Architecture 2019 Exchange recommandées
Avec chaque nouvelle version de Exchange Server pour nos clients locaux, nous mettons à jour notre architecture préférée et discutons des modifications que nous aimerions que nos clients connaissent. Exchange Server 2013 nous a apporté la première architecture préférée dans l’histoire moderne d’Exchange, puis a été suivie d’une actualisation pour Exchange Server 2016 en fournissant des perfectionnements pour les modifications apportées à la version 2016. Avec cette mise à jour pour Exchange Server 2019, nous allons itérer sur la pa précédente pour tirer parti des nouvelles technologies et des améliorations.
L’architecture par défaut
Le pa est la recommandation des meilleures pratiques de l’équipe d’ingénierie Exchange Server pour ce que nous pensons être la meilleure architecture de déploiement pour Exchange Server 2019 dans un environnement local.
Bien qu’Exchange 2019 offre un large éventail de choix architecturaux pour les déploiements locaux, l’architecture décrite ici est la plus examinée. Bien qu’il existe d’autres architectures de déploiement prises en charge, elles ne sont pas recommandées.
Le fait de suivre la pa permet aux clients de devenir membres d’une communauté d’organisations avec des déploiements Exchange Server similaires. Cette stratégie facilite le partage des connaissances et fournit une réponse plus rapide aux circonstances imprévues. Notre propre organisation de support est consciente de ce à quoi doit ressembler un déploiement d’autorité de réponse Exchange Server et l’empêche de passer de longs cycles à apprendre et à comprendre l’environnement hautement personnalisé d’un client avant de travailler avec lui vers une résolution de cas de support.
Le pa est conçu avec plusieurs exigences métier à l’esprit, telles que l’exigence que l’architecture soit en mesure de :
Inclure à la fois la haute disponibilité dans le centre de données et la résilience des sites entre les centres de données
Prendre en charge plusieurs copies de chaque base de données, ce qui permet une activation rapide
Réduire le coût de l’infrastructure de messagerie
Augmenter la disponibilité en optimisant les domaines d’échec et en réduisant la complexité
La nature normative spécifique du pa signifie que tous les clients ne seront pas en mesure de le déployer mot à mot. Par exemple, tous nos clients n’ont pas plusieurs centres de données. Certains de nos clients peuvent avoir des exigences métier ou des stratégies internes différentes qu’ils doivent respecter, ce qui nécessite une architecture de déploiement différente. Si vous entrez dans ces catégories et que vous souhaitez déployer Exchange localement, il existe toujours des avantages à adhérer aussi étroitement que possible à l’autorité de certification et à s’écarter uniquement lorsque vos exigences ou stratégies vous forcent à différer. Vous pouvez également toujours envisager Microsoft 365 ou Office 365 où vous ne devez plus déployer ou gérer un grand nombre de serveurs.
Le pa supprime la complexité et la redondance si nécessaire pour diriger l’architecture vers un modèle de récupération prédictible : en cas de défaillance, une autre copie de la base de données affectée est activée.
Le PA couvre les quatre domaines d’intérêt suivants :
Pour Exchange Server 2019, nous n’avons aucune modification dans trois des quatre catégories de l’architecture préférée Exchange Server 2016. Les domaines de la conception de l’espace de noms, de la conception du centre de données et de la conception DAG ne reçoivent aucune modification majeure. Nous avons été satisfaits des déploiements de clients qui ont suivi de près la pa Exchange Server 2016 et ne voyons pas la nécessité de s’écarter des recommandations dans ces domaines.
Les changements les plus notables dans le Exchange Server PA 2019 se concentrent sur le domaine de la conception du serveur en raison de certaines technologies nouvelles et passionnantes.
Conception de l’espace de noms
Dans les articles Principes de planification de l’espace de noms et d’équilibrage de charge pour Exchange Server 2016, Ross Smith IV a décrit les différents choix de configuration disponibles avec Exchange 2016 et ces concepts continuent de s’appliquer pour Exchange Server 2019. Pour l’espace de noms, les choix sont de déployer un espace de noms lié (en ayant une préférence pour les utilisateurs pour qu’ils opèrent à partir d’un centre de données spécifique) ou un espace de noms indépendant (les utilisateurs se connectant à n’importe quel centre de données sans préférence).
