Disponibilité de SAP HANA dans l’ensemble des régions Azure
Cet article décrit les scénarios concernant la disponibilité de SAP HANA dans différentes régions Azure. En raison de la distance entre les régions Azure, la configuration de la disponibilité de SAP HANA dans plusieurs régions Azure est associée à des considérations particulières.
Raison pour laquelle effectuer un déploiement dans plusieurs régions Azure
Les régions Azure sont souvent séparées par d’importantes distances. En fonction de la région géopolitique, la distance entre des régions Azure peut se compter en centaines de kilomètres, voire en milliers de kilomètres, comme aux États-Unis. En raison de la distance, le trafic réseau entre des ressources déployées dans deux régions Azure différentes subit une importante latence à l’aller et au retour. Cette latence est assez importante pour exclure tout échange de données synchrone entre deux instances SAP HANA sous des charges de travail SAP typiques.
En revanche, les organisations ont souvent une exigence en matière de distance entre l’emplacement du centre de données principal et d’un centre de données secondaire. Une exigence en matière de distance permet de proposer un certain niveau de disponibilité si une catastrophe naturelle touche un vaste emplacement géographique. Nous pouvons citer comme exemple les ouragans qui ont frappé les Caraïbes et la Floride en septembre et octobre 2017. Votre organisation peut avoir une exigence en matière de distance minimum. Pour la plupart des clients Azure, une définition de distance minimum nécessite que vous proposiez de la disponibilité dans l’ensemble des régions Azure. Comme la distance entre deux régions Azure est trop importante pour utiliser le mode de réplication synchrone de HANA, les exigences quant aux objectifs de délai de récupération et de point de récupération pourraient vous obliger à déployer des configurations de disponibilité dans une seule région, puis à procéder à des déploiements supplémentaires dans une seconde région.
Un autre aspect à prendre en compte dans ce scénario est le basculement et la redirection du client. Hypothétiquement, le basculement entre des instances SAP HANA dans deux régions Azure différentes est toujours manuel. Comme le mode de réplication de la réplication du système SAP HANA est défini sur asynchrone, il est possible que les données renseignées dans l’instance HANA principale ne soient pas encore parvenues jusqu’à l’instance HANA secondaire. Par conséquent, le basculement automatique n’est pas une option pour les configurations où la réplication est asynchrone. Même avec un basculement contrôlé manuellement, comme dans un exercice de basculement, vous devez prendre les mesures nécessaires et vous assurer que toutes les données renseignées dans l’instance principale sont parvenues à l’instance secondaire avant de basculer manuellement vers l’autre région Azure.
Le réseau virtuel Azure utilise une autre plage d’adresses IP. Les adresses IP sont déployées dans la seconde région Azure. Par conséquent, vous devez modifier la configuration du client SAP HANA ou créer les étapes nécessaires pour modifier la résolution de noms (cette option est la plus recommandée). Ainsi, les clients sont redirigés vers la nouvelle adresse IP du serveur du site secondaire. Pour plus d’informations, consultez l’article SAP Client Connection Recovery after Takeover (Récupération d’une connexion client après une prise de contrôle).
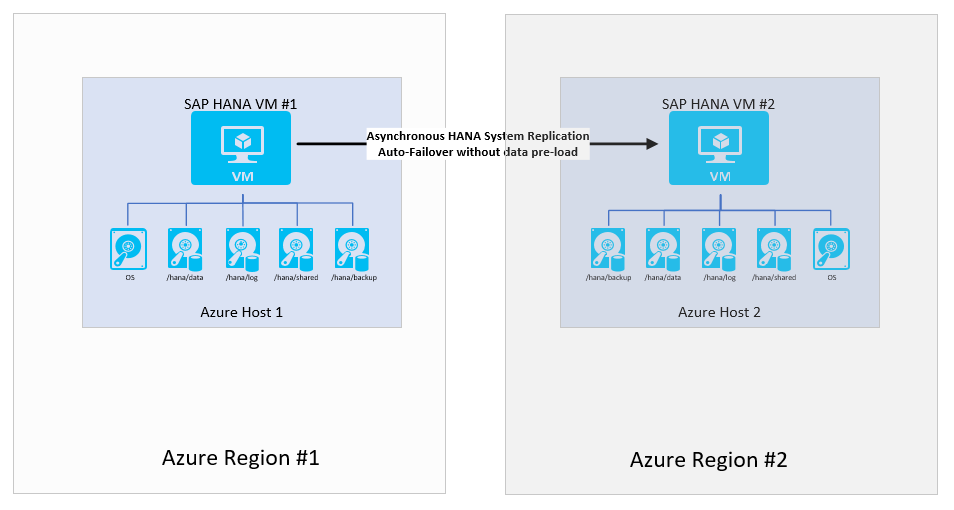
Disponibilité simple entre deux régions Azure
Vous pouvez choisir de ne pas mettre en place de configuration de disponibilité dans une seule région, mais vous avez toujours la possibilité d’avoir la charge de travail prise en charge en cas d’incident. Les systèmes de non-production sont des cas typiques de tels scénarios. Même si vous pouvez tolérer que le système soit hors service pendant une demi-journée, voire une journée entière, vous ne pouvez pas vous permettre qu’il soit indisponible pendant 48 heures ou plus. Pour que la configuration soit moins coûteuse, exécutez un autre système moins important dans la machine virtuelle. L’autre système fonctionne en tant que destination. Vous pouvez également dimensionner la machine virtuelle dans la région secondaire pour qu’elle soit plus petite et choisir de ne pas précharger les données. Étant donné que le basculement se fait manuellement et qu’il comporte de nombreuses étapes supplémentaires pour basculer la pile d’applications complète, le temps supplémentaire nécessaire pour arrêter, redimensionner et redémarrer la machine virtuelle est acceptable.
Si vous utilisez le scénario consistant à partager la cible DR avec un système d'assurance qualité dans une seule machine virtuelle, vous devez tenir compte des considérations suivantes :
- Il existe deux modes d’opération avec delta_datashipping et logreplay, disponibles pour ce type de scénario
- Les deux modes d’opération ont des besoins en mémoire différents sans préchargement des données
- Il se peut que delta_datashipping nécessite beaucoup moins de mémoire sans l’option de préchargement que logreplay. Consultez le chapitre 4.3 du document SAP Comment effectuer une réplication de système pour SAP HANA
- La mémoire requise pour le mode d’opération logreplay sans préchargement n’est pas déterministe et dépend des structures columnstore chargées. Dans les cas extrêmes, vous pouvez avoir besoin de 50 % de la mémoire de l’instance principale. La mémoire pour le mode d’opération logreplay ne dépend pas du fait que vous ayez choisi l’ensemble de données préchargées ou non.
Remarque
Dans cette configuration, vous ne pouvez pas fournir un objectif de point de récupération égal à 0, car le mode de réplication du système HANA est asynchrone. Si vous devez fournir un objectif de point de récupération égal à 0, cette configuration n’est pas celle à choisir.
Une petite modification que vous pouvez effectuer dans la configuration peut être de configurer les données pour qu’elles soient préchargées. Toutefois, comme le basculement est une opération manuelle, et que les couches d’application doivent aussi être déplacées dans la deuxième région, le préchargement des données peut ne pas être logique.
Combiner la disponibilité dans une région et entre des régions
Une combinaison de disponibilité dans une région et entre des régions peut être obtenue via ces facteurs :
- Un objectif de point de récupération égal à 0 dans une région Azure.
- L’organisation n’est pas prête ou capable d’avoir des opérations globales affectées par une catastrophe naturelle majeure qui touche une région plus vaste. C’était le cas ces dernières années avec les ouragans qui ont frappé les Caraïbes.
- Des réglementations qui exigent des distances entre des sites principaux et secondaires clairement au-delà de ce que les zones de disponibilité Azure peuvent fournir.
