Considérations relatives aux performances pour EF 4, 5 et 6
Par David Obando, Eric Dettinger et autres
Date de publication : avril 2012
Dernière mise à jour : mai 2014
1. Introduction
Les frameworks de mappage objet-relationnel (ORM) constituent un moyen pratique de fournir une abstraction pour l’accès aux données dans une application orientée objet. Pour les applications .NET, le framework ORM recommandé par Microsoft est Entity Framework. Avec toute abstraction cependant, les performances peuvent devenir un problème.
Ce livre blanc a été écrit pour montrer les considérations relatives aux performances lors du développement d’applications à l’aide d’Entity Framework, pour donner aux développeurs une idée des algorithmes internes Entity Framework qui peuvent affecter les performances, et pour fournir des conseils en matière d’investigation et d’amélioration des performances dans les applications qui utilisent Entity Framework. Il existe déjà un certain nombre de bonnes rubriques sur les performances disponibles sur le web, et nous avons également essayé de pointer vers ces ressources dans la mesure du possible.
Les performances sont un sujet épineux. Ce livre blanc est destiné à vous aider à prendre des décisions relatives aux performances pour vos applications qui utilisent Entity Framework. Nous avons inclus certaines métriques de test pour illustrer les performances, mais ces métriques ne sont pas conçues comme des indicateurs absolus des performances que vous observerez dans votre application.
À des fins pratiques, ce document part du principe qu’Entity Framework 4 est exécuté sous .NET 4.0 et Entity Framework 5 et 6 sont exécutés sous .NET 4.5. De nombreuses améliorations des performances apportées pour Entity Framework 5 résident dans les composants principaux fournis avec .NET 4.5.
Entity Framework 6 est une version hors bande qui ne dépend pas des composants Entity Framework fournis avec .NET. Entity Framework 6 fonctionne à la fois sur .NET 4.0 et .NET 4.5, et peut offrir un grand avantage de performances à ceux qui n’ont pas procédé à la mise à niveau à partir de .NET 4.0, mais souhaitent disposer des bits Entity Framework les plus récents dans leur application. Lorsque ce document mentionne Entity Framework 6, il fait référence à la dernière version disponible au moment de sa rédaction, c’est-à-dire la version 6.1.0.
2. Exécution de requête froide ou chaude
La première fois qu’une requête est effectuée sur un modèle donné, Entity Framework effectue beaucoup de travail en arrière-plan pour charger et valider le modèle. Nous faisons souvent référence à cette première requête en tant que requête « froide ». Les requêtes ultérieures sur un modèle déjà chargé sont appelées requêtes « chaudes, et sont beaucoup plus rapides.
Examinons de manière générale l’endroit où le temps est consacré lors de l’exécution d’une requête à l’aide d’Entity Framework, et voyons où les choses s’améliorent dans Entity Framework 6.
Première exécution de requête : requête froide
| Écritures de code | Action | Impact sur les performances d’EF4 | Impact sur les performances d’EF5 | Impact sur les performances d’EF6 |
|---|---|---|---|---|
using(var db = new MyContext()) { |
Création de contexte | Moyenne | Moyenne | Faible |
var q1 = from c in db.Customers where c.Id == id1 select c; |
Création d’expression de requête | Faible | Faible | Faible |
var c1 = q1.First(); |
Exécution de requête LINQ | - Chargement des métadonnées : élevé mais mis en cache - Génération de vue : potentiellement très élevée mais mise en cache - Évaluation des paramètres : moyenne - Traduction de requête : moyenne - Génération de matérialiseur : moyenne mais mise en cache - Exécution de requêtes de base de données : potentiellement élevée + Connection.Open + Command.ExecuteReader + DataReader.Read Matérialisation d’objet : moyenne - Recherche d’identité : moyenne |
- Chargement des métadonnées : élevé mais mis en cache - Génération de vue : potentiellement très élevée mais mise en cache - Évaluation des paramètres : faible - Traduction de requête : moyenne mais mise en cache - Génération de matérialiseur : moyenne mais mise en cache - Exécution de requêtes de base de données : potentiellement élevée (meilleures requêtes dans certaines situations) + Connection.Open + Command.ExecuteReader + DataReader.Read Matérialisation d’objet : moyenne - Recherche d’identité : moyenne |
- Chargement des métadonnées : élevé mais mis en cache - Génération de vue : moyenne mais mise en cache - Évaluation des paramètres : faible - Traduction de requête : moyenne mais mise en cache - Génération de matérialiseur : moyenne mais mise en cache - Exécution de requêtes de base de données : potentiellement élevée (meilleures requêtes dans certaines situations) + Connection.Open + Command.ExecuteReader + DataReader.Read Matérialisation d’objet : moyenne (plus rapide qu’EF5) - Recherche d’identité : moyenne |
} |
Connection.Close | Faible | Faible | Faible |
Deuxième exécution de requête : requête chaude
| Écritures de code | Action | Impact sur les performances d’EF4 | Impact sur les performances d’EF5 | Impact sur les performances d’EF6 |
|---|---|---|---|---|
using(var db = new MyContext()) { |
Création de contexte | Moyenne | Moyenne | Faible |
var q1 = from c in db.Customers where c.Id == id1 select c; |
Création d’expression de requête | Faible | Faible | Faible |
var c1 = q1.First(); |
Exécution de requête LINQ | - - - Évaluation des paramètres : moyenne - - - Exécution de requêtes de base de données : potentiellement élevée + Connection.Open + Command.ExecuteReader + DataReader.Read Matérialisation d’objet : moyenne - Recherche d’identité : moyenne |
- - - Évaluation des paramètres : faible - - - Exécution de requêtes de base de données : potentiellement élevée (meilleures requêtes dans certaines situations) + Connection.Open + Command.ExecuteReader + DataReader.Read Matérialisation d’objet : moyenne - Recherche d’identité : moyenne |
- - - Évaluation des paramètres : faible - - - Exécution de requêtes de base de données : potentiellement élevée (meilleures requêtes dans certaines situations) + Connection.Open + Command.ExecuteReader + DataReader.Read Matérialisation d’objet : moyenne (plus rapide qu’EF5) - Recherche d’identité : moyenne |
} |
Connection.Close | Faible | Faible | Faible |
Il existe plusieurs façons de réduire le coût des performances des requêtes froides et chaudes, et nous allons les examiner dans la section suivante. Plus précisément, nous allons examiner la réduction du coût du chargement de modèle dans les requêtes froides à l’aide de vues prégénérées, ce qui devrait aider à atténuer les dégradations de performances observées pendant la génération de vue. Pour les requêtes chaudes, nous aborderons la mise en cache du plan de requête, les requêtes sans suivi, et différentes options d’exécution de requête.
2.1 Qu’est-ce que la génération de vue ?
Pour comprendre la génération de vue, nous devons d’abord comprendre ce que sont les « vues de mappage ». Les vues de mappage sont des représentations exécutables des transformations spécifiées dans le mappage pour chaque jeu d’entités et association. En interne, ces vues de mappage prennent la forme d’arborescences des requêtes canoniques. Il existe deux types de vues de mappage :
- Vues de requête : elles représentent la transformation nécessaire pour passer du schéma de base de données au modèle conceptuel.
- Vues de mise à jour : elles représentent la transformation nécessaire pour passer du modèle conceptuel au schéma de base de données.
N’oubliez pas que le modèle conceptuel peut différer du schéma de base de données de différentes façons. Par exemple, une table unique peut être utilisée pour stocker les données pour deux types d’entités différents. L’héritage et les mappages non triviaux jouent un rôle dans la complexité des vues de mappage.
Le processus de calcul de ces vues en fonction de la spécification du mappage est ce que nous appelons la génération de vue. La génération de vue peut être effectuée dynamiquement lorsqu’un modèle est chargé ou au moment de la génération à l’aide de « vues prégénées » ; ces dernières sont sérialisées sous la forme d’instructions Entity SQL dans un fichier C# ou VB.
Lorsque les vues sont générées, elles sont également validées. Du point de vue des performances, la grande majorité des coûts de génération de vue est en fait la validation des vues qui garantit que les connexions entre les entités sont logiques et ont la cardinalité correcte pour toutes les opérations prises en charge.
Lorsqu’une requête sur un jeu d’entités est exécutée, la requête est combinée avec la vue de requête correspondante, et le résultat de cette composition est exécuté via le compilateur de plan pour créer la représentation de la requête que le magasin de stockage peut comprendre. Pour SQL Server, le résultat final de cette compilation sera une instruction T-SQL SELECT. La première fois qu’une mise à jour sur un jeu d’entités est effectuée, la vue de mise à jour est exécutée via un processus similaire afin de la transformer en instructions DML pour la base de données cible.
2.2 Facteurs qui affectent les performances de la génération de vue
Les performances de l’étape de génération de vue dépendent non seulement de la taille de votre modèle, mais également de la façon dont il est interconnecté. Si deux entités sont connectées via une chaîne d’héritage ou une association, elles sont dites « connectées ». De même, si deux tables sont connectées via une clé étrangère, elles sont connectées. À mesure que le nombre de tables et d’entités connectées dans vos schémas augmente, le coût lié à la génération de vue augmente.
L’algorithme que nous utilisons pour générer et valider des vues est exponentiel dans le pire des cas, bien que nous utilisions certaines optimisations pour améliorer cela. Les principaux facteurs qui semblent affecter négativement les performances sont les suivants :
- Taille du modèle, faisant référence au nombre d’entités et à la quantité d’associations entre ces entités
- Complexité du modèle, en particulier l’héritage impliquant un grand nombre de types
- Utilisation d’associations indépendantes au lieu d’associations de clés étrangères
Pour les petits modèles simples, le coût peut être assez faible pour ne pas se donner la peine d’utiliser des vues prégénérées. À mesure que la taille et la complexité du modèle augmentent, plusieurs options sont disponibles pour réduire le coût de la génération et de la validation de vue.
2.3 Utilisation de vues prégénérées pour réduire le temps de chargement du modèle
Pour plus d’informations sur l’utilisation de vues prégénérées sur Entity Framework 6, accédez à Vues de mappage prégénérées.
2.3.1 Vues prégénérées à l’aide d’Entity Framework Power Tools Community Edition
Vous pouvez utiliser Entity Framework 6 Power Tools Community Edition pour générer des vues de modèles EDMX et Code First en cliquant avec le bouton droit sur le fichier de classe de modèle et en utilisant le menu Entity Framework pour sélectionner « Générer des vues ». Entity Framework Power Tools Community Edition fonctionne uniquement sur les contextes dérivés de DbContext.
2.3.2 Comment utiliser des vues prégénérées avec un modèle créé par EDMGen
EDMGen est un utilitaire fourni avec .NET, qui fonctionne avec Entity Framework 4 et 5 mais pas avec Entity Framework 6. EDMGen vous permet de générer un fichier de modèle, la couche objet et les vues à partir de la ligne de commande. L’une des sorties est un fichier de vues dans le langage de votre choix, VB ou C#. Il s’agit d’un fichier de code contenant des extraits de code Entity SQL pour chaque jeu d’entités. Pour activer les vues prégénérées, vous incluez simplement le fichier dans votre projet.
Si vous apportez manuellement des modifications aux fichiers de schéma du modèle, vous devez recréer le fichier de vues. Pour ce faire, exécutez EDMGen avec l’indicateur /mode:ViewGeneration.
2.3.3 Comment utiliser des vues prégénérées avec un fichier EDMX
Vous pouvez également utiliser EDMGen pour générer des vues pour un fichier EDMX (la rubrique MSDN référencée plus haut explique comment ajouter un événement de pré-génération à cette fin), mais cela est compliqué et il existe certains cas où ce n’est pas possible. Il est généralement plus facile d’utiliser un modèle T4 pour générer les vues lorsque votre modèle se trouve dans un fichier edmx.
Le blog de l’équipe ADO.NET contient un billet qui décrit comment utiliser un modèle T4 pour la génération de vue (<https://learn.microsoft.com/archive/blogs/adonet/how-to-use-a-t4-template-for-view-generation>). Ce billet inclut un modèle qui peut être téléchargé et ajouté à votre projet. Le modèle a été écrit pour la première version d’Entity Framework. Son fonctionnement n’est donc pas garanti avec les dernières versions d’Entity Framework. Toutefois, vous pouvez télécharger un ensemble de modèles de génération de vue plus à jour pour Entity Framework 4 et 5 à partir de la galerie Visual Studio :
- VB.NET : <http://visualstudiogallery.msdn.microsoft.com/118b44f2-1b91-4de2-a584-7a680418941d>
- C#: <http://visualstudiogallery.msdn.microsoft.com/ae7730ce-ddab-470f-8456-1b313cd2c44d>
Si vous utilisez Entity Framework 6, vous pouvez obtenir les modèles T4 de génération de vue à partir de la galerie Visual Studio à l’adresse <http://visualstudiogallery.msdn.microsoft.com/18a7db90-6705-4d19-9dd1-0a6c23d0751f>.
2.4 Réduction du coût de la génération de vue
L’utilisation de vues prégénérées déplace le coût de la génération de vue du chargement de modèle (moment d’exécution) au moment de la conception. Bien que cela améliore les performances de démarrage au moment de l’exécution, vous devrez toujours faire face aux tracas liés à la génération de vue pendant le développement. Il existe plusieurs astuces supplémentaires qui peuvent aider à réduire le coût de la génération de vue, à la fois au moment de la compilation et au moment de l’exécution.
2.4.1 Utilisation d’associations de clés étrangères pour réduire le coût de la génération de vue
Nous avons observé un certain nombre de cas où le fait de basculer des associations indépendantes vers des associations de clés étrangères dans le modèle a considérablement raccourci le temps consacré à la génération de vue.
Pour illustrer cette amélioration, nous avons généré deux versions du modèle Navision à l’aide d’EDMGen. Remarque : Consultez l’annexe C pour obtenir une description du modèle Navision. Le modèle Navision est intéressant pour cet exercice en raison de sa très grande quantité d’entités et de relations entre elles.
