Créer, développer et gérer des notebooks Synapse dans Azure Synapse Analytics
Un notebook Synapse est une interface web permettant de créer des fichiers contenant du code, des visualisations et du texte descriptif dynamiques. Les blocs-notes constituent un bon endroit où valider des idées et effectuer des expérimentations rapides pour extraire des insights de vos données. Les blocs-notes sont également largement utilisés pour la préparation et la visualisation de données, l’apprentissage automatique et d’autres scénarios en lien avec le Big Data.
Avec un notebook Synapse, vous pouvez :
- Commencer à travailler sans le moindre effort de configuration.
- Sécuriser les données avec des fonctionnalités de sécurité d’entreprise intégrées.
- Analyser des données dans des formats bruts (CSV, txt, JSON, etc.), des formats de fichiers traités (Parquet, Delta Lake, ORC, etc.) et des fichiers de données tabulaires SQL sur Spark et SQL.
- Être productif grâce à des fonctionnalités de création améliorées et à la visualisation de données intégrée.
Cet article explique comment utiliser des notebooks dans Synapse Studio.
Créer un notebook
Il existe deux façons de créer un bloc-notes. Vous pouvez créer un notebook ou en importer un dans un espace de travail Synapse à partir de l’Explorateur d’objets. Les notebooks Synapse reconnaissent les fichiers IPYNB Jupyter Notebook standard.
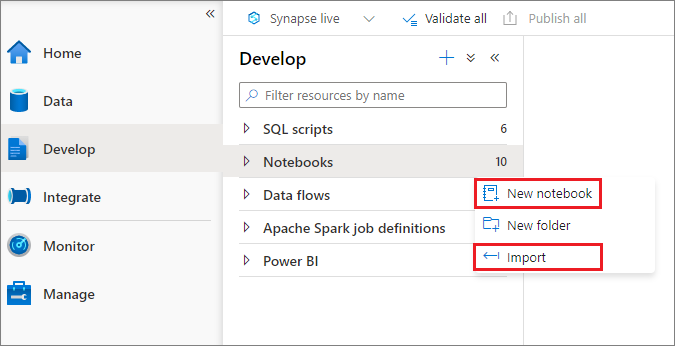
Développer des notebooks
Les notebooks sont constitués de cellules qui sont des blocs individuels de code ou de texte qui peuvent être exécutés de façon indépendante ou en tant que groupe.
Nous proposons des opérations riches pour développer des notebooks :
- Ajouter une cellule
- Définir un langage principal
- Utiliser plusieurs langages
- Utiliser des tables temporaires pour référencer des données dans plusieurs langages
- IntelliSense de style IDE
- Extraits de code
- Mettre en forme une cellule de texte avec des boutons de barre d’outils
- Opération d’annulation/de rétablissement de cellule
- Commentaires des cellules de code
- Déplacer une cellule
- Supprimer une cellule
- Réduire une entrée de cellule
- Réduire une sortie de cellule
- Structure du notebook
Notes
Dans les notebooks, une session SparkSession est créée automatiquement pour vous, stockée dans une variable appelée spark. Il existe également une variable pour SparkContext qui est appelée sc. Les utilisateurs peuvent accéder directement à ces variables et ne doivent pas modifier leurs valeurs.
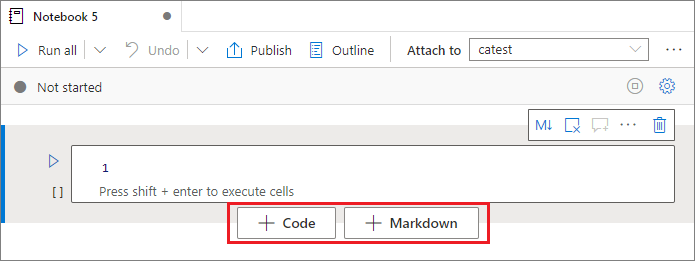
Ajouter une cellule
Il existe plusieurs façons d’ajouter une cellule à un bloc-notes.
Placez le curseur sur l’espace entre deux cellules et sélectionnez Code ou Démarque.
Utilisez les touches de raccourci aznb en mode de commande. Appuyez sur A pour insérer une cellule au-dessus de la cellule active. Appuyez sur B pour insérer une cellule en dessous de la cellule active.
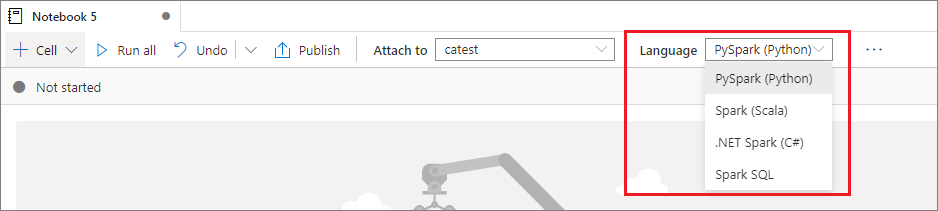
Définir un langage principal
Les notebooks Synapse prennent en charge quatre langages Apache Spark :
- PySpark (Python)
- Spark (Scala)
- Spark SQL
- .NET Spark (C#)
- SparkR (R)
Vous pouvez définir le langage principal des nouvelles cellules ajoutées dans la liste déroulante de la barre de commandes supérieure.
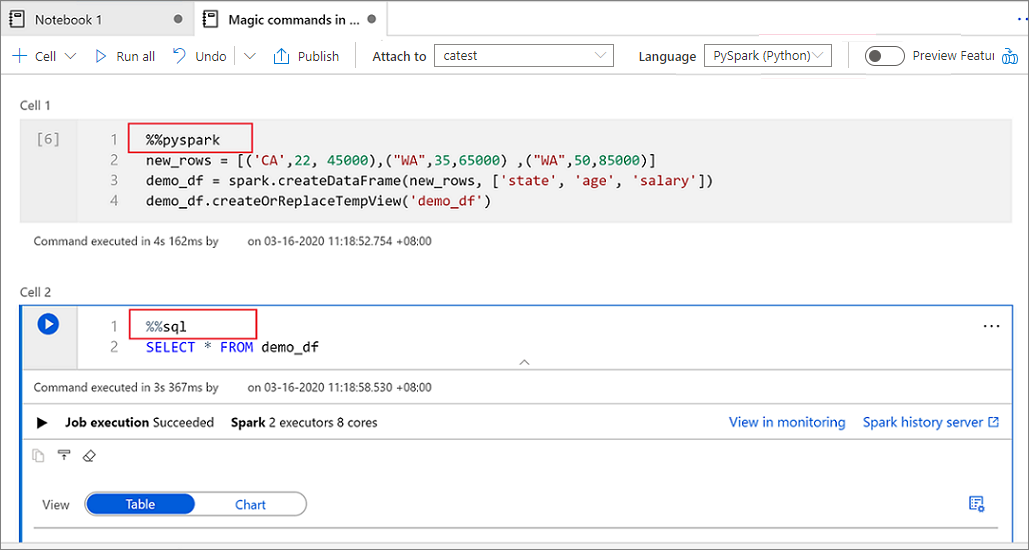
Utiliser plusieurs langages
Vous pouvez utiliser plusieurs langages dans un même bloc-notes en spécifiant la commande magic du langage approprié au début d’une cellule. Le tableau suivant répertorie les commandes magic pour basculer les langages des cellules.
| Commande magic | Langage | Description |
|---|---|---|
| %%pyspark | Python | Exécuter une requête Python sur du contexte Spark. |
| %%spark | Scala | Exécuter une requête Scala sur du contexte Spark. |
| %%sql | SparkSQL | Exécuter une requête SparkSQL sur du contexte Spark. |
| %%csharp | .NET pour Spark C# | Exécutez une requête .NET pour Spark C# sur du contexte Spark. |
| %%sparkr | R | Exécuter une requête R sur du contexte Spark. |
L’image suivante illustre la façon d’écrire une requête PySpark avec la commande magic %%PySpark, ou une requête SparkSQL avec la commande magic %%sql dans un bloc-notes Spark(Scala) . Notez que le langage principal du notebook est défini sur pySpark.
Utiliser des tables temporaires pour référencer des données dans plusieurs langages
Vous ne pouvez pas référencer des données ou variables directement dans différents langages dans un notebook Synapse. Dans Spark, une table temporaire peut être référencée dans plusieurs langages. Voici un exemple de lecture d’une tramedonnées Scala en PySpark et SparkSQL en utilisant une table temporaire Spark comme solution de contournement.