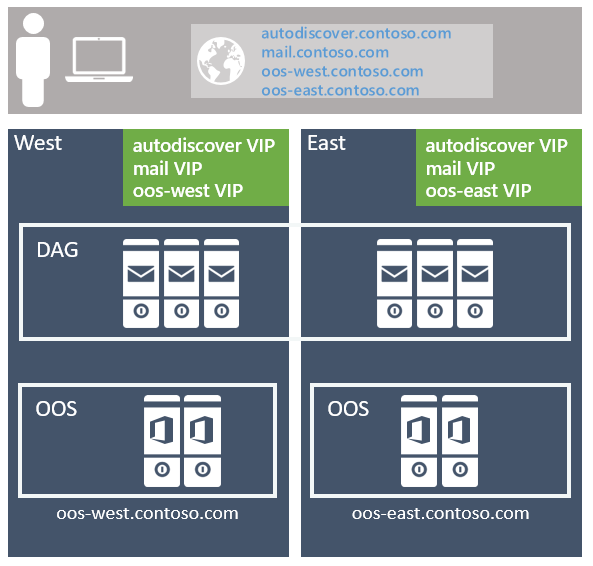
L’approche recommandée est d’utiliser le modèle sans limite, en déployant un espace de noms Exchange unique par protocole client pour la paire de centres de données résilients au site (où chaque centre de données est supposé représenter son propre site Active Directory ( voir plus d’informations à ce sujet ci-dessous). Par exemple :
Pour le service de découverte automatique : autodiscover.contoso.com
Pour les clients HTTP : mail.contoso.com
Pour les clients IMAP : imap.contoso.com
Pour les clients SMTP : smtp.contoso.com
Chaque espace de noms Exchange est équilibré en charge sur les deux centres de données dans une configuration de couche 7 qui n’utilise pas l’affinité de session, ce qui entraîne la proxiation de 50 % du trafic entre les centres de données. Le trafic est réparti de manière égale entre les centres de données dans la paire résiliente au site, par le biais d’un DNS par tourniquet (round robin), d’un géo-DNS ou d’autres solutions similaires. De notre point de vue, la solution la plus simple étant la moins complexe et la plus facile à gérer, nous vous recommandons d’utiliser le DNS par tourniquet (round robin).
L’une des précautions que nous avons pour les clients consiste à vous assurer que vous affectez une valeur TTL (durée de vie) faible pour tout enregistrement DNS associé à votre architecture Exchange. Si une panne complète du centre de données se produit lorsque vous utilisez le DNS par tourniquet (round robin), vous devez conserver la possibilité de mettre à jour rapidement vos enregistrements DNS. Vous devez supprimer les adresses IP du centre de données hors connexion afin qu’elles ne soient pas retournées pour les requêtes DNS. Par exemple, si vos enregistrements DNS ont une durée de vie plus longue de 24 heures, la mise à jour correcte des caches DNS en aval peut prendre jusqu’à un jour. Si vous n’effectuez pas cette étape, vous constaterez peut-être que certains clients ne peuvent pas passer correctement aux adresses IP encore disponibles dans votre centre de données restant. N’oubliez pas de rajouter les adresses IP à vos enregistrements DNS lorsque votre centre de données précédemment hors connexion est récupéré et prêt à héberger à nouveau des services.
L’affinité de centre de données est requise pour les batteries de serveurs Office Online Server. Par conséquent, un espace de noms est déployé par centre de données avec l’équilibreur de charge utilisant la couche 7 et conservant l’affinité de session via la persistance basée sur les cookies.
Si vous avez plusieurs paires de centres de données résilientes au site dans votre environnement, vous devez décider si vous souhaitez avoir un seul espace de noms mondial ou si vous souhaitez contrôler le trafic vers chaque centre de données spécifique à l’aide d’espaces de noms régionaux. Votre décision dépend de la topologie de votre réseau et du coût associé à l’utilisation d’un modèle indépendant ; Par exemple, si vous avez des centres de données situés en Amérique du Nord et en Afrique du Sud, la liaison réseau entre ces régions peut non seulement être coûteuse, mais elle peut également présenter une latence élevée, ce qui peut entraîner des problèmes opérationnels et de douleur pour les utilisateurs. Dans ce cas, il est judicieux de déployer un modèle lié avec un espace de noms distinct pour chaque région. Toutefois, des options telles que le DNS géographique vous offrent la possibilité de déployer un espace de noms unifié unique, même lorsque vous avez des liaisons réseau coûteuses. geo-DNS vous permet de diriger vos utilisateurs vers le centre de données le plus proche en fonction de l’adresse IP de leur client.