Une version de ce modèle très volumineux a été générée avec des associations de clés étrangères, et l’autre a été générée avec des associations indépendantes. Nous avons ensuite chronométré le temps nécessaire pour générer les vues pour chaque modèle. Le test Entity Framework 5 a utilisé la méthode GenerateViews() de la classe EntityViewGenerator pour générer les vues, tandis que le test Entity Framework 6 a utilisé la méthode GenerateViews() de la classe StorageMappingItemCollection. Cela est dû à la restructuration du code qui s’est produite dans le codebase Entity Framework 6.
À l’aide d’Entity Framework 5, la génération de vue pour le modèle avec des clés étrangères a pris 65 minutes dans une machine de laboratoire. On ignore combien de temps il aurait fallu pour générer les vues pour le modèle qui utilisait des associations indépendantes. Nous avons laissé le test s’exécuter pendant plus d’un mois avant de redémarrer la machine dans notre laboratoire pour installer les mises à jour mensuelles.
À l’aide d’Entity Framework 6, la génération de vue pour le modèle avec des clés étrangères a pris 28 secondes sur la même machine de laboratoire. La génération de vue pour le modèle qui utilise des associations indépendantes a pris 58 secondes. Les améliorations apportées à Entity Framework 6 sur son code de génération de vue signifient que de nombreux projets n’auront pas besoin de vues prégénérées pour offrir des temps de démarrage plus courts.
Il est important de noter que la prégénération des vues dans Entity Framework 4 et 5 peut être effectuée avec EDMGen ou Entity Framework Power Tools. Pour la génération de vue Entity Framework 6, vous pouvez le faire via Entity Framework Power Tools ou par programmation, comme décrit dans Vues de mappage prégénérées.
2.4.1.1 Comment utiliser des clés étrangères au lieu d’associations indépendantes
Lorsque vous utilisez EDMGen ou le Concepteur d’entités dans Visual Studio, vous obtenez des clés étrangères par défaut, et une seule case à cocher ou un seul indicateur de ligne de commande suffit pour basculer entre les clés étrangères et les associations indépendantes.
Si vous avez un grand modèle Code First, l’utilisation d’associations indépendantes aura le même effet sur la génération de vue. Vous pouvez éviter cet impact en incluant des propriétés de clés étrangères sur les classes de vos objets dépendants, bien que certains développeurs considéreront cela comme polluant leur modèle objet. Vous trouverez plus d’informations sur ce sujet dans <http://blog.oneunicorn.com/2011/12/11/whats-the-deal-with-mapping-foreign-keys-using-the-entity-framework/>.
| Lors de l’utilisation de | Effectuez l’opération suivante |
|---|---|
| Concepteur d'entités | Après avoir ajouté une association entre deux entités, vérifiez que vous disposez d’une contrainte référentielle. Les contraintes référentielles indiquent à Entity Framework qu’il faut utiliser des clés étrangères plutôt que des associations indépendantes. Pour plus de détails, consultez <https://learn.microsoft.com/archive/blogs/efdesign/foreign-keys-in-the-entity-framework>. |
| EDMGen | Lorsque vous utilisez EDMGen pour générer vos fichiers à partir de la base de données, vos clés étrangères sont respectées et ajoutées au modèle telles quelles. Pour plus d’informations sur les différentes options exposées par EDMGen, consultez http://msdn.microsoft.com/library/bb387165.aspx. |
| Code First | Consultez la section « Convention de relation » de la rubrique Conventions Code First pour plus d’informations sur l’ajout de propriétés de clés étrangères sur les objets dépendants lors de l’utilisation de Code First. |
2.4.2 Déplacement de votre modèle vers un assembly distinct
Lorsque votre modèle est inclus directement dans le projet de votre application et que vous générez des vues par le biais d’un événement prédéfini ou d’un modèle T4, la génération et la validation de vue se produisent chaque fois que le projet est reconstruit, même si le modèle n’a pas été modifié. Si vous déplacez le modèle vers un assembly distinct et que vous le référencez à partir du projet de votre application, vous pouvez apporter d’autres modifications à votre application sans avoir à reconstruire le projet contenant le modèle.
Remarque : Lors du déplacement de votre modèle vers des assemblys distincts, n’oubliez pas de copier les chaînes de connexion du modèle dans le fichier de configuration d’application du projet client.
2.4.3 Désactiver la validation d’un modèle basé sur edmx
Les modèles EDMX sont validés au moment de la compilation, même si le modèle est inchangé. Si votre modèle a déjà été validé, vous pouvez supprimer la validation au moment de la compilation en affectant la valeur false à la propriété « Valider lors de la génération » dans la fenêtre des propriétés. Lorsque vous modifiez votre mappage ou votre modèle, vous pouvez réactiver temporairement la validation pour vérifier vos modifications.
Notez que des améliorations des performances ont été apportées au concepteur Entity Framework pour Entity Framework 6, et que le coût de la validation lors de la génération est beaucoup plus faible que dans les versions précédentes du concepteur.
3 Mise en cache dans Entity Framework
Entity Framework intègre les formes suivantes de mise en cache :
- Mise en cache d’objets : l’ObjectStateManager intégré à une instance ObjectContext effectue le suivi en mémoire des objets récupérés à l’aide de cette instance. Ceci est également connu sous le nom de « mise en cache de premier niveau ».
- Mise en cache du plan de requête : réutilisation de la commande de magasin générée lorsqu’une requête est exécutée plusieurs fois.
- Mise en cache des métadonnées : partage des métadonnées pour un modèle entre différentes connexions au même modèle.
Outre les caches fournis par défaut par EF, un type spécial de fournisseur de données ADO.NET appelé fournisseur de services Wrapper peut également être utilisé pour étendre Entity Framework avec un cache pour les résultats récupérés à partir de la base de données. Ceci est également appelé « mise en cache de deuxième niveau ».
3.1 Mise en cache d’objets
Par défaut, lorsqu’une entité est retournée dans les résultats d’une requête, juste avant qu’EF la matérialise, ObjectContext vérifie si une entité avec la même clé a déjà été chargée dans son ObjectStateManager. Si une entité avec les mêmes clés est déjà présente, EF l’inclut dans les résultats de la requête. Bien qu’EF émette toujours la requête sur la base de données, ce comportement peut éviter la majeure partie du coût lié à la matérialisation multiple de l’entité.
3.1.1 Obtention d’entités à partir du cache d’objets à l’aide de DbContext Find
Contrairement à une requête régulière, la méthode Find dans DbSet (API incluses pour la première fois dans EF 4.1) effectue une recherche en mémoire avant même d’émettre la requête sur la base de données. Il est important de noter que deux instances ObjectContext différentes ont deux instances ObjectStateManager différentes, ce qui signifie qu’elles ont des caches d’objets distincts.
La méthode Find utilise la valeur de clé primaire pour tenter de trouver une entité suivie par le contexte. Si l’entité n’est pas dans le contexte, une requête est exécutée et évaluée par rapport à la base de données, et la valeur Null est retournée si l’entité est introuvable dans le contexte ou dans la base de données. Notez que Find retourne également les entités qui ont été ajoutées au contexte mais qui n’ont pas encore été enregistrées dans la base de données.
Il existe une considération en matière de performances à prendre en compte lors de l’utilisation de Find. Les appels à cette méthode par défaut déclenchent une validation du cache d’objets afin de détecter les modifications qui sont toujours en attente de validation dans la base de données. Ce processus peut être très coûteux s’il existe un très grand nombre d’objets dans le cache d’objets ou dans un graphe d’objets volumineux ajouté au cache d’objets, mais il peut également être désactivé. Dans certains cas, vous pourrez observer une différence sensible lors de l’appel de la méthode Find lorsque vous désactivez la détection automatique des modifications. Une différence encore plus sensible est perçue lorsque l’objet se trouve dans le cache, par rapport au cas où il doit être récupéré à partir de la base de données. Voici un exemple de graphe avec des mesures prises à l’aide de certains de nos microbenchmarks, exprimées en millisecondes, avec une charge de 5 000 entités :

Exemple de Find avec détection automatique des modifications désactivée :
context.Configuration.AutoDetectChangesEnabled = false;
var product = context.Products.Find(productId);
context.Configuration.AutoDetectChangesEnabled = true;
...
Voici ce que vous devez prendre en compte lors de l’utilisation de la méthode Find :
- Si l’objet n’est pas dans le cache, les avantages offerts par Find sont annulés, mais la syntaxe est toujours plus simple qu’une requête par clé.
- Si la détection automatique des modifications est activée, le coût de la méthode Find peut augmenter sensiblement, en fonction de la complexité de votre modèle et de la quantité d’entités dans votre cache d’objets.
Gardez également à l’esprit que Find retourne uniquement l’entité que vous recherchez, et qu’elle ne charge pas automatiquement ses entités associées si elles ne sont pas déjà dans le cache d’objets. Si vous avez besoin de récupérer des entités associées, vous pouvez utiliser une requête par clé avec chargement hâtif. Pour plus d’informations, consultez 8.1 Chargement différé vs. chargement hâtif.
3.1.2 Problèmes de performances lorsque le cache d’objets a de nombreuses entités
Le cache d’objets permet d’augmenter la réactivité globale d’Entity Framework. Toutefois, lorsqu’il a une très grande quantité d’entités chargées, il peut affecter certaines opérations telles qu’Add, Remove, Find, Entry, SaveChanges et bien plus encore. En particulier, les opérations qui déclenchent un appel à DetectChanges seront négativement affectées par des caches d’objets très volumineux. DetectChanges synchronise le graphe d’objets avec le gestionnaire d’état d’objet, et ses performances seront déterminées directement par la taille du graphe d’objet. Pour plus d’informations sur DetectChanges, consultez Suivi des modifications dans les entités POCO.
Lors de l’utilisation d’Entity Framework 6, les développeurs peuvent appeler AddRange et RemoveRange directement sur un DbSet, au lieu d’effectuer une itération sur une collection et d’appeler Add une fois par instance. L’avantage offert par l’utilisation des méthodes de plage est que le coût de DetectChanges n’est payé qu’une seule fois pour l’ensemble complet d’entités, et non une fois par entité ajoutée.
3.2 Mise en cache du plan de requête
La première fois qu’une requête est exécutée, elle passe par le compilateur de plan interne afin de traduire la requête conceptuelle en la commande de magasin (par exemple, le T-SQL exécuté lors de l’exécution sur SQL Server). Si la mise en cache du plan de requête est activée, la prochaine fois que la requête est exécutée, la commande de magasin est récupérée directement à partir du cache du plan de requête pour l’exécution, en contournant le compilateur de plan.
Le cache du plan de requête est partagé entre les instances ObjectContext dans le même AppDomain. Vous n’avez pas besoin d’utiliser une instance ObjectContext pour tirer parti de la mise en cache du plan de requête.
3.2.1 Quelques remarques sur la mise en cache du plan de requête
- Le cache du plan de requête est partagé pour tous les types de requêtes : Entity SQL, LINQ to Entities et objets CompiledQuery.
- Par défaut, la mise en cache du plan de requête est activée pour les requêtes Entity SQL, qu’elles soient exécutées via EntityCommand ou par le biais d’une ObjectQuery. Elle est également activée par défaut pour les requêtes LINQ to Entities dans Entity Framework sur .NET 4.5 et dans Entity Framework 6.
- La mise en cache du plan de requête peut être désactivée en affectant la valeur false à la propriété EnablePlanCaching (sur EntityCommand ou ObjectQuery). Par exemple :
var query = from customer in context.Customer
where customer.CustomerId == id
select new
{
customer.CustomerId,
customer.Name
};
ObjectQuery oQuery = query as ObjectQuery;
oQuery.EnablePlanCaching = false;
- Pour les requêtes paramétrisées, la modification de la valeur du paramètre atteint toujours la requête mise en cache. Toutefois, la modification des facettes d’un paramètre (par exemple la taille, la précision ou l’échelle) atteindra une autre entrée dans le cache.
- Lorsque vous utilisez Entity SQL, la chaîne de requête fait partie de la clé. La modification de la requête entraîne des entrées de cache différentes, même si les requêtes sont fonctionnellement équivalentes. Cela inclut les modifications apportées à la casse ou aux espaces blancs.
- Lorsque vous utilisez LINQ, la requête est traitée pour générer une partie de la clé. La modification de l’expression LINQ génère donc une clé différente.
- D’autres limitations techniques peuvent s’appliquer ; pour plus d’informations, consultez Requêtes autocompilées.
3.2.2 Algorithme d’éviction du cache
Comprendre le fonctionnement de l’algorithme interne vous aidera à déterminer quand activer ou désactiver la mise en cache du plan de requête. L’algorithme de nettoyage est le suivant :
- Une fois que le cache contient un nombre défini d’entrées (800), nous démarrons un minuteur qui balaye régulièrement (une fois par minute) le cache.
- Pendant les balayages du cache, les entrées sont supprimées du cache selon le principe LFRU (Least frequently – recently used). Cet algorithme prend en compte le nombre d’accès et l’âge lors du choix des entrées éjectées.
- À la fin de chaque balayage du cache, le cache contient à nouveau 800 entrées.
Toutes les entrées de cache sont traitées de façon égale lors de la détermination des entrées à supprimer. Cela signifie que la commande de magasin pour une CompiledQuery a la même chance d’éviction que la commande de magasin pour une requête Entity SQL.
Notez que le minuteur d’éviction du cache est lancé lorsqu’il y a 800 entités dans le cache, mais que le cache n’est balayé que 60 secondes après le démarrage de ce minuteur. Cela signifie que pendant 60 secondes, votre cache risque de croître jusqu’à une taille assez importante.