Dans ce cas, vous pouvez configurer ce que SAP appelle une configuration de réplication système multiniveau SAP HANA à l’aide de la réplication système HANA. L’architecture ressemblerait à :

SAP a introduit la réplication de système multi-cibles avec HANA 2.0 SPS3. La réplication de système multi-cibles offre certains avantages dans les scénarios de mise à jour. Par exemple, le site de récupération d’urgence (région 2) n’est pas affecté lorsque le site haute disponibilité secondaire est arrêté pour la maintenance ou les mises à jour. Vous trouverez plus d’informations sur la réplication de système multi-cibles HANA sur le portail d’aide SAP. L’architecture possible avec la réplication multi-cibles ressemblerait à :
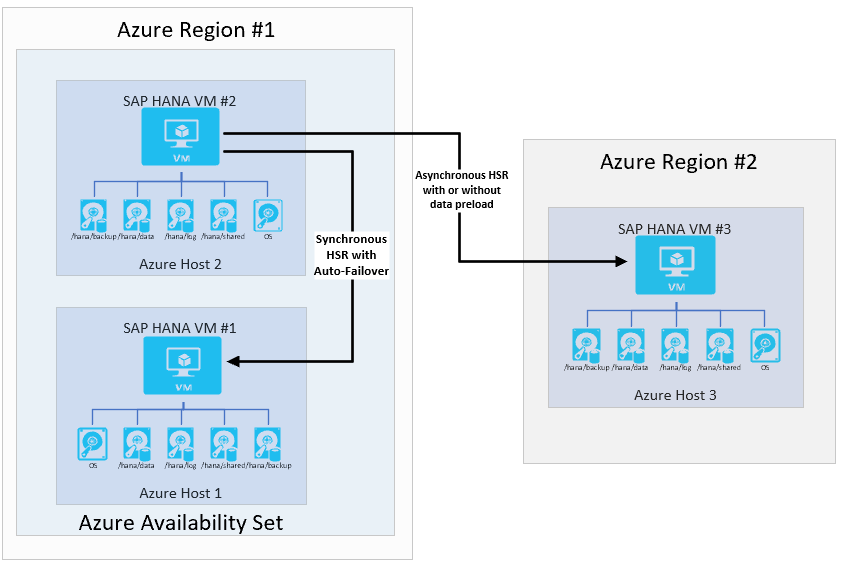
Si l’organisation dispose de la configuration requise pour la préparation de la haute disponibilité dans la région Azure secondaire (récupération d’urgence), l’architecture ressemblerait à :
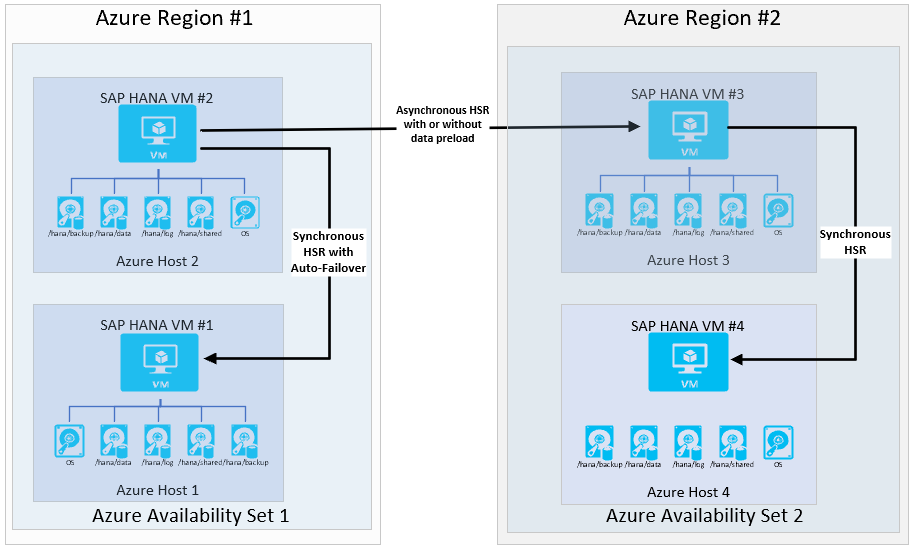
Avec le mode d’opération logreplay, cette configuration offre un objectif de point de récupération égal à 0, avec un objectif de délai de récupération faible, dans la région primaire. La configuration fournit également un objectif de point de récupération acceptable en cas de migration vers la région secondaire. Les délais d’objectifs de délai de récupération dans la région secondaire dépendent du préchargement ou non des données. De nombreux clients utilisent la machine virtuelle dans la région secondaire pour exécuter un test du système. Dans ce cas d’usage, les données ne peuvent pas être préchargées.
Important
Les modes d’opération entre les différents niveaux doivent être homogènes. Vous ne pouvez pas utiliser logreplay comme mode d’opération entre le niveau 1 et le niveau 2 et delta_datashipping pour fournir le niveau 3. Vous pouvez uniquement choisir un mode d’opération ou l’autre, qui doit être cohérent pour tous les niveaux. Étant donné que delta_datashipping ne permet pas d’offrir un objectif de point de récupération égal à 0, le seul mode d’opération raisonnable pour ce type de configuration multiniveau reste logreplay. Pour plus d’informations sur les modes de fonctionnement et sur quelques restrictions, consultez l’article SAP Operation Modes for SAP HANA System Replication (Modes de fonctionnement pour la réplication du système SAP HANA).
Étapes suivantes
Pour obtenir des instructions sur la mise en place de ces configurations dans Azure, consultez :