Conception de paires de centres de données résilientes aux sites
Pour obtenir une architecture hautement disponible et résiliente au site, vous devez disposer de deux centres de données ou plus bien connectés (dans l’idéal, vous souhaitez une faible latence réseau aller-retour, sinon la réplication et l’expérience client sont affectées négativement). En outre, les centres de données doivent être connectés via des chemins réseau redondants fournis par différents opérateurs d’exploitation.
Bien que nous prenions en charge l’extension d’un site Active Directory sur plusieurs centres de données, nous recommandons que chaque centre de données soit son propre site Active Directory. Il y a deux raisons :
La résilience du site de transport par le biais de la redondance de l’ombre dans Exchange Server et du réseau de sécurité dans Exchange Server ne peut être obtenue que lorsque le DAG a des membres situés dans plusieurs sites Active Directory.
Active Directory a publié des instructions qui indiquent que les sous-réseaux doivent être placés dans différents sites Active Directory lorsque la latence aller-retour est supérieure à 10 ms entre les sous-réseaux.
Conception du serveur
Dans le pa, tous les serveurs sont des serveurs physiques et utilisent un stockage attaché localement. Le matériel physique est déployé plutôt que le matériel virtualisé pour deux raisons :
Les serveurs sont mis à l’échelle pour utiliser 80 % des ressources pendant le mode de défaillance le plus grave.
La virtualisation est accompagnée d’une légère baisse des performances et d’une couche supplémentaire de gestion et de complexité, ce qui introduit des modes de récupération supplémentaires qui n’ajoutent pas de valeur, en particulier dans la mesure où Exchange Server fournit en mode natif les mêmes fonctionnalités.
Serveurs de produits de base
Les plateformes de serveurs de base sont utilisées dans l’autorité d’administration. Les plateformes de produits de base actuelles sont et incluent :
Serveurs à double socket 2U avec jusqu’à 48 cœurs de processeur physique (une augmentation par rapport à 24 cœurs dans Exchange 2016)
Jusqu’à 256 Go de mémoire (une augmentation par rapport à 192 Go dans Exchange 2016)
Contrôleur de cache d’écriture avec batterie
12 baies de lecteur ou plus dans le châssis du serveur
La possibilité de combiner le stockage à plateau pivotant traditionnel (HDD) et le stockage SSD (Solid State Storage) dans le même châssis.
Théorie de l’échelle
Il est important de noter que même si nous avons augmenté la capacité de processeur et de mémoire autorisée dans Exchange Server 2019, la recommandation de PG Exchange Server reste de monter en puissance plutôt que de monter en puissance. La montée en puissance signifie que nous préférerions que vous déployiez un plus grand nombre de serveurs avec un peu moins de ressources par serveur plutôt qu’un plus petit nombre de serveurs denses utilisant un maximum de ressources et remplis d’un grand nombre de boîtes aux lettres. En localisant un nombre raisonnable de boîtes aux lettres au sein d’un serveur, vous réduisez l’impact de toute panne planifiée ou non planifiée et vous réduisez le risque de découvrir d’autres goulots d’étranglement du système.
Une augmentation des ressources système ne doit pas entraîner l’hypothèse selon laquelle vous constaterez des gains de performances linéaires dans Exchange Server 2019 en utilisant le nombre maximal de ressources autorisées lors de la comparaison avec les ressources maximales autorisées d’Exchange 2016. Chaque nouvelle version d’Exchange apporte de nouveaux processus et mises à jour qui, à leur tour, rendent difficile la comparaison d’une version actuelle à une version antérieure. Suivez tous les conseils de dimensionnement de Microsoft pour déterminer la conception de votre serveur.
Stockage
Des baies de lecteurs supplémentaires peuvent être directement attachées par serveur en fonction du nombre de boîtes aux lettres, de la taille des boîtes aux lettres et de la scalabilité des ressources du serveur.
Chaque serveur héberge une paire de disques RAID1 unique pour le système d’exploitation, les fichiers binaires Exchange, les journaux du protocole/client et la base de données de transport.
Le stockage restant est configuré en tant que JBOD (Just a Bunch of Disks). N’oubliez pas que certains contrôleurs de stockage matériels peuvent nécessiter que chaque disque soit configuré en tant que groupe RAID0 à disque unique pour que la mise en cache en écriture soit utilisée. Consultez le fabricant de votre matériel pour confirmer la configuration appropriée pour votre système qui garantit l’utilisation du cache d’écriture.
