Planification de la capacité pour les applications Service Fabric
Ce document explique comment estimer la quantité de ressources (UC, RAM, stockage sur disque) dont vous avez besoin pour exécuter vos applications Azure Service Fabric. Il est courant que les ressources requises changent au fil du temps. Vous avez besoin généralement de peu de ressources quand vous développez/testez votre service, puis vous avez besoin de plus de ressources quand vous passez en production et que votre application grandit en popularité. Quand vous concevez votre application, réfléchissez à la configuration requise à long terme et faites des choix qui permettront à votre service d’évoluer pour répondre à la hausse de demande des clients.
Quand vous créez un cluster Service Fabric, vous décidez quels types de machines virtuelles (VM) doivent le constituer. Chaque machine virtuelle est fournie avec une quantité limitée de ressources sous forme d’UC (cœurs et vitesse), bande passante réseau, mémoire RAM et stockage sur disque. À mesure que votre service croît, vous pouvez effectuer des mises à niveau vers des machines virtuelles qui offrent davantage de ressources et/ou ajouter des machines virtuelles à votre cluster. Dans ce dernier cas, vous devez créer l’architecture de votre service initialement de façon à tirer parti des nouvelles machines virtuelles ajoutées dynamiquement au cluster.
Certains services gèrent peu à pas de données sur les machines virtuelles proprement dites. Par conséquent, la planification de capacité pour ces services doit se concentrer principalement sur les performances, ce qui signifie qu’il faut sélectionner les unités centrales appropriées (cœurs et vitesse) des machines virtuelles. En outre, vous devez prendre en compte la bande passante réseau, notamment la fréquence des transferts réseau et la quantité de données transférées. Si votre service doit être performant lorsque l'utilisation de service augmente, vous pouvez ajouter davantage de machines virtuelles dans le cluster et équilibrer la charge des demandes réseau entre les machines virtuelles.
Pour les services qui gèrent de grandes quantités de données sur les machines virtuelles, la planification de la capacité doit se concentrer principalement sur la taille. Cela signifie donc que vous devez être attentif à la capacité de RAM et du stockage sur disque de la machine virtuelle. Le système de gestion de mémoire virtuelle dans Windows rend l’espace disque similaire à la RAM pour le code d’application. En outre, le runtime Service Fabric offre la pagination intelligente en conservant uniquement les données à chaud en mémoire et en déplaçant les données à froid sur le disque. Cela permet aux applications d’utiliser plus de mémoire que la quantité physique disponible sur la machine virtuelle. Avoir plus de mémoire vive augmente simplement les performances, car la machine virtuelle peut conserver davantage de stockage sur disque dans la mémoire RAM. La machine virtuelle que vous sélectionnez doit avoir un disque suffisamment grand pour stocker les données que vous souhaitez sur la machine virtuelle. De même, la machine virtuelle doit avoir suffisamment de RAM pour vous fournir les performances souhaitées. Si les données de votre service augmentent au fil du temps, vous pouvez ajouter davantage de machines virtuelles au cluster et partitionner les données entre les machines virtuelles.
Déterminer le nombre de nœuds nécessaire
Le fait de partitionner votre service vous permet d’augmenter la taille des instances des données de votre service. Pour plus d’informations sur le partitionnement, consultez Partitionnement de Service Fabric. Chaque partition doit tenir sur une seule machine virtuelle, mais plusieurs (petites) partitions peuvent être placées sur une seule machine virtuelle. Ainsi, avoir plus de petites partitions offre davantage de souplesse que d’avoir un petit nombre de grandes partitions. En contrepartie, disposer d’un grand nombre de partitions augmente la charge de Service Fabric et vous ne pouvez pas effectuer des opérations traitées sur plusieurs partitions. Il y a également plus de trafic réseau potentiel si votre code de service doit fréquemment accéder à des éléments de données qui résident dans des partitions différentes. Lorsque vous concevez votre service, vous devez étudier soigneusement ces avantages et inconvénients pour obtenir une stratégie de partitionnement efficace.
Supposons que votre application possède un seul service avec état qui a une taille de magasin qui doit atteindre DB_Size Go dans un an. Vous êtes prêt à ajouter d’autres applications (et partitions) pour accompagner votre croissance au-delà de cette année. Le facteur de réplication (RF), qui détermine le nombre de réplicas pour votre service a une incidence sur la taille DB_Size totale. La taille DB_Size totale sur tous les réplicas correspond au facteur de réplication (RF) multiplié par DB_Size. Node_Size représente l’espace disque/la RAM par nœud que vous souhaitez utiliser pour votre service. Pour de meilleures performances, DB_Size doit tenir dans la mémoire au sein du cluster et vous devez utiliser une taille Node_Size équivalente à la RAM de la machine virtuelle. En allouant une valeur Node_Size qui est supérieure à la capacité de la mémoire RAM, vous vous reposez sur la pagination fournie par le runtime Service Fabric. Par conséquent, les performances peuvent ne pas être optimales si toutes vos données sont considérées comme étant à chaud (car alors les données sont paginées en entrée/sortie). Toutefois, pour de nombreux services où seule une fraction des données est à chaud, cela est plus rentable.
Le nombre de nœuds nécessaires pour optimiser les performances peut être calculé comme suit :
Number of Nodes = (DB_Size * RF)/Node_Size
Prendre la croissance en compte
Vous pouvez calculer le nombre de nœuds en fonction de la valeur DB_Size que votre service doit atteindre selon vous, en plus de la valeur DB_Size avec laquelle vous avez commencé. Vous pouvez ensuite augmenter le nombre de nœuds à mesure que votre service se développe afin de ne pas surapprovisionner le nombre de nœuds. Toutefois, le nombre de partitions doit être basé sur le nombre de nœuds qui sont nécessaires quand vous exécutez votre service à croissance maximale.
Il est judicieux d’avoir des ordinateurs supplémentaires disponibles à tout moment afin de pouvoir gérer les pics ou les défaillances inattendus (si, par exemple, plusieurs machines virtuelles tombent en panne). Bien que la capacité supplémentaire doive être déterminée à l’aide de vos pics attendus, un bon point de départ consiste à réserver quelques machines virtuelles supplémentaires (5 à 10 % supplémentaires).
La proposition ci-dessus suppose un seul service avec état. Si vous avez plus d’un service avec état, vous devez ajouter la valeur DB_Size associée aux autres services dans l’équation. Vous pouvez également calculer le nombre de nœuds séparément pour chaque service avec état. Votre service peut avoir des réplicas ou des partitions qui ne sont pas équilibrés. N’oubliez pas que certaines partitions peuvent également contenir plus de données que d’autres. Pour plus d’informations sur le partitionnement, consultez l’article sur les meilleures pratiques de partitionnement. Toutefois, l’équation précédente ne tient pas compte des partitions et des réplicas, car Service Fabric garantit que les réplicas sont répartis entre les nœuds de manière optimisée.
Utiliser une feuille de calcul pour le calcul des coûts
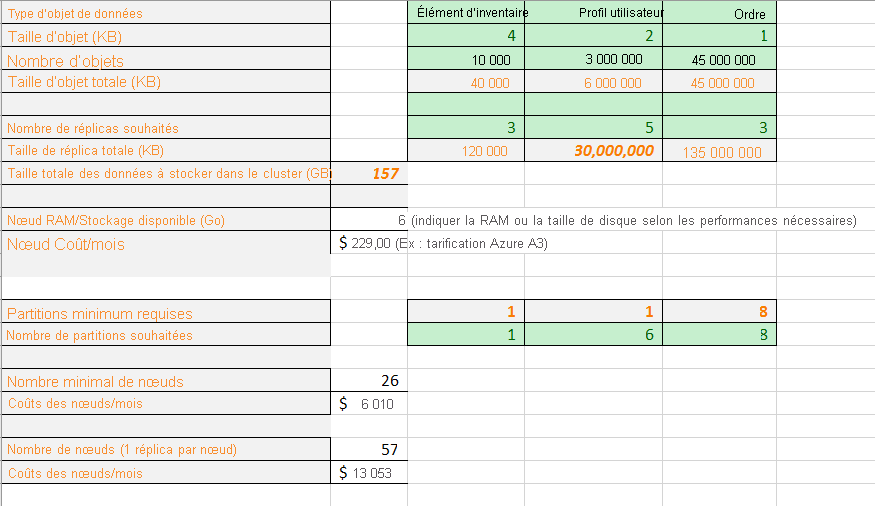
Maintenant, nous allons placer des chiffres réels dans la formule. Un exemple de feuille de calcul montre comment planifier la capacité pour une application qui contient trois types d’objets de données. Pour chaque objet, nous estimons sa taille et le nombre d'objets que nous nous attendons à avoir. Nous sélectionnons également le nombre de réplicas pour chaque type d’objet. La feuille de calcul calcule la quantité totale de mémoire à stocker dans le cluster.
Ensuite, nous entrons une taille de machine virtuelle et le coût mensuel. Selon la taille de la machine virtuelle, la feuille de calcul vous indique le nombre minimal de partitions nécessaires à la répartition physique des données sur les nœuds. Vous pouvez souhaiter un plus grand nombre de partitions pour prendre en charge les besoins en calcul et trafic réseau spécifiques de votre application. La feuille de calcul montre que le nombre de partitions pour gérer les objets de profils utilisateur est passé de un à six.
À présent, avec toutes ces informations, la feuille de calcul montre que vous pouvez physiquement obtenir toutes les données avec les partitions et les réplicas souhaités sur un cluster de 26 nœuds. Toutefois, ce cluster étant très compact, vous pouvez vouloir des nœuds supplémentaires pour prendre en charge les mises à niveau et les défaillances de nœud. La feuille de calcul indique également qu’avoir plus de 57 nœuds ne fournit aucune valeur supplémentaire, car vous auriez des nœuds vides. Là encore, vous souhaiterez peut-être aller au-dessus des 57 nœuds malgré tout pour prendre en charge les mises à niveau et les défaillances de nœud. Vous pouvez modifier la feuille de calcul pour répondre aux besoins spécifiques de votre application.
Étapes suivantes
Consultez la page Partitionnement des services Service Fabric pour en savoir plus sur le partitionnement de votre service.