3.2.3 Métriques de test illustrant les performances de mise en cache du plan de requête
Pour illustrer l’effet de la mise en cache du plan de requête sur les performances de votre application, nous avons effectué un test où nous avons exécuté un certain nombre de requêtes Entity SQL sur le modèle Navision. Consultez l’annexe pour obtenir une description du modèle Navision et des types de requêtes qui ont été exécutées. Dans ce test, nous parcourons d’abord la liste des requêtes et exécutons chacune d’elles une fois pour les ajouter au cache (si la mise en cache est activée). Cette étape n’est pas chronométrée. Ensuite, nous endormons le thread principal pendant plus de 60 secondes afin que le balayage du cache puisse avoir lieu. Pour finir, nous parcourons la liste une deuxième fois afin d’exécuter les requêtes mises en cache. Par ailleurs, le cache du plan SQL Server est vidé avant l’exécution de chaque ensemble de requêtes afin que les temps que nous obtenons reflètent avec justesse l’avantage donné par le cache du plan de requête.
3.2.3.1 Résultats des tests
| Test | EF5 sans mise en cache | EF5 avec mise en cache | EF6 sans mise en cache | EF6 avec mise en cache |
|---|---|---|---|---|
| Énumération des 18 723 requêtes | 124 | 125,4 | 124,3 | 125,3 |
| Balayage évité (seulement les 800 premières requêtes, quelle que soit la complexité) | 41,7 | 5.5 | 40,5 | 5.4 |
| Juste les requêtes AggregatingSubtotals (178 au total, ce qui évite le balayage) | 39,5 | 4.5 | 38,1 | 4.6 |
Toutes les durées sont en secondes.
Morale de l’histoire : lors de l’exécution d’un grand nombre de requêtes distinctes (par exemple des requêtes créées dynamiquement), la mise en cache n’aide pas, et le vidage résultant du cache peut même empêcher les requêtes qui tireraient le plus parti de la mise en cache du plan de l’utiliser.
Les requêtes AggatingSubtotals sont les requêtes les plus complexes que nous avons testées. Comme prévu, plus la requête est complexe, plus vous constaterez l’avantage offert par la mise en cache du plan de requête.
Une requête CompiledQuery étant en réalité une requête LINQ avec son plan mis en cache, la comparaison d’une CompiledQuery avec la requête Entity SQL équivalente devrait donner des résultats similaires. En fait, si une application a beaucoup de requêtes Entity SQL dynamiques, le remplissage du cache avec des requêtes entraînera également la « décompilation » des CompiledQueries lorsqu’elles seront vidées du cache. Dans ce scénario, les performances peuvent être améliorées en désactivant la mise en cache sur les requêtes dynamiques afin de rendre les CompiledQueries prioritaires. Bien entendu, il serait encore préférable de réécrire l’application de façon à utiliser des requêtes paramétrisées plutôt que des requêtes dynamiques.
3.3 Utilisation de CompiledQuery pour améliorer les performances avec les requêtes LINQ
Nos tests indiquent que l’utilisation de CompiledQuery peut offrir une amélioration de 7 % par rapport aux requêtes LINQ autocompilées ; cela signifie que vous passerez 7 % moins de temps à exécuter du code à partir de la pile Entity Framework, et non que votre application sera 7 % plus rapide. En règle générale, étant donné le coût de l’écriture et de la maintenance des objets CompiledQuery dans EF 5.0, les avantages offerts risquent de ne pas compenser les efforts nécessaires. Le kilométrage peut varier ; veillez donc à exercer cette option si votre projet nécessite une petite poussée supplémentaire. Notez que les CompiledQueries sont compatibles uniquement avec les modèles dérivés d’ObjectContext, et pas avec les modèles dérivés de DbContext.
Pour plus d’informations sur la création et l’appel d’une CompiledQuery, consultez Requêtes compilées (LINQ to Entities).
Il existe deux considérations à prendre en compte lors de l’utilisation d’une CompiledQuery, à savoir la nécessité d’utiliser des instances statiques et les problèmes liés à la composabilité. Voici une explication détaillée de ces deux considérations.
3.3.1 Utiliser des instances CompiledQuery statiques
La compilation d’une requête LINQ étant un long processus, vous ne souhaiterez pas le faire chaque fois que vous devez extraire des données de la base de données. Les instances CompiledQuery vous permettent de compiler une seule fois et d’exécuter plusieurs fois, mais vous devez être prudent et faire en sorte de réutiliser chaque fois la même instance CompiledQuery au lieu de la recompiler sans arrêt. L’utilisation de membres statiques pour stocker les instances CompiledQuery devient nécessaire ; autrement, vous ne constaterez aucun avantage.
Par exemple, supposez que votre page a le corps de méthode suivant pour gérer l’affichage des produits pour la catégorie sélectionnée :
// Warning: this is the wrong way of using CompiledQuery
using (NorthwindEntities context = new NorthwindEntities())
{
string selectedCategory = this.categoriesList.SelectedValue;
var productsForCategory = CompiledQuery.Compile<NorthwindEntities, string, IQueryable<Product>>(
(NorthwindEntities nwnd, string category) =>
nwnd.Products.Where(p => p.Category.CategoryName == category)
);
this.productsGrid.DataSource = productsForCategory.Invoke(context, selectedCategory).ToList();
this.productsGrid.DataBind();
}
this.productsGrid.Visible = true;
Dans ce cas, vous créerez une instance CompiledQuery à la volée chaque fois que la méthode est appelée. Au lieu de bénéficier des avantages en termes de performances en récupérant la commande de magasin à partir du cache du plan de requête, la CompiledQuery passe par le compilateur de plan chaque fois qu’une nouvelle instance est créée. En fait, vous polluez votre cache de plan de requête avec une nouvelle entrée CompiledQuery chaque fois que la méthode est appelée.
Au lieu de cela, vous devez créer une instance statique de la requête compilée ; ainsi, vous appelez la même requête compilée chaque fois que la méthode est appelée. L’une des manières de procéder consiste à ajouter l’instance CompiledQuery en tant que membre du contexte de votre objet. Vous pouvez ensuite rendre les choses un peu plus propres en accédant à la CompiledQuery par le biais d’une méthode d’assistance :
public partial class NorthwindEntities : ObjectContext
{
private static readonly Func<NorthwindEntities, string, IEnumerable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
public IEnumerable<Product> GetProductsForCategory(string categoryName)
{
return productsForCategoryCQ.Invoke(this, categoryName).ToList();
}
Cette méthode d’assistance est appelée comme suit :
this.productsGrid.DataSource = context.GetProductsForCategory(selectedCategory);
3.3.2 Composition sur une CompiledQuery
La capacité à composer sur n’importe quelle requête LINQ est extrêmement utile ; pour ce faire, il vous suffit d’appeler une méthode après l’IQueryable, telle que Skip() ou Count(). Toutefois, cette opération retourne essentiellement un nouvel objet IQueryable. Bien que techniquement rien ne vous empêche de composer sur une CompiledQuery, cela entraîne la génération d’un nouvel objet IQueryable qui nécessite de passer à nouveau par le compilateur de plan.
Certains composants utilisent des objets IQueryable composés pour activer des fonctionnalités avancées. Par exemple, GridView d’ASP.NET peut être lié aux données à un objet IQueryable via la propriété SelectMethod. Le GridView compose ensuite sur cet objet IQueryable afin d’autoriser le tri et la pagination sur le modèle de données. Comme vous pouvez le voir, l’utilisation d’une CompiledQuery pour le GridView n’atteint pas la requête compilée, mais génère une nouvelle requête autocompilée.
L’un des endroits où vous pourriez rencontrer ce scénario est lors de l’ajout de filtres progressifs à une requête. Par exemple, supposez que vous avez une page Customers avec plusieurs listes déroulantes pour ds filtres facultatifs (par exemple Country et OrdersCount). Vous pouvez composer ces filtres sur les résultats IQueryable d’une requête compilée, mais cela entraînerait le passage de la nouvelle requête par le compilateur de plan chaque fois que vous l’exécuteriez.
using (NorthwindEntities context = new NorthwindEntities())
{
IQueryable<Customer> myCustomers = context.InvokeCustomersForEmployee();
if (this.orderCountFilterList.SelectedItem.Value != defaultFilterText)
{
int orderCount = int.Parse(orderCountFilterList.SelectedValue);
myCustomers = myCustomers.Where(c => c.Orders.Count > orderCount);
}
if (this.countryFilterList.SelectedItem.Value != defaultFilterText)
{
myCustomers = myCustomers.Where(c => c.Address.Country == countryFilterList.SelectedValue);
}
this.customersGrid.DataSource = myCustomers;
this.customersGrid.DataBind();
}
Pour éviter cette nouvelle compilation, vous pouvez réécrire la CompiledQuery de façon à prendre en compte les filtres possibles :
private static readonly Func<NorthwindEntities, int, int?, string, IQueryable<Customer>> customersForEmployeeWithFiltersCQ = CompiledQuery.Compile(
(NorthwindEntities context, int empId, int? countFilter, string countryFilter) =>
context.Customers.Where(c => c.Orders.Any(o => o.EmployeeID == empId))
.Where(c => countFilter.HasValue == false || c.Orders.Count > countFilter)
.Where(c => countryFilter == null || c.Address.Country == countryFilter)
);
Ce qui serait appelé dans l’interface utilisateur comme suit :
using (NorthwindEntities context = new NorthwindEntities())
{
int? countFilter = (this.orderCountFilterList.SelectedIndex == 0) ?
(int?)null :
int.Parse(this.orderCountFilterList.SelectedValue);
string countryFilter = (this.countryFilterList.SelectedIndex == 0) ?
null :
this.countryFilterList.SelectedValue;
IQueryable<Customer> myCustomers = context.InvokeCustomersForEmployeeWithFilters(
countFilter, countryFilter);
this.customersGrid.DataSource = myCustomers;
this.customersGrid.DataBind();
}
Ici, le compromis est que la commande de magasin générée aura toujours les filtres avec les vérifications Null, mais le serveur de base de données ne devrait pas avoir trop de mal à les optimiser :
...
WHERE ((0 = (CASE WHEN (@p__linq__1 IS NOT NULL) THEN cast(1 as bit) WHEN (@p__linq__1 IS NULL) THEN cast(0 as bit) END)) OR ([Project3].[C2] > @p__linq__2)) AND (@p__linq__3 IS NULL OR [Project3].[Country] = @p__linq__4)
3.4 Mise en cache des métadonnées
Entity Framework prend également en charge la mise en cache des métadonnées. Il s’agit essentiellement de mettre en cache des informations de type et des informations de mappage de type à base de données parmi différentes connexions au même modèle. Le cache de métadonnées est unique par AppDomain.
3.4.1 Algorithme de mise en cache des métadonnées
Les informations de métadonnées d’un modèle sont stockées dans une ItemCollection pour chaque EntityConnection.
- Soit dit en passant, il existe différents objets ItemCollection pour différentes parties du modèle. Par exemple, StoreItemCollections contient des informations sur le modèle de base de données ; ObjectItemCollection contient des informations sur le modèle de données, et EdmItemCollection contient des informations sur le modèle conceptuel.
Si deux connexions utilisent la même chaîne de connexion, elles partageront la même instance ItemCollection.
Des chaînes de connexion fonctionnellement équivalentes mais textuellement différentes peuvent entraîner des caches de métadonnées différents. Nous tokenisons les chaînes de connexion. Par conséquent, il suffit de modifier l’ordre des jetons pour générer des métadonnées partagées. Mais deux chaînes de connexion qui semblent fonctionnellement identiques peuvent ne pas être évaluées comme identiques après la tokenisation.
L’utilisation de l’ItemCollection est régulièrement vérifiée. S’il est déterminé qu’un espace de travail n’a pas été sollicité récemment, il est marqué pour le nettoyage lors du balayage du cache suivant.
La simple création d’une EntityConnection entraînera la création d’un cache de métadonnées (mais les collections d’éléments qu’il contiendra ne seront initialisées que lors de l’ouverture de la connexion). Cet espace de travail restera en mémoire jusqu’à ce que l’algorithme de mise en cache détermine qu’il n’est pas « en cours d’utilisation ».
L’équipe de conseil client a écrit un billet de blog qui décrit la tenue d’une référence à une ItemCollection afin d’éviter la « dépréciation » lors de l’utilisation de modèles volumineux : <https://learn.microsoft.com/archive/blogs/appfabriccat/holding-a-reference-to-the-ef-metadataworkspace-for-wcf-services>.
3.4.2 Relation entre la mise en cache des métadonnées et la mise en cache du plan de requête
L’instance de cache du plan de requête réside dans l’ItemCollection de MetadataWorkspace des types de magasin. Cela signifie que les commandes de magasin mises en cache seront utilisées pour les requêtes sur tout contexte instancié à l’aide d’un MetadataWorkspace donné. Cela signifie également que si vous avez deux chaînes de connexions qui sont légèrement différentes et ne correspondent pas après la tokenisation, vous aurez des instances de cache de plan de requête différentes.
3.5 Mise en cache des résultats
Avec la mise en cache des résultats (également appelée « mise en cache de second niveau »), vous conservez les résultats des requêtes dans un cache local. Lors de l’émission d’une requête, vous voyez d’abord si les résultats sont disponibles localement avant d’effectuer une requête sur le magasin. Bien que la mise en cache des résultats ne soit pas directement prise en charge par Entity Framework, il est possible d’ajouter un cache de second niveau à l’aide d’un fournisseur de services Wrapper. Le cache de second niveau Entity Framework basé sur NCache d’Alachisoft constitue un exemple de fournisseur de services Wrapper avec un cache de second niveau.
Cette implémentation de la mise en cache de second niveau est une fonctionnalité injectée qui se produit une fois que l’expression LINQ a été évaluée (et funcletizée) et que le plan d’exécution de requête a été calculé ou récupéré à partir du cache de premier niveau. Le cache de second niveau stocke ensuite uniquement les résultats bruts de la base de données. Par conséquent, le pipeline de matérialisation s’exécute toujours par la suite.