La nouveauté de la pa Exchange Server 2019 est la recommandation de disposer de deux classes de stockage pour tout ce qui n’est pas déjà situé sur la paire de disques RAID1 mentionnée précédemment.
Classe de stockage traditionnelle
Cette classe de stockage contient Exchange Server fichiers de base de données et Exchange Server fichiers journaux des transactions. Ces disques sont des disques SCSI (SAS) attachés en série d’une grande capacité de 7,2 000 tr/min. Bien que des disques SATA soient également disponibles, nous observons de meilleures E/S et un taux de défaillance annualisé inférieur à l’aide de l’équivalent SAS.
Pour vous assurer que la capacité et les E/S de chaque disque sont utilisées aussi efficacement que possible, jusqu’à quatre copies de base de données sont déployées par disque. La disposition de copie normale au moment de l’exécution garantit qu’il n’y a pas plus d’une seule copie de base de données active par disque.
Au moins un disque du pool de disques de stockage traditionnel est réservé en tant que disque de secours. AutoReseed est activé et restaure rapidement la redondance de la base de données après une défaillance de disque en activant le disque de secours à chaud et en lançant la nouvelle copie de la base de données.
Classe de stockage solid-state
Cette classe de stockage contient les nouveaux fichiers MCDB (MetaCache Database) d’Exchange 2019. Ces disques SSD peuvent se présenter dans différents facteurs de forme tels que, mais sans s’y limiter, les lecteurs SAS 2.5"/3.5 » traditionnels connectés ou les lecteurs connectés PCIe M.2.
Les clients doivent s’attendre à déployer environ 5 à 10 % de stockage supplémentaire en tant que stockage ssd. Par exemple, si un serveur unique était censé contenir 28 To de fichiers de base de données de boîtes aux lettres sur le stockage traditionnel, un stockage ssd supplémentaire de 1,4 à 2,8 To supplémentaires serait également recommandé comme stockage supplémentaire pour le même serveur.
Les disques ssd et traditionnels doivent être déployés dans un ratio 3:1 si possible. Pour trois disques traditionnels au sein du serveur, un seul disque SSD est déployé. Ces disques SSD contiennent les mcdb pour toutes les bases de données au sein des trois disques traditionnels associés. Cette recommandation limite le domaine d’échec qu’une défaillance de disque SSD peut imposer à un système. En cas de défaillance d’un disque SSD, Exchange 2019 bascule toutes les copies de base de données utilisant ce disque SSD pour leur MCDB vers un autre nœud DAG avec des ressources MCDB saines pour la base de données affectée. La limitation du nombre de basculements de base de données réduit le risque d’impact sur les utilisateurs si un grand nombre de bases de données partageaient un plus petit nombre de disques SSD.
En cas de défaillance du service Exchange High Availability d’un disque SSD, tente de monter les bases de données affectées sur différents nœuds DAG où il existe toujours un MCDB sain pour chaque base de données affectée. Si, pour une raison quelconque, il n’existe aucun MCDB sain pour l’une des bases de données affectées, les services De haute disponibilité Exchange laisseront la copie de base de données affectée locale en cours d’exécution sans les avantages en matière de performances de la base de données MCDB.
Par exemple, si un client devait déployer un système capable de contenir 20 lecteurs, il peut avoir une disposition semblable à celle-ci.
2 DISQUES DURS pour la mise en miroir du système d’exploitation, les fichiers binaires Exchange et la base de données de transport
12 disques durs pour le stockage de base de données Exchange
1 DISQUE DUR comme disque de rechange AutoReseed
4 disques SSD pour les MCDB Exchange qui fournissent entre 5 et 10 % de la capacité de stockage de base de données cumulée.
Si vous le souhaitez, un client peut choisir d’ajouter un disque SSD de rechange ou un deuxième lecteur autoréseed.
