Problématiques et solutions pour la gestion des données distribuées
Conseil
Ce contenu est un extrait du livre électronique « .NET Microservices Architecture for Containerized .NET Applications », disponible sur .NET Docs ou sous forme de PDF téléchargeable gratuitement et pouvant être lu hors ligne.

Défi n° 1 : Comment définir les limites de chaque microservice
Définir les limites d’un microservice est sans doute la première problématique à laquelle tout le monde est confronté. Chaque microservice doit être un composant de votre application et chaque microservice doit être autonome, avec tous les avantages et les défis induits. Mais comment identifier ces limites ?
Vous devez d’abord vous concentrer sur les modèles de domaine logique de l’application et les données associées. Essayez d’identifier les îlots de données découplés et les différents contextes au sein d’une même application. Chaque contexte peut avoir un langage métier différent (des termes métier différents). Les contextes doivent être définis et gérés indépendamment. Les termes et entités utilisés dans ces différents contextes peuvent sembler similaires, mais vous pouvez découvrir que dans un contexte spécifique, un concept métier d’un contexte est utilisé à des fins différentes dans un autre contexte, et qu’il peut même porter un autre nom. Par exemple, un utilisateur peut s’appeler un utilisateur dans un contexte d’identité ou d’appartenance, un client dans un contexte de gestion de la relation clientèle, un acheteur dans un contexte de prise de commande, etc.
La façon dont vous identifiez les limites entre plusieurs contextes d’application avec un domaine différent pour chaque contexte correspond exactement à la façon dont vous pouvez identifier les limites pour chaque microservice métier, et son modèle de domaine et ses données associés. Vous essayez toujours de minimiser le couplage entre ces microservices. Ce guide présente plus en détails cette identification et cette conception du modèle de domaine plus loin dans la section Identification des limites du modèle de domaine pour chaque microservice.
Défi n°2 : Comment créer des requêtes qui récupèrent des données à partir de plusieurs microservices
Une deuxième problématique est la façon d’implémenter des requêtes qui extraient des données de plusieurs microservices, tout en évitant des communication intensives entre les microservices et les applications clientes distantes. Par exemple, un écran d’une application mobile a besoin d’afficher les informations utilisateur détenues par des microservices distincts gérant respectivement le panier d’achat, le catalogue et l’identité des utilisateurs. Un autre exemple est un rapport complexe impliquant plusieurs tables qui se trouvent dans plusieurs microservices. La bonne solution dépend de la complexité des requêtes. Dans tous les cas, il vous faut un moyen d’agréger les informations pour améliorer l’efficacité des communications de votre système. Les solutions les plus répandues sont les suivantes :
Passerelle d’API. Pour une agrégation de données simples provenant de plusieurs microservices qui ont des bases de données différentes, l’approche recommandée est un microservice d’agrégation, connu sous le nom de passerelle d’API. Vous devez cependant être prudent dans l’implémentation de ce modèle, car il peut être un goulot d’étranglement dans votre système, et il peut violer le principe d’autonomie des microservices. Pour atténuer ce risque, vous pouvez avoir plusieurs passerelles d’API réduites, chacune étant consacrée à une « section » verticale ou un domaine d’activité du système. Le modèle de passerelle d’API est détaillé plus loin dans la section relative à la passerelle d’API.
Fédération GraphQL :GraphQL Federation est une possibilité à envisager si vos microservices utilisent déjà GraphQL. La fédération vous permet de définir des « sous-graphes » à partir d’autres services et de les composer en un « supergraphe » agrégé qui fonctionne comme un schéma autonome.
CQRS (Command Query Responsibility Segregation) avec des tables de requête/lectures. Une autre solution pour agréger des données provenant de plusieurs microservices est le modèle de vue matérialisée. Dans cette approche, vous générez à l’avance (vous préparez des données dénormalisées avant que les requêtes réelles ne soient effectuées) une table en lecture seule avec les données détenues par plusieurs microservices. La table a un format adapté aux besoins de l’application cliente.