3.5.1 Références supplémentaires pour la mise en cache des résultats avec le fournisseur de services Wrapper
- Julie Lerman a écrit un article MSDN intitulé « Mise en cache de second niveau dans Entity Framework et Windows Azure » qui explique comment mettre à jour l’exemple de fournisseur de services Wrapper pour utiliser la mise en cache Windows Server AppFabric : https://msdn.microsoft.com/magazine/hh394143.aspx
- Si vous travaillez avec Entity Framework 5, le blog de l’équipe contient un billet qui explique comment procéder avec le fournisseur de mise en cache pour Entity Framework 5 : <https://learn.microsoft.com/archive/blogs/adonet/ef-caching-with-jarek-kowalskis-provider>. Il inclut également un modèle T4 pour vous aider à automatiser l’ajout de la mise en cache de second niveau à votre projet.
4 Requêtes autocompilées
Lorsqu’une requête est émise sur une base de données à l’aide d’Entity Framework, elle doit passer par une série d’étapes avant de matérialiser réellement les résultats ; l’une de ces étapes est la compilation de requête. Les requêtes Entity SQL sont connues comme offrant de bonnes performances, car elles sont automatiquement mises en cache. Par conséquent, la deuxième ou la troisième fois que vous exécutez la même requête, elle peut ignorer le compilateur de plan et utiliser le plan mis en cache à la place.
Entity Framework 5 a introduit la mise en cache automatique pour les requêtes LINQ to Entities également. Dans les éditions précédentes d’Entity Framework, la création d’une CompiledQuery pour accélérer les performances était une pratique courante, car cela rendait votre requête LINQ to Entities compatible avec la mise en cache. La mise en cache étant désormais effectuée automatiquement sans l’utilisation d’une CompiledQuery, nous employons le terme « requêtes autocompilées » pour désigner cette fonctionnalité. Pour plus d’informations sur le cache du plan de requête et ses mécanismes, consultez Mise en cache du plan de requête.
Entity Framework détecte lorsqu’une requête doit être recompilée, et le fait lorsque la requête est appelée même si elle a été compilée auparavant. Les conditions courantes qui entraînent la recompilation de la requête sont les suivantes :
- Modification de la MergeOption associée à votre requête. La requête mise en cache n’est pas utilisée ; au lieu de cela, le compilateur de plan s’exécute à nouveau et le plan nouvellement créé est mis en cache
- Modification de la valeur de ContextOptions.UseCSharpNullComparisonBehavior. L’effet est le même qu’en cas de modification de MergeOption
D’autres conditions peuvent empêcher votre requête d’utiliser le cache. Voici des exemples courants :
- Utilisation d’IEnumerable<T>.Contains<>(valeur T)
- Utilisation de fonctions qui produisent des requêtes avec des constantes
- Utilisation des propriétés d’un objet non mappé
- Liaison de votre requête à une autre requête qui doit être recompilée
4.1 Utilisation d’IEnumerable<T>.Contains<T>(valeur T)
Entity Framework ne met pas en cache les requêtes qui appellent IEnumerable<T>.Contains<T>(valeur T) sur une collection en mémoire, car les valeurs de la collection sont considérées comme volatiles. L’exemple de requête suivant ne sera pas mis en cache. Il sera donc toujours traité par le compilateur de plan :
int[] ids = new int[10000];
...
using (var context = new MyContext())
{
var query = context.MyEntities
.Where(entity => ids.Contains(entity.Id));
var results = query.ToList();
...
}
Notez que la taille de l’IEnumerable par rapport à laquelle Contains est exécuté détermine la vitesse ou la lenteur de compilation de votre requête. Les performances peuvent se dégrader considérablement lors de l’utilisation de collections volumineuses, comme celle illustrée dans l’exemple ci-dessus.
Entity Framework 6 contient des optimisations de la façon dont IEnumerable<T>.Contains<T>(valeur T) fonctionne lorsque les requêtes sont exécutées. Le code SQL généré est beaucoup plus rapide à produire et plus lisible, et dans la plupart des cas, il s’exécute également plus rapidement sur le serveur.
4.2 Utilisation de fonctions qui produisent des requêtes avec des constantes
Les opérateurs LINQ Skip(), Take(), Contains() et DefautIfEmpty() ne produisent pas de requêtes SQL avec des paramètres ; au lieu de cela, ils placent les valeurs qui leur sont transmises en tant que constantes. Pour cette raison, des requêtes qui seraient autrement identiques finissent par polluer le cache du plan de requête, à la fois sur la pile EF et sur le serveur de base de données, et elles ne sont pas réutilisées, sauf si les mêmes constantes sont utilisées dans une exécution de requête ultérieure. Par exemple :
var id = 10;
...
using (var context = new MyContext())
{
var query = context.MyEntities.Select(entity => entity.Id).Contains(id);
var results = query.ToList();
...
}
Dans cet exemple, chaque fois que cette requête est exécutée avec une valeur différente pour l’ID, la requête est compilée dans un nouveau plan.
Prêtez une attention particulière à l’utilisation de Skip et Take lors de la pagination. Dans EF6, ces méthodes ont une surcharge lambda qui rend le plan de requête mis en cache réutilisable, car EF peut capturer des variables passées à ces méthodes et les traduire en SQLparameters. Cela permet également de favoriser la propreté du cache, car autrement chaque requête avec une constante différente pour Skip et Take obtiendrait sa propre entrée de cache de plan de requête.
Considérez le code suivant, qui est non optimal, mais est destiné uniquement à illustrer cette classe de requêtes :
var customers = context.Customers.OrderBy(c => c.LastName);
for (var i = 0; i < count; ++i)
{
var currentCustomer = customers.Skip(i).FirstOrDefault();
ProcessCustomer(currentCustomer);
}
Une version plus rapide de ce même code impliquerait l’appel de Skip avec une expression lambda :
var customers = context.Customers.OrderBy(c => c.LastName);
for (var i = 0; i < count; ++i)
{
var currentCustomer = customers.Skip(() => i).FirstOrDefault();
ProcessCustomer(currentCustomer);
}
Le deuxième extrait de code peut s’exécuter jusqu’à 11 % plus rapidement, car le même plan de requête est utilisé chaque fois que la requête est exécutée, ce qui permet de gagner du temps processeur et d’éviter de polluer le cache de requête. En outre, étant donné que le paramètre de Skip se trouve dans une fermeture, le code peut ressembler à ceci maintenant :
var i = 0;
var skippyCustomers = context.Customers.OrderBy(c => c.LastName).Skip(() => i);
for (; i < count; ++i)
{
var currentCustomer = skippyCustomers.FirstOrDefault();
ProcessCustomer(currentCustomer);
}
4.3 Utilisation des propriétés d’un objet non mappé
Lorsqu’une requête utilise les propriétés d’un type d’objet non mappé en tant que paramètre, la requête n’est pas mise en cache. Par exemple :
using (var context = new MyContext())
{
var myObject = new NonMappedType();
var query = from entity in context.MyEntities
where entity.Name.StartsWith(myObject.MyProperty)
select entity;
var results = query.ToList();
...
}
Dans cet exemple, supposez que la classe NonMappedType ne fait pas partie du modèle Entity. Cette requête peut facilement être modifiée de façon à ne pas utiliser de type non mappé, et à utiliser plutôt une variable locale comme paramètre pour la requête :
using (var context = new MyContext())
{
var myObject = new NonMappedType();
var myValue = myObject.MyProperty;
var query = from entity in context.MyEntities
where entity.Name.StartsWith(myValue)
select entity;
var results = query.ToList();
...
}
Dans ce cas, la requête pourra être mise en cache et tirera parti du cache du plan de requête.
4.4 Liaison à des requêtes nécessitant une recompilation
Poursuivons avec l’exemple ci-dessus. Si vous avez une deuxième requête qui s’appuie sur une requête qui doit être recompilée, votre deuxième requête sera également recompilée. Voici un exemple pour illustrer ce scénario :
int[] ids = new int[10000];
...
using (var context = new MyContext())
{
var firstQuery = from entity in context.MyEntities
where ids.Contains(entity.Id)
select entity;
var secondQuery = from entity in context.MyEntities
where firstQuery.Any(otherEntity => otherEntity.Id == entity.Id)
select entity;
var results = secondQuery.ToList();
...
}
L’exemple est générique, mais il illustre la façon dont la liaison à firstQuery entraîne l’impossibilité de mettre en cache secondQuery. Si firstQuery n’avait pas été une requête nécessitant une recompilation, secondQuery aurait été mise en cache.
5 Requêtes NoTracking
5.1 Désactivation du suivi des modifications pour réduire la surcharge de gestion de l’état
Si vous êtes dans un scénario en lecture seule et que vous souhaitez éviter la surcharge liée au chargement des objets dans ObjectStateManager, vous pouvez émettre des requêtes « sans suivi ». Le suivi des modifications peut être désactivé au niveau de la requête.
Notez néanmoins qu’en désactivant le suivi des modifications, vous désactivez le cache d’objets. Lorsque vous interrogez une entité, nous ne pouvons pas ignorer la matérialisation en extrayant les résultats de la requête précédemment matérialisée à partir d’ObjectStateManager. Si vous interrogez de manière répétée les mêmes entités sur le même contexte, vous observerez peut-être un avantage en matière de performances en cas d’activation du suivi des modifications.
Lors de l’interrogation à l’aide d’ObjectContext, les instances ObjectQuery et ObjectSet mémorisent une option MergeOption une fois qu’elle est définie, et les requêtes qui sont composées dessus héritent de l’option MergeOption effective de la requête parente. Lors de l’utilisation de DbContext, le suivi peut être désactivé en appelant le modificateur AsNoTracking() sur DbSet.
5.1.1 Désactivation du suivi des modifications pour une requête lors de l’utilisation de DbContext
Vous pouvez basculer le mode d’une requête sur NoTracking en chaînant un appel à la méthode AsNoTracking() dans la requête. Contrairement à ObjectQuery, les classes DbSet et DbQuery de l’API DbContext n’ont pas de propriété mutable pour MergeOption.
var productsForCategory = from p in context.Products.AsNoTracking()
where p.Category.CategoryName == selectedCategory
select p;
5.1.2 Désactivation du suivi des modifications au niveau de la requête à l’aide d’ObjectContext
var productsForCategory = from p in context.Products
where p.Category.CategoryName == selectedCategory
select p;
((ObjectQuery)productsForCategory).MergeOption = MergeOption.NoTracking;
5.1.3 Désactivation du suivi des modifications pour un jeu d’entités complet à l’aide d’ObjectContext
context.Products.MergeOption = MergeOption.NoTracking;
var productsForCategory = from p in context.Products
where p.Category.CategoryName == selectedCategory
select p;
5.2 Métriques de test illustrant l’avantage en terme de performances des requêtes NoTracking
Dans ce test, nous examinons le coût de remplissage de l’ObjectStateManager en comparant les requêtes avec suivi aux requêtes sans suivi pour le modèle Navision. Consultez l’annexe pour obtenir une description du modèle Navision et des types de requêtes qui ont été exécutées. Dans ce test, nous parcourons la liste des requêtes et exécutons chacune d’elles une fois. Nous exécutons deux variantes du test, une fois avec des requêtes NoTracking et une fois avec l’option de fusion par défaut « AppendOnly ». Nous exécutons chaque variante trois fois et prenons la valeur moyenne des exécutions. Entre les tests, nous effaçons le cache de requête sur SQL Server et réduisons tempdb en exécutant les commandes suivantes :
- DBCC DROPCLEANBUFFERS
- DBCC FREEPROCCACHE
- DBCC SHRINKDATABASE (tempdb, 0)
Résultats des tests, médiane sur trois exécutions :
| AUCUN SUIVI – ENSEMBLE DE TRAVAIL | AUCUN SUIVI – TEMPS | AJOUT UNIQUEMENT – ENSEMBLE DE TRAVAIL | AJOUT UNIQUEMENT – TEMPS | |
|---|---|---|---|---|
| Entity Framework 5 | 460 361 728 | 1 163 536 ms | 596 545 536 | 127 3042 ms |
| Entity Framework 6 | 647 127 040 | 190 228 ms | 832 798 720 | 195 521 ms |
Entity Framework 5 aura une empreinte mémoire plus petite qu’Entity Framework 6 à la fin de l’exécution. La mémoire supplémentaire consommée par Entity Framework 6 est le résultat de structures de mémoire et de code supplémentaires qui procurent de nouvelles fonctionnalités et de meilleures performances.
Il existe également une différence claire dans l’empreinte mémoire lors de l’utilisation d’ObjectStateManager. Entity Framework 5 a augmenté son empreinte de 30 % lors du suivi de toutes les entités que nous avons matérialisées à partir de la base de données. Entity Framework 6 a augmenté son empreinte de 28 % lors de cette opération.
En termes de temps, Entity Framework 6 offre de loin de meilleures performances qu’Entity Framework 5 dans ce test. Entity Framework 6 a terminé le test en environ 16 % du temps consommé par Entity Framework 5. En outre, Entity Framework 5 prend 9 % plus de temps quand ObjectStateManager est utilisé. En comparaison, Entity Framework 6 utilise 3 % plus de temps lors de l’utilisation d’ObjectStateManager.
