Fiabilité dans Azure AI Search
Dans Azure, la fiabilité signifie la résilience et disponibilité en cas de panne ou de dégradation du service. Dans Recherche IA Azure, la fiabilité peut être obtenue au sein d’un seul service ou via plusieurs services de recherche dans des régions distinctes.
Déployez un service de recherche unique et effectuez un scale-up pour la haute disponibilité. Vous pouvez ajouter plusieurs réplicas pour gérer des charges de travail d’indexation et de requête plus élevées. Si votre service de recherche prend en charge les zones de disponibilité, les réplicas sont automatiquement approvisionnés dans différents centres de données physiques pour une résilience supplémentaire.
Déployez plusieurs services de recherche dans différentes régions géographiques. Toutes les charges de travail de recherche sont entièrement contenues dans un seul service qui s’exécute dans une seule région géographique, mais dans un scénario multiservices, vous avez des options pour synchroniser le contenu afin qu’il soit identique entre tous les services. Vous pouvez également configurer une solution d’équilibrage de charge pour redistribuer des requêtes ou basculer en cas de panne de service.
Pour la continuité d’activité et la récupération des sinistres au niveau régional, planifiez une topologie interrégionnelle, composée de plusieurs services de recherche ayant une configuration et un contenu identiques. Votre script personnalisé ou votre code fournit le mécanisme de basculement à un autre service de recherche si celui-ci devient soudainement indisponible.
Haute disponibilité
Dans Azure AI Search, les réplicas sont des copies de votre index. Un service de recherche est commandé avec au moins un réplica et peut avoir jusqu’à 12 réplicas. Ajouter des réplicas permet à Azure AI Search de gérer les redémarrages et la maintenance des machines pour un réplica spécifique, alors que les requêtes continuent de s’exécuter sur d’autres réplicas.
Pour chaque service de recherche, Microsoft garantit une disponibilité d’au moins 99,9 % pour les configurations qui répondent à ces critères :
Deux réplicas pour la haute disponibilité des charges de travail en lecture seule (requêtes)
Trois réplicas (ou plus) pour la haute disponibilité des charges de travail en lecture-écriture (requêtes et indexation)
Le système dispose de mécanismes internes pour surveiller l’intégrité du réplica et l’intégrité des partitions. Si vous approvisionnez une combinaison spécifique de réplicas et de partitions, le système garantit ce niveau de capacité pour votre service.
Aucun Contrat de niveau de service n’est fourni pour le niveau Gratuit. Pour plus d’informations, consultez SLA pour Azure AI Search.
Prise en charge des zones de disponibilité
Zones de disponibilité est une capacité de la plateforme Azure qui divise les centres de données d’une région en groupes situés dans des emplacements physiques distincts afin de fournir une haute disponibilité au sein d’une même région. Dans Azure AI Search, les réplicas correspondent aux unités de l’attribution de zone. Un service de recherche s’exécute dans une région ; ses réplicas s’exécutent dans différents centres de données physiques (ou zones) dans cette région.
Les zones de disponibilité sont utilisées lorsque vous ajoutez deux réplicas ou plus à votre service de recherche. Chaque réplica est placé dans une zone de disponibilité distincte au sein de la région. Si vous avez plus de réplicas qu’il n’y a de zones de disponibilité dans la région du service de recherche, les réplicas sont répartis entre les zones de disponibilité aussi uniformément que possible. Vous n’avez aucune action spécifique à effectuer, si ce n’est de créer un service de recherche dans une région qui fournit zones de disponibilité, puis de configurer le service pour qu’il utilise plusieurs réplicas.
Prérequis
- Le niveau de service doit être Standard ou supérieur.
- La région de service doit se trouver dans une région qui contient des zones disponibles (répertoriées dans la section suivante).
- La configuration doit inclure plusieurs réplicas : deux pour les charges de travail de requête en lecture seule, trois pour les charges de travail en lecture-écriture qui incluent l’indexation.
