Gestion de la consommation des ressources et des charges dans Service Fabric à l’aide de mesures
Les mesures sont les ressources qui intéressent vos services et qui sont fournies par les nœuds dans le cluster. Une mesure représente ce que vous souhaitez gérer afin d’améliorer ou de surveiller les performances de vos services. Par exemple, vous pourrez surveiller la consommation de mémoire pour savoir si votre service est surchargé. Vous pouvez également déterminer si le service peut être déplacé vers un autre emplacement où la mémoire est moins contrainte afin d’obtenir de meilleures performances.
Il peut s’agir par exemple de l’utilisation de la mémoire, du disque ou du processeur. Il s’agit de mesures physiques, des ressources qui correspondent aux ressources physiques sur le nœud qui doivent être gérées. Les mesures peuvent également être (et sont généralement) des mesures logiques. Les mesures logiques sont des éléments tels que « MyWorkQueueDepth », « MessagesToProcess » ou « TotalRecords ». Les mesures logiques sont définies par l’application et correspondent indirectement à la consommation des ressources physiques. Les mesures logiques sont courantes car il peut être difficile de mesurer et de signaler la consommation des ressources physiques pour chaque service. La complexité liée à la détermination de mesures physiques personnalisées et à la création de rapports sur celles-ci explique également pourquoi Service Fabric propose des mesures par défaut.
Mesures par défaut
Supposons que vous souhaitez commencer à écrire et à déployer votre service. À ce stade, vous ne connaissez pas les ressources physiques ou logiques qu’il consomme. Pas de problème ! Service Fabric Cluster Resource Manager utilise certaines mesures par défaut si aucune autre mesure n’est spécifiée. Il s'agit de :
- PrimaryCount - nombre de réplicas principaux sur le nœud
- ReplicaCount - nombre total de réplicas avec état sur le nœud
- Count - nombre de tous les objets de service (avec et sans état) sur le nœud
| Métrique | Charge de l’instance sans état | Charge secondaire avec état | Charge principale avec état | Poids |
|---|---|---|---|---|
| PrimaryCount | 0 | 0 | 1 | Élevé |
| ReplicaCount | 0 | 1 | 1 | Moyenne |
| Count | 1 | 1 | 1 | Faible |
Pour les charges de travail de base, les mesures par défaut fournissent une distribution acceptable du travail dans le cluster. Dans l’exemple suivant, examinons ce qui se passe lorsque nous créons deux services et que nous utilisons les mesures par défaut pour l’équilibrage. Le premier est un service avec état présentant trois partitions et une taille de jeu de réplicas cible de trois. Le second est un service sans état présentant une partition et un nombre d’instances de trois.
Voici ce que vous obtenez :
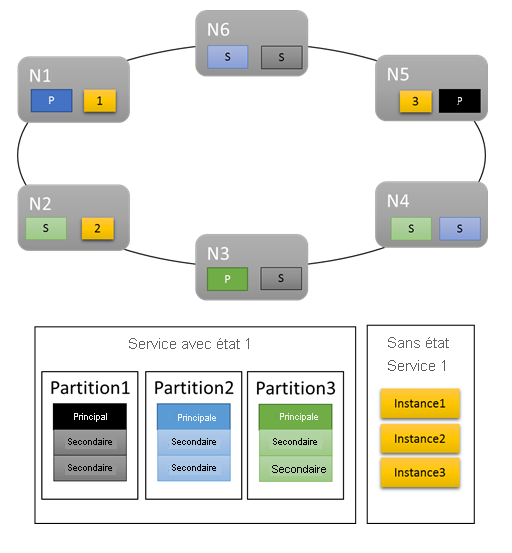
Quelques éléments à prendre en compte :
- Les réplicas principaux du service avec état sont répartis dans plusieurs nœuds
- Les réplicas pour la même partition sont sur des nœuds différents
- L’ensemble des réplicas principaux et secondaires sont répartis dans le cluster
- L’ensemble des objets de service sont alloués uniformément sur chaque nœud
Bien !
Les mesures par défaut fonctionnent très bien comme point de départ. Mais elles ne vous permettront pas d’en faire plus. Par exemple : quelle est la probabilité que le schéma de partitionnement de votre choix garantisse une utilisation des ressources parfaitement uniforme sur l’ensemble des partitions ? Quelle est la probabilité que la charge d’un service donné reste constante au fil du temps, ou même simplement identique sur plusieurs partitions ?
Vous pouvez vous contenter des mesures par défaut. Toutefois, cette approche signifie que l’utilisation de votre cluster est inférieure et plus irrégulière que ce que vous souhaitez. En effet, les mesures par défaut ne sont pas adaptatives et partent du principe que tous les éléments sont équivalents. Par exemple, un serveur principal qui est occupé et un autre serveur qui ne l’est pas contribuent à une valeur de « 1 » à la mesure PrimaryCount. Dans le pire des cas, utiliser uniquement les mesures par défaut peut également entraîner des surplanifications de nœuds, ce qui peut causer des problèmes de performances. Si vous souhaitez tirer le meilleur parti de votre cluster et éviter de rencontrer des problèmes de performances, vous devez utiliser des mesures personnalisées et des rapports de charge dynamique.
Mesures personnalisées
La configuration des mesures se fait lors de la création du service, sur la base d’une instance de service nommée.
N’importe quelle mesure présente un certain nombre de propriétés qui la décrivent : un nom, un poids et une charge par défaut.
- Nom de la métrique : Nom de la mesure. utilisé par Resource Manager pour la mesure au sein du cluster.
Notes
Le nom de métrique personnalisé ne doit pas être l’un des noms de métriques système, à savoir servicefabric:/_CpuCores ou servicefabric:/_MemoryInMB, car cela peut entraîner un comportement non défini. À compter de Service Fabric version 9.1, pour les services existants avec ces noms de métriques personnalisés, un avertissement d’intégrité est émis pour indiquer que le nom de métrique est incorrect.
- Poids : pondération de la métrique, qui définit l’importance de la métrique par rapport aux autres métriques utilisées pour ce service.
- Charge par défaut : la charge par défaut est représentée différemment selon que le service est avec ou sans état.
- Pour les services sans état, chaque mesure présente une propriété unique nommée DefaultLoad.
- Pour les services avec état, vous devez définir les éléments suivants :
- PrimaryDefaultLoad : quantité par défaut de la métrique que le service consomme lorsqu’il s’agit d’un réplica principal.
- SecondaryDefaultLoad : quantité par défaut de la métrique que le service consomme lorsqu’il s’agit d’un réplica secondaire.
Notes
Si vous définissez des mesures personnalisées et souhaitez également utiliser les mesures par défaut, vous devez explicitement rajouter ces mesures par défaut et définir leurs poids ainsi que leurs valeurs. En effet, vous devez définir la relation entre les mesures par défaut et vos mesures personnalisées. Peut-être accordez-vous plus d’importance au paramètre ConnectionCount ou WorkQueueDepth qu’à la distribution principale. Par défaut, le poids de la mesure PrimaryCount est élevé. Vous devez donc le réduire à un niveau moyen lorsque vous ajoutez vos autres mesures pour vous assurer qu’elles sont prioritaires.
Exemple de définition de mesures pour votre service
Supposons que vous souhaitez obtenir la configuration suivante :
- Votre service signale une mesure nommée « ConnectionCount »
- Vous souhaitez également utiliser des mesures par défaut
- Vous avez effectué des mesures et savez que normalement un réplica principal de ce service utilise jusqu’à 20 unités de la mesure « ConnectionCount »
- Les réplicas secondaires utilisent 5 unités de la mesure « ConnectionCount »
- Vous savez que la mesure « ConnectionCount » est la mesure la plus importante en matière de gestion des performances de ce service spécifique
- Mais vous souhaitez néanmoins que les réplicas principaux soient équilibrés. L’équilibrage des réplicas principaux est généralement une bonne solution. Il permet d’éviter que la perte d’un domaine de nœud ou d’erreur n’affecte une majorité de réplicas principaux.
- Sinon, les mesures par défaut conviennent parfaitement
Voici le code que vous devez écrire pour créer un service avec cette configuration de mesures :
Code :
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
StatefulServiceLoadMetricDescription connectionMetric = new StatefulServiceLoadMetricDescription();
connectionMetric.Name = "ConnectionCount";
connectionMetric.PrimaryDefaultLoad = 20;
connectionMetric.SecondaryDefaultLoad = 5;
connectionMetric.Weight = ServiceLoadMetricWeight.High;
StatefulServiceLoadMetricDescription primaryCountMetric = new StatefulServiceLoadMetricDescription();
primaryCountMetric.Name = "PrimaryCount";
primaryCountMetric.PrimaryDefaultLoad = 1;
primaryCountMetric.SecondaryDefaultLoad = 0;
primaryCountMetric.Weight = ServiceLoadMetricWeight.Medium;
StatefulServiceLoadMetricDescription replicaCountMetric = new StatefulServiceLoadMetricDescription();
replicaCountMetric.Name = "ReplicaCount";
replicaCountMetric.PrimaryDefaultLoad = 1;
replicaCountMetric.SecondaryDefaultLoad = 1;
replicaCountMetric.Weight = ServiceLoadMetricWeight.Low;
StatefulServiceLoadMetricDescription totalCountMetric = new StatefulServiceLoadMetricDescription();
totalCountMetric.Name = "Count";
totalCountMetric.PrimaryDefaultLoad = 1;
totalCountMetric.SecondaryDefaultLoad = 1;
totalCountMetric.Weight = ServiceLoadMetricWeight.Low;
serviceDescription.Metrics.Add(connectionMetric);
serviceDescription.Metrics.Add(primaryCountMetric);
serviceDescription.Metrics.Add(replicaCountMetric);
serviceDescription.Metrics.Add(totalCountMetric);
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
PowerShell :
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("ConnectionCount,High,20,5”,"PrimaryCount,Medium,1,0”,"ReplicaCount,Low,1,1”,"Count,Low,1,1”)
Notes
Les exemples ci-dessus et le reste de ce document décrivent les mesures de gestion pour chaque service nommé. Il est également possible de définir les mesures de vos services au niveau du type de service. Cette opération s’effectue en les spécifiant dans vos manifestes de service. La définition des mesures au niveau du type n’est pas recommandée pour plusieurs raisons. Premièrement, les noms des mesures sont souvent spécifiques à l’environnement. À moins qu’un contrat ait été clairement mis en place, vous ne pouvez pas être sûr que la mesure « Cores » d’un environnement ne devient pas « MiliCores » ou « CoReS » dans d’autres. Si vos métriques sont définies dans votre manifeste, vous devez créer de nouveaux manifestes pour chaque environnement. Cela entraîne généralement une prolifération de plusieurs manifestes avec des différences mineures, ce qui peut provoquer des problèmes de gestion.
Les charges de mesure sont couramment attribuées pour chaque service nommé. Par exemple, supposons que vous créez une instance du service pour un Client A qui envisage de ne l’utiliser que rarement. Supposons également que vous créez une autre instance de service pour un Client B disposant d’une plus grande charge de travail. Dans ce cas, vous souhaitez probablement optimiser les charges par défaut pour ces services. Si vous avez des mesures et des charges définies via des manifestes et souhaitez prendre en charge ce scénario, vous devez utiliser des types d’application et de service différents pour chaque client. Les valeurs définies au moment de la création du service remplacent celles définies dans le manifeste, et vous pouvez donc les utiliser pour définir les valeurs par défaut spécifiques. Mais en procédant ainsi, les valeurs déclarées dans les manifestes ne correspondent pas à celles que le service utilise. Cette situation peut entraîner une certaine confusion.
Rappel : si vous voulez simplement utiliser les mesures par défaut, vous n’avez pas du tout besoin d’utiliser la collection de mesures ou d’intervenir. Les mesures par défaut sont automatiquement utilisées si aucune autre mesure n’est définie.
À présent, passons en revue chacun de ces paramètres plus en détail et examinons leur impact sur le comportement.
Load
La définition de mesures a pour but de représenter certaines charges. Une charge correspond à la quantité d’une mesure spécifique qui est consommée par une instance ou un réplica de service sur un nœud donné. La charge peut être configurée en presque n’importe quel point. Par exemple :
- La charge peut être définie lors de la création d’un service. Ce type de configuration de chargement est appelé charge par défaut.
- Les informations sur les mesures, notamment les charges par défaut, d’un service peuvent être mises à jour une fois le service créé. Cette mise à jour de métrique est effectuée par la mise à jour d’un service.
- Les charges d’une partition donnée peuvent être réinitialisées aux valeurs par défaut pour ce service. Cette mise à jour de métrique est nommée Réinitialisation d’une charge de partition.
- La charge peut être dynamiquement signalée pour chaque objet de service lors de l’exécution. Cette mise à jour de métrique est nommée Signalement de charge.
- Le chargement des réplicas ou instances de la partition peut également être mis à jour en signalant des valeurs de chargement via un appel d’API Fabric. Cette mise à jour de métrique est nommée Signalement de charge pour une partition.
Toutes ces stratégies peuvent être utilisées dans le même service pendant sa durée de vie.
Charge par défaut
La charge par défaut correspond à la mesure consommée par chaque objet de service (instance sans état ou réplica avec état). Cluster Resource Manager utilise ce nombre pour la charge de l’objet de service jusqu'à ce qu’il reçoive d’autres informations, par exemple un rapport de charge dynamique. Pour les services plus simples, la charge par défaut est une définition statique. La charge par défaut n’est jamais mise à jour et est utilisée pour toute la durée de vie du service. La charge par défaut est idéale pour les scénarios de planification de capacité simples où certaines quantités de ressources sont dédiées à différentes charges de travail et n’évoluent pas.
Notes
Pour plus d’informations sur la gestion de la capacité et la définition des capacités pour les nœuds de votre cluster, consultez cet article.
Cluster Resource Manager permet aux services avec état de spécifier une charge par défaut différente pour leurs réplicas principaux et secondaires. Les services sans état peuvent seulement spécifier une valeur qui s’applique à toutes les instances. Dans le cas des services avec état, les charges par défaut des réplicas principaux et secondaires sont généralement différentes, puisque les réplicas n’exécutent pas les mêmes tâches selon qu’ils remplissent l’un ou l’autre rôle. Par exemple, les réplicas principaux assument généralement les opérations de lecture et d’écriture, et gèrent que la plupart des tâches de calcul, ce qui n’est pas le cas des réplicas secondaires. La charge par défaut pour un réplica principal est généralement supérieure à la charge par défaut pour des réplicas secondaires. Les valeurs réelles varient selon vos propres mesures.
Charge dynamique
Supposons que vous exécutiez votre service depuis un certain temps. En procédant à certaines analyses, vous avez observé que :
- Certaines partitions ou instances d’un service donné consomment plus de ressources que d’autres.
- La charge de certains services varie au fil du temps.
De nombreux facteurs peuvent causer ces types de fluctuations de charge. Par exemple, différents services ou partitions sont associés à différents clients présentant différentes exigences. La charge peut également changer car la quantité de travail effectuée par le service ne varie au cours de la journée. Quelle que soit la raison, il n’existe généralement pas de valeur unique utilisable pour la charge par défaut. Cela est particulièrement vrai si vous souhaitez exploiter au maximum le cluster. La valeur que vous choisissez pour la charge par défaut sera forcément inadaptée à un moment ou un autre. Si les charges par défaut sont incorrectes, Resource Manager alloue un nombre trop important ou insuffisant de ressources. Certains nœuds se retrouvent alors sur ou sous-utilisés, même si Cluster Resource Manager considère que le cluster est équilibré. Les charges par défaut sont toujours adaptées car elles fournissent certaines informations pour le placement initial, mais elles n’offrent pas un tableau complet des charges de travail réelles. Pour prendre en compte avec précision les changements de besoins en ressources, Cluster Resource Manager permet à chaque objet de service de mettre à jour sa propre charge pendant l’exécution. On parle de « rapports de charge dynamique ».
Les rapports de charge dynamique permettent aux réplicas ou aux instances d’ajuster leur allocation ou la charge signalée pour les mesures pendant toute leur durée de vie. Des réplicas ou des instances de service inactifs signalent généralement qu’ils utilisent une faible quantité d’une mesure spécifique. Des réplicas ou des instances de service actifs signalent quant à eux qu’ils en utilisent une quantité plus importante.
Les rapports de charge par réplica ou par instance permettent à Cluster Resource Manager de réorganiser les objets de service individuels dans le cluster. La réorganisation des services permet de s’assurer qu’ils récupèrent les ressources dont ils ont besoin. Les services actifs peuvent ainsi récupérer les ressources de réplicas ou d’instances qui sont actuellement inactifs ou moins actifs.
Dans Reliable Services, le code permettant de signaler dynamiquement la charge ressemble à ceci :
Code :
this.Partition.ReportLoad(new List<LoadMetric> { new LoadMetric("CurrentConnectionCount", 1234), new LoadMetric("metric1", 42) });
Un service peut générer un rapport sur n’importe quelle mesure définie au moment de la création. Si un service génère un rapport pour une charge d’une mesure qui n’est pas configurée pour être utilisée, Service Fabric ignore ce rapport. Si d’autres mesures valides ont été signalées en même temps, ces rapports sont acceptés. Le code du service peut mesurer et signaler toutes les mesures qu’il connaît, et les opérateurs peuvent spécifier la configuration de mesures à utiliser sans avoir à modifier le code du service.
Création de rapports de charge pour une partition
La section précédente décrit comment les réplicas de service ou les instances signalent leur chargement. Il existe une option supplémentaire pour reporter dynamiquement la charge pour les réplicas ou les instances d’une partition par le biais de l’API Service Fabric. Lors du signalement de charge pour une partition, vous pouvez générer des rapports sur plusieurs partitions à la fois.
Ces rapports sont utilisés de la même façon que les rapports de charge provenant des réplicas ou des instances eux-mêmes. Les valeurs signalées sont valides jusqu’à ce que de nouvelles valeurs de chargement soient signalées par le réplica ou par l’instance ou en signalant une nouvelle valeur de chargement pour une partition.
Avec cette API, il existe plusieurs façons de mettre à jour la charge dans le cluster :
- Une partition de service avec état peut mettre à jour sa charge de réplica principal.
- Les services sans état et avec état peuvent mettre à jour la charge de tous ses réplicas secondaires ou instances.
- Les services sans état et avec état peuvent mettre à jour la charge d’un réplica ou d’une instance sur un nœud.
Il est également possible de combiner les mises à jour par partition en même temps. La combinaison des mises à jour de charge pour une partition particulière doit être spécifiée par le biais de l’objet PartitionMetricLoadDescription, qui peut contenir la liste correspondante des mises à jour de charge comme indiqué dans l’exemple ci-dessous. Les mises à jour de charge sont représentées par l’objet MetricLoadDescription, qui peut contenir la valeur de charge actuelle ou prédite pour une métrique, spécifiée par un nom de métrique.
Notes
Les valeurs de charge de métrique prédites sont actuellement une fonctionnalité en préversion. Cela permet de signaler les valeurs de charge prédites et de les utiliser du côté Service Fabric, mais cette fonctionnalité n’est pas activée actuellement.
La mise à jour de charges pour plusieurs partitions est possible avec un seul appel d’API, auquel cas la sortie contiendra une réponse par partition. Si la mise à jour de la partition n’est pas correctement appliquée pour une raison quelconque, les mises à jour de cette partition seront ignorées et le code d’erreur correspondant pour une partition ciblée est fourni :
- PartitionNotFound - L’ID de partition spécifié n’existe pas.
- ReconfigurationPending - La partition est en cours de reconfiguration.
- InvalidForStatelessServices - Une tentative de modification de la charge d’un réplica principal pour une partition appartenant à un service sans état a été effectuée.
- ReplicaDoesNotExist - Le réplica ou l’instance secondaire n’existe pas sur un nœud spécifié.
- InvalidOperation - Cela peut se produire dans deux cas : la mise à jour de la charge pour une partition qui appartient à l’application système ou la mise à jour de la charge prédite n’est pas activée.
Si certaines de ces erreurs sont retournées, vous pouvez mettre à jour l’entrée pour une partition spécifique et retenter la mise à jour dessus.
Code :
Guid partitionId = Guid.Parse("53df3d7f-5471-403b-b736-bde6ad584f42");
string metricName0 = "CustomMetricName0";
List<MetricLoadDescription> newPrimaryReplicaLoads = new List<MetricLoadDescription>()
{
new MetricLoadDescription(metricName0, 100)
};
string nodeName0 = "NodeName0";
List<MetricLoadDescription> newSpecificSecondaryReplicaLoads = new List<MetricLoadDescription>()
{
new MetricLoadDescription(metricName0, 200)
};
OperationResult<UpdatePartitionLoadResultList> updatePartitionLoadResults =
await this.FabricClient.UpdatePartitionLoadAsync(
new UpdatePartitionLoadQueryDescription
{
PartitionMetricLoadDescriptionList = new List<PartitionMetricLoadDescription>()
{
new PartitionMetricLoadDescription(
partitionId,
newPrimaryReplicaLoads,
new List<MetricLoadDescription>(),
new List<ReplicaMetricLoadDescription>()
{
new ReplicaMetricLoadDescription(nodeName0, newSpecificSecondaryReplicaLoads)
})
}
},
this.Timeout,
cancellationToken);
Dans cet exemple, vous allez effectuer une mise à jour de la dernière charge signalée pour une partition 53df3d7f-5471-403b-b736-bde6ad584f42. La charge du réplica principal d’une mesure CustomMetricName0 est mise à jour avec la valeur 100. En même temps, la charge pour la même mesure pour un réplica secondaire spécifique situé sur le nœud NodeName0 sera mise à jour avec la valeur 200.
Mise à jour de la configuration des mesures d’un service
La liste des mesures associées au service et les propriétés de ces mesures peuvent être mises à jour dynamiquement pendant que le service est en ligne. Cela permet une meilleure expérimentation et plus de flexibilité. Voici quelques exemples :
- désactivation d’une mesure avec un état incorrect pour un service particulier
- reconfiguration des poids de métriques en fonction du comportement souhaité
- activation d’une nouvelle mesure uniquement une fois que le code a déjà été déployé et validé via d’autres mécanismes
- modification de la charge par défaut pour un service en fonction de la consommation et du comportement observés
Les API principales permettant de modifier la configuration des mesures sont FabricClient.ServiceManagementClient.UpdateServiceAsync dans C# et Update-ServiceFabricService dans PowerShell. Les informations que vous spécifiez avec ces API remplacent aussitôt les informations existantes concernant les mesures de ce service.
Mélange des valeurs de charge par défaut et des rapports de charge dynamique
Vous pouvez utiliser une charge par défaut et des charges dynamiques pour le même service. Lorsqu’un service utilise à la fois une charge par défaut et des rapports de charge dynamique, la charge par défaut sert d’estimation jusqu’à ce que les rapports dynamiques arrivent. La charge par défaut est une bonne solution car Cluster Resource Manager dispose ainsi de données avec lesquelles travailler. La charge par défaut permet à Cluster Resource Manager de positionner les objets de service à un emplacement adéquat lors de leur création. Si aucune information n’est fournie pour la charge par défaut, le positionnement des services est aléatoire. Lorsque les rapports de charge arrivent plus tard, le placement aléatoire initial est souvent incorrect et Cluster Resource Manager doit alors déplacer des services.
Reprenons l’exemple précédent et voyons ce qui se passe lorsque nous ajoutons des mesures personnalisées et les rapports de charge dynamique. Dans cet exemple, nous utilisons « MemoryInMb » comme exemple de mesure.
Notes
La mémoire est une des mesures système dont Service Fabric peut gérer les ressources, et générer un rapport sur la mémoire est généralement une tâche difficile à effectuer soi-même. Vous n’êtes pas censé générer un rapport sur la consommation de mémoire ; la mémoire est utilisée ici pour vous aider à découvrir les fonctionnalités de Cluster Resource Manager.
Supposons que nous ayons initialement créé le service avec état avec la commande suivante :
PowerShell :
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("MemoryInMb,High,21,11”,"PrimaryCount,Medium,1,0”,"ReplicaCount,Low,1,1”,"Count,Low,1,1”)
Pour rappel, la syntaxe utilisée est ("MetricName, MetricWeight, PrimaryDefaultLoad, SecondaryDefaultLoad").
Voyons quelle pourrait être une disposition de cluster possible :

Informations importantes à noter :
- Les réplicas secondaires dans une partition peuvent avoir chacun leur propre charge
- Dans l’ensemble, les mesures semblent équilibrées. Pour rappel, le rapport entre la charge maximale et la charge minimale est égal à 1,75 (le nœud avec la charge la plus importante est N3, celui avec la moins importante N2, et 28/16 = 1,75).
Il reste certaines choses à expliquer :
- Quel élément a permis de déterminer qu’un rapport de 1,75 était raisonnable ou non ? Comment Cluster Resource Manager sait-il si c’est suffisant ou s’il reste d’autres actions à effectuer ?
- À quel moment l’équilibrage se produit-il ?
- Qu’est-ce que cela signifie que Memory (mémoire) était pondérée comme étant « High » (haute) ?
Poids des mesures
Il est important de pouvoir suivre les mêmes mesures pour différents services. C’est ce qui permet à Cluster Resource Manager de suivre la consommation dans le cluster, d’équilibrer la consommation entre les nœuds et de faire en sorte que les nœuds ne dépassent pas leur capacité. Cependant, les services n’accordent pas forcément la même importance à une même mesure. Par ailleurs, dans un cluster qui présente un grand nombre de mesures et de services, il se peut qu’il n’existe pas de solution parfaitement équilibrée pour toutes les mesures. Comment Cluster Resource Manager doit-il gérer ces situations ?
Les poids des mesures permettent à Cluster Resource Manager de déterminer comment équilibrer le cluster lorsqu’il n’existe aucune réponse adaptée. Les poids des mesures permettent également à Cluster Resource Manager d’équilibrer des services spécifiques différemment. Les métriques peuvent avoir quatre niveaux de pondération : zéro, faible, moyen et élevé. Une mesure avec un poids de Zero n’entre aucunement en compte dans la décision d’équilibrage des éléments. Mais sa charge contribue toujours à des aspects tels que la gestion de la capacité. Les mesures avec un poids nul sont toujours utiles et sont fréquemment utilisées dans le cadre de l’analyse des performances et du comportement d’un service. Cet article fournit de plus amples informations sur l’utilisation des mesures pour analyser et diagnostiquer vos services.
Le véritable impact des différents poids de mesure dans le cluster est que Cluster Resource Manager génère plusieurs solutions. Les poids des mesures indiquent à Cluster Resource Manager que certaines mesures sont plus importantes que d’autres. Lorsqu’il n’existe aucune solution parfaite, Cluster Resource Manager peut privilégier des solutions qui équilibrent mieux les mesures de poids supérieur. Si un service considère qu’une mesure particulière n’est pas importante, il peut trouver que l’utilisation de cette mesure cause un déséquilibre. Cela permet à un autre service d’obtenir une répartition uniforme d’une mesure importante pour lui.
Prenons pour exemple quelques rapports de charge et regardons de quelle façon les différents poids de mesure entraînent des allocations différentes dans le cluster. Dans cet exemple, nous voyons que lorsque le poids relatif des mesures est échangé, Cluster Resource Manager crée des dispositions différentes des services.
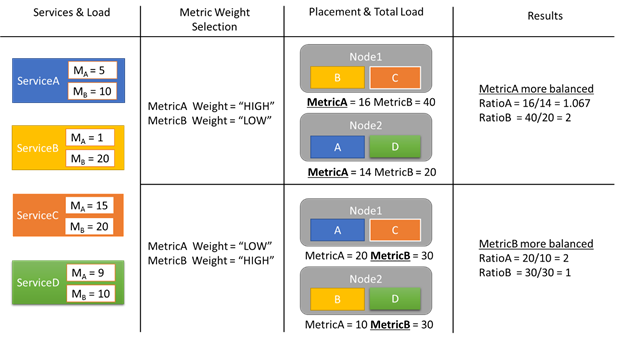
Dans cet exemple, nous avons quatre services différents qui signalent tous des valeurs différentes pour deux mesures, MetricA et MetricB. Dans un cas, tous les services définissent la mesure MetricA comme la plus importante (Weight = High) et la mesure MetricB comme relativement peu importante (Weight = Low). En effet, nous constatons que Cluster Resource Manager place les services de façon à ce que la mesure MetricA soit mieux équilibrée que la mesure MetricB. « Mieux équilibrée » signifie que la mesure MetricA présente un écart type plus faible que celui de la mesure MetricB. Dans le deuxième cas, nous inversons les poids des mesures. Cluster Resource Manager échange alors les services A et B afin de proposer une allocation où la mesure MetricB est mieux équilibrée que la mesure MetricA.
Notes
Les poids des mesures déterminent la façon dont Cluster Resource Manager doit effectuer l’équilibrage, mais pas le moment où cet équilibrage doit se produire. Pour plus d’informations sur l’équilibrage, consultez cet article
Poids globaux des mesures
Supposons que le service ServiceA définit la mesure MetricA avec un poids élevé (High) et que le service ServiceB définit le poids de la mesure MetricA avec un poids faible (Low) ou nul (Zero). Quel est le poids réel qui sera utilisé ?