6 Options d’exécution SQL
Entity Framework offre plusieurs manières différentes d’interroger. Nous allons examiner les options suivantes, comparer les avantages et les inconvénients de chacune, et examiner leurs caractéristiques en terme de performances :
- LINQ to Entities
- LINQ to Entities sans suivi
- Entity SQL sur un ObjectQuery
- Entity SQL sur un EntityCommand
- ExecuteStoreQuery
- SqlQuery
- CompiledQuery
6.1 Requêtes LINQ to Entities
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
Avantages
- Convient aux opérations CUD
- Objets entièrement matérialisés
- Le plus simple à écrire, avec une syntaxe intégrée au langage de programmation
- Bonnes performances
Inconvénients
- Certaines restrictions techniques, telles que :
- Les modèles utilisant DefaultIfEmpty pour les requêtes OUTER JOIN génèrent des requêtes plus complexes que des instructions OUTER JOIN simples dans Entity SQL
- Vous ne pouvez toujours pas utiliser LIKE avec la mise en correspondance générale de modèle
6.2 Requêtes LINQ to Entities sans suivi
Lorsque le contexte dérive d’ObjectContext :
context.Products.MergeOption = MergeOption.NoTracking;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
Lorsque le contexte dérive de DbContext :
var q = context.Products.AsNoTracking()
.Where(p => p.Category.CategoryName == "Beverages");
Avantages
- Amélioration des performances sur les requêtes LINQ régulières
- Objets entièrement matérialisés
- Le plus simple à écrire, avec une syntaxe intégrée au langage de programmation
Inconvénients
- Ne convient pas aux opérations CUD
- Certaines restrictions techniques, telles que :
- Les modèles utilisant DefaultIfEmpty pour les requêtes OUTER JOIN génèrent des requêtes plus complexes que des instructions OUTER JOIN simples dans Entity SQL
- Vous ne pouvez toujours pas utiliser LIKE avec la mise en correspondance générale de modèle
Notez que les requêtes qui projettent des propriétés scalaires ne sont pas suivies, même si NoTracking n’est pas spécifié. Par exemple :
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages").Select(p => new { p.ProductName });
Cette requête particulière ne spécifie pas explicitement NoTracking, mais étant donné qu’elle ne matérialise pas un type connu du gestionnaire d’état d’objet, le résultat matérialisé n’est pas suivi.
6.3 Entity SQL sur un ObjectQuery
ObjectQuery<Product> products = context.Products.Where("it.Category.CategoryName = 'Beverages'");
Avantages
- Convient aux opérations CUD
- Objets entièrement matérialisés
- Prend en charge la mise en cache du plan de requête
Inconvénients
- Implique des chaînes de requête textuelles qui sont davantage sujettes aux erreurs utilisateur que les constructions de requête intégrées au langage
6.4 Entity SQL sur une commande Entity
EntityCommand cmd = eConn.CreateCommand();
cmd.CommandText = "Select p From NorthwindEntities.Products As p Where p.Category.CategoryName = 'Beverages'";
using (EntityDataReader reader = cmd.ExecuteReader(CommandBehavior.SequentialAccess))
{
while (reader.Read())
{
// manually 'materialize' the product
}
}
Avantages
- Prend en charge la mise en cache du plan de requête dans .NET 4.0 (la mise en cache du plan est prise en charge par tous les autres types de requêtes dans .NET 4.5)
Inconvénients
- Implique des chaînes de requête textuelles qui sont davantage sujettes aux erreurs utilisateur que les constructions de requête intégrées au langage
- Ne convient pas aux opérations CUD
- Les résultats ne sont pas matérialisés automatiquement, et doivent être lus à partir du lecteur de données
6.5 SqlQuery et ExecuteStoreQuery
SqlQuery sur Database :
// use this to obtain entities and not track them
var q1 = context.Database.SqlQuery<Product>("select * from products");
SqlQuery sur DbSet :
// use this to obtain entities and have them tracked
var q2 = context.Products.SqlQuery("select * from products");
ExecuteStoreQuery :
var beverages = context.ExecuteStoreQuery<Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued, P.DiscontinuedDate
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
Avantages
- Généralement le plus rapide, car le compilateur de plan est contourné
- Objets entièrement matérialisés
- Convient aux opérations CUD en cas d’utilisation à partir du DbSet
Inconvénients
- La requête est textuelle et sujette aux erreurs
- La requête est liée à un back-end spécifique, par l’utilisation de la sémantique de magasin plutôt que la sémantique conceptuelle
- Lorsque l’héritage est présent, une requête artisanale doit tenir compte des conditions de mappage pour le type demandé
6.6 CompiledQuery
private static readonly Func<NorthwindEntities, string, IQueryable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
…
var q = context.InvokeProductsForCategoryCQ("Beverages");
Avantages
- Fournit une amélioration des performances allant jusqu’à 7 % par rapport aux requêtes LINQ régulières
- Objets entièrement matérialisés
- Convient aux opérations CUD
Inconvénients
- Complexité accrue et surcharge de programmation
- L’amélioration des performances est perdue lors de la composition sur une requête compilée
- Certaines requêtes LINQ ne peuvent pas être écrites en tant que CompiledQuery (par exemple les projections de types anonymes)
6.7 Comparaison des performances de différentes options de requête
Des microbenchmarks simples où la création du contexte n’était pas chronométrée ont été soumis à un test. Nous avons mesuré l’interrogation 5 000 fois pour un ensemble d’entités non mises en cache dans un environnement contrôlé. Ces chiffres doivent être pris avec un avertissement : ils ne reflètent pas les chiffres réels produits par une application, mais constituent plutôt une mesure très précise de l’étendue de la différence en terme de performances lorsque différentes options d’interrogation sont comparées, à l’exclusion du coût de la création d’un nouveau contexte.
| EF | Test | Temps (ms) | Mémoire |
|---|---|---|---|
| EF5 | ESQL ObjectContext | 2 414 | 38 801 408 |
| EF5 | Requête Linq ObjectContext | 2 692 | 38 277 120 |
| EF5 | Requête Linq DbContext sans suivi | 2 818 | 41 840 640 |
| EF5 | Requête Linq DbContext | 2 930 | 41 771 008 |
| EF5 | Requête Linq ObjectContext sans suivi | 3013 | 38 412 288 |
| EF6 | ESQL ObjectContext | 2 059 | 46 039 040 |
| EF6 | Requête Linq ObjectContext | 3074 | 45 248 512 |
| EF6 | Requête Linq DbContext sans suivi | 3125 | 47 575 040 |
| EF6 | Requête Linq DbContext | 3420 | 47 652 864 |
| EF6 | Requête Linq ObjectContext sans suivi | 3 593 | 45 260 800 |
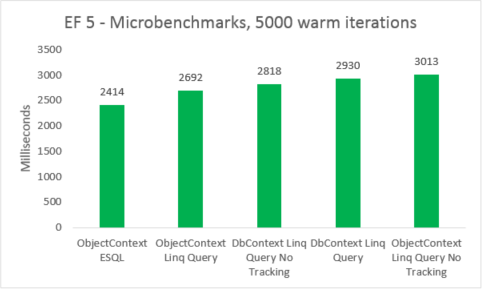
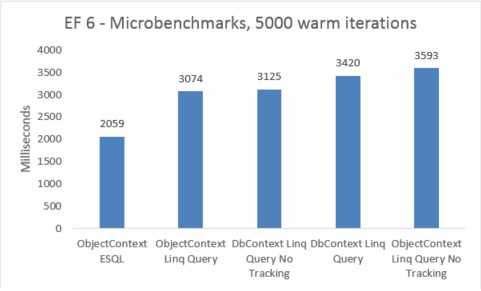
Les microbenchmarks sont très sensibles aux petites modifications du code. Dans le cas présent, la différence entre les coûts d’Entity Framework 5 et Entity Framework 6 est due à l’ajout de l’interception et des améliorations transactionnelles. Les chiffres de ces microbenchmarks sont néanmoins une vision amplifiée d’un très petit fragment de ce que fait Entity Framework. Les scénarios réels de requêtes chaudes ne devraient pas présenter de régression des performances lors de la mise à niveau d’Entity Framework 5 vers Entity Framework 6.
Pour comparer les performances réelles des différentes options de requête, nous avons créé cinq variantes de test distinctes où nous utilisons une option de requête différente pour sélectionner tous les produits dont le nom de catégorie est « Beverages ». Chaque itération inclut le coût de création du contexte et le coût de matérialisation de toutes les entités retournées. Dix itérations sont exécutées sans chronométrage, avant de prendre la somme de 1000 itérations chronométrées. Les résultats indiqués sont l’exécution médiane de cinq exécutions de chaque test. Pour plus d’informations, consultez l’Annexe B, qui inclut le code du test.
| EF | Test | Temps (ms) | Mémoire |
|---|---|---|---|
| EF5 | Commande Entity ObjectContext | 621 | 39 350 272 |
| EF5 | Requête SQL DbContext sur Database | 825 | 37 519 360 |
| EF5 | Requête de magasin ObjectContext | 878 | 39 460 864 |
| EF5 | Requête Linq ObjectContext sans suivi | 969 | 38 293 504 |
| EF5 | Entity SQL ObjectContext à l’aide d’ObjectQuery | 1089 | 38 981 632 |
| EF5 | Requête compilée ObjectContext | 1099 | 38 682 624 |
| EF5 | Requête Linq ObjectContext | 1152 | 38 178 816 |
| EF5 | Requête Linq DbContext sans suivi | 1208 | 41 803 776 |
| EF5 | Requête SQL DbContext sur DbSet | 1414 | 37 982 208 |
| EF5 | Requête Linq DbContext | 1574 | 41 738 240 |
| EF6 | Commande Entity ObjectContext | 480 | 47 247 360 |
| EF6 | Requête de magasin ObjectContext | 493 | 46 739 456 |
| EF6 | Requête SQL DbContext sur Database | 614 | 41 607 168 |
| EF6 | Requête Linq ObjectContext sans suivi | 684 | 46 333 952 |
| EF6 | Entity SQL ObjectContext à l’aide d’ObjectQuery | 767 | 48 865 280 |
| EF6 | Requête compilée ObjectContext | 788 | 48 467 968 |
| EF6 | Requête Linq DbContext sans suivi | 878 | 47 554 560 |
| EF6 | Requête Linq ObjectContext | 953 | 47 632 384 |
| EF6 | Requête SQL DbContext sur DbSet | 1023 | 41 992 192 |
| EF6 | Requête Linq DbContext | 1290 | 47 529 984 |
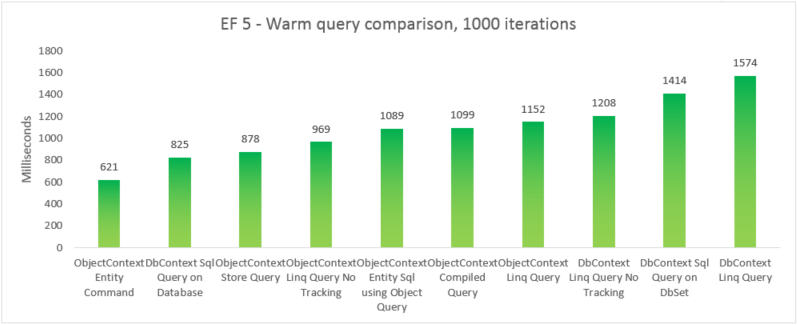
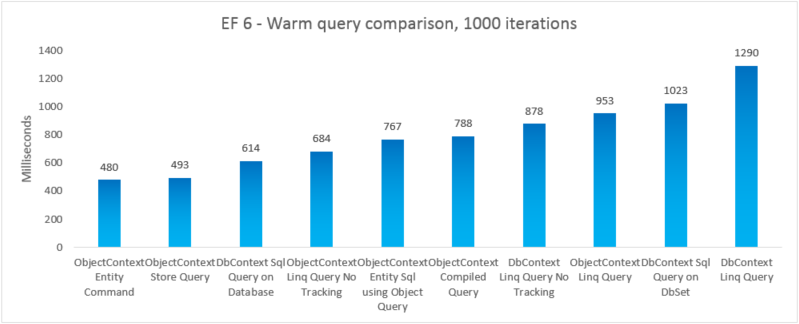
Remarque
À des fins d’exhaustivité, nous avons inclus une variante dans laquelle nous exécutons une requête Entity SQL sur une EntityCommand. Toutefois, étant donné que les résultats ne sont pas matérialisés pour ces requêtes, la comparaison n’est pas nécessairement rigoureuse. Le test comprend une bonne approximation de la matérialisation afin d’essayer de rendre la comparaison plus équitable.
Dans ce cas de bout en bout, Entity Framework 6 offre de meilleures performances qu’Entity Framework 5 en raison d’améliorations apportées aux performances de plusieurs parties de la pile, notamment une initialisation DbContext beaucoup plus légère et des recherches MetadataCollection<T> plus rapides.
7 Considérations relatives aux performances au moment de la conception
7.1 Stratégies d’héritage
Une autre considération en matière de performances lors de l’utilisation d’Entity Framework concerne la stratégie d’héritage que vous adoptez. Entity Framework prend en charge trois types de base d’héritage et leurs combinaisons :
- Table par hiérarchie (TPH) : chaque jeu d’héritage est mappé à une table avec une colonne de discrimination pour indiquer quel type particulier de la hiérarchie est représenté sur la ligne.
- Table par type (TPT) : chaque type a sa propre table dans la base de données ; les tables enfants définissent uniquement les colonnes que la table parente ne contient pas.
- Table par classe (TPC) : chaque type a sa propre table complète dans la base de données ; les tables enfants définissent tous leurs champs, y compris ceux définis dans les types parentes.
Si votre modèle utilise l’héritage TPT, les requêtes générées seront plus complexes que celles générées avec les autres stratégies d’héritage, ce qui peut entraîner des temps d’exécution plus longs sur le magasin. Il faudra généralement plus de temps pour générer des requêtes sur un modèle TPT et pour matérialiser les objets résultants.
Consultez le billet de blog MSDN intitulé « Performance Considerations when using TPT (Table per Type) Inheritance in the Entity Framework » : <https://learn.microsoft.com/archive/blogs/adonet/performance-considerations-when-using-tpt-table-per-type-inheritance-in-the-entity-framework>.
7.1.1 Éviter TPT dans les applications Model First ou Code First
Lorsque vous créez un modèle sur une base de données existante qui a un schéma TPT, vous n’avez pas beaucoup d’options. En revanche, lors de la création d’une application à l’aide de Model First ou Code First, vous devez éviter l’héritage TPT pour des raisons de performances.