Cette configuration peut être visualisées à l’aide du diagramme suivant :
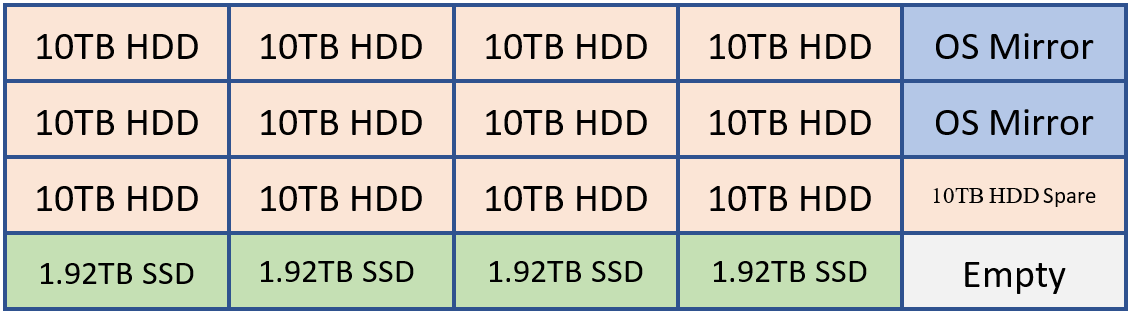
Dans l’exemple ci-dessus, nous avons 120 To de stockage de base de données Exchange et 7,68 To de stockage MCDB, soit environ 6,4 % de l’espace de stockage de base de données traditionnel. Avec cette quantité de stockage MCBD, nous sommes parfaitement alignés sur les recommandations de 5 à 10 %. Chacun des lecteurs de 10 To contiendra quatre copies de base de données et chaque lecteur MCDB contiendrait 12 mcdb.
Paramètres de stockage courants
Qu’ils soient traditionnels ou ssd, tous les disques qui hébergent des données Exchange sont formatés avec ReFS (avec la fonctionnalité d’intégrité désactivée) et le DAG est configuré de manière à ce que autoreseed formate les disques avec ReFS :
Set-DatabaseAvailabilityGroup -Identity <DAGIdentity> -FileSystem ReFS
BitLocker est utilisé pour chiffrer chaque disque, fournissant ainsi un chiffrement des données au repos et atténuant les problèmes liés au vol de données ou au remplacement du disque. Pour plus d’informations, consultez Activation de BitLocker sur les serveurs Exchange.
Conception du groupe de disponibilité de base de données
Dans chaque paire de centres de données résilients au site, vous aurez un ou plusieurs DAG. Il n’est pas recommandé d’étendre un DAG sur plus de deux centres de données.
Configuration du DAG
Comme pour le modèle d’espace de noms, chaque DAG au sein de la paire de centres de données résilients au site fonctionne dans un modèle indépendant avec des copies actives réparties de manière égale sur tous les serveurs du DAG. Ce modèle :
Garantit que la pile complète de services de chaque membre du DAG (connectivité cliente, pipeline de réplication, transport, etc.) est validée pendant les opérations normales.
Répartit la charge sur autant de serveurs que possible lors d’un scénario de défaillance, ce qui permet d’augmenter de façon incrémentielle l’utilisation des ressources entre les membres restants au sein du DAG.
Chaque centre de données est symétrique, avec un nombre égal de membres DAG dans chaque centre de données. Cela signifie que chaque DAG a un nombre pair de serveurs et utilise un serveur témoin pour la maintenance du quorum.
Le DAG est le bloc de construction fondamental dans Exchange 2019. En ce qui concerne la taille du DAG, un DAG avec un plus grand nombre de nœuds membres participants offre davantage de redondance et de ressources. Au sein du pa, l’objectif est de déployer des DAG avec un plus grand nombre de nœuds membres, en commençant généralement par un DAG de huit membres et en augmentant le nombre de serveurs en fonction des besoins. Vous ne devez créer de nouveaux DAG que lorsque l’extensibilité présente des problèmes concernant la disposition de copie de base de données existante.
Conception du réseau DAG
Le pa utilise une interface réseau unique, sans association, pour la connectivité cliente et la réplication des données. Une seule interface réseau est tout ce qui est nécessaire, car en fin de compte, notre objectif est d’atteindre un modèle de récupération standard, quelle que soit la défaillance du serveur . Qu’une défaillance de serveur se produise ou qu’une défaillance réseau se produise, le résultat est le même : une copie de base de données est activée sur un autre serveur dans le DAG. Cette modification architecturale simplifie la pile réseau et évite la nécessité d’éliminer manuellement la conversation croisée des pulsations.
Placement du serveur témoin
L’emplacement du serveur témoin détermine si l’architecture peut fournir des fonctionnalités de basculement automatique du centre de données ou si elle nécessite une activation manuelle pour activer le service en cas de défaillance du site.
Si votre organisation dispose d’un troisième emplacement avec une infrastructure réseau isolée des défaillances réseau qui affectent la paire de centres de données résilients au site dans laquelle le DAG est déployé, il est recommandé de déployer le serveur témoin du DAG dans ce troisième emplacement. Cette configuration donne au DAG la possibilité de basculer automatiquement les bases de données vers l’autre centre de données en réponse à un événement de défaillance au niveau du centre de données, quel que soit le centre de données en panne.
