Reconstruire une expérience Studio (classique) dans Azure Machine Learning
Important
La prise en charge d’Azure Machine Learning Studio (classique) prendra fin le 31 août 2024. Nous vous recommandons de passer à Azure Machine Learning avant cette date.
Depuis le 1er décembre 2021, vous ne pouvez plus créer de nouvelles ressources Machine Learning Studio (classique) (espace de travail et plan de service Web). Jusqu’au 31 août 2024, vous pouvez continuer à utiliser les expériences et les services Web Machine Learning Studio (classiques) existants. Pour plus d’informations, consultez l’article suivant :
- Migrer vers Azure Machine Learning depuis Machine Learning Studio (classique)
- Qu'est-ce que Microsoft Azure Machine Learning ?
La documentation de Machine Learning Studio (classique) est en cours de retrait et pourrait ne pas être mise à jour à l’avenir.
Dans cet article, vous allez apprendre à reconstruire une expérience ML Studio (classique) dans Azure Machine Learning. Pour plus d’informations sur la migration à partir de Studio (classique), consultez l’article de présentation sur la migration.
Les expériences Studio (classique) sont similaires aux pipelines dans Azure Machine Learning. Toutefois, dans Azure Machine Learning, les pipelines sont générés sur le même serveur principal qui alimente le Kit de développement logiciel (SDK). Cela signifie que deux options s’offrent à vous pour le développement Machine Learning : le concepteur de type « glisser-déplacer » ou les SDK de type « Code First ».
Pour plus d’informations sur la création de pipelines avec le SDK, consultez Présentation des pipelines Azure Machine Learning.
Prérequis
- Compte Azure avec un abonnement actif. Créez un compte gratuitement.
- Un espace de travail Azure Machine Learning. Créez des ressources d’espace de travail.
- Une expérience Studio (classique) à migrer.
- Chargez votre jeu de données sur Azure Machine Learning.
Reconstruire le pipeline
Après avoir migré votre jeu de données vers Azure Machine Learning, vous êtes prêt à recréer votre expérience.
Dans Azure Machine Learning, le graphique visuel est appelé un brouillon de pipeline. Dans cette section, vous recréez votre expérience classique sous forme de brouillon de pipeline.
Accédez à Azure Machine Learning studio (ml.azure.com).
Dans le volet de navigation de gauche, sélectionnez Concepteur>Modules prédéfinis faciles à utiliser
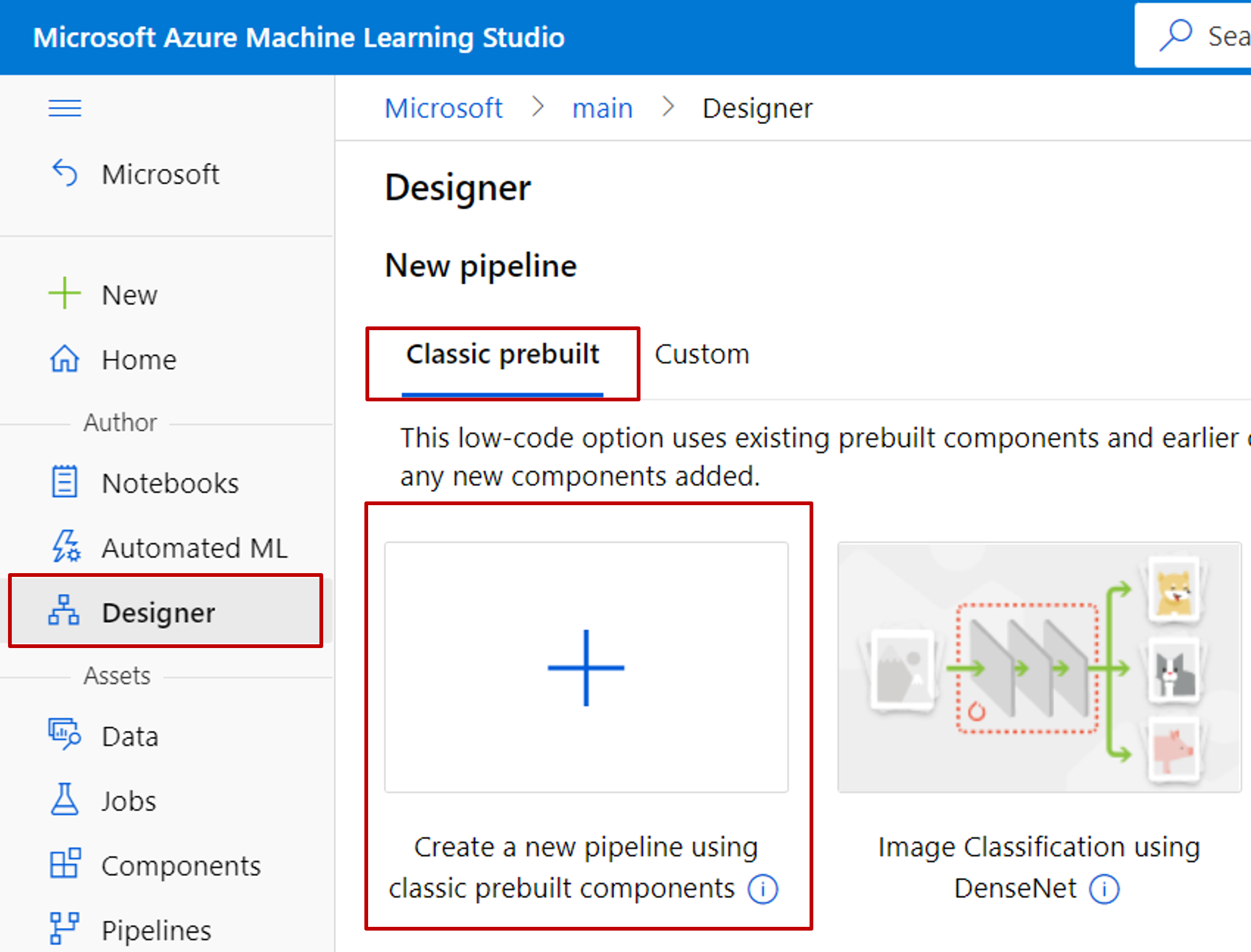
Regénérez manuellement votre expérience avec des composants du concepteur.
Consultez le tableau de correspondance des modules pour rechercher les modules de remplacement. Plusieurs des modules les plus populaires de Studio (classique) ont des versions identiques dans le concepteur.
Important
Si votre expérience utilise le module Exécuter un script R, vous devez effectuer des étapes supplémentaires pour migrer votre expérience. Pour plus d’informations, consultez Migrer des modules de script R.
Ajustez les paramètres.
Sélectionnez chaque module et ajustez les paramètres dans le panneau des paramètres du module à droite. Utilisez les paramètres pour recréer les fonctionnalités de votre expérience Studio (classique). Pour plus d’informations sur chaque module, consultez la référence relative aux modules.
Envoyer un travail et vérifier les résultats
Après avoir recréé votre expérience Studio (classique), il est temps de soumettre un travail de pipeline.
Un travail de pipeline s’exécute sur une cible de calcul rattachée à votre espace de travail. Vous pouvez définir une cible de calcul par défaut pour l’ensemble du pipeline, ou vous pouvez spécifier des cibles de calcul pour chaque module.
Lorsque vous envoyez un travail à partir d’un brouillon de pipeline, il se transforme en travail de pipeline. Chaque travail de pipeline est enregistré et consigné dans Azure Machine Learning.
Pour définir une cible de calcul par défaut pour l’ensemble du pipeline :
- Sélectionnez l’icône en forme d’engrenage
 à côté du nom du pipeline.
à côté du nom du pipeline. - Cliquez sur Sélectionner une cible de calcul.
- Sélectionnez un calcul existant ou créez un nouveau calcul en suivant les instructions à l’écran.
Maintenant que votre cible de calcul est définie, vous pouvez envoyer un travail de pipeline :
En haut du canevas, sélectionnez Envoyer.
Sélectionnez Créer nouveau pour créer une nouvelle expérience.
Les expériences organisent les travaux de pipeline similaires ensemble. Si vous exécutez un pipeline plusieurs fois, vous pouvez sélectionner la même expérience pour les travaux successifs. Cela est utile pour la journalisation et le suivi.
Entrez un nom d’expérience. Puis, sélectionnez Envoyer.
Le premier travail peut prendre jusqu’à 20 minutes. Comme les paramètres de calcul par défaut ont une taille de nœud minimale de 0, le concepteur doit allouer des ressources après une période d’inactivité. Les travaux ultérieurs prendront moins de temps, puisque les nœuds sont déjà alloués. Pour accélérer le temps d’exécution, vous pouvez créer une ressource de calcul avec une taille de nœud minimale de 1 ou plus.
Une fois le travail terminé, vous pouvez vérifier les résultats de chaque module :
Cliquez avec le bouton droit sur le module dont vous voulez voir la sortie.
Sélectionnez Visualiser, Afficher la sortie ou Afficher le journal.
- Visualiser : Affiche un aperçu du jeu de données de résultats.
- Afficher la sortie : Ouvre un lien vers l’emplacement de stockage de la sortie. À utiliser pour explorer ou télécharger la sortie.
- Afficher le journal : Affiche les journaux du pilote et du système. Utilisez le 70_driver_log pour voir les informations relatives à votre script envoyé par l’utilisateur, telles que les erreurs et les exceptions.
Important
Les composants du concepteur utilisent des packages Python open source pour implémenter des algorithmes d’apprentissage automatique. Toutefois, Studio (classique) utilise une bibliothèque C# interne à Microsoft. Par conséquent, les résultats des prédictions peuvent varier entre le concepteur et Studio (classique).
Enregistrer un modèle formé pour l’utiliser dans un autre pipeline
Il peut arriver que vous souhaitiez enregistrer le modèle formé dans un pipeline et l’utiliser ultérieurement dans un autre pipeline. Dans Studio (classique), tous les modèles formés sont enregistrés dans la catégorie « Modèles formés » de la liste des modules. Dans le concepteur, les modèles formés sont automatiquement inscrits en tant que jeu de données de fichier avec un nom généré par le système. La convention d’affectation de noms suit le modèle « MD - nom du projet de pipeline - nom du composant - ID du modèle formé ».
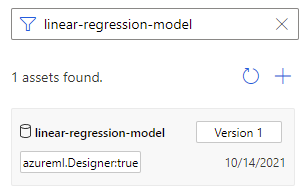
Pour attribuer un nom explicite à un modèle formé, vous pouvez enregistrer la sortie du composant Former le modèle en tant que jeu de données de fichier. Donnez-lui le nom de votre choix, par exemple modèle-régression-linéaire.
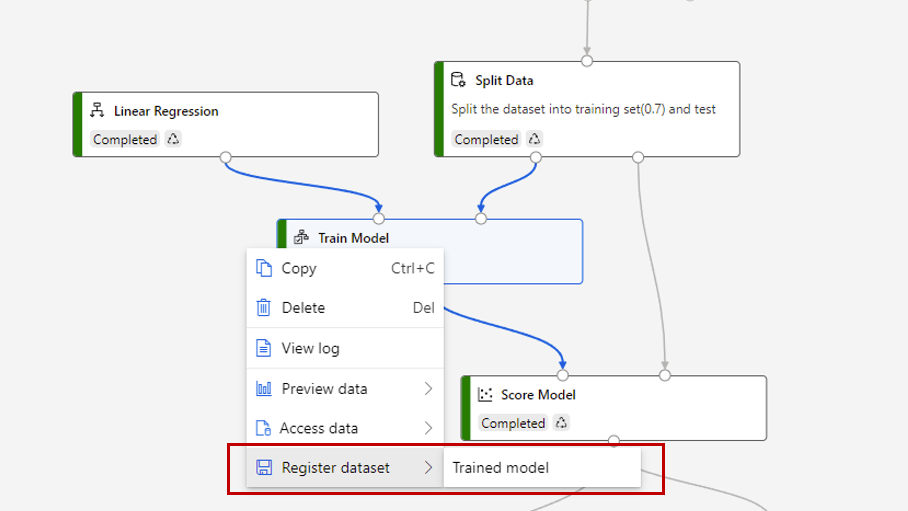
Vous pouvez trouver le modèle formé dans la catégorie « Jeu de données » dans la liste des composants ou le rechercher par son nom. Connectez ensuite le modèle formé à un composant Effectuer le scoring d’un modèle pour l’utiliser pour la prédiction.
Étapes suivantes
Dans cet article, vous avez appris à reconstruire une expérience Studio (classique) dans Azure Machine Learning. L’étape suivante consiste à reconstruire les services web dans Azure Machine Learning.
Consultez les autres articles de la série sur la migration Studio (classique) :
- Vue d’ensemble de la migration.
- Migrer un jeu de données.
- Reconstruire un pipeline de formation Studio (classique).
- Reconstruire un service web Studio (classique).
- Intégrer un service web Azure Machine Learning à des applications clientes.
- Migrer Exécuter un script R.