Régions prises en charge
La prise en charge des zones de disponibilité dépend de l’infrastructure et du stockage. Actuellement, deux zones annoncées en octobre 2023 ont un stockage insuffisant et ne fournissent pas de zone de disponibilité pour Recherche IA Azure :
- Israël Central
- Italie Nord
Dans le cas contraire, les zones de disponibilité pour Recherche IA Azure sont prises en charge dans les régions suivantes :
| Région | Déploiement |
|---|---|
| Australie Est | 30 janvier 2021 ou ultérieur |
| Brésil Sud | 2 mai 2021 ou ultérieur |
| Centre du Canada | 30 janvier 2021 ou ultérieur |
| Inde centrale | 20 janvier 2022 ou ultérieur |
| USA Centre | 4 décembre 2020 ou ultérieur |
| Chine Nord 3 | 7 septembre 2022 ou ultérieur |
| Asie Est | 13 janvier 2022 ou ultérieur |
| USA Est | 27 janvier 2021 ou ultérieur |
| USA Est 2 | 30 janvier 2021 ou ultérieur |
| France Centre | 23 octobre 2020 ou ultérieur |
| Allemagne Centre-Ouest | 3 mai 2021 ou ultérieur |
| Japon Est | 30 janvier 2021 ou ultérieur |
| Centre de la Corée | 20 janvier 2022 ou ultérieur |
| Europe Nord | 28 janvier 2021 ou ultérieur |
| Norvège Est | 20 janvier 2022 ou ultérieur |
| Qatar Central | 25 août 2022 ou ultérieur |
| Afrique du Sud Nord | 7 septembre 2022 ou ultérieur |
| États-Unis - partie centrale méridionale | 30 avril 2021 ou ultérieur |
| Asie Sud-Est | 31 janvier 2021 ou ultérieur |
| Suède Centre | 21 janvier 2022 ou ultérieur |
| Suisse Nord | 7 septembre 2022 ou ultérieur |
| Émirats arabes unis Nord | 9 septembre 2022 ou ultérieur |
| Sud du Royaume-Uni | 30 janvier 2021 ou ultérieur |
| Gouvernement américain - Virginie | 30 avril 2021 ou ultérieur |
| Europe Ouest | 29 janvier 2021 ou ultérieur |
| USA Ouest 2 | 30 janvier 2021 ou ultérieur |
| USA Ouest 3 | 02 juin 2021 ou ultérieur |
Remarque
Les zones de disponibilité ne modifient pas les termes du Contrat de niveau de service d’Azure AI Search. Vous avez toujours besoin d’au moins trois réplicas pour la haute disponibilité des requêtes.
Plusieurs services dans des régions géographiques distinctes
La redondance de service est nécessaire si vos besoins opérationnels sont les suivants :
Prérequis de la continuité d’activité et reprise d’activité (BCDR) (Azure AI Search ne fournit pas de basculement instantané en cas de panne.)
Performances rapides pour une application distribuée mondialement. Si les demandes d’interrogation et d’indexation proviennent du monde entier, les utilisateurs les plus proches du centre de données hôte bénéficieront de performances plus rapides. La création de services supplémentaires dans les régions les plus proches de ces utilisateurs peut égaliser les performances pour tous les utilisateurs.
Si vous avez besoin de deux services de recherche ou plus, leur création dans des régions différentes peut répondre aux exigences des applications en matière de continuité et de récupération, ainsi qu’à des temps de réponse plus rapides pour une base d’utilisateurs mondiale.
Azure AI Search n’offre pas de méthode automatisée de réplication des index de recherche entre régions géographiques, mais certaines techniques simplifient l’implémentation et la gestion de ce processus. Celles-ci sont décrites dans les sections suivantes.
L’objectif d’un ensemble géodistribué de services de recherche est de disposer de plusieurs index dans au moins deux régions et de rediriger l’utilisateur vers le service Azure AI Search qui offre la plus faible latence :
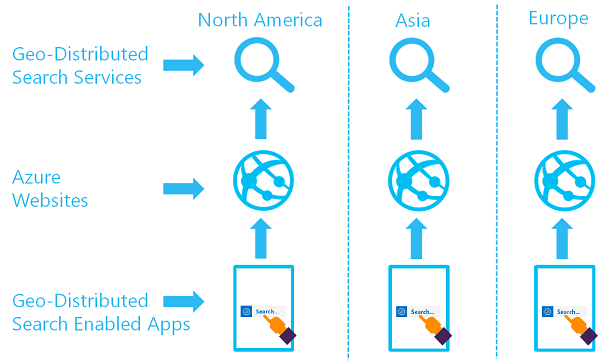
Vous pouvez implémenter cette architecture en créant plusieurs services et en concevant une stratégie de synchronisation des données. Si vous le souhaitez, vous pouvez inclure une ressource comme Azure Traffic Manager pour le routage des demandes.
Conseil
Pour obtenir de l’aide sur le déploiement de plusieurs services de recherche dans plusieurs régions, consultez cet exemple Bicep sur GitHub qui déploie une solution de recherche multirégion entièrement configurée. L’exemple vous offre deux options pour la synchronisation d’index et la redirection de requêtes à l’aide de Traffic Manager.
Synchronisation des données sur plusieurs services
Il existe deux options pour conserver deux services de recherche distincts ou plus distincts synchronisés :
- Extrayez les mises à jour de contenu dans un index de recherche à l’aide d’un indexeur.
- Envoyez du contenu à un index à l’aide de l’API Ajouter ou mettre à jour des documents (REST) ou d’une API équivalente au Kit de développement logiciel (SDK) Azure.
Pour configurer l’une ou l’autre option, nous vous recommandons d’utiliser l’exemple de script Bicep dans le référentiel azure-search-multiple-region, modifié dans vos régions et stratégies d’indexation.
Option 1 : Mettre à jour le contenu dans plusieurs services à l’aide d’indexeurs
Si vous utilisez déjà un indexeur sur un service unique, vous pouvez configurer un second indexeur sur un deuxième service pour qu’il utilise le même objet de source de données, en extrayant les données au même emplacement. Chacun des services de chaque région dispose de son propre indexeur et d’un index cible (votre index de recherche n’est pas partagé, ce qui signifie que chaque index a sa copie des données), mais chaque indexeur référence la même source de données.
Voici une vue d’ensemble de l’aspect d’une telle architecture.
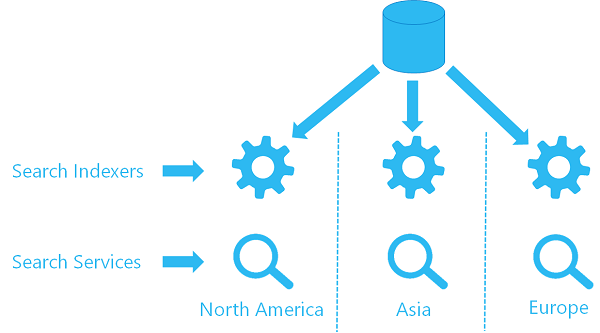
Option 2 : Envoyer (push) les mises à jour de contenu à plusieurs services à l’aide d’API REST
Si vous utilisez l’API REST Azure AI Search pour envoyer (push) le contenu à votre index de recherche, vous pouvez assurer la synchronisation continue de vos différents services de recherche en envoyant les modifications à tous ces services chaque fois qu’une mise à jour est nécessaire. Dans votre code, veillez à gérer les cas dans lesquels la mise à jour d’un service de recherche échoue, mais réussit pour d’autres services de recherche.
Basculer ou rediriger des requêtes
Si vous avez besoin de redondance au niveau de la requête, Azure fournit plusieurs options d’équilibrage de charge :
- Azure Traffic Manager vous permet d’acheminer les requêtes vers plusieurs sites géo-localisés et pris en charge par plusieurs services de recherche.
- Application Gatewayvous permet d’équilibrer la charge entre vos serveurs dans une région au niveau de la couche Application.
- Azure Front Door vous permet d’optimiser le routage global du trafic web et fournir un basculement global.
Certains points à garder à l’esprit lors de l’évaluation des options d’équilibrage de charge :
La recherche est un service principal qui accepte les requêtes et l’indexation des requêtes d’un client.
Les demandes du client vers un service de recherche doivent être authentifiées. Pour accéder aux opérations de recherche, l’appelant doit disposer d’autorisations en fonction du rôle ou fournir une clé API sur la demande.
Les points de terminaison de service sont atteints via une connexion Internet publique par défaut. Si vous configurez un point de terminaison privé pour les connexions clientes provenant d’un réseau virtuel, utilisez Application Gateway.
Azure AI Search accepte les demandes adressées au point de terminaison
<your-search-service-name>.search.windows.net. Si vous atteignez le même point de terminaison à l’aide d’un autre nom DNS dans l’en-tête de l’hôte, tel qu’un CNAME, la requête est rejetée.
Azure AI Search fournit un exemple de déploiement multirégion qui utilise Azure Traffic Manager pour la redirection de requêtes si le point de terminaison principal échoue. Cette solution est utile lorsque vous routez vers un client compatible avec la recherche qui appelle uniquement un service de recherche dans la même région.
Azure Traffic Manager est principalement utilisé pour acheminer le trafic réseau entre différents points de terminaison en fonction de méthodes de routage spécifiques (telles que la priorité, les performances ou l’emplacement géographique). Il agit au niveau DNS pour diriger les requêtes entrantes vers le point de terminaison approprié. Si un point de terminaison que Traffic Manager assure la maintenance commence à refuser les demandes, le trafic est acheminé vers un autre point de terminaison.
Traffic Manager ne fournit pas de point de terminaison pour une connexion directe à Azure AI Search, ce qui signifie que vous ne pouvez pas placer un service de recherche directement derrière Traffic Manager. Au lieu de cela, l’hypothèse est que les requêtes circulent vers Traffic Manager, puis vers un client web avec recherche, puis vers un service de recherche sur le back-end. Le client et le service se trouvent dans la même région. Si un service de recherche tombe en panne, le client de recherche démarre en échec et Traffic Manager redirige vers le client restant.
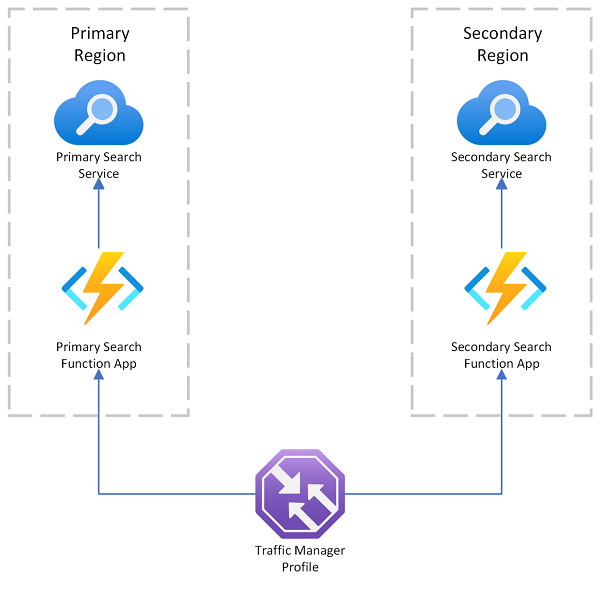
À propos de la résidence des données dans un déploiement multirégion
Lorsque vous déployez plusieurs services de recherche dans différentes régions géographiques, votre contenu est stocké dans la région que vous avez choisie pour chaque service de recherche.
Azure AI Search ne stocke pas de données en dehors de votre région spécifiée sans votre autorisation. L’autorisation est implicite lorsque vous utilisez les fonctionnalités qui écrivent dans une ressource de Stockage Azure : cache d’enrichissement, session de débogage, base de connaissances. Dans tous les cas, le compte de stockage est celui que vous fournissez, dans la région de votre choix.
Remarque
Si le compte de stockage et le service de recherche se trouvent dans la même région, le trafic réseau entre la recherche et le stockage utilise une adresse IP privée et circule sur le réseau principal Microsoft. Étant donné que des adresses IP privées sont utilisées, vous ne pouvez pas configurer de pare-feu IP ou de point de terminaison privé pour la sécurité réseau. Au lieu de cela, vous pouvez utiliser l’exception de service approuvé lorsque les deux services se trouvent dans la même région.
À propos des pannes de service et des événements catastrophiques
Comme indiqué dans le Contrat de niveau de service (SLA), Microsoft garantit un haut niveau de disponibilité pour les demandes de requête d’index lorsqu’une instance du service Azure AI Search est configurée avec au moins deux réplicas, et les demandes de mise à jour d’index lorsqu’une instance du service d’Azure AI Search est configurée avec trois réplicas ou plus. Cependant, il n'existe actuellement aucun mécanisme intégré de récupération d'urgence. Si le service ne doit pas être interrompu même en cas de défaillances catastrophiques qui échappent au contrôle de Microsoft, nous vous recommandons d’approvisionner un service supplémentaire dans une autre région et de mettre en œuvre une stratégie de géoréplication pour assurer une redondance complète des index sur tous les services.
Les clients qui utilisent des indexeurs pour remplir et actualiser les index peuvent gérer la récupération d’urgence par le biais d’indexeurs propres à la région qui récupèrent des données depuis la même source de données. Deux services situés dans des régions différentes, chacun exécutant un indexeur, peuvent indexer la même source de données pour bénéficier de la géoredondance. Si vous indexez à partir de sources de données qui sont aussi géoredondantes, n’oubliez pas que les indexeurs d’Azure AI Search ne peuvent assurer qu’une indexation incrémentielle (en fusionnant les mises à jour de documents nouveaux, modifiés ou supprimés) à partir de réplicas principaux. À l’occasion d’un basculement, veillez à rediriger l’indexeur vers le nouveau réplica principal.
Si vous n’utilisez pas d’indexeur, vous devez utiliser le code de votre application pour envoyer (push) des objets et données à différents services de recherche en parallèle. Pour plus d’informations, consultez Garantir la synchronisation des données entre plusieurs services.
Alternatives de sauvegarde et de restauration
Une stratégie de continuité d’activité pour la couche de données inclut généralement une étape de restauration à partir d’une sauvegarde. Azure AI Search n’étant pas une solution de stockage de données principal, Microsoft ne fournit pas de mécanisme formel de sauvegarde et de restauration en libre-service. Toutefois, vous pouvez utiliser l’exemple de code index-backup-restore dans cet exemple de dépôt .NET Azure AI Search pour sauvegarder la définition et l’instantané d’un index dans une série de fichiers JSON, puis utiliser ces fichiers pour restaurer l’index, si nécessaire. Cet outil peut également déplacer des index entre les niveaux de service.
Sinon, le code de votre application utilisé pour créer et remplir un index est l’option de restauration de facto si vous supprimez un index par erreur. Pour reconstruire un index, vous devez le supprimer (s’il existe), recréer l’index dans le service et le recharger en récupérant les données à partir de votre banque de données principale.
Étapes suivantes
- Pour plus d’informations sur les niveaux tarifaires et les limites de service de chacun d’eux, consultez Limites de service.
- Consultez la page Planification des capacités pour en savoir plus sur les combinaisons de partitions et de réplicas.
- Consultez Étude de cas : La recherche cognitive au service de scénarios d’intelligence artificielle complexes (en anglais) si vous avez besoin d’aide pour la configuration.