cas de spécification, doit être un entier compris entre 1 et 1000.timeout: Durée maximale, en secondes, pendant laquelle l’exécution du travail de balayage est autorisée. Une fois cette limite atteinte, le système annule le travail de balayage, y compris toutes ses évaluations.trial_timeout: durée maximale, en minutes, pendant laquelle l’exécution de chaque travail d’évaluation est autorisée. Une fois cette limite atteinte, le système annule l’évaluation.
Notes
Si max_total_trials et le délai d’expiration sont tous deux spécifiés, l’expérience d’optimisation des hyperparamètres s’arrête dès que le premier de ces deux seuils est atteint.
Notes
Le nombre de travaux d’évaluation simultanés est limité par les ressources disponibles dans la cible de calcul spécifiée. Vérifiez que la cible de calcul dispose des ressources nécessaires à l’accès concurrentiel souhaité.
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=4, timeout=1200)
Ce code configure l’expérience d’optimisation des hyperparamètres pour qu’elle utilise un maximum de 20 travaux d’évaluation au total, exécutant quatre travaux d’évaluation à la fois avec un délai d’expiration de 1200 secondes pour l’ensemble du travail de balayage.
Configurer l’expérience d’optimisation des hyperparamètres
Pour configurer votre optimisation des hyperparamètres, fournissez les informations suivantes :
- Espace de recherche des hyperparamètres défini
- Votre algorithme d’échantillonnage
- Votre stratégie d’arrêt anticipé
- Votre objectif
- Limites des ressources
- CommandJob ou CommandComponent
- SweepJob
SweepJob peut exécuter un balayage d’hyperparamètres sur Command ou Command Component.
Notes
La cible de calcul utilisée dans sweep_job doit avoir suffisamment de ressources pour répondre à votre niveau d’accès concurrentiel. Pour plus d’informations sur les cibles de calcul, consultez Cibles de calcul.
Configurez votre expérience d’optimisation des hyperparamètres :
from azure.ai.ml import MLClient
from azure.ai.ml import command, Input
from azure.ai.ml.sweep import Choice, Uniform, MedianStoppingPolicy
from azure.identity import DefaultAzureCredential
# Create your base command job
command_job = command(
code="./src",
command="python main.py --iris-csv ${{inputs.iris_csv}} --learning-rate ${{inputs.learning_rate}} --boosting ${{inputs.boosting}}",
environment="AzureML-lightgbm-3.2-ubuntu18.04-py37-cpu@latest",
inputs={
"iris_csv": Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/iris.csv",
),
"learning_rate": 0.9,
"boosting": "gbdt",
},
compute="cpu-cluster",
)
# Override your inputs with parameter expressions
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.01, max_value=0.9),
boosting=Choice(values=["gbdt", "dart"]),
)
# Call sweep() on your command job to sweep over your parameter expressions
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm="random",
primary_metric="test-multi_logloss",
goal="Minimize",
)
# Specify your experiment details
sweep_job.display_name = "lightgbm-iris-sweep-example"
sweep_job.experiment_name = "lightgbm-iris-sweep-example"
sweep_job.description = "Run a hyperparameter sweep job for LightGBM on Iris dataset."
# Define the limits for this sweep
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=10, timeout=7200)
# Set early stopping on this one
sweep_job.early_termination = MedianStoppingPolicy(
delay_evaluation=5, evaluation_interval=2
)
La fonction command_job est appelée afin que nous puissions appliquer les expressions de paramètre aux entrées de balayage. La fonction sweep est ensuite configurée avec trial, sampling-algorithm, objective, limits et compute. L’extrait de code ci-dessus est extrait de l’exemple de notebook Exécuter le balayage d’hyperparamètre sur Command ou commandComponent. Dans cet exemple, les paramètres learning_rate et boosting sont réglés. L’arrêt précoce des travaux sera déterminé par un MedianStoppingPolicy, qui arrête un travail dont la valeur de métrique principale est pire que la médiane des moyennes pour tous les travaux d’entraînement (consultez la référence de classe MedianStoppingPolicy).