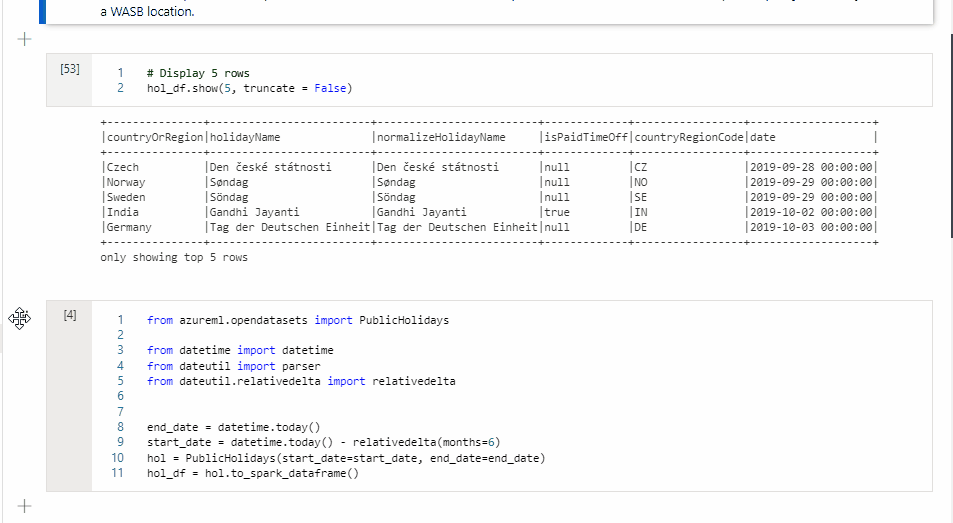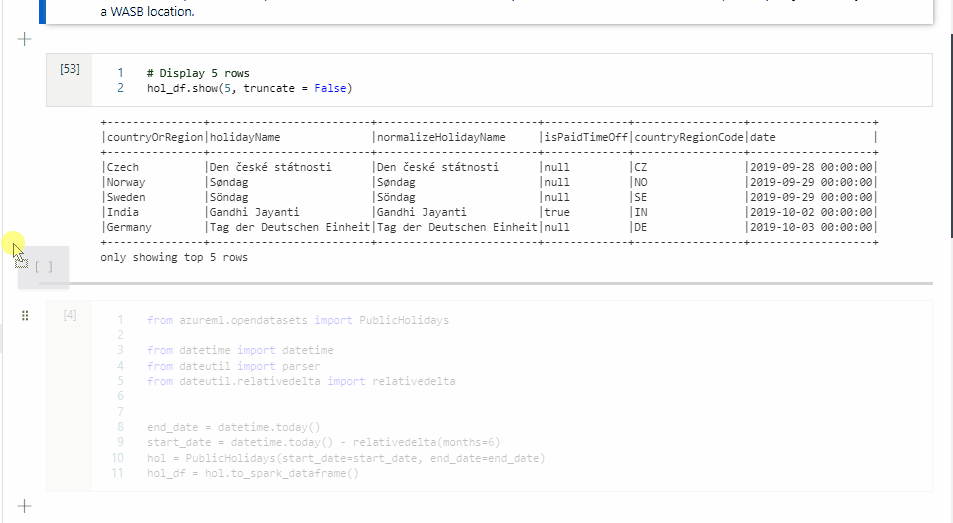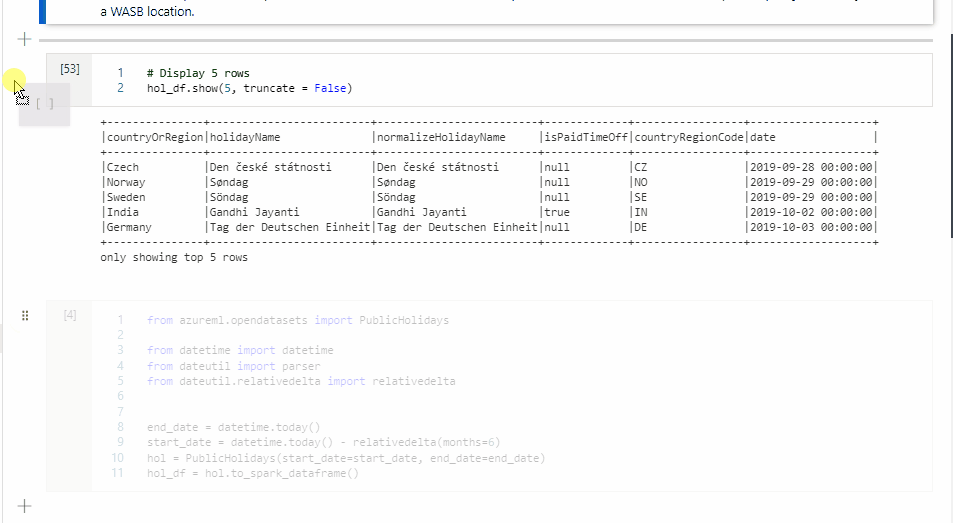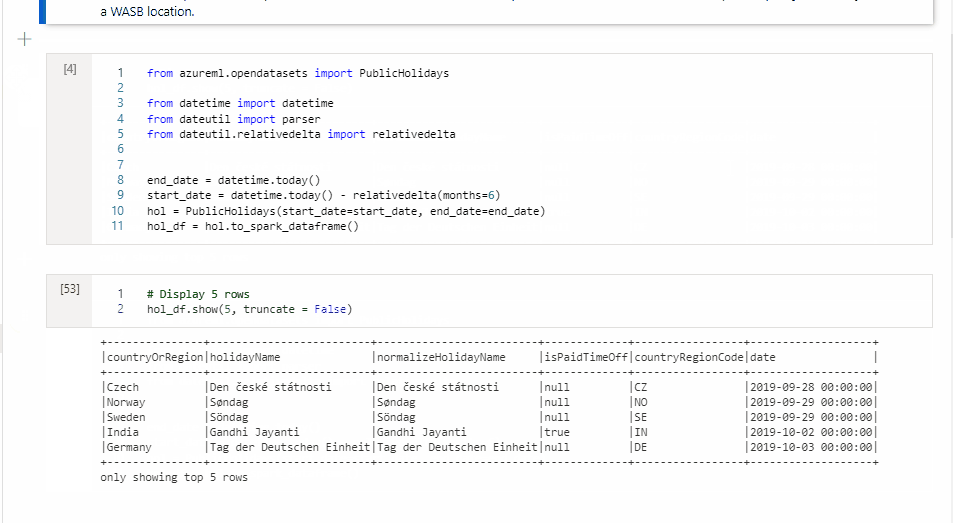
Dans la cellule 1, lisez une tramedonnées à partir du connecteur de pool SQL en utilisant Scala, puis créez une table temporaire.
%%spark val scalaDataFrame = spark.read.sqlanalytics("mySQLPoolDatabase.dbo.mySQLPoolTable") scalaDataFrame.createOrReplaceTempView( "mydataframetable" )Dans la cellule 2, interrogez les données en utilisant Spark SQL.
%%sql SELECT * FROM mydataframetableDans la cellule 3, utilisez les données dans PySpark.
%%pyspark myNewPythonDataFrame = spark.sql("SELECT * FROM mydataframetable")
IntelliSense de style IDE
Les notebooks Synapse sont intégrés à l’éditeur Monaco pour doter l’éditeur de cellule de la fonctionnalité IntelliSense (de style IDE). Une mise en évidence de la syntaxe, un marqueur d’erreurs et des saisies semi-automatiques de code vous aident à écrire le code et à identifier les problèmes plus rapidement.
Les fonctionnalités IntelliSense sont à des niveaux de maturité différents pour les différents langages. Utilisez le tableau suivant pour voir ce qui est pris en charge.
| Languages | Mise en évidence de la syntaxe | Marqueur d’erreur de syntaxe | Saisie semi-automatique de code de syntaxe | Saisie semi-automatique de code variable | Saisie semi-automatique de code de fonction système | Saisie semi-automatique de code de fonction utilisateur | Mise en retrait intelligente | Pliage de code |
|---|---|---|---|---|---|---|---|---|
| PySpark (Python) | Oui | Oui | Oui | Oui | Oui | Oui | Oui | Oui |
| Spark (Scala) | Oui | Oui | Oui | Oui | Oui | Oui | - | Oui |
| SparkSQL | Oui | Oui | Oui | Oui | Oui | - | - | - |
| .NET pour Spark (C#) | Oui | Oui | Oui | Oui | Oui | Oui | Oui | Oui |
Notes
Une session Spark active est requise pour tirer parti de la saisie semi-automatique du code, de la saisie semi-automatique du code de fonction du système, de l’exécution du code de fonction de l’utilisateur pour .NET pour Spark (C#).