Considérons par exemple l’écran d’une application mobile. Si vous avez une seule base de données, vous pouvez extraire en une seule fois les données pour cet écran en utilisant une requête SQL qui effectue une jointure complexe impliquant plusieurs tables. Cependant, quand vous avez plusieurs bases de données et que chaque base de données est détenue par un microservice différent, vous ne pouvez pas interroger ces bases de données et créer une jointure SQL. Votre requête complexe devient un vrai défi. Vous pouvez répondre à cette exigence à l’aide d’une approche CQRS : vous créez une table dénormalisée dans une autre base de données, utilisée seulement pour les requêtes. La table peut être conçue spécifiquement pour les données dont vous avez besoin pour la requête complexe, avec une relation un-à-un entre les champs nécessaires à l’écran de votre application et les colonnes de la table de requête. Elle peut également servir pour la création de rapports.
Cette approche résout non seulement le problème d’origine (comment faire des requêtes et des jointures entre des microservices), mais elle améliore également considérablement les performances en comparaison d’une jointure complexe, car vous avez déjà les données nécessaires à l’application dans la table de requête. Bien sûr, l’utilisation de CQRS (séparation des responsabilités en matière de commande et de requête) avec des tables de requêtes/lectures signifie davantage de travail de développement et l’application d’une cohérence à terme. Néanmoins, les exigences de performances et de haute scalabilité dans les scénarios collaboratifs (ou les scénarios de concurrence, selon le point de vue) doivent vous inciter à appliquer CQRS à plusieurs bases de données.
« Données à froid » dans les bases de données centrales. Pour les rapports et les requêtes complexes ne nécessitant pas de données en temps réel, une approche courante consiste à exporter vos « données chaudes » (données transactionnelles des microservices) en tant que « données froides » dans des bases de données volumineuses utilisées seulement pour la création de rapports. Ce système de base de données centrale peut être un système basé sur Big Data, comme Hadoop, un entrepôt de données basé sur Azure SQL Data Warehouse, ou même une base de données SQL utilisée seulement pour les rapports (si la taille n’est pas un problème).
Gardez à l’esprit que cette base de données centralisée doit être utilisée seulement pour les requêtes et les rapports qui n’ont pas besoin de données en temps réel. Les mises à jour et les transactions d’origine, qui constituent votre source de référence, doivent être effectuées dans les données de vos microservices. Vous allez synchroniser les données via une communication pilotée par les événements (traitée dans les sections suivantes) ou via d’autres outils d’importation/exportation de l’infrastructure de base de données. Si vous utilisez une communication pilotée par les événements, ce processus d’intégration est similaire à la façon dont vous propagez les données comme cela a été décrit précédemment pour les tables de requête CQRS.
Toutefois, si la conception de votre application implique d’agréger constamment les informations provenant de plusieurs microservices pour des requêtes complexes, cela peut être le symptôme d’une mauvaise conception : un microservice doit être aussi isolé que possible des autres microservices. (Cela exclut les rapports/analyses qui doivent toujours utiliser des bases de données centrales à froid.) Le fait d’avoir ce problème peut souvent être une raison de fusionner des microservices. Vous devez équilibrer l’autonomie de l’évolution et du déploiement de chaque microservice avec des dépendances fortes, la cohésion et l’agrégation des données.
Défi n°3 : Comment assurer la cohérence entre plusieurs microservices
Comme indiqué précédemment, les données détenues par chaque microservice sont privées pour ce microservice et sont accessibles seulement via son API de microservice. Ainsi, le problème est de savoir comment implémenter des processus métier de bout en bout tout en conservant la cohérence entre plusieurs microservices.
Pour analyser ce problème, prenons l’exemple de l’application de référence eShopOnContainers. Le microservice Catalog (Catalogue) gère les informations relatives à tous les produits, notamment leur prix. Le microservice Basket (Panier) gère les données temporelles relatives aux articles que les utilisateurs ajoutent à leurs paniers d’achat, notamment le prix des articles au moment où ils ont été ajoutés au panier. Quand le prix d’un produit est mis à jour dans le catalogue, ce prix doit l’être également dans les paniers actifs qui contiennent le produit correspondant. De plus, le système doit en principe avertir l’utilisateur en lui indiquant que le prix d’un article particulier a changé depuis son ajout au panier.
Dans une hypothétique version monolithique de cette application, quand le prix change dans la table des produits, le sous-système de catalogue peut simplement utiliser une transaction ACID pour mettre à jour le prix actuel dans la table Basket (Panier).
Toutefois, dans une application basée sur les microservices, les tables Order (Commande) et Product (Produit) appartiennent à leurs microservices respectifs. Aucun microservice ne doit jamais inclure de tables/stockage appartenant à un autre microservice dans ses propres transactions, pas même dans les requêtes directes, comme indiqué sur la figure 4-9.
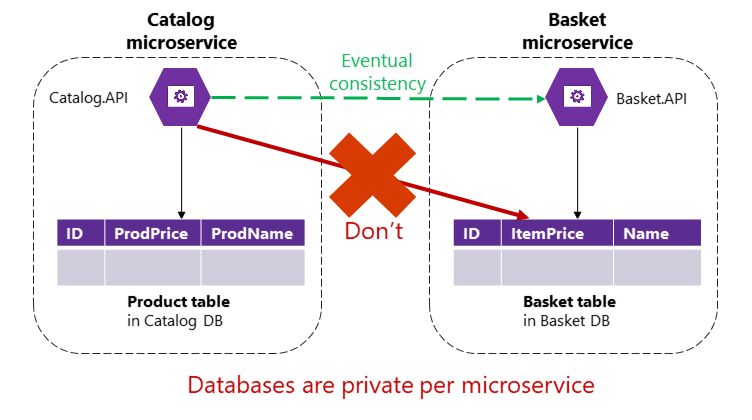
Figure 4-9. Un microservice ne peut pas accéder directement à une table dans un autre microservice
Le microservice Catalog ne doit pas mettre à jour directement la table Basket, car elle est détenue par le microservice Basket. Pour permettre une mise à jour du microservice Basket, le microservice Catalog doit utiliser une cohérence à terme probablement basée sur une communication asynchrone, par exemple celle des événements d’intégration (communication basée sur des messages et des événements). Voici comment l’application de référence eShopOnContainers effectue ce type de cohérence parmi plusieurs microservices.
Comme le montre le théorème CAP, vous devez choisir entre la disponibilité et la cohérence forte d’ACID. La plupart des scénarios basés sur des microservices demandent la disponibilité et une haute scalabilité, plutôt qu’une cohérence forte. Les applications critiques doivent rester opérationnelles, et les développeurs peuvent contourner les problèmes liés à la cohérence forte en utilisant des techniques permettant de travailler avec une cohérence faible ou à terme. Il s’agit de l’approche adoptée par la plupart des architectures basée sur les microservices.
De plus, les transactions de style ACID ou avec validation en deux phases ne sont pas seulement en opposition avec les principes des microservices : la plupart des bases de données NoSQL (par exemple Azure Cosmos DB, MongoDB, etc.) ne prennent pas en charge les transactions avec validation en deux phases, ce qui est typique des scénarios de bases de données distribuées. Cependant, conserver la cohérence des données entre les services et les bases de données est fondamental. Cette problématique concerne aussi la façon de propager les changements parmi plusieurs microservices quand certaines données doivent être redondantes, par exemple quand vous devez avoir le nom ou la description du produit dans le microservice Catalog et dans le microservice Basket.
Une bonne solution pour résoudre ce problème est d’utiliser la cohérence à terme entre les microservices, articulée autour d’une communication pilotée par les événements et d’un système de publication-abonnement. Ces rubriques sont traitées dans la section Communication asynchrone pilotée par les événements plus loin dans ce guide.
Défi n°4 : Comment concevoir la communication entre les limites de microservice
La communication entre les limites des microservices est une vraie problématique. Dans ce contexte, la communication ne fait pas référence au protocole à utiliser (HTTP et REST, AMQP, messagerie, etc.). Au lieu de cela, elle concerne le style de communication que vous devez utiliser, et en particulier comment vos microservices doivent être couplés. Selon le niveau de couplage, l’impact d’une défaillance sur votre système varie considérablement.
Dans un système distribué comme une application basée sur des microservices, avec un si grand nombre d’artefacts concernés et avec des services distribués sur plusieurs serveurs ou plusieurs hôtes, certains composants finissent à leur tour par connaître une défaillance. Une défaillance partielle et même des interruptions plus importantes vont se produire. Vous devez donc concevoir les microservices et leur mode de communication en tenant compte des risques courants liés à ce type de système distribué.