Pour voir comment les valeurs de paramètre sont reçues, analysées et passées au script d’entraînement à optimiser, reportez-vous à cet exemple de code.
Important
Chaque travail de balayage d’hyperparamètres redémarre l’apprentissage à partir de zéro, y compris la regénération du modèle et de tous les chargeurs de données. Vous pouvez réduire ce coût à l’aide d’un pipeline Azure Machine Learning ou d’un processus manuel pour effectuer au mieux la préparation des données avant les travaux d’apprentissage.
Soumettre une expérience d’optimisation des hyperparamètres
Une fois que vous avez défini votre configuration d’optimisation des hyperparamètres, soumettez le travail :
# submit the sweep
returned_sweep_job = ml_client.create_or_update(sweep_job)
# get a URL for the status of the job
returned_sweep_job.services["Studio"].endpoint
Visualiser les travaux d’optimisation des hyperparamètres
Vous pouvez visualiser tous vos travaux d’optimisation des hyperparamètres dans Azure Machine Learning studio. Pour plus d’informations sur la visualisation d’une expérience sur le portail, reportez-vous à Consulter les enregistrements de travail dans le studio.
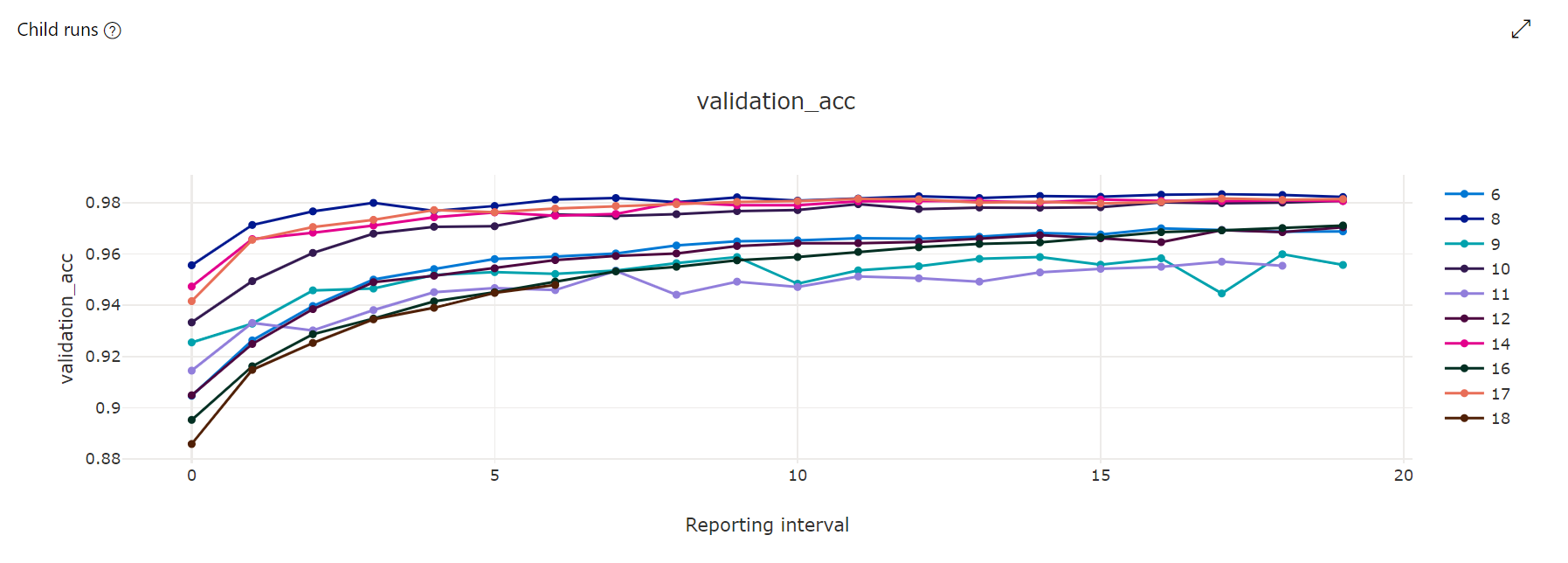
Graphique des métriques : cette visualisation assure le suivi des métriques journalisées pour chaque travail enfant Hyperdrive pendant la durée de l’optimisation des hyperparamètres. Chaque ligne représente un travail enfant, tandis que chaque point mesure la valeur de métrique principale à cette itération d’exécution.