Extraits de code
Les notebooks Synapse fournissent des extraits de code qui facilitent l’entrée de modèles de code couramment utilisés, tels que la configuration de votre session Spark, la lecture des données en tant que DataFrame Spark ou la création de graphiques avec matplotlib, etc.
Les extraits de code apparaissent dans Touches de raccourci d’IntelliSense style IDE en combinaison avec d’autres suggestions. Le contenu des extraits de code s’aligne avec le langage des cellules de code. Vous pouvez voir les extraits de code disponibles en tapant Extrait ou n’importe quel mot clé apparaît dans le titre de l’extrait dans l’éditeur de cellule de code. Par exemple, en tapant lire, vous pouvez voir la liste des extraits pour lire les données à partir de différentes sources de données.

Mettre en forme une cellule de texte avec des boutons de barre d’outils
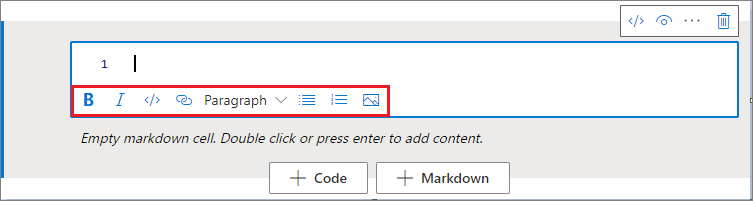
Vous pouvez utiliser les boutons de mise en forme dans la barre d’outils des cellules de texte pour effectuer des actions de markdown (démarquage) courantes. Celles-ci incluent la mise en gras et en italique de texte, l’insertion de paragraphes ou d’en-têtes par le biais d’une liste déroulante, l’insertion de code, l’insertion de liste non triée, l’insertion de liste triée, l’insertion de lien hypertexte et l’insertion d’image à partir d’une URL.
Opération d’annulation/de rétablissement de cellule
Sélectionnez le bouton Annuler / Restaurer ou appuyez sur Z / Maj+Z pour révoquer les opérations de cellule les plus récentes. Vous pouvez désormais annuler/restaurer jusqu’aux 10 dernières opérations sur cellule.

Opérations de cellule d’annulation prises en charge :
- Insérer/supprimer une cellule : Vous pouvez révoquer les opérations de suppression en sélectionnant Annuler ; le contenu de texte est conservé avec la cellule.
- Réorganiser la cellule.
- Basculer le paramètre.
- Effectuer une conversion entre une cellule de code et une cellule Markdown.
Notes
Les opérations de texte dans les cellules et les opérations de commentaires des cellules de code ne peuvent pas être annulées. Vous pouvez désormais annuler/restaurer jusqu’aux 10 dernières opérations sur cellule.
Commentaires des cellules de code
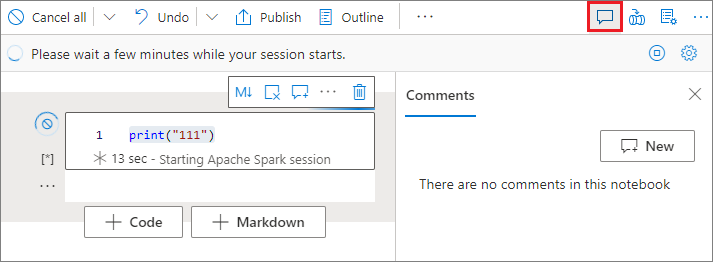
Sélectionnez le bouton Commentaires dans la barre d’outils du notebook pour ouvrir le volet Commentaires.
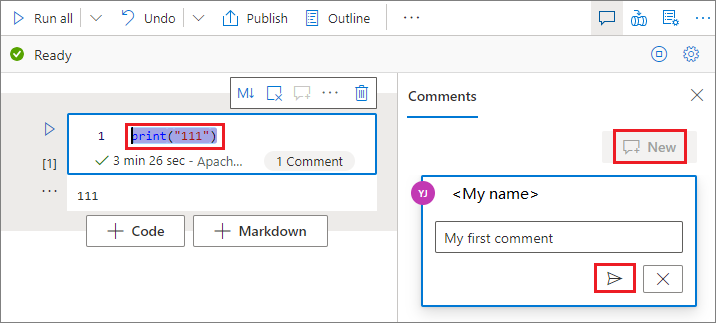
Sélectionnez code dans la cellule code, cliquez sur Nouveau dans le volet Commentaires, ajoutez des commentaires, puis cliquez sur le bouton Poster un commentaire pour l’enregistrer.
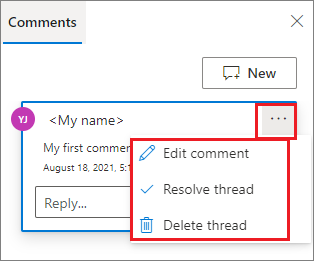
Vous pouvez Modifier un commentaire, Résoudre le thread ou Supprimer le thread en cliquant sur le bouton Plus en regard de votre commentaire.
Déplacer une cellule
Cliquez sur le côté gauche d’une cellule et faites-la glisser vers la position de votre choix.
Supprimer une cellule
Pour supprimer une cellule, sélectionnez le bouton Supprimer à droite de la cellule.
Vous pouvez également utiliser des touches de raccourci en mode de commande. Appuyez sur Maj + D pour supprimer la cellule active.
Réduire une entrée de cellule
Sélectionnez Plus d’ellipses de commandes (…) dans la barre d’outils de la cellule et Cacher l’entrée pour réduire l’entrée de la cellule active. Pour la développer, sélectionnez Afficher l’entrée quand la cellule est réduite.
Réduire une sortie de cellule
Sélectionnez Plus d’ellipses de commandes (…) dans la barre d’outils de la cellule et Cacher la sortie pour réduire la sortie de la cellule active. Pour la développer, sélectionnez Afficher la sortie quand la sortie de la cellule est réduite.
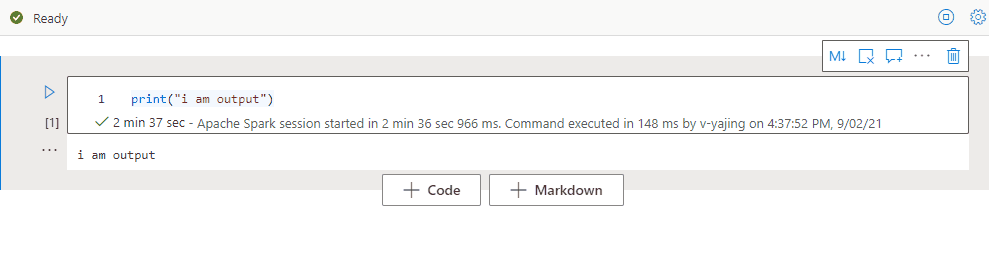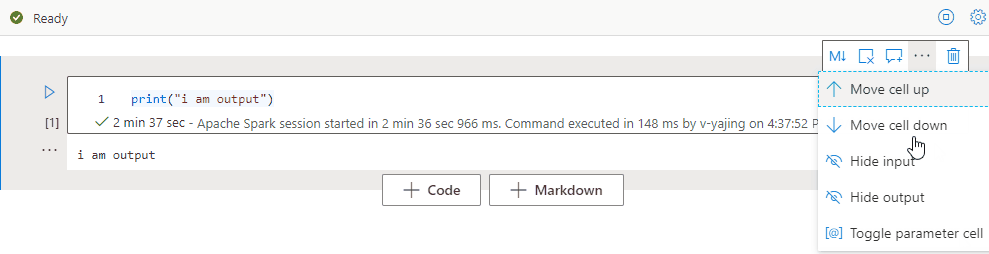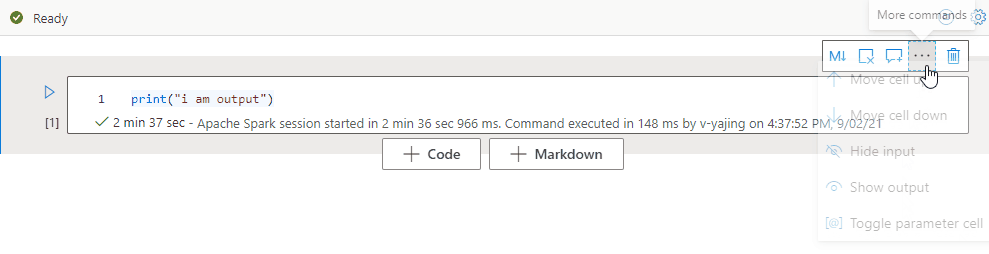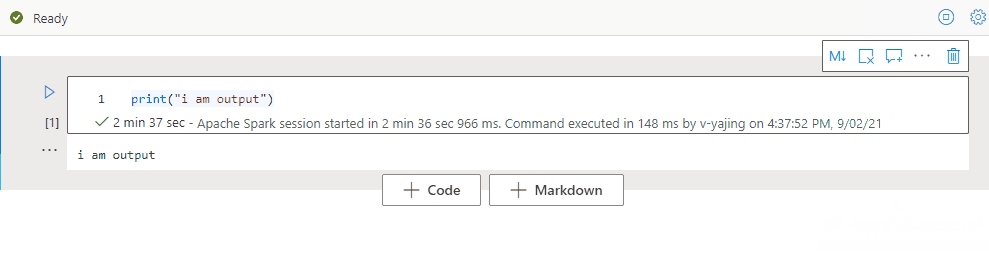
Structure du notebook
La Structure (Table des matières) présente le premier en-tête Markdown d'une cellule Markdown sur une barre latérale pour une navigation rapide. La barre latérale de la Structure est redimensionnable et réductible pour s'adapter au mieux à l'écran. Vous pouvez sélectionner le bouton Structure de la barre de commandes du notebook pour ouvrir ou masquer la barre latérale.
