Utilisation des mosaïques
Vous pouvez utiliser le tiling pour optimiser l’accélération de votre application. Le mosaïque divise les threads en sous-ensembles ou vignettes rectangulaires égaux. Si vous utilisez une taille de vignette appropriée et un algorithme en mosaïque, vous pouvez obtenir encore plus d’accélération à partir de votre code AMP C++. Les composants de base de la mosaïne sont les suivants :
tile_staticVariables. Le principal avantage de la mosaïne est le gain de performances de l’accèstile_static. L’accès aux données entile_staticmémoire peut être beaucoup plus rapide que l’accès aux données dans l’espace global (arrayouarray_viewles objets). Une instance d’unetile_staticvariable est créée pour chaque vignette, et tous les threads de la vignette ont accès à la variable. Dans un algorithme en mosaïque classique, les données sont copiées danstile_staticla mémoire une fois à partir de la mémoire globale, puis accessibles plusieurs fois à partir de latile_staticmémoire.tile_barrier ::wait, méthode. Un appel pour
tile_barrier::waitinterrompre l’exécution du thread actuel jusqu’à ce que tous les threads de la même vignette atteignent l’appel .tile_barrier::waitVous ne pouvez pas garantir l’ordre dans lequel les threads s’exécutent, uniquement qu’aucun thread de la vignette ne s’exécute après l’appel jusqu’àtile_barrier::waitce que tous les threads aient atteint l’appel. Cela signifie qu’à l’aide de latile_barrier::waitméthode, vous pouvez effectuer des tâches sur une base de vignette par vignette plutôt que sur une base thread par thread. Un algorithme de mosaïque classique a du code pour initialiser latile_staticmémoire de l’ensemble de la vignette suivie d’un appel àtile_barrier::wait. Le code suivanttile_barrier::waitcontient des calculs qui nécessitent l’accès à toutes lestile_staticvaleurs.Indexation locale et globale. Vous avez accès à l’index du thread par rapport à l’intégralité
array_viewouarrayà l’objet et à l’index par rapport à la vignette. L’utilisation de l’index local permet de faciliter la lecture et le débogage de votre code. En règle générale, vous utilisez l’indexation locale pour accédertile_staticaux variables et l’indexation globale pour accéderarrayaux variables.array_viewclasse tiled_extent et classe tiled_index. Vous utilisez un
tiled_extentobjet au lieu d’unextentobjet dans l’appelparallel_for_each. Vous utilisez untiled_indexobjet au lieu d’unindexobjet dans l’appelparallel_for_each.
Pour tirer parti du mosaïque, votre algorithme doit partitionner le domaine de calcul en vignettes, puis copier les données de vignette dans tile_static des variables pour un accès plus rapide.
Exemple d’index globaux, de mosaïques et locaux
Remarque
Les en-têtes AMP C++ sont déconseillés à partir de Visual Studio 2022 version 17.0.
L’inclusion d’en-têtes AMP génère des erreurs de génération. Définissez _SILENCE_AMP_DEPRECATION_WARNINGS avant d’inclure tous les en-têtes AMP pour silence les avertissements.
Le diagramme suivant représente une matrice 8x9 de données organisées en vignettes 2x3.
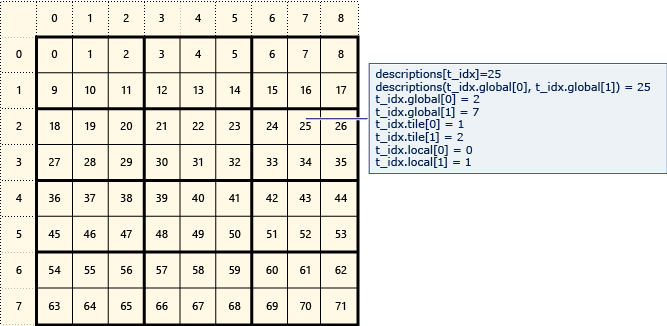
L’exemple suivant affiche les index globaux, mosaïques et locaux de cette matrice en mosaïque. Un array_view objet est créé à l’aide d’éléments de type Description. Contient Description les index globaux, mosaïques et locaux de l’élément dans la matrice. Code de l’appel pour parallel_for_each définir les valeurs des index globaux, mosaïques et locaux de chaque élément. La sortie affiche les valeurs dans les Description structures.