Si votre organisation n’a pas de troisième emplacement, envisagez de placer le témoin de serveur dans Azure . vous pouvez également placer le serveur témoin dans l’un des centres de données au sein de la paire de centres de données résilients au site. Si vous avez plusieurs DAG dans la paire de centres de données résilients au site, placez le serveur témoin pour tous les DAG dans le même centre de données (généralement le centre de données où la plupart des utilisateurs se trouvent physiquement). En outre, assurez-vous que le gestionnaire actif principal (PAM) pour chaque DAG se trouve également dans le même centre de données.
Exchange Server 2019 et toutes les versions antérieures ne prennent pas en charge l’utilisation de la fonctionnalité Témoin cloud introduite pour la première fois dans Windows Server 2016 cluster de basculement.
Résilience des données
La résilience des données est obtenue en déployant plusieurs copies de base de données. Dans la pa, les copies de base de données sont distribuées entre la paire de centres de données résilients au site, garantissant ainsi que les données de boîte aux lettres sont protégées contre les défaillances logicielles, matérielles et même du centre de données.
Chaque base de données a quatre copies, avec deux copies dans chaque centre de données, ce qui signifie qu’au minimum, le pa nécessite quatre serveurs. Sur ces quatre copies, trois d’entre elles sont configurées comme hautement disponibles. La quatrième copie (la copie avec le numéro de préférence d’activation le plus élevé) est configurée en tant que copie de base de données avec décalage. En raison de la conception du serveur, chaque copie d’une base de données est isolée de ses autres copies, ce qui réduit les domaines d’échec et augmente la disponibilité globale de la solution, comme indiqué dans DAG : Beyond the « A ».
L’objectif de la copie de base de données en retard est de fournir un mécanisme de récupération pour le rare événement de corruption logique catastrophique à l’échelle du système. Il n’est pas destiné à la récupération individuelle de boîtes aux lettres ou à la récupération d’éléments de boîte aux lettres.
La copie de base de données différée est configurée avec un ReplayLagTime de sept jours. En outre, le Gestionnaire de décalage de relecture est également activé pour fournir une lecture dynamique du fichier journal pour les copies différées lorsque la disponibilité est compromise en raison de la perte de copies non différées.
En utilisant la copie de base de données en retard de cette manière, il est important de comprendre que la copie de base de données en retard n’est pas une sauvegarde à un instant dans le temps garantie. La copie de base de données retardée aura un seuil de disponibilité, généralement d’environ 90 %, en raison des périodes où le disque contenant une copie retardée est perdu en raison d’une défaillance du disque, la copie retardée devient une copie haute disponibilité (en raison de la lecture automatique) et des périodes où la copie de base de données retardée reconstruit la file d’attente de relecture.
Pour vous protéger contre la suppression accidentelle (ou malveillante) d’éléments, les technologies de récupération d’élément unique ou de conservation sur place sont utilisées, et la fenêtre Rétention des éléments supprimés est définie sur une valeur qui respecte ou dépasse tout contrat SLA de récupération au niveau de l’élément défini.
Avec toutes ces technologies en jeu, les sauvegardes traditionnelles sont inutiles. par conséquent, le pa utilise la protection des données natives Exchange.
conception Office Online Server
Au minimum, vous souhaiterez déployer une batterie de serveurs Office Online Server (OOS) avec au moins deux nœuds OOS dans chaque centre de données qui héberge des serveurs Exchange 2019. Chaque Office Online Server doit avoir au moins 8 cœurs de processeur, 32 Go de mémoire et au moins 40 Go d’espace dédié aux fichiers journaux. Les serveurs de boîtes aux lettres Exchange 2019 doivent être configurés pour s’appuyer sur la batterie de serveurs OOS locale dans leur centre de données afin de garantir la latence la plus faible possible et la bande passante la plus élevée possible entre les serveurs afin de restituer le contenu du fichier aux utilisateurs.
Résumé
Exchange Server 2019 continue d’améliorer les investissements introduits dans les versions précédentes d’Exchange et introduit des technologies supplémentaires inventées à l’origine pour une utilisation dans Microsoft 365 et Office 365.
En vous alignant sur l’architecture préférée, vous tirerez parti de ces modifications et fournirez la meilleure expérience utilisateur locale possible. Vous allez poursuivre la tradition d’un déploiement Exchange hautement fiable, prévisible et résilient.