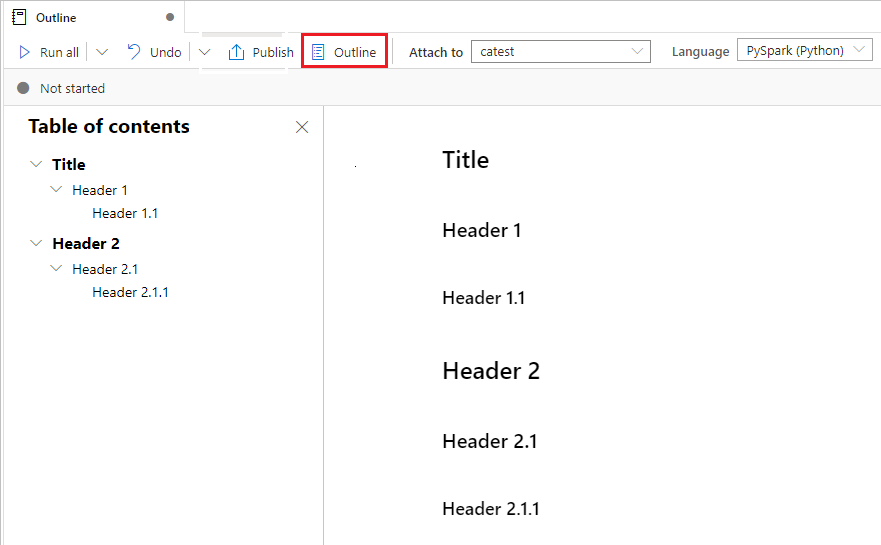
Exécuter des blocs-notes
Vous pouvez exécuter les cellules de code dans votre bloc-notes individuellement ou toutes en même temps. L’état et la progression de chaque cellule sont représentés dans le bloc-notes.
Exécuter une cellule
Il existe plusieurs façons d’exécuter le code figurant dans une cellule.
Pointez sur la cellule à exécuter, puis sélectionnez le bouton Exécuter la cellule ou appuyez sur Ctrl + Entrée.

Utilisez les touches de raccourci en mode de commande. Appuyez sur Maj + Entrée pour exécuter la cellule active et sélectionner la cellule en dessous. Appuyez sur Alt + Entrée pour exécuter la cellule active et insérer une nouvelle cellule en dessous.
Exécuter toutes les cellules
Sélectionnez le bouton Exécuter tout pour exécuter toutes les cellules du notebook actuel dans l’ordre.

Exécuter toutes les cellules au-dessus ou en dessous
Développez la liste déroulante du bouton Exécuter tout, puis sélectionnez Exécuter les cellules ci-dessus pour exécuter dans l’ordre toutes les cellules au-dessus de la cellule actuelle. Sélectionnez Exécuter les cellules en dessous pour exécuter toutes les cellules sous la cellule active dans l’ordre.

Annuler toutes les cellules en cours d’exécution
Sélectionnez le bouton Annuler tout pour annuler les cellules en cours d’exécution ou les cellules dans la file d’attente.

Référence de notebook
Vous pouvez utiliser la commande magic %run <notebook path> pour référencer un autre notebook dans le contexte du notebook actuel. Toutes les variables définies dans le notebook de référence sont disponibles dans le notebook actuel. La commande magic %run prend en charge les appels imbriqués, mais pas les appels récursifs. Vous recevez une exception si la profondeur de l’instruction est supérieure à cinq.
Exemple : %run /<path>/Notebook1 { "parameterInt": 1, "parameterFloat": 2.5, "parameterBool": true, "parameterString": "abc" }.
La référence de notebook fonctionne en mode interactif et en pipeline Synapse.
Notes
- Actuellement, la commande
%runne prend en charge qu’un chemin d’accès absolu ou un nom de notebook comme paramètre. Le chemin d’accès relatif n’est pas pris en charge. - Actuellement, la commande
%runne prend en charge que 4 types valeur de paramètre :int,float,bool,stringl’opération de remplacement de variable n’est pas prise en charge. - Les notebooks référencés doivent être publiés. Vous devez publier les notebooks pour les référencer, sauf si l’option Référencer le notebook non publié est activée. Synapse Studio ne reconnaît pas les notebooks non publiés du référentiel Git.
- Les notebooks référencés ne prennent pas en charge les instructions dont la profondeur est supérieure à cinq.
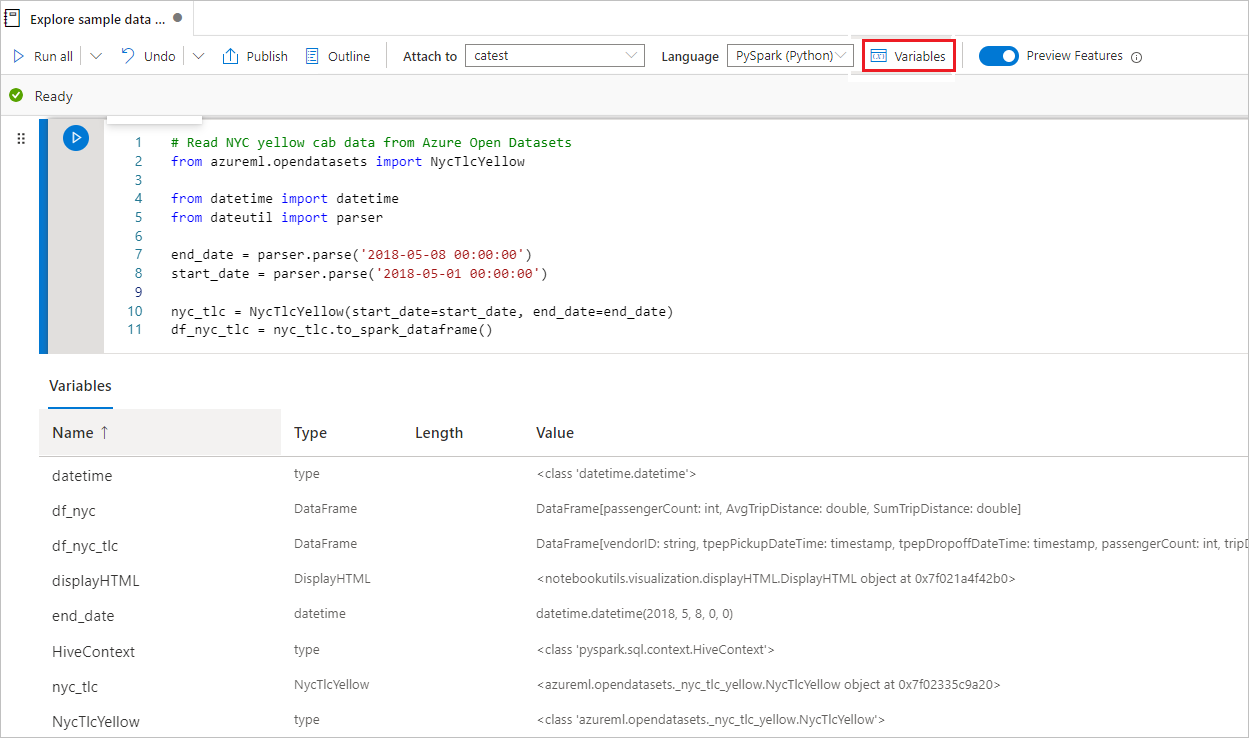
Explorateur de variables
Synapse Notebook fournit un explorateur de variables qui vous permet de voir la liste des noms, des types, des longueurs et des valeurs des variables dans la session Sparkle en cours pour les cellules PySpark (Python). D'autres variables apparaissent automatiquement à mesure qu'elles sont définies dans les cellules de code. Un clic sur chaque en-tête de colonne permet de trier les variables de la table.