#include <iostream>
#include <iomanip>
#include <Windows.h>
#include <amp.h>
using namespace concurrency;
const int ROWS = 8;
const int COLS = 9;
// tileRow and tileColumn specify the tile that each thread is in.
// globalRow and globalColumn specify the location of the thread in the array_view.
// localRow and localColumn specify the location of the thread relative to the tile.
struct Description {
int value;
int tileRow;
int tileColumn;
int globalRow;
int globalColumn;
int localRow;
int localColumn;
};
// A helper function for formatting the output.
void SetConsoleColor(int color) {
int colorValue = (color == 0) 4 : 2;
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), colorValue);
}
// A helper function for formatting the output.
void SetConsoleSize(int height, int width) {
COORD coord;
coord.X = width;
coord.Y = height;
SetConsoleScreenBufferSize(GetStdHandle(STD_OUTPUT_HANDLE), coord);
SMALL_RECT* rect = new SMALL_RECT();
rect->Left = 0;
rect->Top = 0;
rect->Right = width;
rect->Bottom = height;
SetConsoleWindowInfo(GetStdHandle(STD_OUTPUT_HANDLE), true, rect);
}
// This method creates an 8x9 matrix of Description structures.
// In the call to parallel_for_each, the structure is updated
// with tile, global, and local indices.
void TilingDescription() {
// Create 72 (8x9) Description structures.
std::vector<Description> descs;
for (int i = 0; i < ROWS * COLS; i++) {
Description d = {i, 0, 0, 0, 0, 0, 0};
descs.push_back(d);
}
// Create an array_view from the Description structures.
extent<2> matrix(ROWS, COLS);
array_view<Description, 2> descriptions(matrix, descs);
// Update each Description with the tile, global, and local indices.
parallel_for_each(descriptions.extent.tile< 2, 3>(),
[=] (tiled_index< 2, 3> t_idx) restrict(amp)
{
descriptions[t_idx].globalRow = t_idx.global[0];
descriptions[t_idx].globalColumn = t_idx.global[1];
descriptions[t_idx].tileRow = t_idx.tile[0];
descriptions[t_idx].tileColumn = t_idx.tile[1];
descriptions[t_idx].localRow = t_idx.local[0];
descriptions[t_idx].localColumn= t_idx.local[1];
});
// Print out the Description structure for each element in the matrix.
// Tiles are displayed in red and green to distinguish them from each other.
SetConsoleSize(100, 150);
for (int row = 0; row < ROWS; row++) {
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Value: " << std::setw(2) << descriptions(row, column).value << " ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Tile: " << "(" << descriptions(row, column).tileRow << "," << descriptions(row, column).tileColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Global: " << "(" << descriptions(row, column).globalRow << "," << descriptions(row, column).globalColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Local: " << "(" << descriptions(row, column).localRow << "," << descriptions(row, column).localColumn << ") ";
}
std::cout << "\n";
std::cout << "\n";
}
}
int main() {
TilingDescription();
char wait;
std::cin >> wait;
}
Le travail principal de l’exemple est dans la définition de l’objet array_view et l’appel à parallel_for_each.
Le vecteur de
Descriptionstructures est copié dans un objet 8x9array_view.La
parallel_for_eachméthode est appelée avec untiled_extentobjet comme domaine de calcul. L’objettiled_extentest créé en appelant laextent::tile()méthode de ladescriptionsvariable. Les paramètres de type de l’appel àextent::tile(),<2,3>spécifient que les vignettes 2x3 sont créées. Ainsi, la matrice 8x9 est mosaïque en 12 vignettes, quatre lignes et trois colonnes.La
parallel_for_eachméthode est appelée à l’aide d’untiled_index<2,3>objet (t_idx) comme index. Les paramètres de type de l’index (t_idx) doivent correspondre aux paramètres de type du domaine de calcul (descriptions.extent.tile< 2, 3>()).Lorsque chaque thread est exécuté, l’index
t_idxretourne des informations sur la vignette dans laquelle le thread se trouve (tiled_index::tilepropriété) et l’emplacement du thread dans la vignette (tiled_index::localpropriété).
Synchronisation de vignettes : tile_static et tile_barrier ::wait
L’exemple précédent illustre la disposition et les index de mosaïque, mais n’est pas en soi très utile. Le mosaïque devient utile lorsque les vignettes font partie intégrante de l’algorithme et exploitent tile_static des variables. Étant donné que tous les threads d’une vignette ont accès aux tile_static variables, les appels à utiliser tile_barrier::wait pour synchroniser l’accès tile_static aux variables. Bien que tous les threads d’une vignette aient accès aux tile_static variables, il n’existe aucun ordre garanti d’exécution des threads dans la vignette. L’exemple suivant montre comment utiliser tile_static des variables et la tile_barrier::wait méthode pour calculer la valeur moyenne de chaque vignette. Voici les clés permettant de comprendre l’exemple :
RawData est stocké dans une matrice 8x8.
La taille de la vignette est de 2 x 2. Cela crée une grille 4x4 de vignettes et les moyennes peuvent être stockées dans une matrice 4x4 à l’aide d’un
arrayobjet. Il n’existe qu’un nombre limité de types que vous pouvez capturer par référence dans une fonction restreinte AMP. Laarrayclasse est l’une d’entre elles.La taille de matrice et la taille de l’échantillon sont définies à l’aide
#defined’instructions, car les paramètres de type àarray,array_viewetextenttiled_indexdoivent être des valeurs constantes. Vous pouvez également utiliser desconst int staticdéclarations. En guise d’avantage supplémentaire, il est trivial de modifier la taille de l’échantillon pour calculer la moyenne sur les vignettes 4x4.Un
tile_statictableau 2x2 de valeurs float est déclaré pour chaque vignette. Bien que la déclaration se trouve dans le chemin du code de chaque thread, un seul tableau est créé pour chaque vignette de la matrice.Il existe une ligne de code pour copier les valeurs de chaque vignette dans le
tile_statictableau. Pour chaque thread, une fois la valeur copiée dans le tableau, l’exécution sur le thread s’arrête en raison de l’appel àtile_barrier::wait.Lorsque tous les threads d’une vignette ont atteint la barrière, la moyenne peut être calculée. Étant donné que le code s’exécute pour chaque thread, il existe une
ifinstruction pour calculer uniquement la moyenne sur un thread. La moyenne est stockée dans la variable moyenne. La barrière est essentiellement la construction qui contrôle les calculs par vignette, autant que vous pouvez utiliser uneforboucle.Les données de la
averagesvariable, car il s’agit d’unarrayobjet, doivent être copiées vers l’hôte. Cet exemple utilise l’opérateur de conversion de vecteur.Dans l’exemple complet, vous pouvez modifier SAMPLESIZE sur 4 et le code s’exécute correctement sans aucune autre modification.
#include <iostream>
#include <amp.h>
using namespace concurrency;
#define SAMPLESIZE 2
#define MATRIXSIZE 8
void SamplingExample() {
// Create data and array_view for the matrix.
std::vector<float> rawData;
for (int i = 0; i < MATRIXSIZE * MATRIXSIZE; i++) {
rawData.push_back((float)i);
}
extent<2> dataExtent(MATRIXSIZE, MATRIXSIZE);
array_view<float, 2> matrix(dataExtent, rawData);
// Create the array for the averages.
// There is one element in the output for each tile in the data.
std::vector<float> outputData;
int outputSize = MATRIXSIZE / SAMPLESIZE;
for (int j = 0; j < outputSize * outputSize; j++) {
outputData.push_back((float)0);
}
extent<2> outputExtent(MATRIXSIZE / SAMPLESIZE, MATRIXSIZE / SAMPLESIZE);
array<float, 2> averages(outputExtent, outputData.begin(), outputData.end());
// Use tiles that are SAMPLESIZE x SAMPLESIZE.
// Find the average of the values in each tile.
// The only reference-type variable you can pass into the parallel_for_each call
// is a concurrency::array.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before you calculate the average.
t_idx.barrier.wait();
// If you remove the if statement, then the calculation executes for every
// thread in the tile, and makes the same assignment to averages each time.
if (t_idx.local[0] == 0 && t_idx.local[1] == 0) {
for (int trow = 0; trow < SAMPLESIZE; trow++) {
for (int tcol = 0; tcol < SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE * SAMPLESIZE);
}
});
// Print out the results.