Graphique des coordonnées parallèles : cette visualisation montre la corrélation entre les performances de la métrique principale et les valeurs individuelles des hyperparamètres. Le graphique est interactif via le déplacement des axes (cliquez sur l’étiquette d’un axe et faites-la glisser) et la mise en surbrillance des valeurs d’un axe spécifique (cliquez sur un axe et opérez un glissement vertical le long de ce dernier pour mettre en surbrillance une plage de valeurs souhaitées). Le graphe des coordonnées parallèles comprend sur la partie la plus à droite un axe qui représente la meilleure valeur métrique correspondant aux hyperparamètres définis pour cette instance de travail. Cet axe permet de projeter de façon plus lisible la légende de gradient du graphe sur les données.

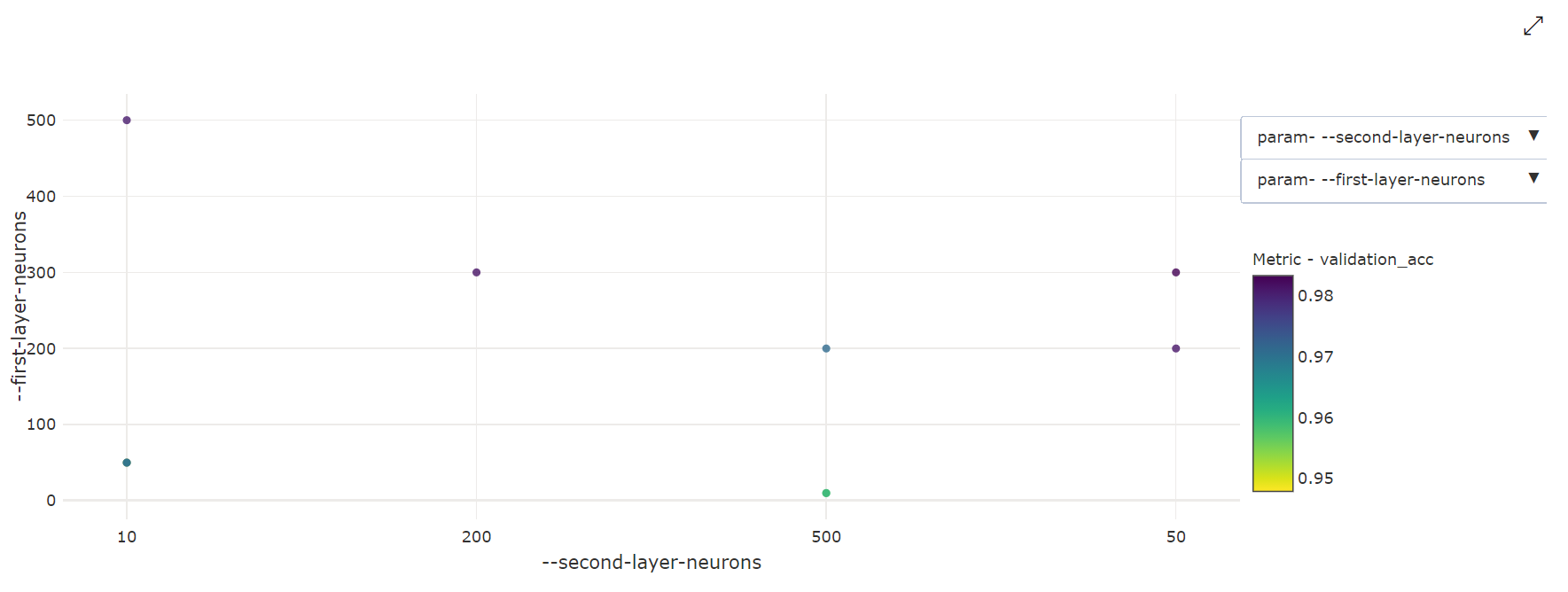
Graphique à nuages de points bidimensionnel : cette visualisation montre la corrélation entre deux hyperparamètres individuels et la valeur de leur métrique principale associée.