Vous pouvez sélectionner le bouton Variables de la barre des commandes du notebook pour ouvrir ou masquer l'Explorateur de variables.
Notes
L’Explorateur de variables ne prend en charge que Python.
Indicateur d’état de cellule
Un état d’exécution de cellule pas à pas est affiché sous la cellule pour vous aider à voir la progression en cours. Une fois l’exécution de la cellule terminée, un résumé de l’exécution avec la durée totale et l’heure de fin sont affichés et conservés là pour référence future.

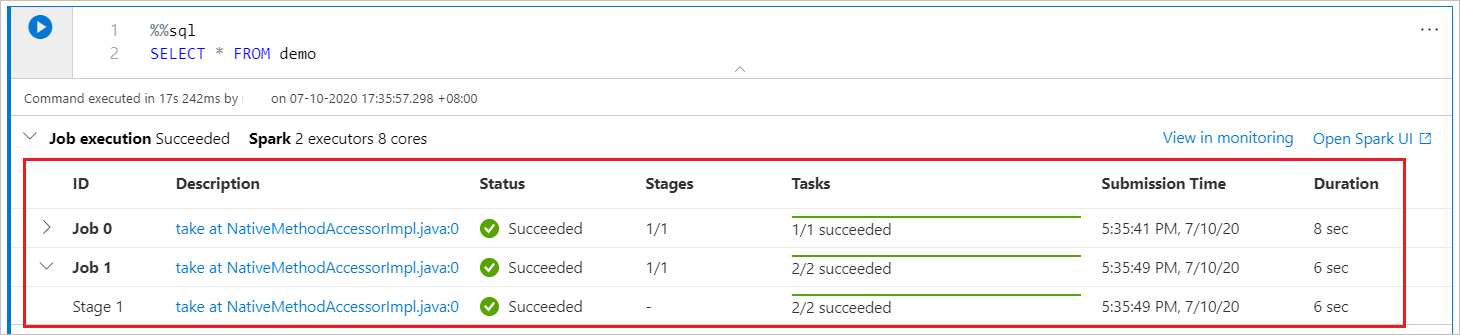
Indicateur de progression Spark
Le notebook Synapse est entièrement basé sur Spark. Les cellules de code sont exécutées sur le pool Apache Spark serverless à distance. Un indicateur de progression du travail Spark est fourni avec une barre de progression en temps réel qui s’affiche pour vous aider à comprendre l’état d’exécution du travail. Le nombre de tâches par travail ou index vous aide à identifier le niveau parallèle de votre travail Spark. Vous pouvez également explorer plus en profondeur l’IU Spark pour un travail (ou index) spécifique en sélectionnant le lien hypertexte du nom du travail (ou de l’index).
Configuration de session Spark
Vous pouvez spécifier le délai d’expiration, le nombre et la taille des exécuteurs à transmettre à la session Spark en cours dans Configurer la session. Redémarrez la session Spark pour que les modifications apportées à la configuration prennent effet. Toutes les variables du bloc-notes mises en cache sont effacées.
Vous pouvez également créer une configuration à partir de la configuration Apache Spark ou sélectionner une configuration existante. Pour plus d’informations, reportez-vous à Gestion de la configuration Apache Spark.

Commande magic de configuration de session Spark
Vous pouvez également spécifier des paramètres de session Spark via une commande magic %%configure. La session Spark doit redémarrer pour que les paramètres s’appliquent. Nous vous recommandons d’exécuter la fonctionnalité %%configure au début de votre notebook. En voici un exemple. Reportez-vous à https://github.com/cloudera/livy#request-body pour obtenir la liste complète des paramètres valides.
%%configure
{
//You can get a list of valid parameters to config the session from https://github.com/cloudera/livy#request-body.
"driverMemory":"28g", // Recommended values: ["28g", "56g", "112g", "224g", "400g", "472g"]
"driverCores":4, // Recommended values: [4, 8, 16, 32, 64, 80]
"executorMemory":"28g",
"executorCores":4,
"jars":["abfs[s]://<file_system>@<account_name>.dfs.core.windows.net/<path>/myjar.jar","wasb[s]://<containername>@<accountname>.blob.core.windows.net/<path>/myjar1.jar"],
"conf":{
//Example of standard spark property, to find more available properties please visit:https://spark.apache.org/docs/latest/configuration.html#application-properties.
"spark.driver.maxResultSize":"10g",
//Example of customized property, you can specify count of lines that Spark SQL returns by configuring "livy.rsc.sql.num-rows".
"livy.rsc.sql.num-rows":"3000"
}
}
Notes
- « DriverMemory » et « ExecutorMemory » sont recommandés pour définir la même valeur dans %%configure, tout comme « driverCores » et « executorCores ».
- Vous pouvez utiliser %%configure dans les pipelines Synapse, mais si elle n’est pas définie dans la première cellule de code, l’exécution du pipeline échoue en raison de l’impossibilité de redémarrer la session.
- La commande %%configure utilisée dans mssparkutils.notebook.run va être ignorée, mais si elle est utilisée dans %run, le notebook continue de s’exécuter.
- Les propriétés de configuration Spark standard doivent être utilisées dans le corps « conf ». Nous ne prenons pas en charge la référence de niveau supérieur pour les propriétés de configuration Spark.
- Certaines propriétés Spark spéciales, y compris « spark.driver.cores », « spark.executor.cores », « spark.driver.memory », « spark.executor.memory », « spark.executor.instances » ne sont pas prises en compte dans le corps « conf ».
Configuration de session paramétrable à partir du pipeline
La configuration de session paramétrable vous permet de remplacer la valeur dans la commande magic %%configure par les paramètres d’exécution de pipeline (activité de notebook). Lorsque vous préparez la cellule de code %%configure, vous pouvez remplacer les valeurs par défaut (également configurables, 4 et « 2000 » dans l’exemple ci-dessous) par un objet comme celui-ci :
{
"activityParameterName": "paramterNameInPipelineNotebookActivity",
"defaultValue": "defaultValueIfNoParamterFromPipelineNotebookActivity"
}
%%configure
{
"driverCores":
{
"activityParameterName": "driverCoresFromNotebookActivity",
"defaultValue": 4
},
"conf":
{
"livy.rsc.sql.num-rows":
{
"activityParameterName": "rows",
"defaultValue": "2000"
}
}
}
Notebook utilise la valeur par défaut si vous exécutez un notebook en mode interactif directement ou si aucun paramètre correspondant à « activityParameterName » n’est fourni par l’activité de notebook du pipeline.