// You cannot access the values in averages directly. You must copy them
// back to a CPU variable.
outputData = averages;
for (int row = 0; row < outputSize; row++) {
for (int col = 0; col < outputSize; col++) {
std::cout << outputData[row*outputSize + col] << " ";
}
std::cout << "\n";
}
// Output for SAMPLESIZE = 2 is:
// 4.5 6.5 8.5 10.5
// 20.5 22.5 24.5 26.5
// 36.5 38.5 40.5 42.5
// 52.5 54.5 56.5 58.5
// Output for SAMPLESIZE = 4 is:
// 13.5 17.5
// 45.5 49.5
}
int main() {
SamplingExample();
}
Conditions de concurrence
Il peut être tentant de créer une tile_static variable nommée total et d’incrémenter cette variable pour chaque thread, comme suit :
// Do not do this.
tile_static float total;
total += matrix[t_idx];
t_idx.barrier.wait();
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
Le premier problème avec cette approche est que tile_static les variables ne peuvent pas avoir d’initialiseurs. Le deuxième problème est qu’il existe une condition de concurrence sur l’affectation à total, car tous les threads de la vignette ont accès à la variable dans aucun ordre particulier. Vous pouvez programmer un algorithme pour autoriser un seul thread à accéder au total à chaque barrière, comme indiqué ci-dessous. Toutefois, cette solution n’est pas extensible.
// Do not do this.
tile_static float total;
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
total = matrix[t_idx];
}
t_idx.barrier.wait();
if (t_idx.local[0] == 0&& t_idx.local[1] == 1) {
total += matrix[t_idx];
}
t_idx.barrier.wait();
// etc.
Clôtures de mémoire
Il existe deux types d’accès à la mémoire qui doivent être synchronisés : l’accès à la mémoire globale et tile_static l’accès à la mémoire. Un concurrency::array objet alloue uniquement de la mémoire globale. Un concurrency::array_view peut référencer la mémoire globale, tile_static la mémoire ou les deux, selon la façon dont elle a été construite. Il existe deux types de mémoire qui doivent être synchronisés :
mémoire globale
tile_static
Une clôture de mémoire garantit que les accès à la mémoire sont disponibles pour d’autres threads dans la vignette de thread et que les accès à la mémoire sont exécutés en fonction de l’ordre du programme. Pour vous assurer que cela, les compilateurs et les processeurs ne réorganisent pas les lectures et les écritures sur la clôture. En C++ AMP, une clôture de mémoire est créée par un appel à l’une des méthodes suivantes :
méthode tile_barrier ::wait : crée une clôture autour de la mémoire globale et
tile_staticde la mémoire.méthode tile_barrier ::wait_with_all_memory_fence : crée une clôture autour de la mémoire globale et
tile_staticde la mémoire.méthode tile_barrier ::wait_with_global_memory_fence : crée une clôture autour de la mémoire globale uniquement.
méthode tile_barrier ::wait_with_tile_static_memory_fence : crée une clôture autour de la mémoire uniquement
tile_static.
L’appel de la clôture spécifique dont vous avez besoin peut améliorer les performances de votre application. Le type de barrière affecte la façon dont le compilateur et les instructions de réorganisation matérielle. Par exemple, si vous utilisez une clôture de mémoire globale, elle s’applique uniquement aux accès à la mémoire globale et, par conséquent, le compilateur et le matériel peuvent réorganiser les lectures et les écritures dans tile_static des variables sur les deux côtés de la clôture.
Dans l’exemple suivant, la barrière synchronise les écritures dans tileValues, une tile_static variable. Dans cet exemple, tile_barrier::wait_with_tile_static_memory_fence est appelé au lieu de tile_barrier::wait.
// Using a tile_static memory fence.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before calculating the average.
t_idx.barrier.wait_with_tile_static_memory_fence();
// If you remove the if statement, then the calculation executes
// for every thread in the tile, and makes the same assignment to
// averages each time.
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
for (int trow = 0; trow <SAMPLESIZE; trow++) {
for (int tcol = 0; tcol <SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
}
});
Voir aussi
C++ AMP (C++ Accelerated Massive Parallelism)
tile_static, mot clé
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour