Présentation de l’ingestion des données Azure Synapse Data Explorer (préversion)
L’ingestion des données est le processus qui consiste à charger des enregistrements de données d’une ou plusieurs sources pour importer des données dans une table du pool Azure Synapse Data Explorer. Une fois ingérées, les données sont disponibles pour les requêtes.
Le service de gestion des données Azure Synapse Data Explorer, qui est responsable de l’ingestion des données, implémente le processus suivant :
- Extrait des données par lot ou en streaming d’une source externe et lit les demandes d’une file d’attente Azure.
- Les données traitées par lot à destination de la même base de données et de la même table sont optimisées pour un débit d’ingestion élevé.
- Les données initiales sont validées et le format est converti si nécessaire.
- Parmi les autres tâches de manipulation des données, citons la mise en correspondance des schémas, l’organisation, l’indexation, l’encodage et la compression des données.
- Les données sont conservées dans le stockage en fonction d’une stratégie de conservation définie.
- Les données ingérées sont validées dans le moteur, où elles sont disponibles pour la requête.
Formats de données pris en charge, propriétés et autorisations
Propriétés d’ingestion : propriétés qui affectent la façon dont les données sont ingérées (par exemple : étiquetage, mappage, heure de création).
Autorisations : pour ingérer des données, le processus nécessite des autorisations de niveau Ingéreur de base de données. D’autres actions, comme l’exécution d’une requête, peuvent nécessiter des autorisations d’administrateur de base de données, d’utilisateur de base de données ou d’administrateur de table.
Ingestions par lot ou en streaming
L’ingestion par lot, qui traite les données par lot, est optimisée pour un débit d’ingestion élevé. Cette méthode d’ingestion est la plus performante et donc recommandée. Les données sont traitées par lot en fonction des propriétés d’ingestion. De petits lots de données sont fusionnés et optimisés pour des résultats de requête rapides. La stratégie d’ingestion par lot peut être définie sur des bases de données ou des tables. Par défaut, les valeurs maximales de traitement par lot sont les suivantes : 5 minutes, 1000 éléments ou une taille totale de 1 Go. La taille maximale des données pour une commande d’ingestion par lots est de 4 Go.
L’ingestion en streaming ingère les données en continu à partir d’une source de streaming. L’ingestion en streaming permet une latence en quasi temps réel pour les petits jeux de données par table. Les données sont initialement ingérées dans un rowstore, puis déplacées dans des étendues columnstore.
Méthodes d’ingestion et outils
Azure Synapse Data Explorer prend en charge plusieurs méthodes d’ingestion, chacune avec ses propres scénarios cibles. Parmi ces méthodes, citons des outils d’ingestion, des connecteurs et des plug-ins pour divers services, des pipelines gérés, l’ingestion programmatique à l’aide de kits SDK et l’accès direct à l’ingestion.
Ingestion à l’aide de pipelines gérés
Pour les organisations qui souhaitent confier la gestion (limitation, nouvelles tentatives, analyses, alertes, etc.) à un service externe, l’utilisation d’un connecteur est probablement la solution la plus appropriée. L’ingestion en file d’attente convient aux grands volumes de données. Azure Synapse Data Explorer prend en charge les pipelines Azure suivants :
- Event Hub : pipeline qui transfère des événements de services vers Azure Synapse Data Explorer. Pour plus d’informations, consultez Ingérer des données d’un Event Hub dans Azure Synapse Data Explorer.
- Pipelines Synapse : un service complètement managé d’intégration de données pour les charges de travail analytiques dans Pipelines Synapse se connecte à plus de 90 sources prises en charge pour assurer un transfert de données efficace et résilient. Pipelines Synapse prépare, transforme et enrichit les données pour fournir des insights qui peuvent être supervisés de différentes façons. Ce service peut apporter une solution ponctuelle, s’inscrire dans une chronologie périodique ou être déclenché par des événements spécifiques.
Ingestion programmatique à l’aide de kits SDK
Azure Synapse Data Explorer fournit des Kits de développement logiciel (SDK) qui peuvent être utilisés pour l’ingestion de données et les requêtes. L’ingestion par programmation est optimisée afin de réduire les coûts d’ingestion, grâce à la réduction des transactions de stockage pendant et après le processus d’ingestion.
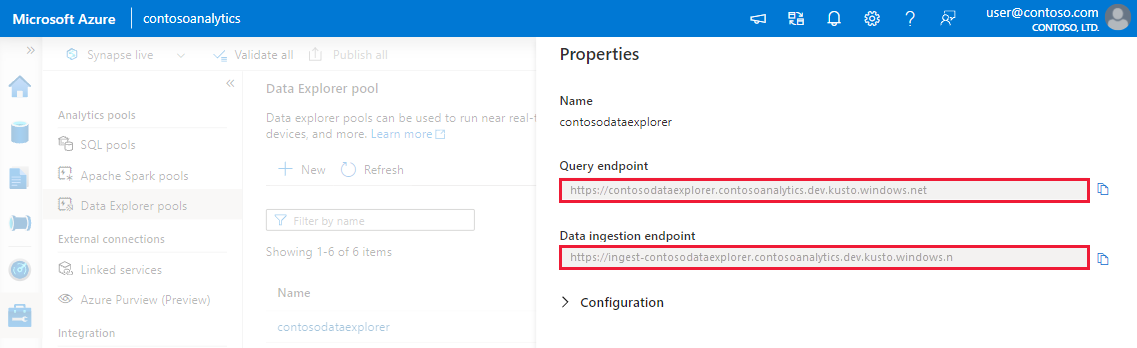
Avant de commencer, procédez comme suit pour obtenir les points de terminaison du pool Data Explorer pour la configuration de l’ingestion programmatique.
Dans Synapse Studio, dans le volet de gauche, sélectionnez Gérer>Pools Data Explorer.
Sélectionnez le pool Data Explorer à utiliser pour voir ses détails.
Notez les points de terminaison de requête et d’ingestion de données. Utilisez le point de terminaison de requête comme cluster pour la configuration des connexions à votre pool Data Explorer. Lors de la configuration des kits de développement logiciel (SDK) pour l’ingestion des données, utilisez le point de terminaison d’ingestion des données.
Kits SDK et projets open source disponibles
Outils
- Ingestion en un clic : vous permet d’ingérer rapidement des données en créant et en ajustant des tables à partir d’un large éventail de types sources. L’ingestion en un clic suggère automatiquement des tables et des structures de mappage en fonction de la source de données dans Azure Synapse Data Explorer. L’ingestion en un clic peut constituer une méthode d’ingestion ponctuelle. Elle peut aussi servir à définir l’ingestion continue, par le biais d’Event Grid, sur le conteneur dans lequel les données ont été ingérées.
Commandes de contrôle d’ingestion KQL
Plusieurs méthodes faisant appel à des commandes KQL (Kusto Query Language) permettent d’ingérer directement des données dans le moteur. Étant donné que cette méthode ignore les services Gestion des données, elle ne convient qu’à l’exploration et au prototypage. N’utilisez pas cette méthode dans les scénarios de production ou ceux impliquant de grands volumes.
Ingestion Inline : une commande de contrôle .ingest inline est envoyée au moteur, les données à ingérer étant intégrées au texte de la commande. Cette méthode est destinée à des fins de tests improvisés.
Ingestion à partir d’une requête : une commande de contrôle .set, .append, .set-or-append ou .set-or-replace est envoyée au moteur, les données étant spécifiées indirectement comme résultats d’une requête ou d’une commande.
Ingestion à partir du stockage - tirage (pull) : Une commande de contrôle .ingest into est envoyée au moteur, les données étant stockées dans un stockage externe (par exemple, Stockage Blob Azure) accessible par le moteur et vers lequel la commande pointe.
Pour obtenir un exemple d’utilisation des commandes de contrôle d’ingestion, consultez Analyser à l’aide d’Azure Data Explorer.
Processus d’ingestion
Une fois que vous avez choisi la méthode d’ingestion la mieux adaptée à vos besoins, effectuez les étapes suivantes :
Définir la stratégie de conservation
Les données ingérées dans une table dans Azure Synapse Data Explorer sont soumises à la stratégie de rétention en vigueur de la table. À moins d’être explicitement définie sur une table, la stratégie de conservation effective découle de la stratégie de conservation de la base de données. La conservation à chaud est une fonction de la taille de cluster et de votre stratégie de conservation. Le fait d’ingérer plus de données que d’espace disponible forcera la conservation à froid des premières données entrées.
Vérifiez que la stratégie de conservation de la base de données est adaptée à vos besoins. Si ce n’est pas le cas, remplacez-la explicitement au niveau de la table. Pour plus d’informations, consultez Stratégie de conservation.
Création d'une table
Avant de pouvoir ingérer des données, vous devez créer une table. Utilisez l’une des options suivantes :
Créez une table avec une commande. Pour un exemple d’utilisation de la commande « create a table », consultez Analyser à l’aide d’Azure Data Explorer.
Créez une table à l’aide de l’ingestion en un clic.
Notes
Si un enregistrement est incomplet ou un champ ne peut pas être analysé en tant que type de données requis, les colonnes correspondantes de la table sont remplies avec des valeurs null.
Créer un mappage de schéma
Le mappage de schéma permet de lier des champs de données sources à des colonnes de table de destination. Le mappage vous permet de regrouper dans une même table les données de différentes sources en fonction des attributs définis. Différents types de mappages sont pris en charge, à la fois orientés ligne (CSV, JSON et AVRO) et orientés colonne (Parquet). Dans la plupart des méthodes, des mappages peuvent également être précréés sur la table et référencés à partir du paramètre de commande ingest.
Définir une stratégie de mise à jour (facultatif)
Certains mappages de format de données (Parquet, JSON et Avro) prennent en charge des transformations simples et utiles au moment de l’ingestion. Si le scénario nécessite un traitement plus complexe au moment de l’ingestion, utilisez la stratégie de mise à jour. Celle-ci permet d’effectuer un traitement léger au moyen de commandes KQL. La stratégie de mise à jour exécute automatiquement les extractions et les transformations sur les données ingérées de la table d’origine, puis ingère les données résultantes dans une ou plusieurs tables de destination. Définissez votre stratégie de mise à jour.