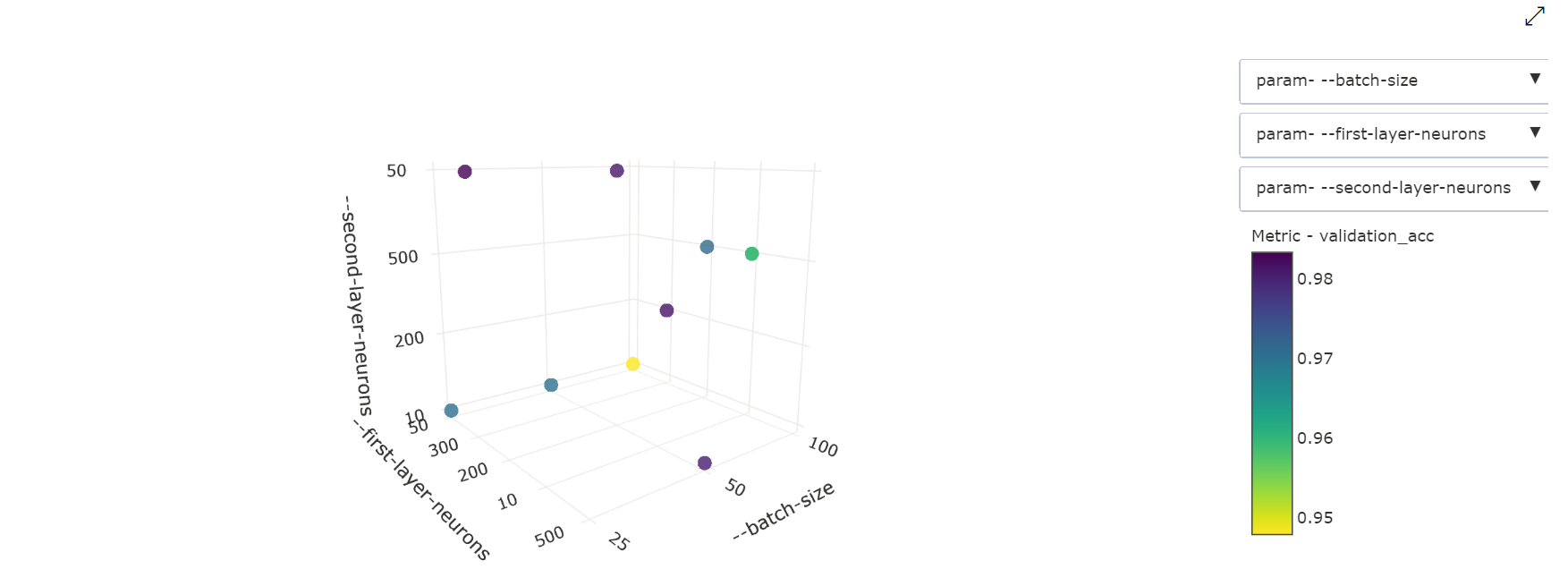
Graphique à nuages de points tridimensionnel : cette visualisation est identique à celle à 2 dimensions, mais elle permet trois dimensions de corrélation des hyperparamètres avec la valeur de la métrique principale. Vous pouvez également cliquer et faire glisser pour réorienter le graphique afin de voir différentes corrélations dans l’espace 3D.
Trouver le meilleur travail d’évaluation
Une fois que tous les travaux d’optimisation des hyperparamètres sont terminés, récupérez vos meilleures sorties d’évaluation :
# Download best trial model output
ml_client.jobs.download(returned_sweep_job.name, output_name="model")
Vous pouvez utiliser l’interface CLI pour télécharger toutes les sorties par défaut et nommées du meilleur travail d’évaluation et des journaux du travail de balayage.
az ml job download --name <sweep-job> --all
Si vous le souhaitez, pour télécharger uniquement la meilleure sortie d’évaluation
az ml job download --name <sweep-job> --output-name model