Lors du mode d’exécution du pipeline, vous pouvez configurer les paramètres d’activité de notebook du pipeline comme suit : 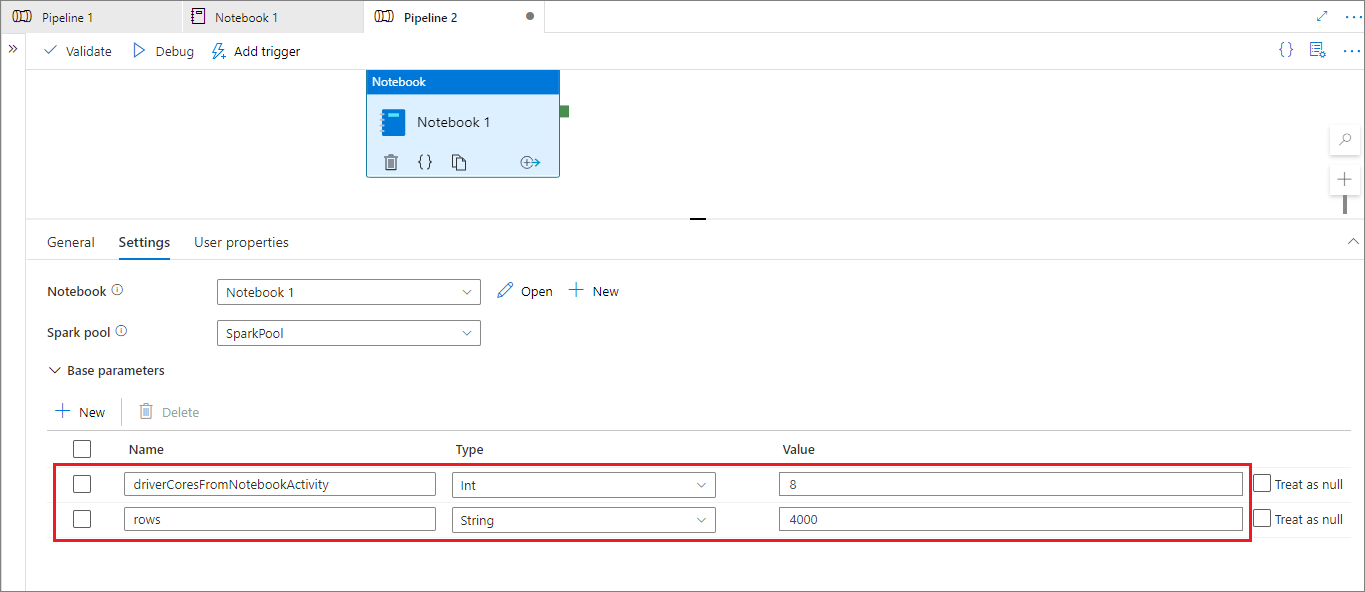
Si vous souhaitez modifier la configuration de session, le nom des paramètres d’activité de notebook du pipeline doit être identique à activityParameterName dans le notebook. Lors de l’exécution de ce pipeline, dans cet exemple, driverCores dans %%configure sera remplacé par 8 et livy.rsc.sql.num-rows sera remplacé par 4000.
Notes
Si le pipeline exécuté a échoué en raison de l’utilisation de cette nouvelle commande magic %%configure, vous pouvez consulter d’autres informations sur l’erreur en exécutant la cellule magic %%configure dans le mode interactif du notebook.
Importer des données dans un bloc-notes
Vous pouvez charger des données à partir du service Stockage Blob Azure, d’Azure Data Lake Store Gén. 2 et d’un pool SQL, comme illustré dans les exemples de code ci-dessous.
Lire un fichier CSV à partir d’Azure Data Lake Store Gén. 2 en tant que tramedonnées Spark
from pyspark.sql import SparkSession
from pyspark.sql.types import *
account_name = "Your account name"
container_name = "Your container name"
relative_path = "Your path"
adls_path = 'abfss://%s@%s.dfs.core.windows.net/%s' % (container_name, account_name, relative_path)
df1 = spark.read.option('header', 'true') \
.option('delimiter', ',') \
.csv(adls_path + '/Testfile.csv')
Lire un fichier CSV à partir du service Stockage Blob Azure en tant que tramedonnées Spark
from pyspark.sql import SparkSession
# Azure storage access info
blob_account_name = 'Your account name' # replace with your blob name
blob_container_name = 'Your container name' # replace with your container name
blob_relative_path = 'Your path' # replace with your relative folder path
linked_service_name = 'Your linked service name' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
wasb_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasb_path)
df = spark.read.option("header", "true") \
.option("delimiter","|") \
.schema(schema) \
.csv(wasbs_path)
Lire des données à partir du compte de stockage principal
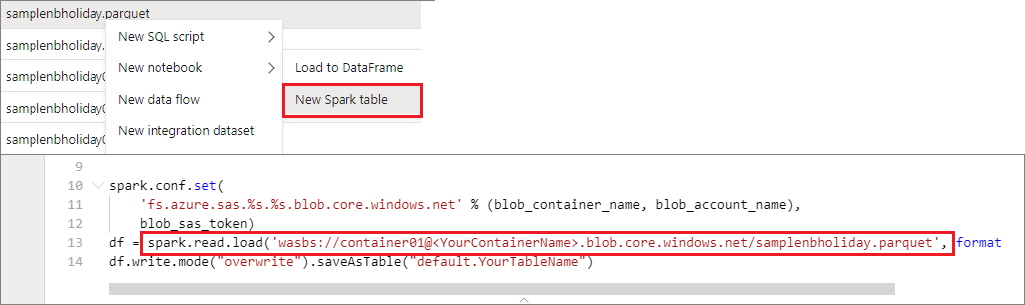
Vous pouvez accéder aux données directement dans le compte de stockage principal. Il n’est pas nécessaire de fournir les clés secrètes. Dans l’Explorateur de données, cliquez avec le bouton droit sur un fichier, puis sélectionnez Nouveau bloc-notes pour afficher un nouveau bloc-notes avec l’extracteur de données généré automatiquement.
Widgets IPython
Les widgets sont des objets Python avec événement qui ont une représentation dans le navigateur, souvent sous la forme d’un contrôle tel qu’un curseur, une zone de texte, etc. Les widgets IPython fonctionnent uniquement dans un environnement Python ; ils ne sont pas encore pris en charge dans d’autres langages (par exemple, Scala, SQL, C#).
Pour utiliser un widget IPython
Vous devez d'abord importer le module
ipywidgetspour utiliser l’infrastructure de widgets Jupyter.import ipywidgets as widgetsVous pouvez utiliser la
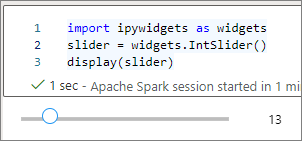
displayfonction de niveau supérieur pour afficher un widget ou conserver une expression de type widget au niveau de la dernière ligne de la cellule de code.slider = widgets.IntSlider() display(slider)slider = widgets.IntSlider() sliderExécutez la cellule. Le widget s’affiche dans la zone de sortie.
Vous pouvez utiliser plusieurs appels
display()pour afficher la même instance de widget plusieurs fois, mais ils restent synchronisés les uns avec les autres.slider = widgets.IntSlider() display(slider) display(slider)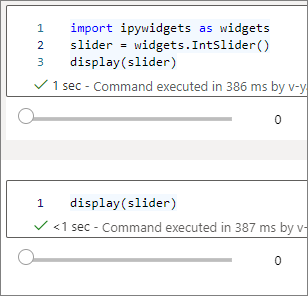
Pour afficher deux widgets indépendamment l’un de l’autre, créez deux instances de widget :
slider1 = widgets.IntSlider() slider2 = widgets.IntSlider() display(slider1) display(slider2)
Widgets pris en charge
| Type de widgets | Widgets |
|---|---|
| Widgets numériques | IntSlider, FloatSlider, FloatLogSlider, IntRangeSlider, FloatRangeSlider, IntProgress, FloatProgress, BoundedIntText, BoundedFloatText, IntText, FloatText |
| Widgets booléens | ToggleButton, Checkbox, Valid |
| Widgets de sélection | Dropdown, RadioButtons, Select, SelectionSlider, SelectionRangeSlider, ToggleButtons, SelectMultiple |
| Widgets de chaîne | Text, Text area, Combobox, Password, Label, HTML, HTML Math, Image, Button |
| Widgets de lecture (Animation) | Date picker, Color picker, Controller |
| Widgets de conteneur/disposition | Box, HBox, VBox, GridBox, Accordion, Tabs, Stacked |
Limites connues
Les widgets suivants ne sont pas encore pris en charge. Vous pouvez suivre la solution de contournement correspondante comme indiqué ci-dessous :
Fonctionnalité Solution de contournement Widget OutputVous pouvez utiliser la fonction print()pour écrire du texte dans stdout.widgets.jslink()Vous pouvez utiliser la fonction widgets.link()pour lier deux widgets similaires.Widget FileUploadPas encore pris en charge. La fonction
displayglobale fournie par Synapse ne prend pas en charge l’affichage de plusieurs widgets dans un appel (c’est-à-diredisplay(a, b)), qui est différent de la fonctiondisplayIPython.Si vous fermez un notebook qui contient un widget IPython, vous ne pourrez pas le voir ou interagir avec lui tant que vous n’aurez pas réexécuté la cellule correspondante.
Enregistrer des blocs-notes
Vous pouvez enregistrer un seul bloc-notes ou tous les blocs-notes dans votre espace de travail.
Pour enregistrer les modifications apportées à un seul bloc-notes, sélectionnez le bouton Publier dans la barre de commandes du bloc-notes.

Pour enregistrer tous les blocs-notes dans votre espace de travail, sélectionnez le bouton Publier tout dans la barre de commandes de l’espace de travail.

Dans les propriétés du bloc-notes, vous pouvez éventuellement configurer l’inclusion de la sortie de cellule lors de l’enregistrement.
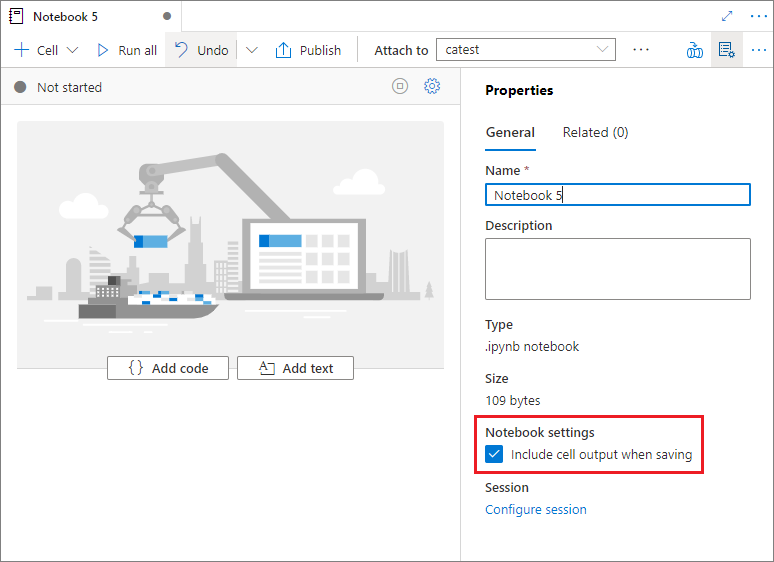
Commandes magic
Vous pouvez utiliser des commandes magic Jupyter connues dans les notebooks Synapse. Vérifiez la liste suivante des commandes magic actuellement disponibles. Parlez-nous de vos cas d’usage sur GitHub pour nous permettre de continuer à créer des commandes magic supplémentaires afin de répondre à vos besoins.
Notes
Seules les commandes magic suivantes sont prises en charge dans le pipeline Synapse : %%pyspark, %%spark, %%csharp, %%sql.
Commandes magic de ligne disponibles : %lsmagic, %time, %timeit, %history, %run, %load
Commandes magic de cellule disponibles : %%time, %%timeit, %%capture, %%writefile, %%sql, %%pyspark, %%spark, %%csharp, %%html, %%configure
Référencer un notebook non publié
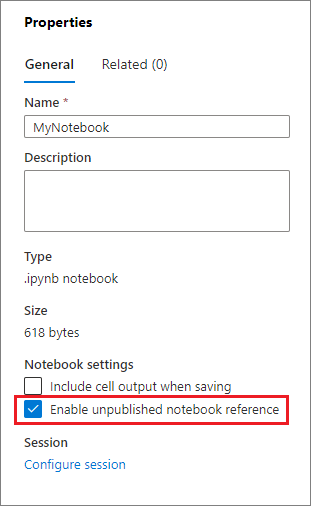
Référencer un notebook non publié est utile lorsque vous souhaitez déboguer « localement ». Lors de l’activation de cette fonctionnalité, l’exécution du notebook récupère le contenu actuel dans le cache web. Si vous exécutez une cellule incluant une instruction de notebooks de référence, vous référencez les notebooks de présentation dans le navigateur du notebook actuel au lieu d’une version enregistrée dans le cluster, ce qui signifie que les modifications de votre éditeur de notebook peuvent être référencées immédiatement par d’autres notebooks sans avoir à être publiées (mode direct) ou validées (mode Git). En tirant parti de cette approche, vous pouvez facilement éviter que les bibliothèques courantes soient polluées pendant le processus de développement ou de débogage.
Vous pouvez activer la référence du notebook non publié dans le panneau Propriétés :
Pour comparer différents cas, consultez le tableau ci-dessous :
Notez que %run et mssparkutils.notebook.run ont le même comportement ici. Nous utilisons %run ici comme exemple.
| Cas | Disable | Activer |
|---|---|---|
| Mode direct | ||
- Nb1 (publié) %run Nb1 |
Exécuter la version publiée de Nb1 | Exécuter la version publiée de Nb1 |
- Nb1 (nouveau) %run Nb1 |
Erreur | Exécuter le nouveau Nb1 |
- Nb1 (précédemment publié, modifié) %run Nb1 |
Exécuter la version publiée de Nb1 | Exécuter la version modifiée de Nb1 |
| Mode Git | ||
- Nb1 (publié) %run Nb1 |
Exécuter la version publiée de Nb1 | Exécuter la version publiée de Nb1 |
- Nb1 (nouveau) %run Nb1 |
Erreur | Exécuter le nouveau Nb1 |
- Nb1 (non publié, validé) %run Nb1 |
Erreur | Exécuter le Nb1 validé |
- Nb1 (précédemment publié, validé) %run Nb1 |
Exécuter la version publiée de Nb1 | Exécuter la version validée de Nb1 |
- Nb1 (précédemment publié, nouveau dans Current Branch) %run Nb1 |
Exécuter la version publiée de Nb1 | Exécuter le nouveau Nb1 |
- Nb1 (non publié, précédemment validé, modifié) %run Nb1 |
Erreur | Exécuter la version modifiée de Nb1 |
- Nb1 (précédemment publié et validé, modifié) %run Nb1 |
Exécuter la version publiée de Nb1 | Exécuter la version modifiée de Nb1 |
Conclusion
- S’il est désactivé, exécutez toujours la version publiée.
- S’il est activé, la priorité est : modifié/nouveau > validé > publié.
Gestion des sessions actives
Vous pouvez facilement réutiliser vos sessions de notebook sans avoir à en démarrer de nouvelles. Le notebook Synapse prend désormais en charge la gestion de vos sessions actives dans la liste Gérer les sessions. Vous pouvez voir toutes les sessions de l’espace de travail actuel que vous avez démarré à partir du notebook.
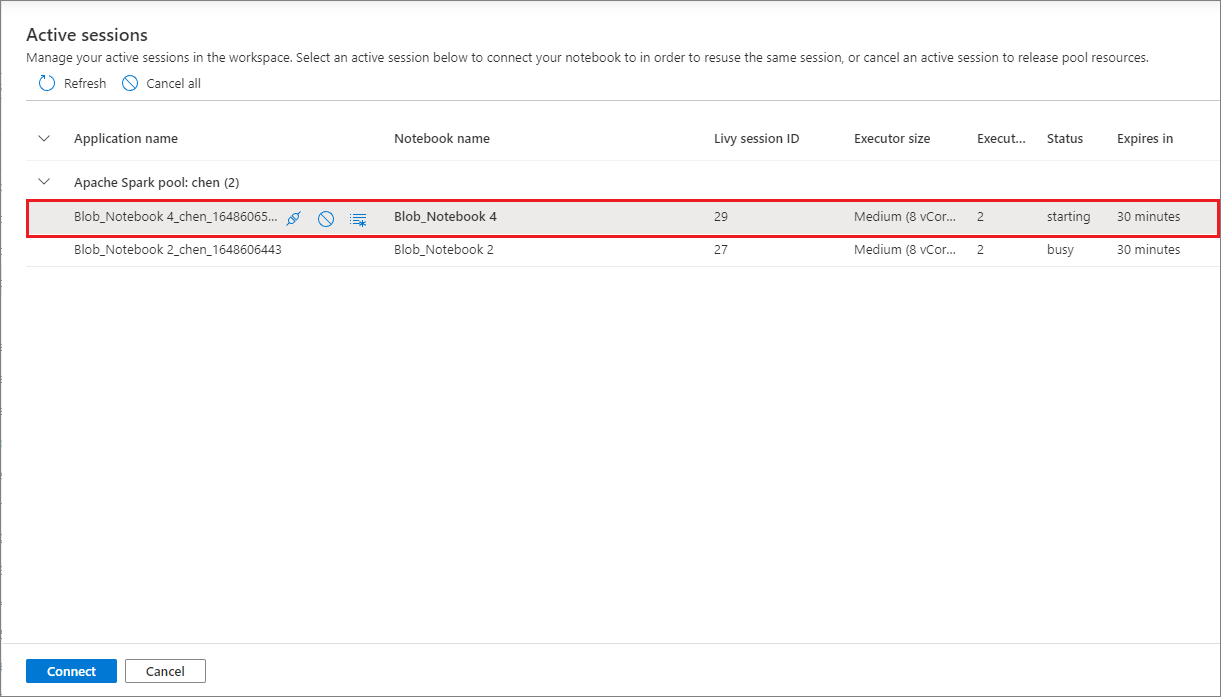
Dans la liste Sessions actives, vous pouvez voir les informations de session et le notebook correspondant actuellement attaché à la session. Vous pouvez détacher le notebook, arrêter la session et afficher la surveillance à partir d’ici. En outre, vous pouvez facilement connecter le notebook sélectionné à une session active dans la liste démarrée à partir d’un autre notebook. La session est alors détachée du notebook précédent (si elle n’est pas inactive), puis attachée à la session en cours.
Journalisation de Python dans le notebook
Vous pouvez trouver des journaux Python et définir différents niveaux de journalisation et formats en suivant l’exemple de code ci-dessous :
import logging
# Customize the logging format for all loggers
FORMAT = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
formatter = logging.Formatter(fmt=FORMAT)
for handler in logging.getLogger().handlers:
handler.setFormatter(formatter)
# Customize log level for all loggers
logging.getLogger().setLevel(logging.INFO)
# Customize the log level for a specific logger
customizedLogger = logging.getLogger('customized')
customizedLogger.setLevel(logging.WARNING)
# logger that use the default global log level
defaultLogger = logging.getLogger('default')
defaultLogger.debug("default debug message")
defaultLogger.info("default info message")
defaultLogger.warning("default warning message")
defaultLogger.error("default error message")
defaultLogger.critical("default critical message")
# logger that use the customized log level
customizedLogger.debug("customized debug message")
customizedLogger.info("customized info message")
customizedLogger.warning("customized warning message")
customizedLogger.error("customized error message")
customizedLogger.critical("customized critical message")
Intégrer un notebook
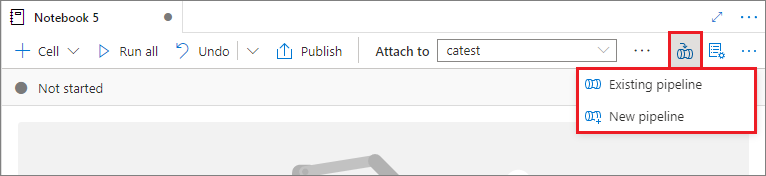
Ajouter un notebook à un pipeline
Sélectionnez le bouton Ajouter au pipeline dans le coin supérieur droit pour ajouter un notebook à un pipeline existant ou créer un pipeline.
Désigner une cellule de paramètres
Pour paramétrer votre notebook, sélectionnez le bouton de sélection (…) pour accéder au menu Plus de commandes au niveau de la barre d’outils de la cellule. Sélectionnez ensuite Activer/désactiver la cellule Paramètres pour désigner la cellule comme cellule de paramètre.
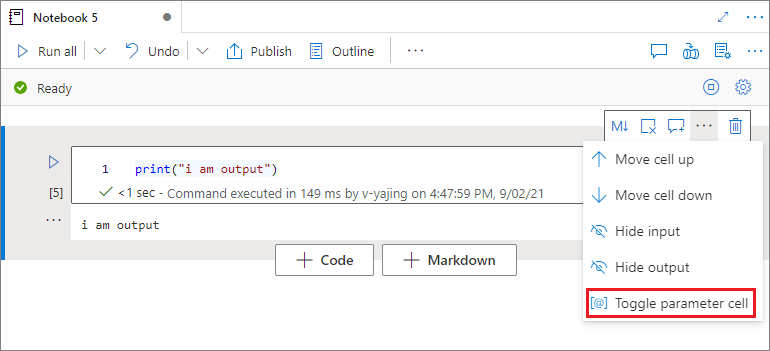
Azure Data Factory recherche la cellule de paramètre et la traite comme cellule par défaut pour les paramètres transmis au moment de l’exécution. Le moteur d’exécution a une nouvelle cellule sous la cellule des paramètres avec des paramètres d’entrée en vue de remplacer les valeurs par défaut.
Attribuer des valeurs de paramètres à partir d’un pipeline
Une fois que vous avez créé le notebook avec paramètres, vous pouvez l’exécuter depuis un pipeline à l’aide de l’activité Notebook Synapse. Après avoir ajouter l’activité à votre canevas de pipeline, vous serez en mesure de définir les valeurs des paramètres dans la section Paramètres de base de l’onglet Paramètres.
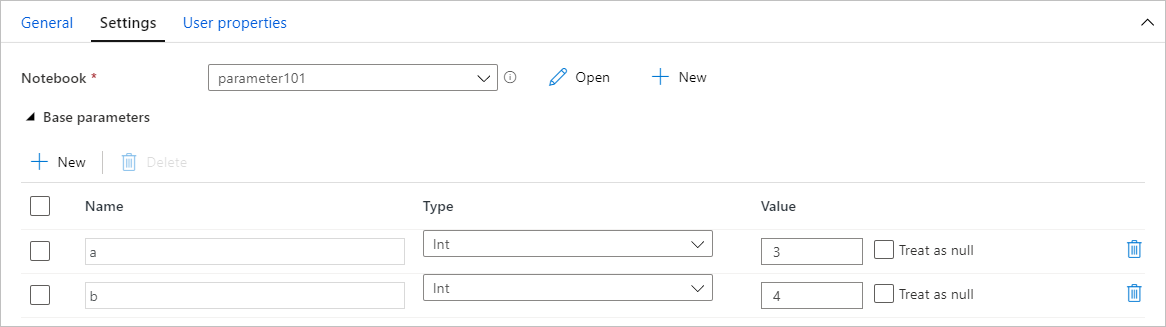
Lors de l’attribution des valeurs de paramètre, vous pouvez utiliser le langage d’expression du pipeline ou des variables système.
Touches de raccourci
Tout comme les notebooks Jupyter, les notebooks Synapse disposent d’une interface utilisateur modale. Le clavier effectue des actions différentes selon le mode dans lequel se trouve la cellule du bloc-notes. Les notebooks Synapse prennent en charge les deux modes suivants pour une cellule de code donnée : le mode de commande et le mode d’édition.
Une cellule est en mode de commande quand elle n’affiche aucun curseur texte vous invitant à saisir. Quand une cellule est en mode de commande, vous pouvez modifier le bloc-notes entier, mais pas taper dans des cellules individuelles. Entrez en mode de commande en appuyant sur
ESCou en utilisant la souris pour sélectionner en dehors de la zone de l’éditeur d’une cellule.
Le mode d’édition est indiqué par un curseur texte qui vous invite à taper dans la zone de l’éditeur. Quand une cellule est en mode d’édition, vous pouvez saisir dans la cellule. Entrez en mode édition en appuyant sur
Enterou en utilisant la souris pour sélectionner la zone de l’éditeur d’une cellule.
Touches de raccourci en mode de commande
| Action | Raccourcis de notebook Synapse |
|---|---|
| Exécuter la cellule active et sélectionner la cellule en dessous | Maj + Entrée |
| Exécuter la cellule active et insérer en dessous | Alt + Entrée |
| Exécuter la cellule active | CTRL+ Enter |
| Sélectionner la cellule au-dessus | Haut |
| Sélectionner la cellule en dessous | Descendre |
| Sélectionner la cellule précédente | K |
| Sélectionner la cellule suivante | J |
| Insérer une cellule au-dessus | Un |
| Insérer une cellule en dessous | B |
| Supprimer les cellules sélectionnées | Maj + D |
| Basculer en mode d’édition | Entrez |
Touches de raccourci en mode d’édition
Les raccourcis clavier suivants vous permettent de naviguer et d’exécuter du code plus facilement dans les notebooks Synapse en mode d’édition.
| Action | Raccourcis de notebook Synapse |
|---|---|
| Déplacer le curseur vers le haut | Haut |
| Déplacer le curseur vers le bas | Descendre |
| Annuler | Ctrl + Z |
| Rétablir | CTRL + Y |
| Commenter/Supprimer un commentaire | Ctrl + / |
| Supprimer le mot précédent | Ctrl + Retour arrière |
| Supprimer le mot suivant | Ctrl + Suppr |
| Atteindre le début de la cellule | Ctrl + Début |
| Atteindre la fin de la cellule | Ctrl + Fin |
| Atteindre le mot à gauche | CTRL + Gauche |
| Atteindre le mot à droite | Ctrl + Droite |
| Sélectionner tout | Ctrl + A |
| Retrait | Ctrl + ] |
| Retrait négatif | Ctrl + [ |
| Passer en mode de commande | Échap |
Étapes suivantes
- Consultez les exemples de notebooks Synapse
- Démarrage rapide : Créer un pool Apache Spark dans Azure Synapse Analytics avec des outils web
- Présentation d’Apache Spark dans Azure Synapse Analytics
- Utiliser .NET pour Apache Spark avec Azure Synapse Analytics
- Documentation .NET pour Apache Spark
- Azure Synapse Analytics