Lorsque vous utilisez Model First dans l’Assistant Concepteur d’entités, vous obtenez TPT pour tout héritage dans votre modèle. Si vous souhaitez basculer vers une stratégie d’héritage TPH avec Model First, vous pouvez utiliser l’« Entity Designer Database Generation Power Pack » disponible à partir de la galerie Visual Studio (<http://visualstudiogallery.msdn.microsoft.com/df3541c3-d833-4b65-b942-989e7ec74c87/>).
Lorsque vous utilisez Code First pour configurer le mappage d’un modèle avec héritage, EF utilise TPH par défaut ; par conséquent, toutes les entités de la hiérarchie d’héritage sont mappées à la même table. Pour plus d’informations, consultez la section « Mappage avec l’API Fluent » de l’article « Code First dans ADO.NET Entity Framework 4.1 » dans MSDN Magazine (http://msdn.microsoft.com/magazine/hh126815.aspx).
7.2 Mise à niveau d’EF4 pour améliorer le temps de génération de modèle
Une amélioration propre à SQL Server de l’algorithme qui génère la couche magasin (SSDL) du modèle est disponible dans Entity Framework 5 et 6, et en tant que mise à jour d’Entity Framework 4 lorsque Visual Studio 2010 SP1 est installé. Les résultats de test suivants illustrent l’amélioration lors de la génération d’un modèle très volumineux, en l’occurrence le modèle Navision. Pour plus d’informations, consultez l’Annexe C.
Le modèle contient 1005 jeux d’entités et 4 227 ensembles d’associations.
| Configuration | Répartition du temps consommé |
|---|---|
| Visual Studio 2010, Entity Framework 4 | Génération SSDL : 2 h 27 min Génération de mappage : 1 seconde Génération CSDL : 1 seconde Génération ObjectLayer : 1 seconde Génération de vue : 2 h 14 min |
| Visual Studio 2010 SP1, Entity Framework 4 | Génération SSDL : 1 seconde Génération de mappage : 1 seconde Génération CSDL : 1 seconde Génération ObjectLayer : 1 seconde Génération de vue : 1 h 53 min |
| Visual Studio 2013, Entity Framework 5 | Génération SSDL : 1 seconde Génération de mappage : 1 seconde Génération CSDL : 1 seconde Génération ObjectLayer : 1 seconde Génération de vue : 65 minutes |
| Visual Studio 2013, Entity Framework 6 | Génération SSDL : 1 seconde Génération de mappage : 1 seconde Génération CSDL : 1 seconde Génération ObjectLayer : 1 seconde Génération de vue : 28 secondes. |
Il est important de noter que lors de la génération de la SSDL, la charge est presque entièrement dépensée sur le serveur SQL, tandis que l’ordinateur de développement client attend que les résultats reviennent du serveur. Les administrateurs de base de données apprécieront sans doute particulièrement cette amélioration. Il convient également de noter qu’en grande partie, le coût total de la génération de modèle est désormais lié à la génération de vue.
7.3 Fractionnement de grands modèles avec Database First et Model First
À mesure que la taille du modèle augmente, la surface du concepteur devient encombrée et difficile à utiliser. Nous considérons généralement un modèle avec plus de 300 entités comme étant trop volumineux pour une utilisation efficace du concepteur. Le billet de blog suivant décrit plusieurs options pour fractionner les grands modèles : <https://learn.microsoft.com/archive/blogs/adonet/working-with-large-models-in-entity-framework-part-2>.
Ce billet a été écrit pour la première version d’Entity Framework, mais les étapes s’appliquent toujours.
7.4 Considérations relatives aux performances avec le contrôle de source de données Entity
Nous avons observé des cas dans les tests de performances multithreads et de contraintes où les performances d’une application web utilisant le contrôle EntityDataSource se dégradaient considérablement. La cause sous-jacente est qu’EntityDataSource appelle de manière répétée MetadataWorkspace.LoadFromAssembly sur les assemblys référencés par l’application web pour découvrir les types à utiliser en tant qu’entités.
La solution consiste à définir le ContextTypeName de l’EntityDataSource sur le nom de type de votre classe ObjectContext dérivée. Cela désactive le mécanisme qui analyse tous les assemblys référencés pour les types d’entités.
La définition du champ ContextTypeName empêche également un problème fonctionnel où EntityDataSource dans .NET 4.0 lève une ReflectionTypeLoadException lorsqu’il ne peut pas charger un type à partir d’un assembly via la réflexion. Ce problème a été résolu dans .NET 4.5.
7.5 Entités POCO et proxys de suivi des modifications
Entity Framework vous permet d’utiliser des classes de données personnalisées avec votre modèle de données sans modifier les classes de données elles-mêmes. Cela signifie que vous pouvez utiliser des objets CLR « classiques » (ou POCO), tels que les objets de domaine existants, avec votre modèle de données. Ces classes de données POCO (également appelées objets qui ignorent la persistance), qui sont mappées à des entités définies dans un modèle de données, prennent en charge la plupart des comportements de requête, d’insertion, de mise à jour et de suppression des types d’entités générés par les outils Entity Data Model.
Entity Framework peut également créer des classes proxy dérivées de vos types POCO, qui sont utilisées lorsque vous souhaitez activer des fonctionnalités telles que le chargement différé et le suivi automatique des modifications sur les entités POCO. Vos classes POCO doivent répondre à certaines exigences pour permettre à Entity Framework d’utiliser des proxys, comme décrit ici : http://msdn.microsoft.com/library/dd468057.aspx.
Les proxys de suivi des modifications notifient le gestionnaire d’état d’objet chaque fois que la valeur de l’une des propriétés de vos entités change. Entity Framework connaît donc en permanence l’état réel de vos entités. Vous devez pour cela ajouter des événements de notification au corps des méthodes setter de vos propriétés, et faire en sorte que le gestionnaire d’état d’objet traite ces événements. Notez que la création d’une entité proxy sera généralement plus coûteuse que la création d’une entité POCO non proxy, en raison de l’ensemble d’événements supplémentaire créé par Entity Framework.
Lorsqu’une entité POCO n’a pas de proxy de suivi des modifications, les modifications sont détectées en comparant le contenu de vos entités à une copie d’un état enregistré précédent. Cette comparaison approfondie deviendra un long processus lorsque vous aurez de nombreuses entités dans votre contexte, ou lorsque vos entités auront une très grande quantité de propriétés, même si aucune d’entre elles n’a changé depuis la dernière comparaison.
En résumé : vous paierez un coût en terme de performances lors de la création du proxy de suivi des modifications, mais le suivi des modifications vous aidera à accélérer le processus de détection des modifications lorsque vos entités ont de nombreuses propriétés ou lorsque vous avez de nombreuses entités dans votre modèle. Pour les entités avec un petit nombre de propriétés où la quantité d’entités n’augmente pas trop, le fait d’avoir des proxys de suivi des modifications peut ne pas être très avantageux.
8 Chargement d’entités associées
8.1 Chargement différé ou Chargement hâtif
Entity Framework offre plusieurs façons de charger les entités associées à votre entité cible. Par exemple, lorsque vous interrogez des produits, les commandes associées seront chargées de différentes façons dans le gestionnaire d’état d’objet. Du point de vue des performances, la principale question à se poser lors du chargement des entités associées est la suivante : faut-il utiliser le chargement différé ou le chargement hâtif ?
Lors de l’utilisation du chargement hâtif, les entités associées sont chargées avec votre jeu d’entités cible. Vous utilisez une instruction Include dans votre requête pour indiquer les entités associées que vous souhaitez inclure.
Lorsque vous utilisez le chargement différé, votre requête initiale apporte uniquement le jeu d’entités cibles. Mais chaque fois que vous accédez à une propriété de navigation, une autre requête est émise sur le magasin pour charger l’entité associée.
Une fois qu’une entité a été chargée, toutes les requêtes supplémentaires pour l’entité la chargent directement à partir du gestionnaire d’état d’objet, que vous utilisiez le chargement différé ou le chargement hâtif.
8.2 Comment choisir entre le chargement différé et le chargement hâtif
L’essentiel est de bien comprendre la différence entre le chargement différé et le chargement hâtif, afin de pouvoir faire le bon choix pour votre application. Cela vous aidera à évaluer le compromis entre l’émission de requêtes multiples sur la base de données et l’émission d’une requête unique susceptible de contenir une charge utile importante. Il peut être approprié d’utiliser le chargement hâtif dans certaines parties de votre application et le chargement différé dans d’autres parties.
En guise d’exemple de ce qui se passe en coulisse, supposez que vous souhaitez rechercher les clients qui vivent au Royaume-Uni et leur nombre de commandes.
Utilisation du chargement hâtif
using (NorthwindEntities context = new NorthwindEntities())
{
var ukCustomers = context.Customers.Include(c => c.Orders).Where(c => c.Address.Country == "UK");
var chosenCustomer = AskUserToPickCustomer(ukCustomers);
Console.WriteLine("Customer Id: {0} has {1} orders", customer.CustomerID, customer.Orders.Count);
}
Utilisation du chargement différé
using (NorthwindEntities context = new NorthwindEntities())
{
context.ContextOptions.LazyLoadingEnabled = true;
//Notice that the Include method call is missing in the query
var ukCustomers = context.Customers.Where(c => c.Address.Country == "UK");
var chosenCustomer = AskUserToPickCustomer(ukCustomers);
Console.WriteLine("Customer Id: {0} has {1} orders", customer.CustomerID, customer.Orders.Count);
}
Lors de l’utilisation du chargement hâtif, vous émettrez une requête unique qui retourne tous les clients et toutes les commandes. La commande de magasin ressemble à ceci :
SELECT
[Project1].[C1] AS [C1],
[Project1].[CustomerID] AS [CustomerID],
[Project1].[CompanyName] AS [CompanyName],
[Project1].[ContactName] AS [ContactName],
[Project1].[ContactTitle] AS [ContactTitle],
[Project1].[Address] AS [Address],
[Project1].[City] AS [City],
[Project1].[Region] AS [Region],
[Project1].[PostalCode] AS [PostalCode],
[Project1].[Country] AS [Country],
[Project1].[Phone] AS [Phone],
[Project1].[Fax] AS [Fax],
[Project1].[C2] AS [C2],
[Project1].[OrderID] AS [OrderID],
[Project1].[CustomerID1] AS [CustomerID1],
[Project1].[EmployeeID] AS [EmployeeID],
[Project1].[OrderDate] AS [OrderDate],
[Project1].[RequiredDate] AS [RequiredDate],
[Project1].[ShippedDate] AS [ShippedDate],
[Project1].[ShipVia] AS [ShipVia],
[Project1].[Freight] AS [Freight],
[Project1].[ShipName] AS [ShipName],
[Project1].[ShipAddress] AS [ShipAddress],
[Project1].[ShipCity] AS [ShipCity],
[Project1].[ShipRegion] AS [ShipRegion],
[Project1].[ShipPostalCode] AS [ShipPostalCode],
[Project1].[ShipCountry] AS [ShipCountry]
FROM ( SELECT
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[CompanyName] AS [CompanyName],
[Extent1].[ContactName] AS [ContactName],
[Extent1].[ContactTitle] AS [ContactTitle],
[Extent1].[Address] AS [Address],
[Extent1].[City] AS [City],
[Extent1].[Region] AS [Region],
[Extent1].[PostalCode] AS [PostalCode],
[Extent1].[Country] AS [Country],
[Extent1].[Phone] AS [Phone],
[Extent1].[Fax] AS [Fax],
1 AS [C1],
[Extent2].[OrderID] AS [OrderID],
[Extent2].[CustomerID] AS [CustomerID1],
[Extent2].[EmployeeID] AS [EmployeeID],
[Extent2].[OrderDate] AS [OrderDate],
[Extent2].[RequiredDate] AS [RequiredDate],
[Extent2].[ShippedDate] AS [ShippedDate],
[Extent2].[ShipVia] AS [ShipVia],
[Extent2].[Freight] AS [Freight],
[Extent2].[ShipName] AS [ShipName],
[Extent2].[ShipAddress] AS [ShipAddress],
[Extent2].[ShipCity] AS [ShipCity],
[Extent2].[ShipRegion] AS [ShipRegion],
[Extent2].[ShipPostalCode] AS [ShipPostalCode],
[Extent2].[ShipCountry] AS [ShipCountry],
CASE WHEN ([Extent2].[OrderID] IS NULL) THEN CAST(NULL AS int) ELSE 1 END AS [C2]
FROM [dbo].[Customers] AS [Extent1]
LEFT OUTER JOIN [dbo].[Orders] AS [Extent2] ON [Extent1].[CustomerID] = [Extent2].[CustomerID]
WHERE N'UK' = [Extent1].[Country]
) AS [Project1]
ORDER BY [Project1].[CustomerID] ASC, [Project1].[C2] ASC
Lors de l’utilisation du chargement différé, vous émettrez initialement la requête suivante :
SELECT
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[CompanyName] AS [CompanyName],
[Extent1].[ContactName] AS [ContactName],
[Extent1].[ContactTitle] AS [ContactTitle],
[Extent1].[Address] AS [Address],
[Extent1].[City] AS [City],
[Extent1].[Region] AS [Region],
[Extent1].[PostalCode] AS [PostalCode],
[Extent1].[Country] AS [Country],
[Extent1].[Phone] AS [Phone],
[Extent1].[Fax] AS [Fax]
FROM [dbo].[Customers] AS [Extent1]
WHERE N'UK' = [Extent1].[Country]
Et chaque fois que vous accéderez à la propriété de navigation Orders d’un client, une autre requête comme celle-ci sera émise sur le magasin :
exec sp_executesql N'SELECT
[Extent1].[OrderID] AS [OrderID],
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[EmployeeID] AS [EmployeeID],
[Extent1].[OrderDate] AS [OrderDate],
[Extent1].[RequiredDate] AS [RequiredDate],
[Extent1].[ShippedDate] AS [ShippedDate],
[Extent1].[ShipVia] AS [ShipVia],
[Extent1].[Freight] AS [Freight],
[Extent1].[ShipName] AS [ShipName],
[Extent1].[ShipAddress] AS [ShipAddress],
[Extent1].[ShipCity] AS [ShipCity],
[Extent1].[ShipRegion] AS [ShipRegion],
[Extent1].[ShipPostalCode] AS [ShipPostalCode],
[Extent1].[ShipCountry] AS [ShipCountry]
FROM [dbo].[Orders] AS [Extent1]
WHERE [Extent1].[CustomerID] = @EntityKeyValue1',N'@EntityKeyValue1 nchar(5)',@EntityKeyValue1=N'AROUT'
Pour plus d’informations, consultez Chargement d’objets connexes.
8.2.1 Aide-mémoire pour le chargement différé/chargement hâtif
Il n’existe pas de solution miracle et universelle lors du choix entre le chargement hâtif et le chargement différé. Essayez d’abord de comprendre les différences entre les deux stratégies afin de pouvoir prendre une décision bien informée. Déterminez également si votre code correspond à l’un des scénarios suivants :
| Scénario | Notre suggestion |
|---|---|
| Avez-vous besoin d’accéder à de nombreuses propriétés de navigation à partir des entités extraites ? | Non - Les deux options conviendront probablement. Toutefois, si la charge utile apportée par votre requête n’est pas trop volumineuse, vous obtiendrez peut-être des avantages en matière de performances en utilisant le chargement hâtif, car il nécessite moins d’allers-retours réseau pour matérialiser vos objets. Oui - Si vous avez besoin d’accéder à de nombreuses propriétés de navigation à partir des entités, vous devez le faire à l’aide de plusieurs instructions include dans votre requête avec le chargement hâtif. Plus vous incluez d’entités, plus la charge utile retournée par votre requête sera importante. Dès que vous incluez trois entités ou plus dans votre requête, envisagez de passer au chargement différé. |
| Savez-vous exactement quelles données seront nécessaires au moment de l’exécution ? | Non - Le chargement différé sera plus adapté. Autrement, vous risquez de finir par interroger des données dont vous n’aurez pas besoin. Oui - Le chargement hâtif sera probablement le meilleur choix ; il aidera à charger des jeux entiers plus rapidement. Si votre requête nécessite l’extraction d’une très grande quantité de données, et que cela devient trop lent, essayez le chargement différé à la place. |
| Votre code s’exécute-t-il loin de votre base de données ? (latence réseau accrue) | Non - Lorsque la latence réseau n’est pas un problème, l’utilisation du chargement différé peut simplifier votre code. N’oubliez pas que la topologie de votre application peut changer, donc ne prenez pas la proximité de la base de données comme acquise. Oui - Quand le réseau constitue un problème, vous seul pouvez décider de ce qui convient le mieux à votre scénario. En règle générale, le chargement hâtif sera préférable, car il nécessite moins d’allers-retours. |
8.2.2 Problèmes de performances avec plusieurs instructions Include
Lorsque nous entendons des questions relatives aux performances qui impliquent des problèmes de temps de réponse du serveur, la source du problème est fréquemment au niveau des requêtes comportant plusieurs instructions Include. Bien que l’inclusion d’entités associées dans une requête soit puissante, il est important de comprendre ce qui se passe en coulisse.
Il faut relativement longtemps pour qu’une requête comportant plusieurs instructions Include passe par notre compilateur de plan interne en vue de produire la commande de magasin. La plus grande partie de ce temps est consacrée à essayer d’optimiser la requête résultante. La commande de magasin générée contient une jointure externe ou une union pour chaque instruction Include, en fonction de votre mappage. Les requêtes telles que celles-ci apportent de grands graphes connectés à partir de votre base de données dans une charge utile unique, ce qui accroît encore davantage les éventuels problèmes de bande passante, en particulier lorsqu’il y a beaucoup de redondance dans la charge utile (par exemple lorsque plusieurs niveaux d’Include sont utilisés pour traverser des associations dans la direction un-à-plusieurs).
Vous pouvez rechercher les cas où vos requêtes retournent des charges utiles excessivement volumineuses en accédant au TSQL sous-jacent de la requête à l’aide de ToTraceString et en exécutant la commande de magasin dans SQL Server Management Studio pour voir la taille de la charge utile. Dans ces cas-là, vous pouvez essayer de réduire le nombre d’instructions Include dans votre requête afin d’importer simplement les données dont vous avez besoin. Vous pouvez également décomposer votre requête en une séquence plus petite de sous-requêtes, par exemple comme suit :
Avant de décomposer la requête :
using (NorthwindEntities context = new NorthwindEntities())
{
var customers = from c in context.Customers.Include(c => c.Orders)
where c.LastName.StartsWith(lastNameParameter)
select c;
foreach (Customer customer in customers)
{
...
}
}
Après avoir décomposé la requête :
using (NorthwindEntities context = new NorthwindEntities())
{
var orders = from o in context.Orders
where o.Customer.LastName.StartsWith(lastNameParameter)
select o;
orders.Load();
var customers = from c in context.Customers
where c.LastName.StartsWith(lastNameParameter)
select c;
foreach (Customer customer in customers)
{
...
}
}
Cela fonctionne uniquement sur les requêtes suivies, car nous utilisons la capacité du contexte à effectuer automatiquement la résolution des identités et la correction d’association.
Comme avec le chargement différé, le compromis sera un plus grand nombre de requêtes pour des charges utiles plus petites. Vous pouvez également utiliser des projections de propriétés individuelles pour sélectionner explicitement uniquement les données dont vous avez besoin à partir de chaque entité, mais vous ne chargerez pas d’entités dans ce cas, et les mises à jour ne seront pas prises en charge.
8.2.3 Solution de contournement pour obtenir le chargement différé des propriétés
Entity Framework ne prend actuellement pas en charge le chargement différé de propriétés scalaires ou complexes. Toutefois, dans les cas où vous disposez d’une table qui inclut un objet volumineux tel qu’un objet BLOB, vous pouvez utiliser le fractionnement de table pour séparer les propriétés volumineuses en une entité distincte. Par exemple, supposez que vous disposez d’une table Product qui inclut une colonne de photos varbinary. Si vous n’avez pas fréquemment besoin d’accéder à cette propriété dans vos requêtes, vous pouvez utiliser le fractionnement de table pour importer uniquement les parties de l’entité dont vous avez normalement besoin. L’entité représentant la photo du produit ne sera chargée que lorsque vous en aurez besoin explicitement.
Le billet de blog de Gil Fink intitulé « Table Splitting in Entity Framework » (<http://blogs.microsoft.co.il/blogs/gilf/archive/2009/10/13/table-splitting-in-entity-framework.aspx>) constitue une bonne ressource qui illustre comment activer le fractionnement de table.
9 Autres considérations
9.1 Nettoyage de la mémoire du serveur
Certains utilisateurs peuvent observer une contention de ressources qui limite le parallélisme attendu lorsque le récupérateur de mémoire n’est pas correctement configuré. Chaque fois qu’EF est utilisé dans un scénario multithread ou dans une application qui s’apparente à un système côté serveur, veillez à activer le nettoyage de la mémoire du serveur. Cette opération peut être effectuée par le biais d’un simple paramètre dans votre fichier de configuration d’application :
<?xmlversion="1.0" encoding="utf-8" ?>
<configuration>
<runtime>
<gcServer enabled="true" />
</runtime>
</configuration>
Cela devrait diminuer votre contention de threads et augmenter votre débit jusqu’à 30 % dans les scénarios de saturation du processeur. En général, vous devez toujours tester le comportement de votre application à l’aide du nettoyage de la mémoire classique (qui est plus adapté aux scénarios côté interface utilisateur et côté client) et du nettoyage de la mémoire de serveur.
9.2 AutoDetectChanges
Comme mentionné plus haut, Entity Framework peut présenter des problèmes de performances lorsque le cache d’objets comporte de nombreuses entités. Certaines opérations, telles qu’Add, Remove, Find, Entry et SaveChanges, déclenchent des appels à DetectChanges qui peuvent consommer une grande quantité de ressources de processeur en fonction de la taille du cache d’objets. La raison en est que le cache d’objets et le gestionnaire d’état d’objet essaient de rester le plus synchronisés possible lors de chaque opération effectuée dans un contexte, afin de garantir que les données produites soient correctes dans un large éventail de scénarios.
Il est généralement recommandé de laisser la détection automatique des modifications d’Entity Framework activée pour toute la durée de vie de votre application. Si votre scénario est affecté négativement par une utilisation élevée du processeur et que vos profils indiquent que le coupable est l’appel à DetectChanges, désactivez temporairement AutoDetectChanges dans la partie sensible de votre code :
try
{
context.Configuration.AutoDetectChangesEnabled = false;
var product = context.Products.Find(productId);
...
}
finally
{
context.Configuration.AutoDetectChangesEnabled = true;
}
Avant de désactiver AutoDetectChanges, il faut savoir qu’Entity Framework risque dans ce cas de perdre sa capacité à suivre certaines informations concernant les modifications qui se produisent sur les entités. Si cette situation est mal gérée, cela peut entraîner des incohérences de données sur votre application. Pour plus d’informations sur la désactivation d’AutoDetectChanges, consultez <http://blog.oneunicorn.com/2012/03/12/secrets-of-detectchanges-part-3-switching-off-automatic-detectchanges/>.
9.3 Contexte par requête
Les contextes d’Entity Framework sont censés être utilisés en tant qu’instances de courte durée afin de fournir une expérience aux performances optimales. Les contextes étant censés être de courte durée et supprimés, ils ont par conséquent été implémentés pour être très légers et de manière à réutiliser les métadonnées dans la mesure du possible. Dans les scénarios web, il est important de garder cela à l’esprit et de ne pas avoir de contexte pendant plus de la durée d’une seule requête. De même, dans les scénarios non web, le contexte doit être supprimé en fonction de votre compréhension des différents niveaux de mise en cache dans Entity Framework. En règle générale, il est préférable d’éviter d’avoir une instance de contexte pendant toute la durée de vie de l’application, ainsi que des contextes par thread et des contextes statiques.
9.4 Sémantique Null de la base de données
Entity Framework génère par défaut du code SQL qui a une sémantique de comparaison Null C#. Prenez l’exemple de requête suivant :
int? categoryId = 7;
int? supplierId = 8;
decimal? unitPrice = 0;
short? unitsInStock = 100;
short? unitsOnOrder = 20;
short? reorderLevel = null;
var q = from p incontext.Products
where p.Category.CategoryName == "Beverages"
|| (p.CategoryID == categoryId
|| p.SupplierID == supplierId
|| p.UnitPrice == unitPrice
|| p.UnitsInStock == unitsInStock
|| p.UnitsOnOrder == unitsOnOrder
|| p.ReorderLevel == reorderLevel)
select p;
var r = q.ToList();
Dans cet exemple, nous comparons un certain nombre de variables nullables à des propriétés nullables sur l’entité, telles que SupplierID et UnitPrice. Le code SQL généré pour cette requête demande si la valeur du paramètre est identique à la valeur de colonne, ou si les valeurs du paramètre et de la colonne sont toutes deux Null. Cela masque la façon dont le serveur de base de données gère les valeurs Null, et fournit une expérience Null C# cohérente avec différents fournisseurs de base de données. En revanche, le code généré est un peu alambiqué, et risque de ne pas offrir d’excellentes performances lorsque la quantité de comparaisons dans l’instruction where de la requête atteint un chiffre élevé.
L’une des façons de gérer cette situation consiste à utiliser la sémantique Null de base de données. Notez que le comportement peut différer de celui de la sémantique Null C#, car Entity Framework générera désormais du code SQL plus simple qui exposera la façon dont le moteur de base de données gère les valeurs Null. La sémantique Null de base de données peut être activée par contexte avec une seule ligne de configuration appliquée à la configuration du contexte :
context.Configuration.UseDatabaseNullSemantics = true;
Les requêtes de petite à moyenne taille n’offrent pas d’amélioration des performances perceptibles lors de l’utilisation de la sémantique Null de base de données, mais la différence devient plus visible sur les requêtes avec un grand nombre de comparaisons Null potentielles.
Dans l’exemple de requête ci-dessus, la différence de performances était inférieure à 2 % dans un microbenchmark s’exécutant dans un environnement contrôlé.
9.5 Async
Entity Framework 6 a introduit la prise en charge des opérations asynchrones lors de l’exécution sur .NET 4.5 ou version ultérieure. Dans la plupart des cas, les applications qui ont des conflits liés aux E/S tireront le meilleur parti de l’utilisation d’opérations de requête et d’enregistrement asynchrones. Si votre application ne souffre pas de conflits d’E/S, l’utilisation d’Async, dans le meilleur des cas, entraînera une exécution de manière synchrone et retournera le résultat dans les mêmes délais qu’un appel synchrone. Dans le pire des cas, cela différera simplement l’exécution à une tâche asynchrone et ajoutera du temps supplémentaire à l’achèvement de votre scénario.
Pour plus d’informations sur le fonctionnement de la programmation asynchrone qui vous aideront à décider si Async améliorera les performances de votre application, consultez Programmation asynchrone avec Async et Await. Pour plus d’informations sur l’utilisation d’opérations asynchrones sur Entity Framework, consultez Requête et enregistrement asynchrones.
