Résoudre les problèmes liés aux requêtes Azure Stream Analytics
Cet article décrit les problèmes courants liés au développement de requêtes Stream Analytics et les procédures à suivre pour les résoudre.
Cet article décrit les problèmes courants liés au développement de requêtes Azure Stream Analytics, ainsi que la façon de résoudre les problèmes de requêtes et de corriger les problèmes. De nombreuses étapes de résolution des problèmes nécessitent que les journaux de ressources soient activés pour votre travail Stream Analytics. Si les journaux de ressources ne sont pas activés, consultez la section Résoudre les problèmes liés à Azure Stream Analytics à l’aide des journaux de ressources.
La requête ne produit pas la sortie attendue
Examinez les erreurs en effectuant un test local :
- Sur le Portail Azure, sous l’onglet Requête, sélectionnez Test. Utilisez les exemples de données téléchargés pour tester la requête. Examinez les éventuelles erreurs et tentez de les corriger.
- Vous pouvez également tester votre requête localement à l’aide des outils Azure Stream Analytics pour Visual Studio ou Visual Studio Code.
Déboguer des requêtes étape par étape localement à l’aide du diagramme de travail dans les outils Azure Stream Analytics pour Visual Studio Code. Le diagramme de travail montre la façon dont les données circulent des sources d’entrée (Event Hub, IoT Hub, etc.), via plusieurs étapes de requête et, enfin, jusqu’aux récepteurs de sortie. Chaque étape de la requête est mappée à un jeu de résultats temporaire défini dans le script à l’aide de l’instruction WITH. Vous pouvez afficher les données et les métriques dans chaque jeu de résultats intermédiaire pour trouver la source du problème.
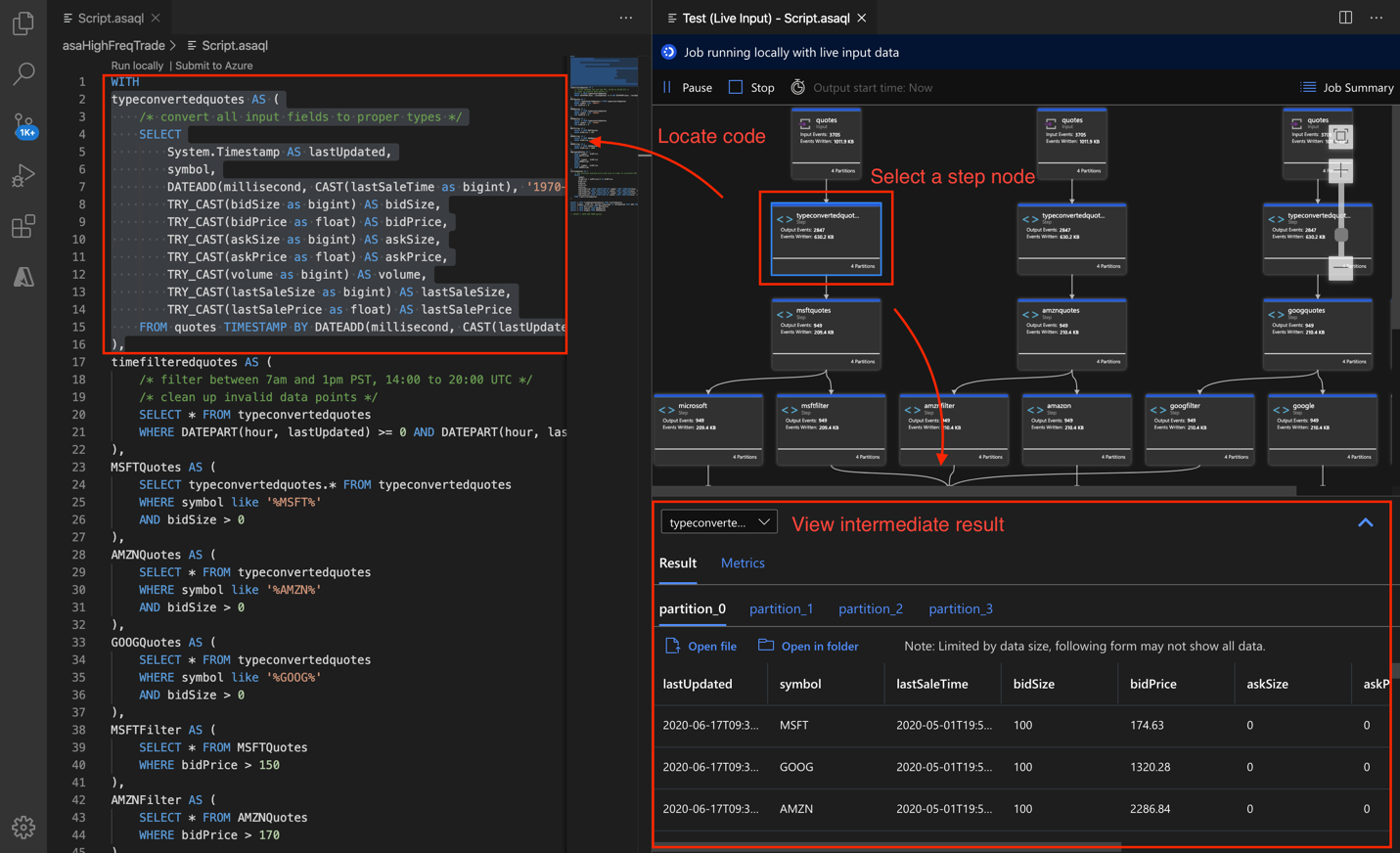
Si vous utilisez l’objet Timestamp By, assurez-vous que les événements présentent des horodatages postérieurs à l’heure de début du travail.
Éliminez les pièges les plus courants, comme par exemple :
- Une clause WHERE dans la requête a filtré l’ensemble des événements, ce qui empêche la génération des sorties.
- Une fonction CAST échoue, ce qui provoque l’échec du travail. Pour éviter les échecs de conversion de type, utilisez plutôt TRY_CAST.
- Lorsque vous utilisez des fonctions de fenêtre, attendez la durée totale de la fenêtre pour obtenir une sortie.
- L’horodatage des événements est antérieur à l’heure de début du travail, provoquant l’abandon des événements.
- Les conditions JOIN ne correspondent pas. S’il n’y a aucune correspondance, aucune sortie ne pourra être produite.
Vérifiez que les stratégies d’ordre des événements sont configurées comme prévu. Accédez à Paramètres et sélectionnez Ordre des événements. La stratégie n’est pas appliquée lorsque vous utilisez le bouton Test pour tester la requête. C’est une des différences entre le test en navigateur et l’exécution réelle du travail.
Déboguez à l’aide des journaux d’activité et de ressources :
- Utilisez les journaux d’activité pour identifier et déboguer les erreurs.
- Utilisez les journaux de ressources pour identifier et déboguer les erreurs.
L’utilisation des ressources est élevée
Veillez à tirer parti de la parallélisation dans Azure Stream Analytics. Vous pouvez apprendre à mettre à l’échelle des travaux Stream Analytics avec parallélisation des requêtes en configurant des partitions d’entrée et en réglant la définition des requêtes Analytics.
Si l’utilisation des ressources est régulièrement supérieure à 80 %, le délai en filigrane augmente; tout comme le nombre d’événements retardés. Dans ce cas, vous pouvez d’augmenter les unités de streaming. Une utilisation intensive indique que la tâche atteint une limite proche de la quantité maximale de ressources allouées.
Déboguer les requêtes progressivement
Lors du traitement de données en temps réel, savoir à quoi ressemblent les données au milieu de la requête peut être utile. Vous pouvez le voir à l’aide du diagramme de travail dans Visual Studio. Si vous n’avez pas Visual Studio, vous pouvez prendre des mesures supplémentaires pour générer des données intermédiaires.
Étant donné que les entrées ou les étapes d’un travail Azure Stream Analytics peuvent être lues plusieurs fois, vous pouvez écrire des instructions SELECT INTO supplémentaires. Cela génère des données intermédiaires dans le stockage et vous permet d’inspecter l’exactitude des données, tout comme le font les variables espionnes lorsque vous déboguez un programme.
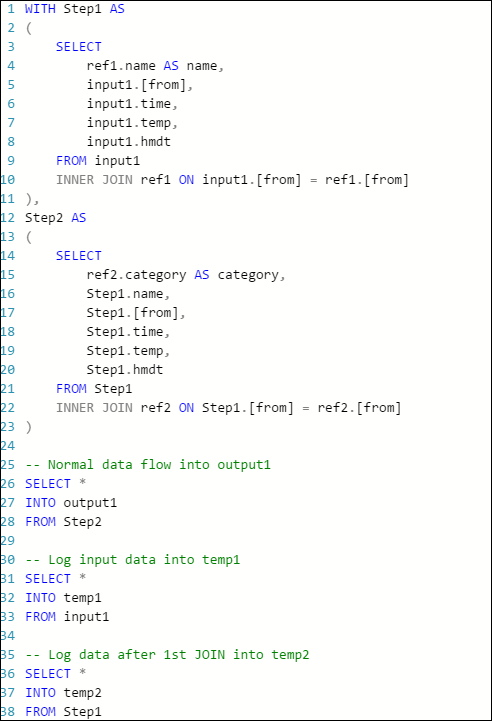
L’exemple de requête suivant dans un travail Azure Stream Analytics a un flux d’entrée, deux entrées de données de référence et une sortie pour Stockage Table Azure. La requête joint les données du Event Hub et deux objets blob de référence pour obtenir les informations de nom et de catégorie :
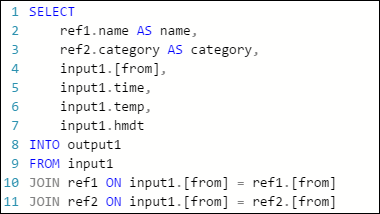
Notez que le travail est en cours d’exécution, mais aucun événement n’est produit dans la sortie. Dans la vignette Surveillance, illustrée ici, vous pouvez voir que l’entrée génère des données, mais vous ne savez pas quelle étape de JOIN a causé la suppression de tous les événements.
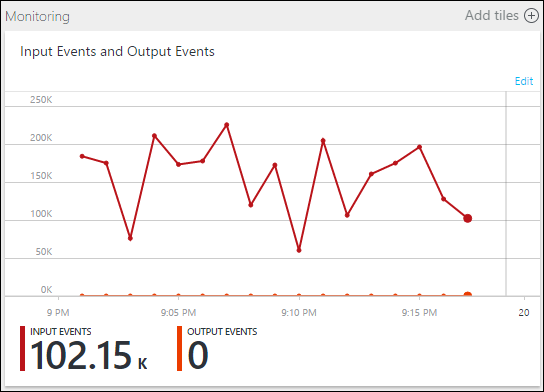
Dans ce cas, vous pouvez ajouter quelques instructions SELECT INTO supplémentaires pour « journaliser » les résultats JOIN intermédiaires et les données lues à partir de l’entrée.
Dans cet exemple, nous avons ajouté deux nouvelles « sorties temporaires ». Il peut s’agir du récepteur de votre choix. Ici, nous utilisons Stockage Azure comme exemple :
Vous pouvez ensuite réécrire la requête comme suit :
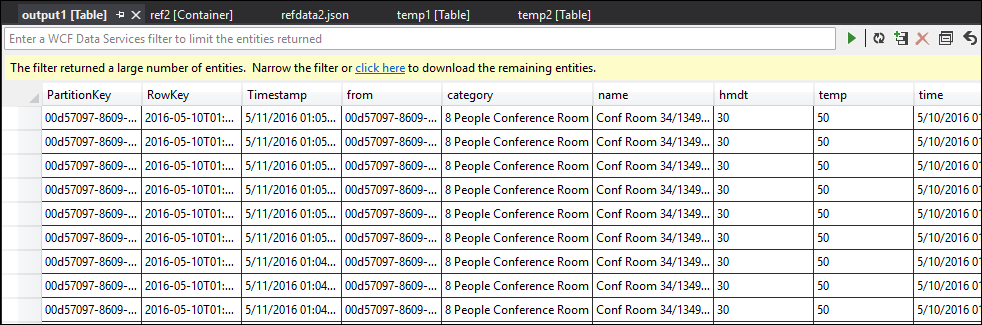
À présent, relancez le travail et laissez-le s’exécuter pendant quelques minutes. Ensuite, interrogez temp1 et temp2 avec Visual Studio Cloud Explorer pour produire les tables suivantes :
temp1 table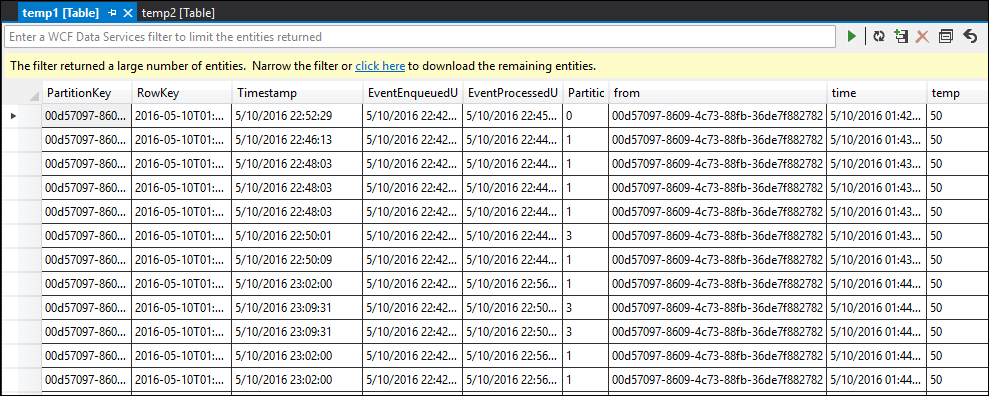
temp2 table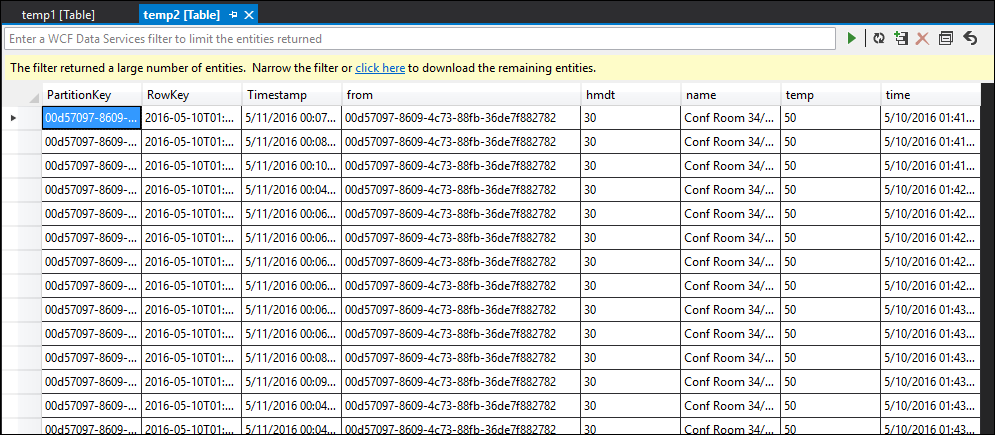
Comme vous pouvez le voir, temp1 et temp2 présentent tous deux des données, et la colonne de nom est remplie correctement dans temp2. Toutefois, étant donné qu’il n’y a toujours aucune donnée dans la sortie, quelque chose ne va pas :
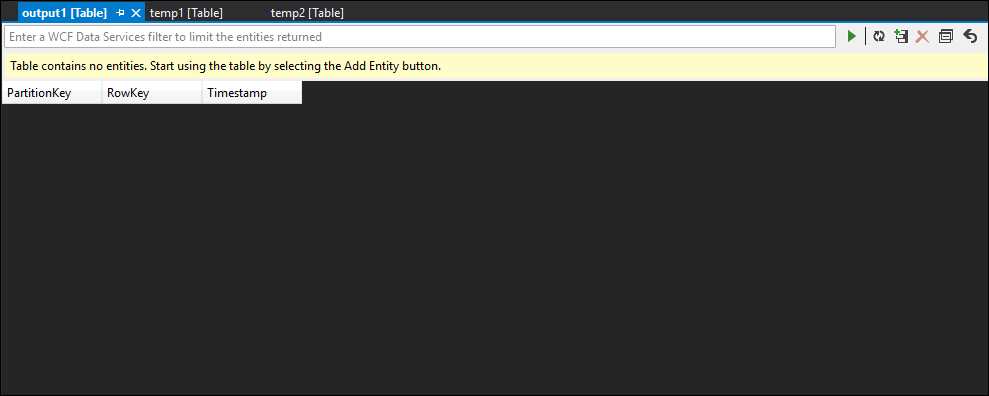
En échantillonnant les données, vous pouvez être presque certain que le problème concerne le deuxième JOIN. Vous pouvez télécharger les données de référence à partir de l’objet blob et jeter un coup de œil :
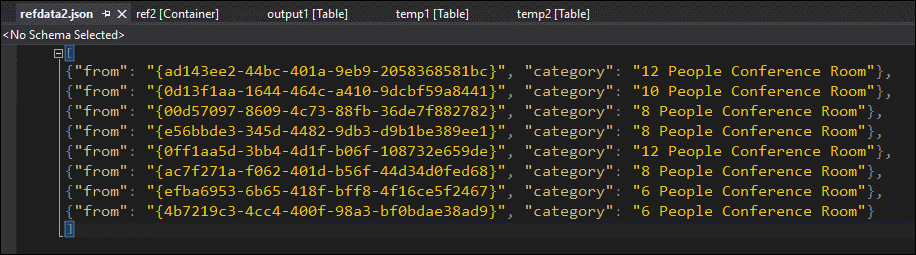
Comme vous pouvez le voir, le format du GUID dans ces données de référence est différent du format de la colonne [from] dans temp2. C’est pourquoi les données ne sont pas arrivées dans output1 comme prévu.
Vous pouvez corriger le format de données, les télécharger pour référencer des objets blob, puis réessayer :
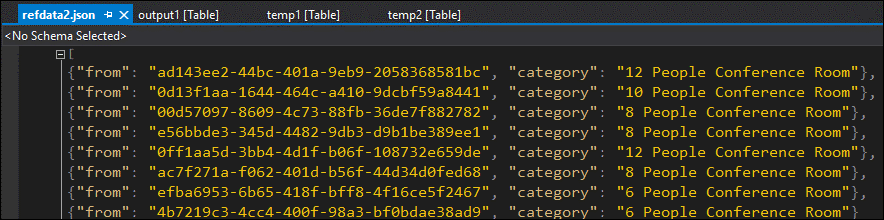
Cette fois, les données dans la sortie sont mises en forme et remplies comme prévu.
Obtenir de l’aide
Pour obtenir de l’aide supplémentaire, essayez notre page de questions Microsoft Q&A pour Azure Stream Analytics.