Démarrage rapide : Déployer un cluster Apache Spark managé avec Azure Databricks
Azure Managed Instance pour Apache Cassandra offre des opérations de déploiement et de mise à l’échelle automatisées pour les centres de données Apache Cassandra open source managés. Cette fonctionnalité accélère les scénarios hybrides et réduit la maintenance continue.
Ce guide de démarrage rapide explique comment utiliser le portail Azure pour créer un cluster Apache Spark complètement managé dans le réseau virtuel Azure de votre cluster Azure Managed Instance pour Apache Cassandra. Vous créez le cluster Spark dans Azure Databricks. Plus tard, vous pourrez créer ou attacher des notebooks au cluster, lire des données de différentes sources, et analyser des insights.
Pour en savoir plus et obtenir des instructions détaillées, consultez Déployer Azure Databricks dans votre réseau virtuel Azure (injection dans le réseau virtuel).
Prérequis
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Créer un cluster Azure Databricks
Effectuez les étapes suivantes pour créer un cluster Azure Databricks dans un réseau virtuel avec Azure Managed Instance pour Apache Cassandra :
Connectez-vous au portail Azure.
Dans le volet de navigation de gauche, localisez Groupes de ressources. Accédez au groupe de ressources contenant le réseau virtuel sur lequel votre instance gérée est déployée.
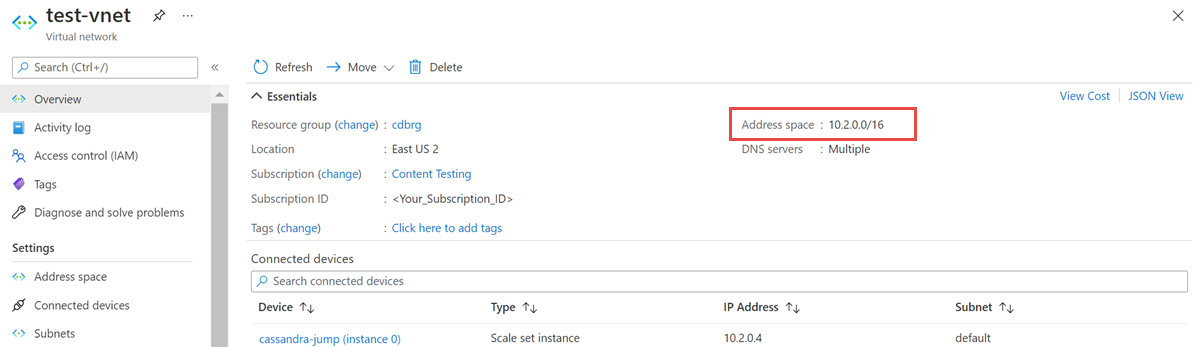
Ouvrez la ressource Réseau virtuel et prenez note de la valeur dans Espace d’adressage :
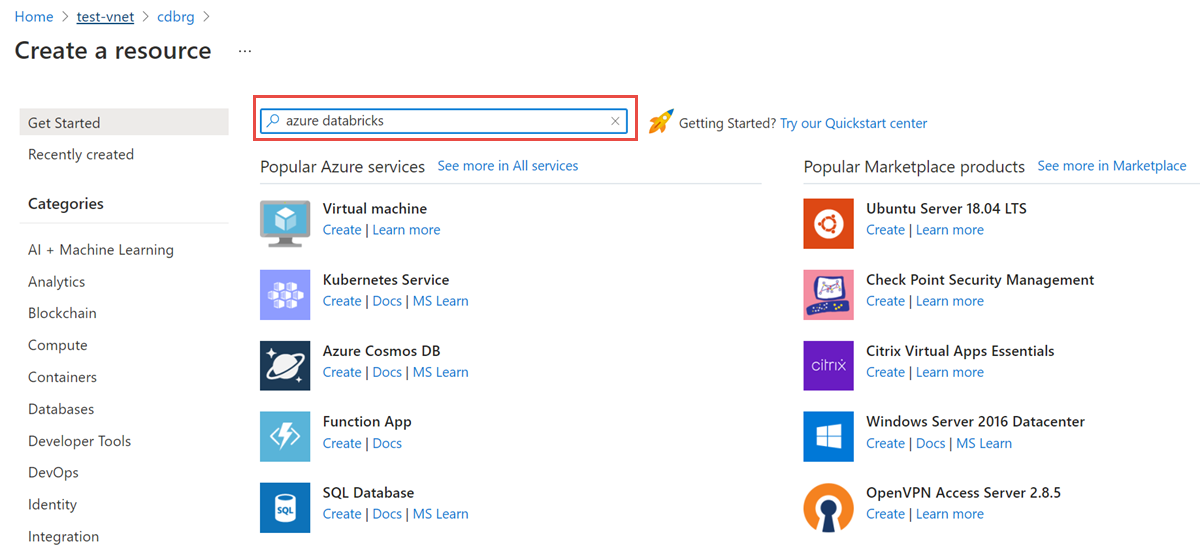
Dans le groupe de ressources, sélectionnez Ajouter et faites une recherche sur Azure Databricks dans le champ de recherche :
Sélectionnez Créer pour créer un compte Azure Databricks :
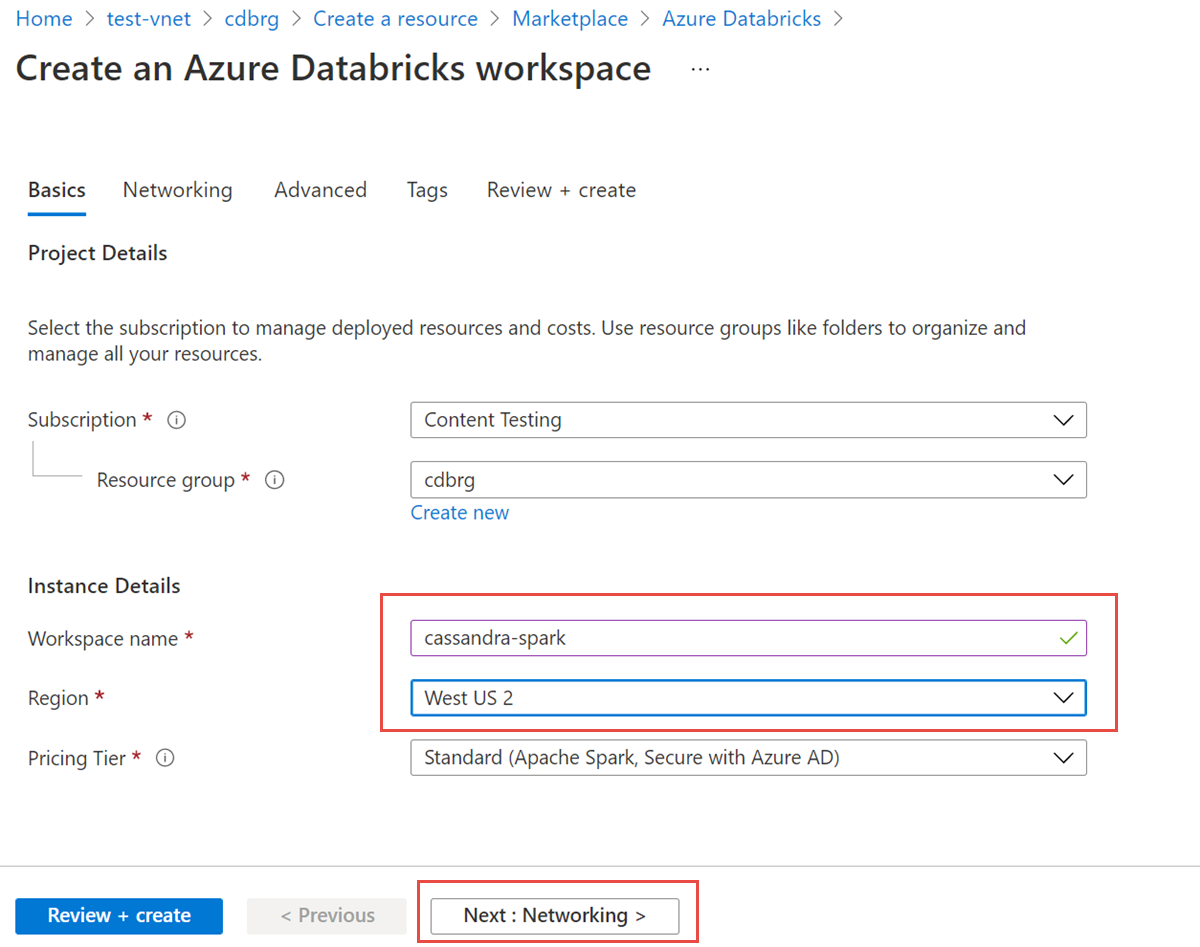
Saisissez les valeurs suivantes :
- Nom de l’espace de travail : entrez un nom pour votre espace de travail Databricks.
- Région : veillez à sélectionner la même région que celle de votre réseau virtuel.
- Niveau tarifaire : choisissez le niveau Standard, Premium ou Essai. Pour plus d’informations sur ces niveaux, consultez la page de tarification Databricks.
Ensuite, sélectionnez l’onglet Mise en réseau et entrez les informations suivantes :
- Déployer l’espace de travail Azure Databricks dans votre réseau virtuel (VNet) : sélectionnez Oui.
- Réseau virtuel : dans la liste déroulante, choisissez le réseau virtuel sur lequel se trouve votre instance managée.
- Nom du sous-réseau public : entrez un nom pour le sous-réseau public.
- Plage CIDR du sous-réseau public : entrez une plage d’adresses IP pour le sous-réseau public.
- Nom du sous-réseau privé : entrez un nom pour le sous-réseau privé.
- Plage CIDR du sous-réseau privé : entrez une plage d’adresses IP pour le sous-réseau privé.
Pour éviter les collisions d’étendues, sélectionnez des plages plus grandes. Si nécessaire, utilisez un calculateur de sous-réseau visuel pour diviser les plages :
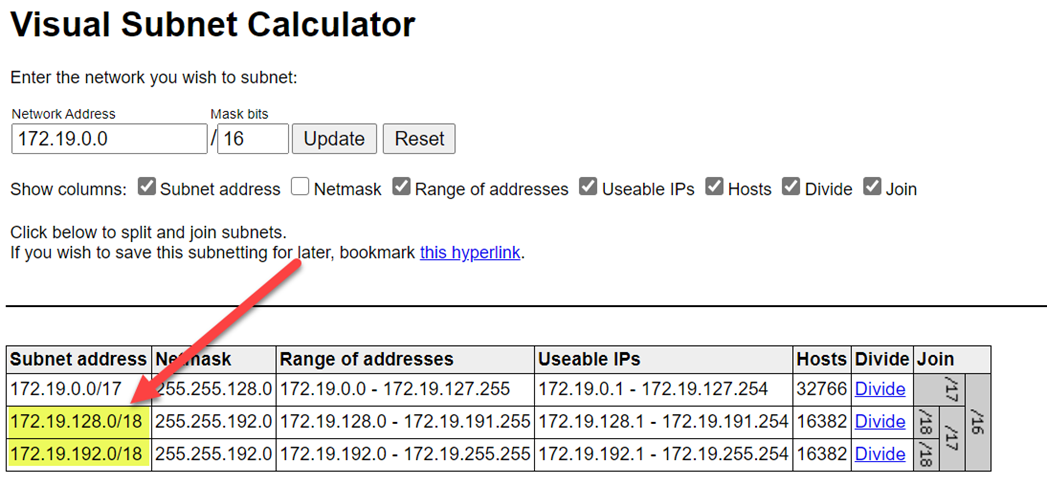
La capture d’écran suivante montre des exemples de détails dans le volet Réseau :
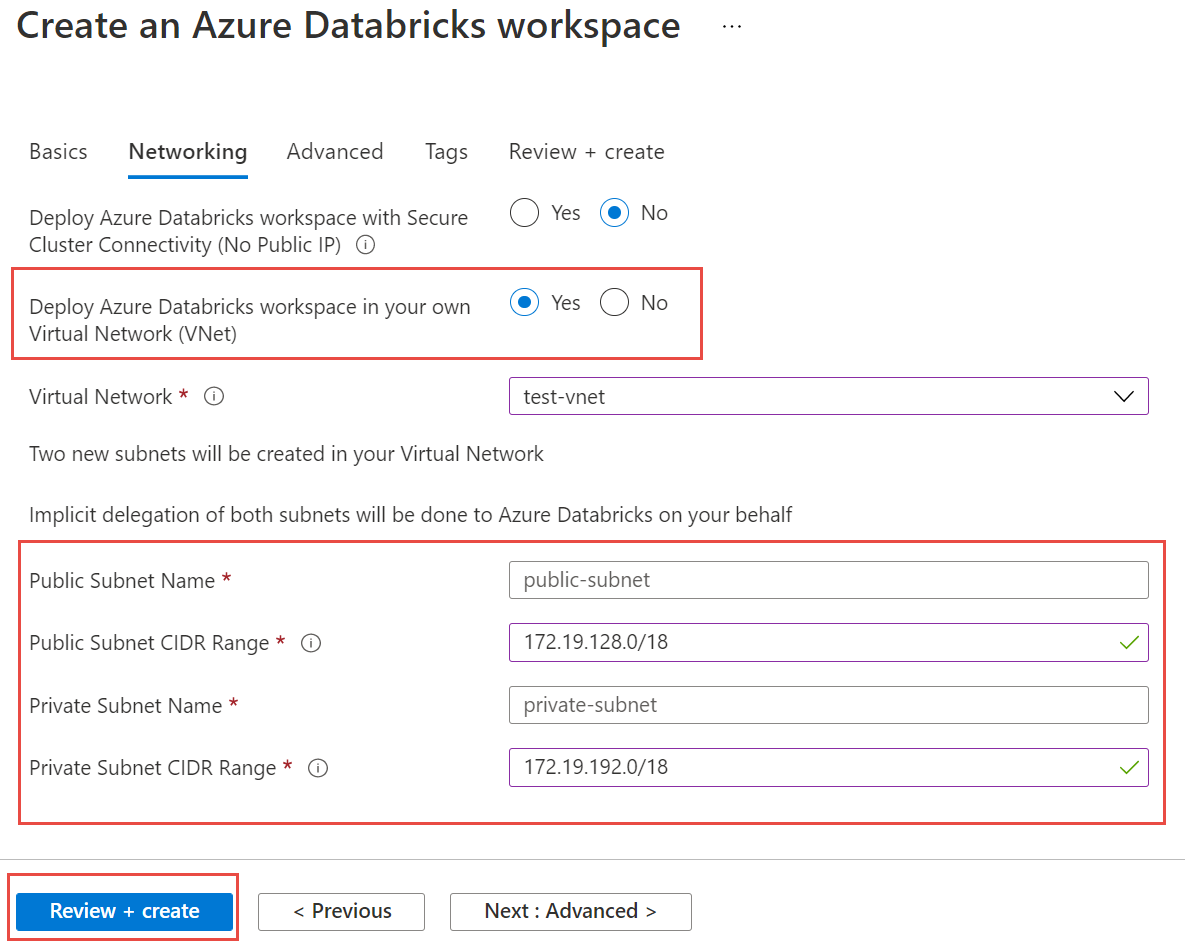
Sélectionnez Vérifier et créer, puis sélectionnez Créer pour déployer l’espace de travail.
Lancer l’espace de travail après sa création.
Vous êtes redirigé vers le portail Azure Databricks. Dans le portail, sélectionnez Nouveau cluster.
Dans le volet Nouveau cluster, acceptez les valeurs par défaut pour tous les champs autres que les champs suivants :
- Nom du cluster : entrez un nom pour le cluster.
- Version du runtime Databricks : nous recommandons de sélectionner la version du runtime Databricks 7.5 ou supérieure pour la prise en charge de Spark 3.x.
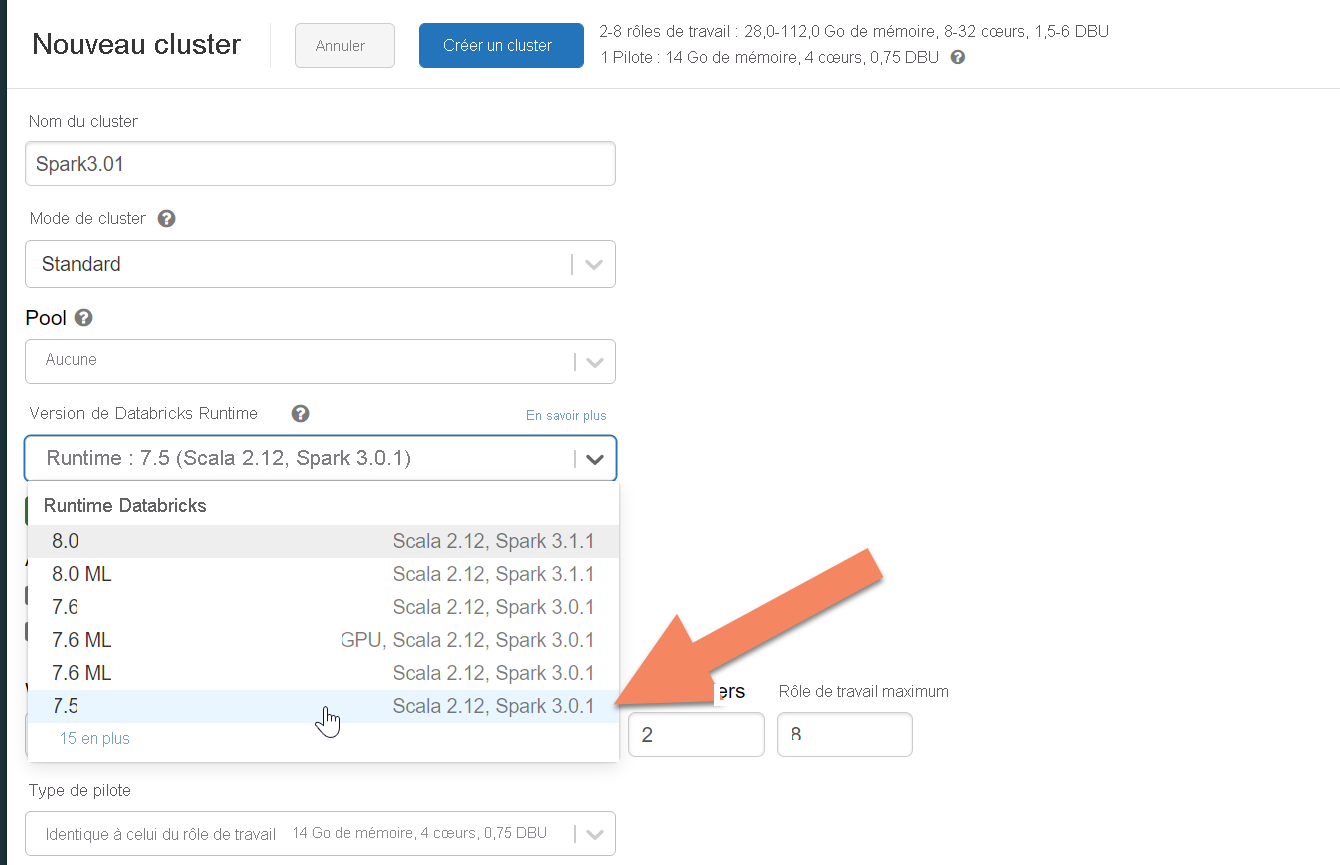
Développez Options avancées et ajoutez la configuration suivante. N’oubliez pas d’indiquer les adresses IP des nœuds et les informations d’identification :
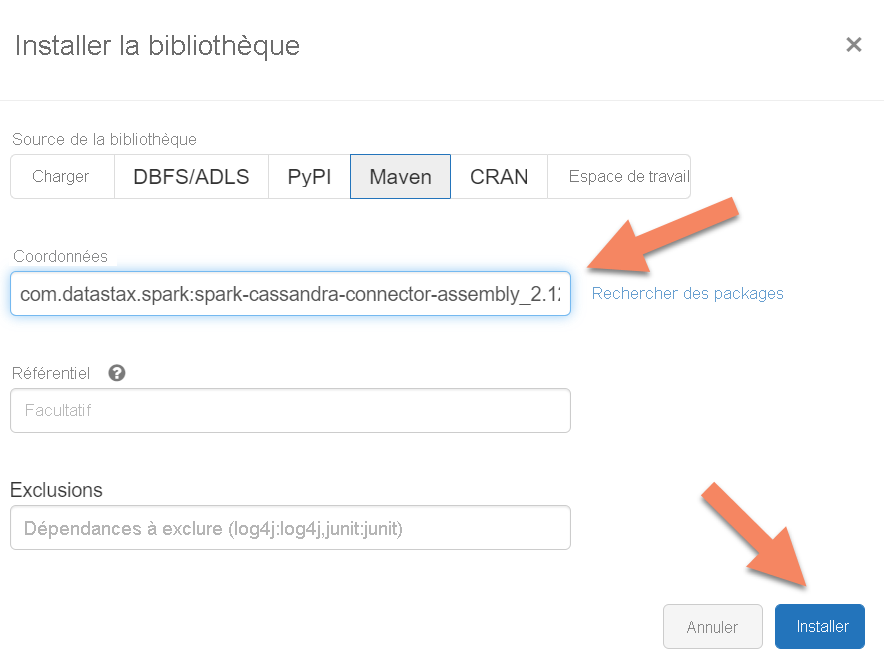
spark.cassandra.connection.host <node1 IP>,<node 2 IP>, <node IP> spark.cassandra.auth.password cassandra spark.cassandra.connection.port 9042 spark.cassandra.auth.username cassandra spark.cassandra.connection.ssl.enabled trueAjoutez la bibliothèque du connecteur Apache Spark Cassandra à votre cluster pour vous connecter aux points de terminaison Cassandra natifs et Azure Cosmos DB. Dans votre cluster, sélectionnez Bibliothèques>Installer nouveau>Maven, puis ajoutez
com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0dans les coordonnées Maven.
Nettoyer les ressources
Si vous ne comptez pas continuer à utiliser ce cluster Managed Instance, supprimez-le en effectuant les étapes suivantes :
- Dans le menu de gauche du portail Azure, sélectionnez Groupes de ressources.
- Dans la liste, sélectionnez le groupe de ressources créé pour ce guide de démarrage rapide.
- Dans le volet Vue d’ensemble du groupe de ressources, sélectionnez Supprimer un groupe de ressources.
- Dans la fenêtre suivante, entrez le nom du groupe de ressources à supprimer, puis sélectionnez Supprimer.
Étapes suivantes
Dans ce guide de démarrage rapide, vous avez vu comment créer un cluster Apache Spark complètement managé dans le réseau virtuel de votre cluster Azure Managed Instance pour Apache Cassandra. Vous pouvez ensuite apprendre à gérer les ressources du cluster et du centre de ressources :