9.6 NGEN
Entity Framework 6 n’est pas fourni avec l’installation par défaut du .NET Framework. Par conséquent, NGEN n’est pas exécuté par défaut sur les assemblys Entity Framework, ce qui signifie que tout le code Entity Framework est soumis aux mêmes coûts JIT que tout autre assembly MSIL. Cela peut dégrader l’expérience F5 lors du développement et du démarrage à froid de votre application dans les environnements de production. Afin de réduire les coûts de processeur et de mémoire liés à JIT, il est conseillé d’exécuter NGEN sur les images Entity Framework selon les besoins. Pour plus d’informations sur la façon d’améliorer les performances de démarrage d’Entity Framework 6 avec NGEN, consultez Amélioration des performances de démarrage avec NGen.
9.7 Code First et EDMX
Entity Framework aborde le problème d’incompatibilité d’impédance entre la programmation orientée objet et les bases de données relationnelles en ayant une représentation en mémoire du modèle conceptuel (les objets), du schéma de stockage (la base de données) et d’un mappage entre les deux. Ces métadonnées sont appelées Entity Data Model, ou EDM. À partir de cet EDM, Entity Framework dérive les vues pour l’aller-retour des données entre les objets en mémoire et la base de données.
Lorsque Entity Framework est utilisé avec un fichier EDMX qui spécifie formellement le modèle conceptuel, le schéma de stockage et le mappage, l’étape de chargement du modèle doit uniquement vérifier que l’EDM est correct (par exemple s’assurer qu’aucun mappage n’est manquant), générer les vues, les valider, puis faire en sorte que ces métadonnées soient prêtes à être utilisées. C’est uniquement à ce moment-là qu’une requête pourra être exécutée ou de nouvelles données enregistrées dans le magasin de données.
L’approche Code First est essentiellement un générateur d’Entity Data Model sophistiqué. Entity Framework doit produire un EDM à partir du code fourni ; il le fait en analysant les classes impliquées dans le modèle, en appliquant des conventions et en configurant le modèle via l’API Fluent. Une fois l’EDM généré, Entity Framework se comporte essentiellement de la même façon que si un fichier EDMX avait été présent dans le projet. Ainsi, la génération du modèle à partir de Code First ajoute une complexité supplémentaire qui se traduit par un temps de démarrage plus lent pour Entity Framework, par rapport à l’utilisation d’un fichier EDMX. Le coût dépend entièrement de la taille et de la complexité du modèle qui est généré.
Lors du choix entre EDMX et Code First, il est important de savoir que la flexibilité introduite par Code First augmente le coût de la génération initiale du modèle. Si votre application peut supporter le coût de cette charge initiale, il est généralement préférable d’adopter l’approche Code First.
10 Investigation des performances
10.1 Utiliser le profileur Visual Studio
Si vous rencontrez des problèmes de performances avec Entity Framework, vous pouvez utiliser un profileur comme celui intégré à Visual Studio pour voir où votre application passe son temps. Il s’agit de l’outil que nous avons utilisé pour générer les graphiques en secteurs dans le billet de blog « Exploring the Performance of the ADO.NET Entity Framework - Part 1 » (<https://learn.microsoft.com/archive/blogs/adonet/exploring-the-performance-of-the-ado-net-entity-framework-part-1>) qui indiquent où Entity Framework passe son temps pendant les requêtes froides et chaudes.
Le billet de blog « Profiling Entity Framework using the Visual Studio 2010 Profiler » écrit par l’équipe de consultants clients Données et modélisation illustre un exemple concret de la façon dont elle a utilisé le profileur pour investiguer un problème de performances. <https://learn.microsoft.com/archive/blogs/dmcat/profiling-entity-framework-using-the-visual-studio-2010-profiler>. Ce billet a été écrit pour une application Windows. Si vous devez profiler une application web, il peut être préférable d’utiliser les outils WPR (Enregistreur de performance Windows) et WPA (Analyseur de performances Windows) plutôt que de travailler à partir de Visual Studio. WPR et WPA font partie de Windows Performance Toolkit, qui est inclus dans le Kit de déploiement et d’évaluation Windows.
10.2 Profilage d’application/de base de données
Des outils tels que le profileur intégré à Visual Studio vous indiquent où votre application passe du temps. Un autre type de profileur disponible effectue une analyse dynamique de votre application en cours d’exécution, en production ou en préproduction en fonction des besoins, et recherche des pièges courants et des anti-modèles d’accès à la base de données.
Entity Framework Profiler (<http://efprof.com>) et ORMProfiler (<http://ormprofiler.com>) sont deux profileurs disponibles commercialement.
Si votre application est une application MVC utilisant Code First, vous pouvez utiliser MiniProfiler de StackExchange. Scott Hanselman décrit cet outil dans son blog à l’adresse <http://www.hanselman.com/blog/NuGetPackageOfTheWeek9ASPNETMiniProfilerFromStackExchangeRocksYourWorld.aspx>.
Pour plus d’informations sur le profilage de l’activité de base de données de votre application, consultez l’article MSDN Magazine de Julie Lerman intitulé Profilage de l’activité des bases de données dans Entity Framework.
10.3 Enregistreur d’événements de base de données
Si vous utilisez Entity Framework 6, pensez également à utiliser la fonctionnalité de journalisation intégrée. La propriété Database du contexte peut être chargée de consigner son activité via une configuration simple en une seule ligne :
using (var context = newQueryComparison.DbC.NorthwindEntities())
{
context.Database.Log = Console.WriteLine;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
Dans cet exemple, l’activité de base de données est journalisée dans la console, mais la propriété Log peut être configurée de façon à appeler n’importe quel délégué Action<chaîne>.
Si vous souhaitez activer la journalisation de base de données sans recompiler et que vous utilisez Entity Framework 6.1 ou version ultérieure, vous pouvez le faire en ajoutant un intercepteur dans le fichier web.config ou app.config de votre application.
<interceptors>
<interceptor type="System.Data.Entity.Infrastructure.Interception.DatabaseLogger, EntityFramework">
<parameters>
<parameter value="C:\Path\To\My\LogOutput.txt"/>
</parameters>
</interceptor>
</interceptors>
Pour plus d’informations sur l’ajout de la journalisation sans recompiler, accédez à <http://blog.oneunicorn.com/2014/02/09/ef-6-1-turning-on-logging-without-recompiling/>.
11 Annexe
11.1 A. Environnement de test
Cet environnement utilise une configuration à deux machines, la base de données étant sur une machine distincte de l’application cliente. Les machines se trouvant dans le même rack, la latence réseau est relativement faible, mais plus réaliste qu’un environnement à une seule machine.
11.1.1 Serveur d’applications
11.1.1.1 Environnement logiciel
- Environnement logiciel Entity Framework 4
- Nom du système d’exploitation : Windows Server 2008 R2 Enterprise SP1
- Visual Studio 2010 – Ultimate
- Visual Studio 2010 SP1 (uniquement pour certaines comparaisons).
- Environnement logiciel Entity Framework 5 et 6
- Nom du système d’exploitation : Windows 8.1 Entreprise
- Visual Studio 2013 – Ultimate
11.1.1.2 Environnement matériel
- Double processeur : Processeur Intel(R) Xeon(R) L5520 W3530 @ 2,27 GHz, 2 261 Mhz8 GHz, quatre cœurs, 84 processeurs logiques
- 2 412 Go de RAM
- Lecteur 136 Go SCSI250GB SATA 7200 rpm 3 Go/s fractionné en quatre partitions
11.1.2 Serveur de base de données
11.1.2.1 Environnement logiciel
- Nom du système d’exploitation : Windows Server 2008 R28.1 Enterprise SP1
- SQL Server 2008 R22012
11.1.2.2 Environnement matériel
- Processeur unique : Processeur Intel(R) Xeon(R) L5520 @ 2,27 GHz, 2261 MhzES-1620 0 @ 3,60 GHz, quatre cœurs, huit processeurs logiques
- 824 Go de RAM
- Lecteur 465 Go ATA500GB SATA 7200 rpm 6 Go/s fractionné en quatre partitions
11.2 B. Tests de comparaison des performances des requêtes
Le modèle Northwind a été utilisé pour exécuter ces tests. Il a été généré à partir de la base de données à l’aide du concepteur Entity Framework. Ensuite, le code suivant a été utilisé pour comparer les performances des options d’exécution de requête :
using System;
using System.Collections.Generic;
using System.Data;
using System.Data.Common;
using System.Data.Entity.Infrastructure;
using System.Data.EntityClient;
using System.Data.Objects;
using System.Linq;
namespace QueryComparison
{
public partial class NorthwindEntities : ObjectContext
{
private static readonly Func<NorthwindEntities, string, IQueryable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
public IQueryable<Product> InvokeProductsForCategoryCQ(string categoryName)
{
return productsForCategoryCQ(this, categoryName);
}
}
public class QueryTypePerfComparison
{
private static string entityConnectionStr = @"metadata=res://*/Northwind.csdl|res://*/Northwind.ssdl|res://*/Northwind.msl;provider=System.Data.SqlClient;provider connection string='data source=.;initial catalog=Northwind;integrated security=True;multipleactiveresultsets=True;App=EntityFramework'";
public void LINQIncludingContextCreation()
{
using (NorthwindEntities context = new NorthwindEntities())
{
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void LINQNoTracking()
{
using (NorthwindEntities context = new NorthwindEntities())
{
context.Products.MergeOption = MergeOption.NoTracking;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void CompiledQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
var q = context.InvokeProductsForCategoryCQ("Beverages");
q.ToList();
}
}
public void ObjectQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
ObjectQuery<Product> products = context.Products.Where("it.Category.CategoryName = 'Beverages'");
products.ToList();
}
}
public void EntityCommand()
{
using (EntityConnection eConn = new EntityConnection(entityConnectionStr))
{
eConn.Open();
EntityCommand cmd = eConn.CreateCommand();
cmd.CommandText = "Select p From NorthwindEntities.Products As p Where p.Category.CategoryName = 'Beverages'";
using (EntityDataReader reader = cmd.ExecuteReader(CommandBehavior.SequentialAccess))
{
List<Product> productsList = new List<Product>();
while (reader.Read())
{
DbDataRecord record = (DbDataRecord)reader.GetValue(0);
// 'materialize' the product by accessing each field and value. Because we are materializing products, we won't have any nested data readers or records.
int fieldCount = record.FieldCount;
// Treat all products as Product, even if they are the subtype DiscontinuedProduct.
Product product = new Product();
product.ProductID = record.GetInt32(0);
product.ProductName = record.GetString(1);
product.SupplierID = record.GetInt32(2);
product.CategoryID = record.GetInt32(3);
product.QuantityPerUnit = record.GetString(4);
product.UnitPrice = record.GetDecimal(5);
product.UnitsInStock = record.GetInt16(6);
product.UnitsOnOrder = record.GetInt16(7);
product.ReorderLevel = record.GetInt16(8);
product.Discontinued = record.GetBoolean(9);
productsList.Add(product);
}
}
}
}
public void ExecuteStoreQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
ObjectResult<Product> beverages = context.ExecuteStoreQuery<Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void ExecuteStoreQueryDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var beverages = context.Database.SqlQuery\<QueryComparison.DbC.Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void ExecuteStoreQueryDbSet()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var beverages = context.Products.SqlQuery(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void LINQIncludingContextCreationDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void LINQNoTrackingDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var q = context.Products.AsNoTracking().Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
}
}
11.3 C. Modèle Navision
La base de données Navision est une base de données volumineuse utilisée à des fins de démonstration de Microsoft Dynamics – NAV. Le modèle conceptuel généré contient 1005 jeux d’entités et 4 227 ensembles d’associations. Le modèle utilisé lors du test est « plat » ; aucun héritage n’y a été ajouté.
11.3.1 Requêtes utilisées pour les tests Navision
La liste des requêtes utilisée avec le modèle Navision contient trois catégories de requêtes Entity SQL :
11.3.1.1 Recherche
Une requête de recherche simple sans agrégation
- Quantité : 16 232
- Exemple :
<Query complexity="Lookup">
<CommandText>Select value distinct top(4) e.Idle_Time From NavisionFKContext.Session as e</CommandText>
</Query>
11.3.1.2 SingleAggregating
Une requête BI normale avec plusieurs agrégations, mais pas de sous-totaux (requête unique)
- Quantité : 2 313
- Exemple :
<Query complexity="SingleAggregating">
<CommandText>NavisionFK.MDF_SessionLogin_Time_Max()</CommandText>
</Query>
Où MDF_SessionLogin_Time_Max() est défini dans le modèle comme suit :
<Function Name="MDF_SessionLogin_Time_Max" ReturnType="Collection(DateTime)">
<DefiningExpression>SELECT VALUE Edm.Min(E.Login_Time) FROM NavisionFKContext.Session as E</DefiningExpression>
</Function>
11.3.1.3 AggregatingSubtotals
Une requête BI avec agrégations et sous-totaux (via union all)
- Quantité : 178
- Exemple :
<Query complexity="AggregatingSubtotals">
<CommandText>
using NavisionFK;
function AmountConsumed(entities Collection([CRONUS_International_Ltd__Zone])) as
(
Edm.Sum(select value N.Block_Movement FROM entities as E, E.CRONUS_International_Ltd__Bin as N)
)
function AmountConsumed(P1 Edm.Int32) as
(
AmountConsumed(select value e from NavisionFKContext.CRONUS_International_Ltd__Zone as e where e.Zone_Ranking = P1)
)
----------------------------------------------------------------------------------------------------------------------
(
select top(10) Zone_Ranking, Cross_Dock_Bin_Zone, AmountConsumed(GroupPartition(E))
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed
group by E.Zone_Ranking, E.Cross_Dock_Bin_Zone
)
union all
(
select top(10) Zone_Ranking, Cast(null as Edm.Byte) as P2, AmountConsumed(GroupPartition(E))
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed
group by E.Zone_Ranking
)
union all
{
Row(Cast(null as Edm.Int32) as P1, Cast(null as Edm.Byte) as P2, AmountConsumed(select value E
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed))
}</CommandText>
<Parameters>
<Parameter Name="MinAmountConsumed" DbType="Int32" Value="10000" />
</Parameters>
</Query>
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour