Groupes de placements de proximité
S’applique aux : ✔️ Machines virtuelles Linux ✔️ Machines virtuelles Windows ✔️ Groupes identiques flexibles ✔️ Groupes identiques uniformes
Le fait de placer les machines virtuelles dans une seule région réduit la distance physique entre les instances. Le fait de les placer dans une zone de disponibilité unique les rapproche également physiquement. Cependant, à mesure que l’empreinte Azure augmente, une seule zone de disponibilité peut s’étendre sur plusieurs centres de données physiques, ce qui peut entraîner une latence réseau qui peut affecter votre application.
Pour que les machines virtuelles soient aussi proches que possible, avec la latence la plus faible possible, déployez-les dans un groupe de placements de proximité.
Le groupe de placements de proximité est un regroupement logique utilisé pour s’assurer que les ressources de calcul Azure se trouvent proches les unes des autres. Les groupes de placements de proximité sont utiles pour les charges de travail où une latence faible est requise.
- Latence faible entre les machines virtuelles autonomes.
- La latence faible entre les machines virtuelles dans un groupe à haute disponibilité ou un groupe de machines virtuelles identiques.
- Latence faible entre des machines virtuelles autonomes, des machines virtuelles dans plusieurs groupes à haute disponibilité ou plusieurs groupes identiques. Vous pouvez disposer de plusieurs ressources de calcul dans un seul groupe de placements pour créer une application multicouche.
- Latence faible entre plusieurs couches d’application à l’aide de différents types de matériels. Par exemple, l’exécution du serveur principal à l’aide de la série M dans un groupe à haute disponibilité et du serveur frontal sur une instance de la série D dans un groupe identique, dans un seul groupe de placements de proximité.
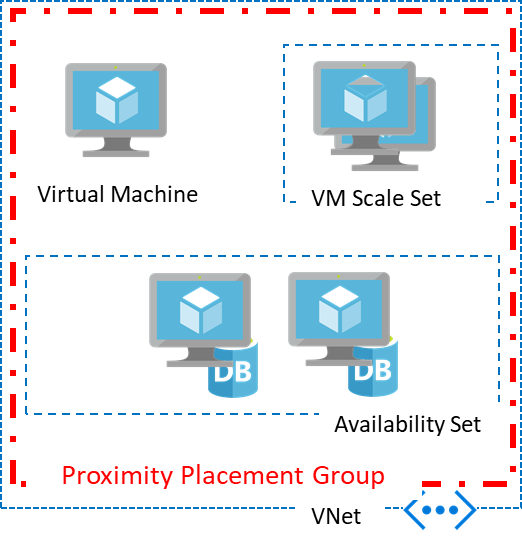
Utilisation des groupes de placements de proximité
Un groupe de placement de proximité est une ressource dans Azure. Vous devez en créer un avant de l’utiliser avec d’autres ressources. Une fois créé, il peut être utilisé avec des machines virtuelles, des groupes à haute disponibilité ou des groupes de machines virtuelles identiques. Vous spécifiez un groupe de placement de proximité lors de la création de ressources de calcul fournissant l’ID de groupe de placement de proximité.
Vous pouvez également déplacer une ressource existante dans un groupe de placement de proximité. Lors du déplacement d’une ressource vers un groupe de placement de proximité, vous devez commencer par arrêter (libérer) la ressource, car elle pourrait être redéployée dans un autre centre de données de la région afin de satisfaire à la contrainte de colocalisation.
Dans le cas des groupes à haute disponibilité et de groupes de machines virtuelles identiques, vous devez définir le groupe de placement de proximité au niveau de la ressource plutôt que sur les machines virtuelles individuelles.
Un groupe de placement de proximité est une contrainte de colocalisation plutôt qu’un mécanisme d’épinglage. Il est épinglé à un centre de données spécifique avec le déploiement de la première ressource à l’utiliser. Une fois que toutes les ressources utilisant le groupe de placement de proximité ont été arrêtées (désallouées) ou supprimées, elles ne sont plus épinglées. Par conséquent, lors de l’utilisation d’un groupe de placement de proximité avec plusieurs séries de machines virtuelles, il est important de spécifier tous les types requis au préalable dans un modèle quand c’est possible, ou de suivre une séquence de déploiement qui améliore vos chances de réussir le déploiement. Si votre déploiement échoue, redémarrez le déploiement avec la taille de machine virtuelle qui a échoué en tant que première taille à déployer.
Utiliser l’intention pour spécifier des tailles de machine virtuelle
Vous pouvez utiliser le paramètre facultatif intent pour fournir les tailles de machine virtuelle souhaitées pour constituer le groupe de placement de proximité. Ce paramètre peut être spécifié au moment de la création d’un groupe de placement de proximité ou il peut être ajouté/modifié lors de la mise à jour d’un groupe de placement de proximité après l’allocation de toutes les machines virtuelles.
Lors de la spécification de intent, vous pouvez également ajouter le paramètre facultatif zone pour spécifier une zone de disponibilité, indiquant que le groupe de placement de proximité doit être créé dans une zone de disponibilité spécifique. Notez les points suivants lors de la fourniture du paramètre zone :
- Le paramètre de zone de disponibilité ne peut être fourni que lors de la création du groupe de placement de proximité et ne peut pas être modifié ultérieurement.
- Le paramètre
zonene peut être utilisé qu’avecintent; il ne peut pas être utilisé seul. - Une seule zone de disponibilité peut être spécifiée.
La création ou la mise à jour du groupe de placement de proximité réussit uniquement lorsqu’au moins un centre de données prend en charge toutes les tailles de machine virtuelle spécifiées dans l’intention. Sinon, la création ou la mise à jour échoue avec « OverconstrainedAllocationRequest », ce qui indique que la combinaison de tailles de machine virtuelle ne peut pas être prise en charge dans un groupe de placement de proximité. L’intention ne fournit aucune réservation ou garantie de capacité. Les tailles de machine virtuelle et la zone indiquées dans intent sont utilisées pour sélectionner un centre de données approprié, ce qui réduit les risques d’échec si la taille de machine virtuelle souhaitée n’est pas disponible dans un centre de données. Des échecs d’allocation peuvent toujours se produire s’il n’y a plus de capacité pour une taille de machine virtuelle au moment du déploiement.
Notes
Pour utiliser l’intention pour vos groupes de placement de proximité, vérifiez que la version de l’API est 2021-11-01 ou ultérieure
Bonnes pratiques lors de l’utilisation de l’intention
- Fournissez une zone de disponibilité pour votre groupe de placement de proximité uniquement lorsque vous fournissez une intention. La fourniture d’une zone de disponibilité sans intention entraîne une erreur lors de la création du groupe de placement de proximité.
- Si vous fournissez une zone de disponibilité dans l’intention, assurez-vous que la zone de disponibilité des machines virtuelles que vous déployez correspond à ce qui est spécifié dans l’intention, afin d’éviter les erreurs lors du déploiement des machines virtuelles.
- La création et l’ajout de machines virtuelles avec des tailles qui ne sont pas incluses dans l’intention sont possibles, mais pas recommandés. La taille n’existe peut-être pas dans le centre de données sélectionné, ce qui peut entraîner des échecs au moment du déploiement des machines virtuelles.
- Pour les groupes de placement existants, nous vous recommandons d’inclure les tailles des machines virtuelles existantes lors de la mise à jour de l’intention, afin d’éviter un échec lors du redéploiement des machines virtuelles.
L’intention peut être affectée par la désaffectation
- Il est possible qu’après avoir créé un groupe de placement de proximité avec l’intention et avant de déployer des machines virtuelles, des événements de maintenance planifiée comme la désaffectation matérielle dans un centre de données Azure peuvent se produire, ce qui entraîne l’indisponibilité de la combinaison de tailles de machine virtuelle spécifiée dans l’intention pour le centre de données. Dans ce cas, une erreur « OverconstrainedAllocationRequest » se produit, même lors du déploiement de machines virtuelles des tailles spécifiées dans l’intention. Vous pouvez essayer d’allouer toutes les ressources du groupe de placement de proximité et de les recréer pour obtenir un centre de données capable de prendre en charge l’intention. S’il n’existe aucun centre de données avec les tailles de machine virtuelle spécifiées après la désaffectation, vous devrez peut-être modifier l’intention pour utiliser une combinaison différente de tailles de machine virtuelle, car la combinaison de tailles de machine virtuelle n’est plus prise en charge.
- Azure peut mettre hors service une famille de machines virtuelles entière ou un ensemble spécifique de tailles de machine virtuelle. Si vous avez une telle taille de machine virtuelle dans l’intention, vous devrez peut-être la supprimer ou la remplacer par une taille différente avant la date de mise hors service de la taille de machine virtuelle d’origine. Sinon, l’intention ne sera plus valide.
Ce qui se passe quand vous utilisez des groupes de placement de proximité
Les groupes de placement de proximité offrent une colocalisation dans le même centre de données. Toutefois, du fait que les groupes de placement de proximité constituent une contrainte de déploiement supplémentaire, des échecs d’allocation peuvent se produire. Dans certains cas d’utilisation, des échecs d’allocation se produisent lors de l’utilisation de groupes de placement de proximité :
- Lorsque vous demandez la première machine virtuelle dans le groupe de placement de proximité, le centre de données est automatiquement sélectionné. Dans certains cas, une deuxième demande taille de machine virtuelle différente peut échouer si celle-ci n’existe pas dans ce centre de données. Dans ce cas, une erreur OverconstrainedAllocationRequest est retournée. Pour éviter cette erreur, essayez de modifier l’ordre dans lequel vous déployez vos tailles de machines virtuelles ou faites en sorte que les deux ressources soient déployées à l’aide d’un seul modèle ARM.
- Si le groupe de placement de proximité est créé avec une intention, les machines virtuelles n’ont pas à être déployées dans un ordre particulier et n’ont pas à être traitées par lot à l’aide d’un modèle ARM unique, car l’intention est utilisée pour sélectionner un centre de données qui prend en charge toutes les tailles de machine virtuelle indiquées dans l’intention.
- Dans le cas de charges de travail élastiques où vous ajoutez et supprimez des instances de machine virtuelle, l’existence d’une contrainte de groupe de placement de proximité sur votre déploiement peut entraîner un échec de satisfaction de la demande générant l’erreur AllocationFailure.
- L’arrêt (désallocation) et le démarrage de vos machines virtuelles en fonction des besoins sont une autre façon d’obtenir l’élasticité. Étant donné que la capacité n’est pas conservée une fois que vous arrêtez (désallouez) une machine virtuelle, le redémarrage de celle-ci peut générer une erreur AllocationFailure.
- Les opérations de démarrage et de redéploiement des machines virtuelles continueront à respecter le groupe de placement de proximité une fois la configuration réussie.
Maintenance planifiée et groupes de placement de proximité
Les événements de maintenance planifiée, tels que la désaffectation de matériel dans un centre de ressources Azure, sont susceptibles d’affecter l’alignement des ressources dans des groupes de placement de proximité. Les ressources peuvent être déplacées vers un autre centre de données, ce qui perturbe les attentes en matière de colocation et de latence associées au groupe de placement de proximité.
Vérifier l’état de l’alignement
Vous pouvez procéder comme suit pour vérifier l’état d’alignement de vos groupes de placement de proximité.
L’état de colocation du groupe de placement de proximité peut être affiché à l’aide du portail, de l’interface CLI et de PowerShell.
Pour PowerShell, l’état de colocation peut être obtenu à l’aide de l’applet de commande Get-AzProximityPlacementGroup en incluant le paramètre facultatif « -ColocationStatus ».
Pour l’interface CLI, l’état de colocation peut être obtenu à l’aide de
az ppg showen incluant le paramètre facultatif « --include-colocation-status ».
Pour chaque groupe de placement de proximité, une propriété état de colocation fournit le résumé de l’état d’alignement actuel des ressources groupées.
Aligned : la ressource se trouve dans la même enveloppe de latence du groupe de placement de proximité.
Unknown : au moins l’une des ressources de machines virtuelles a été libérée. Une fois que celles-ci ont été redémarrées, l’état doit revenir à Aligned.
Not Aligned : au moins une ressource n’est pas alignée avec le groupe de placement de proximité. Les ressources spécifiques qui ne sont pas alignées sont également appelées séparément dans la section liée à l’appartenance.
Pour les groupes à haute disponibilité, vous pouvez voir des informations sur l’alignement des machines virtuelles individuelles sur la page Vue d’ensemble du groupe à haute disponibilité.
Pour les groupes identiques, vous pouvez consulter les informations relatives à l’alignement des instances individuelles dans l’onglet Instances de la page Vue d’ensemble du groupe identique.
Réaligner les ressources
Si un groupe de placement de proximité est Not Aligned, vous pouvez arrêter/libérer, puis redémarrer les ressources affectées. Si la machine virtuelle se trouve dans un groupe à haute disponibilité ou un groupe identique, toutes les machines virtuelles dans le groupe à haute disponibilité ou le groupe identique doivent être arrêtées/libérées avant leur redémarrage.
En cas d’échec d’affectation en raison de contraintes de déploiement, il se peut que vous deviez d’abord arrêter/libérer toutes les ressources du groupe de placement de proximité affecté (y compris les ressources alignées), puis les redémarrer pour restaurer l’alignement.
Meilleures pratiques
- Pour une latence plus faible, utilisez des groupes de placements de proximité avec une mise en réseau accélérée. Pour plus d’informations, consultez les articles Créer une machine virtuelle Windows avec mise en réseau accélérée ou Créer une machine virtuelle Linux avec mise en réseau accélérée.
- Pour éviter de vous retrouver avec du matériel qui ne prend pas en charge toutes les références SKU et tailles de machine virtuelle dont vous avez besoin, utilisez l’intention pour les groupes de placement de proximité. S’il s’agit d’un groupe de placement de proximité déjà existant sans intention, vous pouvez utiliser un modèle ARM unique avec toutes les tailles de machine virtuelle spécifiées pour éviter ce problème.
- Lorsque vous réutilisez un groupe de placements existant dans lequel des machines virtuelles ont été supprimées, attendez que la suppression se termine complètement avant d’y ajouter des machines virtuelles.
- Si la latence est votre première priorité, placez les machines virtuelles dans un groupe de placements de proximité et l’ensemble de la solution dans une zone de disponibilité. Toutefois, si la résilience est votre priorité, répartissez vos instances sur plusieurs zones de disponibilité (un seul groupe de placements de proximité ne peut pas s’étendre sur plusieurs zones).
Étapes suivantes
- Déployez une machine virtuelle dans un groupe de placement de proximité avec Azure CLI ou PowerShell.
- Découvrez comment tester le temps de réponse du réseau.
- Découvrez comment optimiser le débit du réseau.
- Découvrez comment utiliser des groupes de placement de proximité avec des applications SAP.