Une approche courante consiste à implémenter des microservices basés sur HTTP (REST), en raison de leur simplicité. Une approche basée sur HTTP est parfaitement acceptable ; le problème est ici la façon dont vous l’utilisez. Si vous utilisez des requêtes et des réponses HTTP simplement pour interagir avec vos microservices à partir d’applications clientes ou de passerelles d’API, cela convient. Mais si vous créez de longues chaînes d’appels HTTP synchrones entre des microservices, en communiquant entre leurs limites comme si les microservices étaient des objets dans une application monolithique, votre application finira par rencontrer des problèmes.
Par exemple, supposons que votre application cliente effectue un appel d’API HTTP à un microservice individuel, comme le microservice Ordering. Si le microservice Ordering appelle à son tour d’autres microservices en utilisant le protocole HTTP dans le même cycle de requête-réponse, vous créez une chaîne d’appels HTTP. Cela peut initialement sembler raisonnable. Des points importants sont cependant à prendre en compte si vous suivez cette voie :
Blocage et faibles performances. En raison de la nature synchrone du protocole HTTP, la requête d’origine n’obtient pas de réponse tant que tous les appels HTTP internes ne sont pas achevés. Imaginez dès lors que le nombre de ces appels augmente considérablement et qu’en même temps, un des appels HTTP intermédiaires à un microservice soit bloqué. Le résultat est que les performances sont impactées et que la scalabilité globale est affectée de façon exponentielle avec l’augmentation du nombre de requêtes HTTP.
Couplage des microservices avec HTTP. Vous ne devez pas coupler des microservices métier avec d’autres microservices métier. Dans l’idéal, ils ne doivent rien « savoir » sur l’existence d’autres microservices. Si votre application s’appuie sur le couplage de microservices comme dans l’exemple, parvenir à une autonomie des microservices est pratiquement impossible.
Défaillance dans un des microservices. Si vous avez implémenté une chaîne de microservices liés par des appels HTTP, quand un des microservices connaît une défaillance (et ce sera le cas pour tous au final), la chaîne entière des microservices échoue. Un système basé sur des microservices doit être conçu pour continuer à fonctionner aussi bien que possible en cas de défaillances partielles. Même si vous implémentez une logique cliente qui utilise les nouvelles tentatives avec des mécanismes de backoff exponentiel ou de disjoncteur, plus les chaînes d’appels HTTP sont complexes, plus l’implémentation d’une stratégie de défaillance basée sur le protocole HTTP est complexe.
En fait, si vos microservices internes communiquent en créant des chaînes de requêtes HTTP comme indiqué auparavant, cela signifie que vous avez une application monolithique. Toutefois, celle-ci est basée plutôt sur le protocole HTTP entre processus et non sur des mécanismes de communication intraprocessus.
Par conséquent, pour atteindre à l’autonomie des microservices et avoir une meilleure résilience, vous devez minimiser l’utilisation de chaînes de communication de demande/réponse entre les microservices. Il est recommandé d’utiliser seulement une interaction asynchrone pour la communication entre les microservices, via une communication asynchrone basée sur des messages et des événements, ou via une interrogation HTTP (asynchrone) indépendante du cycle de requête-réponse HTTP d’origine.
L’utilisation d’une communication asynchrone est détaillée plus loin dans ce guide, dans les sections L’intégration de microservices asynchrones implique l’autonomie des microservices et Communication asynchrone basée sur des messages.
Ressources supplémentaires
Théorème CAP
https://en.wikipedia.org/wiki/CAP_theoremCohérence éventuelle
https://en.wikipedia.org/wiki/Eventual_consistencyData Consistency Primer (Manuel d’introduction à la cohérence des données)
https://learn.microsoft.com/previous-versions/msp-n-p/dn589800(v=pandp.10)Martin Fowler. CQRS (Command and Query Responsibility Segregation)
https://martinfowler.com/bliki/CQRS.htmlVue matérialisée
https://learn.microsoft.com/azure/architecture/patterns/materialized-viewCharles Row. ACID et BASE : Le pH de décalage du traitement des transactions de base de données
https://www.dataversity.net/acid-vs-base-the-shifting-ph-of-database-transaction-processing/Transaction de compensation
https://learn.microsoft.com/azure/architecture/patterns/compensating-transactionUdi Dahan. Service Oriented Composition
https://udidahan.com/2014/07/30/service-oriented-composition-with-video/
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour