Réduire les problèmes SQL pour les migrations Oracle
Cet article est le premier d’une série de sept qui fournit des conseils sur la migration d’Oracle vers Azure Synapse Analytics. L’objectif de cet article est de fournir les meilleures pratiques pour réduire les problèmes de SQL.
Vue d’ensemble
Caractéristiques des environnements Oracle
Le produit de base de données initial d’Oracle, publié en 1979, était une base de données relationnelle SQL commerciale pour les applications OLTP (On-Line Transaction Processing), avec des taux de transaction beaucoup plus faibles qu’aujourd’hui. Depuis cette version initiale, l’environnement Oracle a évolué jusqu’à devenir beaucoup plus complexe et englober de nombreuses fonctionnalités. Ces fonctionnalités incluent les architectures client-serveur, les bases de données distribuées, le traitement parallèle, l’analytique données, la haute disponibilité, l’entreposage de données, les techniques de données en mémoire et la prise en charge des instances cloud.
Conseil
Oracle a lancé le concept d’« appliance d’entrepôt de données » au début des années 2000.
En raison du coût et de la complexité de la maintenance et de la mise à niveau des environnements Oracle locaux hérités, de nombreux utilisateurs Oracle souhaitent tirer parti des innovations fournies par les environnements cloud. Les environnements cloud modernes, tels que le cloud, IaaS et PaaS, vous permettent de déléguer des tâches telles que la maintenance de l’infrastructure et le développement de plateforme au fournisseur cloud.
De nombreux entrepôts de données qui prennent en charge les requêtes SQL analytiques complexes sur de grands volumes de données utilisent des technologies Oracle. Ces entrepôts de données ont généralement un modèle de données dimensionnel, tel que des schémas en étoile ou en flocon, et utilisent des datamarts pour chaque service.
Conseil
De nombreuses installations Oracle existantes sont des entrepôts de données qui utilisent un modèle de données dimensionnel.
La combinaison de modèles de données SQL et dimensionnels dans Oracle simplifie la migration vers Azure Synapse, car les concepts de modèles de données de base et SQL sont transférables. Microsoft vous recommande de déplacer votre modèle de données existant tel quel vers Azure afin de réduire les risques, les efforts et le temps de migration. Bien que votre plan de migration puisse inclure une modification du modèle de données sous-jacent, tel qu’un déplacement d’un modèle Inmon vers un coffre de données, il est judicieux d’effectuer initialement une migration telle quelle. Après la migration initiale, vous pouvez apporter des modifications dans l’environnement cloud Azure pour tirer parti de ses performances, de sa scalabilité élastique, de ses fonctionnalités intégrées et de ses avantages en matière de coûts.
Bien que le langage SQL soit normalisé, les fournisseurs implémentent parfois des extensions propriétaires. Par conséquent, vous pouvez observer des différences SQL pendant la migration qui nécessitent des solutions de contournement dans Azure Synapse.
Utiliser les installations Azure pour implémenter une migration basée sur les métadonnées
Vous pouvez automatiser et orchestrer le processus de migration en utilisant les fonctionnalités de l’environnement Azure. Cette approche permet de réduire l’impact sur les performances dans l’environnement Oracle existant, qui est peut-être déjà près de sa pleine capacité.
Azure Data Factory est un service d’intégration de données basé sur le cloud qui vous permet de créer des flux de travail orientés données dans le cloud pour orchestrer et automatiser le déplacement des données et la transformation des données. Vous pouvez utiliser Azure Data Factory pour créer et planifier des workflows pilotés par les données (pipelines) qui ingèrent des données provenant de différents magasins de données. Data Factory peut traiter et transformer les données à l’aide de services de calcul tels qu’Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics et Azure Machine Learning.
Azure inclut également Azure Database Migration Services pour vous aider à planifier et à effectuer une migration à partir d’environnements tels qu’Oracle. SQL Server Migration Assistant (SSMA) pour Oracle peut automatiser la migration de bases de données Oracle, notamment dans certains cas des fonctions et du code procédural.
Conseil
Automatisez le processus de migration à l’aide des fonctionnalités Azure Data Factory.
Lorsque vous envisagez d’utiliser des installations Azure, telles que Data Factory, pour gérer le processus de migration, créez au préalable des métadonnées qui listent toutes les tables de données à migrer et leur emplacement.
Différences DDL SQL entre Oracle et Azure Synapse
La norme ANSI SQL définit la syntaxe de base pour les commandes DDL (Data Definition Language). Certaines commandes DDL, telles que CREATE TABLE et CREATE VIEW, sont communes à Oracle et Azure Synapse, mais ont été étendues de manière à fournir des fonctionnalités propres à l’implémentation telles que des options d’indexation, de distribution des tables et de partitionnement.
Conseil
Les commandes SQL DDL CREATE TABLE et CREATE VIEW disposent d’éléments principaux standard, mais sont également utilisés pour définir des options spécifiques à l’implémentation.
Les sections suivantes traitent des options propres à Oracle qui doivent être prises en compte lors d’une migration vers Azure Synapse.
Considérations relatives aux tables/vues
Lorsque vous migrez des tables entre différents environnements, seules les données brutes et les métadonnées qui les décrivent physiquement sont migrées. Les autres éléments de base de données du système source, tels que les index et les fichiers journaux, ne sont généralement pas migrés, car ils peuvent être inutiles ou implémentés différemment dans le nouvel environnement. Par exemple, l’option TEMPORARY dans la syntaxe CREATE TABLE d’Oracle équivaut à préfixer un nom de table avec un caractère # dans Azure Synapse.
Les optimisations des performances dans l’environnement source, telles que les index, indiquent où vous pouvez ajouter l’optimisation des performances dans le nouvel environnement cible. Par exemple, si des index bitmap sont fréquemment utilisés dans des requêtes dans l’environnement Oracle source, cela suggère qu’un index non-cluster doit être créé dans Azure Synapse. D’autres techniques d’optimisation des performances natives, telles que la réplication de table, peuvent être plus applicables qu’une création d’index « à l’identique ». SSMA pour Oracle peut fournir des recommandations de migration pour la distribution et l’indexation des tables.
Conseil
Les index existants marquent les candidats à l’indexation dans l’entrepôt migré.
Les définitions de vue SQL contiennent des instructions DML (Data Manipulation Language) SQL qui définissent la vue, généralement avec une ou plusieurs instructions SELECT. Lorsque vous migrez des instructions CREATE VIEW, prenez en compte les différences DML entre Oracle et Azure Synapse.
Types d’objets de base de données Oracle non pris en charge
Les fonctionnalités propres à Oracle peuvent souvent être remplacées par des fonctionnalités Azure Synapse. Toutefois, certains objets de base de données Oracle ne sont pas directement pris en charge dans Azure Synapse. La liste suivante d’objets de base de données Oracle non pris en charge explique comment obtenir une fonctionnalité équivalente dans Azure Synapse :
Options d’indexation : dans Oracle, plusieurs options d’indexation, telles que les index bitmap, les index basés sur des fonctions et les index de domaine, n’ont pas d’équivalent direct dans Azure Synapse. Bien qu’Azure Synapse ne prenne pas en charge ces types d’index, vous pouvez obtenir une réduction similaire des E/S de disque en utilisant des types d’index définis par l’utilisateur et/ou un partitionnement. La réduction des E/S de disque améliore les performances des requêtes.
Vous pouvez déterminer les colonnes indexées et leur type d’index en interrogeant des tables et affichages catalogue système, tels que
ALL_INDEXES,DBA_INDEXES,USER_INDEXESetDBA_IND_COL. Vous pouvez également interroger les vuesdba_index_usageouv$object_usagelorsque le monitoring est activé.Les fonctionnalités Azure Synapse, telles que le traitement de requête parallèle et la mise en cache en mémoire des données et des résultats, font que les applications de l’entrepôt de données auront probablement besoin de moins d’index pour atteindre d’excellents objectifs de performances.
Tables cluster : les tables Oracle peuvent être organisées afin que les lignes de table fréquemment consultées ensemble (sur la base d’une valeur commune) soient stockées physiquement ensemble. Cette stratégie réduit les E/S de disque lorsque les données sont récupérées. Oracle propose également une option hash-cluster pour les tables individuelles, qui applique une valeur de hachage à la clé de cluster et stocke physiquement toutes les lignes qui ont la même valeur de hachage.
Dans Azure Synapse, un résultat similaire peut être obtenu en partitionnant et/ou en utilisant d’autres index.
Vues matérialisées : Oracle prend en charge les vues matérialisées et recommande une ou plusieurs d’entre elles pour les grandes tables comportant de nombreuses colonnes si quelques colonnes seulement sont régulièrement utilisées dans les requêtes. Les vues matérialisées sont automatiquement actualisées par le système lorsque des données dans la table de base sont mises à jour.
En 2019, Microsoft a annoncé qu’Azure Synapse prendrait en charge les vues matérialisées avec les mêmes fonctions que dans Oracle. Les vues matérialisées sont désormais une fonctionnalité d’évaluation dans Azure Synapse.
Déclencheurs dans la base de données : dans Oracle, un déclencheur peut être configuré pour s’exécuter automatiquement lorsqu’un événement de déclenchement se produit. Les événements de déclenchement peuvent être :
Une instruction DML, comme
INSERT,UPDATEouDELETE, s’exécute. Si vous avez défini un déclencheur qui se déclenche avant une instructionINSERTsur une table client, le déclencheur se déclenchera une fois avant qu’une nouvelle ligne soit insérée dans la tableUne instruction DDL, comme
CREATEouALTER, s’exécute. Cet événement déclencheur est souvent utilisé pour enregistrer les modifications de schéma à des fins d’auditUn événement système, tel que le démarrage ou l’arrêt de la base de données Oracle
Un événement utilisateur tel que la connexion ou la déconnexion
Azure Synapse ne prend pas en charge les déclencheurs de base de données Oracle. Toutefois, vous pouvez obtenir des fonctionnalités équivalentes à l’aide de Data Factory, bien que cela vous oblige à refactoriser les processus qui utilisent des déclencheurs.
Synonymes : Oracle prend en charge la définition de synonymes en tant que noms alternatifs pour plusieurs types d’objets de base de données. Ces types incluent les tables, les vues, les séquences, les procédures, les fonctions stockées, les packages, les vues matérialisées, les objets de schéma de classe Java, les objets définis par l’utilisateur ou autres synonymes.
Azure Synapse ne prend pas en charge la définition de synonymes. Toutefois, si dans Oracle un synonyme fait référence à une table ou à une vue, vous pouvez définir une vue dans Azure Synapse pour qu’elle corresponde au nom alternatif. Si un synonyme dans Oracle fait référence à une fonction ou à une procédure stockée, vous pouvez remplacer le synonyme dans Azure Synapse par une autre fonction ou procédure stockée qui appelle la cible.
Types définis par l’utilisateur : Oracle prend en charge les objets définis par l’utilisateur qui peuvent contenir une série de champs, chacun avec sa propre définition et ses propres valeurs par défaut. Ces objets peuvent ensuite être référencés dans une définition de table de la même façon que les types de données intégrés comme
NUMBERouVARCHAR.Azure Synapse ne prend pas en charge les types définis par l’utilisateur. Si les données que vous devez déplacer incluent des types de données définis par l’utilisateur, vous devez soit les « aplatir » dans une définition de table conventionnelle, soit, s’il s’agit de tableaux de données, les normaliser dans une table distincte.
Génération de DDL SQL
Vous pouvez modifier les scripts Oracle CREATE TABLE et CREATE VIEW existants pour obtenir les mêmes définitions dans Azure Synapse. Pour ce faire, vous devrez peut-être utiliser des types de données modifiés et supprimer ou modifier des clauses propres à Oracle, telles que TABLESPACE.
Conseil
Utilisez les métadonnées Oracle existantes pour automatiser la génération de DDL CREATE TABLE et CREATE VIEW pour Azure Synapse.
Dans l’environnement Oracle, les tables de catalogue système spécifient la définition actuelle de la table/vue. Contrairement à la documentation gérée par l’utilisateur, les informations du catalogue système sont toujours complètes et synchronisées avec les définitions de table actuelles. Vous pouvez accéder aux informations du catalogue système à l’aide d’utilitaires tels qu’Oracle SQL Developer. Oracle SQL Developer peut générer des instructions DDL CREATE TABLE que vous pouvez modifier pour qu’elles s’appliquent à des tables équivalentes dans Azure Synapse, comme illustré dans la capture d’écran suivante.

Oracle SQL Developer génère l’instruction CREATE TABLE suivante, qui contient des clauses propres à Oracle que vous devez supprimer. Mappez tous les types de données non pris en charge avant d’exécuter votre instruction CREATE TABLE modifiée sur Azure Synapse.
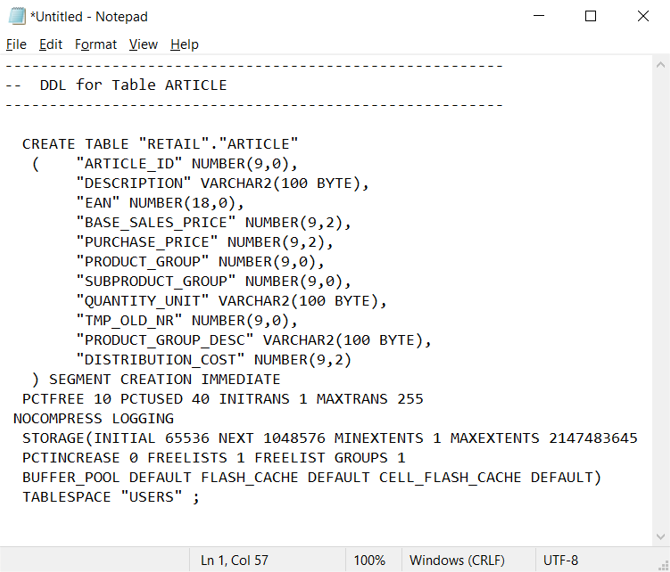
Vous pouvez également générer automatiquement des instructions CREATE TABLE à partir des informations contenues dans les tables de catalogue Oracle à l’aide de requêtes SQL, de SSMA ou d’outils de migration tiers. Cette approche est la plus rapide et la plus cohérente pour générer des instructions CREATE TABLE pour de nombreuses tables.
Conseil
Des outils et services tiers peuvent automatiser des tâches de mappage de données.
Des fournisseurs tiers proposent des outils et services permettant d’automatiser la migration, dont le mappage de type de données. Si un outil ETL tiers est déjà utilisé dans l’environnement Oracle, utilisez cet outil pour implémenter toutes les transformations de données nécessaires.
Différences DML SQL entre Oracle et Azure Synapse
La norme ANSI SQL définit la syntaxe de base pour les commandes DML telles que SELECT, INSERT, UPDATE et DELETE. Bien qu’Oracle et Azure Synapse prennent en charge les commandes DDL, dans certains cas ils implémentent la même commande différemment.
Conseil
Les commandes DML SQL standard SELECT, INSERT et UPDATE peuvent avoir des options de syntaxe supplémentaires dans différents environnements de base de données.
Les sections suivantes traitent des commandes DML propres à Oracle qui doivent être prises en compte lors d’une migration vers Azure Synapse.
Différences de syntaxe SQL DML
Il existe des différences de syntaxe SQL DML entre Oracle SQL et Azure Synapse T-SQL :
Table
DUAL: Oracle a une table système nomméeDUALcomposée d’exactement d’une colonne nomméedummyet d’un enregistrement avec la valeurX. La table systèmeDUALest utilisée lorsqu’une requête nécessite un nom de table pour des raisons de syntaxe, mais que le contenu de la table n’est pas nécessaire.SELECT sysdate from dual;est un exemple de requête Oracle qui utilise la tableDUAL. L’équivalent Azure Synapse estSELECT GETDATE();. Pour simplifier la migration de DML, vous pouvez créer une table équivalenteDUALdans Azure Synapse à l’aide du code DDL suivant.CREATE TABLE DUAL ( DUMMY VARCHAR(1) ) GO INSERT INTO DUAL (DUMMY) VALUES ('X') GOValeurs
NULL: une valeurNULLdans Oracle est une chaîne vide, représentée par un type de chaîneCHARouVARCHARde longueur0. Dans Azure Synapse et la plupart des autres bases de données,NULLsignifie quelque chose d’autre. Lors de la migration de données ou de processus qui gèrent ou stockent des données, veillez à ce que les valeursNULLsoient gérées de manière cohérente.Syntaxe de jointure externe Oracle : bien que les versions plus récentes d’Oracle prennent en charge la syntaxe de jointure externe ANSI, les anciens systèmes Oracle utilisent une syntaxe propriétaire pour les jointures externes qui utilise un signe plus (
+) dans l’instruction SQL. Si vous migrez un environnement Oracle plus ancien, vous pouvez rencontrer l’ancienne syntaxe. Par exemple :SELECT d.deptno, e.job FROM dept d, emp e WHERE d.deptno = e.deptno (+) AND e.job (+) = 'CLERK' GROUP BY d.deptno, e.job;La syntaxe standard ANSI équivalente est la suivante :
SELECT d.deptno, e.job FROM dept d LEFT OUTER JOIN emp e ON d.deptno = e.deptno and e.job = 'CLERK' GROUP BY d.deptno, e.job ORDER BY d.deptno, e.job;Données
DATE: dans Oracle, le type de donnéesDATEpeut stocker à la fois la date et l’heure. Azure Synapse stocke la date et l’heure dans des types de donnéesDATE,TIMEetDATETIMEdistincts. Lorsque vous migrez des colonnes OracleDATE, vérifiez si elles stockent à la fois la date et l’heure ou simplement une date. Si elles stockent uniquement une date, mappez la colonne àDATE; autrement, mappez-la àDATETIME.Arithmétique
DATE: Oracle prend en charge la soustraction de dates, par exempleSELECT date '2018-12-31' - date '2018-1201' from dual;. Dans Azure Synapse, vous pouvez soustraire des dates à l’aide de la fonctionDATEDIFF(), par exempleSELECT DATEDIFF(day, '2018-12-01', '2018-12-31');.Oracle peut soustraire des entiers de dates, par exemple
SELECT hire_date, (hire_date-1) FROM employees;. Dans Azure Synapse, vous pouvez ajouter ou soustraire des entiers de dates à l’aide de la fonctionDATEADD().Mises à jour par le biais de vues : dans Oracle, vous pouvez exécuter des opérations d’insertion, de mise à jour et de suppression sur une vue pour mettre à jour la table sous-jacente. Dans Azure Synapse, vous exécutez ces opérations sur une table de base, pas sur une vue. Vous devrez peut-être reconcevoir le traitement ETL si une table Oracle est mise à jour par le biais d’une vue.
Fonctions intégrées : le tableau suivant présente les différences de syntaxe et d’usage de certaines fonctions intégrées.
| Fonction Oracle | Description | Équivalent Synapse |
|---|---|---|
| ADD_MONTHS | Ajouter un nombre spécifié de mois | DATEADD |
| CAST | Convertir un type de données intégré en un autre | CAST |
| DECODE | Évaluer une liste de conditions | Expression CASE |
| EMPTY_BLOB | Créer une valeur BLOB vide | Constante 0x (chaîne binaire vide) |
| EMPTY_CLOB | Créer une valeur CLOB ou NCLOB vide | '' (chaîne vide) |
| INITCAP | Mettre en majuscule la première lettre de chaque mot | Fonction définie par l'utilisateur |
| INSTR | Rechercher la position d’une sous-chaîne dans une chaîne | CHARINDEX |
| LAST_DAY | Obtenir la dernière date du mois | EOMONTH |
| LENGTH | Obtenir la longueur de chaîne en caractères | LEN |
| LPAD | Chaîne de remplissage gauche à la longueur spécifiée | Expression utilisant REPLICATE, RIGHT et LEFT |
| MOD | Obtenir le reste d’une division d’un nombre par un autre | Opérateur : % |
| MONTHS_BETWEEN | Obtenir le nombre de mois entre deux dates | DATEDIFF |
| NVL | Remplacer NULL par une expression |
ISNULL |
| SUBSTR | Retourner une sous-chaîne à partir d’une chaîne | SUBSTRING |
| TO_CHAR pour datetime | Convertir datetime en chaîne | CONVERT |
| TO_DATE | Convertir une chaîne en datetime | CONVERT |
| TRANSLATE | Substitution d’un caractère unique | Expressions utilisant REPLACE ou une fonction définie par l’utilisateur |
| TRIM | Découper les caractères de début ou de fin | LTRIM et RTRIM |
| TRUNC pour datetime | Tronquer datetime | Expressions utilisant CONVERT |
| UNISTR | Convertir des points de code Unicode en caractères | Expressions utilisant NCHAR |
Fonctions, procédures stockées et séquences
Quand vous effectuez la migration d’un entrepôt de données à partir d’un environnement hérité mature comme Oracle, vous devez la plupart du temps migrer d’autres éléments que des tables et vues simples. Pour les fonctions, les procédures stockées et les séquences, vérifiez si les outils dans l’environnement Azure peuvent remplacer leurs fonctionnalités, car il est généralement plus efficace d’utiliser des outils Azure intégrés que de recoder les fonctions Oracle.
Dans le cadre de votre phase de préparation, créez un inventaire des objets qui doivent être migrés, définissez une méthode pour les gérer et allouez les ressources appropriées dans votre plan de migration.
Les outils Microsoft tels que SSMA pour Oracle et Azure Database Migration Service, ou les produits et services de migration tiers, peuvent automatiser la migration de fonctions, de procédures stockées et de séquences.
Conseil
Les produits et services tiers peuvent automatiser la migration d’éléments autres que des données.
Les sections suivantes décrivent la migration des fonctions, des procédures stockées et des séquences.
Fonctions
Comme la plupart des produits de base de données, Oracle prend en charge les fonctions système et les fonctions définies par l’utilisateur dans l’implémentation SQL. Lorsque vous migrez une plateforme de base de données héritée vers Azure Synapse, vous pouvez généralement migrer des fonctions système courantes sans modification. Certaines fonctions système peuvent avoir une syntaxe légèrement différente, mais vous pouvez automatiser les modifications requises.
Pour les fonctions système Oracle ou les fonctions arbitraires définies par l’utilisateur qui n’ont pas d’équivalent dans Azure Synapse, recodez ces fonctions à l’aide du langage d’environnement cible. Les fonctions Oracle définies par l’utilisateur sont codées en PL/SQL, Java ou C. Azure Synapse utilise le langage Transact-SQL pour l’implémentation de ce type de fonctions.
Procédures stockées
La plupart des produits de base de données modernes offrent la possibilité de stocker des procédures. Oracle fournit le langage PL/SQL à cet effet. Une procédure stockée contient généralement les instructions SQL et la logique procédurale, et retourne des données ou un état.
Azure Synapse prend en charge les procédures stockées à l’aide de T-SQL. Vous devrez donc recoder toutes les procédures stockées migrées en T-SQL.
Séquences
Dans Oracle, une séquence est un objet de base de données nommé créé avec CREATE SEQUENCE. Une séquence fournit des valeurs numériques uniques via les méthodes CURRVAL et NEXTVAL. Vous pouvez utiliser les nombres uniques générés en tant que valeurs de clé de substitution pour les clés primaires. Azure Synapse n’implémente pas CREATE SEQUENCE, mais vous pouvez implémenter des séquences avec des colonnes IDENTITY ou du code SQL qui génère le numéro de séquence suivant dans une série.
Utiliser EXPLAIN pour valider les SQL hérités
Conseil
Utilisez des requêtes réelles à partir des journaux de requêtes système existants pour rechercher des problèmes de migration potentiels.
En supposant un modèle de données migré « identique » dans Azure Synapse avec les mêmes noms de tables et de colonnes, l’un des moyens de tester Oracle SQL hérité pour la compatibilité avec Azure Synapse est :
- Capturez des instructions SQL représentatives à partir des journaux de l’historique des requêtes système hérités.
- Préfixez ces requêtes avec l’instruction
EXPLAIN. - Exécutez les instructions
EXPLAINdans Azure Synapse.
Tout code SQL incompatible génère une erreur, et les informations d’erreur peuvent être utilisées afin de déterminer l’ampleur de la tâche de recodage. Cette approche ne vous oblige pas à charger des données dans l’environnement Azure ; vous devez uniquement créer les tables et vues pertinentes.
Résumé
Les installations Oracle héritées existantes sont généralement implémentées d’une manière qui rend la migration vers Azure Synapse relativement simple. Les deux environnements utilisent SQL pour les requêtes analytiques sur des volumes de données importants, et utilisent généralement une forme de modèle de données dimensionnel. Ces facteurs font des installations Oracle un bon candidat pour la migration vers Azure Synapse.
Pour résumer, nos recommandations pour réduire la tâche de migration du code SQL d’Oracle vers Azure Synapse sont les suivantes :
Migrez votre modèle de données existant tel quel afin de minimiser le risque, l’effort et le temps de migration, même si un autre modèle de données, tel qu’un coffre de données, est prévu.
Comprenez les différences entre l’implémentation Oracle SQL et l’implémentation Azure Synapse.
Utilisez les métadonnées et les journaux de requête de l’implémentation Oracle existante pour évaluer l’impact de la modification de l’environnement. Planifiez une approche afin d’atténuer les différences.
Automatisez le processus de migration pour minimiser le risque, l’effort et le temps de migration. Vous pouvez utiliser des outils Microsoft tels qu’Azure Database Migration Services et SSMA.
Utilisez éventuellement des services et outils tiers spécialisés pour simplifier la migration.
Étapes suivantes
Pour en savoir plus sur les outils Microsoft et tiers, consultez l’article suivant de cette série : Outils pour la migration de l’entrepôt de données Oracle vers Azure Synapse Analytics.