Plusieurs poids sont suivis pour chaque mesure. Le premier poids est celui qui est défini pour la mesure lorsque le service est créé. L’autre poids est un poids global, automatiquement calculé. Cluster Resource Manager utilise ces deux poids pour calculer les scores des solutions. Il est important de tenir compte de ces deux poids. Cluster Resource Manager peut ainsi équilibrer chaque service en fonction de ses propres priorités et également s’assurer que le cluster dans son ensemble est correctement alloué.
Que se passerait-il si Cluster Resource Manager n’accordait aucune importance à l’équilibre global et local ? Eh bien, il est facile de créer des solutions qui sont globalement équilibrées mais qui entraînent un mauvais équilibrage des ressources pour des services individuels. Dans l’exemple suivant, examinons un service configuré uniquement avec les mesures par défaut, et observons ce qui se passe lorsque seul l’équilibre global est pris en considération :
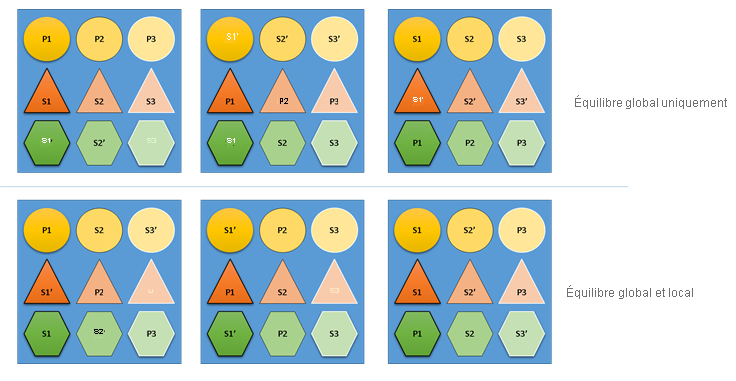
Dans l’exemple du haut, basé uniquement sur un équilibre global, le cluster dans son ensemble est effectivement bien équilibré. Tous les nœuds présentent le même nombre de réplicas principaux et le même nombre total de réplicas. Cependant, si on examine l’impact réel de cette allocation, la situation n’est pas si bonne : la perte d’un nœud a un impact disproportionné sur une charge de travail spécifique, car tous ses réplicas principaux sont également perdus. Par exemple, en cas de défaillance du premier nœud, les trois réplicas principaux des trois différentes partitions du service Circle seraient tous perdus. À l’inverse, les partitions des services Triangle et Hexagon perdent un réplica. Cela n’entraîne aucune interruption de service, hormis le fait que le réplica devra être récupéré.
Dans l’exemple du bas, Cluster Resource Manager a réparti les réplicas en fonction à la fois de l’équilibre global et de l’équilibre du service. Lorsque Cluster Resource Manager calcule le score de la solution, il donne la majorité du poids à la solution globale et une partie (configurable) aux services individuels. L’équilibre global d’une mesure est calculé en fonction de la moyenne des poids des mesures pour chaque service. Chaque service est équilibré selon ses propres poids de mesure. Cela permet de s’assurer que les services sont équilibrés entre eux en fonction de leurs propres besoins. Par conséquent, en cas de défaillance du même premier nœud, la défaillance est répartie sur toutes les partitions de tous les services. L’impact est le même pour chacun d’eux.
Étapes suivantes
- Pour plus d’informations sur la configuration des services, consultez la rubrique En savoir plus sur la configuration des services (service-fabric-cluster-resource-manager-configure-services.md).
- La définition des mesures de défragmentation est une façon de consolider la charge sur les nœuds au lieu de la répartir. Pour savoir comment configurer la défragmentation, reportez-vous à cet article
- Pour en savoir plus sur la façon dont Cluster Resource Manager gère et équilibre la charge du cluster, consultez l’article sur l’équilibrage de la charge
- Commencez au début pour obtenir une présentation de Service Fabric Cluster Resource Manager
- Le coût du mouvement est une façon de signaler à Cluster Resource Manager que certains services sont plus coûteux à déplacer que d’autres. Pour en savoir plus sur le coût du déplacement, reportez-vous à cet article